
LangChain多智能体系统详解:5种架构模式与实战案例实现
本文系统介绍了LangChain中的多智能体系统(MAS)技术,详细解析了Subagents、Handoffs、Skills、Router和Custom workflow五种实现模式及其特性。通过构建搜索智能体的实践案例,展示了基于LangGraph的工作流和基于LangChain的双智能体架构两种具体实现方案。研究指出,多智能体系统能有效突破单智能体能力边界,适用于复杂动态场景,但多数问题可通过
本文详细介绍了LangChain中的多智能体系统(MAS),包括其定义、五种实现模式及其核心特性。通过构建搜索智能体的实际案例,展示了基于LangGraph的工作流和基于LangChain的双智能体架构两种实现方式。多智能体系统通过群体智能突破单智能体能力边界,适合复杂动态场景,但多数问题可通过优化提示和工具调用解决。
多智能体系统(Multi-Agent System,MAS)是由多个具备感知、决策与行动能力的自主智能体,通过通信交互与协同机制,协作或竞争完成复杂任务的分布式 AI 系统,核心是用群体智能突破单智能体能力边界,适配大规模、多目标、强动态的场景。
一、LangChain中多智能体应用简介
根据LangChain 1.0官方文档介绍,多智能体主要是用来解决复杂的工作流,而且并不是每个复杂任务都需要通过多智能体来解决,很多复杂的任务其实可以正确使用提示词和工具来解决。
一般来说以下三种情况会用到多智能体技术:
- 上下文管理:当上下文过多时,在不占用模型上下文窗口过多资源的前提下,提供专业化知识。通过构建多个智能体获取更多的上下文知识。
- 分布式开发:支持不同团队独立开发和维护各项功能,并将其整合为一个边界清晰的大型系统。
- 并行化处理:为子任务分配专用的执行单元,通过并行执行提升任务处理效率。

官网将多智能体的实现方式分成了以下五种模式:
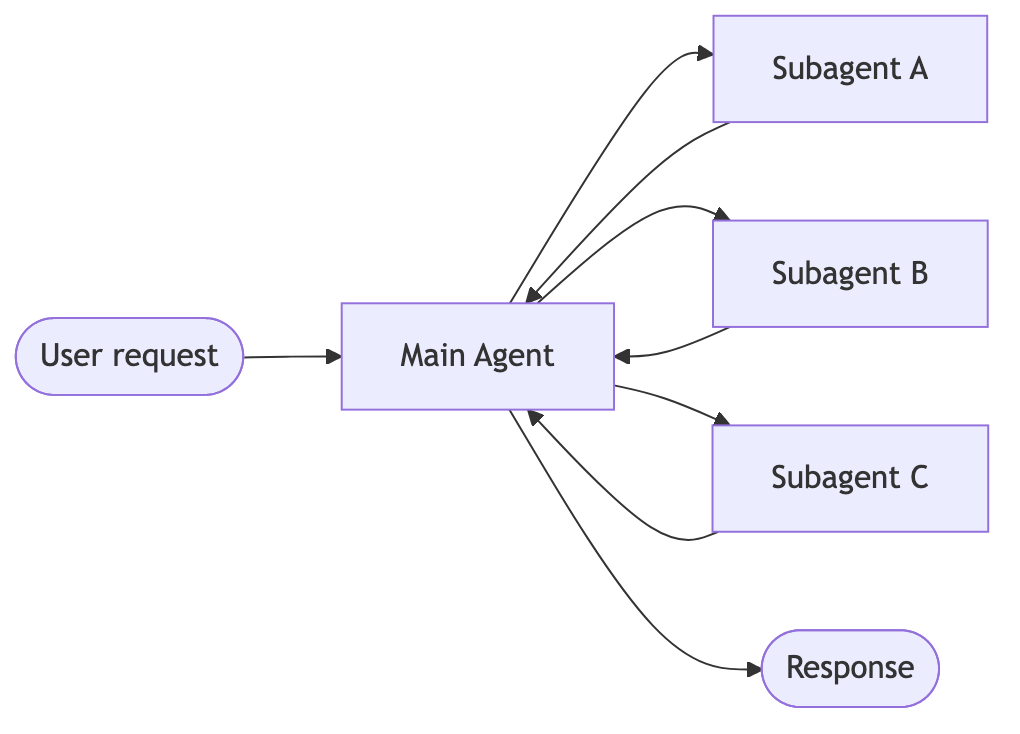
- Subagents:主智能体将子智能体作为工具进行协同调度,所有任务路由均由主智能体统一管控,由其决定调用各子智能体的时机与方式。
Subagents的关键特性有如下几点:
集中式控制:所有任务路由均由主智能体统一处理
无直接用户交互:子智能体将结果反馈至主智能体,而非直接对接用户(不过可在子智能体中设置中断机制,以支持用户交互)
工具化调用子智能体:子智能体通过工具实现调用
