
GraphRAG:大模型架构升级之路,从搜索数据到推理洞察的质变
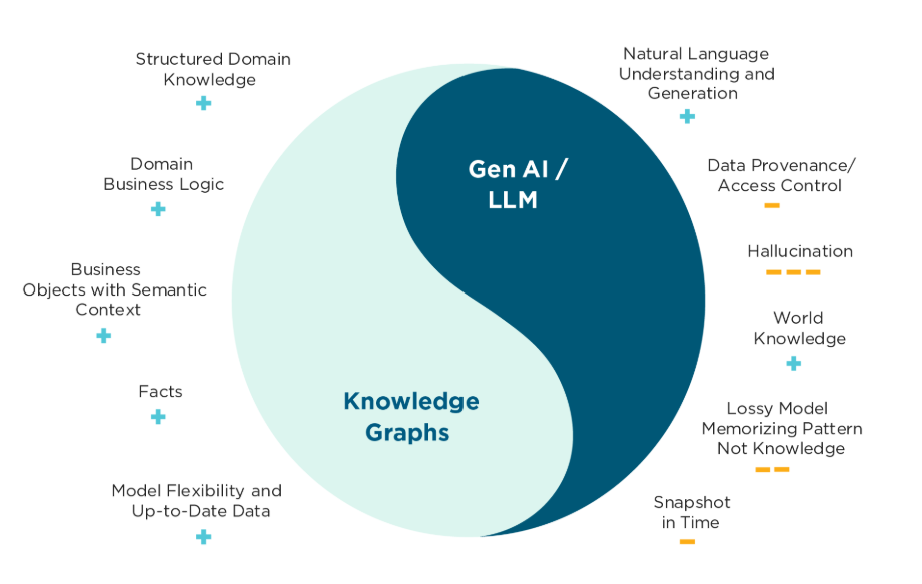
GraphRAG通过整合知识图谱与RAG技术,解决了传统RAG在处理复杂关系和全局性问题时的局限。它实现了从"搜索数据"到"推理洞察"的质变,具备多跳推理、全局总结和可解释性三大优势。GraphRAG将非结构化数据转化为结构化认知,通过显式关系链连接孤岛信息,利用分层社区摘要技术统揽全局,并提供了清晰的溯源路径,代表了大模型应用架构的重要发展方向。
GraphRAG通过整合知识图谱与RAG技术,解决了传统RAG在处理复杂关系和全局性问题时的局限。它实现了从"搜索数据"到"推理洞察"的质变,具备多跳推理、全局总结和可解释性三大优势。GraphRAG将非结构化数据转化为结构化认知,通过显式关系链连接孤岛信息,利用分层社区摘要技术统揽全局,并提供了清晰的溯源路径,代表了大模型应用架构的重要发展方向。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
随着大语言模型(LLM)应用的深入,企业不再满足于构建仅具备基础的问答能力的Chatbot,而是渴求基于更广泛业务数据的更深度的“洞察”Agent。传统的LLM+ RAG(检索增强生成)架构虽然解决了部分幻觉问题,但在处理复杂关系和全局性问题时遭遇了瓶颈。本文将结合 Rewire 的观点,深入剖析 RAG 的局限性,并从技术原理角度阐述 GraphRAG 如何通过知识图谱(Knowledge Graph)将非结构化数据转化为结构化认知,实现从“搜索数据”到“推理洞察”的质变。
— 1 RAG的繁荣与隐忧 —
数据间隐性的逻辑关系
在过去的一年里,RAG(Retrieval-Augmented Generation)已成为企业级 AI 落地的标准架构。通过将私有数据切片、向量化并存储于向量数据库(Vector Database)中,我们成功地让 LLM 拥有了“外挂大脑”,在一定程度上解决了模型训练数据滞后和“一本正经胡说八道”的幻觉问题。
然而,当我们试图让 AI 处理更复杂的任务时,基础 RAG(Naive RAG)的局限性开始暴露无遗。正如 Rewire 在 《From data to insights》 一文中隐含的核心观点:数据不仅仅是离散的片段,数据之间存在着隐性的逻辑关联。
