
Hadoop 2.0生态圈技术简介
本博文主要对开源分布式文件存储及处理框架Hadoop,以及其生态圈中的Zookeeper,Habase,Hive项目进行介绍。
Apache Hadoop项目是Java语言实现的优秀开源分布式文件存储和计算框架。Hadoop2.0中引入HA(High Available,高可用)和Federation机制,解决了Hadoop1.0中的单点问题,提高了NameNode的可用性和水平扩展能力。而Hadoop1.0中饱受诟病的MapReduce JobTracker/TaskTracker机制完全重构,计算资源管理由全新的YARN平台接管。
HDFS
HDFS(Hadoop Distributed File System)是Hadoop之父Doug Cutting参考Google GFS(Google File System)的概念模型设计实现,HDFS采用流式读取文件系统数据的方式,管理和维护其上创建的目录文件的读写等操作。
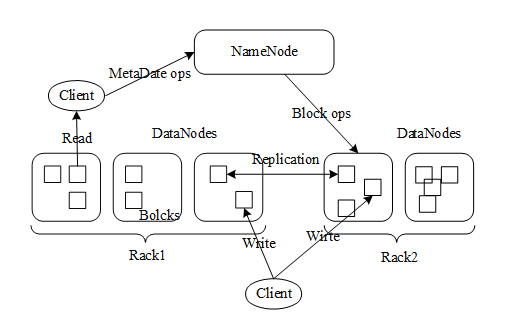
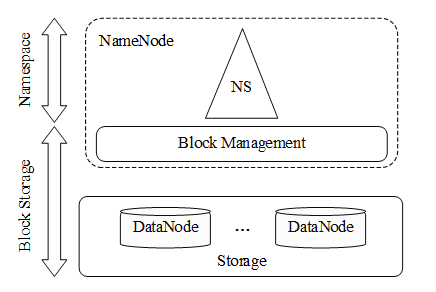
如图所示,HDFS采用Master/Slave架构,集群由NameNode节点和一组DataNode节点组成。NameNode节点担任管理和维护HDFS集群上整个文件系统命名空间的Master,主要负责数据块Block映射到文件的BlockMap位置信息,以及HDFS上目录和文件的元数据信息等。NameNode节点还负责管理和维护与DataNode节点间的关系以及客户端在HDFS上的数据读写过程。
HDFS上的所有文件实际上以普通文件的形式存储在DataNode节点的本地文件系统中。DataNode节点按照NameNode节点的指令为来自Client的读/写请求提供服务,执行其上数据块的创建、删除和复制操作,并将数据块的位置信息定时上报给NameNode。Hadoop2.0以后HDFS上数据块默认为128MB,这个值可通过dfs.block.size参数自行配置。
Rack是机柜,当用户开启Hadoop集群的机架感知能力后,HDFS多数据备份策略将第一份数据存放在和Client处于相同机架,否则由NameNode选择一个合适的DataNode节点上。多数据备份策略之后选择与第一个DataNode节点处于不同机架上的DataNode节点来存放第二个副本。选择与第二个DataNode节点处在同一个机架上的不同DataNode节点来存放第三个副本。Hadoop集群机架感知能力能够有效较少跨机架机器间的数据流量,提高数据的读写速度。
HDFS某一时刻的最新状态存储在一个称为FsImage的映像文件中,这个文件存放在NameNode所在节点的文件系统上,任何对HDFS文件系统Namespace产生修改的操作,NameNode都会使用一种称为EditLog的事务日志记录下来。NameNode节点每次启动时,会执行checkpoint过程,先从硬盘中读取FsImage状态文件和EditLog执行日志,之后将所有EditLog日志中的事务应用到内存中的FsImage上,得到整个HDFS集群的完整元数据信息,并将新生成的FsImage文件从内存中保存到本地磁盘上,然后删除旧的EditLog。
HDFS被设计成为能够部署在普通商用硬件集群上跨机器可靠存储的分布式文件系统,适合进行大规模数据集的离线批量处理任务。用户能够通过配置复制因子来设置保存在HDFS上的文件副本数,保证数据的完整性和可用性,与大多数文件系统类似,采用树形文件组织方式,通过删除、创建、移动等命令操作目录或文件,文件写入过程如图所示。
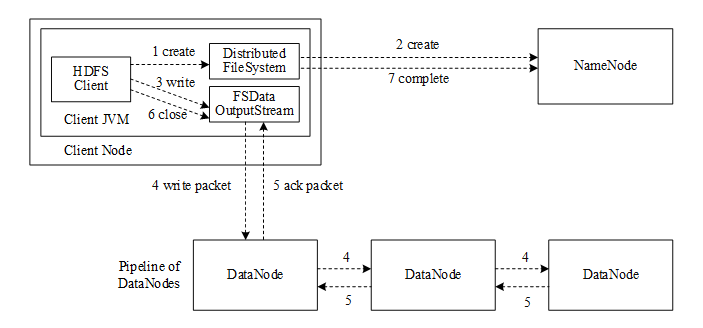
