
测试DeepSeek-V3.2-Exp-Thinking模型后的体验
公司接入DeepSeek-V3.2-Exp-Thinking大模型后,体验远超预期。该实验版模型在V3.1基础上创新引入DeepSeekSparseAttention技术,大幅降低长文本处理成本。测试中发现其具备三层优势:强大的推理能力、灵活的思考模式切换及高效的长文本处理能力,能自然理解中文语境中的幽默与文化内涵。相比其他模型,它完美平衡了性能与成本,使企业能大规模应用于实际工作流。这款中国自主
最近,公司正式接入了传说中的 DeepSeek-V3.2-Exp-Thinking 大模型。(我们这边默认开 reasoning,就习惯叫 DeepSeek-V3.2-Exp-Thinking)
在于DING博士整体测试该模型后,感知不少,最想说的是【中国力量,真香】。

这是 DeepSeek 官方在 2025 年 9 月底刚放出来、作为下一代架构过渡版本的实验模型。
说真的,现在随口一句“我们在用 DeepSeek”,已经完全不够用了——就跟你跟别人说“我们用 iPhone”,结果对方追问:“是 6 还是 16 Pro Max?”一个道理。
DeepSeek 这一路真的在狂飙升级,
-
V2.5 时代:把原来的 Chat 模型和 Coder 模型合体,搞出了一个既会聊天又会写代码的 All-in-One 模型 DeepSeek-V2.5,还开源了权重,中文能力和编码能力都很能打。
-
V3 时代:直接上了一个 671B 参数的 MoE巨兽,每个 token 只激活其中约 37B 参数,靠自家的 Multi-head Latent Attention(MLA)+ DeepSeekMoE,把推理成本压下去,同时在 14.8T 高质量数据上训出来,在很多基准上已经逼近闭源顶级模型。
-
R1 时代:又单独搞了一条“推理优先”的路线 DeepSeek-R1,用大规模 RL 做后训练,数学、代码、推理对标 OpenAI-o1,而且整套技术报告和模型都开放出来。
-
V3.1 时代:在 V3 基础上 继续预训练 840B token,把上下文拉到 128K,同时提示了“Think / Non-Think 双模式”:同一个模型里既有“正常聊天模式”,也有“深度思考模式”,对工具调用、多步 Agent 任务做了很多强化。
然后,轮到我们这次的男主角登场了:
DeepSeek-V3.2-Exp:在 V3.1-Terminus 基础上,新增 DeepSeek Sparse Attention(DSA),专门为长上下文效率开刀的实验版架构。Hugging Face+1
官方自己都说,这是 通往下一代架构的中间版本,不是简单“调个参”,而是在注意力层动了大手术,让长上下文推理的算力和价格都大幅下降——甚至在长上下文场景下,API 成本可以砍到原来的一半左右。
我们公司接入的,就是这个 V3.2-Exp + reasoning 打开 的组合,所以我在文里统称它为:
DeepSeek-V3.2-Exp-Thinking:最新一代、带显式推理链路的 Sparse Attention 版本。
故事从一次旅游计划开始。
刚好朋友在计划一起去成都玩,我联想到公司最近刚接入的模型,突发奇想:
“要不让 DeepSeek-V3.2-Exp-Thinking 当一回旅行策划师?”
结果模型没有直接开写行程,而是先抛出了一连串关键问题:
-
团队大概多少人,要不要提前订位甚至包一小块场地?
-
人均预算在哪个档位,午晚餐是走“体验型”还是“性价比型”?
-
大家说的“科技感”到底是想看酷炫互动装置,还是数字艺术展,还是那种硬核技术体验?
-
以及一个人类常常会忽略的问题:你们的腰和腿,到底能不能撑住一天到处跑?
看到这里我们几个直接愣住了——你说这像在跟一个模型聊,还是在和一个认真做需求澄清的旅行策划师开会??!!
这一下把我们问愣了:

——“你一个模型怎么比真人还会问问题?”
