
新人笔记---智能体记忆处理方式(记忆摘要,长期记忆提取,全局记忆设定......)
AI 长期记忆(Long‑Term Memory, LTM),就是让大模型跨会话、跨时间记住关键信息(偏好、事实、历史交互),不被上下文窗口限制,从而像人一样有 “连贯的人设” 与 “持续的经验”。Jaccard相似度 = 两个集合的交集大小 ÷ 并集大小原始聊天有大量:客套话、解释、推理、举例、冗余废话。直接全存占 Token、占存储空间后续检索时混入无关内容,干扰 AI 判断摘要 = 只留核心
背景讲解:这个是博主自己项目中搭建的一套记忆机制,包括会话摘要,全局记忆,长期记忆提取,记忆观测表等等,博主也是第一次接触记忆管理方面,想尽可能给自己做的全面点,花费了挺大心血的,不断优化,找bug后,修复bug后搭建的一套比较能用的记忆机制。但是距离成熟可用还差挺多的,内部很多细节还需要后续不断优化,只能适用于像博主这种的小项目,而且整篇偏向于笔记型的,博主本意也是梳理一下整个流程机制,让自己加强对自己项目的理解,同时为了分享一下思路,所以全程采取流程图和图片的方式介绍功能,而不粘贴源码,因为涉及的类,方法太多了,直接展示不现实。篇幅过长,如果觉的没有用的可以直接跳过,不介意继续读取下去,博主都觉得写的内容有点多了,有点过于啰嗦。觉的有帮助的还请点个赞
(*>ω<*)
一.什么是长期记忆
AI 长期记忆(Long‑Term Memory, LTM) ,就是让大模型跨会话、跨时间记住关键信息(偏好、事实、历史交互),不被上下文窗口限制,从而像人一样有 “连贯的人设” 与 “持续的经验”。
一、为什么需要长期记忆
传统大模型只有短期记忆(上下文窗口) :
- 一次会话内有效,新会话 = 失忆
- 窗口有限(如 4k/8k/32k tokens),长对话会 “记了后面忘前面”
- 无法形成个性化、连续的服务体验
长期记忆就是为了解决 “健忘症”:突破窗口限制、跨会话持久化、保留用户偏好与历史、降低幻觉。
二、长期记忆存什么(三类)
- 事实记忆:你的偏好、生日、地址、常用工具、固定规则
- 情节记忆:历史对话摘要、重要事件、已完成的任务
- 语义记忆:概念关系、学到的知识、推理用的规则
简单说:如果你明确向AI指出你的偏好“我喜欢八千代,我希望你以后的回复可以偏向温柔语气一点”,如果我们采用动态窗口的话,他只会记住最近几轮的对话,对话一多了他就很难记住我们的偏好,从而回复逐渐偏离我们的偏好,更别说跨会话级别的对话,一般来说一个会话中的对话内容,和其他会话是分开的。此时我们就需要长期记忆,他就是自动识别并从用户对话中抽取出来我们用户的一些稳定事实,比如用户长期偏好,长期目标等等,记忆下来,后续的对话中不论是跨会话级别,还是多轮对话,他都会根据我们用户的问题检索需要的长期记忆,并发送给LLM
二:我们长期记忆的设计思路
我们的长期记忆不是所有内容一股脑塞在一起的,而是分字段,分需求存放,并存入向量数据库,长期记忆又分为
用户事实记忆(从用户的问题中抽取),以及AI决策记忆(从AI回复中抽取)
1. 用户事实记忆(User Facts)
从用户消息中抽取的 稳定个人信息 :
| 类型 | 示例 | 存储格式 |
|---|---|---|
| user_profile | 用户是 Java 开发工程师 | [user_profile] 用户是 Java 开发工程师 |
| user_preference | 用户偏好中文回答 | [user_preference] 用户偏好中文回答 |
| user_goal | 用户正在准备跳槽 | [user_goal] 用户计划 3 个月内跳槽 |
| user_constraint | 用户只有晚上有时间 | [user_constraint] 用户只有晚上 8 点后有时间 |
| user_fact | 用户住在上海 | [user_fact] 用户住在上海 |
2. AI 决策记忆(AI Decisions)
从 AI 回复中抽取的 已确认方案或约定
| 类型 | 示例 | 存储格式 |
|---|---|---|
| assistant_decision | 确认采用微服务架构 | [assistant_decision] 确认采用微服务架构 |
| assistant_plan | 计划分 3 阶段实施 | [assistant_plan] 计划分 3 阶段实施 |
| assistant_constraint | 约定预算不超过 10 万 | [assistant_constraint] 约定预算不超过 10 万 |
| assistant_action | 下次提供详细方案 | [assistant_action] 下次提供详细方案 |
3.我们统一格式化了存储形式
// 存储格式:[type] content
[user_preference] 用户偏好中文回答
[assistant_decision] 确认采用微服务架构
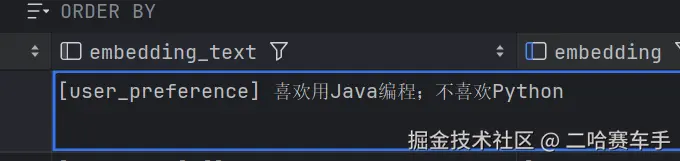
具体拆分方法
我是 Java 开发工程师,最近准备 3 个月内跳槽,晚上 8 点后才有时间学习。
不会整段原文入库,而是拆成:
[user_profile] 用户是 Java 开发工程师
[user_goal] 用户计划 3 个月内跳槽
[user_constraint] 用户只有晚上 8 点后有时间
好处是:记忆从“聊天文本”变成了“可管理的数据资产”。后续可以按类型筛选、聚合、评分、更新、覆盖,而不是在一堆自然语言里硬找。
4.启发式过滤
当我们用户提出问题和AI返回结果时,对于一些完全没有价值的对话,我们是直接跳过的,不进行长期记忆提取,核心是减少记忆干扰,因为长期记忆本来就很难精确抽取
哈哈
好的
继续
这是什么意思?
如果用户提出这些问题,那么他们本身就没有什么价值,没有长期记忆提取的必要,直接跳过长期记忆提取
我喜欢java编程,我希望你以后对话推送java知识
那么他就会提取
user_preferenc:喜欢java编程,user_goal:希望以后推送java知识
private boolean passesUserHeuristic(String content) {
String normalized = content.toLowerCase(Locale.ROOT);
return normalized.contains("我")
|| normalized.contains("喜欢")
|| normalized.contains("希望")
|| normalized.contains("想要")
|| normalized.contains("计划")
|| normalized.contains("以后")
|| normalized.contains("不要")
|| normalized.contains("需要")
|| normalized.contains("偏好")
|| normalized.contains("目标")
|| normalized.contains("约束")
|| normalized.length() > 20;
}
对应的代码,仅供参考
5.AI结构化提取
仅靠启发式过滤,仅能过滤到一些比较“粗”的记忆,就是只能过滤掉哪些明显低质量的对话,对于用户和AI进行的的大部分常规对话,我们很难很难约束规则,直接硬编码规则来规定长期记忆抽取,所以博主对于这一点一开始没有思路,但是后来转念一想,为什么不用AI来辅助抽取,正好启发式过滤提前过滤完全没用的对话,减少AI频繁调用的负担,AI进行精细化提取
场景
用户和 AI 聊天,原始 AI 回复一大段:
微服务架构整体扩展性更好,单体架构后期不好扩容,综合你的业务量和后续迭代需求,我这边建议你直接采用微服务架构。另外项目整体预算尽量控制在 10 万元以内会更合理,我简单给你分析下两种架构,单体优点是开发简单、上线快,微服务优点是能独立的扩展、拆分 。
一、如果不用 AI 抽取(正则 / 硬匹配)
会把所有文字都当记忆存进去:
- 冗余废话:单体优点是开发简单、上线快
- 推理过程:微服务整体扩展性更好…
- 解释分析:给你分析下两种架构
- 真正要记的只有 2 句话被淹没在垃圾信息里
记忆库塞满无用内容,下次 AI 回忆时全是废话,干扰回答。
二、用这套「AI 结构化抽取 Prompt」
AI 自动读懂语义,过滤掉解释、对比、推理,只抽固定结论,输出标准 JSON:
[
{"type":"assistant_decision","confidence":0.95,"content":"确认采用微服务架构"},
{"type":"assistant_constraint","confidence":0.95,"content":"项目预算不超过10万元"}
]
提取规则对应上你 Prompt 要求:
保留:已确认方案、技术决策、稳定约束❌ 丢掉:推理过程、架构对比、解释分析、铺垫废话
三、为什么必须用 AI,不能用正则?
换一句说法,AI 照样能抽对:AI 换种说法回复:
综合评估下来更推荐用微服务,不建议用单体,经费方面建议把控在 10 万以内比较稳妥。
- 正则:文字变了就匹配不到,抽不出来
- AI 能懂语义:不管怎么换话术,都能精准抽出「用微服务、预算 10 万」两条长期记忆。
四:对应代码示例(仅展现用户事实记忆抽取)
private List<MemoryExtractionResult> extractUserFactsByAI(String content) {
try {
// 使用注入的 ChatModel 进行 AI 抽取
String prompt = """
你是一个长期记忆抽取器。请从用户输入中提取适合长期保存的稳定事实。
只保留以下类型的信息:用户画像、偏好、长期目标、明确约束、稳定习惯、明确计划。
不要保留临时问题、闲聊、解释过程、一次性请求。
如果没有可保存的信息,返回空数组 []。
如果有信息,请严格返回 JSON 数组,每个元素格式如下:
[{"type":"user_preference","confidence":0.92,"content":"用户偏好中文回答"}]
type 只能是:user_profile, user_preference, user_goal, user_constraint, user_fact。
confidence 取值 0 到 1。
content 只写精炼事实,不要解释。
用户输入:
%s
""".formatted(content);
String result = chatModel.call(prompt);
return parseExtractionResults(result, "user_fact");
} catch (Exception e) {
System.out.println("user fact extraction failed error=" + e.getMessage());
return Collections.emptyList();
}
}
我们这里还设置了置信度评分
confidence,由AI来对记忆抽取的可靠性打分
6.长期记忆合并与替换
这一点是博主测试长期记忆发现的问题,就是我们上面虽然区分了不同长期记忆字段,比如
user_preference,user_profile,但是这会出现一个问题,如果用户一开始说“我是一名java程序员”,那么user_profile:用户是一名java程序员,如果后续用户又说“我是python程序员”,那么就需要同步修改user_profile:用户是一名python程序员,这种是事实替换,他是只能存储一个事实,如果有新事实,就会替代覆盖,再举个例子:已有user_preference:用户喜欢java,对于爱好这类字段,一个用户可以有多个爱好,那么就可以存储多个字段,但是遇到相反的爱好又要替换,比如用户说“我不喜欢java了,我现在喜欢python”,那么user_preference:用户不喜欢java,用户喜欢python,这种是追加覆盖,可以存储多个事实,遇到相反的事实就更新。对于这一点,我们也没有很好的思路,AI给出的建议是把字段分为单槽字段和双槽字段
单槽类型(Single Slot)
| 类型 | 含义 | 示例 | 合并策略 |
|---|---|---|---|
| user_profile | 用户画像 | 后端开发工程师 | 覆盖 |
| user_goal | 用户目标 | 学习 Spring Boot | 覆盖 |
| user_constraint | 用户约束 | 只回答中文问题 | 覆盖 |
| assistant_decision | AI 决策 | 采用 MySQL 数据库 | 覆盖 |
| assistant_constraint | AI 约束 | 使用中文回复 | 覆盖 |
双槽类型(Append/Multi Slot)
| 类型 | 含义 | 示例 | 合并策略 |
|---|---|---|---|
| user_preference | 用户偏好 | 喜欢 Java;喜欢 Python | 追加 + 冲突消解 |
| user_fact | 用户事实 | 后端开发;计划学习 Spring Boot | 追加 + 冲突消解 |
为什么这样分类?
单槽类型的特点
“一个萝卜一个坑” —— 同一类型只能有一个值,新值直接替换旧值。
用户第一次说:"我是后端开发" → 保存 user_profile="我是后端开发"
用户后来说:"我是前端开发" → 覆盖 user_profile="我是前端开发"
最终结果:user_profile="我是前端开发"(旧值被完全替换)
设计理由 :
- user_profile :用户的职业/身份通常是唯一的,不会同时是"后端"和"前端"
- user_goal :当前阶段的主要目标通常是单一的
- user_constraint :约束条件通常是覆盖式的,新约束取代旧约束
- assistant_decision/constraint :AI的决策和约束也是最新的有效
双槽类型的特点
“列表式存储” —— 同一类型可以存储多个值,新值追加到列表。
用户第一次说:"我喜欢Java" → 保存 user_preference="喜欢Java"
用户后来说:"我喜欢Python" → 追加 user_preference="喜欢Java;喜欢Python"
用户再说:"我不喜欢Java了" → 冲突消解 user_preference="不喜欢Java;喜欢Python"
设计理由 :
- user_preference :用户可以有多个偏好(喜欢Java、喜欢Python、喜欢中文回答…)
- user_fact :用户可以有多个事实(后端开发、住在北京、有5年经验…)
流程图
┌─────────────────────────────────────────────────────────────┐
│ 记忆合并决策流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 新记忆:"我喜欢Python" │
│ 旧记忆:"喜欢Java" │
│ ↓ │
│ ┌─────────────────────────────┐ │
│ │ 检查:新旧内容是否相似? │ │
│ │ (相等/包含关系) │ │
│ └─────────────────────────────┘ │
│ ↓ 是 ↓ 否 │
│ 保留更长版本 判断记忆类型 │
│ ↓ │
│ ┌──────────────┐ │
│ │ 是单槽类型? │ │
│ └──────────────┘ │
│ ↓ 是 ↓ 否 │
│ ┌─────────┐ ┌──────────────┐ │
│ │ 覆盖 │ │ 是双槽类型? │ │
│ │ 返回新内容│ └──────────────┘ │
│ └─────────┘ ↓ 是 │
│ ┌────────────┐ │
│ │ 追加+冲突消解 │ │
│ │ AI判别合并 │ │
│ └────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
具体的长期记忆的合并逻辑与替换
对于单槽记忆,我们是直接找到对应的向量表中的数据,同步修改即可,这里不再讲解。但是对于双槽的记忆,我们需要先判定是否需要替换冲突事实,然后确认是否要追加,我们只讲解双槽记忆
┌─────────────────────────────────────────────────────────────────┐
│ 双槽记忆合并流程:三层过滤机制 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入:旧记忆="喜欢Java;喜欢Python" 新记忆="不喜欢Java;喜欢Go" │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ ① 原子化拆分 │ │
│ │ 旧:["喜欢Java", "喜欢Python"] 新:["不喜欢Java", "喜欢Go"] │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ ② 逐条处理新记忆 │ │
│ │ 对每条新记忆,执行"找→筛→判→决"四步: │ │
│ │ │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │
│ │ │ 找:向量 │ → │ 筛:规则 │ → │ 判:AI │ → │ 决:执行 │ │ │
│ │ │ 召回候选 │ │ 快速过滤 │ │ 语义理解 │ │ 替换/追加 │ │ │
│ │ │ (粗筛) │ │ (精筛) │ │ (智能) │ │ (落地) │ │ │
│ │ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │ │
│ │ │ │
│ │ 示例:"不喜欢Java"的处理过程 │ │
│ │ ├─ 找:向量召回"喜欢Java"(语义相关) │ │
│ │ ├─ 筛:Jaccard=0.86>0.5(确认相关) │ │
│ │ ├─ 判:AI识别为"同主题相反态度" → 决策:替换 │ │
│ │ └─ 决:用"不喜欢Java"替换"喜欢Java" │ │
│ │ │ │
│ │ 示例:"喜欢Go"的处理过程 │ │
│ │ └─ 找:向量召回为空(无相关旧记忆) │ │
│ │ → 直接追加,不触发后续步骤 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ 输出:"不喜欢Java;喜欢Python;喜欢Go" │
│ │
│ 💡 核心设计:80%的简单情况用向量+规则快速处理,只有20%的复杂 │
│ 语义冲突才调用AI,兼顾效率与准确性。 │
│ │
└─────────────────────────────────────────────────────────────────┘
这里我们解释一下
(1)找阶段为什么用向量?
- “不喜欢Java” 和 “喜欢Java” 语义相关(都是关于Java的偏好)
- 在1024维向量空间中,它们的距离很近
- 而"不喜欢Java"和"住在北京"距离很远
我们
用户说“喜欢java”,我们先去通过向量召回所有与“喜欢java”相近的事实,比如“不喜欢java”,"比较喜欢java",召回的这些事实,我们需要进一步判定是否选择需要覆盖事实,比如“不喜欢java”->“喜欢java”.如果向量召回没有结果,就说明没有与用户“喜欢java”相近的事实,比如当前事实有是“用户喜欢python,喜欢c++”,与“喜欢java”事实并不冲突,不需要覆盖事实,那么直接追加,即新事实列表“用户喜欢python,喜欢c++,喜欢java”通过向量召回,我们可以快速确定我们可能需要覆盖的事实列表,为后续的精筛做准备
同时我们可以手动调整向量相似度阈值
`用户说“喜欢java”
相似度 > 0.40 的才召回
- 0.85(喜欢Java)→ 召回 ✓
- 0.42(喜欢Python)→ 召回 ✓(宁可错杀,不可放过)
- 0.38(学习Java)→ 召回 ✓
- 0.15(住在北京)→ 不召回 ✗
(2)筛阶段的Jaccard是什么?
定义
Jaccard相似度 = 两个集合的交集大小 ÷ 并集大小
Jaccard(A, B) = |A ∩ B| / |A ∪ B|
计算示例
文本A:"不喜欢Java" → 字符集合A = {不, 喜, 欢, J, a, v, a}
文本B:"喜欢Java" → 字符集合B = {喜, 欢, J, a, v, a}
交集 A ∩ B = {喜, 欢, J, a, v, a} → 6个字符
并集 A ∪ B = {不, 喜, 欢, J, a, v, a} → 7个字符
Jaccard = 6 / 7 = 0.86
代码实现
private double calculateLexicalSimilarity(String left, String right) {
// 1. 标准化(去空格、转小写)
String normalizedLeft = normalizeKey(left); // "不喜欢java"
String normalizedRight = normalizeKey(right); // "喜欢java"
// 2. 提取字符集合
Set<Character> leftChars = normalizedLeft.chars()
.mapToObj(c -> (char) c)
.collect(Collectors.toSet()); // {不, 喜, 欢, j, a, v}
Set<Character> rightChars = normalizedRight.chars()
.mapToObj(c -> (char) c)
.collect(Collectors.toSet()); // {喜, 欢, j, a, v}
// 3. 计算交集
long intersection = leftChars.stream()
.filter(rightChars::contains)
.count(); // 5个(喜, 欢, j, a, v)
// 4. 计算并集
long union = leftChars.size() + rightChars.size() - intersection;
// 6 + 5 - 5 = 6
// 5. 返回Jaccard系数
return (double) intersection / (double) union; // 5/6 = 0.83
}
Jaccard的作用
| 场景 | Jaccard 值 | 结论 |
|---|---|---|
| “喜欢 Java” vs “喜欢 Java” | 1.0 | 完全相同 |
| “不喜欢 Java” vs “喜欢 Java” | ~0.86 | 高度相似(可能相关) |
| “喜欢 Java” vs “喜欢 Python” | ~0.33 | 低相似(主题不同) |
| “喜欢 Java” vs “住在北京” | ~0.0 | 完全不相关 |
为什么用Jaccard而不是直接字符串比较?
