
一步一步教你使用云服务器部署爬虫
一步一步教你使用云服务器部署爬虫1. 注册阿里云,可以免费试用一个月的云服务器。每天十点0元抢购2. 点击进入阿里云领取页面3. 点击管理可以修改密码4.用显示的公网ip远程登录服务器,默认root用户,密码为刚才修改的密码5.登录成功6.安装 scrapyd服务端pip install scrapyd6.1配置scrapyd文件找到 default_scrapyd.con...
·
一步一步教你使用云服务器部署爬虫
1. 注册阿里云,可以免费试用一个月的云服务器。每天十点0元抢购
2. 点击进入阿里云领取页面
3. 点击管理可以修改密码
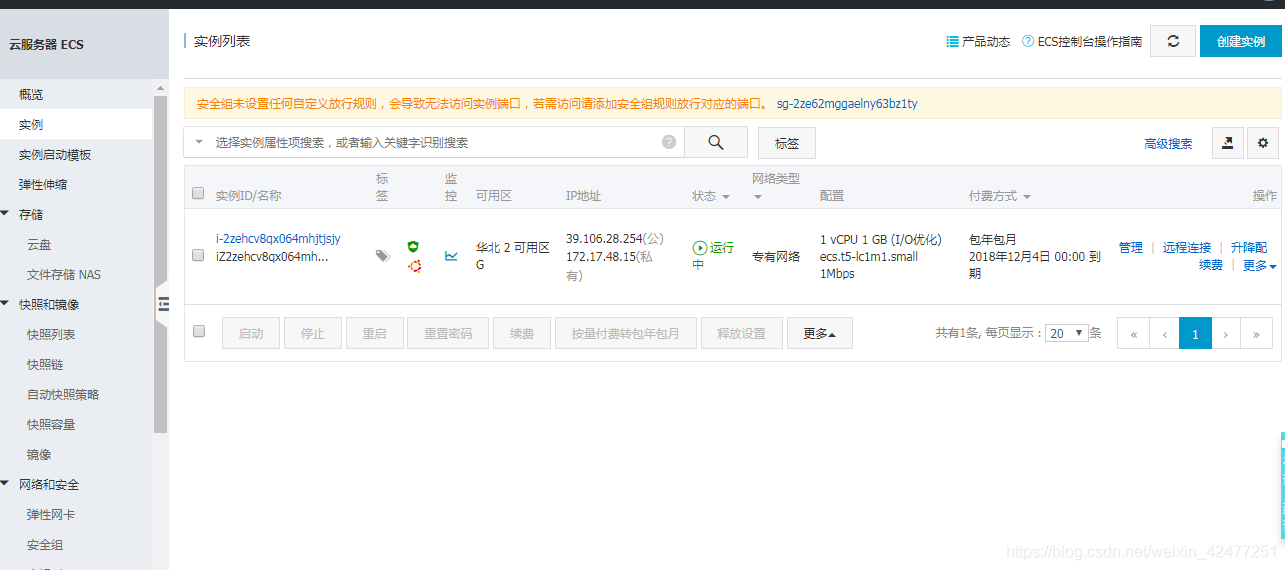
4.用显示的公网ip远程登录服务器,默认root用户,密码为刚才修改的密码
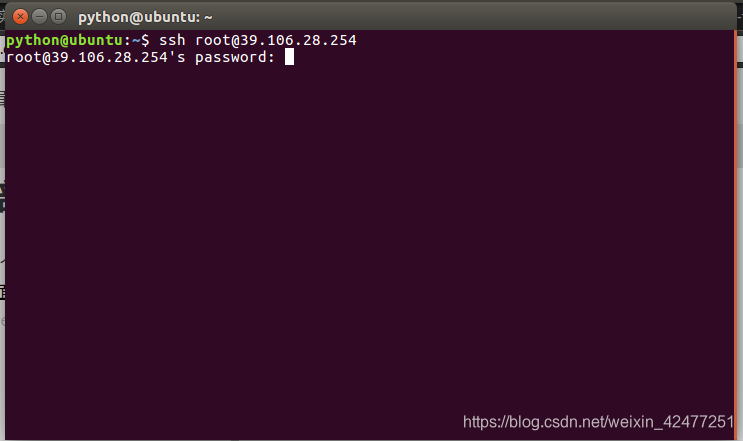
