
FINCON:融合概念性语言强化的 LLM 多智能体金融决策系统
本文是对论文《FINCON》的深度解读。在金融决策领域,如何应对市场波动、整合多源信息并实现风险管控,是关键挑战。NeurIPS 2024 收录的 FINCON 框架,以经理 - 分析师层级架构模拟投资机构分工,结合双级风险控制(CVaR 实时监控与 CVRF 信念更新),支持单股票交易与组合管理,在实验中显著优于 LLM 及 DRL 基线模型。
在金融市场的复杂波动环境中,Sequential 投资决策需要精准整合多源信息并实现智能风险管理,而传统方法在多模态数据处理、长期风险控制和任务适配性上存在明显局限。NeurIPS 2024 收录的论文《FINCON: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making》采用了创新的多智能体架构与双级风险控制机制,在单股票交易和投资组合管理中的取得了突破性表现。
原文链接:https://arxiv.org/pdf/2407.06567
代码链接:https://github.com/The-FinAI/FinCon
一、研究背景与核心痛点
1. 金融决策的核心挑战
金融市场的内在复杂性和波动性对高质量连续投资决策构成重大阻碍。在单股票交易和投资组合管理等任务中,决策需依赖多模态、不同时效性的信息融合,核心目标是在开放环境中最大化收益的同时管控市场风险。
2. 现有方法的局限性
- 风险控制短板:现有 LLM 金融智能体(如 FINGPT、FINAGENT)依赖短期市场波动设定风险偏好,缺乏基于量化金融的长期风险管控机制。
- 任务适配单一:多数系统局限于单资产交易,难以支撑投资组合管理等多资产复杂场景。
- 信息处理效率低:单智能体架构需在有限上下文窗口中处理多源信息,易导致决策质量下降;多智能体系统则存在通信成本高、决策迟缓的问题。
- 学习机制不足:缺乏通过经验精炼持续优化决策的有效机制,难以适应市场动态变化。
3. 研究目标
设计一款基于 LLM 的多智能体框架 FINCON,通过模拟真实投资机构的层级结构,实现多源信息高效融合、双级风险精准管控,同时支持单资产与多资产金融决策任务。