并行执行:主智能体可在单次交互轮次中调用多个子智能体
总体架构图:
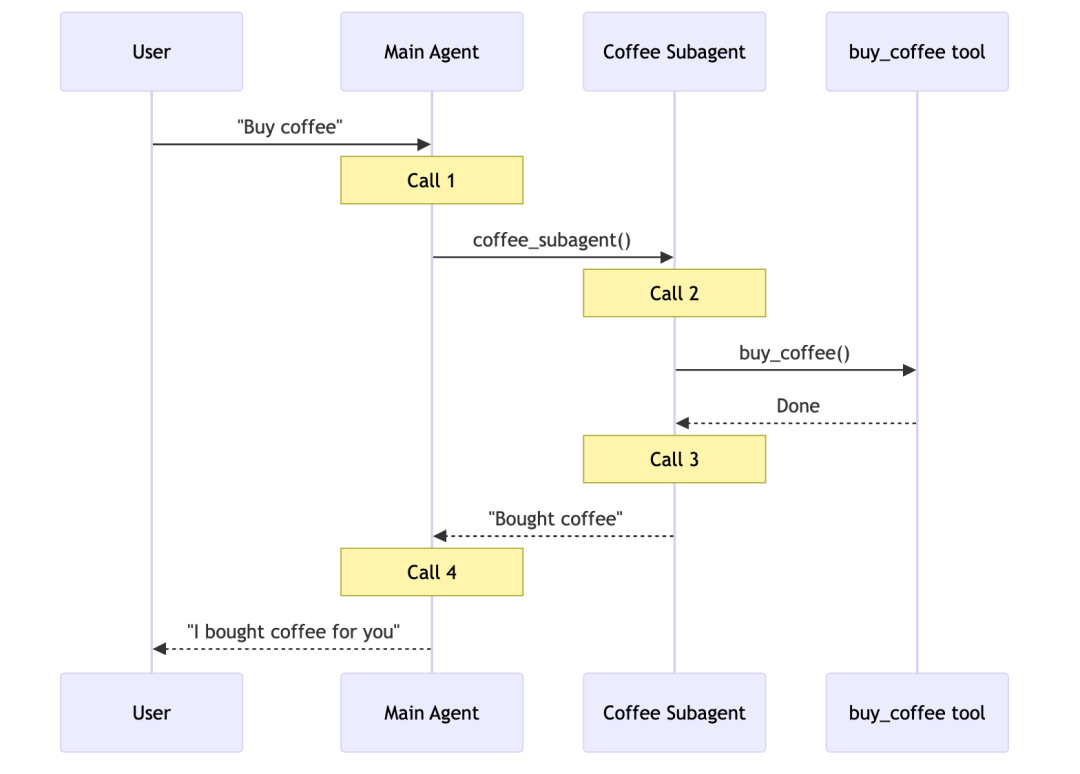
以购买咖啡为例,它的时序图如下:
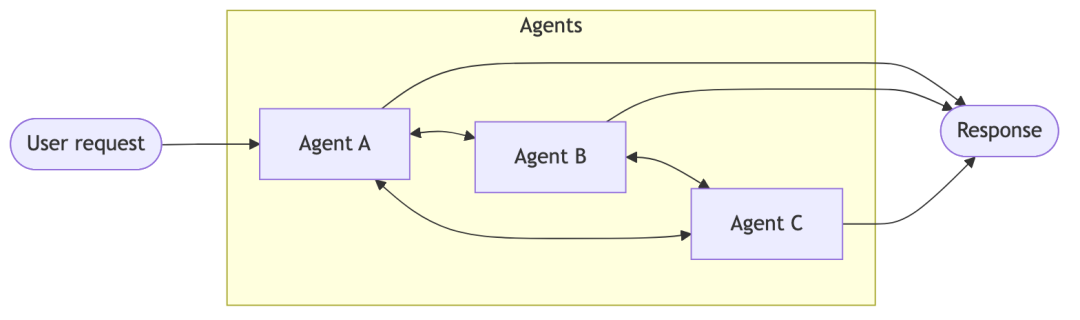
- Handoffs:行为根据系统状态动态调整。工具调用操作会更新一个状态变量,该变量触发任务路由或配置变更,进而完成智能体切换,或调整当前智能体的关联工具与提示词。智能体之间通过工具调用实现控制权移交。每个智能体既可以将控制权交接给其他智能体,也可以直接向用户反馈结果。在这种架构中,系统行为会基于状态动态调整。其核心机制为:工具调用会更新一个可跨交互轮次持久化的状态变量(例如current_step(当前步骤)或active_agent(活跃智能体)),系统读取该变量后对自身行为进行调整 —— 要么加载不同的配置信息(系统提示词、工具集),要么将任务路由至其他智能体。这种模式既支持不同智能体之间的任务交接,也可实现单个智能体内部的动态配置变更。
Handoffs的关键特性有以下几点:
状态驱动行为:行为基于状态变量进行调整
工具触发状态切换:通过工具调用更新状态变量,以实现不同状态间的流转
直接用户交互:各状态对应的配置可直接处理用户消息
状态持久化:状态可跨对话轮次保留
总体架构图:
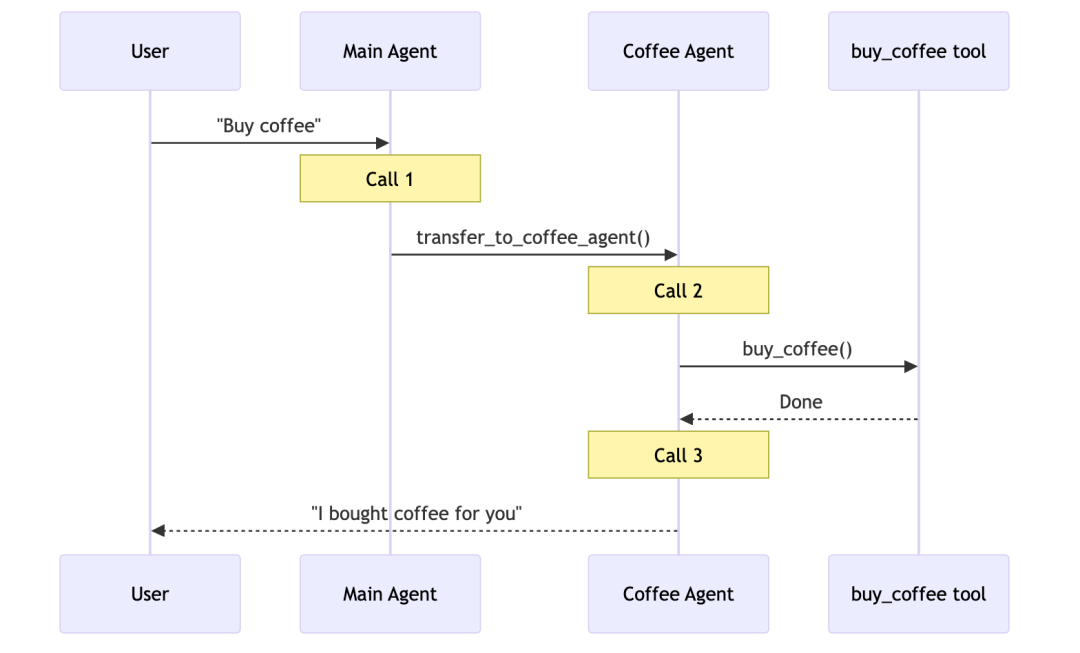
以购买咖啡为例,它的时序图如下:
- Skills:这种架构下,各类专用能力被封装为可调用的 “技能组件”,以此扩展智能体的行为边界。这类技能组件本质上是由提示词驱动的专用模块,可供智能体根据需求灵活调用。
Skills关键特性有以下几点:
提示词驱动:技能组件主要由专用提示词定义
渐进式能力:技能组件根据上下文信息或用户需求按需启用
分布式开发:不同团队可独立开展技能组件的开发与维护工作
轻量化组合:技能组件的复杂度低于完整的子智能体
总体架构图:
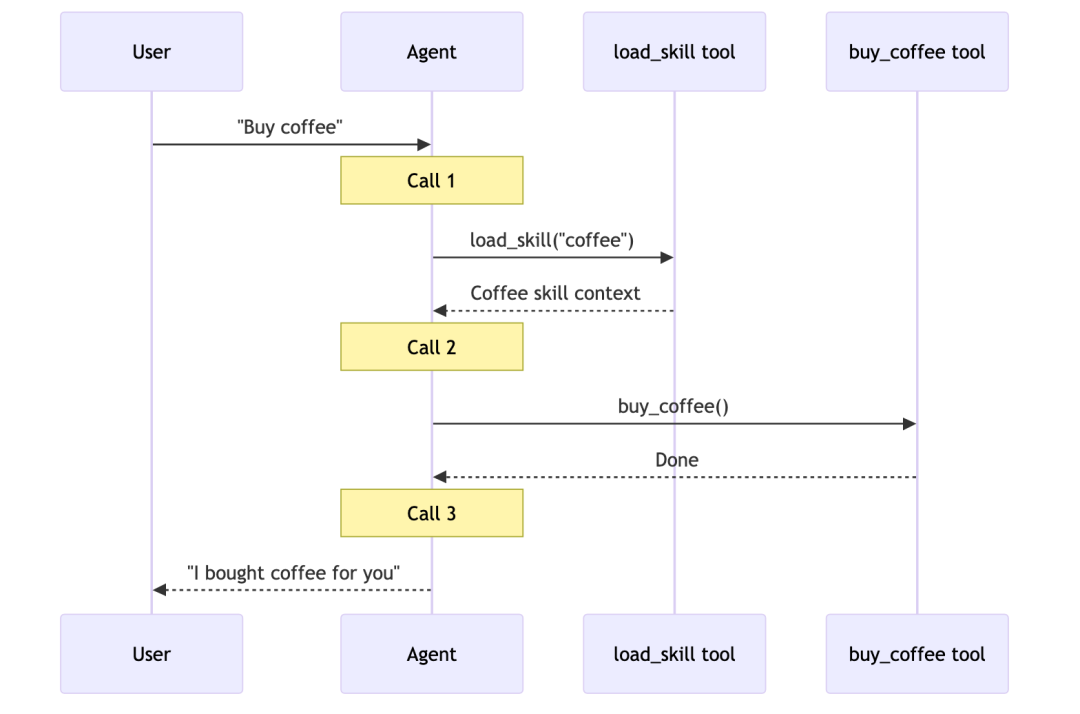
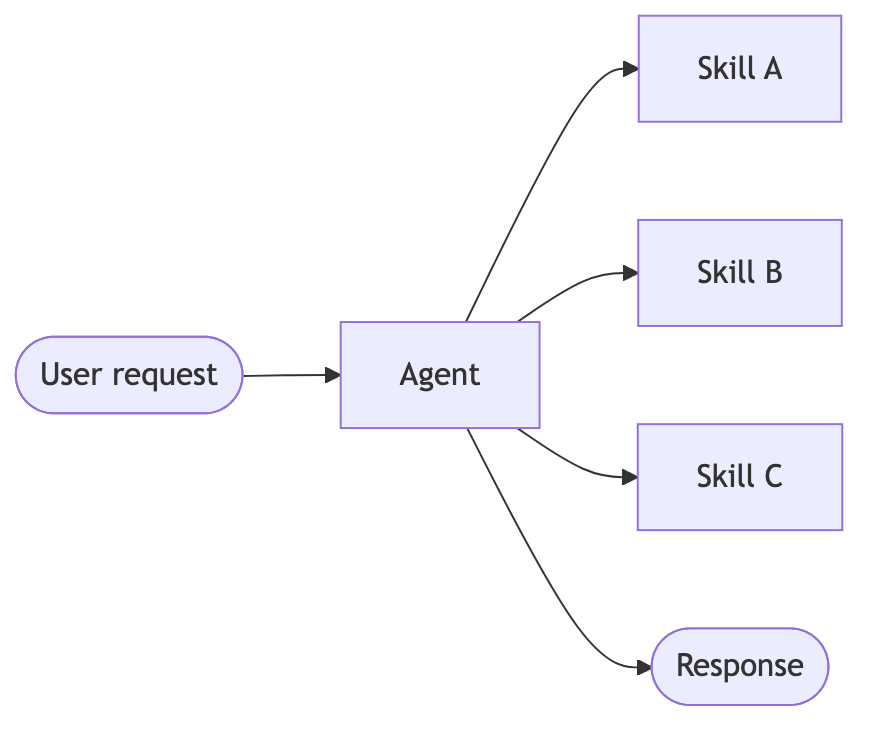 以购买咖啡为例,它的时序图如下:
以购买咖啡为例,它的时序图如下:
- Router:在Router架构下,系统会通过一个路由步骤对输入内容进行分类,并将其分发至对应的专用智能体,随后系统将各智能体返回的结果整合为一份合并后的响应内容。这种架构在处理垂直领域场景时尤为实用 —— 即当存在多个相互独立的知识域,且每个知识域都需要配备专属智能体的情况。
