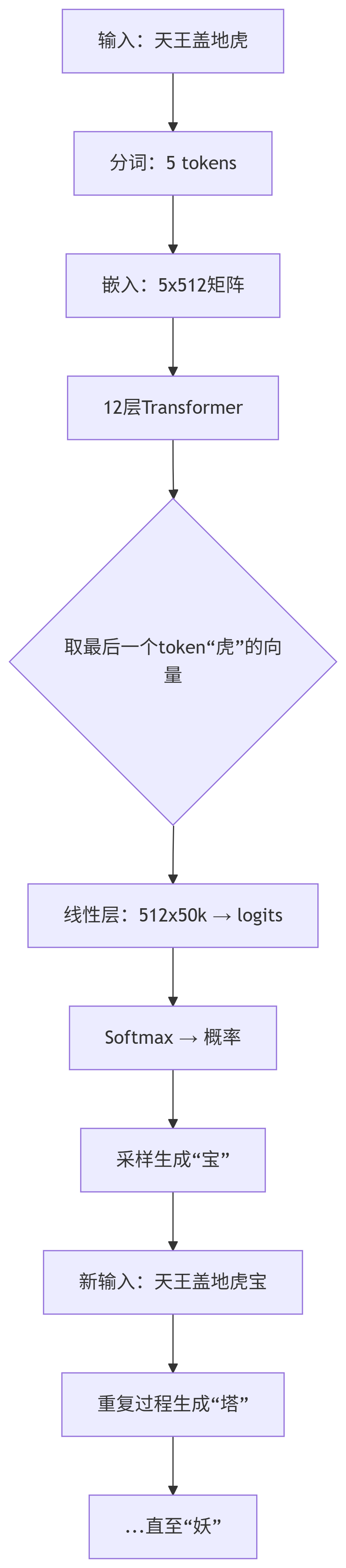
以对对子为例的transformer过程
摘要:对对联"天王盖地虎"→"宝塔镇神妖"的过程解析:1)输入分词为5个字token;2)通过512维词向量矩阵进行Embedding编码;3)经12层Transformer处理,每层通过自注意力机制建立字间关联(如"虎"关注"盖");4)基于最后一字向量生成概率分布,依次自回归输出5个目标token。BGE等嵌入模型
核心提示:对对子,输入天王盖地虎,输出是宝塔镇神妖。宝塔镇神妖是几个token?形象说明整个过程, embedding,多少个维度向量,词汇表是咋回事,经过几层神经网络,怎么就拼成一个宝塔镇神妖。
1. 输入与分词(Tokenization)
-
输入序列:
"天王盖地虎" -
分词结果(假设使用字级别分词,实际可能用BPE/WordPiece):
["天", "王", "盖", "地", "虎"] # 5个token
-
词汇表(Vocabulary):模型训练时定义的所有可能token的集合(例如5万个中文汉字+符号)。
假设词汇表:{0:"<pad>", 1:"天", 2:"王", 3:"盖", 4:"地", 5:"虎", 6:"宝", 7:"塔", 8:"镇", 9:"神", 10:"妖", ...}
2. 输入编码(Embedding)
-
每个token转换为向量(假设维度d_model=512):
"天" → 向量 [0.2, -0.7, ..., 1.1](512维)
"王" → 向量 [0.8, 0.3, ..., -0.5](512维)
...
-
输入矩阵:5个token →
5×512的矩阵
3.神经网络层层处理(Transformer Blocks)
-
Transformer层数(假设12层):

-
每层操作:
-
自注意力机制:计算每个token与其他token的关系(如
"虎"关注"盖") -
前馈神经网络:非线性变换更新每个token的向量表示
-
-
输出:经过12层后,得到 更新后的5×512矩阵(每个token的语义更丰富了)
4. 输出层:生成下一个token "宝"
关键!模型是逐词生成的,首先生成第一个字「宝」:
Step 1:取最后一个token的向量
-
输入序列最后一个token是
"虎"→ 取其输出向量(512维)"虎"向量 = [0.1, -0.2, ..., 0.9]
Step 2:通过线性层生成logits
-
线性层(输出层):一个
512×V的矩阵(V=词汇表大小,假设5万) -
计算:
logits = "虎"向量 × 线性层矩阵→ 得到一个 1×50,000的向量,每个元素是对应token的原始分数
举例logits(未归一化):
[ "宝": 8.2, "山": 1.5, "剑": 0.9, "塔": -0.3, ... , "天": -4.1 ]
Step 3:Softmax转概率