当我们问 AI:“在这几百万份文档中,主要的技术趋势是什么?”或者“A 事件是如何间接导致 B 结果的?”时,传统的基于向量相似度的 RAG 往往束手无策。这标志着我们正在触碰“向量检索的天花板”。
— 2 传统 RAG 的技术瓶颈—
丢失的“全景图”
要理解 GraphRAG 的必要性,首先必须从技术底层审视传统 RAG 的运作机制及其缺陷。
2.1语义切片的破碎感:传统 RAG 的核心流程是 Chunking(分块) 、Embedding(嵌入) 、Vector Search(向量搜索)。这种方法假设:答案可以通过语义相似度直接定位到具体的文本片段中。
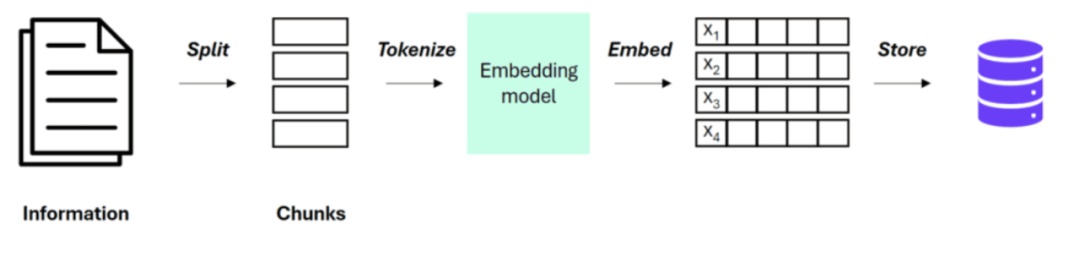
这种假设在处理“Fact Retrieval”(事实检索)时非常有效(例如:“公司的请假政策是什么?”)。但在面对以下两种场景时,它会彻底失效:
- 跨文档的逻辑推理(Multi-hop Reasoning): 假设文档 A 提到“产品 X 使用组件 Y”,文档 B 提到“组件 Y 的供应商 Z 破产了”。如果用户问“产品 X 会受到什么风险?”,传统 RAG 很难将这两块物理上分离、语义上不直接相关的片段联系起来。
- 全局性总结(Global Summarization): 向量搜索倾向于检索 Top-K 个最相似的片段。如果用户询问整个数据集的主题(Query-Focused Summarization),检索出的 Top-K 片段只能代表局部视角,无法拼凑出全貌。
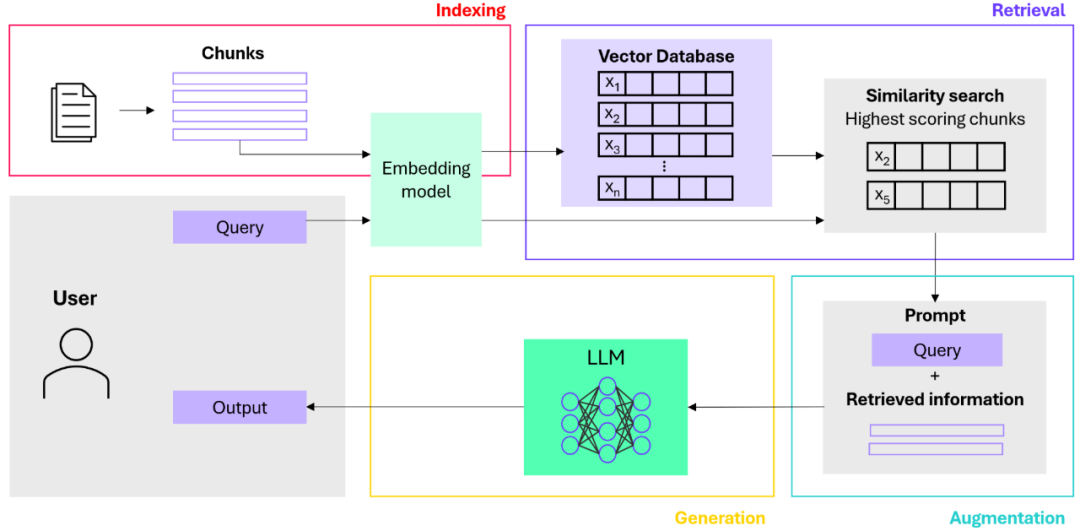
2.2 向量的“扁平化”诅咒:向量数据库将文本压缩为高维空间中的点。虽然这捕捉了语义,但丢弃了结构。在向量空间中,实体之间的明确关系(如“属于”、“导致”、“位于”)被模糊化为距离的远近。这种“扁平化”导致 LLM 只能看到点的集合,而看不到点与点之间构成的“网”。
— 3 GraphRAG—
图谱与向量的深度融合
GraphRAG 并非推翻 RAG,而是对其检索模块的一次升维。它引入了知识图谱(Knowledge Graph, KG),将非结构化文本转化为结构化的节点(Nodes)和边(Edges)。
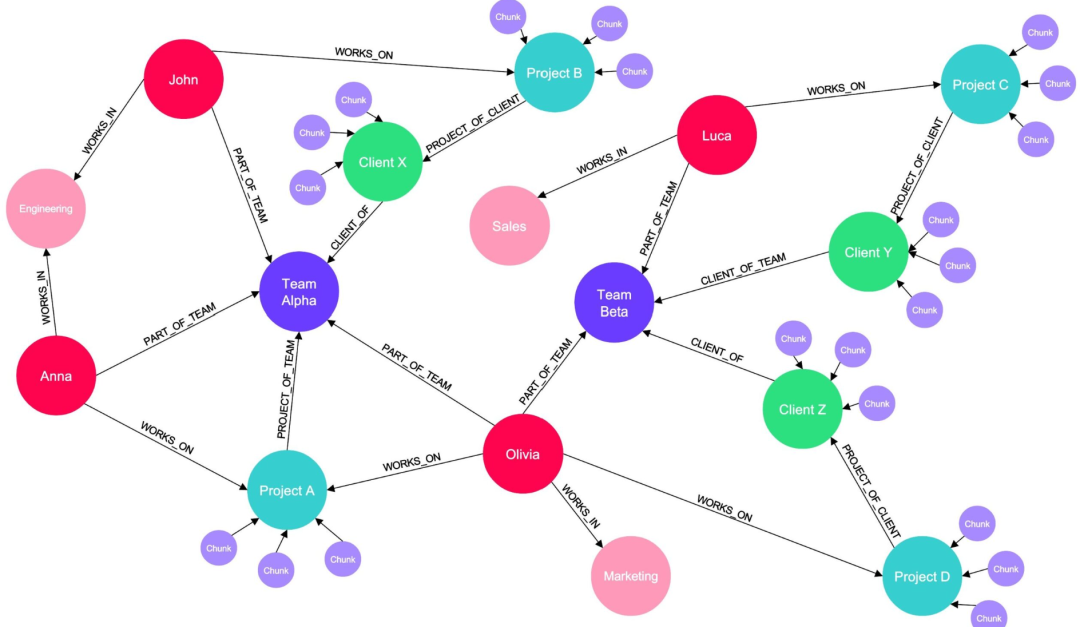