Router的关键特性如下:
-
路由模块对查询请求进行拆解
-
并行调用零个或多个专用智能体
-
将结果整合为连贯一致的响应内容
总体架构图:
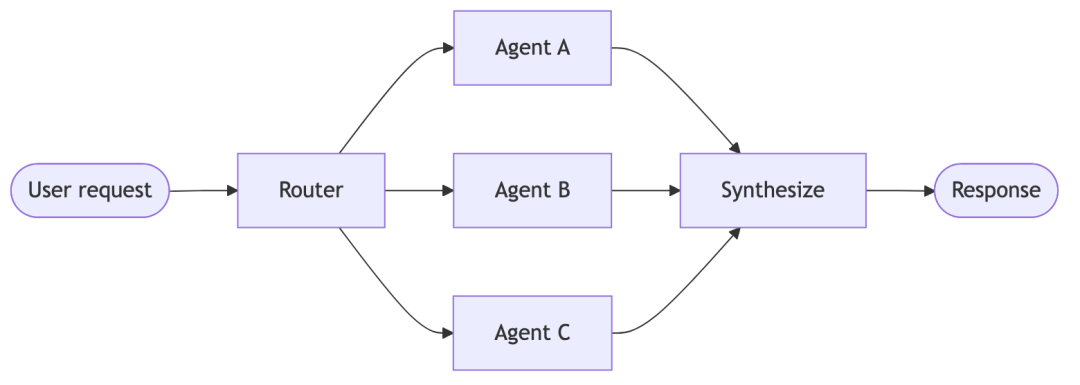
以购买咖啡为例,它的时序图如下:
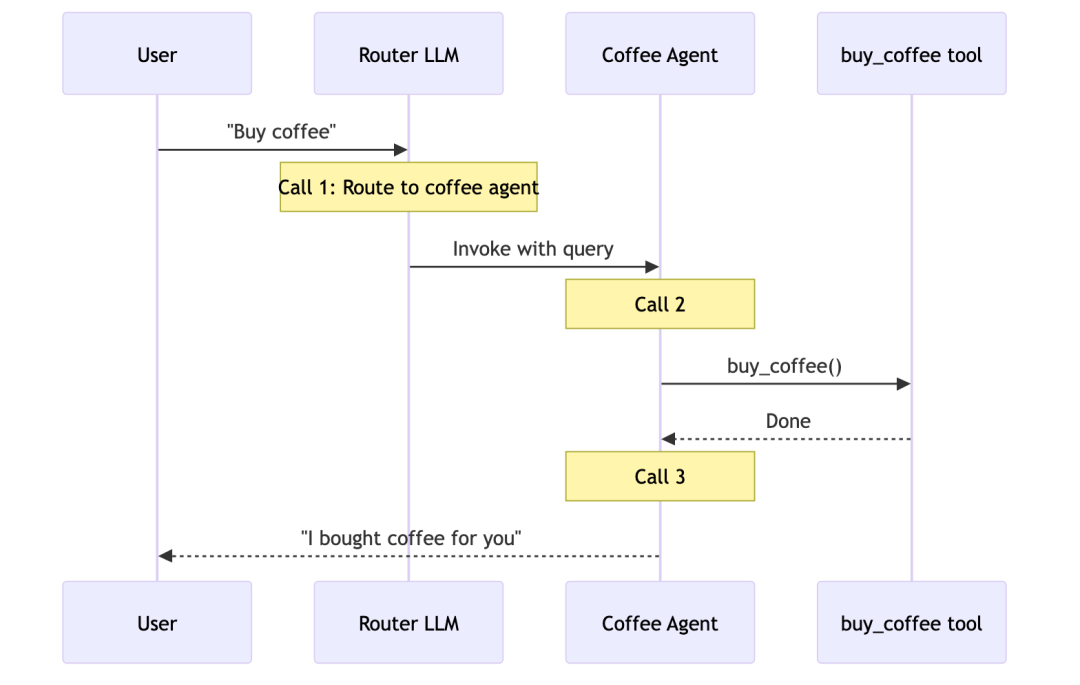
- Custom workflow:这个模式其实就是借助 LangGraph 构建定制化执行流程,能够对图结构实现完全掌控,包括其中的顺序执行步骤、条件分支、循环逻辑以及并行执行机制。
这是完全可以自定义的模式。它的关键特性如下:
- 完全掌控图结构
- 融合确定性逻辑与智能体自主行为
- 支持顺序执行步骤、条件分支、循环逻辑及并行执行机制
- 可以将其他架构模式嵌入工作流,作为流程节点使用
二、多智能体实际应用
现在我希望构建一个搜索智能体,根据用户的搜索信息,确定用户的意图,提取出关键词,然后使用web搜索工具根据关键词搜索,获取信息,最后根据获取的信息组织成符合人类阅读习惯的结果返回给用户。
根据上面的LangChain多智能体的构建方案,我选择了两种方式来实现我的需求。
方式一:基于LangGraph打造工作流,实现关键词获取,搜索和结果反馈几个节点。
方式二:基于LangChain实现两个智能体,一个智能体负责从用户查询中提取关键词,并封装成工具,web搜索也封装成工具,另一个智能体调用着两个工具,实现搜索信息的反馈。
web搜索采用tavily来实现。tavily 是专为 LLM 与 AI 智能体设计的企业级网络数据访问平台,核心提供搜索、提取、抓取等 API,能高效获取实时结构化信息并降低大模型幻觉。
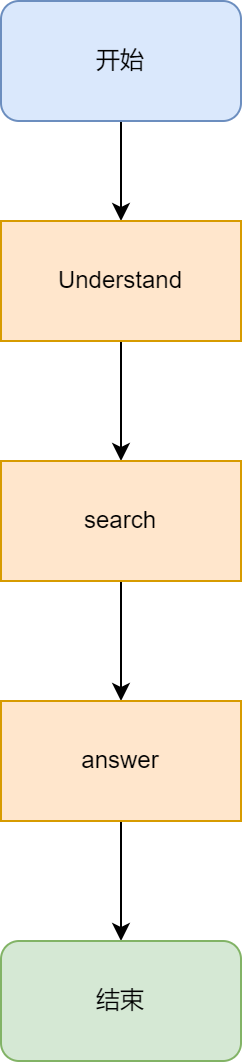
首先是方式一。在方式一中,本质上就是基于LangGraph构建workflow,流程图如下:
首先定义一个状态结构,用于保存工作流中执行的数据和状态。同时初始化大模型和tavily客户端。
# 初始化Tavily客户端
tavily_client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
# 定义状态结构
class SearchState(TypedDict):