-
Softmax处理:将logits转换为概率分布
probs = softmax([8.2, 1.5, 0.9, -0.3, ..., -4.1])
→ [ "宝": 0.85, "山": 0.06, "剑": 0.04, ... ]
Step 4:采样生成"宝"
-
根据概率采样:85%概率选
"宝"→ 输出"宝" -
更新输入:
"天王盖地虎"+"宝"→ 新输入序列["天", "王", "盖", "地", "虎", "宝"]
5. 继续生成后续token
重复上述过程,自回归生成:
-
输入
["天","王","盖","地","虎","宝"]→ 取最后一个token"宝"的向量 -
生成logits → 概率 → 采样 → 输出
"塔"(假设概率最高) -
更新输入:
[... "宝", "塔"]→ 生成"镇" -
更新输入:
[... "塔", "镇"]→ 生成"神" -
更新输入:
[... "镇", "神"]→ 生成"妖"
最终输出序列:"宝塔镇神妖"
关键图解
总结
-
词汇表是什么? → 模型认识的所有token的字典(如5万个中文汉字/词)。
-
输出是几个token? →
"宝塔镇神妖"按字分词是 5个token(实际分词方式可能不同)。 -
Logits在哪生成? → 输出层的线性层为词汇表中每个token生成1个分数(50,000个分数)。
-
为何能拼成完整句子? → 自回归机制:每次生成1个token,并作为新输入的一部分,循环生成直至结束。
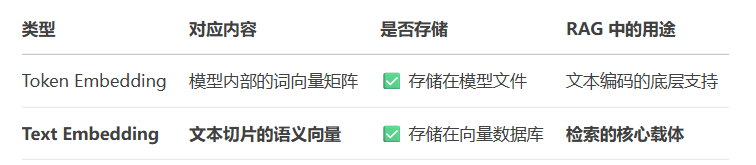
1.词汇表的向量化:Embedding 层
-
每个 token 确实有专属向量:词汇表中的每个 token(字/词/子词)都有一个固定长度的向量表示(如 512 维)。
-
存储位置:这些向量存放在模型的 Embedding 层(词嵌入矩阵) 中,这是一个可训练的权重矩阵。
-
数学表示:
Embedding_Matrix =
[ [0.1, 0.3, ..., -0.2], # token 0 ("") 的向量
[0.8, -0.5, ..., 1.1], # token 1 ("天") 的向量
...,
[0.4, 0.9, ..., -0.7] # token 50000 ("妖") 的向量]
形状:[vocab_size × d_model]
(例:50,000 个 token × 512 维)
2. Embedding 层的本质:巨型查找表
-
工作原理: 当输入 token "天"(假设 ID=1)时:
输入:token_id = 1
输出:Embedding_Matrix[1] = [0.8, -0.5, ..., 1.1] (512维向量)
相当于用 token ID 作为下标检索矩阵中的行。
-
存储与内存:
-
该矩阵是模型文件的一部分(通常占用 70%+ 的模型体积)。
-
以 50,000 词汇表 × 512 维 × 4字节/浮点数 计算:
