
谷歌Gemini 3概括解析:从底层架构到功能模块概览
谷歌发布新一代AI大模型Gemini3,实现多项技术突破:1)完全基于自研TPU训练,摆脱GPU依赖;2)创新统一多模态架构,支持跨模态交互;3)引入分层推理引擎,在MathArena等测试中表现优异;4)首创生成式UI,能动态创建定制化交互界面;5)增强智能体能力,支持复杂工具调用链。该模型在多项基准测试中领先,标志着AI向通用智能体方向迈出重要一步。

为何Gemini 3被视为“王者归来”?
- 技术全面领先:在推理、多模态、Agent、UI生成四大维度同时突破;
- 生态深度整合:首发即接入搜索、App、开发者平台,实现“模型即服务”;
- 自主可控底座:摆脱GPU依赖,彰显谷歌全栈AI实力;
- 用户体验跃迁:从“对话”迈向“共创”,开启生成式交互新纪元。
2025年11月19日,谷歌正式发布其最新一代人工智能大模型——Gemini 3。作为被CEO桑达尔·皮查伊称为“最智能模型”的产品,Gemini 3不仅在多项权威基准测试中实现断层领先(如LMArena榜首、ARC-AGI-2得分31.1%),更首次将通用智能体(Agentic)能力与生成式用户界面(Generative UI) 深度集成到消费级产品中。
一、底层训练基础设施
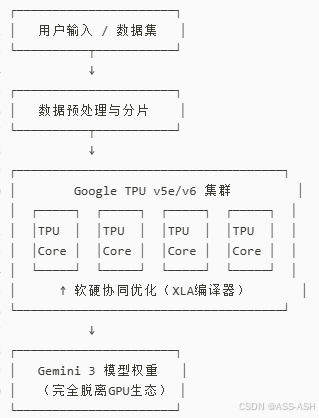
完全基于TPU v5e/v6训练
与当前主流依赖英伟达GPU的AI公司不同,Gemini 3全程使用谷歌自研TPU集群训练,这为其带来了两大关键优势:
- 训练自由度高:无需受制于GPU供应瓶颈,可大规模扩展参数与上下文长度;
- 软硬协同优化:模型架构与TPU指令集深度对齐,推理效率显著提升。
这是首个完全脱离英伟达生态实现SOTA性能的大模型,标志着“去GPU化”路径的可行性。
二、模型架构设计
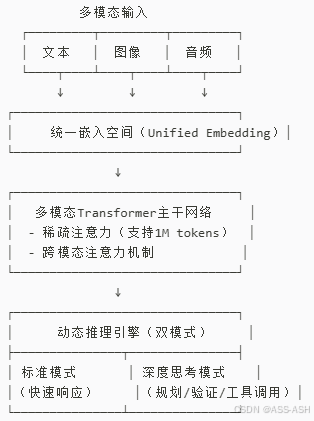
统一多模态Transformer + 动态推理引擎
Gemini 3采用统一多模态Transformer架构,但在此基础上引入多项创新设计:
1. 原生多模态融合(Native Multimodal Fusion)
- 所有输入(文本、图像、音频、视频帧)均被映射为统一的嵌入空间;
- 使用跨模态注意力机制(Cross-modal Attention)实现细粒度对齐;
- 支持任意模态组合输入/输出,例如“看视频+听讲解+写代码”。
2. 分层推理引擎(Hierarchical Reasoning Engine)
Gemini 3内置两种推理模式:
- 标准模式(Standard Mode):适用于日常任务,低延迟;
- 深度思考模式(Deep Think Mode):启用多步规划、自我验证、工具调用链,用于复杂问题(如数学证明、系统调试)。
Benchmark表现:在MathArena Apex中达23.4%,远超GPT-5.1(1.0%);在ARC-AGI-2中达31.1%,展现类人抽象推理能力。
3. 超长上下文支持(Up to 1M Tokens)
- 采用稀疏注意力 + 内存压缩技术,有效处理百万级token;
- 在MRCR v2测试中,28k上下文准确率达77.0%,1M上下文仍保持26.3%有效回忆率。
三、核心功能模块
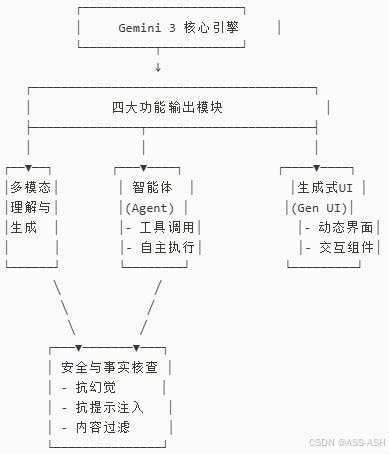
Gemini 3不仅是语言模型,更是一个多功能智能体平台。其功能模块可分为四大类:
模块1:多模态理解与生成
| 能力 | 示例 | Benchmark |
|---|---|---|
| 图像理解 | 解析手写菜谱、截图UI元素 | ScreenSpot-Pro: 72.7% |
| 视频分析 | 观看运动视频生成改进建议 | Video-MMMU: 87.6% |
| 音频处理 | 多语种语音转写+语义摘要 | — |
| 跨模态生成 | 输入论文+讲座视频 → 生成交互式记忆卡 | MMMU-Pro: 81.0% |
模块2:智能体(Agent)能力
Gemini 3是首个在消费端产品中落地通用Agent能力的大模型:
- 工具调用准确率提升30%(vs Gemini 2.5 Pro);
- 支持动态工具组合(如:先查API文档 → 写代码 → 部署 → 测试);
- 在Terminal-Bench 2.0中得分54.2%,领先第二名11个百分点。
配套平台:Google Antigravity —— 新一代智能体开发环境,赋予Agent直接操作IDE、终端、浏览器的权限。
模块3:生成式UI(Generative User Interface)
这是Gemini 3最具革命性的交互创新:
- 不再返回纯文本,而是动态生成定制化UI组件;
- 根据用户身份(如儿童/专家)、设备类型、上下文自动调整布局、色彩、交互逻辑;
- 支持生成:可玩3D游戏、数据仪表盘、教学模拟器等。
[用户提问] → [意图理解] → [审美偏好建模] → [生成响应式UI]
模块4:安全与事实准确性增强
- 接受Google史上最全面的安全评估;
- 抗提示注入能力显著提升;
- 事实准确性在SimpleQA Verified中达72.1%,减少“幻觉”;
- 谄媚性更低,强调“告诉你需要知道的,而非你想听的”。
四、技术架构简图
以下为Gemini 3整体技术栈的简化示意图:

五、依然可能存在的问题
尽管Gemini 3 具有许多创新的功能和优势,但同样存在一些已知的缺陷以及潜在的问题:
-
数据隐私与安全问题:随着模型对多模态数据(文本、图像、音频等)处理能力的增强,如何确保用户数据的安全性和隐私保护成为一个重要议题。特别是涉及到敏感信息处理时,任何泄露都可能导致严重的后果。
-
抗幻觉与事实核查难度增加:虽然 Gemini 3 强调了其在安全性和事实核查方面的努力,但实现完全准确且无误的信息生成依然是一个挑战。特别是在处理未见过的数据或复杂情境时,模型可能会产生看似合理但实际上错误的内容。
-
计算资源消耗大:训练和运行如此复杂的模型需要大量的计算资源,这不仅增加了成本,也对环境造成了更大的负担。尽管 TPU 的使用提高了效率,但长期来看,如何平衡性能提升与资源消耗仍是一个难题。
-
模型偏见:所有的机器学习模型都有可能继承训练数据中的偏见,Gemini 3 也不例外。这些偏见可能会影响模型的公平性和准确性,特别是在涉及社会敏感话题时尤为重要。
-
跨文化适应性有限:尽管 Gemini 3 力求提供全面的语言和文化支持,但由于训练数据集的局限性,某些特定文化的细微差别可能无法被充分理解和表现出来,从而影响用户体验。
-
技术依赖风险:高度依赖于特定硬件(如 TPU v5e/v6 集群)进行优化训练和推理,这意味着对于那些没有访问这些高端资源的研究人员和开发者来说,复现或改进这项工作可能存在障碍。
-
动态推理引擎的复杂性:引入双模式(标准模式与深度思考模式)的动态推理引擎虽然增强了灵活性,但也增加了系统的复杂性,可能导致调试困难及更高的维护成本。

更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)