messages: Annotated[list, add_messages]
user_query: str # 用户查询
search_query: str # 优化后的搜索查询
search_results: str # Tavily搜索结果
final_answer: str # 最终答案
step: str # 当前步骤
# 初始化模型和Tavily客户端
llm = ChatOpenAI(
model=os.getenv("LLM_MODEL_ID", "gpt-4o-mini"),
api_key=os.getenv("LLM_API_KEY"),
base_url=os.getenv("LLM_BASE_URL", "https://api.openai.com/v1"),
temperature=0.7
)
然后基于LangGraph构建一个工作流,其中提示词的设计非常重要。
def understand_query_node(state: SearchState) -> SearchState:
"""步骤1:理解用户查询并生成搜索关键词"""
# 获取最新的用户消息
user_message = ""
for msg in reversed(state["messages"]):
if isinstance(msg, HumanMessage):
user_message = msg.content
break
understand_prompt = f"""分析用户的查询:"{user_message}"
请完成两个任务:
1. 简洁总结用户想要了解什么
2. 生成最适合搜索的关键词(中英文均可,要精准)
格式:
理解:[用户需求总结]
搜索词:[最佳搜索关键词]"""
response = llm.invoke([SystemMessage(content=understand_prompt)])
# 提取搜索关键词
response_text = response.content
search_query = user_message # 默认使用原始查询
if "搜索词:" in response_text:
search_query = response_text.split("搜索词:")[1].strip()
elif "搜索关键词:" in response_text:
search_query = response_text.split("搜索关键词:")[1].strip()
return {
"user_query": response.content,
"search_query": search_query,
"step": "understood",
"messages": [AIMessage(content=f"我理解您的需求:{response.content}")]
}
def tavily_search_node(state: SearchState) -> SearchState:
"""步骤2:使用Tavily API进行真实搜索"""
search_query = state["search_query"]
try:
print(f"🔍 正在搜索:{search_query}")
response = tavily_client.search(
query = search_query,
search_depth = "basic",
include_answer = True,
include_raw_content = False,
max_results = 5
)
# 处理搜索结果
search_results = ""
# 优先使用Tavily的综合答案
if response.get("answer"):
search_results = f"综合答案:\n{response['answer']}\n\n"
# 添加具体的搜索结果
if response.get("results"):
search_results += "相关信息:\n"
for i, result in enumerate(response["results"][:3], 1):
title = result.get("title", "")
content = result.get("content", "")
url = result.get("url", "")
search_results += f"{i}. {title}\n{content}\n来源:{url}\n\n"
if not search_results:
search_results = "抱歉,没有找到相关的信息。"
return {
"search_results": search_results,
"step": "searched",
"messages": [AIMessage(content=f"✅ 搜索完成!找到了相关信息,正在为您整理答案...")]
