
小白从零开始勇闯人工智能Python初级篇(3-组合数据类型)
引言
欢迎回来,未来的Python高手们,在前两篇我们我们学会了让程序思考和重复运转。但现实世界的数据从来不是孤立的,一个班级里有很多学生,如果我们要管理这些学生的姓名,难道我们还要一个个去创建个变量吗?这显然是不现实的,这个时候我们就要将多个数据组织在一个容器中,通过一个变量名来管理,而这个容器就是我们今天要学习的列表、元组和字典。
一、最灵活的数据列车——列表(List)
1、列表的创建与基本概念
列表类型的数据是使用率较高的一种类型,它可以将多种不同的类型的元素按照顺序依次组合在一起,而且列表创建后是可以修改、删除和添加元素的,且其中可以包含重复的的元素。列表类型数据的使用形式是使用方括号[ ],元素用逗号分隔:
[元素1,元素2,元素3...]
ls = [1,'人工智能',2]
print(ls)
2、访问列表元素:索引与切片
列表与字符串类似也可以通过索引或者切片的方式来访问列表里的元素,其使用方法与第一篇中字符串的索引与切片的方法大致一致,但还需要注意三点:
1)、列表中的子列表只能作为列表中的一个元素。
2)、经索引所获取的元素的数据类型与列表中该数据的类型一致,而经切片所获取到的元素的数据类型却是列表类型。
3)、当列表里面还有一个列表即子列表时,我们需要先获取子列表再对子列表索引其中的元素。
索引示例:
a = '人工智能'
ls=[1,'2',[3,4],a]
print(ls[0],ls[1],ls[2],ls[3])#通过索引获取列表中每一个元素
print(type(ls[0]),type(ls[1]),type(ls[2]),type(ls[3]))#查看每一种元素的数据类型
print(ls[2][1])#通过索引获取列表中子列表第二个元素4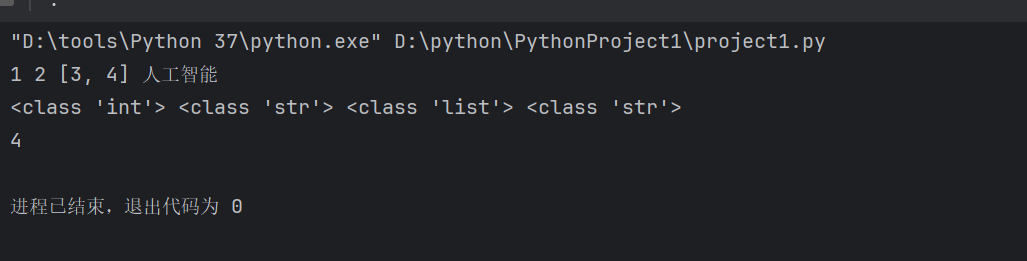
切片示例:
a = '人工智能'
ls=[1,'2',[3,4],a]
print(ls[0:3],ls[2:3])
print(ls[::2]) # (步长为2)
print(ls[::-1]) # (反转列表)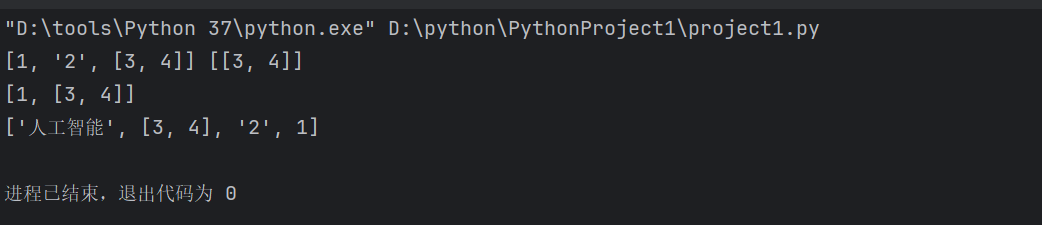
3、列表的嵌套与多维索引
当列表中含有子列表而子列表又包含子列表时,我们想要获取子列表中的子列表里的元素的方法为:ls[索引号][索引号][索引号],同理当列表里包含多层子列表时,我们获取最内层子列表的方法就是:ls[索引号][索引号][索引号]...