50,000 × 512 × 4 ≈ 102,400,000 字节 ≈ 102 MB
这仅是 Embedding 层的权重,实际模型还有其他参数。
-
3. 为什么需要存储?动态计算不行吗?
-
效率问题:如果每次推理都动态计算向量:
-
需要实时运行复杂函数(如哈希+变换)
-
破坏可训练性(无法通过梯度下降优化)
-
-
语义学习: 向量值是通过训练学习的(如 "皇帝" 和 "国王" 向量接近),存储矩阵是知识压缩的结果。
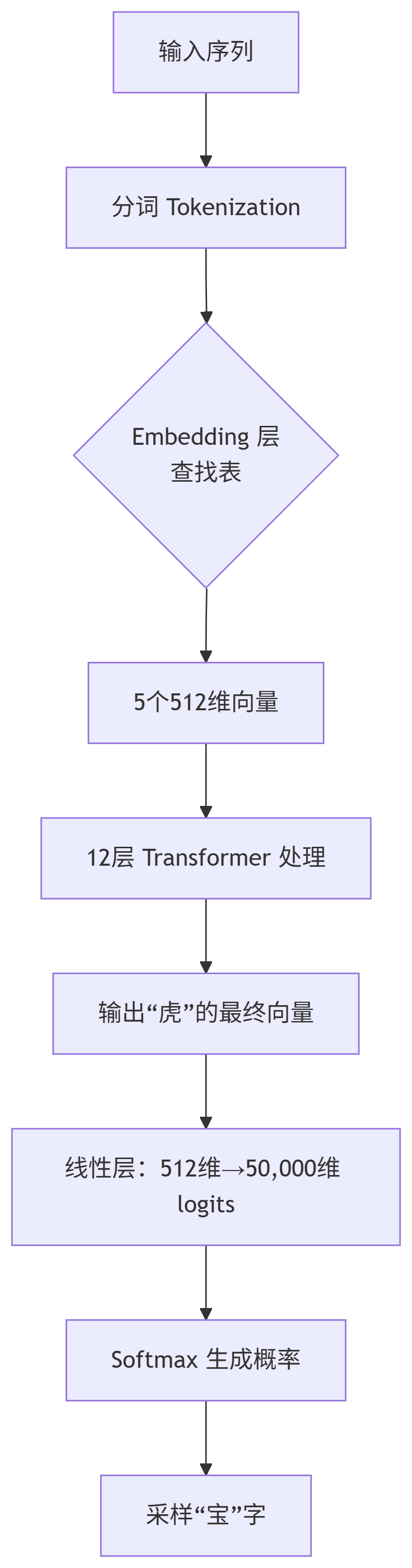
4. 结合例子的完整流程
场景:输入 "天王盖地虎" → 生成 "宝塔镇神妖"
关键步骤详解:
-
输入分词: ["天", "王", "盖", "地", "虎"] → 获取 ID [1, 2, 3, 4, 5]
-
Embedding 查表:
"天"(ID=1) → [0.8, -0.5, ..., 1.1] # 来自矩阵第1行
"王"(ID=2) → [0.3, 1.2, ..., -0.4] # 来自矩阵第2行
... # 其他token同理
-
Transformer 处理: 各层逐步更新向量,最终 "虎" 的向量变为: [0.1, -0.2, ..., 0.9](包含上下文信息)
-
生成第一个字 "宝":
线性层运算:512维 → 50,000维
# 公式: logits = vector_虎 × W_linear
# 其中 W_linear 是 [512×50000] 矩阵
logits = [宝:8.2, 山:1.5, 剑:0.9, ...]
-
-
Softmax 生成概率:宝:0.85, 山:0.06, ...
-
采样选择 "宝"
-
-
生成后续字:
将 "宝" 加入输入,重复上述过程(此时用 "宝" 的向量生成 "塔")。
5. 为什么同一个字在不同位置向量不同?
-
关键误区澄清: Embedding 层输出的向量只是初始表示! 经过 Transformer 层处理后,每个 token 的向量会融合上下文信息:
-
初始 "虎" 向量:表示字面含义(猫科动物)
-
最终 "虎" 向量:在 "天王盖地虎" 中表示「暗号应答」的语义
-
✅ 总结:
-
词汇表向量存储在 Embedding 层权重矩阵中(模型文件的核心部分)
-
该矩阵本质是 token ID → 向量 的查找表
-
存储是必须的,否则无法高效训练和推理
-
同一个字在不同位置的差异由 Transformer 动态修正
通过这种机制,模型才能理解 "苹果手机" 和 "吃苹果" 中的「苹果」有不同含义,这正是大语言模型的神奇之处!
Embedding 的讲究:向量如何蕴含语义?
Embedding 的本质是将离散符号映射到连续向量空间,其「讲究」体现在三方面:
|
核心要素 |
说明 |
示例 |
|---|---|---|
|
语义相似度 |
语义相近的词向量距离小 |
