
智能体AI架构全方位解析:核心组件、安全设计与最佳实践
本文是一份面向智能体AI架构的实操指南,详细介绍了智能体AI架构的核心概念、控制循环、拓扑结构及关键组件。文章从架构设计、工具集成、记忆库管理、安全策略到部署运维,全面阐述了如何构建安全可靠的大模型智能系统,并对比了LangGraph、CrewAI等主流框架,为开发者提供了从理论到实践的生产级实现路径。
本文是一份面向智能体AI架构的实操指南,详细介绍了智能体AI架构的核心概念、控制循环、拓扑结构及关键组件。文章从架构设计、工具集成、记忆库管理、安全策略到部署运维,全面阐述了如何构建安全可靠的大模型智能系统,并对比了LangGraph、CrewAI等主流框架,为开发者提供了从理论到实践的生产级实现路径。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
本文是一份面向智能体AI架构的实操指南,包含组件、护栏、依赖注入、验证、部署、可观测性,并附带对 LangGraph、CrewAI 和云技术栈的说明。
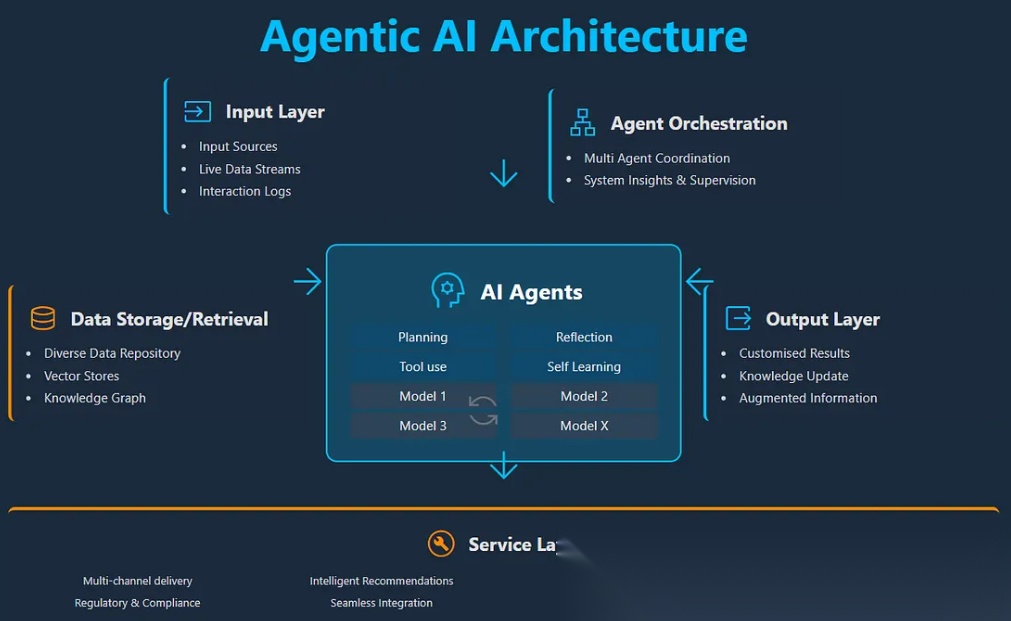
智能体人工智能架构
1 什么是智能体AI架构
智能体AI架构(Agentic AI Architecture)是一种软件系统,其中自主(半自主)的智能体,通过“规划行动→调用工具→观察结果→更新自身认知”循环重复执行,直到达成目标时,满足安全或策略约束的管理。可将其视为一名 AI“操作员”,能够分解任务、适时调用合适的服务、自检工作,并在高风险环境下完成或请求帮助(例如人工审核)。
为何如此重要
传统机器学习(ML)在输入输出固定时表现优秀。现代企业的共同难题:分类处理支持工单、对账交易、生成合规文档,具有开放性,需要调用多个数据源,且需完善的约束机制。智能体AI架构带来“结构”(规划、状态、策略),以安全且可重复的方式利用大模型(LLMs)。
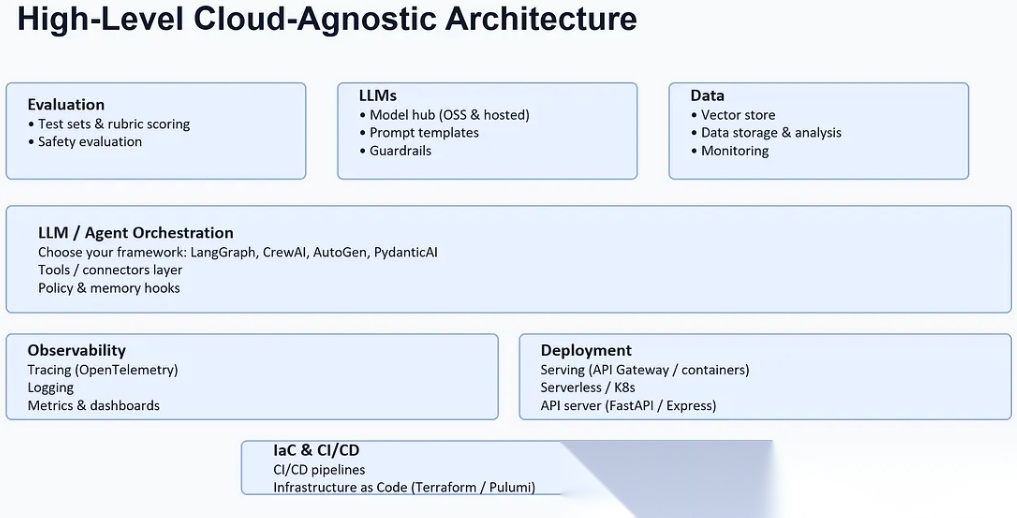
高级云不可知(云无关)架构
控制循环速览:
1 计划:将目标拆解为步骤(如:检索订单 → 核对政策 → 提出解决方案)
2 行动:调用一个或多个工具(如应用程序接口API、数据库、搜索工具、代码运行器)
3 观察:捕获结果及异常情况
4 反思/决策:验证输出结果、更新记忆/状态,随后要么继续循环,要么终止流程。
5 合规:在每个环节都遵守约束机制(包括隐私、成本、安全方面的约束)。
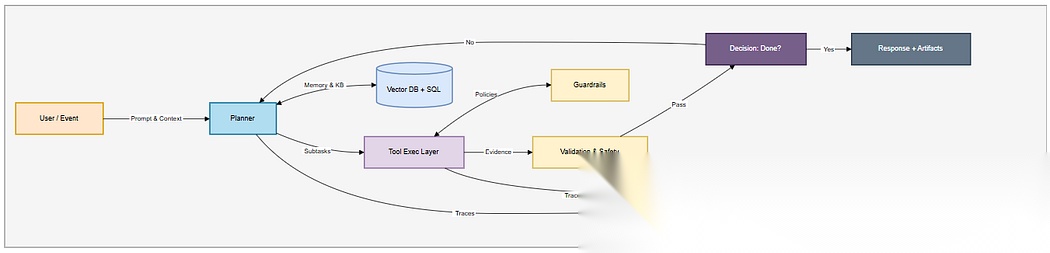
高级数据流
关键术语(从业者视角)
智能体:决策者,通常由大模型驱动,根据目标、上下文和策略决定下一步,在客服中心场景中,智能体可能会先获取客户最近三笔订单,再开始回复。
规划者/实践者:工作流的“工头”,可以把工作流的目标转为一系列步骤,并把工作任务分发给合适的角色或子智能体。可根据观察到的新信息动态,从而调整计划。
推理者:智能体的“内审员”,会进行有限思维链(bounded chain-of-thought)分析,检查矛盾并润色草稿,优秀的系统会限制反思时长,以控制成本与延迟。
工具/技能:智能体可被调用的外部能力:REST / GraphQL 应用程序接口APIs、数据库查询、搜索/检索、代码执行、邮件/日历工具、云软件开发工具包(SDK)等,每个工具需有清晰的协议与权限范围。
验证者/评估者:负责执行确定性检查(如数据模式、业务规则、个人身份信息(PII)/ 数据防泄漏(DLP)检查)和可选的学习型评判(如质量评分器),确保输出可用、安全且符合契约。
编排运行时:执行引擎,负责运行计划、管理重试和超时机制、持久化检查点,并支持人工介入的协同中断,通过该行为,可确保系统能从部分故障中恢复。
策略/约束机制:执行通行规则,工具与域名的允许/禁止清单、隐私与数据驻留控制、成本上限、速率限制、以及高风险操作的升级路径。
记忆库:
- 短期记忆:当前任务的工作上下文(如对话轮次、计划状态)
- 长期记忆:知识库,如向量数据库(用于语义检索)、结构化查询语言(SQL,用于存储事实与台账)、图数据库(用于存储关系与路径)。
- 情景日志:记录过往运行的完整经过,可用于审计与学习。
拓扑结构(及使用场景)
单智能体
- 适用场景:护栏清晰、聚焦目标的专注工作流(如带检索的文档摘要);
- 优势:构建与观测更简单,组件更少;
- 注意事项:若承担过多职责,可能会沦为“全能智能体”(god-agent),导致功能臃肿。
层级式:
- 适用场景:角色明确的多步骤流程(如,规划者→研究员→审核员的协作流程)。
- 优势:职责分离,各角色的扩展与测试更便捷。
- 注意事项:协调成本较高,需确保工作交接清晰、状态共享顺畅。
图结构:
- 适用场景:根据观测结果激活不同路径的动态流程(如,包含决策节点、循环、条件分支的流程)。
- 优势:状态、重试机制与检查点明确,可靠性与可审计性强。