HDFS Client调用DistributedFileSystem对象的create方法,create方法返回一个封装了DFSOutputStream输出流的FSDataOutputStream对象,HDFS Client通过此FSDataOutputStream对象向DataNode节点上写数据。这个过程打开了一个DFSOutputStream流,通过NameNode代理类发起创建新文件的RPC调用。NameNode节点对请求参数进行校验,判断HDFS Client是否具有文件创建权限,以及父节点路径是否存在等,如果校验成功,NameNode节点会创建此新文件,否则向客户端抛出一个RemoteException异常。HDFS Client调用FSDataOutputStream的write方法将数据写入DFSOutputStream流中,数据被组装成一个个packet放入dataQueue中,Streamer线程将packet从dataQueue中取出,放到ackQueue队列中并将其发送给Pipeline中的第一个DataNode节点上,第一个DataNode节点又将packet发送至第二个DataNode节点,如此直到Pipeline中所有的DataNode节点都已收到此packet,之后沿着Pipeline的反方向链依次返回ack。如果向DataNode节点写入packet的过程失败,则DataStreamer线程将packet从ackQueue中移除放到dataQueue中,将失效DataNode节点从Pipeline中移除,并与NameNode节点进行通信申请分配新的DataNode节点。一个packet发送成功后,ResponseProcessor线程则将此packet从ackQueue中移除,直到所有packet写入完成后,HDFS Client调用DFSOutputStream的close方法关闭输出流,调用DistributedFileSystem对象的complete方法通知NameNode节点写文件完成。
MapReduce
MapReduce是Hadoop的核心组件之一,通过MapReduce很容易在Hadoop平台上进行离线分布式批量计算。用户只需实现MapReduce框架的Mapper和Reducer接口,就能够开发分布式并行计算程序,MapReduce框架会将计算作业划分为多个能够在集群中任意节点上执行的task,并负责这些task在集群计算节点间的调度和分配。MapReduce的运行机制如图所示。
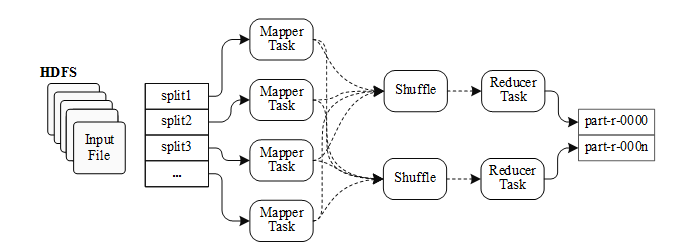
用户指定的并行处理作业提交之后,在调用map方法之前,MapReduce会根据一定标准(HDFS的Block块大小)将输入文件进行分片(Input Split),每个文件分片对应一个Mapper处理线程。在Hadoop2.0中,默认情况下大小为129MB的文件则将被分为两个输入片,因此用户需要根据HDFS上文件存储情况合理设置dfs.block.size参数。
上图中的Shuffle过程处理Map阶段的输出,并将其作为Reduce阶段的输入。每个Map任务把数据输出到内存中开启的一个环状缓冲区中,当缓冲区的使用达到指定阈值时会将缓冲区中的数据刷到磁盘上的临时文件中,这个Spill过程会产生很多临时小文件spill_file。Map阶段结束之前可能会对中间过程产生的多个spill_file进行合并,产生一个最终文件。Reduce进程会通过HTTP网络传输方式获取Map阶段产生的输出文件,复制过来的数据同样会先存入事先开辟的缓冲区中,当数据量到达一定阈值时将数据写入到本地文件系统中,之后MapReduce会执行Reduce端的Merge和Sort过程。Reduce阶段对排序后的键值对执行用户指定的reduce处理过程,将结果写入到各part文件中。
YARN