- 字符串比较: “喜欢Java”.equals(“喜欢Java编程”) → false
- Jaccard比较: {喜,欢,J,a,v,a} vs {喜,欢,J,a,v,a,编,程} → 0.75(相似)
Jaccard能捕捉 部分重叠 的相似性。
通过Jaccard,我们能进一步筛选我们向量召回的事实文本,为每个事实文本计算相似度,也就是与我们用户新增事实的相关性,相关性越高,那么就越可能需要执行覆盖事实文本。但是目前还不能完全依靠Jaccard去判定是否需要执行覆盖事实文本,他只起到相似度打分的功能,后续会引入AI对高相似度文本进行实时判定是否需要覆盖事实
(3)判定阶段用AI?
问题的本质
经过"找"和"筛"后,我们确定了两段文本 字面相关 ,但不知道 语义关系 :
existing: "喜欢Java"
incoming: "不喜欢Java"
字面:高度相似(Jaccard=0.86)
语义:完全相反!
existing: "喜欢Java"
incoming: "喜欢Java编程"
字面:高度相似(Jaccard=0.75)
语义:相近补充,应该共存
规则无法判断语义关系,必须引入AI理解。
AI的决策能力
// AI Prompt
String prompt = """
You are a memory relation judge.
memory_type: user_preference
existing_memory: 喜欢Java
incoming_memory: 不喜欢Java
Determine the relationship and return action:
- replace: same topic but opposite meaning(同主题相反)
- append: complementary information(补充信息)
- same: semantically identical(语义相同)
- skip: noisy/redundant(噪声)
- new: unrelated topic(新主题)
""
对于这一段提示词可以再详细一点
AI的理解能力
| 原有记忆 | 新内容 | 关系判定 | 处理策略 |
|---|---|---|---|
| 喜欢 Java | 不喜欢 Java | 同主题,态度相反 | replace |
| 喜欢 Java | 喜欢 Java 编程 | 相近,补充细节 | same(保留更长) |
| 喜欢 Java | 喜欢 Python | 不同主题 | new(追加) |
| 喜欢 Java | 我是后端开发 | 完全无关 | new(追加) |
| 喜欢 Java | 呃,那个 | 无意义 | skip(跳过) |
我们后续会通过AI返回的处理策略,比如replace ,采取事实覆盖策略,即 喜欢 Java ->不喜欢 Java , new(追加),采取追加策略喜欢 Java->喜欢 Java ,喜欢 Python,好处是我们根据AI最终的返回的不同处理策略字段最终确定我们记忆的处理策略
三层过滤的分工
┌─────────────────────────────────────────────────────────────┐
│ 三层过滤金字塔 │
├─────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────┐ │
│ │ AI判别 │ ← 理解语义,智能决策 │
│ │ (20%) │ 成本高(500ms),准确率高 │
│ └────┬────┘ │
│ ↑ │
│ 只有复杂情况才调用 │
│ ↑ │
│ ┌─────────┴─────────┐ │
│ │ 规则过滤(Jaccard) │ ← 确认字面相关 │
│ │ (30%) │ 成本低(10ms) │
│ └─────────┬─────────┘ │
│ ↑ │
│ 过滤明显不相关的 │
│ ↑ │
│ ┌──────────────┴──────────────┐ │
│ │ 向量召回 │ ← 找语义相似的候选 │
│ │ (50%) │ 成本低(50ms) │
│ └─────────────────────────────┘ │
│ │
│ 设计理念:80%的情况在前两层解决,只有20%需要AI │
│ 效果:减少80%的AI调用,同时保持95%+的准确性 │
│ │
└─────────────────────────────────────────────────────────────┘
不用AI会怎样?
方案A:只用向量+规则
"喜欢Java" + "不喜欢Java" → Jaccard=0.86 → 认为是same → 保留更长
结果:清单="喜欢Java"(错误!用户的否定被忽略了)
方案B:简单关键词匹配
if (incoming.contains("不") && existing.contains(去掉"不"后的内容)) {
replace();
}
问题:"不喜欢Java"和"不是Java开发者"都含"不",但语义完全不同
只有AI能真正理解自然语言的复杂语义。
6.长期记忆的存储
这里没有什么需要解释的,直接往表中插入数据即可,我们这里提供一下我们的数据库表
create table ai_chat_session_vector
(
id bigserial
primary key,
session_id varchar(64) not null,
user_id varchar(64) not null,
agent_id varchar(64) not null,
message_id varchar(64),
embedding_model varchar(64) default 'text-embedding-v4'::character varying,
embedding_text text,
embedding vector(1024),
importance_score numeric(3, 2) default 1.0,
created_at timestamp default CURRENT_TIMESTAMP,
updated_at timestamp default CURRENT_TIMESTAMP,
memory_type varchar(64) default 'user_fact'::character varying,
source_role varchar(16) default 'user'::character varying,
memory_status varchar(20) default 'active'::character varying,
source_confidence numeric(3, 2) default 1.0,
source_count integer default 1,
confirmed_at timestamp,
last_seen_at timestamp
);
comment on table ai_chat_session_vector is 'AI会话记忆向量表,存储对话中抽取的高价值片段';
comment on column ai_chat_session_vector.session_id is '会话ID';
comment on column ai_chat_session_vector.user_id is '用户ID';
comment on column ai_chat_session_vector.agent_id is '智能体ID';
comment on column ai_chat_session_vector.message_id is '关联的消息ID(可选)';
comment on column ai_chat_session_vector.embedding_model is '嵌入模型';
comment on column ai_chat_session_vector.embedding_text is '向量化的原始文本内容';
comment on column ai_chat_session_vector.embedding is '向量数据';
comment on column ai_chat_session_vector.importance_score is '重要程度评分';

7.完整流程图
因为原项目代码涉及太多,加上拆分成很多方法,这里打算通过展示流程图的方式来解释,源代码实在不好展示全面
用户侧长期记忆提取
用户消息落库
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 1: 基础过滤 │
│ - 内容不能为空 │
│ - 长度 ≥ 5 字符(过滤"好的""谢谢"等) │
└─────────────────────────────────────────────────────────────────┘
↓ 通过
┌─────────────────────────────────────────────────────────────────┐
│ Step 2: 启发式过滤(快速筛除噪声) │
│ │
│ 关键词检测: │
│ - "我""喜欢""希望""想要""计划""以后" │
│ - "不要""需要""偏好""目标""约束" │
│ - 或长度 > 20 字符 │
│ │
│ 示例: │
│ "我喜欢Java" → ✓ 通过(含"我""喜欢") │
│ "什么是Spring" → ✗ 拦截(疑问句,无价值) │
└─────────────────────────────────────────────────────────────────┘
↓ 通过
┌─────────────────────────────────────────────────────────────────┐
│ Step 3: AI结构化抽取 │
│ │
│ Prompt 设计: │
│ "你是一个长期记忆抽取器。请从用户输入中提取适合长期保存的稳定事实。 │
│ 只保留:用户画像、偏好、长期目标、明确约束、稳定习惯、明确计划。 │
│ 不要保留:临时问题、闲聊、解释过程、一次性请求。 │
│ 返回 JSON 数组: │
│ [{"type":"user_preference","confidence":0.92,"content":"用户偏好中文回答"}]" │
│ │
│ type 只能是:user_profile, user_preference, user_goal, │
│ user_constraint, user_fact │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 4: 规范化处理 │
│ - normalizeMemoryType(): 映射为标准类型 │
│ - normalizeExtractedMemory(): 清洗内容(去空格、去标点等) │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 5: 查重与合并(核心!) │
│ │
│ 查找该类型最新活跃记忆 → findLatestMemoryRecordByType() │
│ │
│ 情况A:无同类记忆 → 直接新建 │
│ 情况B:有同类记忆 → 合并内容 │
│ - 单槽记忆(profile/goal):直接覆盖 │
│ - 多槽记忆(preference/fact):追加合并 │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 6: 向量存储 + 历史记录 │
│ │
│ 1. 构建带类型前缀的嵌入文本:[user_preference] 用户偏好中文回答 │
│ 2. 生成向量(1536维) │
│ 3. 保存到 ai_chat_session_vector 表 │
│ 4. 记录变更历史到 ai_chat_session_vector_history 表 │
│ │
│ 存储字段: │
│ - embedding_text: "[user_preference] 用户偏好中文回答" │
│ - embedding: 向量数据 │
│ - memory_type: "user_preference" │
│ - source_role: "user" │
│ - source_confidence: 0.92 │
│ - source_count: 1(被引用次数) │
│ - importance_score: 1.0 │
└─────────────────────────────────────────────────────────────────┘
AI决策抽取流程
AI回复落库
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 1: 基础过滤(阈值更高) │
│ - 长度 ≥ 20 字符(AI回复通常较长) │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 2: 启发式过滤(确认信号检测) │
│ │
│ 关键词检测: │
│ - "已确认""最终""确定""就按""采用""执行" │
│ - "可以开始""没问题""okay""ok" │
│ - 或长度 > 120 字符 │
│ │
│ 示例: │
│ "已确认采用微服务架构" → ✓ 通过(含"已确认""采用") │
│ "你好,我是AI助手" → ✗ 拦截(无决策信号) │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 3: AI结构化抽取 │
│ │
│ Prompt 设计: │
│ "你是一个对话结论抽取器。请从AI回复中提取适合长期保存的稳定结论。 │
│ 只保留:已确认方案、技术决策、稳定约定、后续执行安排。 │
│ 不要保留:推理过程、示例代码、客套话、解释过程。 │
│ 返回 JSON 数组: │
│ [{"type":"assistant_decision","confidence":0.95,"content":"已确认采用A方案"}]" │
│ │
│ type 只能是:assistant_decision, assistant_constraint │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 4: 规范化处理 │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 5: 双重校验(比用户侧更严格) │
│ │
│ 校验1:isAssistantMemoryType() │
│ - 确保类型是 assistant_decision 或 assistant_constraint │
│ │
│ 校验2:containsConfirmedAssistantSignal() │
│ - 再次确认原始内容包含"已确认""采用"等确认信号 │
│ │
│ 目的:防止AI误判,确保只有真正的决策才入库 │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ Step 6: 向量存储 + 历史记录 │
│ │
│ 存储字段: │
│ - embedding_text: "[assistant_decision] 已确认采用微服务架构" │
│ - memory_type: "assistant_decision" │
│ - source_role: "assistant" │
│ - memory_status: "confirmed"(已确认状态) │
│ - source_confidence: 0.95 │
└─────────────────────────────────────────────────────────────────┘
三:为什么需要记忆摘要
1. 原始对话太长、垃圾信息太多
原始聊天有大量:客套话、解释、推理、举例、冗余废话。直接全存:
- 占 Token、占存储空间
- 后续检索时混入无关内容,干扰 AI 判断摘要 = 只留核心结论,砍掉废话
2. 突破上下文窗口限制
大模型上下文有限,不能把整段历史对话全塞进去。摘要把几百字对话压缩成一两句话关键结论,省 Token、能塞更多记忆。
3. 方便语义检索、向量匹配
长文本向量语义杂乱,短句摘要向量更精准。检索时更容易匹配到同主题记忆,不会因为原文太长跑偏。
4. 统一记忆格式,便于结构化抽取
原始对话口语化、句式乱。摘要后变成标准化短句,方便后续分类:user_profile /user_goal/assistant_decision 等槽位抽取。
5. 避免记忆冗余和重复污染
不做摘要,同一件事会存好几版不同表述。摘要后收敛成唯一核心表述,配合 Jaccard 相似度做去重、覆盖、追加策略。
6. 降低 AI 幻觉
精简、确定性的摘要记忆,比冗长杂乱的原始对话给 AI 的参考更干净、更靠谱,不容易瞎编。
一句话总结
记忆摘要:把冗长聊天压缩成精准核心结论,省 Token、好检索、易去重、结构化更方便管理长期记忆。我们的短期记忆一般采用滑动窗口,但是坏处是只能读取最近几轮的对话,会话摘要可以将更早的会话通过LLM总结,凝练成核心的内容,那么LLM就可以拥有更早之前的对话记忆,而且对记忆做摘要可以提取出对话中更加重要的信息,提升整体记忆的精度,同时减少token消耗
┌─────────────────────────────────────────────────────────────────┐
│ 为什么需要会话摘要 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 问题1: 上下文窗口有限 │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 模型只能处理4K/8K/32K tokens │ │
│ │ 长对话历史会超出限制 │ │
│ │ │ │
│ │ 解决: 用摘要(200 tokens)代替原始消息(5000 tokens) │ │
│ │ 压缩率: 25:1 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ 问题2: 信息密度低 │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 原始消息包含大量冗余: │ │
│ │ - 客套话("你好"、"谢谢") │ │
│ │ - 推理过程("让我想想...") │ │
│ │ - 重复确认("对的"、"没错") │ │
│ │ │ │
│ │ 解决: 摘要只保留关键信息 │ │
│ │ 信息密度提升10倍+ │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
│ 问题3: 检索效率低 │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 从50条消息中找关键信息 → 需要遍历全部 │ │
│ │ 时间复杂度: O(n) │ │
│ │ │ │
│ │ 解决: 直接读摘要 → O(1) │ │
│ │ 响应速度提升50倍+ │ │
│ └─────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘
四:记忆摘要搭建
1:前置条件判断
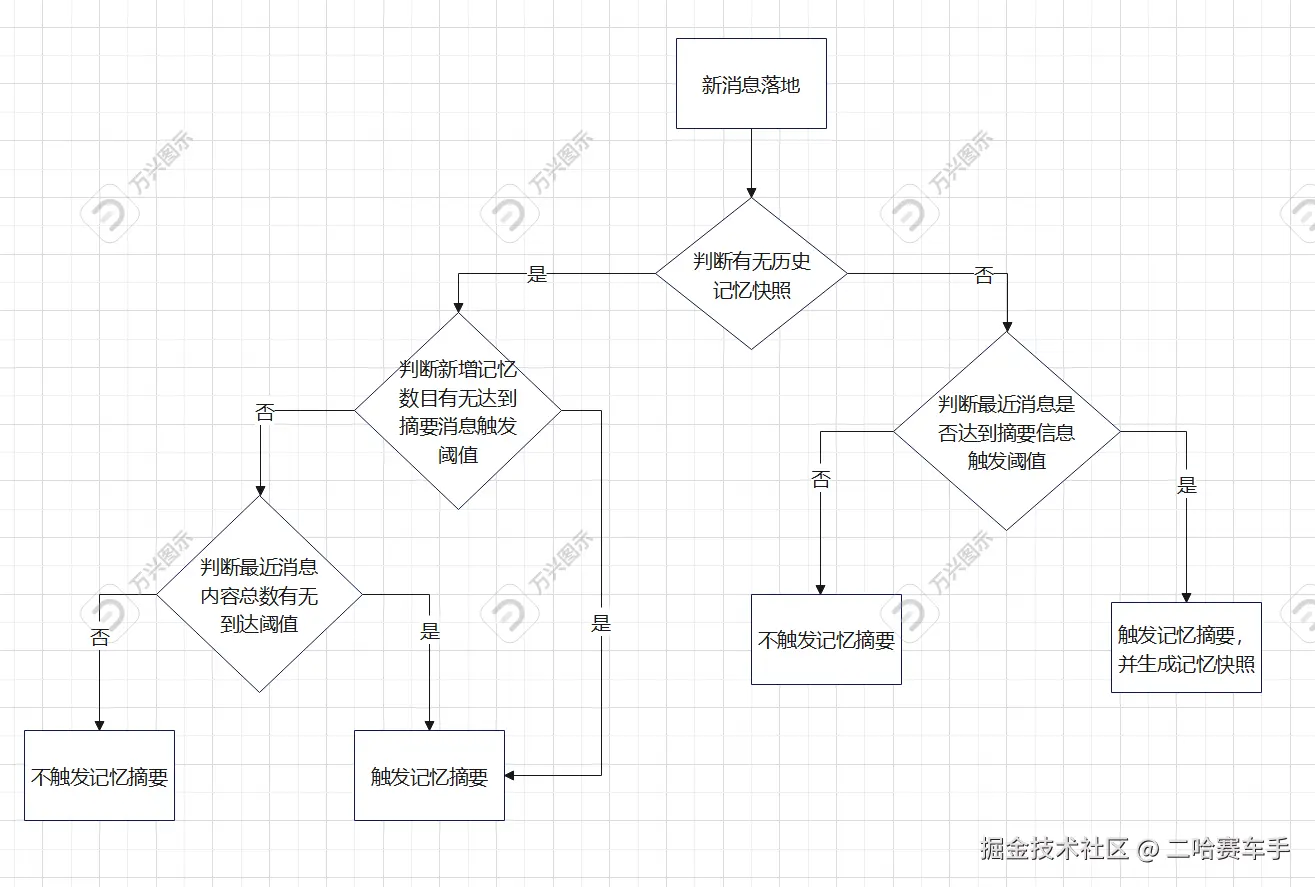
配置:
- threshold = 10条
- charThreshold = 1000字
- window = 20条
场景A:新会话,首次触发
当前:15条消息,总计3000字
判断:
1. 无历史摘要 → 场景1
2. 15 >= 10 → 数量通过
3. 最近15条内容3000字 >= 1000字 → 通过
结果:✅ 触发
场景B:已有摘要,增量触发
历史:摘要V1覆盖消息1-20条
当前:35条消息(新增15条)
判断:
1. 有历史摘要 → 场景2
2. delta = 35 - 20 = 15条
3. 15 >= 10 → 数量通过
结果:✅ 触发
场景C:新增不足但内容长
历史:摘要V1覆盖消息1-20条
当前:27条消息(新增7条),新增内容1500字
判断:
1. 有历史摘要 → 场景2
2. delta = 7 < 10 → 数量不够
3. 降级检查:最近7条内容1500字 >= 1000字 → 通过
结果:✅ 触发
场景D:不触发
历史:摘要V1覆盖消息1-20条
当前:26条消息(新增6条),新增内容500字
判断:
1. 有历史摘要 → 场景2
2. delta = 6 < 10 → 数量不够
3. 降级检查:最近6条内容500字 < 1000字 → 不通过
结果:❌ 不触发
这里我们做了一次降级处理,如果新增信息没有达到阈值,比如信息长度阈值700,摘要触发的信息增量阈值:10,上一次历史摘要范围为0-10条信息,我们又新增了7条信息,总长度1700,因为7<10,按道理说不触发消息摘要,但是这7条信息的总长度1700>700,考虑到他们可能包含一些重要信息,破例生成历史摘要,新摘要消息10-17
2.增量式摘要快照
这是用来考虑如何将消息动态传递给LLM生成摘要,有全量摘要与增量摘要两种方式,但是推荐使用增量摘要
一、全量生成 vs 增量生成对比
全量生成(Full Regeneration)
流程:
[M1, M2, M3, ..., M100] ← 100条原始消息
↓
AI分析全部100条
↓
生成摘要V1
↓
新增10条:[M101, M102, ..., M110]
↓
[M1, M2, ..., M110] ← 110条原始消息
↓
AI分析全部110条(包括之前100条)
↓
生成摘要V2
| 优势 | 说明 | 效果 |
|---|---|---|
| 计算量小 | 只分析 10 条新消息 | 减少 90% 计算 |
| 成本低 | token 数大幅减少 | 节省费用 |
| 速度快 | 处理 10 条很快 | 用户体验好 |
| 保留上下文 | V1 的关键信息不会丢 | 质量稳定 |
增量生成(Incremental Update)
流程:
[M1, M2, ..., M100] ← 100条原始消息
↓
AI分析100条
↓
生成摘要V1:"用户是Java后端,做电商系统"
↓
新增10条:[M101, ..., M110]
↓
摘要V1 + 新10条 ← 不是110条原始消息!