值得注意的是,现在的知识图谱(Knowledge Graph)已经可以整合经由大语言模型(LLM)处理过的非结构化数据,这使得它们能够可靠地检索和利用那些原本非结构化的信息。
例如利用LLM 阅读文本块,识别出其中的实体(人名、地名、概念等)以及实体间的关系。Example: 从文本“Apple 发布了 Vision Pro”中提取 (Apple) --[发布了]–> (Vision Pro)这样的节点和边,形成知识图谱。
RAG 与知识图谱之间的这种协同效应,创造了一个能够管理多种信息类型的互补系统。这种整合对于企业的内部知识管理尤为重要,因为企业必须有效地利用极其广泛的数据资源。
3.1 这种强大的组合是如何运作的?以下是具体流程:
- 利用 RAG 构建知识图谱我们首先基于数据中存在的关联关系来建立知识图谱,并从一开始就引入 RAG 技术。这个过程涉及对所有内部文档进行切片(Chunking)并对这些切片进行向量化(Embedding)。通过对这些向量进行相似度搜索,RAG 能够揭示数据内部的隐性连接,从而在构建过程中帮助塑造知识图谱的结构。
- 将文档连接到图谱一旦知识图谱构建完成,我们将分块文档的向量连接到图谱中对应的终端节点上。例如,所有关于“项目 A”的向量化文档都会连接到图谱中的“项目 A”节点。这样就形成了一个丰富且深度的知识图谱,其中的节点直接链接到了内部文档的向量切片。
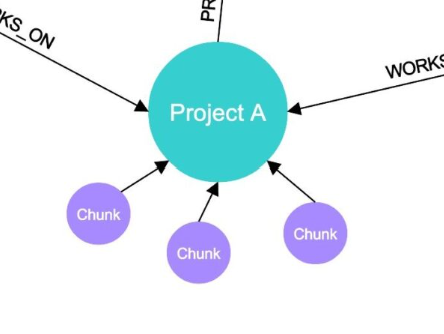
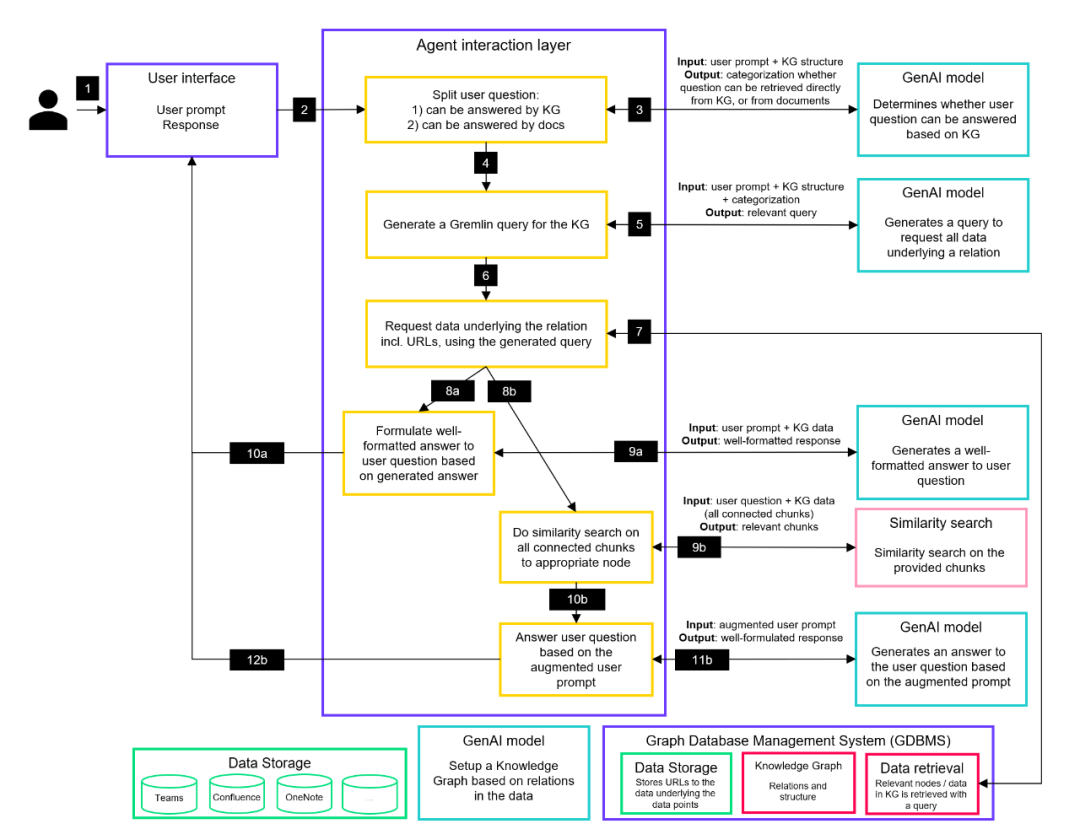
**3.2 利用 RAG 处理复杂查询:**这是 RAG 再次发挥关键作用的环节。
- 对于那些仅凭知识图谱结构就能回答的问题,我们可以快速给出答案。
- 但对于那些需要从文档中获取详细信息的查询,我们则启用 RAG 流程:
- 首先,定位到知识图谱中的相关节点(例如:项目 A)。
- 接着,检索所有连接到该节点的向量(例如:所有连接到“项目 A”的文档切片向量)。
- 然后,在这些向量与用户的问题之间执行相似度搜索。
- 随后,利用搜索到的最相关切片来增强(Augment) 用户的原始提示词(Prompt)(利用数据库键值来获取与相关向量对应的文本切片)。
- 最后,将这个增强后的提示词传递给 LLM,以生成一个全面且详实的答案。