国王 - 男人 + 女人 ≈ 王后(向量加减) |
|
多义性处理 |
同一词在不同语境向量不同(由后续 Transformer 实现) |
苹果在「吃苹果」vs「苹果手机」中位置不同 |
|
几何结构 |
向量空间隐含语义关系(上下位/反义/语法) |
动物→狗→金毛呈层级分布;快-慢方向相反 |
|
维度选择 |
越高维表达能力越强,但计算成本增加(常用 256-1024 维) |
BGE 常用 768 维 (见下文) |
✅ 向量值形成原理:
-
预训练阶段:通过自监督任务(如掩码语言建模 MLM)学习
loss = -∑ log P(token_i | context) # 让模型根据上下文预测被遮蔽的词
-
微调阶段:通过对比学习优化语义空间(如 BGE 的 Retromae 方法)
# 正样本:相似文本对 (query, doc+) # 负样本:不相关文本 (query, doc-) loss = max(0, margin - sim(q, doc+) + sim(q, doc-))
最终效果:语义相似的文本在向量空间中靠近(余弦相似度高)
2. BGE 的维度:行业标准实践
BGE(BAAI General Embedding) 是当前最先进的开源文本嵌入模型:
-
常用版本:BGE-large-zh / BGE-m3
-
向量维度:
模型版本维度特点BGE-base-zh768平衡效率与效果BGE-large-zh1024更高精度,适合对质量敏感场景BGE-m31024支持多语言、多任务
实验数据:在中文语义搜索任务 (T2Ranking) 上,BGE-large-zh 的 nDCG@10 达到 62.3%(超越 OpenAI text-embedding-ada-002)
3. RAG 中的切片向量化:关键设计
RAG 的文档处理流程:
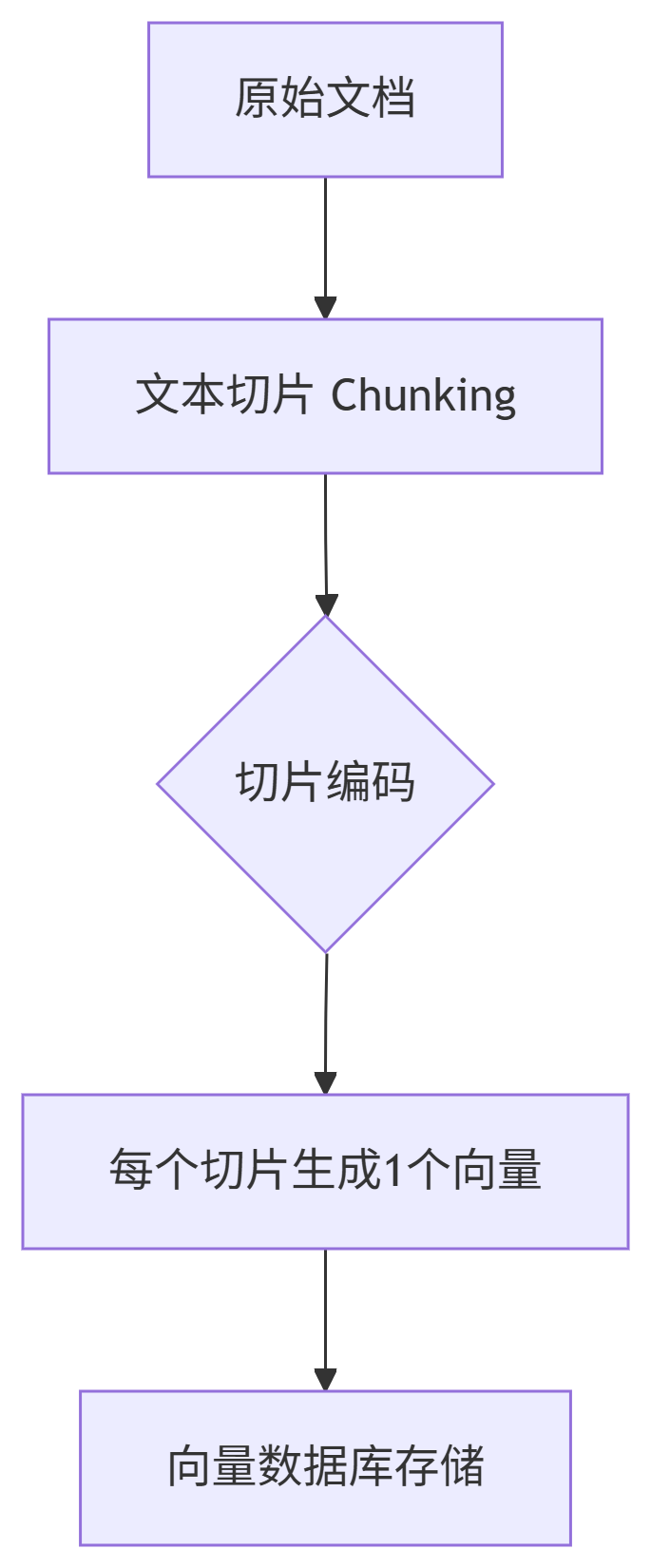
核心规则:
-
一个切片 = 一个向量
-
编码方式:
# 使用 BGE 编码整个切片文本 vector = model.encode("天王盖地虎是...") # 输出 768/1024 维向量
为什么不用多个向量?
|
方案 |
问题 |
RAG选择 |
|---|---|---|
|
整文档单向量 |
丢失细节,无法精确定位 |
❌ |
|
每句子一个向量 |
碎片化,破坏段落逻辑 |
❌ |
|
语义切片单向量 |
保持上下文完整性,便于检索相关片段 |
✅ |
关键技术验证实验
假设我们处理《林海雪原》文档:
切片1
chunk1 = "天王盖地虎是接头暗号,表示请求对方身份"
vector1 = [0.2, -0.3, ..., 0.8] # 768维
切片2
chunk2 = "宝塔镇神妖是正确回应,表明自己为游击队员"
vector2 = [0.7, 0.1, ..., -0.4]
用户提问
query = "暗号回应是什么?"