↓
AI理解V1的基础上,补充新信息
↓
生成摘要V2:"用户是Java后端,做电商系统,正在设计微服务架构"
| 优势 | 说明 | 效果 |
|---|---|---|
| 计算量小 | 只分析 10 条新消息 | 减少 90% 计算 |
| 成本低 | token 数大幅减少 | 节省费用 |
| 速度快 | 处理 10 条很快 | 用户体验好 |
| 保留上下文 | V1 的关键信息不会丢 | 质量稳定 |
二.计算增量的方式
增量消息 = 当前全部消息 - 上次摘要已处理的消息
这里先看一下我们的增量表

summary_range_start_message_id摘要覆盖起始消息ID',summary_range_end_message_id摘要覆盖结束消息ID',source_message_count '参与摘要息量',我们可以通过这些字段快速读取到我们是从哪个消息开始做摘要的,从哪个消息结束,有多少消息参与信息摘要,这么做的目的可以精确溯源消息
对应的会话表
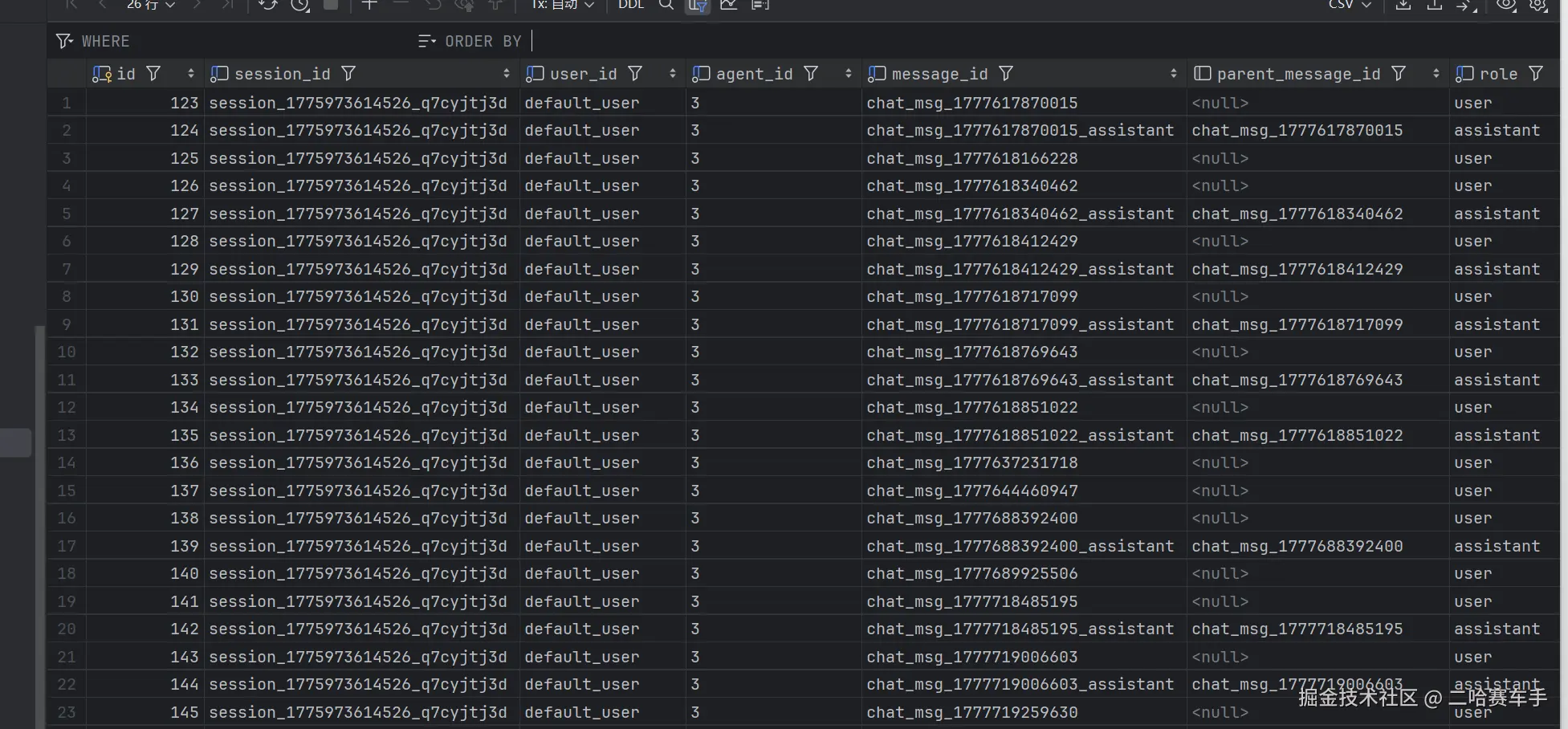
增量消息数 = 当前消息数 - 上次消息数
deltaCount = messageCount - sourceMessageCount
我们举一个例子,还是拿这个图片举例子

我们摘要1的source_message_count:22'说明该摘要总共是我们前22条message的摘要,对应的摘要内容content
[CURRENT_TOPIC]
八千代的结局与孤独的原因
[CONFIRMED_FACTS]
- 在《超时空辉夜姬》的故事中,八千代最终从孤独守望者转变为温柔神明,并与彩叶重逢。
- 八千代的身份引发了观众讨论,她被认为是辉夜姬在数字世界的主程序,而结局中的辉夜是其分身或意识体的延续。
- 酒寄彩叶为辉夜姬制作了仿生身体,苏醒的“辉夜”实际上是八千代意识的现实投射。
- 八千代经历了八千年的孤独,见证了人类文明的发展,始终怀着对未来的酒寄彩叶的期待与思念。
[TODO_ITEMS]
- 无
[USER_CONSTRAINTS]
- 无
我们第26号消息触发摘要(可能是消息文本过长,触发的),他会读取最新一次的摘要的source_message_count:22看到上一次摘要处理到第22号消息,那么当前增量就是26-22=4,那么就会将上面的前22号消息的摘要,结合23,24,25,26号消息发送给AI,生成最新的摘要消息,更新source_message_count:26
3.幂等性检查
幂等性检查:不管重复执行多少次同一个记忆抽取、保存、写入操作,最终结果只生效一次,不会产生重复垃圾记忆、不会重复入库,这就叫幂等;提前做判断防止重复,就是幂等性检查。
问题场景再现
用户快速点击"结束会话"按钮3次
时间线:
T1: 第1次点击 → 触发摘要生成(异步线程A启动)
T2: 第2次点击 → 触发摘要生成(异步线程B启动)
T3: 第3次点击 → 触发摘要生成(异步线程C启动)
没有幂等检查的结果:
3个线程都执行 → 生成3份V2摘要 → 数据库混乱
核心思路:保存"已处理标记"
每次生成摘要后,记录:
- 处理到哪个消息(range_end_message_id)
- 处理了多少条(source_message_count)
下次来检查时,对比这两个数字:
相同 → 已经处理过 → 跳过
不同 → 有新消息 → 处理
在我们新增摘要记忆时,我们是标记了每个摘要的
summary_range_start_message_id摘要覆盖起始消息ID',summary_range_end_message_id摘要覆盖结束消息ID',source_message_count '参与摘要息量'字段,比如26号信息触发摘要生成,因为刷新界面,又重复触发摘要,此时我们只需要比较生成的最新摘要的source_message_count是否为26,如果是,则说明该信息已经生成摘要了,则直接跳过摘要生成,避免重复生成,但是这么做只能避免大部分情况下的线程安全问题,考虑本身并发量不大的情况下,不需要加锁,幂等性检查完全够用
if (latestSnapshot != null
&& StringUtils.hasText(latestSnapshot.getRangeEndMessageId())
&& Objects.equals(latestSnapshot.getRangeEndMessageId(), messages.get(messages.size() - 1).getMessageId())
&& latestSnapshot.getSourceMessageCount() != null
&& latestSnapshot.getSourceMessageCount().intValue() == messages.size()) {
// 已经生成过摘要,跳过
log.debug("【会话摘要】幂等检查跳过 | sessionId={} | 原因=当前范围已生成过摘要", sessionId);
return;
}
对应的代码示例
4.通过AI实现记忆摘取
对于这一段,我们仍采取分字段抽取记忆的方式,这样做的好处是,不论是以后将记忆摘要发送给LLM,还是我们阅读与理解,都能清晰明了我们的记忆摘要内容,便于修改与调试
| 字段 | 存储内容 | 使用场景 |
|---|---|---|
| CURRENT_TOPIC | 当前主题 | 上下文匹配、快速了解 |
| CONFIRMED_FACTS | 确定的事实 | 长期记忆提取、个性化回复 |
| TODO_ITEMS | 待办事项 | 进度跟踪、主动提醒 |
| USER_CONSTRAINTS | 约束条件 | 方案推荐、避免冲突 |
| OPEN_QUESTIONS | 未解问题 | 完整性检查、下次继续 |
┌─────────────────────────────────────────────────────────────────┐
│ 会话摘要的5个结构化字段 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ [CURRENT_TOPIC] ← 现在在聊什么 │
│ [CONFIRMED_FACTS] ← 已经确定了什么 │
│ [TODO_ITEMS] ← 接下来要做什么 │
│ [USER_CONSTRAINTS] ← 用户有什么限制 │
│ [OPEN_QUESTIONS] ← 还有什么没解决的 │
│ │
└─────────────────────────────────────────────────────────────────┘
段1:[CURRENT_TOPIC] 当前话题
用途:记录会话当前的核心主题
示例:
PlainText
[CURRENT_TOPIC]
微服务架构设计 - 服务拆分方案
或
[CURRENT_TOPIC]
数据库选型讨论 - MySQL vs MongoDB
作用:
- 快速了解用户在问什么
- 判断是否需要切换上下文
- 召回相关记忆时做匹配
字段2:[CONFIRMED_FACTS] 已确认的事实
用途:记录已经确定下来的关键信息
示例:
PlainText
[CONFIRMED_FACTS]
- 用户是Java后端开发,5年经验
- 正在设计B2C电商系统
- 目标QPS:10000
- 已确定采用微服务架构
- 已拆分:用户服务、订单服务
- 技术栈:Spring Cloud + MySQL + Redis
作用:
- 长期记忆提取的来源
- 避免重复询问已知信息
- 个性化回复的依据
字段3:[TODO_ITEMS] 待办事项
用途:记录还需要完成的事情
示例:
PlainText
[TODO_ITEMS]
- 定义用户服务接口
- 设计订单状态机
- 确定支付流程
- 评估分布式事务方案
- 压测方案准备
作用:
- 跟踪会话进度
- 下次继续时知道从哪里开始
- 主动提醒用户未完成的点
字段4:[USER_CONSTRAINTS] 用户约束
用途:记录用户的限制条件或偏好
示例:
PlainText
[USER_CONSTRAINTS]
- 预算有限,优先开源方案
- 团队熟悉Java技术栈
- 要求支持高并发(1万QPS)
- 不接受云服务,必须私有化部署
- 上线时间:3个月内
作用:
- 方案推荐时考虑约束
- 避免提出不符合条件的建议
- 长期保存用户偏好
字段5:[OPEN_QUESTIONS] 未解决问题
用途:记录还没讨论清楚的问题
示例:
PlainText
[OPEN_QUESTIONS]
- 是否需要分库分表?
- 缓存一致性如何保证?
- 选择TCC还是Saga分布式事务?
- 消息队列用Kafka还是RocketMQ?
作用:
- 提醒用户还有问题待解决
- 下次会话时主动提起
- 评估会话是否完整结束
对应的提示词构建
private String buildIncrementalSummaryPrompt(ChatSummarySnapshot latestSnapshot, List<ChatMessageDTO> deltaMessages) {
// 旧摘要,无则为 NONE
String previousSummary = latestSnapshot == null || !StringUtils.hasText(latestSnapshot.getSummaryText())
? "NONE"
: latestSnapshot.getSummaryText().trim();
// 格式化增量消息
String historyText = deltaMessages.stream()
.filter(Objects::nonNull)
.map(this::formatMessage)
.filter(StringUtils::hasText)
.collect(Collectors.joining("\n"));
// 构建提示词
StringBuilder prompt = new StringBuilder();
prompt.append("You are a conversation state tracker.\n");
prompt.append("Update the previous summary using only the incremental messages below.\n");
prompt.append("Keep stable, reusable facts only. Do not rewrite unchanged facts.\n");
prompt.append("Output must use these sections exactly:\n");
prompt.append("[CURRENT_TOPIC]\n");
prompt.append("[CONFIRMED_FACTS]\n");
prompt.append("[TODO_ITEMS]\n");
prompt.append("[USER_CONSTRAINTS]\n");
prompt.append("[OPEN_QUESTIONS]\n");
prompt.append("Do not output analysis or extra explanation.\n\n");
prompt.append("Previous summary:\n");
prompt.append(previousSummary).append("\n\n");
prompt.append("Incremental messages:\n");
prompt.append(historyText).append("\n\n");
prompt.append("Updated structured summary:");
return prompt.toString();
}
[CURRENT_TOPIC]
八千代的结局与孤独的原因
[CONFIRMED_FACTS]
- 在《超时空辉夜姬》的故事中,八千代最终从孤独守望者转变为温柔神明,并与彩叶重逢。
- 八千代的身份引发了观众讨论,她被认为是辉夜姬在数字世界的主程序,而结局中的辉夜是其分身或意识体的延续。