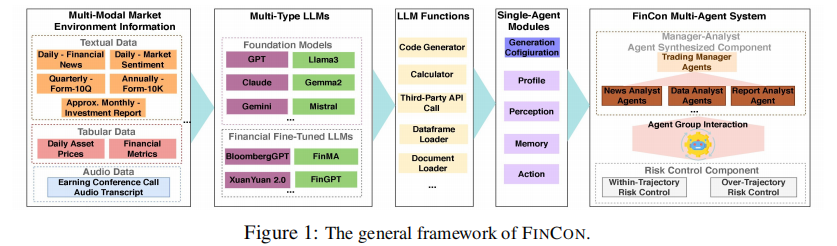
二、核心创新与整体架构
1. 核心创新点
- 提出合成经理 - 分析师层级通信结构,模拟真实投资公司职能分工,降低冗余通信成本。
- 设计双级风险控制组件,结合 episode 内风险监控与 episode 间信念更新,实现动态风险管控。
- 引入概念性语言强化机制(CVRF),通过文本梯度下降优化提示词,实现决策经验的有效传递。
- 首次实现 LLM 多智能体在投资组合管理任务中的有效应用,突破现有系统的任务边界。
2. 整体架构概览
FINCON 的架构由两大核心组件构成:经理 - 分析师智能体组(Manager-Analyst Agent Group)和风险控制组件(Risk-Control Component),整体框架如图 2 所示。
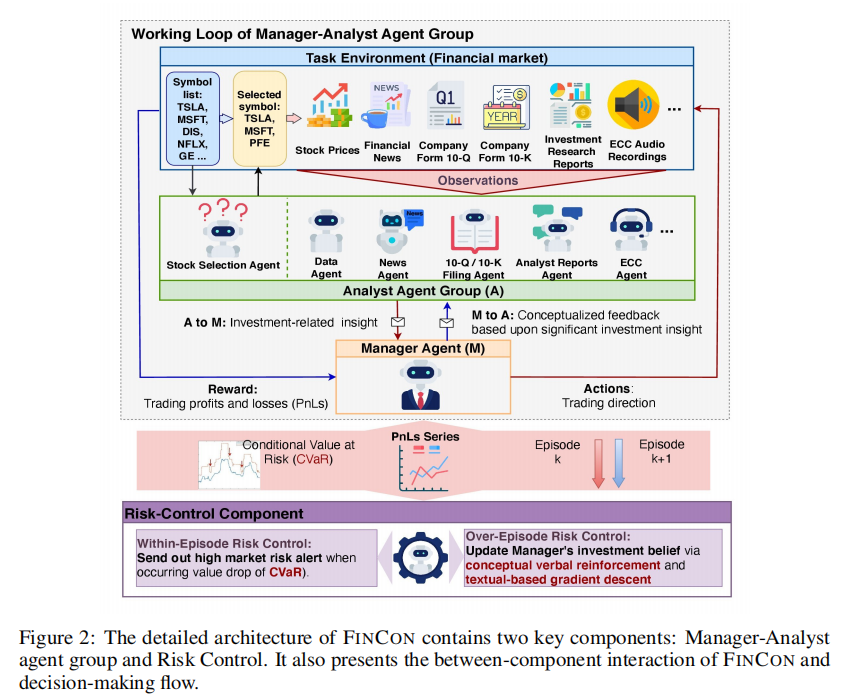
其核心工作流程为:
- 多模态市场数据(股票价格、新闻、财报、会议音频等)输入至对应专业分析师智能体;
- 分析师智能体提炼关键投资洞察,传递给经理智能体;
- 风险控制组件实时监控市场风险并更新投资信念,提供语言强化信号;
- 经理智能体整合洞察与风险信号,生成交易决策(买卖持有 / 组合权重分配);
- 交易结果(PnL)反馈至风险控制组件,用于后续信念更新与提示词优化。
三、任务建模与数学基础
1. 核心金融任务形式化
FINCON 支持两类核心金融任务,均基于部分可观察马尔可夫决策过程(POMDP)建模。
(1)单股票交易任务
- 分析师智能体组处理多模态市场信息,输出文本化洞察;
- 经理智能体基于洞察生成交易动作(买 / 卖 / 持有),其中 “卖” 包含卖空操作(允许负头寸);
- 风险控制组件每日评估投资风险,优化经理智能体提示词。
(2)投资组合管理任务
- 分析师智能体额外需基于股票收益相关性构建股票池;
- 经理智能体通过均值 - 方差优化求解组合权重,公式如下:
其中,w 为组合权重向量,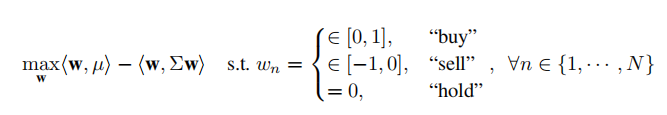
为预期收益收缩估计量,
为协方差矩阵收缩估计量,组合权重每日重新平衡。