当然,这种普通的旅行计划任何4级以上的模型都能做到,但是他的Thinking能力让我有些跃跃欲试了。
于是。。。。。。。
我随手问它一句段子—— 「我妈只打我三次:一次冬天,一次夏天,一次从小到大。」 这类梗在中文互联网太常见了,普通模型要么一句“这是夸张修辞,表示经常挨打”就草草带过,要么立刻切换成家庭暴力宣讲模式,完全带不动笑点。 DeepSeek 的回答明显不在一个档次:它先抓到真正的问题点——前两次是“冬天 / 夏天”这种普通时间点,最后那句“从小到大”直接把整个成长阶段打包成了一次,这种时间维度错位本身就是笑点的来源。 在这个基础上,它没有停在“这是夸张”这种教科书级别解释,而是继续往上提炼:告诉你“只打三次”其实是反话,真正的含义是“从小到大一直在挨打”,然后顺手把这一类挨打梗总结成一个模板——前面用几个正常次数麻痹你,最后扔出一个把整段人生包进去的时间段当“最后一次”。 更妙的是,它还会主动把这句话放回中文语境里,聊到这种说法背后是中国家庭里那种半开玩笑的“棍棒教育回忆”,举了“只打两顿:早饭和晚饭”之类的相似表达,最后再用两三句话收束成一个任何人都看得懂的解释版本。
或者说,当你问一个需要复杂推理的问题时(如“分析一段代码”、“总结一份报告的主旨”),它会进入深度思考模式。你得到的不是一个仓促的结论,而是一份逻辑完整、层次分明的分析报告。当你只需要快速问答时,它又能秒切回简短模式。
对我们而言,有个非常直观的感受,就是它不会“一根筋”。需要深度思考时,它表现得像一位严谨的学者,而需要效率时,它表现得像一位敏捷的助手,这种模式切换带来的输出质量和速度平衡,是极佳的产品体验。


此外,我们还尝试对了对长文本文件内容的解析测试,对比以前用 AI 摘要或分析长篇文档(比如 50 页 PDF)时,用户需要自己手动分段上传,或者担心模型读到后面就忘记开头信息。DeepSeek-V3.2-Exp 通过 DSA 机制,在我们的测试使用过程中,彻底解决了这个问题。你可以一股脑地把所有文档扔给它,不必担心长度限制或关键信息被遗漏。它像拥有超长待机记忆力,能够精准地在长篇大论中,提取到散落在各处的核心论点、数据和结论,让长文档处理变得简单了很多。
其实这样的例子有很多,但如果你真的想了解这个模型,那我告诉你。
如果把 DeepSeek-V3.2-Exp-Thinking 拆开看,其实它身上是叠了三套“人格”的:
-
第一层是 「大脑本体」: 背后继承的是 DeepSeek-V3 / V3.1 那条巨兽系谱——MoE 结构、671B 量级总参数、合理控制的激活参数,再叠加上一整套 RL 推理和工具使用对齐。简单讲,就是这颗脑袋本来就不笨,逻辑、数学、代码、阅读理解,在我们日常用下来都很抗打。
-