}
except Exception as e:
error_msg = f"搜索时发生错误:{str(e)}"
print(f"❌ {error_msg}")
return {
"search_results": error_msg,
"step": "search_failed",
"messages": [AIMessage(content=f"❌ 搜索遇到问题,我将基于已有知识为您回答")]
}
def generate_answer_node(state: SearchState) -> SearchState:
"""步骤3:基于搜索结果生成最终答案"""
# 检查是否有搜索结果
if state["step"] == "search_failed":
# 如果搜索失败,基于LLM知识问答
fallback_prompt = f"""搜索API暂时不可用,请基于您的知识回答用户的问题:
用户问题:{state["user_query"]}
请提供一个有用的回答,并说明这是基于已有知识的回答。"""
response = llm.invoke([SystemMessage(content=fallback_prompt)])
return {
"final_answer": response.content,
"step": "completed",
"messages": [AIMessage(content=response.content)]
}
# 基于搜索结果生成答案
answer_prompt = f"""基于以下的搜索结果为用户提供完整、准确的答案:
用户问题:{state["user_query"]}
搜索结果:
{state["search_results"]}
请要求:
1. 综合搜索结果,提供准确、有用的回答
2. 如果是技术问题,提供具体的解决方案或代码
3. 引用重要信息的来源
4. 回答要结构清晰、易于理解
5. 如果搜索结果不够完整,请说明并提供补充建议
"""
response = llm.invoke([SystemMessage(content=answer_prompt)])
return {
"final_answer": response.content,
"step": "completed",
"messages": [AIMessage(content=response.content)]
}
# 构建搜索工作流
def create_search_assistant():
workflow = StateGraph(SearchState)
# 添加三个节点
workflow.add_node("understand", understand_query_node)
workflow.add_node("search", tavily_search_node)
workflow.add_node("answer", generate_answer_node)
# 设置线性流程
workflow.add_edge(START, "understand")
workflow.add_edge("understand", "search")
workflow.add_edge("search", "answer")
workflow.add_edge("answer", END)
# 编译图
memory = InMemorySaver()
app = workflow.compile(checkpointer=memory)
return app
最后将工作流的访问包装成fast api接口,供前端调用,注意这里的流式输出需要通过Generator封装成StreamingResponse:
"""
通过 fast-api 封装成web接口
"""
app = FastAPI()
# 配置CORS
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许所有来源,生产环境应限制为具体域名
allow_credentials=True,
allow_methods=["*"], # 允许所有方法
allow_headers=["*"], # 允许所有头
)
@app.get("/stream_search", summary="流式获取大模型回答")