query_vec = [0.5, 0.0, ..., -0.2]
向量数据库检索
similarity = cosine_sim(query_vec, vector2) # 得分为0.92(最高)
→ 返回切片2的文本作为答案来源
总结:嵌入技术的精髓
-
Embedding 讲究:
-
RAG 切片原则:
实践建议:
-
中文 Embedding 首选 BGE-large-zh (1024维)
-
RAG 切片长度设置在 200-300 汉字
-
使用余弦相似度做检索
场景设定
-
任务:搭建《林海雪原》知识库的 RAG 系统
-
嵌入模型:BGE-large-zh(1024 维)
-
文档切片:
切片1: "天王盖地虎是接头暗号,表示请求对方身份"
切片2: "宝塔镇神妖是正确回应,表明自己为游击队员"
1. 词汇表(Vocabulary)在 BGE 中的本质
在 BGE 这类文本嵌入模型中,词汇表不是传统语言模型的 token 集合!这是关键区别:
|
模型类型 |
词汇表组成 |
示例 |
大小 |
|---|---|---|---|
|
生成式 LLM |
字/词/subword token |
["天", "王", "盖", ...] |
5-10万 |
|
BGE 嵌入模型 |
完整文本片段的语义编码 |
切片1的语义空间坐标 |
无限大 |
✅ 核心区别:
-
BGE 的"词汇表"是动态语义空间而非固定 token 列表
-
每个"词条"对应一个文本切片的语义表示
-
可容纳任意新文本,无需预定义词典
例如当新增切片:
切片3: "脸怎么黄了?防冷涂的蜡!"
BGE 会直接为其生成新向量,无需扩展"词汇表"
2. Embedding 的双重含义
在 RAG+BGE 场景中,Embedding 有两个层级:
(1) 模型内部的 Token Embedding(静态矩阵)
-
是什么:BGE 模型底层 Transformer 的词向量矩阵
-
形状:[vocab_size × hidden_dim](例:30,000×1024)
-
作用:将输入文本的 token 转为初始向量
-
存储位置:BGE 模型文件中的 embedding.weight
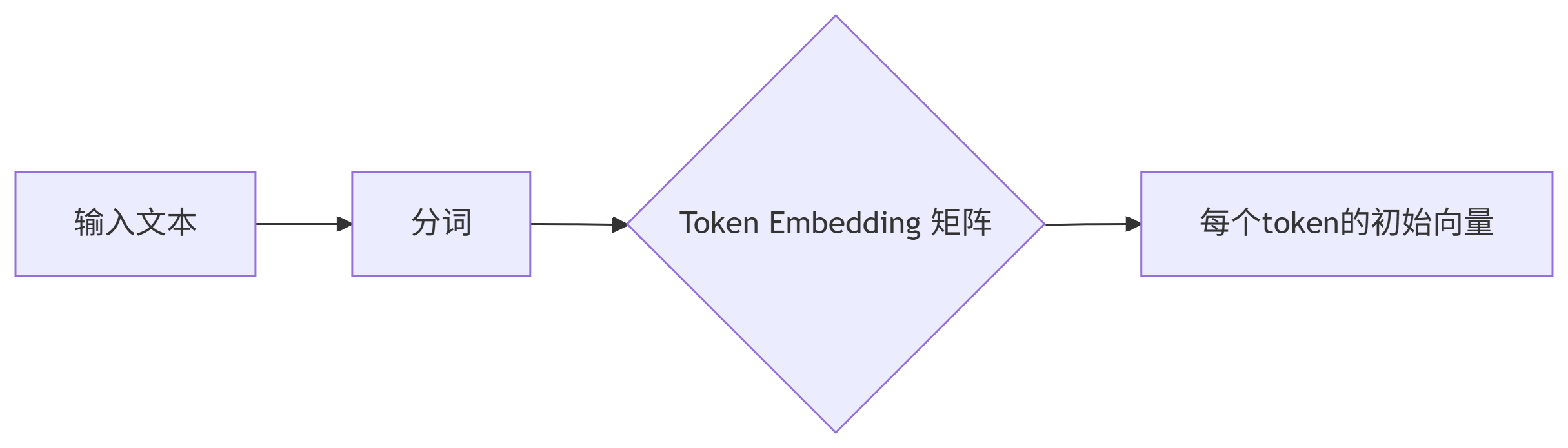
(2) 输出的 Text Embedding(动态语义向量)
是什么:整个文本切片的语义表示
形状:[1 × output_dim](1024 维)
生成方式:
#BGE 的文本编码过程
text = "天王盖地虎是接头暗号"
token_vectors = embedding_layer(token_ids) # [seq_len, 1024]
context_vectors = transformer_layers(token_vectors) # [seq_len, 1024]
text_vector = mean_pooling(context_vectors) # [1, 1024]
3. RAG 全流程演示

步骤详解:
-
文档处理:
-
用户提问:
-
检索计算:
sim(V1, QV) = 0.35
sim(V2, QV) = 0.92 # 返回切片2
关键结论
-
词汇表:
-
Embedding:
-
RAG 存储逻辑:
# 向量数据库示例
vector_db = {
"id1": {"text": "天王盖地虎...", "vector": [0.2, -0.3, ...]},
"id2": {"text": "宝塔镇神妖...", "vector": [0.7, 0.1, ...]}}
当使用 model.encode(text) 时:
-
消耗了 Token Embedding(静态矩阵)
-
生成了 Text Embedding(动态语义向量)
-
后者才是 RAG 的检索对象
这种设计使 BGE 能处理训练时未见的新概念(如"量子纠缠"),只需编码其语义即可加入"词汇表"(向量数据库),这才是现代嵌入模型的强大之处!