2. POMDP 建模量化交易
FINCON 将量化交易建模为无限时域 POMDP,核心组件定义如下:
- 状态空间:
(
为可观测市场状态,
为不可观测状态);
- 动作空间:分析师智能体输出文本化处理结果,经理智能体输出交易动作(单资产:
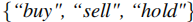 ;多资产:
;多资产: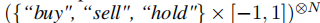 ;
; - 奖励函数:以每日盈亏(PnL)为输出;
- 观测过程:多维度单模态信息流,由对应分析师智能体处理;
- 反射过程:经理智能体的自我反思,每日更新;
- 优化目标:最大化累积交易奖励的同时控制风险,通过语言强化优化智能体策略。
四、关键模块详细解析
1. 经理 - 分析师智能体组
模拟真实投资机构的职能分工,实现专业化协作与高效通信。
(1)分析师智能体(Analyst Agents)
- 核心职责:从特定来源的单模态数据中提炼简洁投资洞察,过滤市场噪声。
- 类型与分工:共 7 类分析师智能体,覆盖多模态数据处理:
- 文本类:3 个专注于财经新闻、分析师报告的情感分析与洞察提取;
- 音频类:通过 Whisper API 解析财报电话会议录音中的投资信号;
- 数据类:计算动量、CVaR 等关键金融指标;
- 选股类:基于量化金融的风险分散方法构建投资组合股票池。
- 设计优势:单模态专业化处理降低任务负载,提升洞察质量;不同智能体设置差异化的程序性记忆衰减率,适配不同金融数据的时效性要求。
(2)经理智能体(Manager Agent)
- 核心职责:唯一决策主体,整合多源洞察生成交易决策,实现跨 episode 学习。
- 决策支撑机制:
- 整合分析师智能体的精炼洞察;
- 接收风险控制组件的实时风险警报与概念性投资信念更新;
- 提炼投资信念,明确不同信息源对交易决策的影响权重;
- 自我反思:回顾历史交易推理过程与结果。
- 组合管理能力:通过凸优化技术,结合方向交易决策求解最优组合权重。
2. 双级风险控制组件
创新设计 episode 内与 episode 间两层风险管控机制,兼顾短期风险应对与长期策略优化。