5.登录成功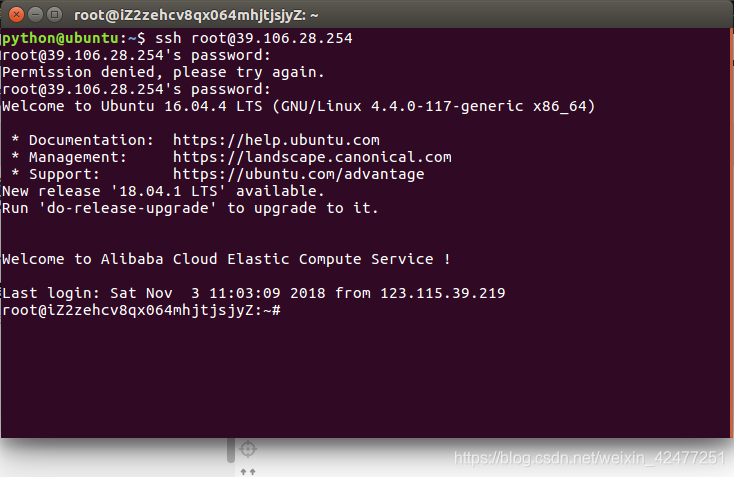
6.安装 scrapyd服务端
pip install scrapyd
6.1配置scrapyd文件
找到 default_scrapyd.conf 文件
使用find查找
sudo find / -name 'default_scrapyd.conf '

找到所用环境的default_scrapyd.conf文件,修改目录下的bind_address,把127.0.0.1修改成0.0.0.0允许远程访问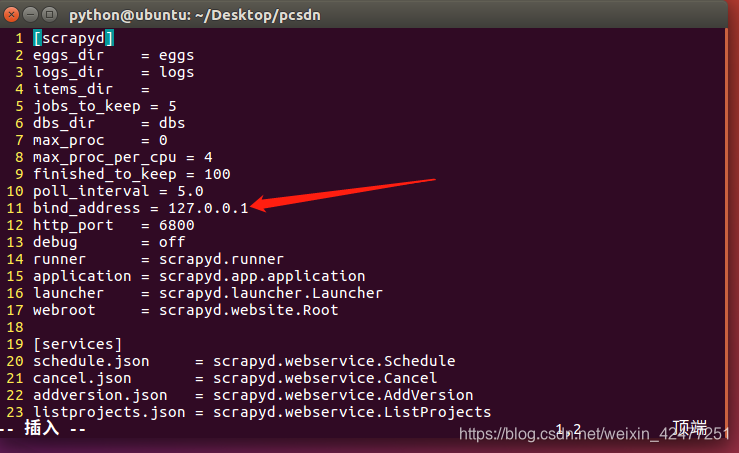
7.启动scrpyd
在scrapy项目路径下 启动scrapyd的命令
sudo scrapyd
8.启动之后把6800端口加入安全组配置,使从外网可以访问到服务器
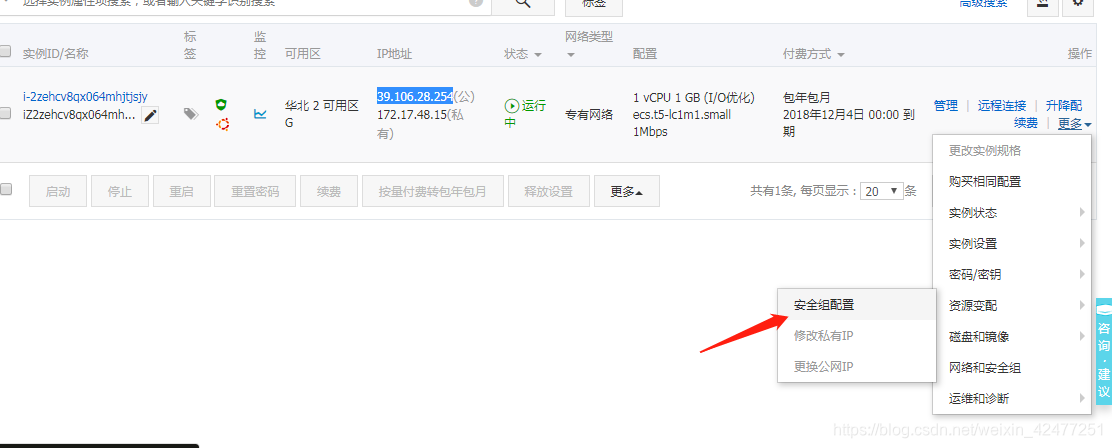
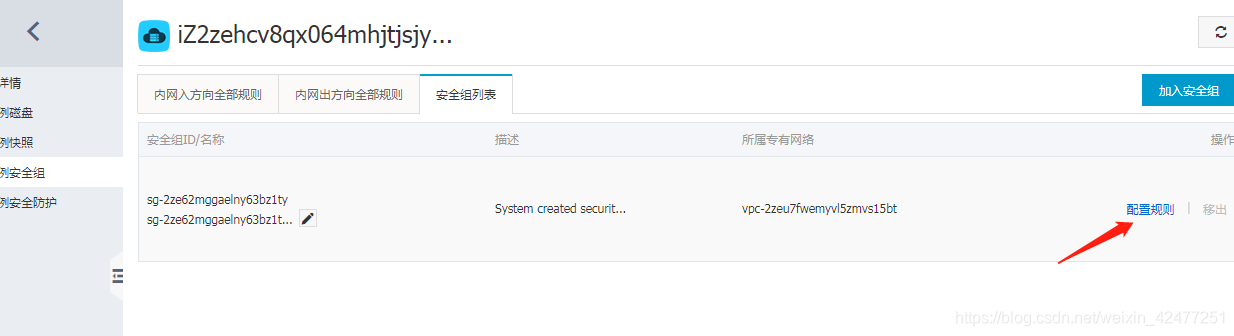