至此我们能够初步总结GraphRAG 在技术上实现了三个维度的跨越:
-
连接孤岛:多跳推理能力。这是 GraphRAG 最直观的优势。通过显式的边(Edges),模型可以沿着关系路径进行推理。Entity_A >{关联到}>Entity_B >{关联到}>Entity_C。在传统 RAG 中,即使 retrieve 到了 A 和 C,模型也往往无法建立因果链。而 GraphRAG 将这种逻辑链条直接喂给了 LLM,使其能够回答需要多步推导的复杂问题,从而产出真正的“洞察”。
-
统揽全局:QFS (Query-Focused Summarization),在处理海量数据(如法律卷宗、医疗病历、金融研报)时,用户往往需要综合性的分析。GraphRAG 利用分层社区摘要技术,解决了上下文窗口限制的问题。它不需要把所有文档塞进 Context Window,而是通过检索高层级的社区摘要,快速构建全局视角。
-
可解释性与溯源,向量搜索是一个黑盒。我们很难解释为什么向量 A 和向量 B 相似。但知识图谱是白盒。GraphRAG 能够明确展示:
“我之所以得出这个结论,是因为文档 A 中提到了实体 X,而实体 X 在文档 B 中被定义为 Y 的子集。”
这种可解释性对于金融、医疗和法律等高风险领域的 AI 落地至关重要。
— 4 GraphRAG—
技术挑战与落地思考
虽然 GraphRAG 描绘了美好的前景,但在工程实践中,它也带来了新的挑战,这是我们在设计系统时必须考量的。
- **构建成本与延迟(Indexing Cost):**相比于极速的向量嵌入,构建知识图谱需要大量调用 LLM 进行实体抽取,这会导致索引阶段的 Token 消耗量激增,写入延迟变长。这对于实时性要求极高的数据流并不友好。
- **图谱质量的维护:**LLM 并非完美,它可能会提取出错误的实体或关系。如何进行图谱的清洗(Graph Cleaning)和实体对齐(Entity Resolution,即识别 “Steve Jobs” 和 “Jobs” 是同一个人)是工程难点。
- **混合检索策略的调优:**并不是所有问题都需要动用 GraphRAG。未来的最佳实践必然是 Vector + Graph 的混合模式。对于简单的事实查询,走向量通道;对于复杂推理,走图谱通道。如何设计这个路由(Router)机制是系统优化的关键。