a = '人工智能'
ls=[1,['2',[[3,4],a]]]#这里面有四层列表嵌套
print(ls[1][1][0][1])#通过索引获得最内层列表里的第二个元素4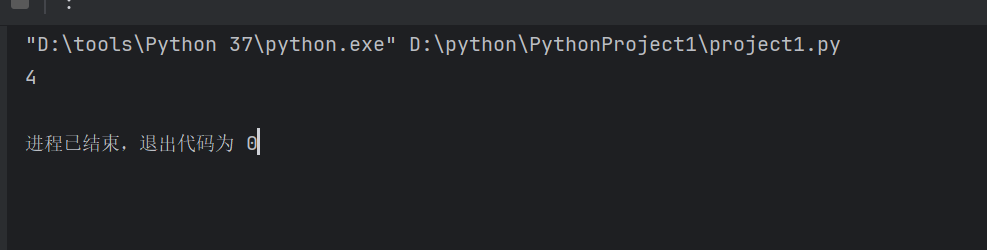
4、遍历列表:与循环的完美结合
在第二篇我们学习了for循环,循环内容可以是数字和字符串,而我们今天学习的列表也可以作为循环里的内容。例如:
a = '人工智能'
ls=[1,'2',[3,4],a]
for i in ls:
print(i)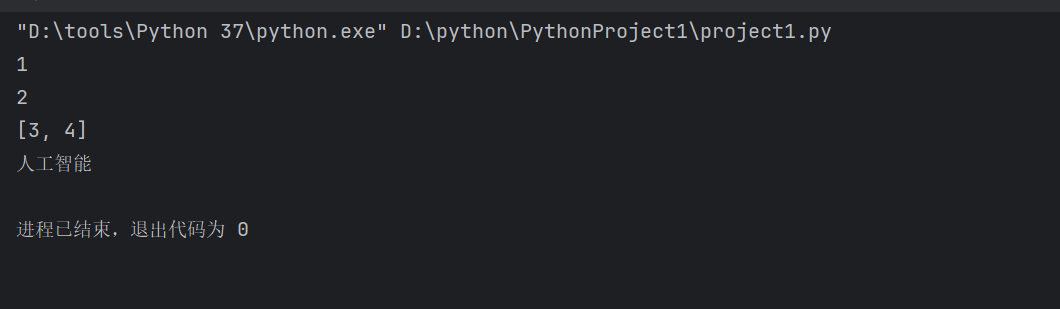
5、列表的常用操作:函数 vs 方法
如果我们想把其他数据类型强制转换为列表类型的话我们就可以使用list()函数来实现。其中要注意我们只能转换有顺序属性的内容例如字符串,而想数值的话是不能狗进行转换的。
a = '人工智能'
b=1
print(list(a))
print(list(b))#数值1没有顺序属性转换会报错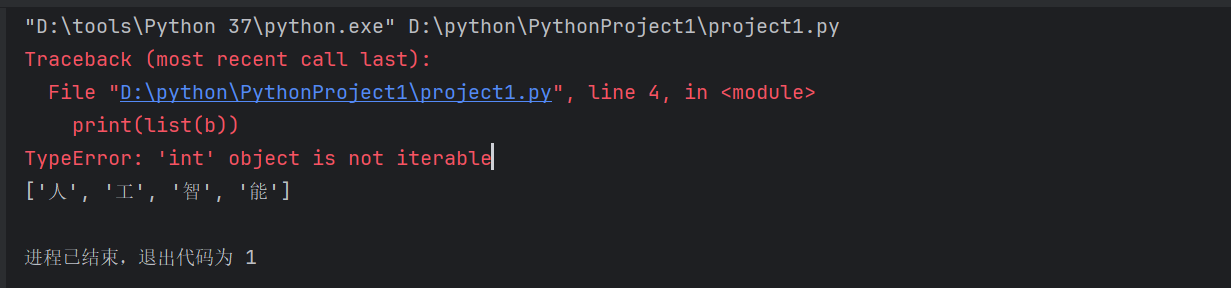
列表里还有其他函数,我们常见的有len(list):(获取列表长度(元素个数))。max(list) / min(list):(获取最大/最小值(要求元素可比较))。sum(list):(求和(要求元素是数字))。sorted(list):(返回排序后的新列表,原列表不变)。
list_1=['人','工','智','能']
print(len(list_1))
num = [5, 2, 0, 1, 3, 1, 4]
print(max(num))#输出最大的数字5
print(min(num))#输出最小的数字0
num2 = [5, 2, 0, 1, 3,1,4]
print(sum(num2)) # 求和输出
num3 = [5, 2, 0, 1, 3, 1, 4]
sorted_num3 = sorted(num3)
print(sorted_num3) # 从小到大排序
print(num3) # 原列表不变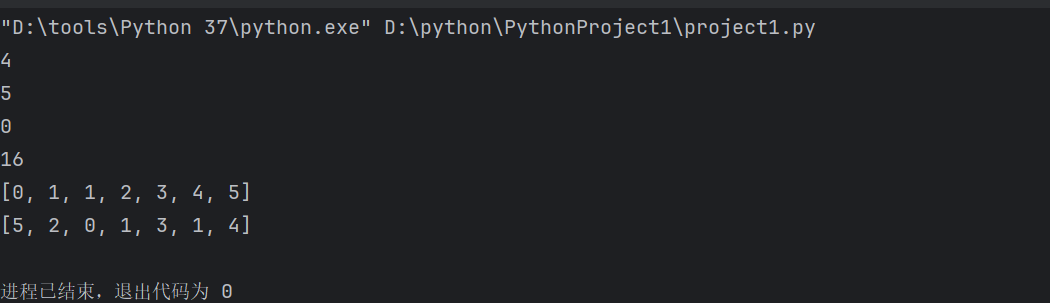
列表是可以进行修改的,我们通过. 调用,会修改原列表,所有的方法可以通过print(dir(list))查看,下面我将例举10中常用的方法。
1)、增:
.append(元素):在末尾添加一个元素。
ls = ['人','工','智能']
ls.append('真厉害')
print(ls)
.insert(索引, 元素):在指定索引位置插入元素。
ls = ['人','工','智能']
ls.insert(0,'我爱')
print(ls)
.copy:复制一个新的列表