- 酒寄彩叶为辉夜姬制作了仿生身体,苏醒的“辉夜”实际上是八千代意识的现实投射。
- 八千代经历了八千年的孤独,见证了人类文明的发展,始终怀着对未来的酒寄彩叶的期待与思念。
- 八千代保留了八千年来的记忆,但她选择以一种更纯粹的形式存在。
- 这个结局不仅完成了她与彩叶之间的命运循环,也标志着八千代从“时空囚徒”到获得完整一生的蜕变。
[TODO_ITEMS]
- 无
[USER_CONSTRAINTS]
- 无
[OPEN_QUESTIONS]
- 无
最终形成类似的记忆摘要结构
5.完成功能流程图
这一部分还是只展示流程图,不好展示源码部分
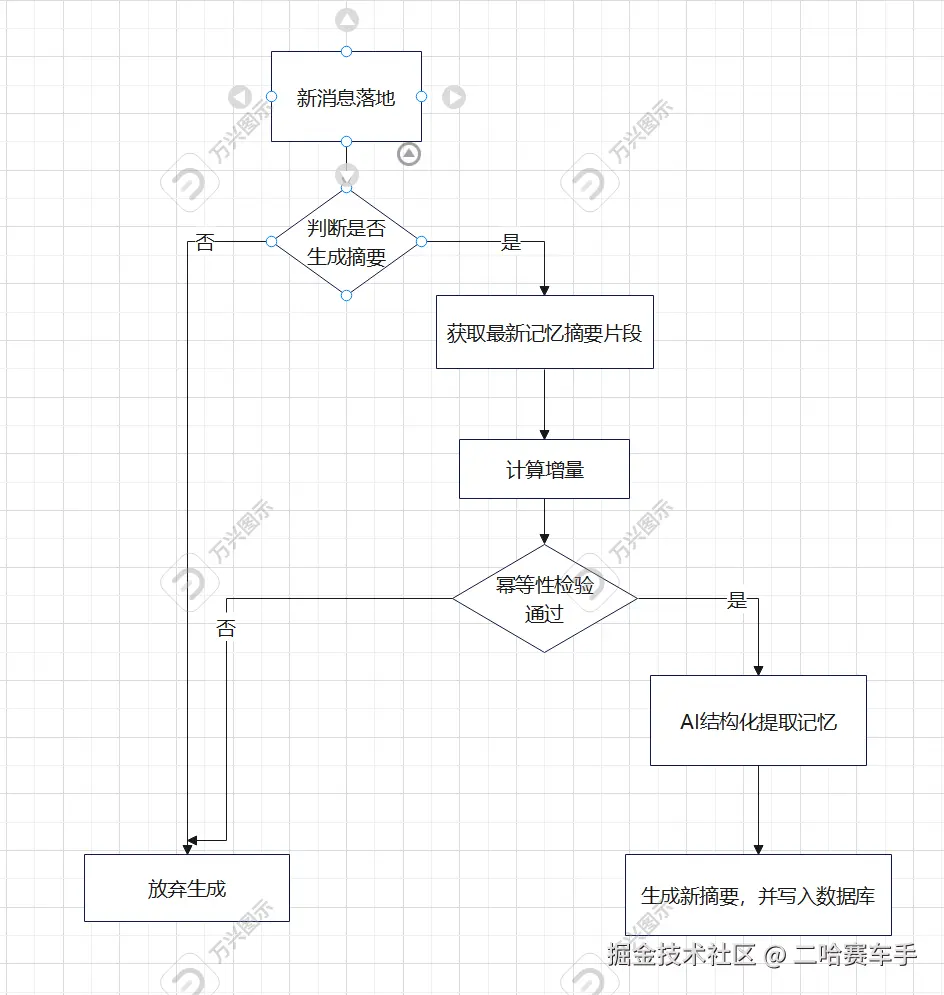
6.附上记忆摘要表
create table ai_chat_session_summary
(
id bigint auto_increment comment '自增主键'
primary key,
session_id varchar(64) not null comment '业务会话ID',
user_id varchar(64) not null comment '用户ID',
agent_id varchar(64) not null comment '智能体ID',
summary_version int default 1 not null comment '摘要版本号',
summary_text text null comment '会话摘要文本',
summary_range_start_message_id varchar(64) null comment '摘要覆盖起始消息ID',
summary_range_end_message_id varchar(64) null comment '摘要覆盖结束消息ID',
source_message_count int default 0 not null comment '参与摘要的消息数量',
summary_status tinyint default 1 not null comment '摘要状态:1-成功,2-失败',
summary_latency_ms bigint null comment '摘要生成耗时(毫秒)',
summary_error varchar(512) null comment '摘要失败原因',
deleted tinyint default 0 not null comment '逻辑删除:0-否,1-是',
created_at datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updated_at datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间'
)
comment 'AI Agent 会话摘要表' collate = utf8mb4_unicode_ci;
create index idx_session_version
on ai_chat_session_summary (session_id, summary_version);
create index idx_user_agent
on ai_chat_session_summary (user_id, agent_id);
这是记忆摘要表
create table ai_chat_message
(
id bigint auto_increment comment '自增主键'
primary key,
session_id varchar(64) not null comment '业务会话ID',
user_id varchar(64) not null comment '用户ID',
agent_id varchar(64) not null comment '智能体ID',
message_id varchar(64) not null comment '业务消息ID',
parent_message_id varchar(64) null comment '父消息ID',
role varchar(32) not null comment '消息角色',
message_type varchar(32) default 'chat' not null comment '消息类型',
stage varchar(32) null comment '阶段',
sub_type varchar(64) null comment '子类型',
step int null comment '步骤序号',
content longtext null comment '消息内容',
token_count int null comment 'Token数量',
deleted tinyint default 0 not null comment '逻辑删除',
created_at datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updated_at datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
constraint uk_message_id
unique (message_id)
)
collate = utf8mb4_unicode_ci;
create index idx_session_created
on ai_chat_message (session_id, created_at);
create index idx_session_role
on ai_chat_message (session_id, role);
create index idx_stage_step
on ai_chat_message (session_id, stage, step);
create index idx_user_agent
on ai_chat_message (user_id, agent_id);
这是记忆对话表
五.全局记忆
1. 什么是全局记忆
全局记忆:跨所有会话、永久生效的公共长期记忆,不局限某一次聊天,不管你新开多少对话、换多少次会话,AI 都一直记得。
2. 它是干啥的(核心作用)
- 全会话通用新建聊天、清空上下文、换会话,人设、偏好、背景依然保留,不会一换新对话就失忆。
- 存稳定不变的硬核信息专门存长期不会变的内容:
- 用户身份:Java 后端开发、工作年限
- 固定偏好:只用中文、不聊无关话题
- 硬性约束:只晚上有空、拒绝某类方案
- 既定事实:在上海、准备跳槽等
- 给所有对话打底子每次 AI 回答前,先拉取全局记忆,再结合当前会话上下文,做到:统一人设、统一风格、统一约束、个性化连贯。
- 和临时会话记忆区分开
- 会话记忆:只在当前聊天有效,关了就没
- 全局记忆:全局生效、持久保存、所有会话共享
3. 极简例子
你在任意会话告诉 AI:
我是 Java 后端,只用中文回答,不要废话。
存入全局记忆。之后每一次新开对话,AI 自动遵守:默认中文、简洁回答、知道你是 Java 开发,不用每次重新自我介绍。
4. 一句话总结
全局记忆 = AI 对你的永久档案库,所有会话通用、跨聊天不丢失,用来固定人设、偏好、身份和硬性规则。
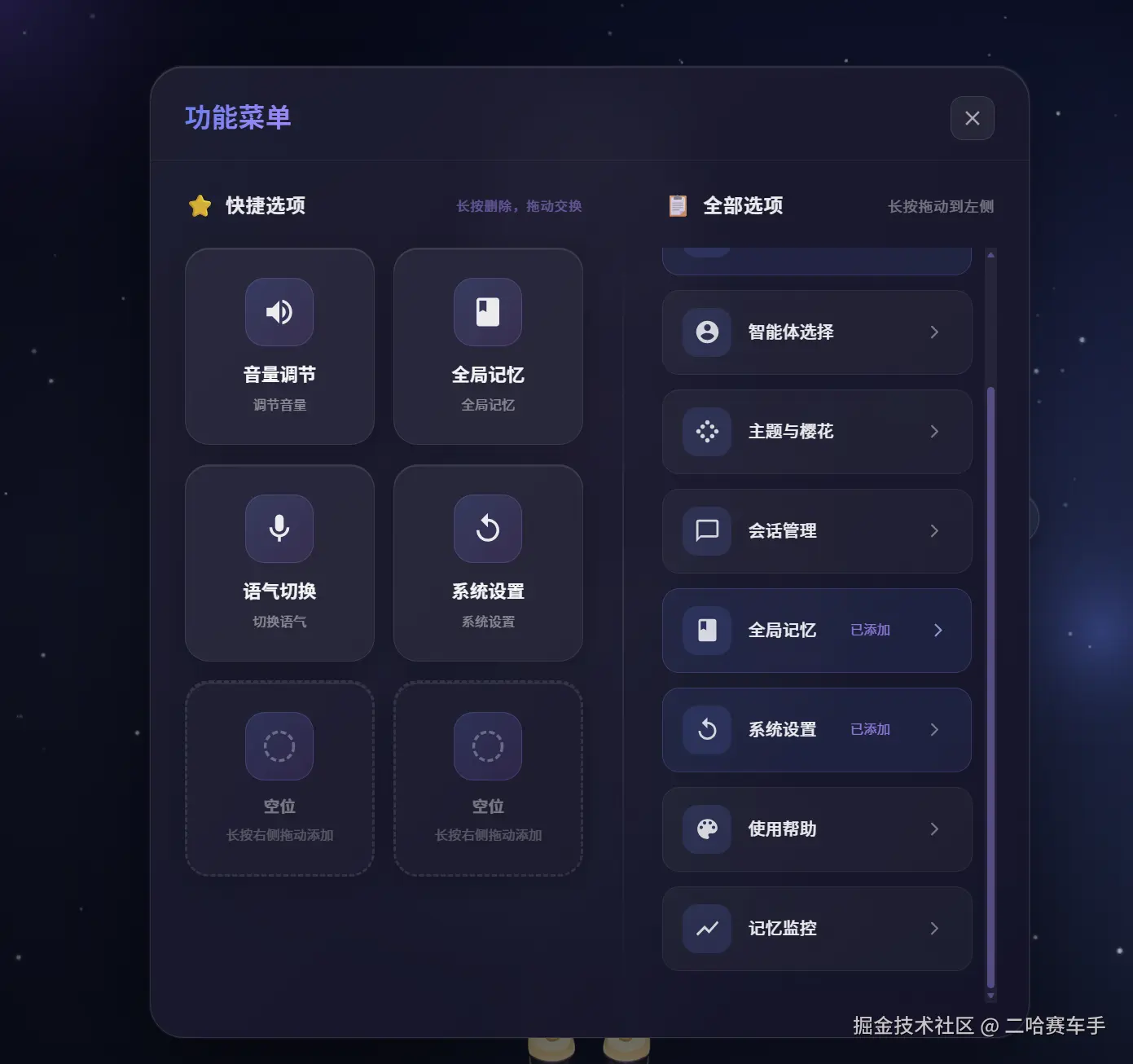
我们智能体项目中是设定了一个全局记忆的功能
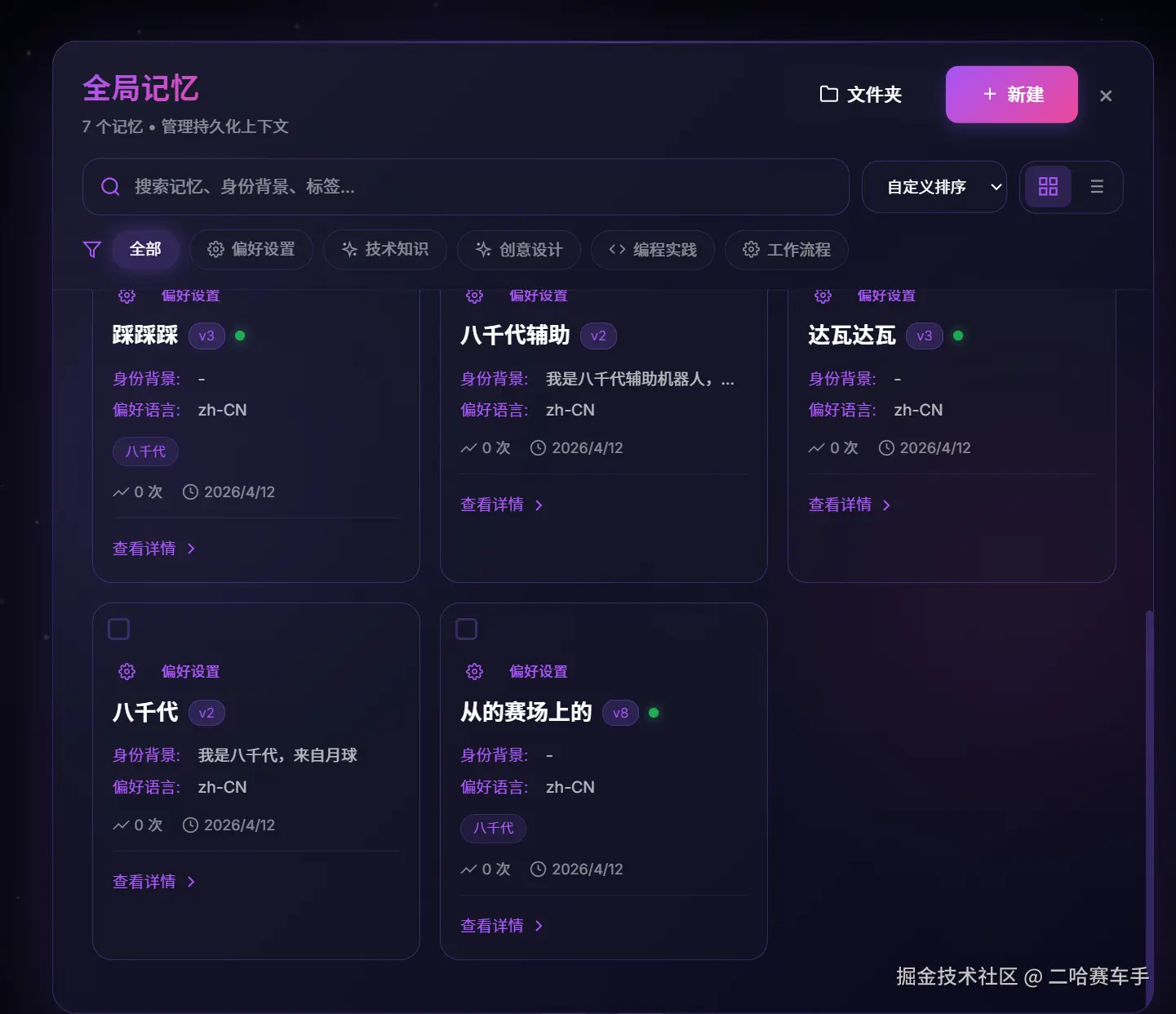
他这里采取文件夹式的全局记忆管理,并且支持标签分类,主要还是避免全局记忆堆在一起
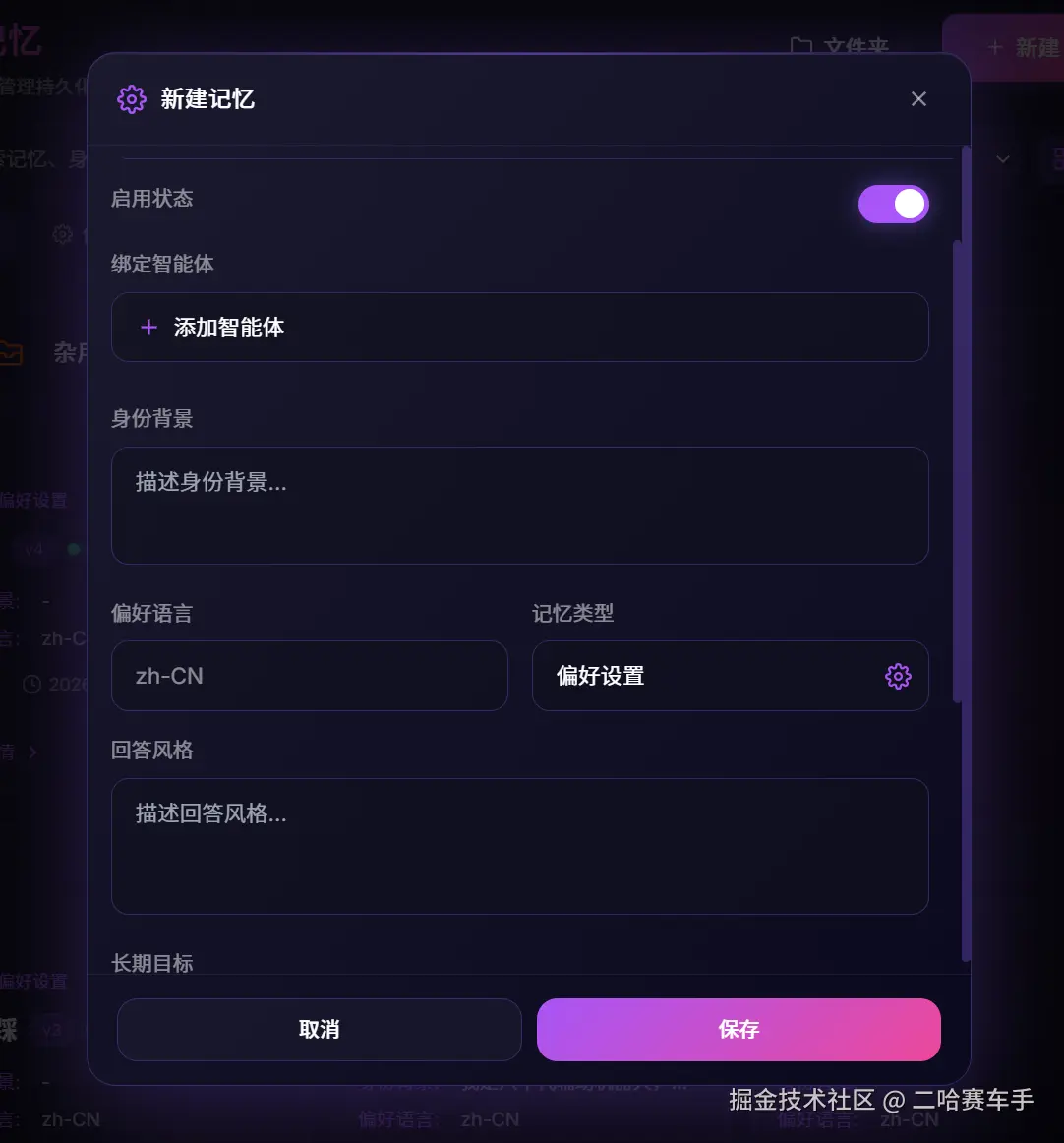
它支持填写以下信息,还是采取分类填写的方式,便于管理和LLM读取
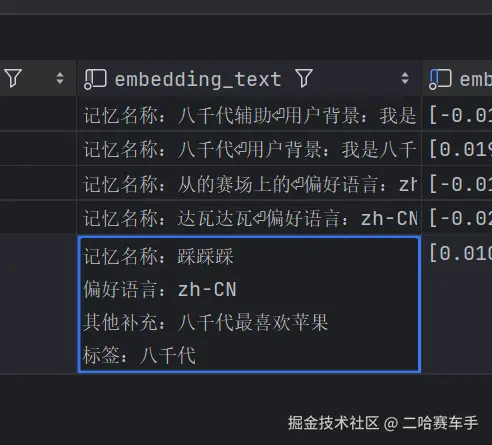
对应的全局记忆存放格式
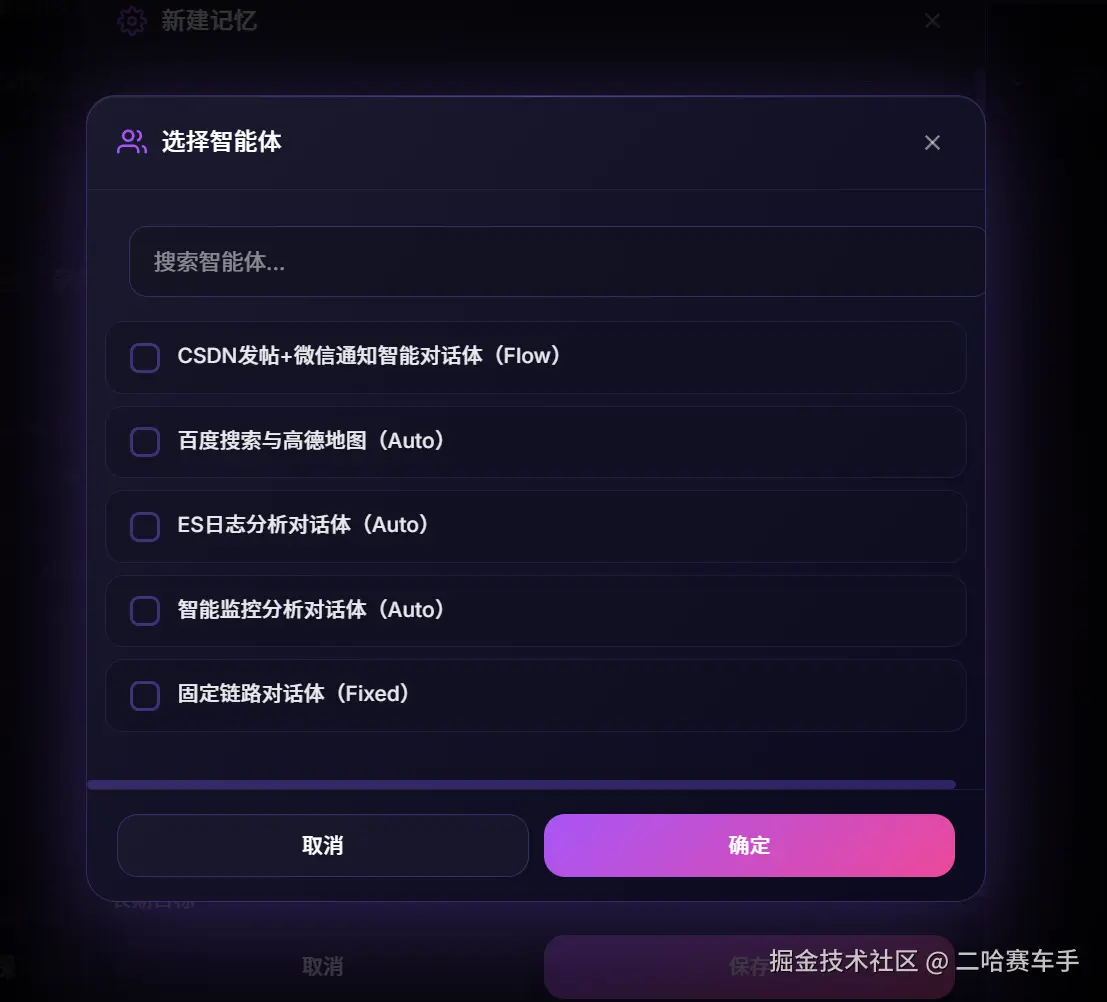
同时我们还支持当前全局记忆关联的智能体选项,支持多选,同时每个智能体支持绑定多个全局记忆,这样后续调用该智能体就会自动携带设置的全局记忆
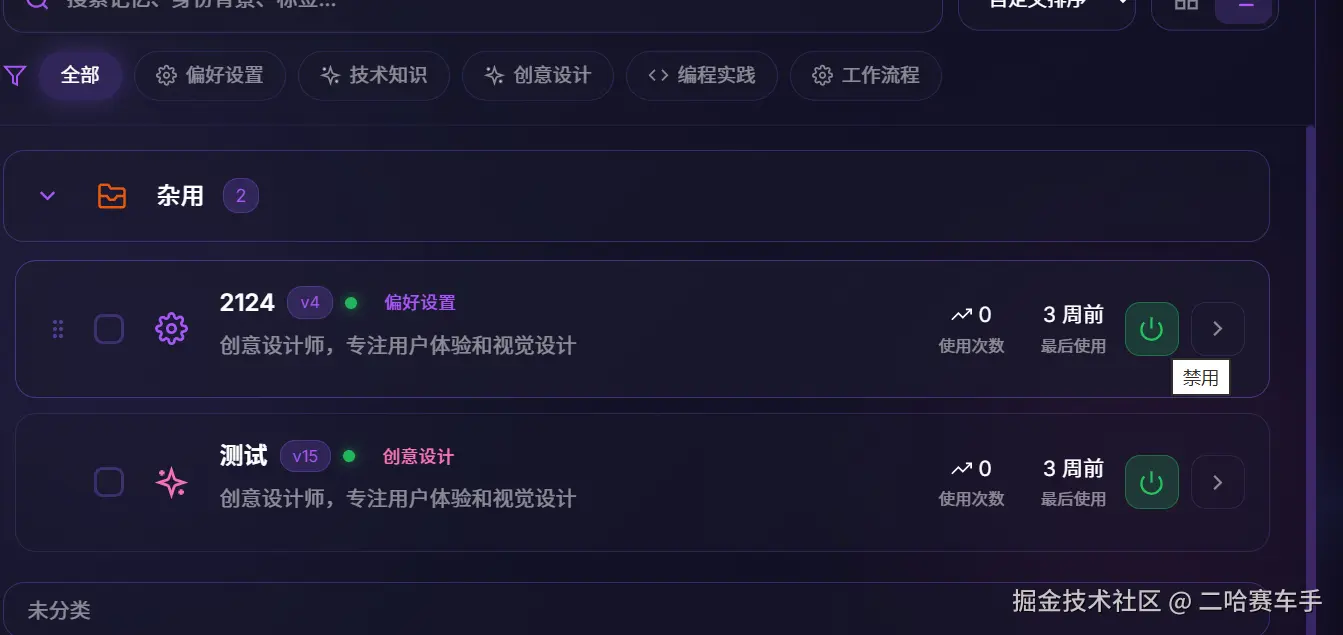
同时还设置了快捷开启/关闭记忆的按钮,便于快速启用,禁用选中的全局记忆,通过这种措施,我们可以快速管理全局记忆,同时关联我们目标的智能体,分类式的填写方式也便于我们读取全局记忆,同时会让LLM更好理解
六.全局记忆设计
这里面简单的表格提交与记忆存储,我们就直接跳过了,这里需要提一下我们的全局记忆是存储在向量表中的。当初博主就设计这一块就想到了,按道理说我们的全局记忆不应该很多,记忆一多就容易杂乱,所以不介意这一块设置很多。但是博主就想,如果有的人一口气设置了几十多个全局记忆,我们总不能全部返回吧,所以博主就打算分层过滤,优先返回给LLM高质量的全局记忆。但是在实际项目中,我们建议前端限制最大全局记忆数量,即一个智能体最多绑定几个全局记忆,博主这里纯属与设计有点过度,搞完后才想到这一点
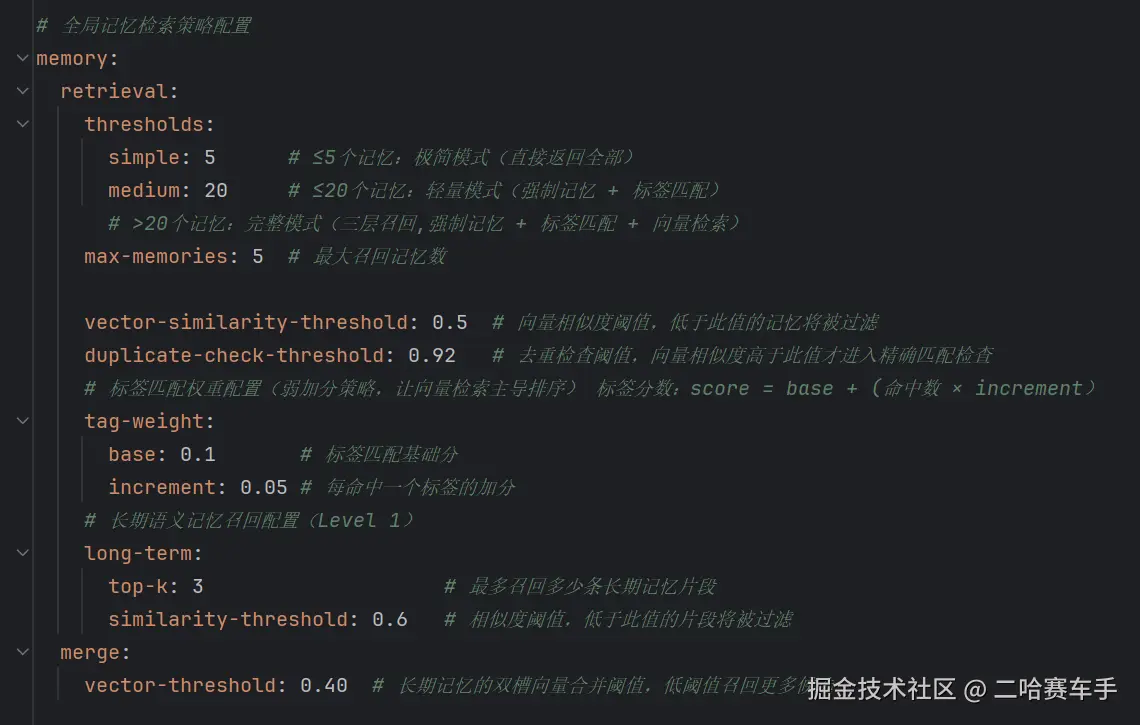
我们可以手动配置返回的全局记忆数目,不同过滤层级的启用阈值,向量检索的相似度阈值等等
(1)轻量过滤模式解释
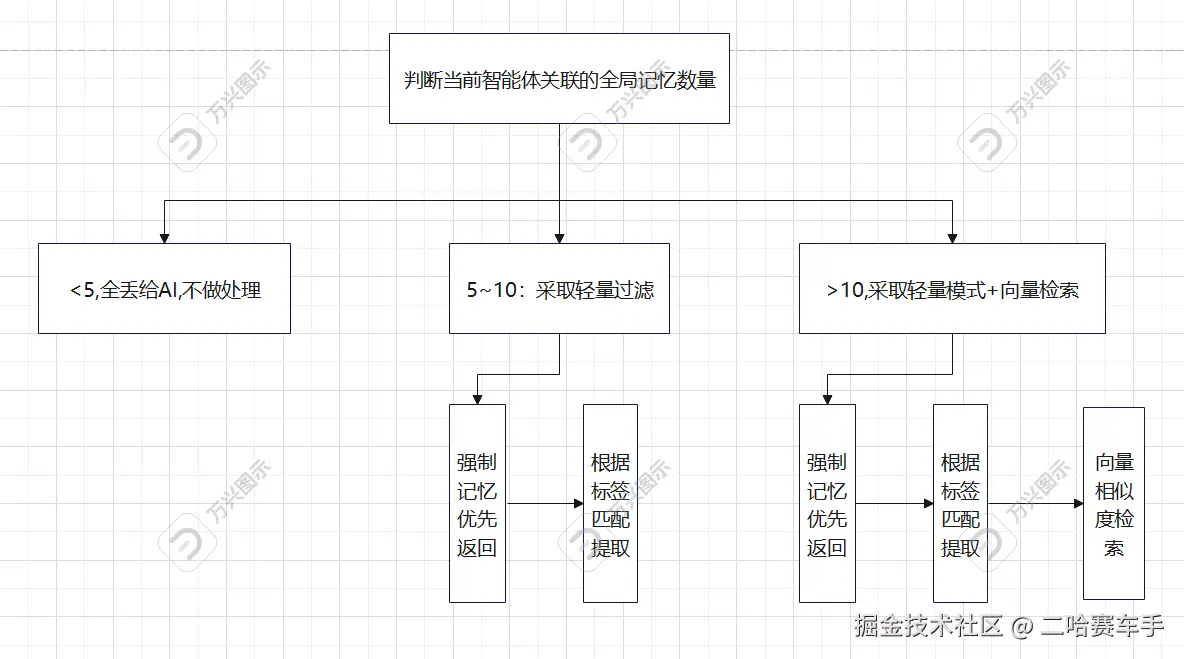
轻量模式 vs 完整模式对比
┌─────────────────────────────────────────────────────────────────────────────┐
│ 三种召回模式对比 │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ 模式 记忆数量 召回策略 适用场景 │
│ ───────────────────────────────────────────────────────────────────────── │
│ 极简模式 ≤5条 直接返回全部 记忆很少 │
│ 轻量模式 5-20条 强制记忆 + 标签匹配 记忆较少 │
│ 完整模式 >20条 强制记忆 + 标签匹配 + 向量检索 记忆较多 │
│ │
│ 轻量模式特点:没有向量检索,性能更好,适合记忆不多的场景 │
│ │
└─────────────────────────────────────────────────────────────────────────────┘
轻量模式流程图
┌─────────────────────────────────────────────────────────────────────────────┐
│ 轻量模式记忆召回(两层架构) │
└─────────────────────────────────────────────────────────────────────────────┘
输入:
- candidates: 候选记忆列表(当前智能体管理的全部全局记忆)
- userQuestion: 用户问题
- maxMemories: 最大返回条数(默认5,配置文件中配置)
输出:
- 按相关性排序的TopK记忆
强制记忆
我们设定了全局记忆的用户身份有
profile和用户长期目标字段longTermGoal为强制记忆,如果当前智能体召回的所有关联的全局记忆集合中,有全局记忆包含了这两个字段,且内容不为空,那么该记忆就是强制记忆,必须要召回,因为这两个字段包含了记忆的重要信息
强制记忆(有profile或longTermGoal):
┌─────────────────────────────────────────────────────────────┐
│ { │
│ "id": 1, │
│ "profile": "Java后端开发,5年经验", ← 有profile,强制记忆 │
│ "longTermGoal": null, │
│ "content": "..." │
│ } │
│ │
│ { │