(1)Episode 内风险控制(Within-Episode Risk Control)
- 核心指标:条件风险价值(CVaR),即最坏 1% 日盈亏的平均值,用于量化极端风险。
- 触发机制:当 CVaR 值突然下降(表明近期交易进入最坏表现区间),触发风险警报。
- 应对策略:经理智能体当日采用风险规避姿态,调整交易动作以减轻潜在损失。
- 适用场景:训练与测试阶段均有效,适配牛熊市及混合市场趋势。
(2)Episode 间风险控制(Over-Episode Risk Control)
- 核心机制:概念性语言强化(CVRF),通过跨 episode 性能对比更新投资信念。
- 实现流程:
- 收集连续训练 episode 的交易轨迹、盈亏序列与推理过程;
- 对比不同 episode 的性能差异,提炼概念化洞察(如 “动量指标阈值调整”“新闻情感量化”);
- 通过文本梯度下降优化提示词,将信念更新传递给经理及相关分析师智能体;
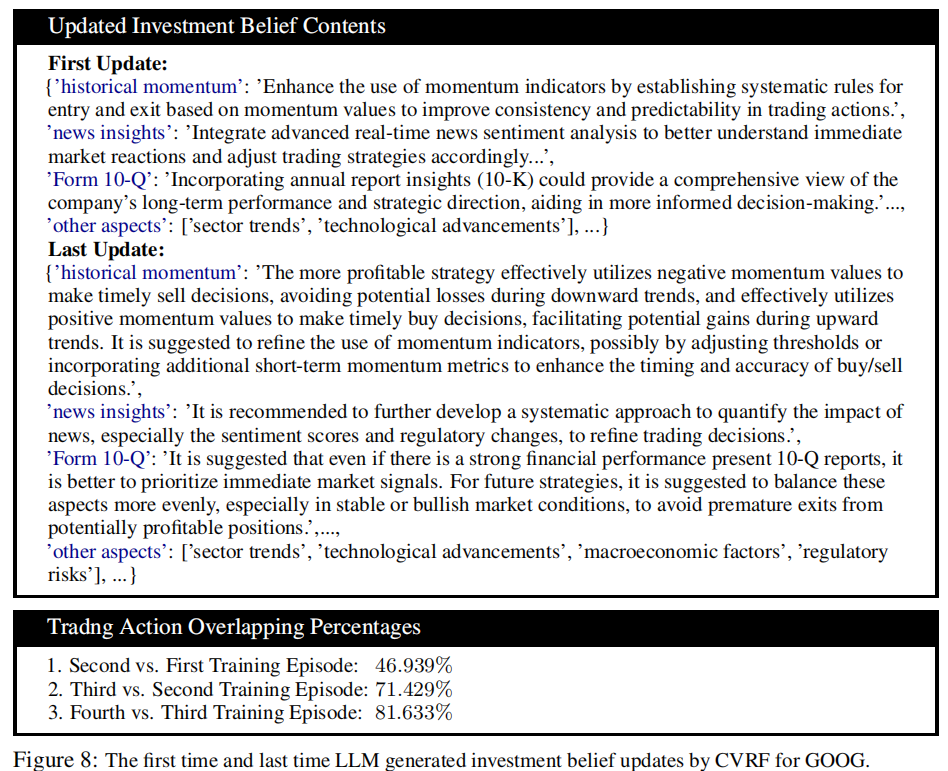
- 学习率计算:基于连续 episode 交易决策序列的重叠百分比(替代传统文本编辑距离),确保更新稳定性。
- 关键优势:仅在训练阶段运行,通过少量 episode(4 个)即可实现显著学习增益,远超传统 RL 算法的训练效率。
3. 智能体模块化设计
每个智能体整合四大功能模块,结合记忆机制实现类人认知与决策能力,模块结构如图 4 所示。

(1)通用配置与角色建模模块
- 定义任务类型(单股票交易 / 组合管理)、交易目标(行业、绩效要求);
- 明确每个智能体的角色职责(如 “新闻分析师”“交易经理”),生成文本化查询用于记忆检索。
(2)感知模块
- 信息输入:市场原始数据、其他智能体反馈、记忆检索结果;
- 格式转换:将多源信息转换为 LLM 可处理格式,确保跨模态信息兼容;
- 通信机制:分析师→经理传递洞察,经理→分析师传递反馈。
(3)记忆模块
采用三层记忆结构,适配不同时效性与重要性的信息存储需求:
- 工作记忆:实时处理观察、提取、精炼信息,支撑即时决策;
- 程序性记忆:记录每个决策步骤的动作、结果与反思,按时效性衰减(不同智能体衰减率不同);