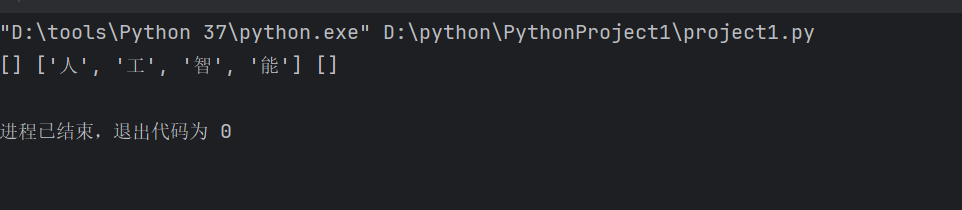
ls=['人','工','智','能']
ls_1=ls.copy()
ls_2=ls
ls.clear()
print(ls,ls_1,ls_2)这里要注意第二行代码是根据ls复制了一个新的列表并且赋值给了ls_1,第三行代码是直接将ls的内容赋值给了ls_2,因为ls_2是通过等号直接由ls赋值得到的列表,它与ls共用一个内存空间,所以我们删除ls的内容后ls_2的内容也会被删除,而ls_1复制出了一个新的列表所以不受影响。
2)、删:
.remove(元素值):删除第一个匹配到的指定值的元素。
ls=['人','工','智','能','人','工','智','能']
ls.remove('工')#只删除了第一个出现的‘工’
print(ls)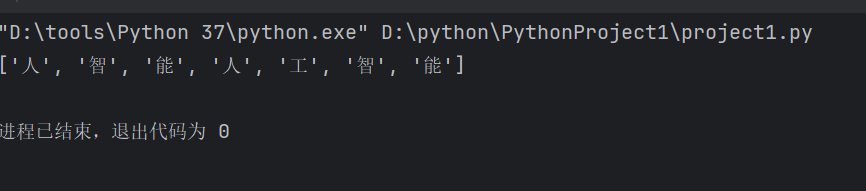
.pop(索引):删除并返回指定索引的元素。
ls=['人','工','智','能']
ls.pop(1)
print(ls)
.clear():清空整个列表。
ls=['人','工','智','能']
ls.clear()
print(ls)

3)、查与改:
.index(元素值):返回指定元素第一次出现的索引。
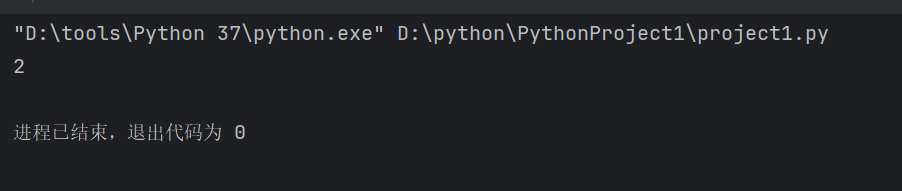
ls=['人','工','智','能','人','工','智','能']
print(ls.index('智'))
.count(元素值):返回指定元素在列表中出现的次数。
ls=['人','工','智','能','人','工','智','能']
print(ls.count('人'))
.sort():对列表原地排序(默认升序),可用 reverse=True 参数降序。如果输入的内容是英文则按照字母顺序排序,如果是汉字,则按照汉字的Unicode编码进行排序,如果是数字则按大小排序。
ls=['人','工','智','能']
ls_1=[5,2,0,1,3,1,4]
ls_2=['r','e','n','g','o','n','g','z','h','i','n','e','n','g']
ls.sort()
ls_1.sort()
ls_2.sort()
print(ls,ls_1,ls_2)
ls.sort(reverse=True)
ls_1.sort(reverse=True)
ls_2.sort(reverse=True)
print(ls,ls_1,ls_2)
 .reverse():原地反转列表。
.reverse():原地反转列表。
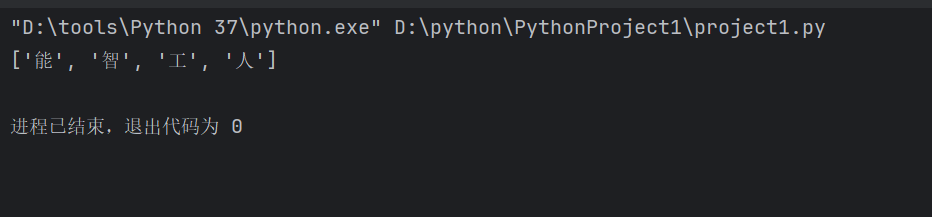
ls=['人','工','智','能']
