
Agent Skill黄金三层结构与五步法打造指南:让AI帮你自动生成若依框架代码!
本文系统介绍了Agent Skill的设计原理与实现方法,提出黄金三层结构(元数据层、指令层、资源层)和五步法(定边界、显性化经验、工具与脚本、引入控制流、迭代与反馈)打造技能包。通过若依代码生成器改造案例,展示了如何将项目规范、代码模板打包成可复用Skill,让AI按预设规则自动生成符合规范的代码。文章强调渐进式披露原则,避免信息过载,并提供避坑指南,帮助开发者构建高效可复用的AI技能包,显著提
文章介绍Agent Skill的设计原理与实现方法,重点讲解黄金三层结构(元数据层、指令层、资源层)和五步法打造技能包(定边界、显性化经验、工具与脚本、引入控制流、迭代与反馈)。通过若依代码生成器改造案例,展示如何将项目规范、代码模板打包成可复用Skill,让AI按预设规则自动生成符合规范的代码,提升开发效率并减少重复工作。
读完这篇文章,你将学会:
✅ 什么是 Agent Skill
✅ 设计技能的黄金三层结构
✅ 五步法打造你的第一个技能包
✅ 实践拆解:将若依代码生成器改为Agent Skill
前几天有小伙伴在 [Antigravity 进阶指南: 3 种方式复刻 Kiro Spec 模式]那篇文章下留言,想要那个示例里的Spec模式 Skill 包。
我想了想,与其直接给大家丢一个 Skill 文件,不如和大家聊聊什么时候需要创建以及怎么创建Agent Skill。
在让 AI 帮我们生成Skill之前,我们需要先理解 Skill 的设计原理。 下面我将用开源项目ruoyi来举例说明。
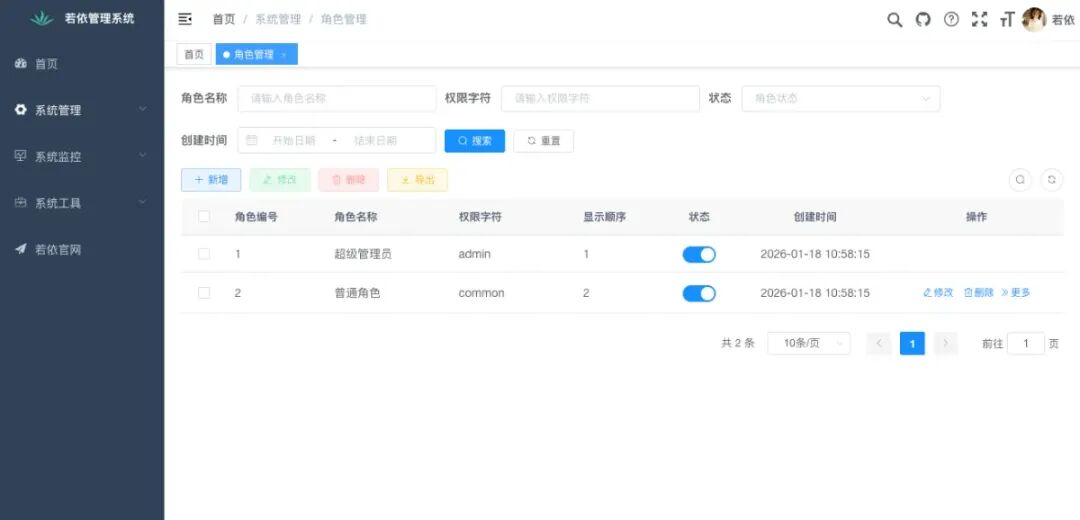
若依框架
用过若依框架的开发者都知道,若依自带一个代码生成器:
- 你在后台导入数据库表
- 配置生成选项(包名、模块名、前端类型等)
- 点击"生成代码",一键产出 Controller、Service、Mapper、Vue 页面
为什么能一键生成? 因为若依把代码规范、目录结构、模板文件(.vm)都预先定义好了。生成器只需要把表信息"填"进模板,就能输出符合规范的代码。
使用 Agent Skill 做代码生成器是完全一样的事——只不过执行者从"若依生成器"变成了"AI"。
你把规范文档、代码模板、执行步骤打包成一个 Skill,AI 读取后就变成了一个"懂若依规范的代码生成器"。
01 | 什么是 Agent Skill?