- 注意事项:需规范设计节点协议与验证节点,确保流程逻辑严谨。
群体型/协作型:
- 适用场景:头脑风暴、信息整合或需多视角参与的任务(如多文档分析)。
- 优势:推理方式多样,边缘场景覆盖度更高。
- 注意事项:必须设定严格护栏,需制定时间 / 步骤预算,并明确争议解决机制(如指定审核员或依据策略裁决)。
具体思维模型:
想象一个理赔智能体,它接收理赔案件,规划步骤,调用工具获取保单与交易数据,按业务规则和个人身份信息(PII)策略,验证拟议的理赔结果,再将推理过程与证据更新至记忆库;最后,若理赔金额未超过阈值,则完成理赔流程;若超过阈值,则转至人工处理。该智能体不会取代现有系统,而是对系统进行协调,同时通过约束机制确保每一步操作均可追溯、可回溯且符合合规要求。
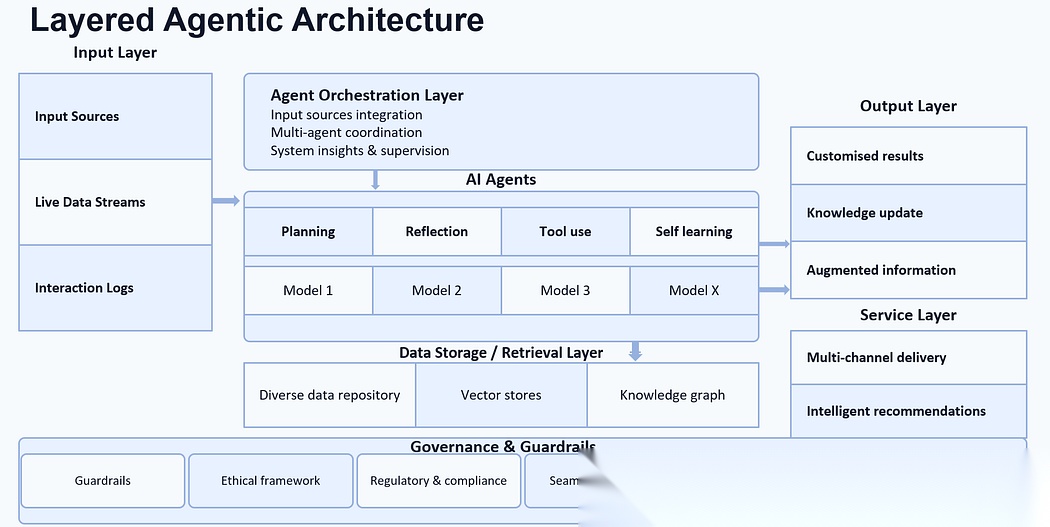
分层智能体架构
2 核心组件与职责
2.1 最小但可投产蓝图
入口 / 应用程序接口:
- 在前端部署 API 网关,(包含 Web 应用防火墙(WAF)、传输层安全协议(TLS)、跨域资源共享 (CORS) 功能),并通过 JSON Web Token(JWT)、开放授权(OAuth)、开放式身份验证连接(OIDC)完成身份验证终止。。
- 按临时用户、用户和智能体(agent)实施速率限制与配额管控,增加突发流量防护机制,并以合理方式返回 429(请求过于频繁)响应。
- 在边缘层应用请求预算(包含token数量、延迟时间、成本),提前拒绝超大负载请求。
- 为每个请求标记关联 ID(correlation ID),并将其传递至所有下游调用链与日志中。
- 设定硬性超时时间与断路器(circuit breaker),防止故障工具引发级联失效。
协调者(Orchestrator):
- 若需明确的节点、重试机制与检查点,选择有状态的图运行时(如 LangGraph);若需模拟人类角色(如规划员 / 研究员 / 审核员)协作,则选择基于角色的协作框架(如 CrewAI)。
- 将工作流、提示词(prompt)、策略进行版本绑定管理;在生产环境中固定版本;通过功能标志(feature flag)实现安全发布。
- 在高风险节点中嵌入人机协同(HITL,Human-in-the-Loop)机制:工作流需暂停并等待审批,审批通过后从检查点恢复执行。
- 将跨服务操作视为长事务(saga):为部分故障场景定义补偿机制。
工具层(DI):
- 维护工具目录,包含工具名称、接口约定(I/O)、负责人、服务等级目标(SLO)、变更历史。
- 使用无状态适配器(适用于 HTTP、数据库、搜索、代码运行、邮件、日历、云软件开发工具包(SDK))对服务提供商进行封装。
- 所有工具调用均通过策略校验,(包括允许 / 禁止列表、工具级别的身份与访问管理(IAM)、出口允许列表、成本检查)。
- 为持续集成(CI)提供模拟工具(mock)与固件测试;发布各环境的兼容性矩阵。
- 为读密集型工具添加降级方案(主服务提供商→备用服务提供商)与带过期时间(TTL)的响应缓存。
记忆库(Memory):
- 采用混合存储架构:向量数据库(RAG)用于检索增强生成,实现语义检索、结构化查询语言(SQL)数据库(用于存储标准事实与状态)、可选的图数据库(用于存储关系与多跳推理数据)。
- 标准化数据分块与元数据(来源、时间戳、权限、语言);优先采用混合检索(稀疏向量 + 稠密向量)与重排序机制。
- 实施临时用户隔离、加密存储、行 / 集合级访问控制,以及数据摄入时的个人身份信息(PII)清洗。
- 跟踪溯源信息以支持引用标注;监控检索命中率与数据新鲜度;对过期内容进行轮换更新。
策略与约束机制:
- 在输入→规划→工具→输出的全流程中分层设置管控措施。
- 实施个人身份信息(PII)脱敏 / 数据防泄漏(DLP)、内容安全(如毒性内容、自残倾向内容检测等)、策略即代码(允许 / 禁止)与沙箱隔离(网络出口、文件系统)。
- 设定预算(token数量、时间、费用)与升级规则(触发人机协同、切换模型或终止流程),以应对风险情况。
- 及时更新治理文档(如模型卡片、风险登记、决策日志)。
验证:
- 所有智能体的I/O均以数据模式(schema)为首要标准,验证数据结构、类型、范围、单位与枚举值。
- 增设业务规则与合理性检查(如证据数量≥阈值、总额核对无误、日期在有效范围内)。
- 明确故障处理方式:修复、重试、启用备用方案或升级处理,并将所有验证失败情况记录为指标。
事件处理:
- 生成仅追加(append-only)的事件流(包括审计、规划步骤、工具调用、审批、事故)。
- 采用模式注册与不可变事件存储,支持回放、离线评估与微调样本生成。
- 最大限度减少事件中的敏感内容,尽可能对敏感信息进行哈希处理或标记化。
可观测性:
- 为追踪、日志、指标植入统一 ID 与标准属性(如智能体步骤、工具名称、模型名称、I/O token数量、成本)。