ls.reverse()
print(ls)
二、不可变的稳定序列——元组(Tuple)
元组是Python中一种重要的有序序列结构。与列表最大的不同在于其不可变性——一旦创建,便无法修改、添加或删除其中的任何元素,所以元组不支持: append(), insert(), remove(), pop(), sort() 等所有会修改元组的方法。这一特性使得元组在存储不应被更改的数据(如程序配置、常量定义)时格外可靠,同时也可作为字典的键使用。正因为其结构固定,元组在内存处理和遍历速度上通常优于列表,执行效率更高。
元组的使用使用形式为:使用圆括号 (),元素用逗号分隔。
tp=('人','工','智','能')
print(tp)
因为不能对元组进行修改,所以元组中可以使用的函数和方法较少,而在元组中可以使用的方法有索引、切片、len(), max(), min(), sum(), 等,只要不修改元组本身都支持。如果我们想要删除整个元组数据可以使用del关键字实现。
tp=('人','工','智','能')
print(len(tp))
print(tp[0])
print(tp[1:3])
tp_2=('5','2','0','1','3','1','4')
print(max(tp_2))
print(min(tp_2))
tp_3=(5,2,0,1,3,1,4)
print(sum(tp_3))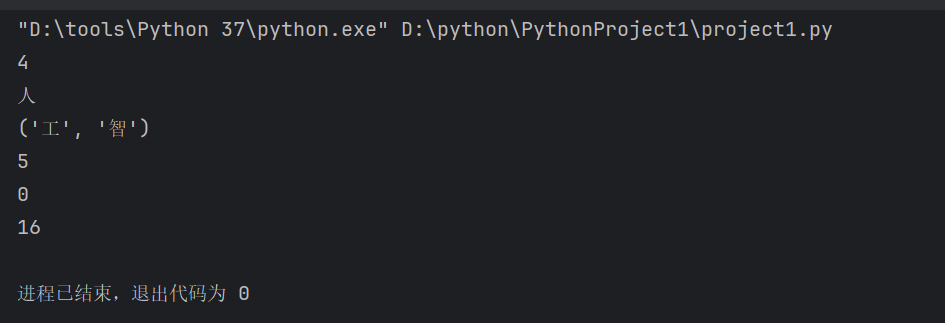
三、高效的键值档案柜——字典(Dictionary)
1、字典的创建与基本概念
字典是Python中极具实用性的键值对集合,通过花括号{}创建,元素以"键: 值"形式组织。每个元素都包含一个唯一的键及其对应的值,这种结构实现了数据的快速查找与关联存储。字典的键必须是字符串、数字或元组等不可变类型且不可重复,而值则支持任何数据类型且允许重复。字典会保持元素的插入顺序,这使遍历操作更可控,但本质上仍被视为无序集合。
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能'
}
print(d)
2、访问字典元素
因为字典本质上被视为无序集合,当我们想要获取字典中的元素时我们不能使用索引或者切片的方法,而是要使用键来获取,因为键是字典里元素的唯一标识,每个值都有一个唯一的键。
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
'birth':'2002年6月29日'
}
print(d)
print(d['birth'],d['名字'],sep='\n')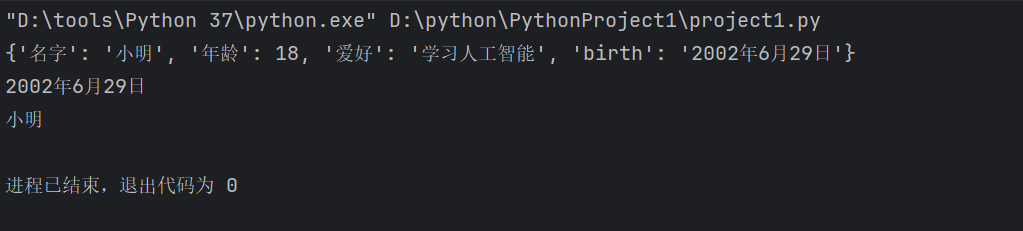