给 AI 的一份特定工作的"工作手册",包含步骤说明、代码模板和规范文档,让 AI 按你要求的方式干活
Prompt vs Skill:一次性指令 vs 可复用资产
简单来说:
- Prompt:一次性的对话指令,用完即弃
- Skill:可复用、版本化、包含执行逻辑的"能力扩展包"

什么时候需要设计 Skill?
问自己三个问题:
-
是否经常重复同样的解释?
→ 需要
-
任务是否需要特定模板或规范?
→ 需要
-
流程是否复杂,需要多步协同?
→ 需要
如果你在开发中反复告诉 AI"我们项目用什么框架、要遵守什么规范、生成什么格式",那你就应该把这些经验打包成一个 Skill。
02 | 设计架构:渐进式披露的三层结构
设计 Skill 有个核心原则:渐进式披露(Progressive Disclosure)。
什么意思?不要把所有信息一股脑塞给 AI。
AI 的上下文窗口是有限的,信息太多反而会让它"注意力分散"。正确的做法是:分层加载,按需读取。
📊 三层结构一览
┌─────────────────────────────────────────────────────┐
│ Level 1:元数据层 (始终可见) │
│ ├── name: 技能名称 │
│ └── description: 触发条件描述 │
├─────────────────────────────────────────────────────┤
│ Level 2:指令层 (激活时加载) │
│ └── SKILL.md 正文:工作流程、输入输出、约束条件 │
├─────────────────────────────────────────────────────┤
│ Level 3:资源层 (按需读取) │
│ ├── templates/:代码模板 │
│ ├── references/:规范文档 │
│ └── scripts/:可执行脚本 │
└─────────────────────────────────────────────────────┘
🔍 若依代码生成器Skill
我们来看一下这个Skill包的结构:
ruoyi-code-generator/
├── SKILL.md ← Level 1+2:元数据 + 指令
├── references/ ← Level 3:参考文档
│ ├── coding-standards.md (命名规范、类型映射)
│ └── examples.md (完整示例)
└── templates/ ← Level 3:代码模板
├── java/
│ ├── domain.java.vm
│ ├── controller.java.vm
│ └── ...
├── vue/
│ └── index.vue.vm
└── sql/
└── sql.vm
Skill包的结构
为什么这样设计?
- 当 AI 判断是否使用这个技能时,只需要读取
description(几行字) - 当技能被激活后,才加载
SKILL.md正文 - 当需要生成具体代码时,才读取
templates/目录下的模板
信息按需加载,效率最大化。
03 | 五步法打造你的第一个 Skill
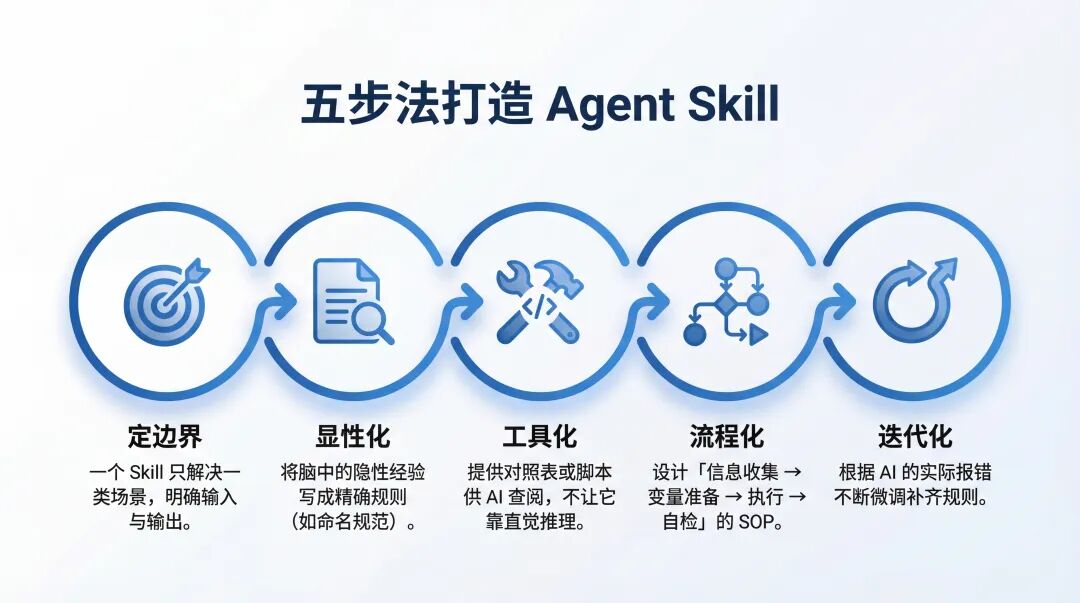
第一步:定边界
一个 Skill 只解决一类问题。
❌ 错误示范:“前端开发助手”(太宽泛)
✅ 正确示范:“若依框架 CRUD 代码生成器”(聚焦具体场景)
同时,明确定义输入和输出:
## 输入定义
- tableName: 数据库表名(必填)
- columns: 字段列表(必填)
- packageName: 包路径(选填,默认 com.ruoyi.system)
## 输出定义
- Java 后端代码(5 个文件)
- Vue 前端代码(2 个文件)
- SQL 脚本(1 个文件)
第二步:显性化经验
把你脑海中的隐性知识写成显性规则。
❌ 模糊描述:“代码风格要规范一点”
✅ 精确规则:
## 命名规范
- 类名使用大驼峰,表名去前缀:sys_user → SysUser
- 变量名使用小驼峰:userName, createTime