- 将成本核算作为核心指标,针对预算超支、安全事件或 95 分位延迟(p95 latency)设置告警。
- 准备运行手册与事故处理手册(包括回滚、紧急关闭、安全模式)。
- 定期开展红队演练,追踪结果与长期回归情况。
2.2 基于依赖注入(DI)的工具架构
为何如此重要
- 供应商灵活性:更换服务提供商(如从搜索工具 A 切换至搜索工具 B)时,无需修改智能体代码。
- 安全性:为每个工具设定最小权限(限定范围的凭证、限时令牌)与输出允许列表。
- 可测试性:在持续集成(CI)中使用模拟工具,通过协议测试检测输出的隐性偏移。
- 可控性:通过功能特征与策略,按角色、临时用户或风险评分启用 / 禁用工具。
核心模式
- 按功能(如知识库搜索(kb.search)、订单读取(orders.read))与协议版本构建统一注册中心。
- 与提供商无关的适配器:无论后端如何,统一I/O标准。
- 执行前策略校验:包括允许 / 禁止判断、预算检查、速率限制、出口规则、模型层级校验。
- 幂等性与重试:附加幂等键、指数退避重试、熔断器、工具级并发上限。
- 确定性读取缓存;针对不稳定服务提供商,采用对冲机制(在 T 毫秒后向备用提供商发送请求)。
- 治理:明确工具负责人、服务等级目标(SLO)、废弃策略,每次协议变更均需进行安全审查。
需规避的禁止模式:
- 直接从提示词 / 智能体中调用服务商 SDK。
- 多个工具共享权限宽泛且长期有效的凭证。
- 输出随隐藏标志变化的 “异形” 工具。
- 为 “紧急” 调用绕过策略或日志记录流程。
2.3 应对实际场景的编排设计
- LangGraph(有状态的DAG):明确建模控制流(规划→检索→行动→验证→决策),在每个节点设置重试、循环与检查点;对不可逆操作增设人机协同(HITL)中断。
- CrewAI(多智能体):组建受监督的角色团队(规划员、研究员、分析师、审核员),共享上下文并明确工作交接流程,适用于模拟团队协作的任务。
- 设计层面支持可重入性:在崩溃、重启或审批后,智能体可从检查点确定性恢复,避免隐藏的全局状态。
- 操作语义:针对副作用操作,优先采用长事务 / 补偿机制而非被动等待;为每个步骤设定超时与截止时间;在安全前提下,对独立分支进行并行处理。
- 离线回放:支持确定性回放,用于事故审查与回归测试;可注入标准测试场景与红队测试场景。
2.4 记忆库选项(检索增强生成(RAG)及更多)
- 本地 / 嵌入式数据库(如 Chroma、FAISS):成本低、易上手,适合团队或单用户应用。
- 托管数据库(如 Weaviate、Pinecone):支持多用户、自动扩缩容与混合搜索,运维工作由服务方承担。
- 大规模数据库(如 Milvus):支持自部署、高吞吐量,适合大型多用户集群。
- 混合记忆库:用向量检索获取上下文,用 SQL 数据库存储记录系统事实,用图数据库存储关系与路径(如解答 “谁与谁相关” 类问题)。
- 检索质量优化:调整分块大小与重叠度;丰富元数据(来源、日期、敏感度、语言);采用 BM25(Best Match 25) 与密集检索结合的混合方式,并进行重排序。
- 治理:定义过期时间(TTL)、数据保留期与 “被遗忘权” 机制;防范数据污染(如通过签名来源、隔离低可信度内容);实施用户级索引与行级权限控制。
2.5 状态、事件与检查点
- 状态模式:明确智能体在每个步骤存储的内容(规划、证据 ID、决策、策略判定结果);对模式进行版本管理,并提供迁移方案。
- 检查点:在每个重要步骤后持久化存储,包含输入、输出、工具元数据与策略决策,以支持审计与恢复。
- 事件流:将关键事件(启动、工具调用、验证、升级、完成、失败)发布至 Apache Kafka/Redpanda data(平台名称);保持最小负载且符合隐私安全要求。
- 回放与消费用户:从事件流驱动评估流水线、异常检测与数据集生成;支持幂等消费用户。
- 预算:按步骤与请求追踪token数量、成本与延迟;超预算时,平缓降级(使用小型模型、缩减上下文、调用更安全的工具)或转交人机协同处理;所有决策均需记录在遥测数据中。
- 设计原则与安全设计(从策略到运行)
3.1 在关键节点设置安全关卡
- 提示词前:数据防泄漏(DLP)/ 个人身份信息(PII)脱敏、意图分类、风险评分
- 工具调用前:策略检查(允许列表域名、速率限制、工具级身份与访问管理(IAM))、预算 / 成本上限
- 工具调用后:模式验证、合理性检查(证据数量、阈值判定)
- 行动前(高风险操作):人机协同(HITL)审批(说明规划、差异、累计成本)
- 响应后:脱敏处理、水印添加、日志 + 追踪 + 证据快照
- 工具级身份(云 IAM / 服务账号)
- 在基础设施层实施网络输出允许列表(如 K8s 网络策略 / 边车模式(sidecar proxy))
- 提交前先执行(模拟运行),展示差异与影响,需获得审批方可执行