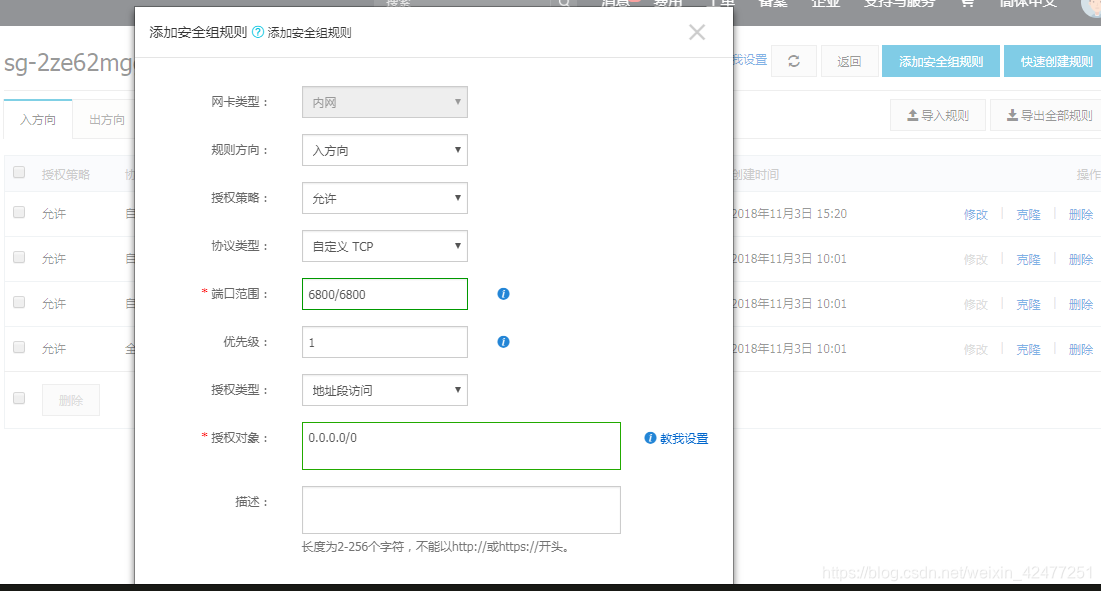
9.启动之后就可以打开本地运行的scrapyd,浏览器中访问6800端口可以查看scrapyd的监控界面!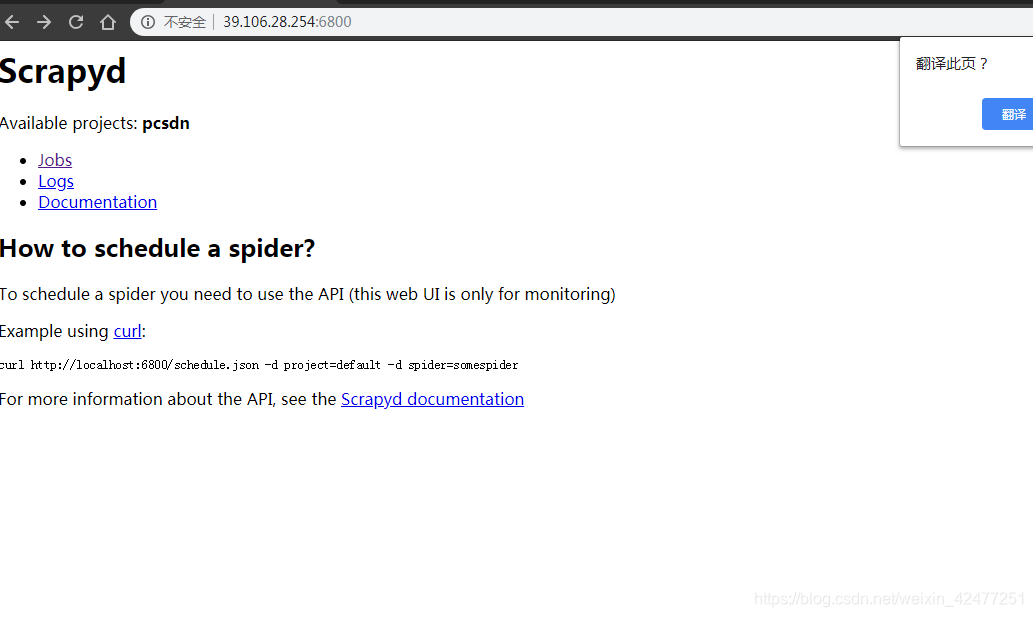
10.点击job可以查看任务监控界面
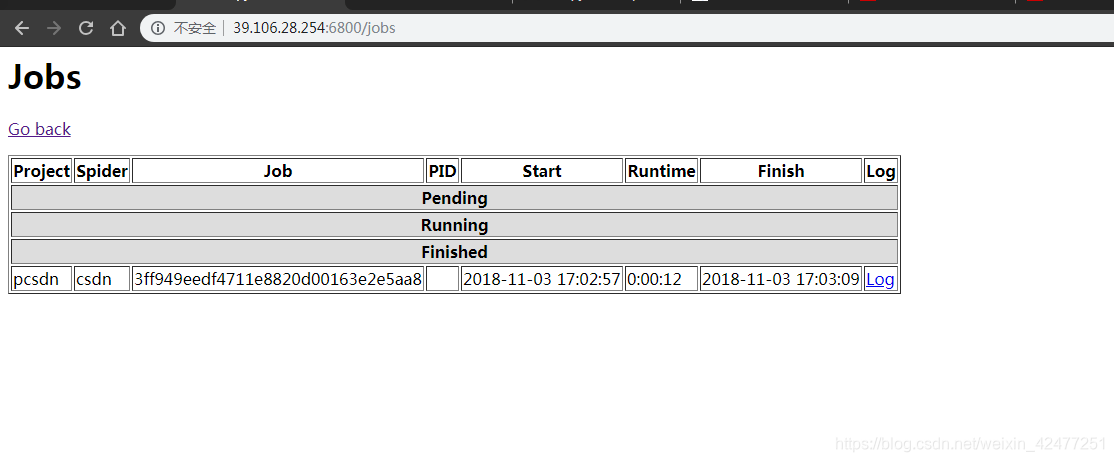
11.本地安装 Scrapyd客户端
pip install scrapyd-client
12.编辑需要部署的项目的scrapy.cfg文件(需要将哪一个爬虫部署到scrapyd中,就配置该项目的该文件)
[deploy:部署名(部署名可以自行定义)]
url = http://39.106.28.254:6800/
project = 项目名(创建爬虫项目时使用的名称)
13.部署项目到服务器上的scrpyd
scrapyd-deploy -p 项目名称