当我们字典里的键不存在时,可以使用.get(键, 默认值) 方法使其返回默认值而不是报错。
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
'birth':'2002年6月29日'
}
print(d)
print(d['birth'],d['名字'],sep='\n')
print(d.get(123))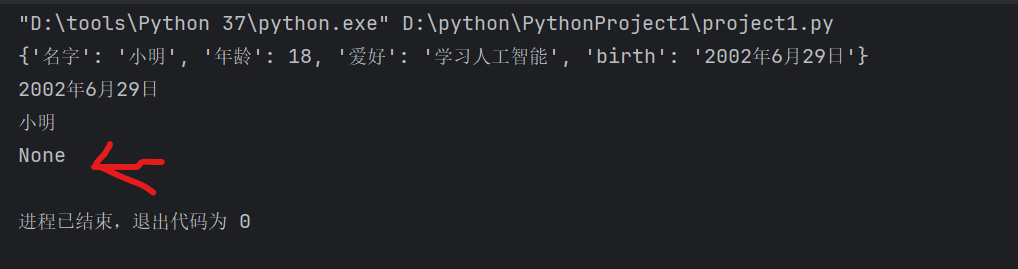
3、字典的常用方法
字典与列表一样也是可以进行修改的,下面我将介绍9中常见的方法:
1) 增与改:
字典[新键] = 值:添加新的键值对
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
}
print(d)
d['birth']='2002年6月29日'
print(d)

字典[已存在键] = 新值:修改已有键对应的值
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
}
print(d)
d['birth']='2002年6月29日'
print(d)
d['birth']='2002年5月19日'
print(d)
.update(另一个字典):用另一个字典的键值对批量更新当前字典
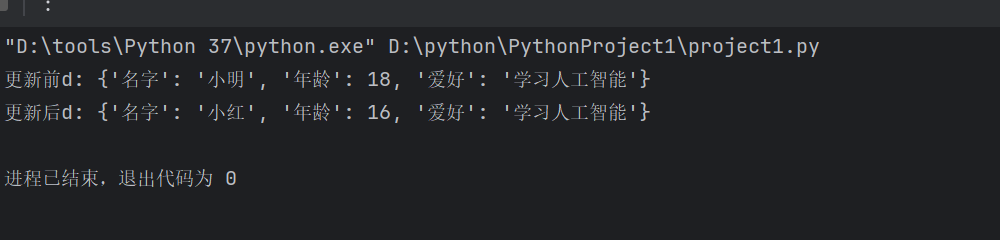
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
}
c={
'名字': '小红',
'年龄': 16,
'爱好': '学习人工智能',
}
print('更新前d:',d)
d.update(c)
print('更新后d:',d)
2)、删:
.pop(键):删除指定键的键值对,并返回对应的值
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
}
print(d)
a=d.pop('年龄')
print(d,a)

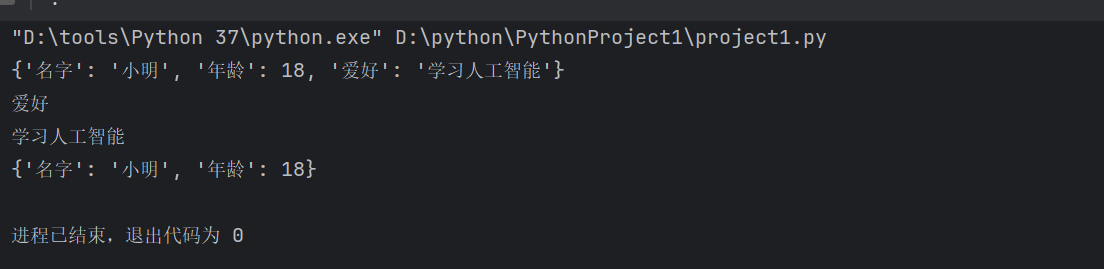
.popitem():删除并返回最后插入的键值对
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
}
print(d)
a,b=d.popitem()
print(a)
print(b)
print(d)
.clear():清空字典
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
}
print(d)
d.clear()
print(d)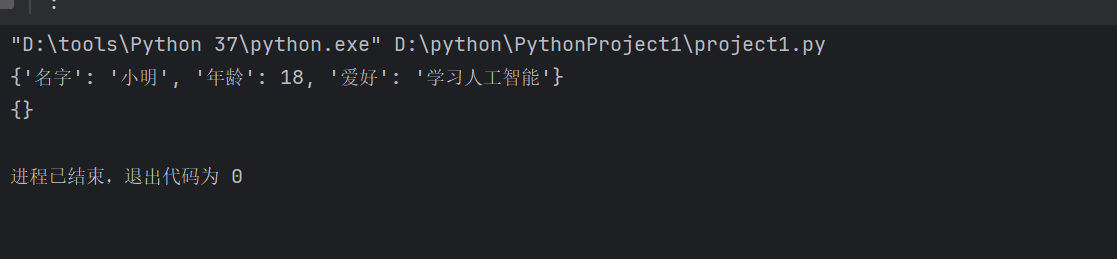