- 为关键操作设计撤销 / 补偿流程
3.2 提示词规范与版本管理
- 将提示词视为代码:进行版本管理、明确负责人、开展评估、在生产(prod)环境中固定版本
- 为每个提示词 / 智能体版本维护变更日志与评估评分卡
3.3 人机协同(HITL)
- 审批队列需包含上下文、规划、证据、差异、策略评分、成本信息
- 可审计的决策记录;超时机制与备用策略
3.4 红队测试与评估(持续集成(CI)+ 生产(prod)环境)
- 离线持续集成:通过自动化评估检测策略回归、幻觉问题(可使用 Promptfoo、DeepEval、Ragas 等工具)
- 在线环境:金丝雀部署、影子流量测试、安全 / 服务等级目标(SLO)违规时自动回滚
- 约束机制:策略、合规与运行时控制
智能体系统具备自主行动能力,约束机制需确保其在策略、预算与安全护栏内运行,同时不影响实用性。设计时应在输入→规划→工具→输出的全流程中分层设置管控措施,并内置明确的升级机制、可观测性与可审计性。
4.1 个人身份信息(PII)与数据防泄漏(DLP)
定义
在数据入口、内存存储、出口三个环节,用于检测、屏蔽或拦截敏感数据(如个人身份信息(PII)、受保护的健康信息(PHI)、支付卡行业数据安全标准(PCI)数据、机密信息)的管控措施。
必要性
- 履行法律与合同义务(隐私保护、数据驻留、数据保留要求)。
- 防止通过提示词、工具输出或日志意外泄露敏感数据。
- 支持团队与临时用户之间的安全协作。
实施方式
- 对输入与输出数据执行个人身份信息(PII)检测,存储前进行脱敏或令牌化处理。
- 在内存存储中应用集合级访问控制与加密。
- 数据摄入时进行分类,执行过期时间(TTL)/ 数据保留策略与 “被遗忘权” 机制。
- 监控个人身份信息(PII)检测命中率与误报率,按领域优化检测器。
需关注的故障模式
过度脱敏(影响准确性)、特定实体类型的检测盲区、通过可观测性工具或事件流泄露数据。
关键绩效指标(KPI)
个人身份信息(PII)检测精确率 / 召回率、脱敏覆盖率、每千次请求的事故数量。
4.2 内容安全与审核
定义
针对恶意内容、仇恨言论、涉性内容、自残倾向内容、暴力内容、极端主义内容及ROOT尝试(试图突破系统限制的操作)的实时过滤机制与管控策略。
必要性
- 保护用户与工作人员。
- 符合平台规则与监管要求。
- 维护品牌形象与合法合规立场。
实施方式
- 提示词前:拦截高风险输入或为其添加免责声明;缩小内容范围。
- 生成后:对内容严重程度进行分类;采取拦截、弱化处理,或升级至人工审核。
- 配置领域允许列表,避免对良性内容产生误判(如避免误拦截医疗术语)。
故障模式
- 过度拦截合法领域术语;对恶意规避性表述拦截不足。
关键绩效指标(KPIs)
- 各分类内容的拦截 / 标记率、误报率、申诉推翻率。
4.3 结构与模式验证(I/O协议)
定义
为智能体所有I/O设定 “模式优先” 的协议;包含确定性检查与可选的 “修复” 流程。
必要性
- 防止下游系统崩溃与隐性数据损坏。
- 强制执行业务规则(如数值范围、总量要求、证据数量要求)。
- 使故障可观测、可恢复。
实施方式
- 为每个步骤(规划、工具输入、工具输出、最终答案)定义带类型的协议。
- 确定故障关闭”(故障时终止流程)与修复重试(尝试修复后重新执行)两种策略的适用场景。
- 记录所有验证失败案例;将其纳入评估数据集。
故障模式
输出 “形态多变”(格式不稳定)、模式僵化(难以适配变化)、隐藏的单位不匹配(如单位混淆)。
关键绩效指标
验证失败率、自动修复成功率、故障修复时长。
4.4 提示词 / 工具注入防御
定义
检测并防范试图篡改策略、窃取数据或劫持工具的恶意指令。
必要性
- 智能体会读取不可信文本(如网页内容、文档、用户输入)。
- 注入攻击可能导致数据泄露或不安全操作。
实施方式
- 多层防御 + 结合检测模型 + 启发式规则与允许列表。
- 若输入存在可疑性,禁用或降低工具权限。
- 回复内容需基于检索到的证据;对高风险声明要求提供引用来源。
故障模式
检测模型被规避、过度依赖单一模型、未配置允许列表导致的虚假安全感。
关键绩效指标
检测到的攻击尝试次数、被拦截的工具调用次数、事后事故发生率。
4.5 策略即代码与运行时授权
定义
集中化、带版本管理的策略(包含允许 / 禁止规则、条件限制、预算管控、审批要求),在运行时进行评估并提供可解释性(说明决策依据)。
必要性
- 确保跨服务的决策一致性。
- 便于审核、审计与回滚操作。
- 规则变更时可快速迭代调整。
实施方式
- 在智能体接入、工具调用前、网络请求前、写入操作前、发送操作前评估策略。
- 存储决策日志(记录操作人 / 操作内容 / 决策原因)。
- 将策略与环境、临时用户、角色及风险评分绑定。
故障模式
策略泛滥、评估延迟峰值、未记录的策略豁免操作。
关键绩效指标
策略评估延迟、拒绝原因分布、变更失败率。