- 情景记忆:仅经理智能体具备,存储历史 episode 交易轨迹、盈亏序列与更新后的投资信念。
- 记忆检索:基于相关性(文本嵌入余弦相似度)与重要性(时间衰减模型)评分,检索 Top-K 关键记忆事件。
(4)动作模块
- 经理智能体:生成交易动作,评估分析师智能体贡献度;
- 分析师智能体:输出精炼投资洞察、金融情感评分及推荐交易方向。
3. 文本梯度下降优化
FINCON 采用提示词优化替代传统模型参数更新,通过文本语义 “梯度” 实现策略迭代,与传统梯度下降的对比如表 1 所示。

- 核心思想:通过 LLM 的自我反思能力,生成 “语义梯度信号”(如 “增加短期动量指标权重”),替代显式梯度;
- 元提示设计:指导 LLM 基于历史盈亏与推理过程,修改任务提示词以提升决策质量;
- 优势:无需模型微调,仅通过提示词更新即可适配市场变化,降低计算成本。
五、实验设计与结果分析
1. 实验设置
(1)数据集
- 时间范围:2022 年 1 月 3 日 - 2023 年 6 月 10 日;
- 数据类型:多模态金融数据,包括股票价格(Yahoo Finance)、财经新闻(Refinitiv)、财报(10-K/10-Q,SEC EDGAR)、财报电话会议音频(ECC);
- 数据分配:基于时效性分配给对应分析师智能体(如日报→新闻分析师,年报→财报分析师)。
(2)评估指标
- 核心指标:累积收益率(CR%)、夏普比率(SR)—— 衡量收益与风险调整后收益;
- 辅助指标:最大回撤(MDD%)—— 衡量极端损失风险。
(3)对比方法
- 单股票交易:3 类 DRL 算法(A2C、PPO、DQN)、4 类 LLM 智能体(GA、FINGPT、FINMEM、FINAGENT)、买入持有策略(B&H);
- 投资组合管理:Markowitz 均值 - 方差模型、FinRL-A2C、等权重 ETF 策略;
- 实验配置:所有 LLM 基于 GPT-4-Turbo(温度 = 0.3),FINCON 训练期(2022.1.3-2022.10.4),测试期(2022.10.5-2023.6.10);DRL 算法训练期延长至 5 年(2018.1.1-2022.10.4)以保证收敛。