3)、查:
.keys():返回所有键的视图
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
}
print(d.keys())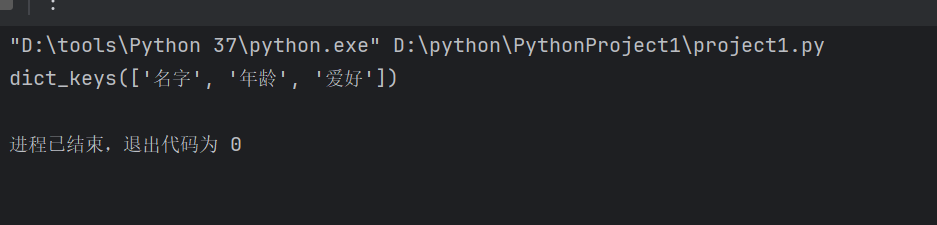
这种数据类型是在Python内部使用的,并不会提供给用户,如果需要使用键信息我们可以通过list()函数将返回的信息转化为列表来使用。
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能',
}
print(list(d.keys()))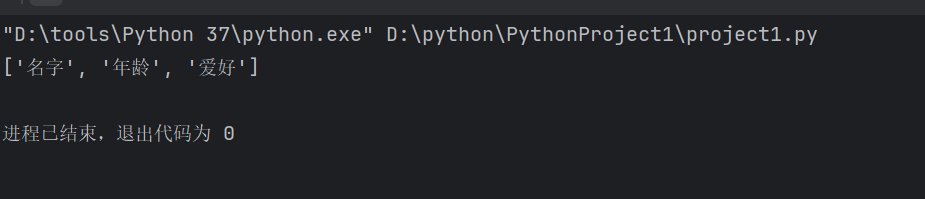
.values():返回所有值的视图
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能'
}
print(d.values())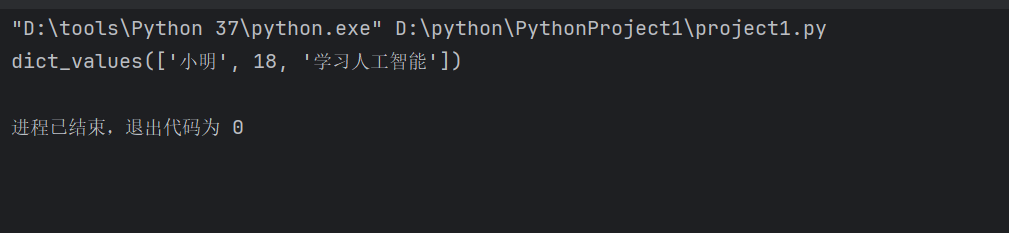
这种数据类型同样是Python内部使用的,我们也要用list()函数将返回的信息转化为列表来使用。
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能'
}
print(list(d.values()))
.items():返回所有键值对的视图,每个键值对是一个元组
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能'
}
print(d.items())
这里与上述两种方法一样
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能'
}
print(list(d.items()))
4、遍历字典
如果我们想访问字典里所有的内容我们可以通过for循环来对字典进行遍历,因为每个字典里每个数据都包含键和值,所以我们遍历时只会得到对应的键信息而得不到值信息,此时我们需要在代码上获取值的信息有两种方法:
1)、第一种是在遍历时加上对值和键的说明
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能'
}
for i in d:print(i)#只能遍历到字典里的键
print('------')
for a in d.keys(): print(a)#只遍历字典里的键
print('------')
for b in d.values(): print(b)#只遍历字典里的值
print('------')
for c,d in d.items(): print(c,d)#遍历字典里的键和值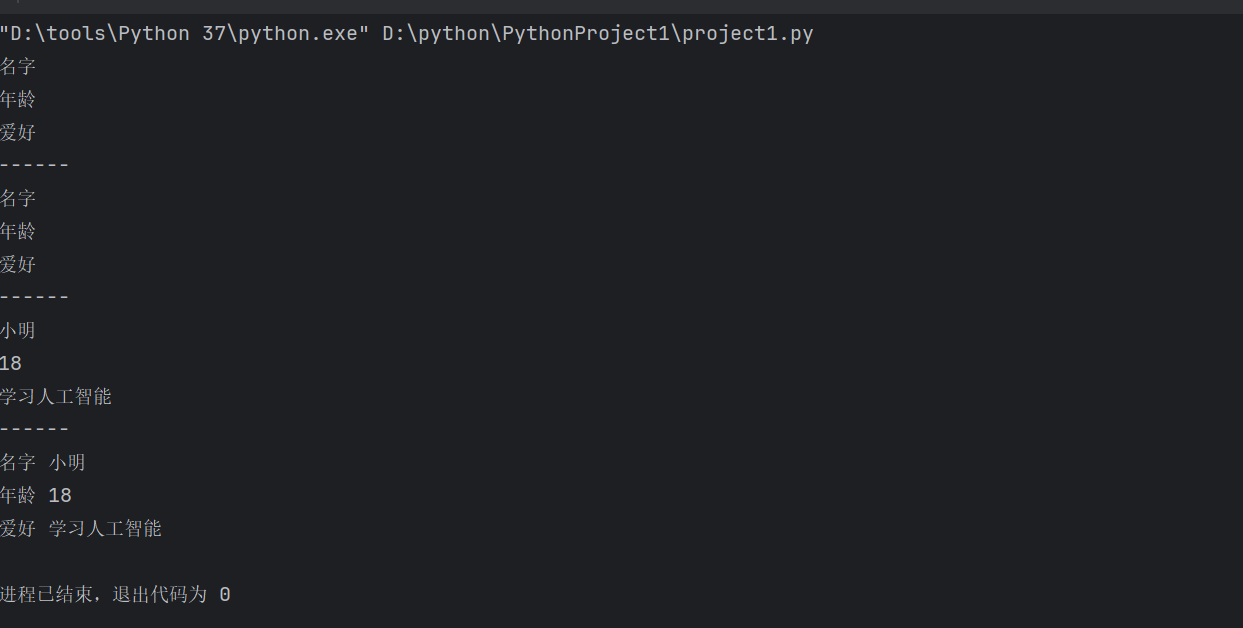