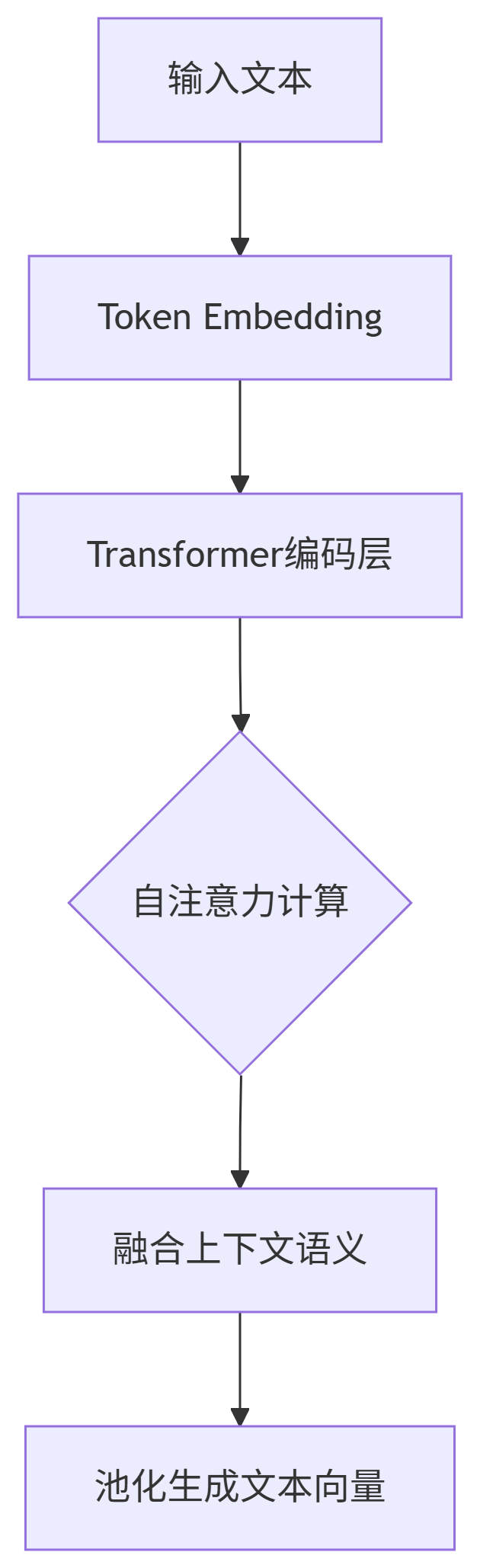
注意力机制在对联生成中的作用
场景复现(以GPT类模型为例):

关键步骤解析:
-
编码阶段(处理输入):
Query_地 = W_q · vector_地
Key_天 = W_k · vector_天
...
# 注意力权重 (反映字词关联性)
attn_权重 = softmax(Query_地 · [Key_天, Key_王, Key_盖, Key_地] / √d)
→ [天:0.02, 王:0.03, 盖:0.9, 地:0.05] # 强烈关注"盖"
作用:发现"盖地"是紧密组合(动词+宾语)
-
解码阶段(生成输出):
Query_虎 = W_q · vector_虎
Key_输入 = [Key_天, Key_王, Key_盖, Key_地, Key_虎]
attn_权重 = softmax(Query_虎 · Key_输入 / √d)
→ [天:0.6, 王:0.3, 盖:0.05, 地:0.03, 虎:0.02] # 强烈关注"天"
逻辑:意识到首字"天"需要工整对应(天王→宝塔)
-
生成结果:
"盖地"(权重高) → 推测需接动词+名词结构("镇神")
✅ 核心作用总结:
-
定位关键成分:识别"盖地"作为语义单元
-
建立远距离关联:连接首字"天"与待生成字
-
抑制无关信息:降低"虎"自身对生成的影响(权重仅0.02)
二、RAG/BGE中的注意力机制
在BGE嵌入模型中的运作:
具体作用:
-
语义聚焦:
# 注意力矩阵示例:
宝: [0.1, 0.1, 0.7, 0.0, 0.0, 0.1] # 聚焦"镇"
塔: [0.1, 0.2, 0.6, 0.0, 0.0, 0.1] # 聚焦"镇"
镇: [0.3, 0.3, 0.1, 0.2, 0.1, 0.0] # 分散关注
神: [0.0, 0.0, 0.8, 0.1, 0.1, 0.0] # 回指"镇"
-
信息压缩:
在RAG检索中的体现:
当用户查询"暗号回应"时:
-
BGE编码查询:
-
匹配过程:
# 计算相似度 (本质是向量空间中的注意力)
sim(查询向量, 切片向量) = 向量点积 / (||q||·||v||)
# 切片2的向量含"回应"语义 → 相似度0.92
# 切片1的向量含"请求"语义 → 相似度0.35
✅ 关键结论:
-
BGE 依赖注意力机制构建文本语义表示
-
RAG 的检索相似度是向量空间的注意力投射
三、注意力机制的本质对比
|
场景 |
注意力类型 |
作用目标 |
输出形式 |
|---|---|---|---|
|
对联生成 |
自注意力+交叉注意力 |
输入/输出的token关联 |