- 接口方法统一前缀:select/insert/update/delete
关键原则:自由度控制
| 任务类型 | 自由度 | 描述方式 |
|---|---|---|
| 创意类(写文案) | 高 | 给原则,让 AI 发挥 |
| 规范类(生成代码) | 低 | 给模板,让 AI 填空 |
代码生成属于低自由度任务,所以我们的技能里提供了完整的 .vm 模板文件,AI 只需要做变量替换,而不是"自由创作"。
第三步:工具与脚本
对于容易出错的步骤,不要让 AI 推理,给它脚本直接执行。
比如复杂的数据类型映射:
### 2.1 MySQL → Java 类型映射
bigint → Long
int/integer → Integer
smallint → Integer
tinyint → Integer
tinyint(1) → Boolean (自动识别布尔类型)
varchar/char → String
text/longtext → String
datetime → Date
timestamp → Date
date → Date
decimal/numeric → BigDecimal
float → Float
double → Double
blob → byte[]
references/coding-standards.md
把这些规则写成文档,AI 需要时直接查表,而不是靠"记忆"或"推理"。
第四步:引入控制流
在 Skill 中设计规划-执行-反思的流程:
## 执行流程
### 第一步:信息收集与验证
1. 解析用户请求,识别表名、字段信息
2. 缺省信息追问(如:主键是哪个字段?)
3. 推断默认值
### 第二步:变量准备
根据输入计算模板变量...
### 第三步:代码生成
按顺序读取并填充模板...
### 第四步:自检与交付
1. 检查生成的代码是否符合规范
2. 提供后续操作指引
SKILL.md
这就是 SOP(标准作业程序)的力量——把复杂任务拆解成可执行的步骤。
第五步:迭代与反馈
没有完美的 Skill,只有不断优化的 Skill。
观察 AI 在哪一步"出错"或"乱猜",然后把那个步骤的规则补充完善。
比如我们发现 AI 有时候会搞混 ClassName(大驼峰)和 className(小驼峰),于是在文档中加了这一段:
## 变量命名对照表
- ${ClassName} → 类名大驼峰(Product)
- ${className} → 类名小驼峰(product)
- ${BusinessName} → 业务名首字母大写(Product)
- ${businessName} → 业务名小写(product)
04 | 避坑指南:这四个错误别犯
❌ 错误 1:SKILL.md 写成"小作文"
技能正文控制在 500 行以内。太长说明你应该把内容拆分到 references/ 目录。
❌ 错误 2:description 太模糊
“处理文件” ← 这种描述,AI 完全不知道什么时候用。
要写成:“从 PDF 文件中提取文本并转换为 Markdown 格式”。
❌ 错误 3:给了脚本/模板但不说怎么用
在正文中明确告诉 AI:
生成实体类时,读取 templates/java/domain.java.vm 模板,
将 ${ClassName}、${columns} 等变量替换后输出。
❌ 错误 4:缺少示例
提供 1-2 个完整的输入输出示例(Few-shot),能大幅提升执行准确率。
我们在 references/examples.md 里放了完整的产品管理模块示例,AI 参考这个示例就能举一反三。
05 | 写在最后
设计 Agent Skill 本质上是一种思维方式的转变:
从"执行者"变成"管理者",从"自己干活"变成"写说明书让 AI 干活"。
这就像你从"一线员工"晋升为"部门经理"——你不再亲自写每一行代码,而是定义规范、设计流程、赋能团队。
AI 就是你的"数字员工",Skill 就是你给它的"培训手册"
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 25
25 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)