2)、第二种在print()里加上d[i]
d= {
'名字': '小明',
'年龄': 18,
'爱好': '学习人工智能'
}
for i in d:print(i,d[i])
5、数据的维度与复杂嵌套
现实数据往往具有多维特征和复杂嵌套结构。例如,一个学生的信息不仅包含姓名、年龄等基本属性,还可能嵌套着成绩单(包含多门课程的成绩记录)、家庭关系(包含多个家庭成员的信息)等。数据的维度从简单的标量值(0维)扩展到列表(1维)、表格(2维)、时序数据(3维)乃至更高维度的张量。理解数据的维度与嵌套关系对于设计合理的数据结构、选择适当的存储方案以及进行有效的数据处理至关重要。
例如一个包含多个学生信息的列表,每个学生信息是一个字典。
students = [
{'姓名': '小明', '年龄': 18, '分数': {'数学': 90, '英语': 85}},
{'姓名': '小红', '年龄': 16, '分数': {'数学': 95, '英语': 92}},
{'姓名': '小王', '年龄': 19 ,'分数': {'数学': 88, '英语': 78}}
]
print(students)
我们可以 组合使用索引和键来访问嵌套数据。
students = [
{'姓名': '小明', '年龄': 18, '分数': {'数学': 90, '英语': 85}},
{'姓名': '小红', '年龄': 16, '分数': {'数学': 95, '英语': 92}},
{'姓名': '小王', '年龄': 19 ,'分数': {'数学': 88, '英语': 78}}
]
# 获取第一个学生的数学成绩
math_score = students[0]["分数"]["数学"]
print(math_score) # 输出:90
同时给我们也可以遍历这个复杂的结构。
students = [
{'姓名': '小明', '年龄': 18, '分数': {'数学': 90, '英语': 85}},
{'姓名': '小红', '年龄': 16, '分数': {'数学': 95, '英语': 92}},
{'姓名': '小王', '年龄': 19 ,'分数': {'数学': 88, '英语': 78}}
]
for student in students:
print(f"学生:{student['姓名']}")
for subject, score in student["分数"].items():
print(f" {subject}分数:{score}")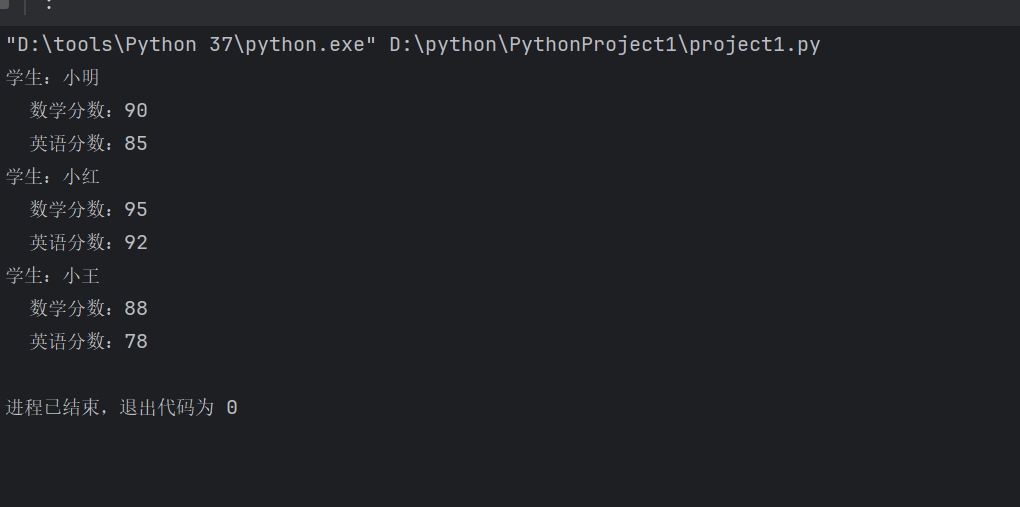
到这里我们就基本了解列表、元组和字典类型的数据的知识了,接下来让我们用一个简单的案例来巩固一下我们所学的知识。