Hadoop1.0中的MapReduce主要有两种进程,JobTracker和TaskTracker。JobTracker管理集群上所有的资源并根据资源使用情况进行计算作业的任务调度,将Map和Reduce作业分配到一个或多个TaskTracker上的可用插槽(Slot)中,管理所有作业的执行过程,并对失败的作业重新执行等。TaskTracker运行在Hadoop集群的其他节点上,监控其所在节点上资源的分配以及Map和Reduce作业的执行情况,并通过heartbeat心跳与JobTracker通信。JobTracker是MapReduce集群的中心节点,存在单点制约问题。而TaskTracker进程将计算资源强制划分为Map slots和Reduce slots,如果只有Map作业或Reduce作业时,会造成集群中计算资源的浪费。
YARN(Yet Another Resource Negotiator)是hadoop-0.23引入的资源管理和调度的新架构,又名MRv2(MapReduce NextGen)。YARN将MapReduce中的JobTracker/TaskTracker机制完全重构,既可以运行Storm、Spark、MR这样的分布式计算作业,也能够长期运行一些服务。YARN平台全权负责集群中CPU和内存等资源的管理和控制,降低集群管理成本。YARN的架构如图所示。
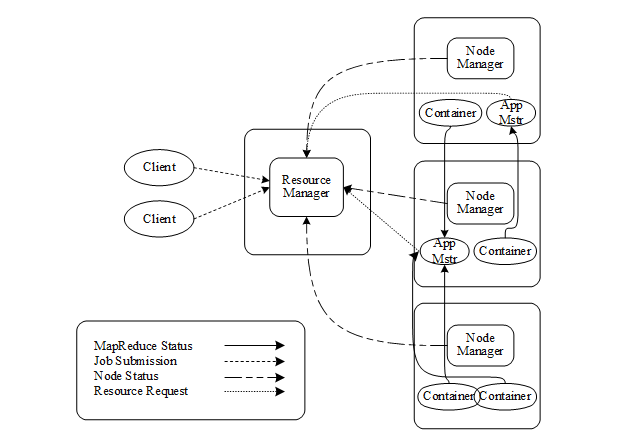
YARN使用ResourceManager和ApplicationMaster这两个组件来分别提供资源分配管理和任务调度监控功能。ResourceManager是YARN的中心节点,负责管理和调度所有NodeManager上向应用程序分配的计算资源,如CPU和内存。每一个计算作业的ApplicationMaster是NodeManager上运行的一个进程,负责为计算作业从ResourceManager申请计算资源,并根据ResourceManager的调度结果,将作业分配到不同的NodeManager上去执行Task。同时与每个NodeManager节点保持心跳,跟踪这些资源的使用以及执行并监控各个Task的执行。
NodeManager节点是ResourceManager的从节点,内部管理维护着许多动态创建的Container,而不是固定数目的Map slots和Reduce slots。NodeManager监控节点上的CPU和内存使用情况定时上报给ResourceManager。
Container是YARN平台上用作资源隔离的框架,对单个节点上的内存和CPU等资源进行封装,兼容各种计算框架。资源分配由ApplicationMaster动态申请,不必事先指定计算任务所需的Container数和每个Container所要分得的资源,资源利用能力得到有效地提升。
Zookeeper
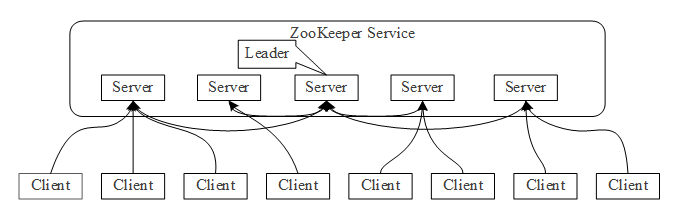
ZooKeeper是Apache Hadoop的一个开源子项目,最初是由Yahoo!参考Google Chubby开发实现。ZooKeeper为分布式应用程序提供协调服务,它维护了一个类似目录树的层次关系数据结构,并对数据结构中的节点进行有效管理,基于此设计出多种分布式数据管理模型,基于此,分布式应用程序可以实现分布式锁服务,状态同步服务,配置项统一维护管理服务,统一命名服务和集群管理等服务功能。
ZooKeeper集群中的角色主要有Leader(领导者),Follower和Client(客户端)。Leader由Follower投票选举产生,负责管理集群;Follower负责接受客户端请求并向客户端返回结果,并在选主过程中参与投票;Client是请求的发起方。
HBase