async def stream_search(query:str) -> StreamingResponse:
"""
接收主题和问题,返回大模型的流式回答
"""
# 定义生成器函数,逐块获取 LangChain 的输出
def generate() -> Generator[str, None, None]:
# 初始状态
inital_state = {
"messages": [HumanMessage(content=query)],
"user_query": "",
"search_query": "",
"search_results": "",
"final_answer": "",
"step": "start"
}
config = {"configurable": {"thread_id": f"search-session-1"}}
search_app = create_search_assistant()
try:
print("\n" + "=" * 60)
chunk_size = 4
import time
# 执行工作流
for output in search_app.stream(inital_state, config=config):
print(output)
for node_name, node_output in output.items():
if "messages" in node_output and node_output["messages"]:
lastest_message = node_output["messages"][-1]
if isinstance(lastest_message, AIMessage):
if node_name == "understand":
print(f"🧠 理解阶段:{lastest_message.content}")
content = f"🧠 理解阶段:{lastest_message.content}\n"
for i in range(0, len(content), chunk_size):
chunk = content[i:i+chunk_size]
print(chunk, end="", flush=True)
time.sleep(0.1)
yield chunk
elif node_name == "search":
print(f"🔍 搜索阶段:{lastest_message.content}")
content = f"🔍 搜索阶段:{lastest_message.content}\n"
for i in range(0, len(content), chunk_size):
chunk = content[i:i+chunk_size]
print(chunk, end="", flush=True)
time.sleep(0.1)
yield chunk
elif node_name == "answer":
print(f"\n💡 最终回答:\n{lastest_message.content}")
content = f"\n💡 最终回答:\n{lastest_message.content}\n"
for i in range(0, len(content), chunk_size):
chunk = content[i:i+chunk_size]
print(chunk, end="", flush=True)
time.sleep(0.1)
yield chunk
print("\n" + "="*60 + "\n")
except Exception as e:
print(f"❌ 发生错误:{e}")
print(f"Error occurred: {str(e)}")
yield f"data: Error occurred: {str(e)}"
# 返回 StreamingResponse,指定媒体类型为 text/event-stream(适合 SSE)
return StreamingResponse(
generate(),
media_type="text/event-stream"
)
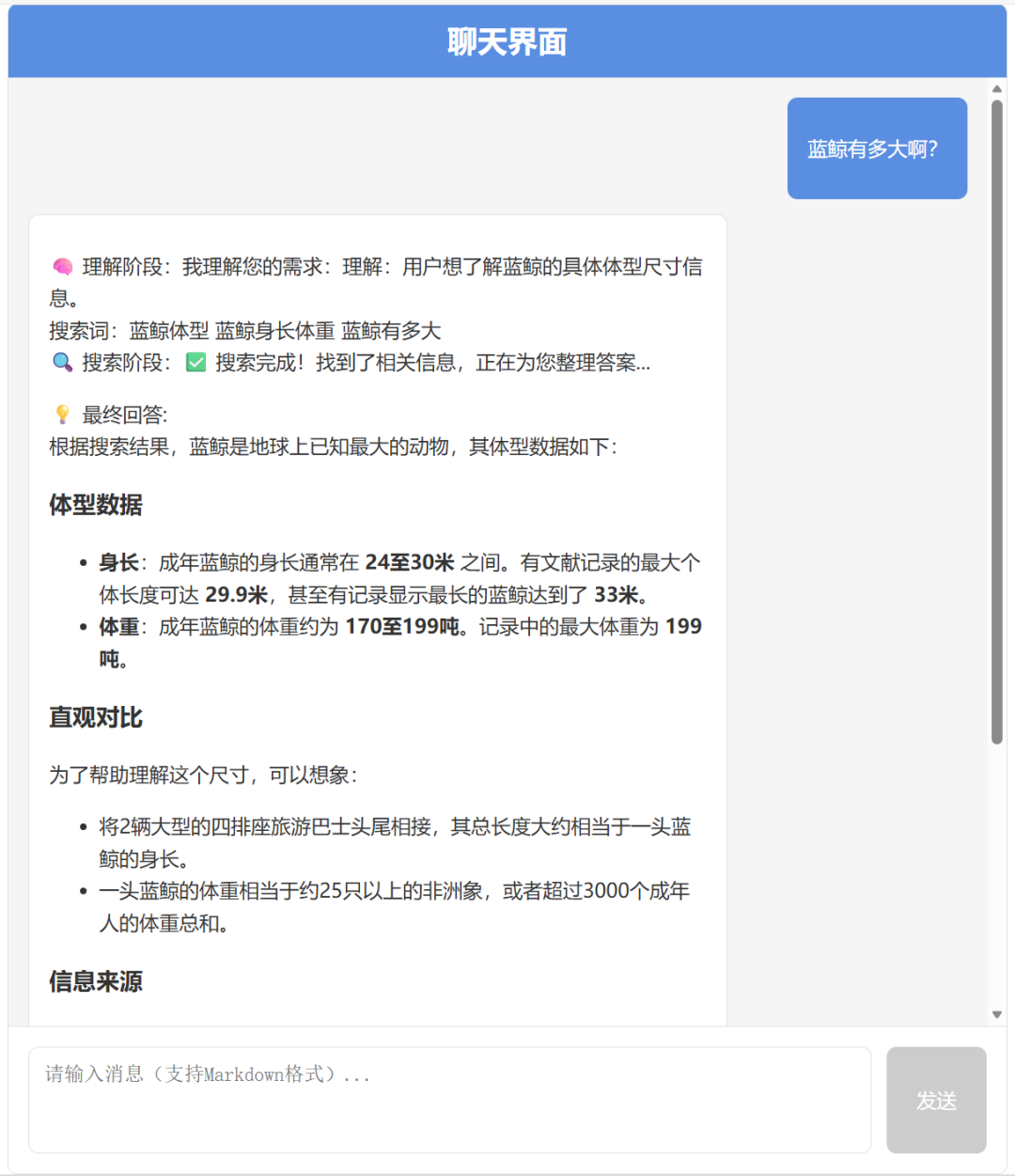