我们来制作一个简易通讯录管理系统。
# 初始化一个空字典来存储联系人
a = {}
# 主程序循环
while True:
print("\n=== 简易通讯录 ===")
print("1. 添加联系人")
print("2. 查找联系人")
print("3. 显示所有联系人")
print("4. 删除联系人")
print("5. 退出系统")
choice = input("请选择功能(1-5):")
# 添加联系人
if choice == "1":
name = input("请输入联系人姓名:")
phone = input("请输入联系人电话:")
a[name] = phone # 核心:向字典添加键值对
print(f"联系人 {name} 添加成功!")
# 查找联系人
elif choice == "2":
name = input("请输入要查找的联系人姓名:")
if name in a: # 核心:检查键是否存在
print(f"{name} 的电话是:{a[name]}") # 核心:通过键访问值
else:
print(f"通讯录中未找到 {name}")
# 显示所有联系人
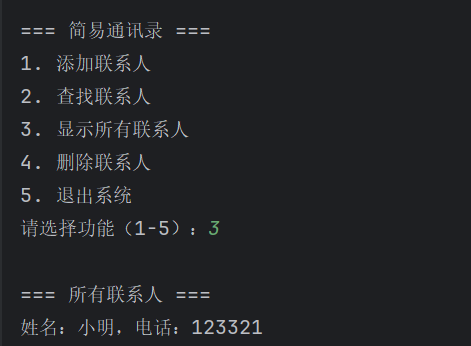
elif choice == "3":
if not a: # 如果字典为空
print("通讯录为空!")
else:
print("\n=== 所有联系人 ===")
for name, phone in a.items(): # 核心:遍历字典的键值对
print(f"姓名:{name},电话:{phone}")
# 删除联系人
elif choice == "4":
name = input("请输入要删除的联系人姓名:")
if name in a:
del a[name] # 核心:删除指定键值对
print(f"联系人 {name} 已删除")
else:
print(f"通讯录中未找到 {name}")
# 退出系统
elif choice == "5":
print("再见!")
break
# 处理错误输入
else:
print("输入错误,请重新选择!")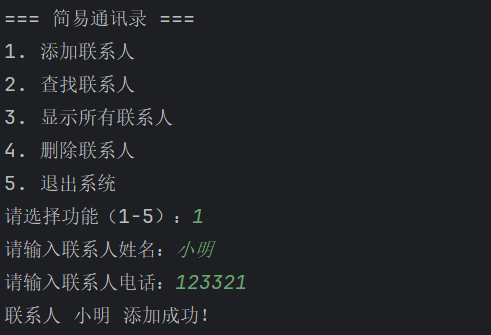



终于现在我们已经能够熟练地使用Python的三大组合数据类型来组织复杂的数据了。在下一篇,我们将学习函数,学习如何将代码封装成可重用的函数。这是从"脚本小子"迈向"真正程序员"的关键一步,也是开发复杂AI项目的基础。
更多推荐
 29
29 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)