2. 核心实验结果
(1)单股票交易任务性能
FINCON 在 8 只股票(含 AAPL、GOOG、NFLX、COIN 等)的测试中,全面超越对比方法,关键指标如表 2 所示。
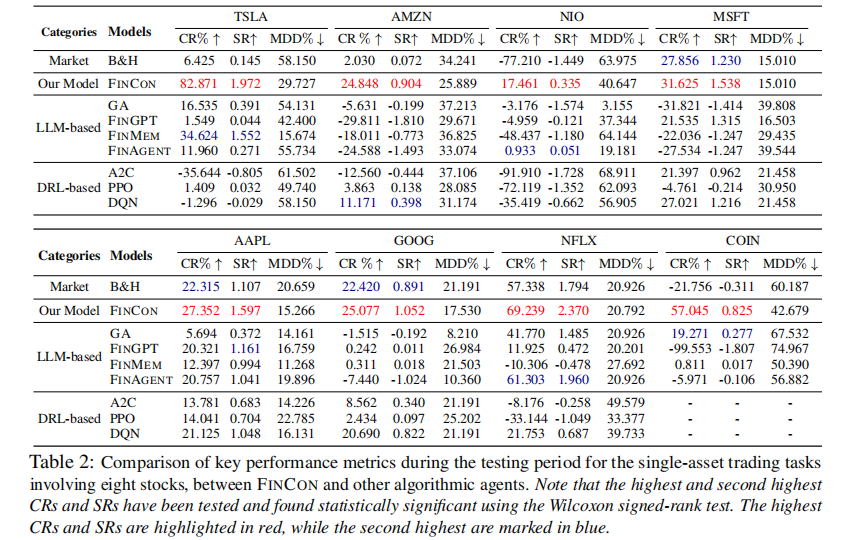
关键结论:
- FINCON 在所有股票的 CR 和 SR 指标上均显著领先,MDD 保持较低水平,实现 “高收益 + 低风险” 平衡;
- 对 IPO 较近(如 COIN,2021 年上市)的股票,DRL 算法因数据不足难以收敛,而 FINCON 凭借多模态信息处理能力,实现 57.045% 的累积收益;
- 在牛市(GOOG)、熊市(NIO)和混合市场(TSLA)中均表现稳定,验证了跨市场适应性。
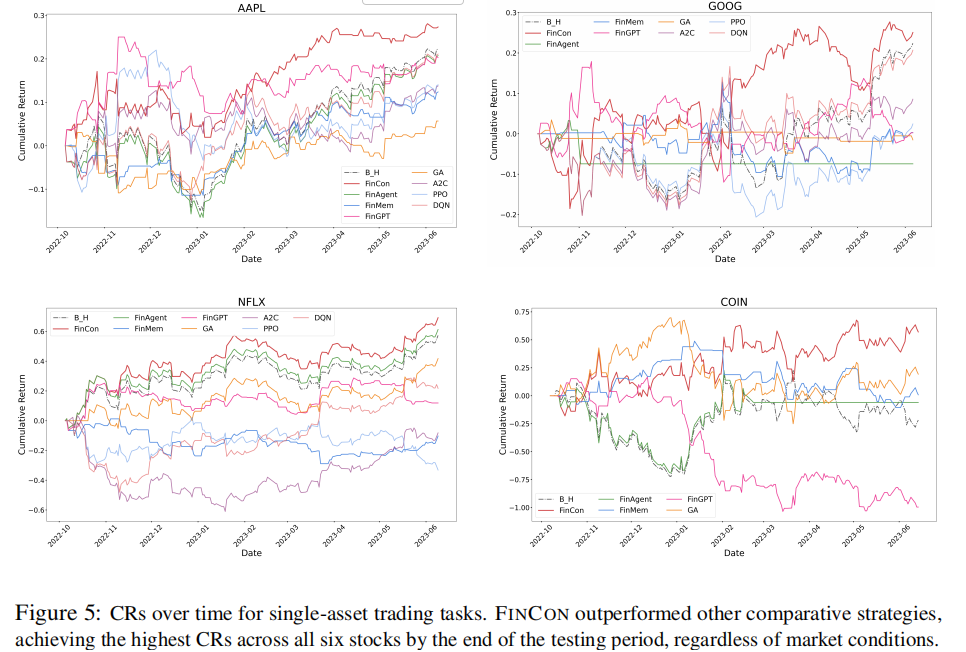
单股票交易的累积收益率时序变化如图 5 所示(部分,全图可以查看原文),FINCON 始终保持领先态势。
(2)投资组合管理任务性能
测试两个小型组合(组合 1:TSLA、MSFT、PFE;组合 2:AMZN、GM、LLY),性能对比如表 3 所示。
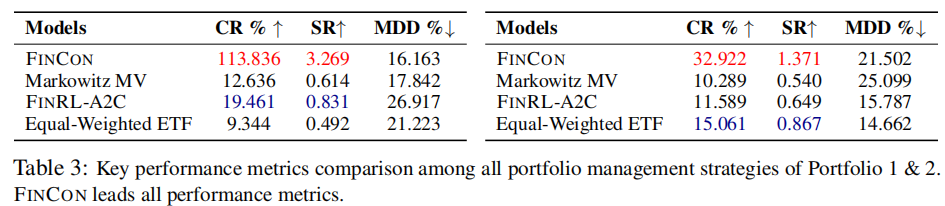
组合价值时序变化如图 3 所示,FINCON 的组合增值速度显著快于对比方法。
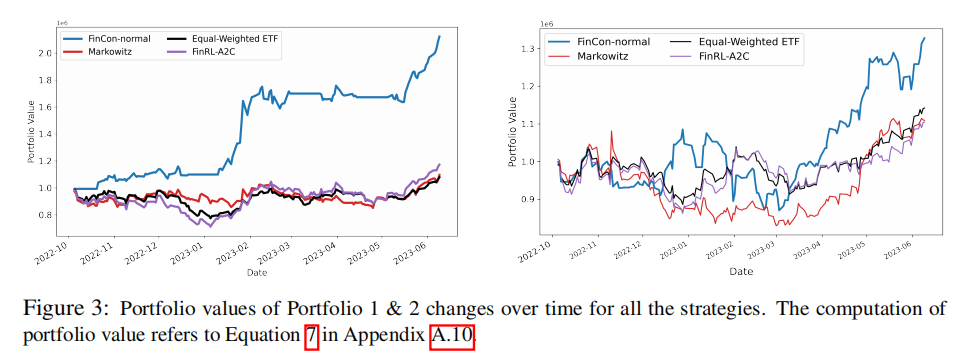
关键结论:
- FINCON 的 CR(32.922%)是 Markowitz MV 的 3 倍以上,SR(1.371)显著高于其他策略,验证了多资产管理能力;
- 尽管组合管理因输入复杂度高易出现 LLM 幻觉,但 FINCON 通过专业化分工与记忆机制,有效降低了错误率;
- 突破现有 LLM 金融智能体的任务边界,首次实现组合管理的高效求解。
3. 消融实验验证
通过两组消融实验,分别验证双级风险控制机制的有效性。
(1)Episode 内风险控制(CVaR)有效性
对比 FINCON 有无 CVaR 机制的性能差异,结果如表 4 所示。
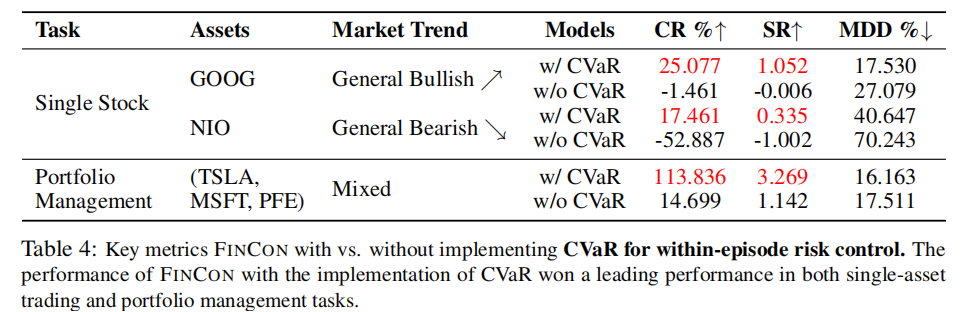