如何学习AI大模型 ?
“最先掌握AI的人,将会晚掌握AI的人有竞争优势,晚掌握AI的人比完全不会AI的人竞争优势更大”。 在这个技术日新月异的时代,不会新技能或者说落后就要挨打。
老蓝我作为一名在一线互联网企业(保密不方便透露)工作十余年,指导过不少同行后辈。帮助很多人得到了学习和成长。
我是非常希望可以把知识和技术分享给大家,但苦于传播途径有限,很多互联网行业的朋友无法获得正确的籽料得到学习的提升,所以也是整理了一份AI大模型籽料包括:AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、落地项目实战等 免费分享出来。
- AI大模型学习路线图
- 100套AI大模型商业化落地方案
- 100集大模型视频教程
- 200本大模型PDF书籍
- LLM面试题合集
- AI产品经理资源合集

大模型学习路线
想要学习一门新技术,你最先应该开始看的就是学习路线图,而下方这张超详细的学习路线图,按照这个路线进行学习,学完成为一名大模型算法工程师,拿个20k、15薪那是轻轻松松!

视频教程
首先是建议零基础的小伙伴通过视频教程来学习,其中这里给大家分享一份与上面成长路线&学习计划相对应的视频教程。文末有整合包的领取方式

技术书籍籽料
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,这里也分享一份我学习期间整理的大模型入门书籍籽料。文末有整合包的领取方式

大模型实际应用报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。文末有整合包的领取方式

大模型落地应用案例PPT
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。文末有整合包的领取方式

大模型面试题&答案
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。文末有整合包的领取方式

领取方式
这份完整版的 AI大模型学习籽料我已经上传CSDN,需要的同学可以微⭐扫描下方CSDN官方认证二维码免费领取!
更多推荐
 28
28 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)