下一个token的概率 |
|
BGE嵌入 |
纯自注意力 |
文本内部语义结构 |
固定维度的语义向量 |
|
RAG检索 |
向量空间注意力 |
查询向量与文档向量的语义匹配 |
相似度分数 |
终极答案:
-
对联生成中的注意力: → 是模型「动态组词」的指挥官,通过权重分配实现:
-
RAG/BGE中的注意力: → BGE必然使用(Transformer编码器核心机制),用于:
正如人类对对联时需注意「天对宝,王对塔」的工整,又像检索时快速抓住「回应」这个关键词——注意力机制正是AI实现这类认知的核心技术。
1. 注意力机制的本质:三组动态权重
注意力不是单一矩阵,而是三重权重系统:
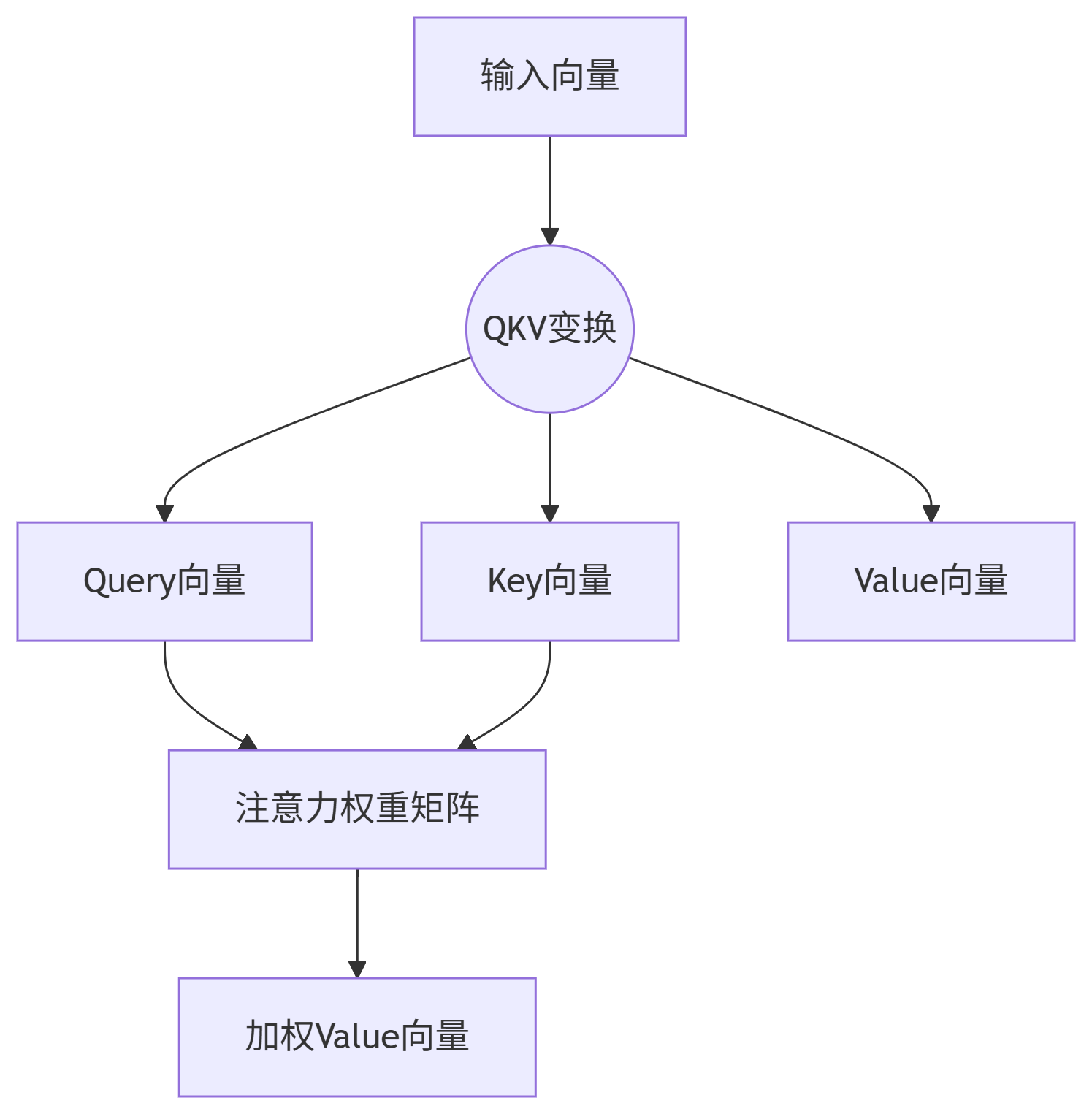
(1) 核心组件
|
组件 |
计算方式 |
物理形态 |
作用 |
|---|---|---|---|
|
Q矩阵 |
Q = X · W_q |
[d_model x d_k] |
生成查询向量 |
|
K矩阵 |
K = X · W_k |
[d_model x d_k] |
生成被查向量 |
|
V矩阵 |
V = X · W_v |
[d_model x d_v] |
携带实际信息 |
|
注意力权重 |
A = softmax(Q·Kᵀ/√d_k) |
[seq_len x seq_len] |
动态关联强度 |
✅ 关键区别:
-
W_q, W_k, W_v 是可训练参数矩阵(模型学到的知识)
-
注意力权重矩阵 A 是动态计算的结果(每次推理实时生成)
2. 在神经网络中的位置与计算
以生成「宝塔镇神妖」中首字「宝」为例:
具体计算步骤:
-
输入向量: X = [vec_天, vec_王, vec_盖, vec_地, vec_虎] (5×512矩阵)
-
QKV变换(传统神经元的扩展):
Q = X @ W_q # [5x512] · [512x64] → 5x64矩阵
K = X @ W_k # 同上
V = X @ W_v # [5x512] · [512x64] → 5x64
此处 W_q, W_k, W_v 就是 y=f(ax+b) 中的 权重参数 a,但扩展到矩阵形式
-
注意力权重计算(核心创新点):
计算关联分数
-
scores = Q @ K.T / √64 # [5x64] · [64x5] → 5x5矩阵
-
"""
-
示例scores:
-
天 王 盖 地 虎
-
天 3.2 -1.1 0.3 0.9 0.2
-
王 -0.8 4.1 2.3 -0.5 1.1
-
盖 0.1 0.7 5.6 3.2 0.8 # "盖"关注"地"
-
地 0.3 -0.2 3.8 4.0 1.3 # "地"关注"盖"