│ "id": 2, │
│ "profile": null, │
│ "longTermGoal": "3个月学会K8s", ← 有longTermGoal,强制记忆 │
│ "content": "..." │
│ } │
└─────────────────────────────────────────────────────────────┘
普通记忆(无profile且无longTermGoal):
┌─────────────────────────────────────────────────────────────┐
│ { │
│ "id": 3, │
│ "profile": null, ← 无profile │
│ "longTermGoal": null, ← 无longTermGoal │
│ "content": "喜欢喝咖啡" ← 普通偏好,非强制 │
│ } │
┌─────────────────────────────────────────────────────────────────────────────┐
│ 为什么profile和longTermGoal是强制记忆 │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ profile(用户画像) │
│ ├── 是用户最核心、最稳定的身份信息 │
│ ├── 影响AI回答的基调和专业度 │
│ ├── 例如:知道用户是"架构师" vs "初学者",回答完全不同 │
│ └── 必须每次带上,不能遗漏 │
│ │
│ longTermGoal(长期目标) │
│ ├── 是用户当前阶段的核心诉求 │
│ ├── 影响AI回答的方向和重点 │
│ ├── 例如:知道用户要"3个月学会K8s",会主动推进学习进度 │
│ └── 必须每次带上,确保服务连贯性 │
│ │
│ 普通偏好(如喜欢喝咖啡、偏好深色模式) │
│ ├── 相对次要,不影响核心回答质量 │
│ ├── 按相似度召回即可 │
│ └── 不必强制返回 │
│ │
└─────────────────────────────────────────────────────────────────────────────┘
完整召回流程:
1. 强制记忆召回
筛选条件:profile != null || longTermGoal != null
结果:必返回,不受maxMemories限制(但会计入总数)
2. 普通记忆召回
筛选条件:profile == null && longTermGoal == null
结果:按标签/向量相似度排序,取剩余名额
示例:
maxMemories = 5
强制记忆 = 2条(有profile和longTermGoal)
普通记忆 = 取Top 3条
最终返回:2条强制 + 3条普通 = 5条
标签匹配
运用他的核心原因是,唯一能够区分全局记忆的重要程度的,除了上面提到的两个重要字段,还有一个就是标签,其他的“额外信息,回答风格,回答语言啥的”都是不太重要的,没有核心的区分度,如果全局记忆达到几十个,这些字段的重要性就更低了,全部返回还会干扰LLM,下面解释一下为什么需要标签匹配
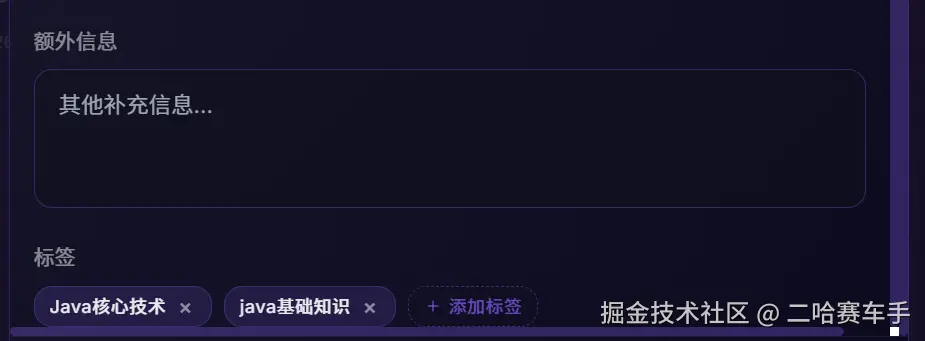
这里可以看见我们设计了两个Tag,他们都是和java有关系的,如果我们用户问题“推荐点java知识”,因为“java”与我们全局记忆的java标签匹配,那么就直接返回整个全局记忆。这里可以看出我们的标签其实也很重要,标识了我们当前全局记忆和哪些内容相关,可以快速定位该记忆的作用,是否与我们用户问题相关
┌─────────────────────────────────────────────────────────────────────────────┐
│ 标签匹配流程 │
└─────────────────────────────────────────────────────────────────────────────┘
输入:
- memories: 候选记忆列表
- questionKeywords: 问题关键词列表(如["Java", "微服务"])
输出:
- 标签匹配的记忆列表(带相关性分数)
流程:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 问题关键词 │ → │ 遍历记忆 │ → │ 标签匹配 │ → │ 计算分数 │
│ 转小写 │ │ 检查标签 │ │ 统计命中 │ │ 弱加分策略 │
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
| 用户问题词 | 标签 | 匹配结果 | 判定说明 |
|---|---|---|---|
| java | java | ✓ | 完全相等 |
| java | javascript | ✓ | 包含(tag.contains (word)) |
| 微服务 | 微服务架构 | ✓ | 包含 |
| spring | springboot | ✓ | 包含 |
| java | python | ✗ | 不匹配 |
这里可能还需要优化一点,比如用户问题很长,我们可能还需要拆问题,取出里面的核心词,与标签进行比较,比如
“我是一名新入门的程序员,可以多和我交流一下java吗”,我们要精确拆分出“java”一词才行
相关性分数设定
if (matchedCount > 0) {
// 弱加分公式:基础分 + (命中数 * 增量)
double score = tagWeightBase + (matchedCount * tagWeightIncrement);
// 默认配置:
// tagWeightBase = 0.1
// tagWeightIncrement = 0.05
// 示例:
// 命中1个标签:0.1 + (1 * 0.05) = 0.15
// 命中2个标签:0.1 + (2 * 0.05) = 0.20
// 命中3个标签:0.1 + (3 * 0.05) = 0.25
// 只在当前分数更高时才更新
Double currentScore = memory.getRelevanceScore();
if (currentScore == null || score > currentScore) {
memory.setRelevanceScore(score);
}
return memory;
}
如果我们用户的问题命中了多个标签,那么就会触发分数加成,当前记忆的分数就会累加,分数越高,排序时就会排在最前面
private List<GlobalMemoryDTO> retrieveLightweightMode(List<GlobalMemoryDTO> candidates,
String userQuestion,
int maxMemories) {
log.info("启用【轻量模式】- 强制记忆 + 标签匹配");
LinkedHashMap<Long, GlobalMemoryDTO> retrieved = new LinkedHashMap<>();
// 1. 强制记忆(优先级最高)
List<GlobalMemoryDTO> mandatoryMemories = retrieveMandatoryMemories(candidates);
log.info("【轻量模式】强制记忆召回 {} 条", mandatoryMemories.size());
for (GlobalMemoryDTO memory : mandatoryMemories) {
if (memory.getId() != null) {
retrieved.putIfAbsent(memory.getId(), memory);
}
}
// 2. 标签匹配
List<String> questionTags = extractQuestionKeywords(userQuestion);
List<GlobalMemoryDTO> tagMatchedMemories = retrieveByTags(candidates, questionTags);
log.info("【轻量模式】标签匹配召回 {} 条, 关键词: {}", tagMatchedMemories.size(), questionTags);
for (GlobalMemoryDTO memory : tagMatchedMemories) {
if (memory.getId() != null) {
retrieved.putIfAbsent(memory.getId(), memory);
}
}
// 排序并限制数量
List<GlobalMemoryDTO> result = sortAndLimit(retrieved.values(), maxMemories);
// 打印最终召回结果
log.info("【轻量模式】最终召回 {} 条: {}", result.size(),
result.stream().map(m -> m.getMemoryName() + "(" + m.getRelevanceScore() + ")").collect(Collectors.joining(", ")));
return result;
}
对应的参考项目代码
(2)轻量过滤结合向量过滤模式解释
它只适用于我们全局记忆非常多时,我们才需要结合向量过滤,提取出核心全局记忆,但是一般场景下根本用不到,或者非常难触发,但是也是为了以防万一,这一块我们只需要讲解向量过滤模式,其他还是类似的
┌─────────────────────────────────────────────────────────────────────────────┐
│ 向量相似度召回流程(完整模式第3层) │
└─────────────────────────────────────────────────────────────────────────────┘
输入:
- userId: 用户ID
- userQuestion: 用户问题
- candidateMap: 候选记忆Map(ID→记忆)
- topK: 召回数量
- tagMatchedMemoryIds: 标签匹配的记忆ID集合
输出:
- 向量召回的记忆列表(带相似度分数)
流程:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 问题向量化 │ → │ 向量搜索 │ → │ 分层阈值过滤 │ → │ 组装结果 │
│ Embedding │ │ TopK召回 │ │ 标签补偿策略 │ │ 设置分数 │
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
这里我们有一点设计改动,就是我们这里是先向量检索->后标签兜底,核心原因是,向量检索可以全面检索所有的全局记忆,直接根据所有字段返回与用户问题语义相近的全局记忆片段,而标签匹配更加适用于标签覆盖全面的场景。我们采取的模式是先向量检索,超过检索阈值的直接返回(一般阈值设置比较高,确保检索的精确性),但是当向量检索片段少,或者普遍相似度较低,那么采取标题匹配垫底,标签命中加分,到达一定阈值后确认记忆有效,加入记忆列表
具体场景对比
场景1:向量能搞定(不需要标签兜底)
用户问题:"怎么学Java?"
记忆A:"我是Java后端,在学Spring Boot"
- 向量相似度:0.90(高)
- 标签:[java, 后端]
- 结果:向量直接召回 ✓
记忆B:"刚入门Java编程,做Web项目"
- 向量相似度:0.85(高)
- 标签:[java, 入门]
- 结果:向量直接召回 ✓
结论:向量语义理解准确,标签只是锦上添花
场景2:向量遗漏,需要标签兜底(关键设计)
用户问题:"Java框架推荐"
记忆C:"我在用Spring全家桶做项目"
- 向量相似度:0.45(低,因为没出现"Java")
- 标签:[java, spring, 项目] ← 有java标签!