4.6 沙箱隔离与出站控制
定义
执行 / 运行时隔离机制与网络 / 文件系统管控措施,限制智能体与工具可访问的范围。
必要性
- 控制工具滥用与远程代码执行的影响范围。
- 防止数据泄露至公共互联网。
实施方式
- 进程 / 容器隔离、只读根目录、临时存储(使用后即销毁)。
- 在平台层面(而非仅在应用代码中)设置网络允许列表。
- 通过密钥管理服务(KMS)管理密钥,使用限时、限定范围的凭证。
故障模式
隐藏的出口路径(如 DNS 请求、边车模式)、权限蔓延(权限逐渐扩大)、日志中包含密钥。
关键绩效指标
出口策略违规次数、密钥轮换周期、沙箱突破事件数。
4.7 速率限制、预算与成本上限
定义
多维度限流与支出管控措施:按用户、按工具、按临时用户、按模型层级设定限制。
必要性
- 保障服务等级目标(SLO),控制成本支出。
- 确保临时用户与团队间的资源分配公平性。
- 负载过高时可预测性地触发故障保护。
实施方式
- 按每秒请求数(RPS)、并发量、token数量、延迟时间、成本金额设定限流阈值。
- 采用模型自动分层(接近上限时,自动切换至更小 / 更廉价的模型)。
- 超限时触发告警;高价值超额场景需启动人机协同(HITL)审核。
故障模式
全局限流导致关键流程资源不足、未统计的重试操作、缺失成本标签(无法精准核算)。
关键绩效指标
95 分位延迟(p95 latency)、单任务成本、限流触发率、切换至备用模型的比例。
4.8 可审计性、可追溯性与透明度
定义
决策全流程追溯机制:包含追踪记录、日志、审批记录、证据与成本信息。
必要性
- 事后事故调查与监管审计需求。
- 可复现性(明确变更内容、变更原因及对应版本)。
- 获得相关方信任。
实施方式
- 为每个规划 / 工具调用 / 验证步骤添加关联 ID,实现全链路追踪。
- 留存决策日志与审批文件。
- 存储策略版本、提示词版本及所用数据集信息。
故障模式
日志中包含敏感数据、缺失追踪链路、成本与操作未关联。
关键绩效指标
追踪完整性、平均解释时长(MTTX,Mean Time to Explain)、审计(发现)问题数。
4.9 运营模式与治理
定义
围绕约束机制建立的人员配置、流程规范与变更管理体系。
必要性
- 防止策略偏移(策略执行逐渐偏离目标)与 “隐性豁免”(未记录的策略绕过操作)。
- 确保持续改进(红队测试、事后复盘、评估优化)。
实施方式
- 明确安全、策略、数据与可观测性领域的负责人。
- 每周召开策略会议讨论变更;制定红队测试周期;执行金丝雀发布流程。
- 文档化:编写运行手册、责任分配矩阵(RACI)与培训材料。

Guardrails 选项速查表(Cheat Sheet)
- 工具的依赖注入(DI)
目标
实现工具使用与服务提供商无关,同时具备稳定契约与策略网关。所以,智能体无需关心所使用的是哪款搜索/数据库/邮件服务,只需关注在明确约束下能获取到何种能力即可。
通常需开放的接口
HTTP(REST/GraphQL协议)、数据库(SQL/NoSQL 类型)、搜索/检索增强生成(RAG,含向量检索+关键词检索)、代码解释器、云开发工具包(SDK)、文件/对象存储、邮件/日历、消息通知、分析/商业智能(BI),以及领域特定适配器(支付、密钥管理系统(KMS)、工单系统、客户关系管理(CRM)等)。
设计原则
- 采用小型、单一用途的适配器,具备明确的I/O、单位与超时时间。
- 优先使用能力名称而非厂商名称(如,用 kb.search 而非 pinecone.search)。
- 对副作用(Side-effect)进行分类(只读型 vs 变更型),以此判断何时需要执行空跑测试、审批流程或补偿操作。
- 变更型调用须具备幂等性(支持去重键、重放安全性)。
- 提供确定性的默认值(排序规则、分页规则、区域/时区、货币类型)。
注册中心与配置
- 搭建统一工具注册中心,实现“性能→协议版本→环境关联”的映射。
- 附加元数据:负责人、服务等级目标(SLO)、风险等级、成本模型、数据敏感度、出口域(egress domain)白名单。
- 支持基于临时用户/区域/用户角色,可切换服务提供商的功能开关;预留 A/B 测试与灰度发布路由。
- 为每个工具配置独立身份(权限范围限定的 IAM/服务账号),从密钥管理器获取短期凭证,并按临时用户划分权限范围。
运行时控制
- 每次调用前触发策略网关(支持允许/拒绝、预算控制、速率/配额限制、出口检查)。
- 配置并发限制、带退避机制的重试、断路器,以及兜底策略(若主服务响应缓慢,自动切换至备用服务)。
- 为读取密集型能力配置缓存(含过期时间(TTL)与缓存键管理规则)。
- 设计多级回退机制(主服务→备用服务→静态摘要→人工处理)。
测试与部署
- 执行协议测试,若输出格式偏离则触发失败;针对错误/超时场景执行负面测试。
- 为持续集成(CI)与临时测试环境提供模拟服务(Mocks)/测试数据(fixtures)。