-
虎 1.2 0.9 0.5 0.7 2.0 # "虎"关注"天"
-
"""
-
Softmax归一化 → 注意力权重矩阵
-
A = softmax(scores, dim=-1)
-
"""
-
结果A:
-
天 王 盖 地 虎
-
天 0.85 0.01 0.03 0.09 0.02
-
王 0.02 0.75 0.15 0.03 0.05
-
盖 0.01 0.04 0.60 0.34 0.01 # "盖"的权重60%给自己,34%给"地"
-
地 0.01 0.02 0.40 0.55 0.02 # "地"的权重55%给自己,40%给"盖"
-
虎 0.35 0.25 0.10 0.15 0.15 # "虎"的注意力:35%在"天"
-
"""
-
加权Value输出:
Z = A @ V # [5x5] · [5x64] → 5x64矩阵
# 每个token的新向量 = 其他token向量的加权组合
# 例如"虎"的新向量 = 0.35*V_天 + 0.25*V_王 + ... + 0.15*V_虎
3. 与传统神经元的关系
y = f(ax + b) 是基础神经元模型:

注意力机制的革命性突破:
-
权重 a 动态化:
-
跨token计算:
-
信息融合方式:
# 传统全连接层 (Dense)
output = activation(W · X + b)
# 固定权重W # 注意力层
output = softmax( (X·W_q)(X·W_k)ᵀ / √d_k ) · (X·W_v) # 权重由输入决定
4. 在RAG/BGE中的具体位置
BGE作为Transformer编码器,其注意力计算在每一层内部:

关键计算时刻:
当BGE编码文本切片 "宝塔镇神妖" 时:
-
首层计算:
-
末层输出:
终极答案总结
|
您的疑问 |
技术解释 |
|---|---|
|
是权重矩阵吗? |
是动态生成的 [seq_len x seq_len] 矩阵,非固定参数 |
|
在何处用到? |
在Transformer的 每一层开头,作为信息融合的核心组件 |
|
与什么一起计算? |
1. 输入向量X 2. 可训练的QKV参数矩阵 3. 缩放因子√d_k 4. Softmax |
|
与传统神经元关系 |
扩展了 y=f(ax+b) 中 a 的动态性 和 跨token计算能力 |
示例中「虎」的注意力权重分配(35%给「天」)正是模型学会「天王→宝塔」对仗的关键!而BGE中「镇神」的高关联权重,使得该短语的语义被强化编码进向量——注意力机制就是AI的“思维焦点控制器”。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)