第二层是 「双档思考模式」: 很多家是把 Chat 和 Reasoner 做成两台模型,切来切去非常痛苦;DeepSeek 是在一台模型里做了 Think / Non-Think 两种 prompt 模式。我们现在接的是默认打开 Thinking 档,所以你会经常看到它不是一句话拍脑袋,而是习惯性地“先拆问题再给结论”。更妙的是,它不是那种“强行 dump chain-of-thought”式的碎碎念,而是会自动结构化:像刚才解释段子的那一条,它会自己整理成「字面意思 → 真正含义 → 段子模板 → 文化语境」这么四段,看着就很像一个有教学意识的语文老师。
-
第三层是 「长文本专注力」: 这就是 V3.2-Exp 的主修课了——官方搞了一个叫 DeepSeek Sparse Attention(DSA)的注意力机制,配套一个 Lightning Indexer。你可以把它想象成一个“先用高速浏览器扫一遍,再把需要认真读的句子圈出来”的过程:
-
在 128K 这么长的上下文里,它不会傻乎乎地对每个 token 都算 full attention,而是先用一个轻量索引器快速打分,筛出“候选重点”;
-
然后再从这些候选里做细粒度选择,真正进入注意力窗口的其实只是少数关键 token。 换成人话就是:它不会对每个字都上纲上线,而是懂得“有的字值得反复掂量,有的字扫一眼就够了”。
-
这三层叠在一起,你能感受到的那种“既能认真想,又不容易拖垮性能,还懂中文语境”的体验,其实不是一个特性带来的,而是架构 + 训练 + 推理策略三重叠加带来的综合效果。
更现实一点说:
我们在内部做了一件很粗暴的事——把之前用过的一些大模型按“能不能扛 50 页 PDF + 中文语感顺不顺 + 价格能不能接受”三个维度拉表格,DeepSeek-V3.2-Exp-Thinking 是那个唯一不需要打折扣的:
-
长文档,它靠 DSA 确实扛得住,不用切七八段;
-
中文内容,它不是“能勉强看懂”,而是能把段子、语气、网络用语都读出门道;
-
成本上,它又不是那种“只能少量体验”的旗舰价位,我们是真敢把它接进生产工作流天天薅的。
所以你说它强大,不只是“推理厉害”这一条的强,是那种——你把几种原来不可能放在同一颗脑子里的要求往上堆,它居然一股脑接下来了。
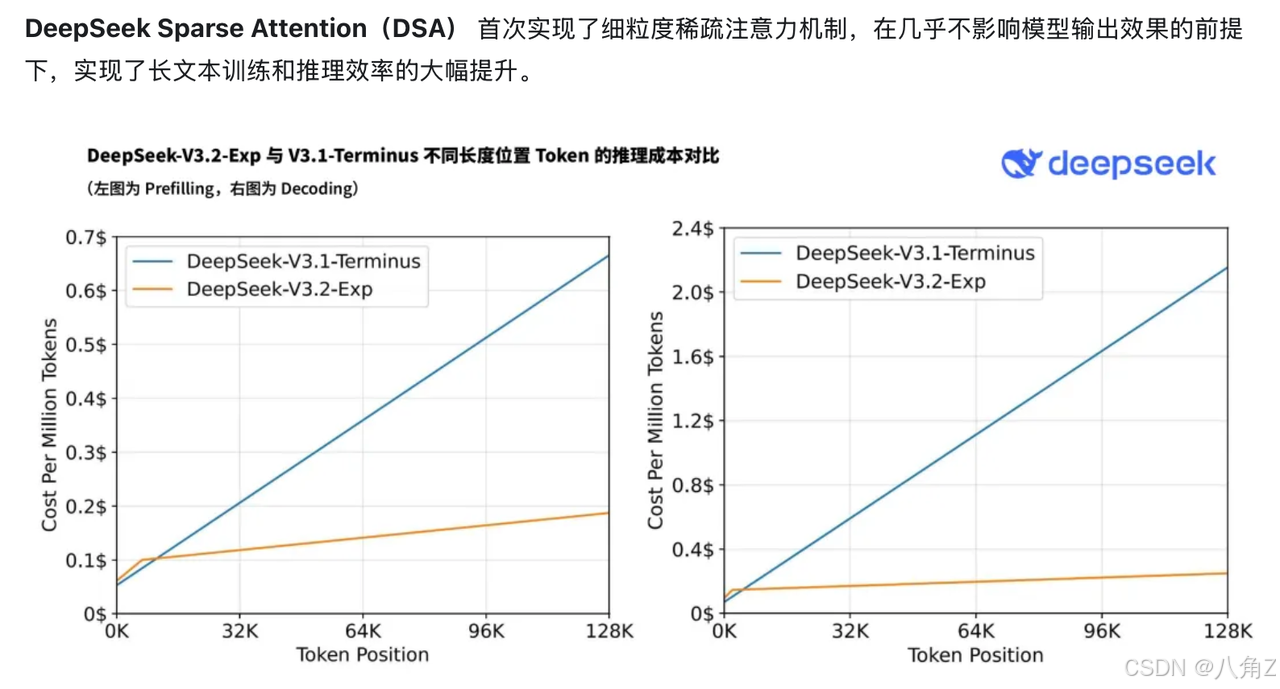
还是那句话,“你可以找很多会 Think 的,也可以找很多长上下文的,但要在中文场景里,把这几件事压在同一个模型上跑、每天真用,我们目前只敢说:DeepSeek-V3.2-Exp-Thinking 是这条线上的独一档。”
其实,最后想说的,也是大家都关注的,就是它的高性能与合理成本。许多顶级模型性能虽强,但价格昂贵,用户只能“浅尝辄止”或用于关键任务。DeepSeek 通过 MoE 架构,在保证顶级性能的同时,将激活成本控制在一个可大规模负担的水平。对企业而言,大规模使用,真的不用太担心“价格焦虑”,可以大面积将它集成到日常的、高频的生产工作流中。
最后再想说一句【中国力量,真香】。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)