HBase(Hadoop Database)是一个具有高可靠、高伸缩性和高性能的构建在HDFS之上的分布式列存储数据库,基于Google Bigtable建模的开源实现方案。与关系型数据库不同,HBase适合非结构化数据的大规模存储,支持多种方式的API来存取数据,如Java API编程,亦或是通过Thrift,Avro的API来访问。
在HBase中,数据是基于列而不是基于行的存储特性,在列导向的存储机制下HBase对于Null值得存储是不占用任何空间的,数据更利于压缩。HBase的数据模型如图所示。
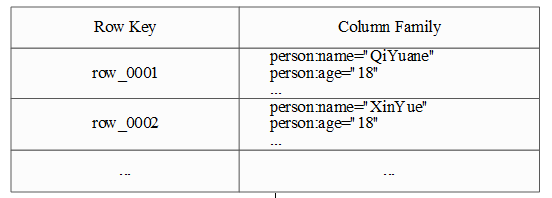
在HBase中,数据类型只有字符串一种。HBase中的Row Key(行键),与传统关系型数据库中的主键类似,唯一标识HBase中存储的每一行数据,其值可以是任意类型的字符串,最大长度为64KB,按字典顺序存储在字节数组中。Column Family(列族)是一些列的集合,存储在HDFS上的一个单独文件中,值为Null的列并不占用存储空间。在HBase中,Cell(存储单元)由行键,列族和Timestamp(时间戳)组成,每个存储单元都保存着同一种数据的多个版本,通过Timestamp(时间戳)倒序存储,即最新的数据排在最前面。
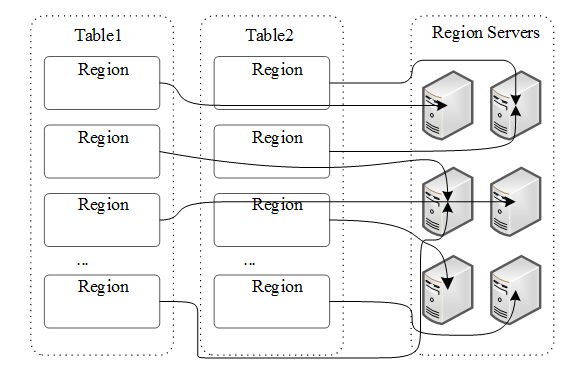
HBase的物理存储模型如下图,Table中每一行都按Row Key的字典顺序排列,并在行的方向上分割为多个Region,其中Region是HBase中负载均衡和分布式存储的最小单元,但不是数据存储的最小单元。不同Region被分布到不同RegionServer上,RegionServer负责用户的I/O请求,向HDFS上写数据,维护Region,以及在某个RegionServer节点故障停机后,负责失效RegionServer上的Region迁移。
Hive
Hive最初由Facebook开发,后作为Apache基金会旗下的一个顶级开源项目,是基于Hadoop的一个数据仓库工具,它使用Hadoop存储和分析处理数据,可以对数据进行ETL(Extract Transform Load,提取,转换,加载)操作,能够很好的解决离线处理中需要对批量处理结果的查询分析。Hive将结构化的数据文件映射为一张数据库表,提供了简单的类似SQL的编程模型HQL。HQL能够转换成MapReduce任务执行,消除了使用MapReduce做批处理操作时的大量通用代码,使用户无论是DBA还是Java工程师只需花费少量精力就可以完成大量工作。Hive也允许熟悉MapReduce的Java开发者自定义Mapper和Reducer来处理内置Mapper和Reducer无法完成的复杂的分析工作,架构如图。
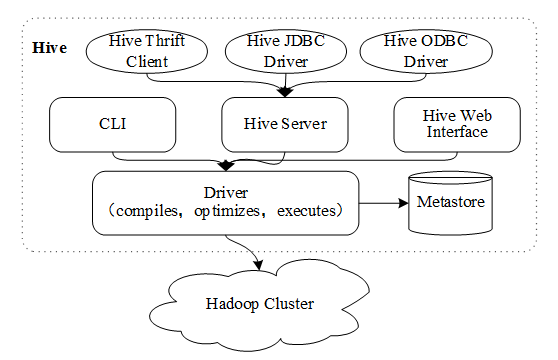
Hive提供了CLI(Command Line Interface,命令行接口),Web页面的服务访问方式,也可以通过Thrift,JDBC/ODBC接口进行编程访问。
Driver组件包括Complier、Optimizer和Executor,所有客户端的命令和查询都会进入到Driver驱动,它将输入语句进行解析、编译,对计算的需求进行优化,生成执行计划,启动底层的MapReduce来执行任务。
Hive将元数据和表模式存放在Metastore中,使用Metastore时有三种存储方式:内嵌Derby方式,local方式和remote方式。内嵌Derby方式是Hive默认的元数据存储方式,同一时间只能有一个进程连接使用数据库,local方式和remote方式则是使用本地或者远程搭建的关系型数据库(通常使用MySQL实例)存储元数据。

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)