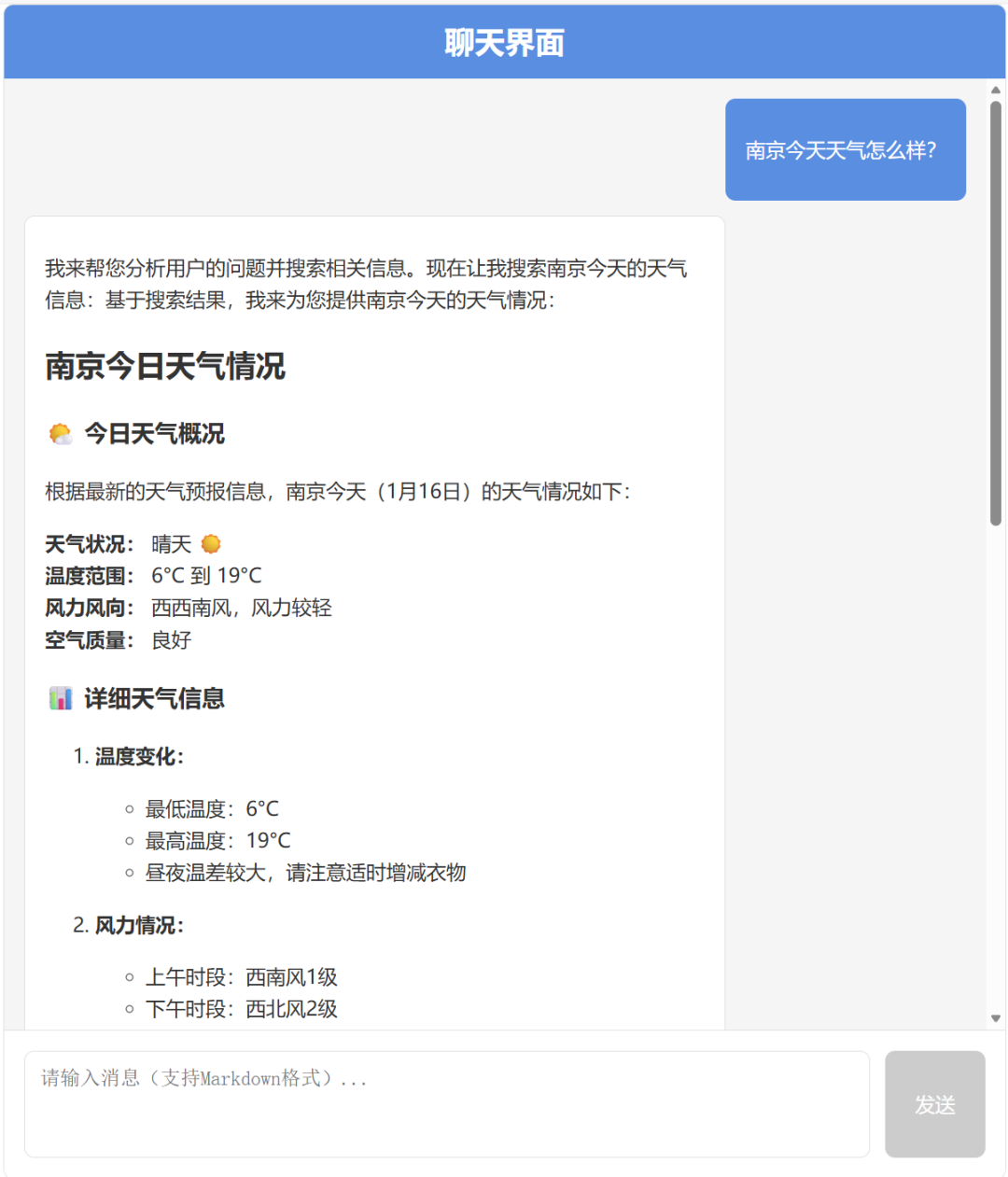
配合前端实现后,测试结果如下:
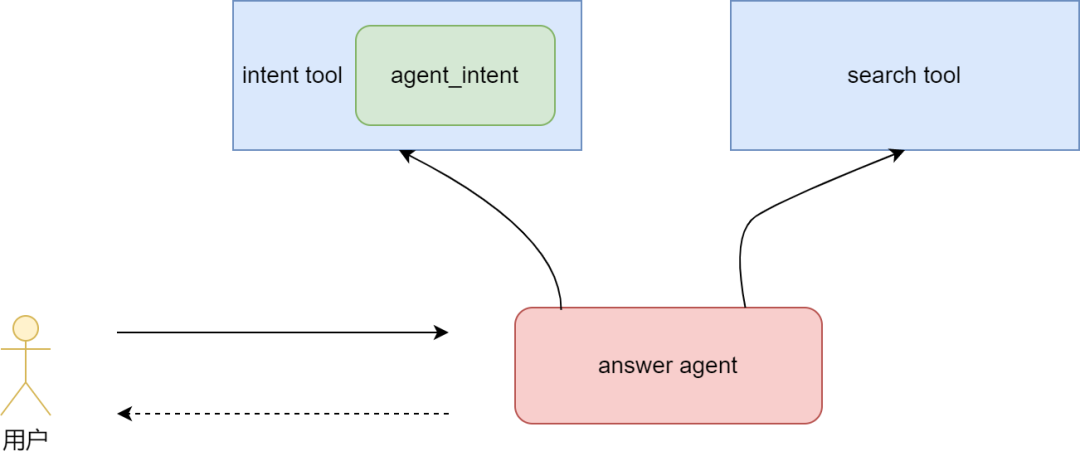
方式二:这种方式的本质是把子智能体封装成工具,供主智能体调用。架构图如下:
核心代码:
分析用户意图,获取搜索关键词,并封装成一个工具:
agent_intent = create_agent(
model=llm,
system_prompt="你是一个助手,你需要帮助用户理解查询意图,并生成最合适的搜索关键词。",
)
# Wrap it as a tool
@tool("intent", description="分析用户的查询意图,并返回最合适的搜索关键词。")
def call_intent_agent(query: str):
intent_prompt = f"""分析用户的查询:"{query}"
请完成两个任务:
1. 简洁总结用户想要了解什么
2. 生成最适合搜索的关键词(中英文均可,要精准)
格式:
理解:[用户需求总结]
搜索词:[最佳搜索关键词]
"""
result = agent_intent.invoke({"messages": [{"role": "user", "content": intent_prompt}]})
print(result["messages"][-1].content)
print("="*60)
return result["messages"][-1].content
搜索工具:
@tool("search", description="根据关键词搜索信息")
def search(keywords: str):
# 调用Tavily API进行搜索
response = tavily_client.search(
query = keywords,
search_depth = "basic",
include_answer = True,
include_raw_content = False,
max_results = 5
)
# 处理搜索结果
search_results = ""
# 优先使用Tavily的综合答案
if response.get("answer"):
search_results = f"综合答案:\n{response['answer']}\n\n"
# 添加具体的搜索结果
if response.get("results"):
search_results += "相关信息:\n"
for i, result in enumerate(response["results"][:3], 1):
title = result.get("title", "")
content = result.get("content", "")
url = result.get("url", "")
search_results += f"{i}. {title}\n{content}\n来源:{url}\n\n"
if not search_results:
search_results = "抱歉,没有找到相关的信息。"
return search_results
构建一个主智能体来回答用户问题:
answer_agent = create_agent(
model=llm,
system_prompt="""你一个助手,你需要基于搜索结果为用户提供完整、准确的答案。
当你收到搜索请求时,需要先分析用户的查询意图,得到查询关键词,
然后进行根据关键词搜索信息,最后给出答案。""",
tools=[call_intent_agent, search],
)
接下来只要调用answer_agent来生成回答,并流式返回给前端即可,其余部分和提示词和方式一类似,不再赘述。测试结果如下:
总之,多智能体系统(MAS)的核心意义在于通过群体智能突破单智能体的能力边界,适配复杂、动态、大规模的任务场景,实现 “1+1>2” 的协同价值。不过我们也不需要遇到复杂的问题就直接考虑多智能体,正如LangChain官网所说,大部分复杂问题都可以通过优化提示和调用工具来解决。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)