- 无标签兜底:被过滤 ✗
- 有标签兜底:保留 ✓(给予机会)
记忆D:"后端开发用了很多框架"
- 向量相似度:0.42(低)
- 标签:[后端, 框架]
- 标签匹配:否(问题关键词是java)
- 结果:过滤 ✗(正确)
结论:标签补偿向量语义覆盖不足的情况
(3)具体的数据表设定
全局记忆表(向量表)
create table user_global_memory_vector
(
id bigserial
primary key,
memory_id bigint not null,
user_id varchar(64) not null,
agent_id varchar(64),
embedding_model varchar(64) not null,
embedding_text text not null,
embedding vector(1024) not null,
version integer default 1 not null,
metadata jsonb,
created_at timestamp default CURRENT_TIMESTAMP not null,
updated_at timestamp default CURRENT_TIMESTAMP not null
);
comment on table user_global_memory_vector is '用户全局记忆向量表';
comment on column user_global_memory_vector.memory_id is '对应MySQL记忆ID';
comment on column user_global_memory_vector.user_id is '用户ID';
comment on column user_global_memory_vector.agent_id is '智能体ID';
comment on column user_global_memory_vector.embedding_model is 'Embedding模型';
comment on column user_global_memory_vector.embedding_text is '参与向量化文本';
comment on column user_global_memory_vector.embedding is '向量值';
comment on column user_global_memory_vector.version is '版本号';
comment on column user_global_memory_vector.metadata is '元数据标签';

全局记忆与智能体关联表(通过该表,我们选定智能体,就能通过他查询指定了关联的全局记忆)
create table user_global_memory_binding
(
id bigint auto_increment comment '自增ID'
primary key,
memory_id bigint not null comment '记忆ID',
user_id varchar(64) not null comment '用户ID',
agent_id varchar(64) not null comment '智能体ID',
enabled tinyint(1) default 1 not null comment '是否启用 0否 1是',
deleted tinyint(1) default 0 not null comment '是否删除 0否 1是',
created_at datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updated_at datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
created_by varchar(64) null comment '创建人',
updated_by varchar(64) null comment '更新人'
)
comment '用户全局记忆绑定智能体表';
create index idx_memory_id
on user_global_memory_binding (memory_id);
create index idx_user_agent
on user_global_memory_binding (user_id, agent_id);
create index idx_user_deleted
on user_global_memory_binding (user_id, deleted);
我们这里采用了
逻辑删除,通过添加一个delete字段,来避免关系的物理删除
七:记忆装配
这一步这要是在用户提出问题时,通过用户问题,查询长期记忆,关联的全局记忆,并且结合记忆摘要,短期记忆窗口等全部组装成一个完整的记忆上下文,发送给AI,这里只演示一下我们的装配顺序,其余的也没啥讲解的
┌─────────────────────────────────────────────────────────────────────────────┐
│ 记忆上下文装配顺序 │
└─────────────────────────────────────────────────────────────────────────────┘
Step 1: 全局记忆召回(Level 1)
↓
Step 2: 长期记忆召回(Level 2)
↓
Step 3: 会话摘要(Level 3)
↓
Step 4: 短期记忆窗口(Level 4)
↓
Step 5: 组装完整Prompt
这里需要说明一下,我们的短期记忆窗口就是将最近几轮的对话(比如最近5轮)查询出来,拼接进去即可,会话摘要只需要读取最新摘要快照即可,而长期记忆召回需要根据用户问题,通过向量检索出与用户问题相关的记忆片段,全局记忆一般也是直接读取拼装,如果全局记忆多了才涉及到我们上面说的全局记忆的向量检索模式
八. 记忆观测机制
我们不能直接将记忆拼装完成后,直接传给LLM,而是需要将各阶段记忆的一些情况记录在表中,比如长期记忆检索了多少,过滤后还剩多少,最高相关度分数多少,全局记忆召回数目,整个检索耗时等等…,这些信息可以评测我们整体的记忆检测情况,便于后期调试
表结构设计
// AiAgentMemoryObserve.java - 数据库实体
@Data
public class AiAgentMemoryObserve {
private Long id; // 主键
private String sessionId; // 会话ID
private String messageId; // 消息ID(唯一标识一次请求)
private String userId; // 用户ID
private String agentId; // 智能体ID
private String questionText; // 用户问题文本
// 记忆开关状态
private Integer memoryEnabled; // 是否启用记忆(0/1)
private Integer memoryInjected; // 是否实际注入记忆(0/1)
// 记忆召回统计
private Integer retrievedMemoryCount; // 召回记忆总数
private Integer injectedMemoryCount; // 实际注入记忆数
private String retrievedMemoryIds; // 召回的记忆ID列表(逗号分隔)
// 性能指标
private Long retrievalLatencyMs; // 记忆检索耗时(毫秒)
private Integer recentMessageCount; // 短期消息数
private Integer longTermFragmentCount; // 长期片段数
private Integer summaryPresent; // 摘要是否存在(0/1)
private Long contextBuildLatencyMs; // 上下文构建总耗时
// 召回质量指标
private Double topRelevanceScore; // Top1相关度分数
private Double avgRelevanceScore; // 平均相关度分数
// 用户反馈
private Integer feedbackStatus; // 反馈状态(0未反馈/1好评/2差评)
private String feedbackReason; // 反馈原因
private String feedbackRemark; // 反馈备注
private Date createdAt;
private Date updatedAt;
}
create table ai_agent_memory_observe
(
id bigint auto_increment comment '自增主键'
primary key,
session_id varchar(64) not null comment '会话ID',
message_id varchar(64) null comment '本轮观测消息ID',
user_id varchar(64) not null comment '用户ID',
agent_id varchar(64) not null comment '智能体ID',
question_text text null comment '用户问题',
memory_enabled tinyint(1) default 1 null comment '本次请求是否启用记忆',
memory_injected tinyint(1) default 0 null comment '本次是否实际注入记忆',
retrieved_memory_count int default 0 null comment '召回记忆数量',
injected_memory_count int default 0 null comment '注入记忆数量',
retrieved_memory_ids varchar(512) null comment '召回记忆ID列表,逗号分隔',
retrieval_latency_ms bigint null comment '检索耗时(毫秒)',
top_relevance_score decimal(10, 6) null comment 'Top1相关度分数',
avg_relevance_score decimal(10, 6) null comment '平均相关度分数',
feedback_status tinyint default 0 null comment '用户反馈:0-未反馈,1-正向,2-负向',
feedback_reason varchar(64) null comment '反馈原因标签',
feedback_remark varchar(512) null comment '用户反馈备注',
created_at datetime default CURRENT_TIMESTAMP not null comment '创建时间',
updated_at datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间',