- 制定协议版本的向后兼容策略与废弃规则。
- 对不同服务提供商进行对比测试(输入条件完全一致,基于质量/成本/延迟构建评分卡);仅当满足退出标准时,才推动服务提供商上线。
可观测性与治理
- 为每个工具配置核心指标:成功率、P50/P95 延迟、错误分类、单位任务成本、缓存命中率、高频调用来源。
- 留存契约与服务提供商的变更日志;高风险工具的变更需经过安全评审。
- 定期对工具独立身份的访问权限与出口白名单进行重新认证。
反模式
- 从提示词/智能体中直接调用厂商 SDK。
- 使用共享的长期凭证。
- 输出格式受隐藏开关控制,导致“格式不稳定”。
- 以“仅此一次”为由跳过策略校验/日志记录流程。
- 自提示与推理优化
自我反思循环
- 将循环构建为 “评估→修正→重试” 的流程,并设置硬性限制(步骤、时间、token、成本)。
- 设定证据阈值(如 “最低引用数量”),满足阈值方可通过结果验收。
- 记录评估意见与变更差异,以此衡量反思是否真正提升结果质量。
- 当置信度或证据量低于策略下限时,触发人机协同(HITL)。
规划模式
- 框架式规划:预先设定少量粗略步骤;速度最快,适用于任务明确已知且对延迟敏感的场景。
- 动态规划:根据每次观察结果重新规划;更适合存在不确定性及分支的任务;需限制循环次数,避免过度思考。
- 在步骤中标注置信度及成本 / 延迟预估信息;让协调者剔除超出预算的路径。
工具感知提示
- 教会代理 “何时调用何种工具”(明确前置条件、预期信号、成本)。
- 对 “需检索或提供证据” 的任务,限制 “无工具辅助” 的答案(减少幻觉输出)。
- 优先选择 “请求工具” 而非猜测:若存在不确定,可通过检索或调用确定性校验工具验证。
- 将工具使用依据作为元数据记录,用于后续审计与训练。
高级推理模式(带约束)
- 思维树 / 思维图(Tree/Graph-of-Thought):探索多条候选路径后收敛;需严格限制推理的广度与深度。
- 辩论式 / 双代理模式(Debate / Dual Agents):分为 “支持 / 反对” 或 “求解 / 审核” 两方;设置平局判定规则,避免僵局。
- 自一致性(Self-Consistency):生成多个解决方案并通过投票筛选;因成本较高,仅用于高风险问题。
数据驱动的优化
- 挖掘生产环境中的失败案例(如验证驳回、人工修正、差评反馈)。
- 维护带标签的错误分类体系(如 “幻觉输出、证据缺失、计算错误、违反策略”)。
- 将复杂案例纳入黄金样本集,并开展定期评估;据此调整提示词、策略或工具。
- 考虑设置奖励信号,鼓励“引用来源、符合格式规范、控制在预算内”等行为。
需跟踪的关键绩效指标(KPI)
- 工具使用率(需使用工具的场景)、证据覆盖率、幻觉输出率、#每次成功所需反思步骤数、单任务成本、规划与执行阶段的延迟占比、黄金样本集上的成功率。
常见失败模式及缓解措施
- 循环失控 / 过度斟酌:实施上限限制(如步骤 / 时间上限)与提前终止策略。
- 工具过度使用:增加边际效用校验;缓存读取结果;合并重复的工具调用。
- 依赖过期记忆:添加新鲜度标签与时效性权重;定期重新摄入最新数据。
- 提示词失效(Prompt Rot):对提示词进行版本管理;开展回归评估;设置偏移告警。
- 验证策略
协议优先
- 每个智能体接口(输入、工具调用、最终答案)均需声明包含 “类型、范围、单位、区域、时区” 的模式。
- 模式中需纳入 “不确定性 / 置信度、证据 ID、安全标注(脱敏信息、策略判定结果)”。
- 对模式进行版本管理;记录破坏性变更;部署前测试向后兼容性。
业务规则
- 嵌入领域阈值规则:最小证据数量、信息时效性窗口、货币与税务规则、审批触发条件(金额、VIP 用户、风险等级)、管辖权约束。
- 明确 “失败阻断(fail-closed)” 与 “修复优先” 的适用场景:部分违规必须阻断流程,部分违规可自动修复或触发兜底机制。
交叉校验
- 基于检索结果的评分(答案必须与检索到的证据一致)。
- 检测各步骤间的矛盾与重复信息。
- 对关键计算(算术运算、总和统计、日期转换、汇率换算)使用确定性计算器校验。
- 时效性校验(声明内容在声称的时间点是否有效);个人身份信息(PII)/ 属地相关的合规校验。
验证通道的部署节点
- 工具调用前(验证:认证、预算、速率、模式合规性)
- 工具调用后(验证:输出格式、不变量、合理性)
- 操作执行前(若操作具有破坏性或高成本,需进行风险审查 / 人机协同(HITL))
- 响应返回前(验证:信息脱敏、证据引用完整性、必要免责声明是否补充)
兜底机制与用户体验
- 设计安全默认值(如缩小结果范围、返回含提示说明的部分结果)。
- 提供清晰的错误类型与人类可理解的解释说明。
- 为高价值场景提供替代方案(如切换轻量模型、缩减上下文范围)与人工交接通道。
- 记录每次兜底触发的原因编码,用于后续调优。
可观测性与学习循环