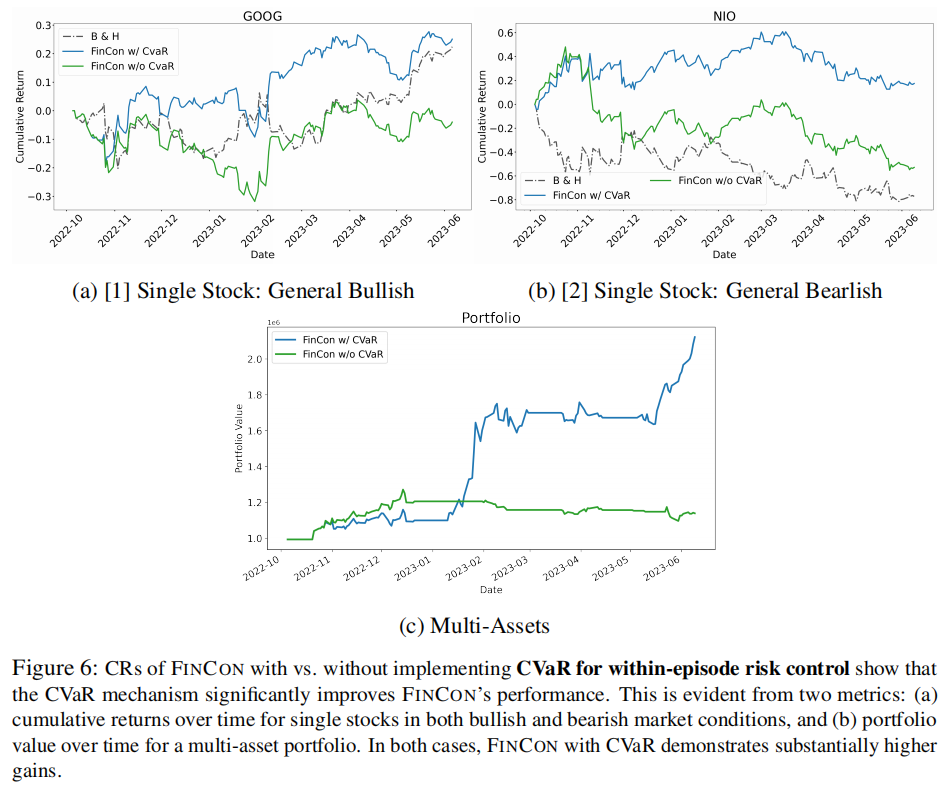
时序对比如图 6 所示,CVaR 机制显著提升了不同市场环境下的收益稳定性。
关键结论:
- 无 CVaR 机制时,单股票交易出现负收益,组合管理收益从 113.836% 降至 14.699%;
- CVaR 能有效捕捉极端风险,在牛市中避免过度乐观,在熊市中控制损失扩大,在混合趋势中稳定组合价值。
(2)Episode 间信念更新(CVRF)有效性
对比 FINCON 有无信念更新机制的性能差异,结果如表 5 所示。
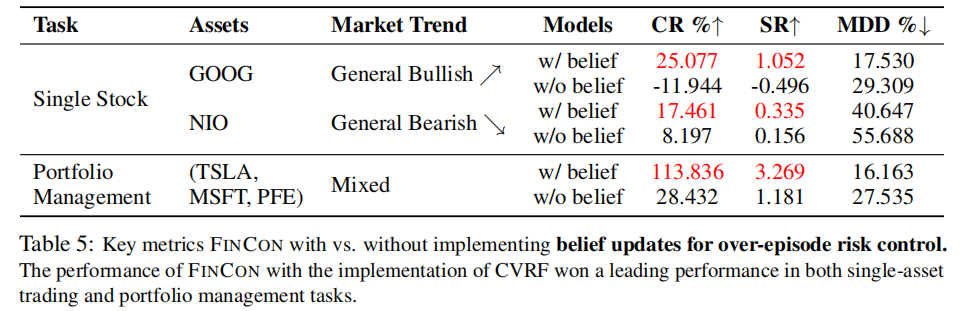
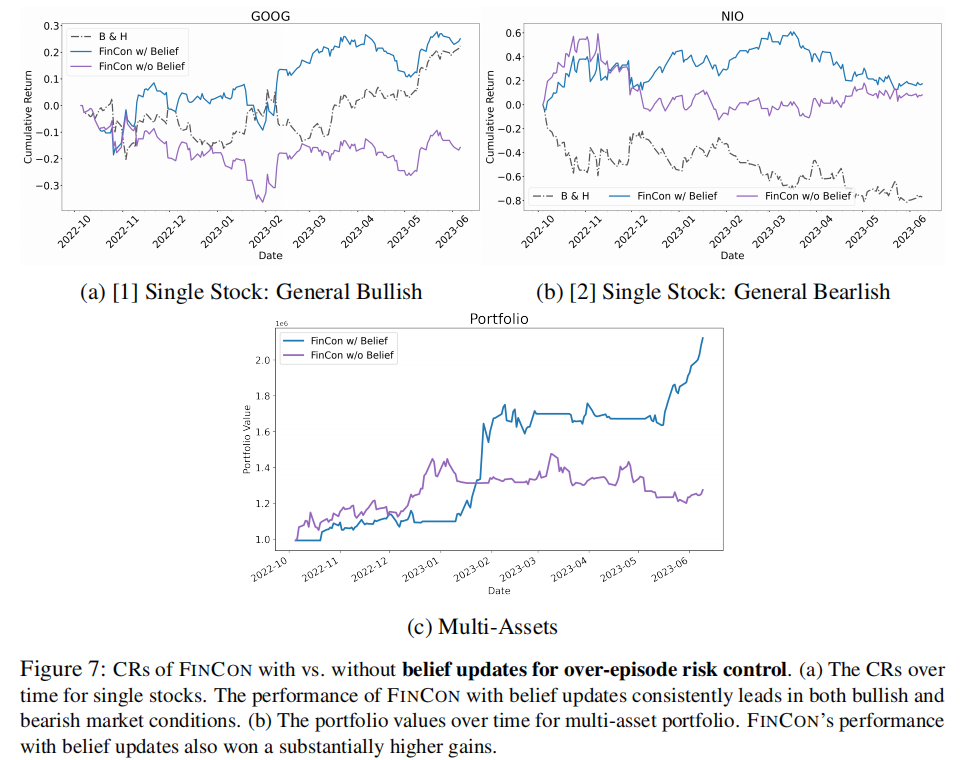
时序对比如图 7 所示,信念更新机制带来了显著的性能提升。
关键结论:
- 信念更新机制对性能的提升作用超过 CVaR,无该机制时,单股票交易 CR 下降超 30%,组合管理 CR 从 113.836% 降至 28.432%;
- 经过 4 个训练 episode,交易决策序列重叠百分比从 46.939% 提升至 81.633%,信念更新逐渐收敛并趋于最优;
- 信念内容从抽象原则(如 “建立动量指标规则”)进化为可执行策略(如 “调整动量阈值捕捉涨跌趋势”),如图 8 所示。
4. 极端市场条件测试
在高波动市场(VIX 指数 > 20,2022 年 4 月 - 10 月)中测试 TSLA 单股票交易与组合管理性能,结果如表 7、表 8 所示。
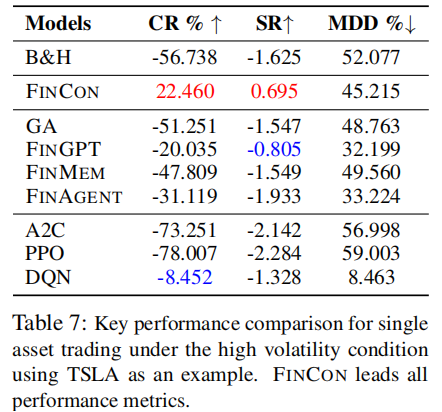
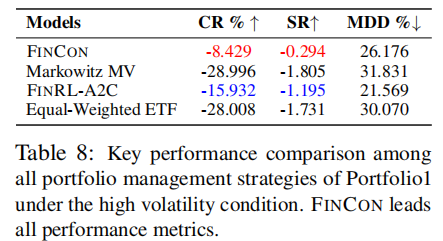
关键结论:
- 高波动环境中,FINCON 是唯一实现正收益(TSLA 单股票 CR=22.460%)的智能体;
- 组合管理中,FINCON 的亏损幅度(-8.429%)远低于其他策略(最低 - 28.996%),验证了极端风险抵御能力;
- 证明双级风险控制机制与多智能体协作架构在复杂市场环境中的鲁棒性。
六、研究贡献与局限
1. 主要贡献
- 架构创新:提出合成经理 - 分析师层级结构,模拟真实投资机构分工,降低通信成本,提升信息处理效率。