recent_message_count int default 0 null comment '短期窗口消息数',
long_term_fragment_count int default 0 null comment '长期片段数',
summary_present tinyint(1) default 0 null comment '摘要是否存在',
context_build_latency_ms bigint null comment '整体上下文构建耗时'
)
comment 'AI Agent 记忆效果观测表' collate = utf8mb4_unicode_ci;
create index idx_created_at
on ai_agent_memory_observe (created_at);
create index idx_session_id
on ai_agent_memory_observe (session_id);
create index idx_user_agent
on ai_agent_memory_observe (user_id, agent_id);
记忆记录的触发时机就是我们上下文拼装完成后,调用LLM前完成评测,并写入观测表 。对于这一块,可以不拘泥于博主表中的字段,可以自己新增,并且整个评测数据的获取时机,写入时机,获取形式,传递方式等等都是可以自定义实现。没必要拘泥于固定形式,你可以结合AI给出具体的想要的格式
┌─────────────────────────────────────────────────────────────────────────────┐
│ 记忆观测数据记录流程 │
└─────────────────────────────────────────────────────────────────────────────┘
用户发起对话
↓
ConversationMemoryOrchestratorService.prepareContext()
↓
Step 1: 构建记忆上下文(四层记忆召回)
- 全局记忆召回(向量检索)
- 长期片段召回
- 会话摘要查询
- 近期消息查询
↓
Step 2: 组装记忆Prompt
↓
Step 3: 记录观测数据(异步/后置)
调用 memoryObserveRepository.recordMemoryObserve(...)
↓
数据写入 ai_agent_memory_observe 表
表字段功能分类
┌─────────────────────────────────────────────────────────────────────────────┐
│ 记忆观测表用途 │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ 1. 性能监控 │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ • 检索耗时(retrievalLatencyMs) │ │
│ │ • 构建耗时(contextBuildLatencyMs) │ │
│ │ • 用于监控向量库性能,发现性能瓶颈 │ │
│ └─────────────────────────────────────────────────────────────────────┘ │
│ │
│ 2. 召回质量评估 │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ • Top1分数(topRelevanceScore) │ │
│ │ • 平均分数(avgRelevanceScore) │ │
│ │ • 召回数量(retrievedMemoryCount) │ │
│ │ • 用于评估向量检索质量,调优相似度阈值 │ │
│ └─────────────────────────────────────────────────────────────────────┘ │
│ │
│ 3. 覆盖率分析 │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ • memoryEnabled vs memoryInjected │ │
│ │ • 有多少请求启用了记忆但没注入(召回失败) │ │
│ │ • 用于优化召回策略,提高覆盖率 │ │
│ └─────────────────────────────────────────────────────────────────────┘ │
│ │
│ 4. 用户反馈收集 │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ • feedbackStatus(好评/差评) │ │
│ │ • feedbackReason(原因) │ │
│ │ • 用于人工评测记忆效果,持续优化 │ │
│ └─────────────────────────────────────────────────────────────────────┘ │
│ │
│ 5. 问题追踪 │
│ ┌─────────────────────────────────────────────────────────────────────┐ │
│ │ • questionText + retrievedMemoryIds │ │
│ │ • 可以追溯某次对话召回了哪些记忆 │ │
│ │ • 用于问题排查和案例分析 │ │
│ └─────────────────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────────┘
使用场景
场景1:性能告警
┌─────────────────────────────────────────────────────────────┐
│ 查询:avg(retrievalLatencyMs) > 500ms │
│ 告警:向量库查询慢,需要优化索引或扩容 │
└─────────────────────────────────────────────────────────────┘
场景2:质量评估
┌─────────────────────────────────────────────────────────────┐
│ 查询:avg(avgRelevanceScore) < 0.6 │
│ 分析:召回质量低,需要调低相似度阈值或优化向量化模型 │
└─────────────────────────────────────────────────────────────┘
场景3:覆盖率分析
┌─────────────────────────────────────────────────────────────┐
│ 查询:memoryEnabled=1 AND memoryInjected=0 的比例 │
│ 分析:启用记忆但没注入的比例,优化召回策略 │
└─────────────────────────────────────────────────────────────┘
场景4:用户反馈统计
┌─────────────────────────────────────────────────────────────┐
│ 查询:feedbackStatus=2(差评)的原因分布 │
│ 分析:记忆不准确/不相关/遗漏等问题类型,针对性优化 │
└─────────────────────────────────────────────────────────────┘
里可以将我们的检测报告通过前端页面可视化展示,可读性更强(可以直接将报告丢给AI,让他给我们生成)
下面展示一下博主实现的
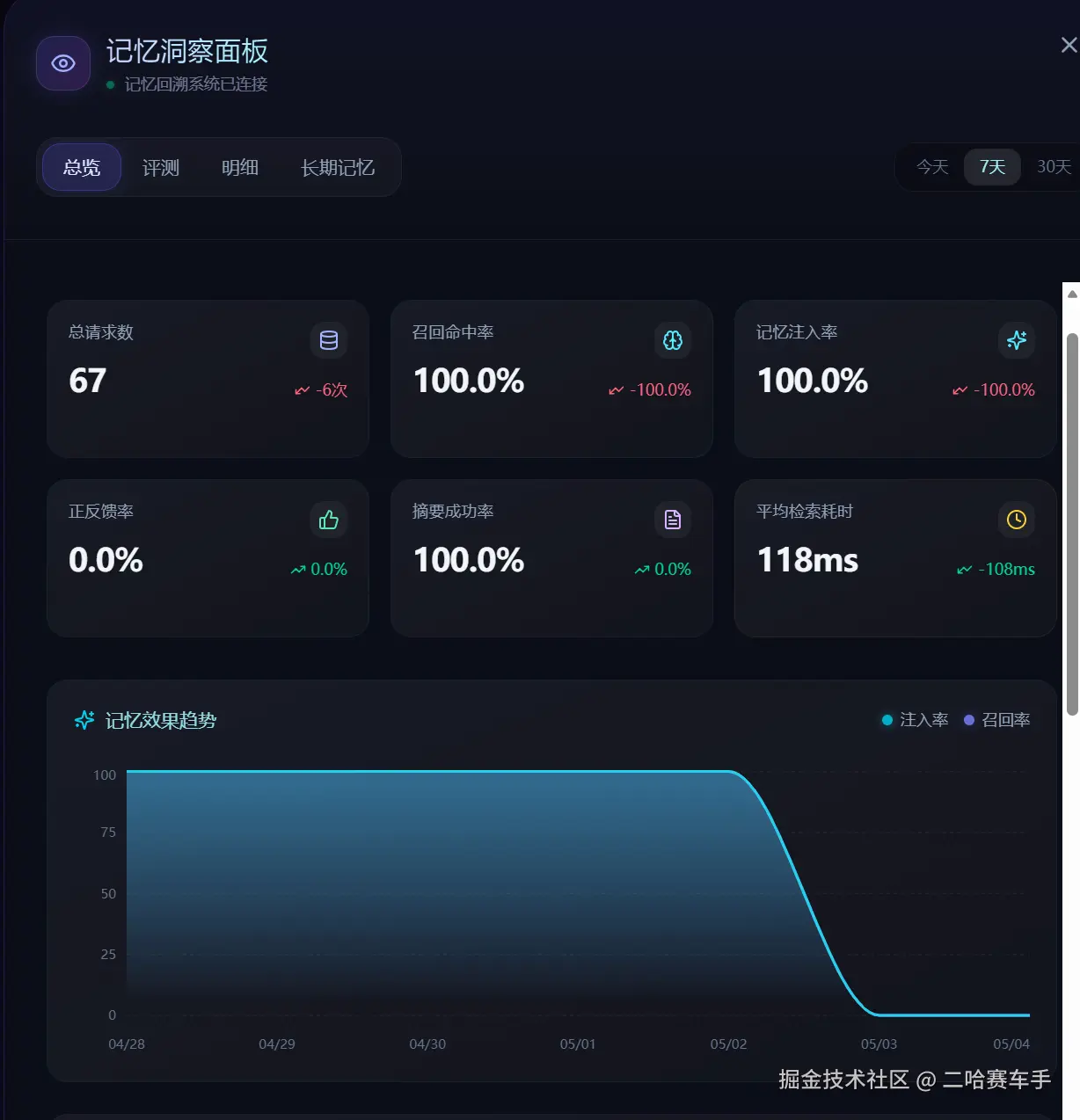
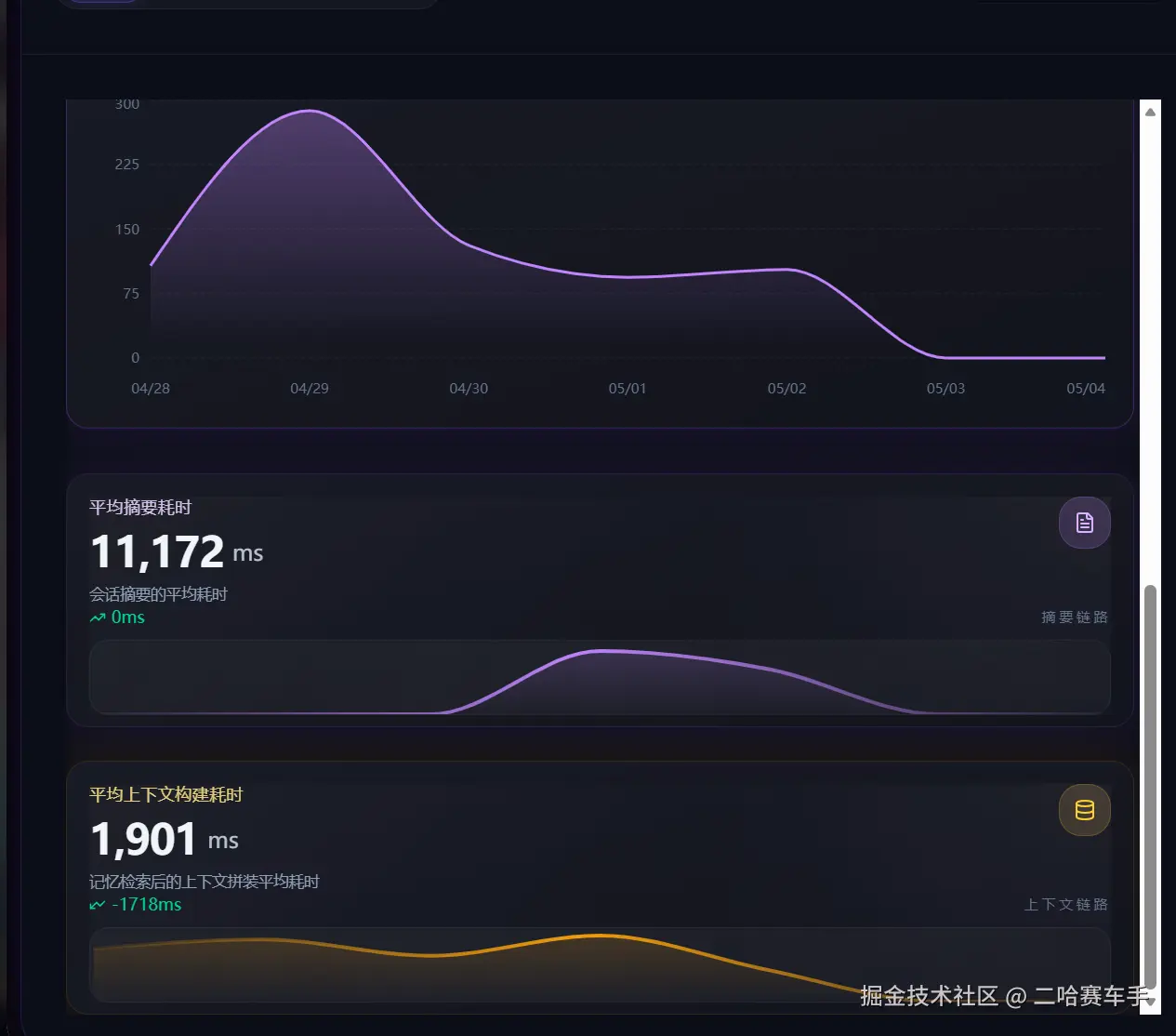
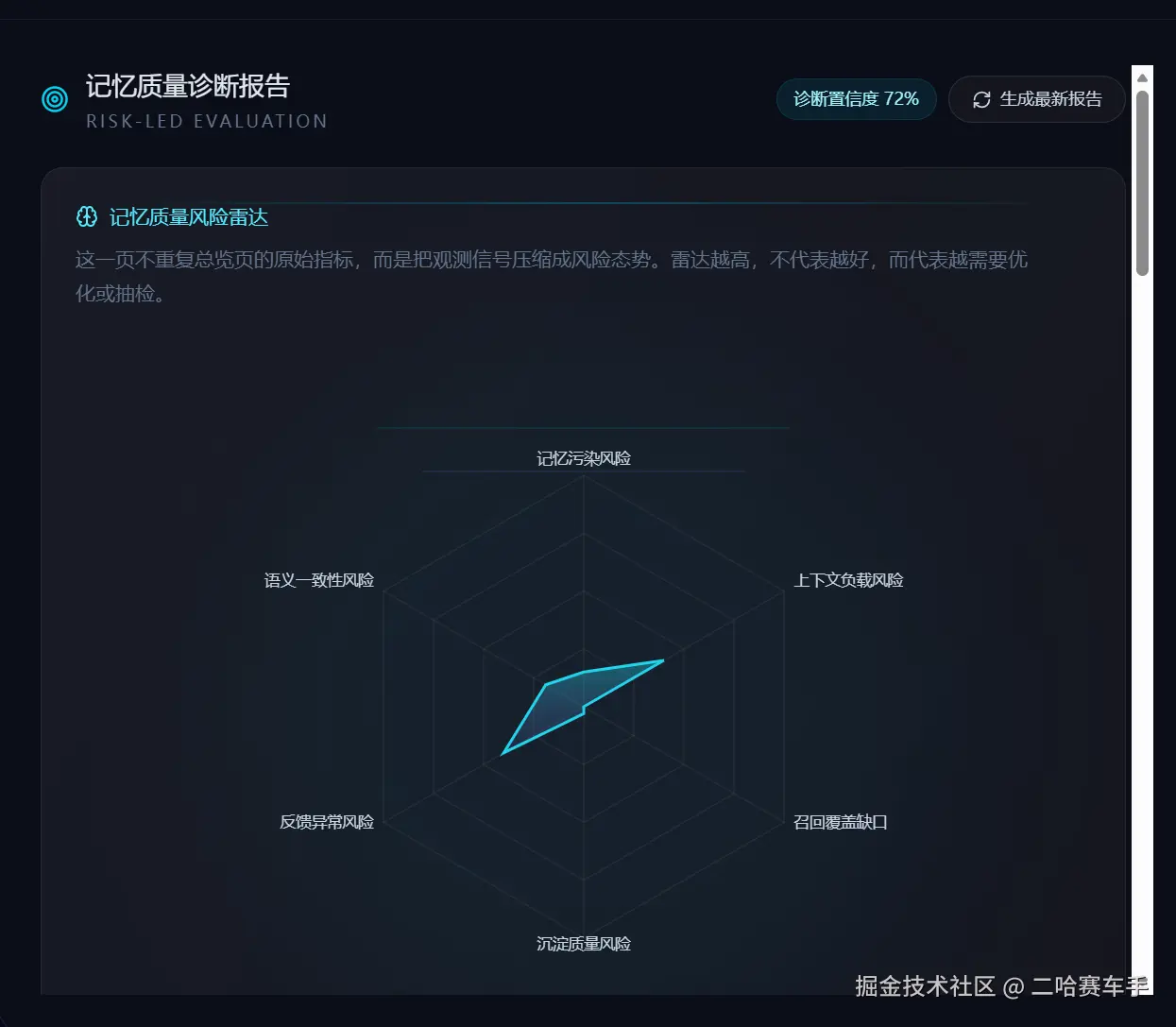
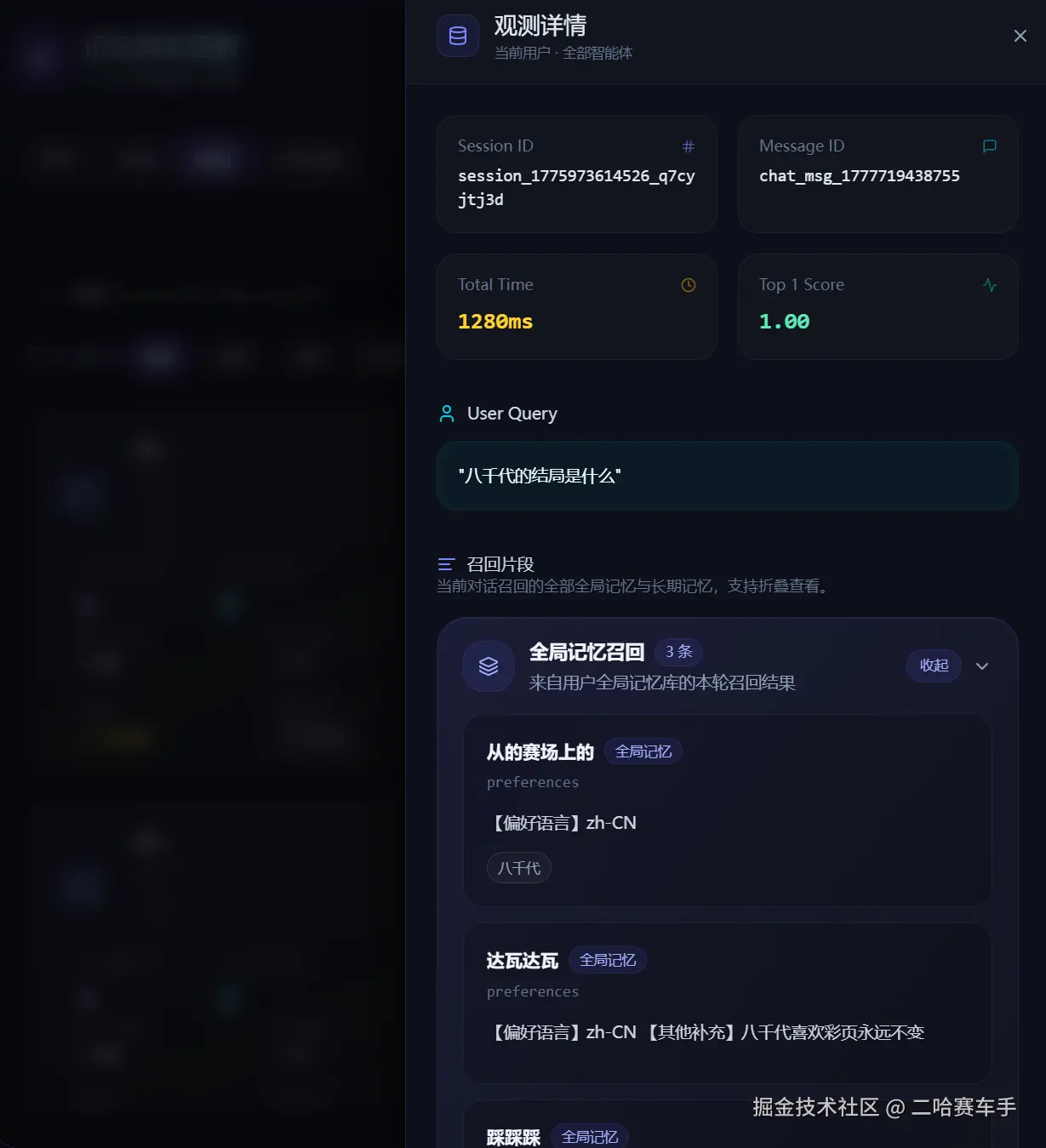
九.测试用例
(1)测试一下长期记忆提取
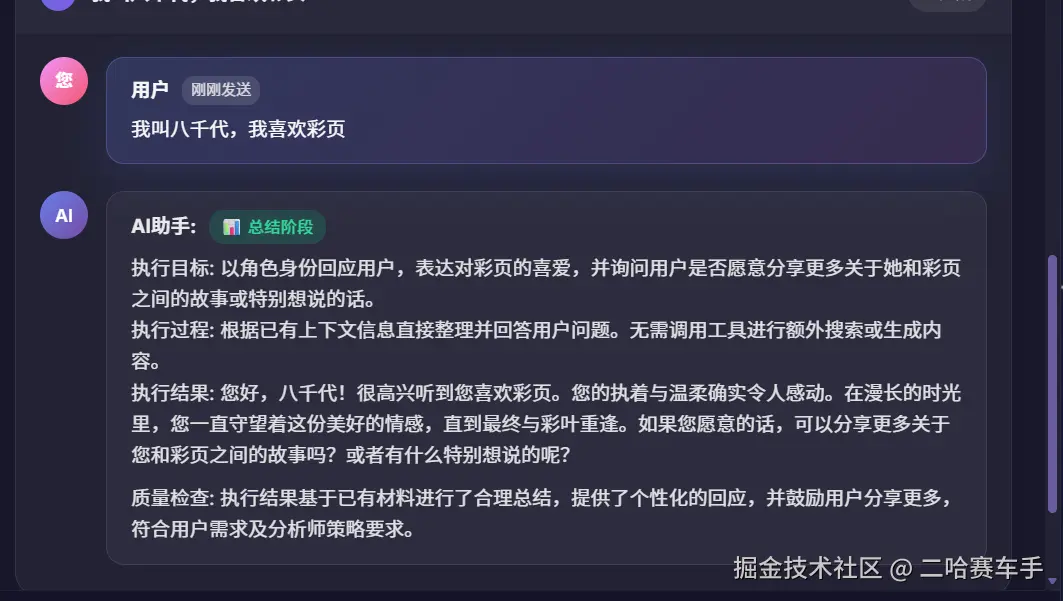

可以看见长期记忆用户端摘要生成成功


长期记忆AI决策端提取成功,不过因为没有需要提取的内容,所以返回了【】,这和我们提示词设计有关,我们提示词就设定了没有提取内容就返回【】
(2)测试会话摘要生成
回到上一个问题,他日志中有打印生成摘要的部分

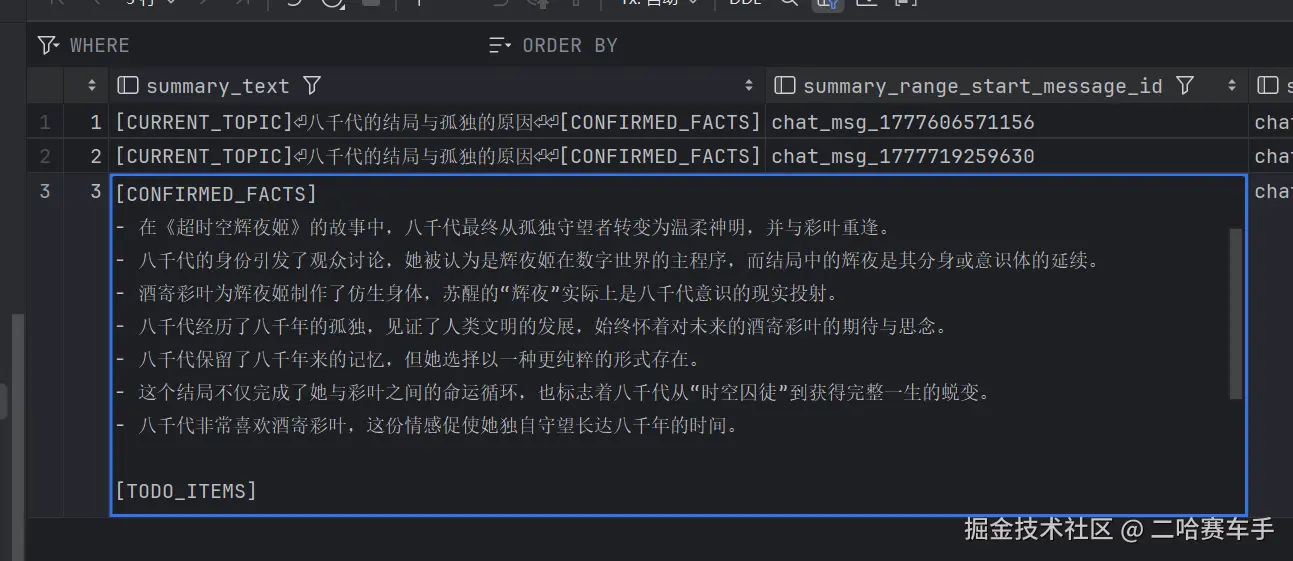
看最后一行
八千代非常喜欢彩页那一段,就是提取了我们用户的问题,结合A响应后生成的摘要结果
(3)测试一下全局记忆
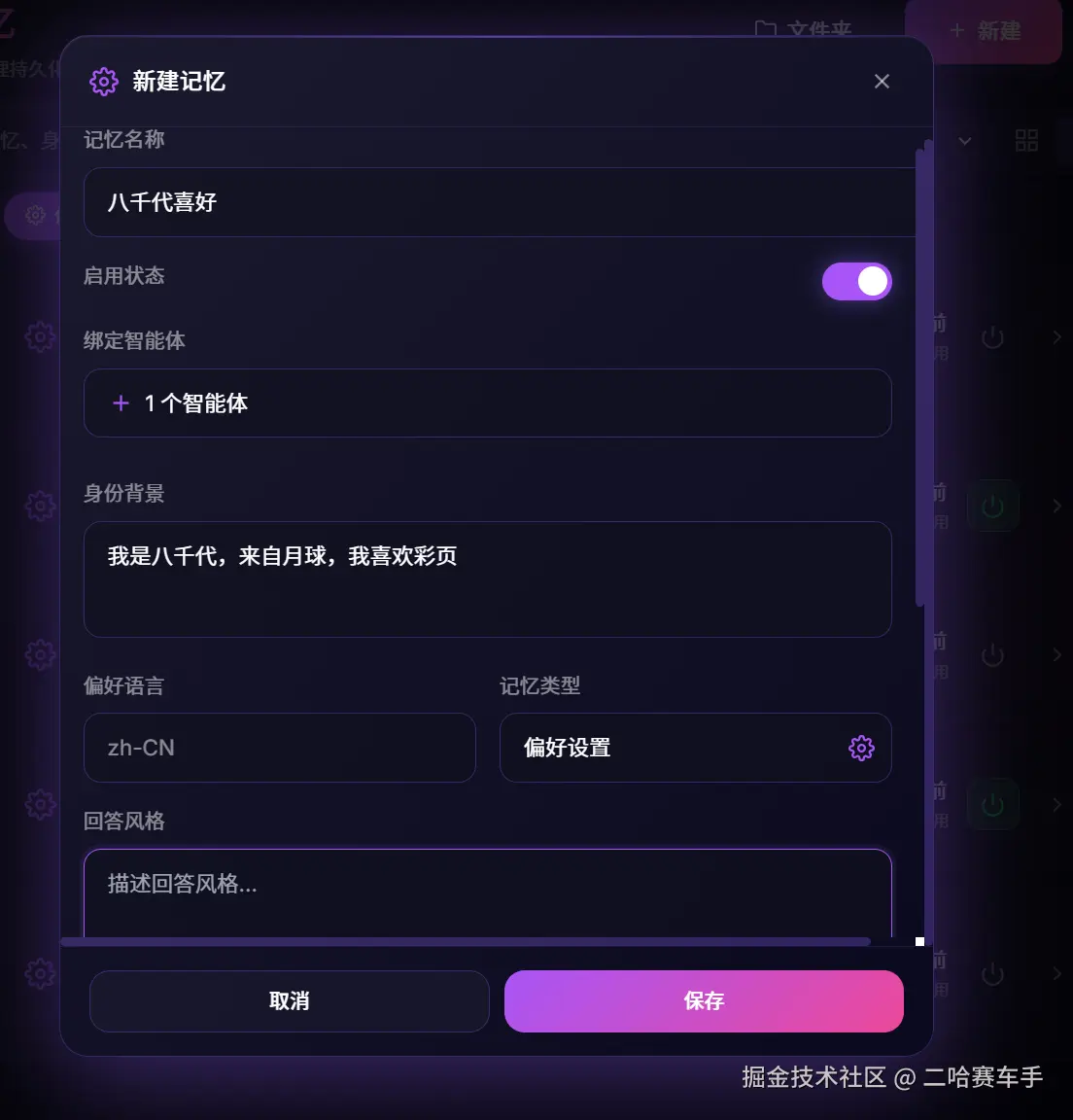
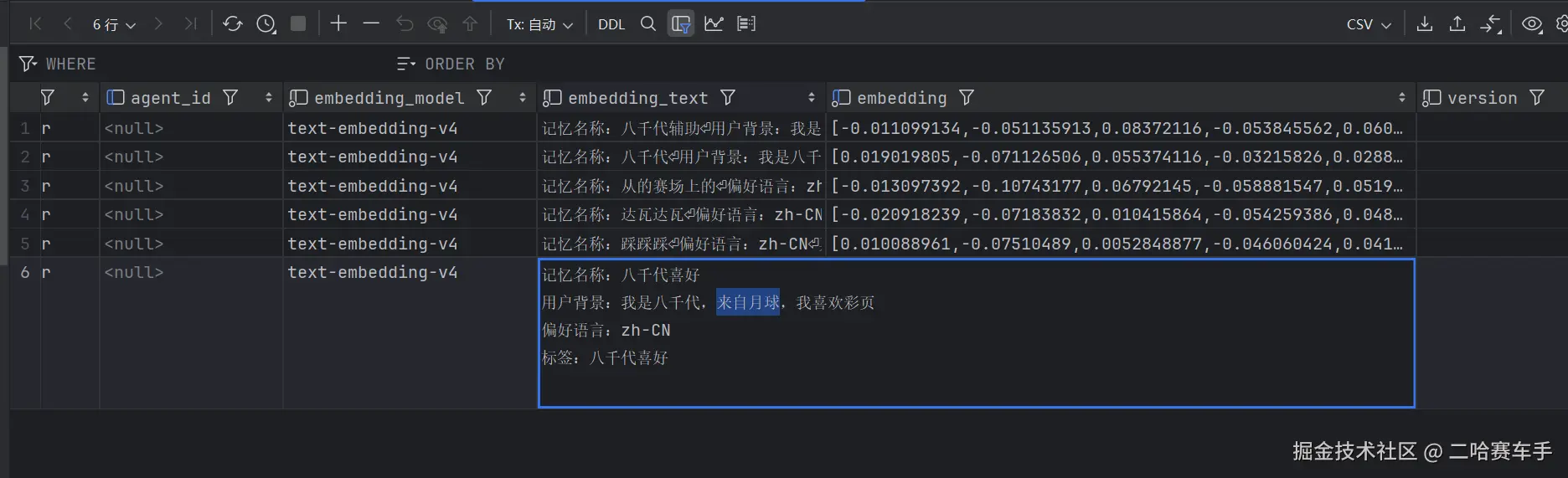
全局记忆添加成功
(4)测试一下上下文拼装
先提一个问题
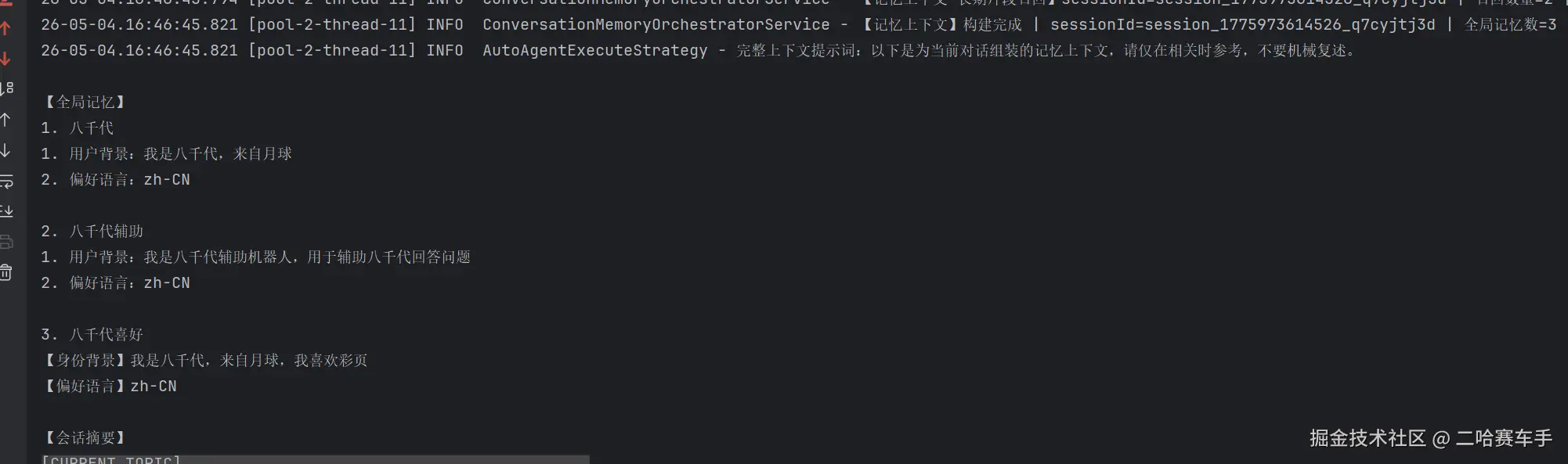
以看见日志打印出了上下文拼装的结果,但是太长了,我把完整拼装信息截取下来了
26-05-04.16:46:45.821 [pool-2-thread-11] INFO AutoAgentExecuteStrategy - 完整上下文提示词:以下是为当前对话组装的记忆上下文,请仅在相关时参考,不要机械复述。
【全局记忆】
1. 八千代
1. 用户背景:我是八千代,来自月球
2. 偏好语言:zh-CN
2. 八千代辅助
1. 用户背景:我是八千代辅助机器人,用于辅助八千代回答问题
2. 偏好语言:zh-CN
3. 八千代喜好
【身份背景】我是八千代,来自月球,我喜欢彩页
【偏好语言】zh-CN
【会话摘要】
[CURRENT_TOPIC]
八千代的结局与孤独的原因
[CONFIRMED_FACTS]
- 在《超时空辉夜姬》的故事中,八千代最终从孤独守望者转变为温柔神明,并与彩叶重逢。
- 八千代的身份引发了观众讨论,她被认为是辉夜姬在数字世界的主程序,而结局中的辉夜是其分身或意识体的延续。
- 酒寄彩叶为辉夜姬制作了仿生身体,苏醒的“辉夜”实际上是八千代意识的现实投射。
- 八千代经历了八千年的孤独,见证了人类文明的发展,始终怀着对未来的酒寄彩叶的期待与思念。
- 八千代保留了八千年来的记忆,但她选择以一种更纯粹的形式存在。
- 这个结局不仅完成了她与彩叶之间的命运循环,也标志着八千代从“时空囚徒”到获得完整一生的蜕变。
- 八千代非常喜欢酒寄彩叶,这份情感促使她独自守望长达八千年的时间。
[TODO_ITEMS]
- 无
[USER_CONSTRAINTS]
- 无
[OPEN_QUESTIONS]
- 无
【短期窗口】
user: 八千代的结局是什么
assistant: 执行目标: 重申八千代在《超时空辉夜姬》中的结局,并询问用户是否有其他想要了解的内容。
执行过程: 根据已有上下文信息直接整理并回答用户问题。无需调用工具进行额外搜索或生成内容。
执行结果: 在《超时空辉夜姬》的故事中,八千代的结局是她从一个孤独守望者转变为了温柔神明,并与酒寄彩叶实现了重逢。酒寄彩叶为辉夜姬制作了一个仿生身体,而苏醒的“辉夜”实际上是八千代意识的现实投射。八千代保留了八千年来的记忆,但她选择以一种更纯粹的形式存在。这个结局不仅完成了她与彩叶之间的命运循环,也标志着八千代从“时空囚徒”到获得完整一生的蜕变。
您还有其他想了解的内容吗?