- 通过仪表盘监控:验证覆盖率、失败率、高频失败规则、修复成功率。
- 将失败案例抽样纳入评估数据集;定期开展回归测试。
- 针对 “规则有效性下降、某类失败率激增、滥用模式出现” 等情况,创建工单或触发告警。
关键绩效指标(KPIs)
- 验证失败率、误报 / 漏报率(有标注数据时)、平均修复时长、转接至人工的比例、端到端验收通过率、用户对验证后输出的满意度。
治理机制
- 采用版本控制管理模式与策略,记录负责人及审查历史。
- 高风险契约的变更需经过审批;制定回滚方案。
- 将参考实现与契约测试纳入持续集成(CI)流程。
- 协调与框架对比
选择协调技术栈的核心是看 “控制能力、安全性、云环境适配性”。下文将说明各类方案的定义、优势场景及典型企业适配性,后续附精简对比表。
8.1 CrewAI(多智能体 + 事件驱动流)
核心定义
一款 Python 框架,用于构建基于角色的协作式智能体(即 “团队”) 与事件驱动流。重点支持任务委托、审核者模式,以及用于追踪 / 可观测性的运维钩子(ops hooks)。当你的业务流程可映射为 “类似团队角色分工”(如 “规划者→研究者→审核者”)时,该框架表现突出。(来源:Google 开发者博客:https://developers.googleblog.com/en/building-agents-google-gemini-open-source-frameworks/?utm_source=chatgpt.com)
适用场景
多角色流水线作业、研究 / 内容运营场景、需明确交接环节的审核循环(如内容审核、报告校验)。
8.2 LangChain(智能体)与 LangGraph 运行时
核心定义
LangChain 的 “智能体模块” 负责决策与工具调用;LangGraph 则提供持久化的有状态执行能力(含检查点、人机协同(HITL)、数据持久化、流处理)。使用该组合可保留 LangChain 库的丰富生态(如多样工具集成),同时获得对 “任务流程” 的明确图控制能力(如定义步骤依赖、分支逻辑)。(来源:Google AI 开发者平台:https://ai.google.dev/gemini-api/docs?utm_source=chatgpt.com)
适用场景
需要 LangChain 生态支持,且需为复杂、多步骤任务(如长文档分析、多工具协同检索)搭建可靠状态机(reliable state machines)的团队。
8.3 Azure AI Foundry—— 智能体服务(Agent Service)
核心定义
一款托管式智能体运行时服务,集成了对话线程管理、工具协调、内容安全、身份认证、网络配置与可观测性功能,且与 Azure 平台服务(如 Azure Storage、Azure Active Directory)深度联动。专为企业级 “安全护栏”(如权限管控、合规校验)与 Azure 环境下的规模化部署设计。(来源:Google AI 开发者平台:https://ai.google.dev/aistudio?utm_source=chatgpt.com)
适用场景
以 Azure 为主要云平台,且需从 “开发到生产” 全流程托管支持(如减少运维成本),同时需要平台级安全管控与工具连接器的企业。
8.4 谷歌:智能体开发工具包(ADK)与 智能体引擎(Vertex AI)
核心定义
智能体开发工具包(ADK):开源框架,用于构建多智能体系统,支持对智能体行为的精准控制(与模型、部署方式无关,且针对 Gemini 模型优化)。智能体引擎(Vertex AI):生产级运行时环境,用于部署与规模化管理智能体(含会话管理、记忆存储、效果评估、托管式运行)。两者结合可覆盖 “智能体构建→部署运维” 全流程。
(来源:Google GitHub、Google Cloud 平台:https://cloud.google.com/vertex-ai/generative-ai/docs/agent-development-kit/quickstart?utm_source=chatgpt.com)
适用场景
以谷歌云(GCP)为核心云平台,既需要开发工具包的灵活性(如自定义智能体交互逻辑),又需托管式运行时支持(如大规模会话管理、效果监控)的团队。(谷歌 2025 年更新内容显示,ADK + 智能体引擎已成为其官方推荐的智能体 “构建 - 部署” 路径。)(补充来源:IT Pro:https://www.itpro.com/cloud/live/google-cloud-next-2025-all-the-news-and-updates-live?utm_source=chatgpt.com)
8.5 AWS:亚马逊 Bedrock AgentCore 网关
核心定义