- 风险控制突破:设计双级风险控制机制,结合 CVaR 实时风险监控与 CVRF 信念更新,实现长短周期风险全覆盖。
- 任务扩展:首次将 LLM 多智能体应用于投资组合管理,突破现有系统的单资产局限。
- 学习机制优化:通过文本梯度下降与概念性语言强化,实现少量 episode 快速学习,提升训练效率。
- 性能验证:在单股票交易、组合管理及极端市场条件下,全面超越 LLM 与 DRL 基线模型。
2. 研究局限
- 组合规模限制:当前仅支持小型组合(3 只股票),扩展至数十只资产时面临 LLM 上下文窗口约束。
- 幻觉问题:多资产决策中仍存在少量记忆事件索引错误等幻觉,需进一步优化信息蒸馏精度。
- 数据依赖:对多模态数据的质量与时效性要求较高,低资源市场(如新兴市场)的适配性有待验证。
- 计算成本:多智能体协作与文本梯度下降仍需一定计算资源,实时高频交易场景的适配性需优化。
七、未来研究方向
- 大规模组合管理:优化信息蒸馏与上下文压缩技术,平衡信息完整性与窗口限制,支持数十只资产的组合管理。
- 幻觉抑制:结合知识图谱与事实核查工具,增强智能体对金融数据的事实性判断能力。
- 多市场适配:扩展数据集至新兴市场,优化记忆衰减率与风险指标,提升跨市场适应性。
- 实时性优化:简化通信流程与信念更新机制,降低延迟,适配高频交易场景。
- 人机协作:引入人类专家反馈模块,实现智能体决策与人类经验的融合,提升实际应用价值。
八、总结
FINCON 通过创新的多智能体层级架构、双级风险控制机制与概念性语言强化技术,构建了一个高效、鲁棒的金融决策系统。其核心优势在于模拟真实投资机构的专业化协作,实现多源信息的精准整合与动态风险的有效管控,同时突破了现有 LLM 金融智能体的任务边界。实验结果表明,FINCON 在单股票交易、投资组合管理及极端市场条件下均表现卓越,为 AI 赋能金融决策提供了全新范式。未来随着组合规模扩展、幻觉抑制与实时性优化,FINCON 有望在实际金融市场中实现规模化应用,推动智能投顾与量化交易的技术革新。
更多推荐

 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)