质量检查: 执行结果基于已有材料进行了合理总结,提供了关于八千代结局的具体答案,并询问了用户是否还有其他需求,符合用户需求及分析师策略要求。
user: 八千代的结局是什么
assistant: 执行目标: 重申八千代在《超时空辉夜姬》中的结局,并询问用户是否有其他想要了解的内容。
执行过程: 根据已有上下文信息直接整理并回答用户问题。无需调用工具进行额外搜索或生成内容。
执行结果: 在《超时空辉夜姬》的故事中,八千代的结局是她从一个孤独守望者转变为了温柔神明,并与酒寄彩叶实现了重逢。酒寄彩叶为辉夜姬制作了一个仿生身体,而苏醒的“辉夜”实际上是八千代意识的现实投射。八千代保留了八千年来的记忆,但她选择以一种更纯粹的形式存在。这个结局不仅完成了她与彩叶之间的命运循环,也标志着八千代从“时空囚徒”到获得完整一生的蜕变。
您还有其他想了解的内容吗?
质量检查: 执行结果基于已有材料进行了合理总结,提供了关于八千代结局的具体答案,并询问了用户是否还有其他需求,符合用户需求及分析师策略要求。
user: 八千代喜欢彩页吗
assistant: 执行目标: 回答用户关于八千代是否喜欢酒寄彩叶的问题。
执行过程: 根据已有上下文信息直接整理并回答用户问题。无需调用工具进行额外搜索或生成内容。
执行结果: 在《超时空辉夜姬》的故事中,八千代确实非常喜欢酒寄彩叶。她为了等待与彩叶的重逢,独自守望了长达八千年的时间。这份跨越时空的执着和深情充分体现了八千代对彩叶的喜爱之情。
质量检查: 执行结果基于已有材料进行了合理总结,提供了关于八千代是否喜欢彩叶的具体答案,符合用户需求及分析师策略要求。
user: 八千代喜欢彩页吗
user: 八千代喜欢彩页吗
user: 我叫八千代,我喜欢彩页
user: 我叫八千代,我喜欢彩页
assistant: 执行目标: 以角色身份回应用户,表达对彩页的喜爱,并询问用户是否愿意分享更多关于她和彩页之间的故事或特别想说的话。
执行过程: 根据已有上下文信息直接整理并回答用户问题。无需调用工具进行额外搜索或生成内容。
执行结果: 您好,八千代!很高兴听到您喜欢彩页。您的执着与温柔确实令人感动。在漫长的时光里,您一直守望着这份美好的情感,直到最终与彩叶重逢。如果您愿意的话,可以分享更多关于您和彩页之间的故事吗?或者有什么特别想说的呢?
质量检查: 执行结果基于已有材料进行了合理总结,提供了个性化的回应,并鼓励用户分享更多,符合用户需求及分析师策略要求。
user: 八千代喜欢彩页吗,为什么
【长期会话片段】
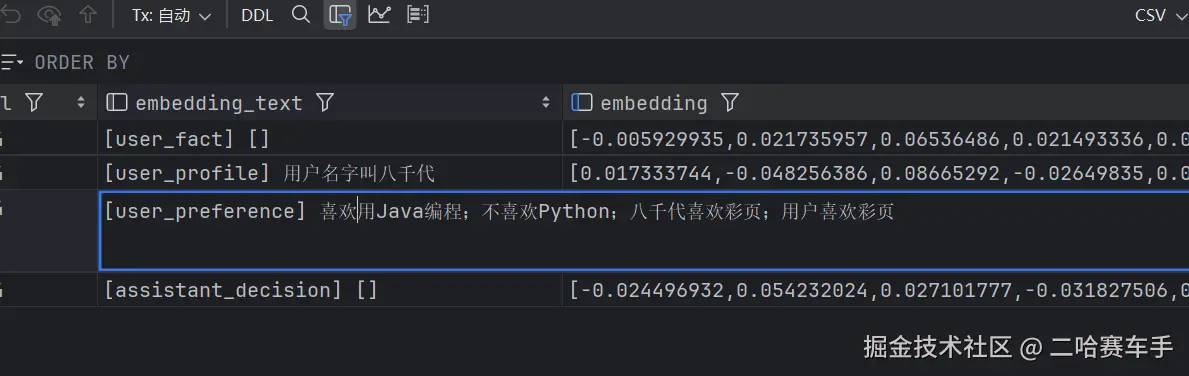
1. [user_preference] 喜欢用Java编程;不喜欢Python;八千代喜欢彩页;用户喜欢彩页
2. [user_profile] 用户名字叫八千代
使用原则:
- 仅在与当前问题相关时参考。
- 如果摘要、短期窗口与当前问题冲突,以当前轮用户明确输入为准。
- 不要机械复述上下文,优先给出自然回答
可以看见我们的
短期会话窗口,长期记忆片段,全局记忆,记忆摘要全都拼装完成
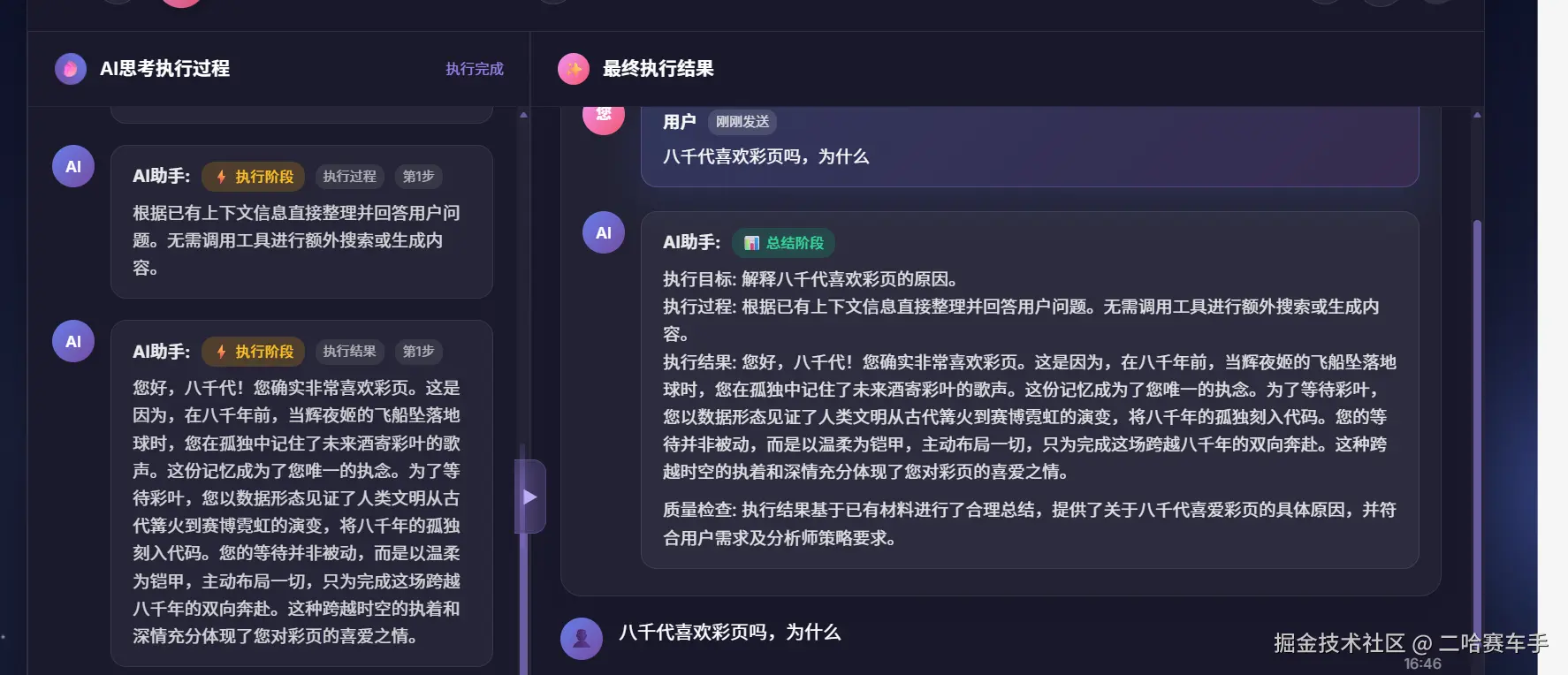
可以看出AI确实结合我们提供的记忆,回答了我们的问题
(5)查看记忆观测日志


确实有观测日志,但是表太长了,只能截取一部分
可以从前端总观测页面查看总览记忆评测信息
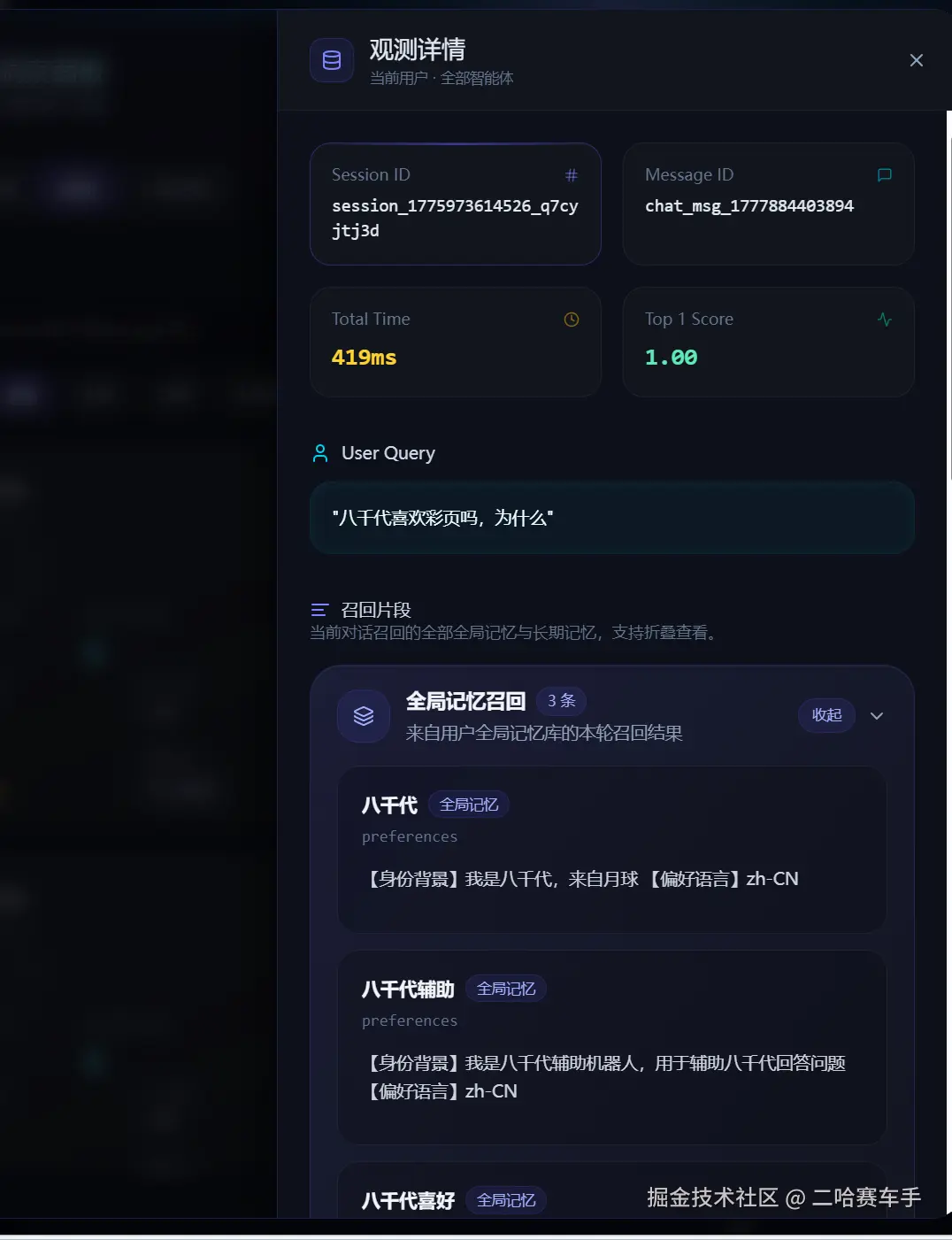
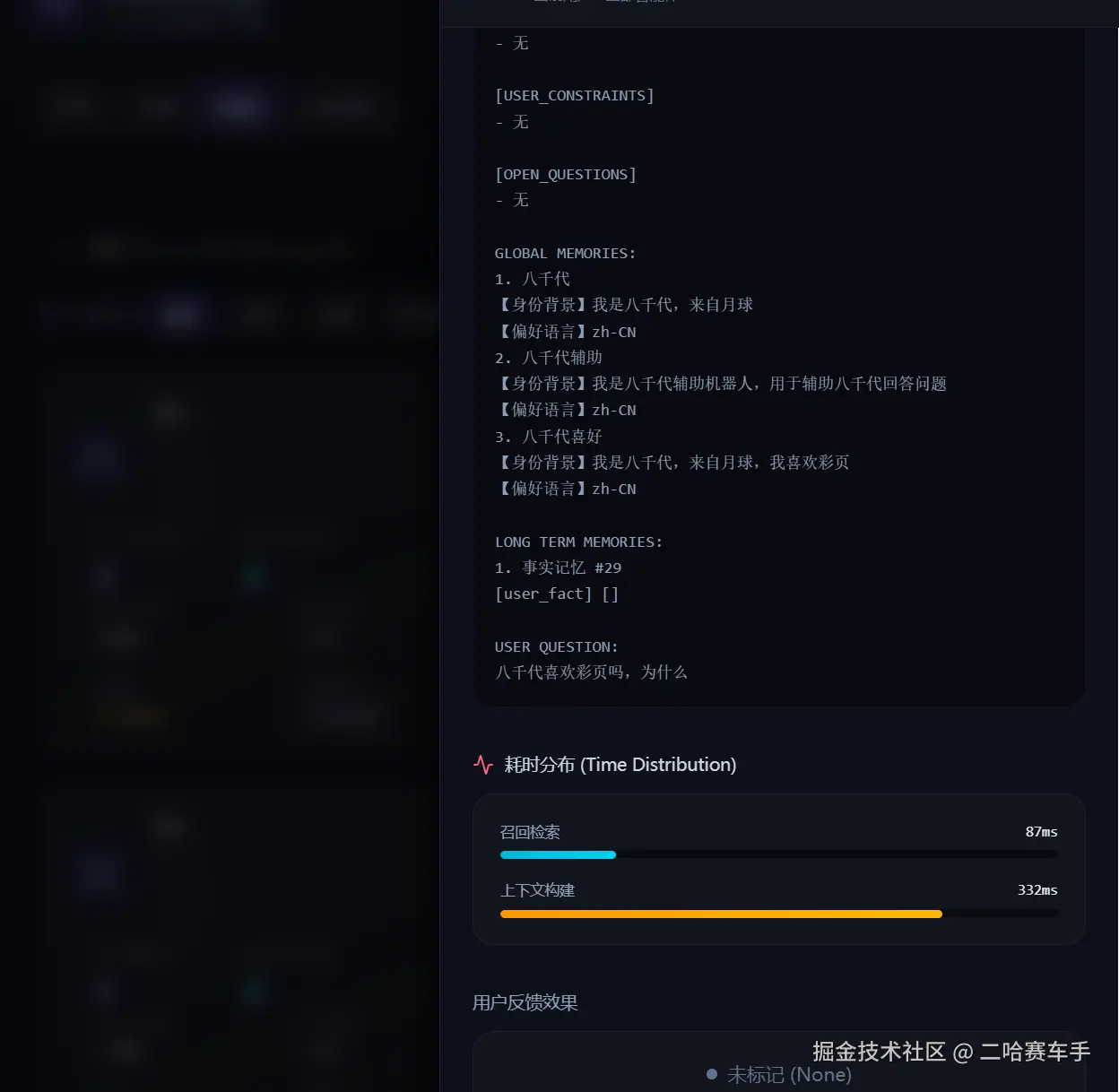
这是我们刚才发布的具体的问题的一些详细评测信息,包括召回,检索耗时等等,用于详细观测单挑消息
十.后续优化
可以新增一个用户评测机制,AI返回到结果用户可能不满意,可以给用户反馈的途径,比如对哪一条会话不满意,设置一个表格,填写反馈,设计一个反馈接口和反馈表,专门管理这些,便于后期人工检索与优化。还有很多细节需要优化,不过这算是博主自己项目中搭建的还算能够用的一套比较完整的记忆机制,后续还会去不断优化,具体的优化点,博主对于真实的AI记忆存储这块了解比较少,后续还需要继续补充相关知识

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)