一款托管式工具网关,可标准化智能体 “发现、访问、调用工具” 的方式(实现 “M 个工具与 N 个智能体” 的灵活对接),支持 MCP(AWS 管理控制点)原生连接、协议转换、OAuth/IAM 安全认证,以及集中式可观测性。核心目标是为企业级规模的工具治理(如统一权限、调用监控)提供解决方案。
适用场景
以 AWS 为主要云平台,需整合大量工具(数千个)并在多智能体之间统一管理工具权限、调用策略的企业(如跨部门智能体共享工具资源时的治理需求)。

快速对比
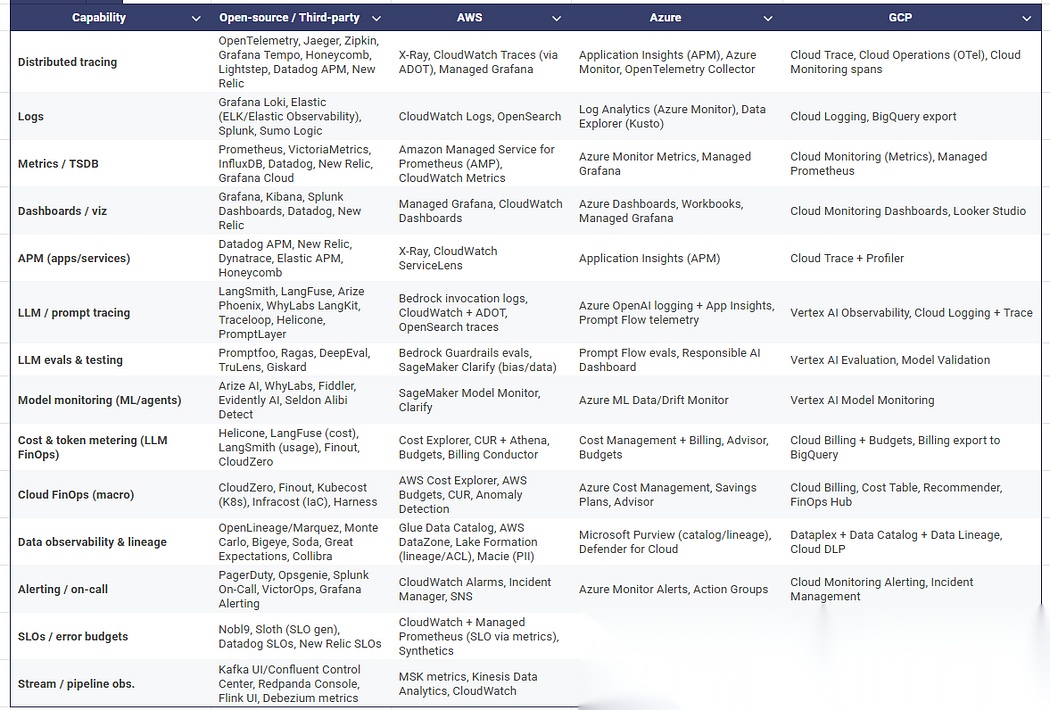
- 数据与记忆层
索引构建(Indexing)
- 采用与查询需求匹配的分块策略:结构化(标题 / 章节)、语义化(主题护栏)、层级化(文档→章节→段落)。
- 优先选择混合检索方式:密集向量嵌入 + 关键词 / BM25 过滤 + 元数据维度(来源、日期、区域、敏感度)。
- 对内容进行标准化处理(统一语言、大小写、单位),剔除冗余内容,并对近乎重复的分块去重。
- 存储丰富元数据(来源 ID、版本、时间戳、作者、权限),同时留存溯源信息以支持引用功能。
时效性管理(Freshness)
- 采用定期或基于变更数据捕获(CDC)的内容摄入方式(按调度周期,或从源系统捕获数据变更)。
- 应用时效性权重或时间感知重排序;在回答中显示 “最后更新时间”。
- 标记过期内容(通过存续时间(TTL)、标记删除 “墓碑机制”),对其进行排除或降权;若来源停止更新,触发告警。
- 保留带版本的索引,以便回滚版本,或对比不同版本发布后的检索表现。
治理机制(Governance)
- 强制执行集合级访问控制列表(ACLs)(按临时用户 / 角色限定范围),必要时启用行级权限。
- 摄入阶段进行个人身份信息(PII)清洗(脱敏 / token处理),并添加溯源标签,确保脱敏操作可审计。
- 追踪从 “源数据→分块→检索→回答” 的完整溯源链路;将证据 ID 与响应结果关联存储。
- 实施静态 / 传输加密;限制数据流出;记录对敏感语料库的访问日志。
性能与成本(可选优化项)
- 平衡质量与成本,调整嵌入模型及维度;对嵌入结果进行缓存。
- 通过重排序减少上下文规模;按置信度限制 top-k 结果数量;压缩长引用内容。
- 监控检索命中率、延迟、单次查询成本;清理低价值内容。
关于基于不同模式的数据库选择,可参考我的另一篇博客。
https://monojkantisaha.medium.com/designing-the-data-memory-layer-for-agentic-ai-scenario-based-cloud-native-blueprints-39b0044e8758

按需求分类的数据库选项
- 部署与运行时架构
安全交付(Ship safely)
- 打包构件(提示词、流程、策略包、数据集)时,明确标注版本信息。
- 基于灰度发布网关(需通过离线评估 + 运行时服务水平目标(SLO)检查)发布;若触发阈值超标,自动回滚版本。
- 通过功能开关实现模型 / 工具切换;预留紧急关闭(kill-switch)通道。
隔离机制(Isolation)
- 按临时用户划分密钥、队列与存储资源;按临时用户及用户角色限制资源使用速率。
- 在网络层配置出口白名单(默认禁止向外访问)。
- 部署 Web 应用防火墙(WAF)+ API 网关,用于输入验证与滥用防护。
密钥管理
- 通过云密钥存储 / 密钥管理系统(KMS)实现密钥轮换;使用短期令牌;禁止在日志中记录密钥。
- 为工具配置基于最小权限原则的专属凭证;按环境绑定凭证(避免跨环境复用)。
可靠性与扩展性(Reliability & scale)
- 为工具调用配置超时控制、带退避机制的重试、幂等键及断路器。
- 合理设置并发量;根据队列深度 / CPU 使用率 / 延迟自动扩缩容;通过预热资源池减少冷启动耗时。
- 定义部署阶段的服务水平目标(SLO)(如错误预算、P95 延迟),并在持续部署(CD)流程中强制校验。
- 可观测性与云成本优化
核心链路(Golden path)
- 追踪数据(Traces):每个步骤(规划、工具调用、验证)生成一个追踪跨度(span),附带关联 ID;同时标注模型、token、延迟、成本等标签。
- 日志(Logs):采用结构化格式;包含决策依据、策略判定结果、证据 ID;对个人身份信息(PII)进行脱敏处理。
- 指标(Metrics):搭建服务水平指标(SLI)/ 服务水平目标(SLO)仪表盘,覆盖质量、安全性、延迟、成本等维度;设置预算告警与异常检测机制。
- 操作手册(Runbooks):制定安全事件、成本激增、工具不稳定等场景的问题分类处理手册;每周开展红队评审(模拟攻击检测漏洞)。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐

 12
12 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)