部署成功可以看到项目名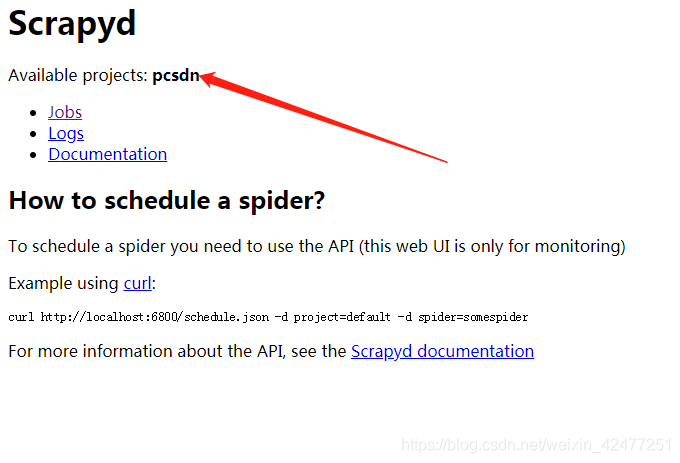
14.启动项目
curl http://ip:端口/schedule.json -d project=项目名称 -d spider=爬虫名称
curl http://39.106.28.254:6800/schedule.json -d project=pcsdn -d spider=csdn
15.关闭项目
curl http://ip:端口/cancel.json -d project=项目名称 -d job=jobid
curl http:/39.106.28.254:6800/cancel.json -d project=pcsdn -d job=3ff949eedf4711e8820d00163e2e5aa8

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)