【深度学习】论文导读:GoogLeNet模型,Inception结构网络简化(Going deeper with convolutions)
论文下载Going deeper with convolutionsgoogle在ILSVRC14比赛中获得冠军的一个模型。GoogLeNet, 一个22层的深度网络。GoogLeNet模型的参数量只是两年前该项赛事的冠军Krizhevsky参数量的1/12,大大降低了网络的复杂度,甚至还达到了比Krizhevsky更高的精度。此篇论文讨论的就是如何有效的控制computa
论文下载
Going deeper with convolutions
google在ILSVRC14比赛中获得冠军的一个模型。GoogLeNet, 一个22层的深度网络。
GoogLeNet模型的参数量只是两年前该项赛事的冠军Krizhevsky参数量的1/12,大大降低了网络的复杂度,甚至还达到了比Krizhevsky更高的精度。
此篇论文讨论的就是如何有效的控制computation cost,降低模型参数的量。
一、多尺度问题
对于多尺度问题,会涉及到很多数学上的东西,然而目前并不需要这些,我们只需要了解基本的概念http://blog.csdn.net/xiaowei_cqu/article/details/8067881如果有兴趣,这篇文章介绍了尺度空间理论
之所以引入尺度这个概念,其实是为了更贴近人类的视觉系统。在某些特征检测提取算法中(如sift等),用到的某些算子会对图像的某些信息作出反应,例如图像当中像素点快速变化的一些区域(一般就是图像当中的一些边缘信息),然后记录下来,形成该图的一组特征。但是某些时候我们的图往往是不能确定大小的(这个大小,也可以理解为相同大小时候,图像的模糊程度),需要做的就是在图像不同大小时,算法都能有效的提出相同的关键点。
由此,我们需要对一张图,生成一组由清晰逐渐变模糊的一组图像,这就是图像的多尺度。总的来说,多尺度模拟了不同远近的物体在视网膜上的形成。而尺度不变性保证不同远近物体可以对视觉神经有相同的刺激。
受到神经科学对灵长类动物的视觉建模的启发,Serre使用了一系列不同大小的Gabor滤波器用来解决图像当中的多尺度问题,这里使用一组
Gabor滤波器就是为了保证对不同尺度的图像,都能检测出相同特征。论文的模型采用了这一观点,使用不同大小的卷积核来提升不同尺度
图像的检测能力。




GoogLeNet借鉴了NIN的特性,在原先的卷积过程中附加了1*1的卷积核加上ReLU激活,这不仅仅提升了网络的深度,提高了representation
power,而且文中还通过1*1的卷积来进行降维,减少了更新参数量。
二、NIN模型
Network-in-Network也是一个热度比较高的模型,主要思想是,普通卷积层只做一次卷积得到一组feature map,这样将不同feature分开对应多个feature map的方法并不是很精确,因为我们按照特征分类的时候只经历了一层,这样会导致对于该特征的表达并不是很完备,所以Network-in-Network模型用全连接的多层感知机去代替传统的卷积过程,以获取特征更加全面的表达,同时,因为前面已经做了提升特征表达的过程,传统CNN最后的全连接层也被替换为一个全局平均池化层,因为作者认为此时的map已经具备分类足够的可信度了,它可以直接通过softmax来计算loss了。NIN的结构
其实Network-in-Network的思想也是对传统CNN做了简化,参数量大大的减少了。
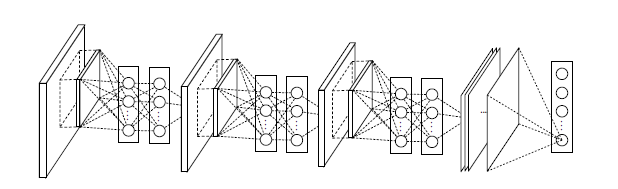
三、Hebbian principle
目前图像领域的深度学习,是使用更深的网络提升representation power,从而提高准确率,但是这会导致网络需要更新的参数爆炸式增长,导致两个严重的问题:1、网络更容易过拟合,当数据集不全的时候,过拟合更容易发生,于是我们需要为网络feed大量的数据,但是制作样本集本身就是一件复杂的事情。
2、大量需要更新的参数就会导致需要大量的计算资源,而当下即使硬件快速发展,这样庞大的计算也是很昂贵的
解决以上问题的根本方法就是把全连接的网络变为稀疏连接(卷积层其实就是一个稀疏连接),当某个数据集的分布可以用一个稀疏网络表达的时候就可以通过分析某些激活值的相关性,将相关度高的神经元聚合,来获得一个稀疏的表示。
这种方法也呼应了Hebbian principle,一个很通俗的现象,先摇铃铛,之后给一只狗喂食,久而久之,狗听到铃铛就会口水连连。这也就是狗的“听到”铃铛的神经元与“控制”流口水的神经元之间的链接被加强了,而Hebbian principle的精确表达就是如果两个神经元常常同时产生动作电位,或者说同时激动(fire),这两个神经元之间的连接就会变强,反之则变弱(neurons that fire together, wire together)
四、Inception结构
通过上述的分析,作者提出了Inception结构,这是一种高效表达特征的稀疏性结构。基于底层的相关性高的单元,通常会聚集在图像的局部区域(因为通常CNN底层卷积提取的都是局部特征),这就相当于在单个局部区域上,我们去学习它的特征,然后在高层用1*1卷积代替这个区域,当然某些相关性可能是隔得比较远的,通过使用大的卷积核学习即可。最后就是这样的一个结构:
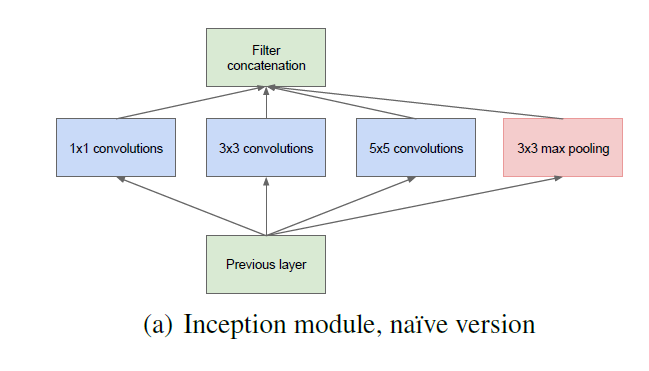
不过3*3,5*5卷积可能会导致参数量过大的问题,所以在之前通过降维可以控制参数量。
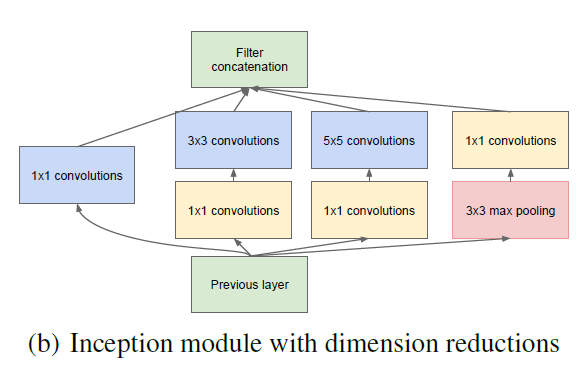
而GoogLeNet无非就是stack这种Inception结构

为什么1*1卷积可以降维?在单张单通道的图上做1*1卷积当然不能降维,降维是对于多通道而言的,具体解释可以看这里 http://www.caffecn.cn/?/question/136
以下就是整个网络的参数表:


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)