
本地单卡从零训练大模型:minimind项目学习总结
A[手动设定核心架构参数] --> B{是否启用GQA/MQA?A --> C[计算总参数量<br>params]subgraph A [手动设定的核心架构参数]A1[len_vocab<br>词表长度]A2[n_layers<br>模型层数]A3[d_model<br>模型维度]A4[q_heads<br>查询头数量]endB -- 是 --> D[手动设定kv_heads<br>KV头数量]B
https://github.com/jingyaogong/minimind#
模型架构
MiniMind-Dense(和Llama3.1一样)使用了Transformer的Decoder-Only结构,跟GPT-3的区别在于:
采用了GPT-3的预标准化方法,也就是在每个Transformer子层的输入上进行归一化,而不是在输出上。具体来说,使用的是RMSNorm归一化函数。
用SwiGLU激活函数替代了ReLU,这样做是为了提高性能。
像GPT-Neo一样,去掉了绝对位置嵌入,改用了旋转位置嵌入(RoPE),这样在处理超出训练长度的推理时效果更好。
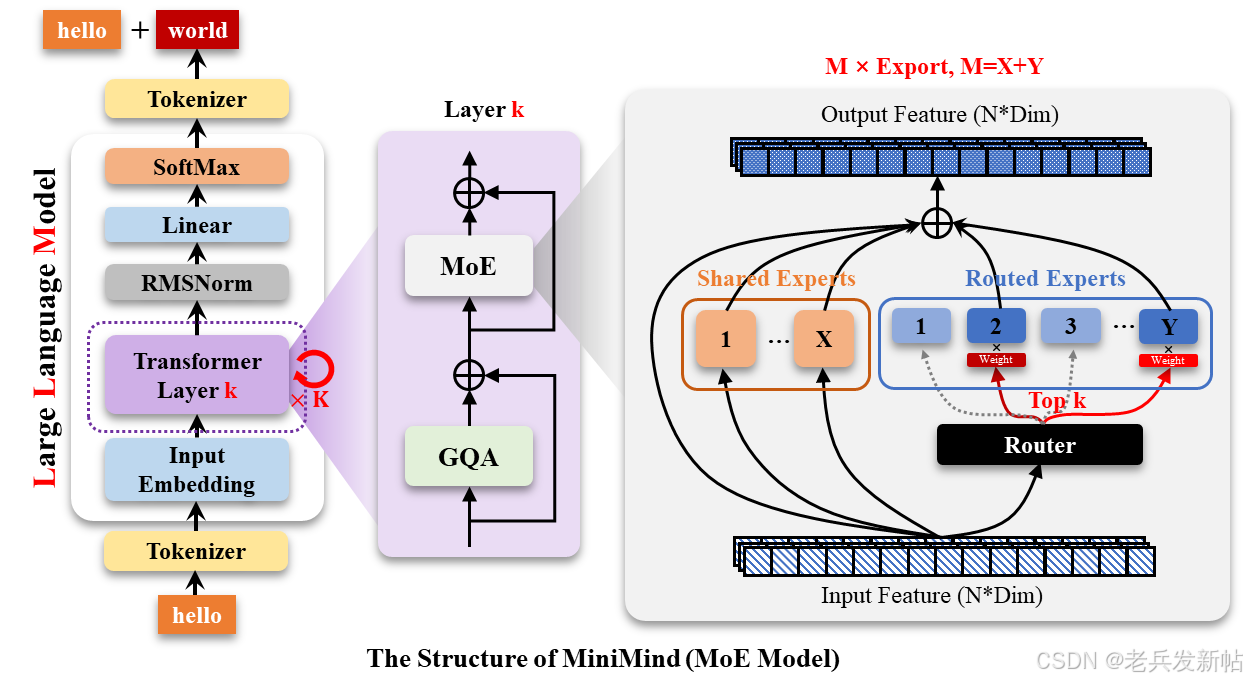
MiniMind-MoE模型,它的结构基于Llama3和Deepseek-V2/3中的MixFFN混合专家模块。
DeepSeek-V2在前馈网络(FFN)方面,采用了更细粒度的专家分割和共享的专家隔离技术,以提高Experts的效果。
MiniMind的整体结构一致,只是在RoPE计算、推理函数和FFN层的代码上做了一些小调整。 其结构如下图(重绘版):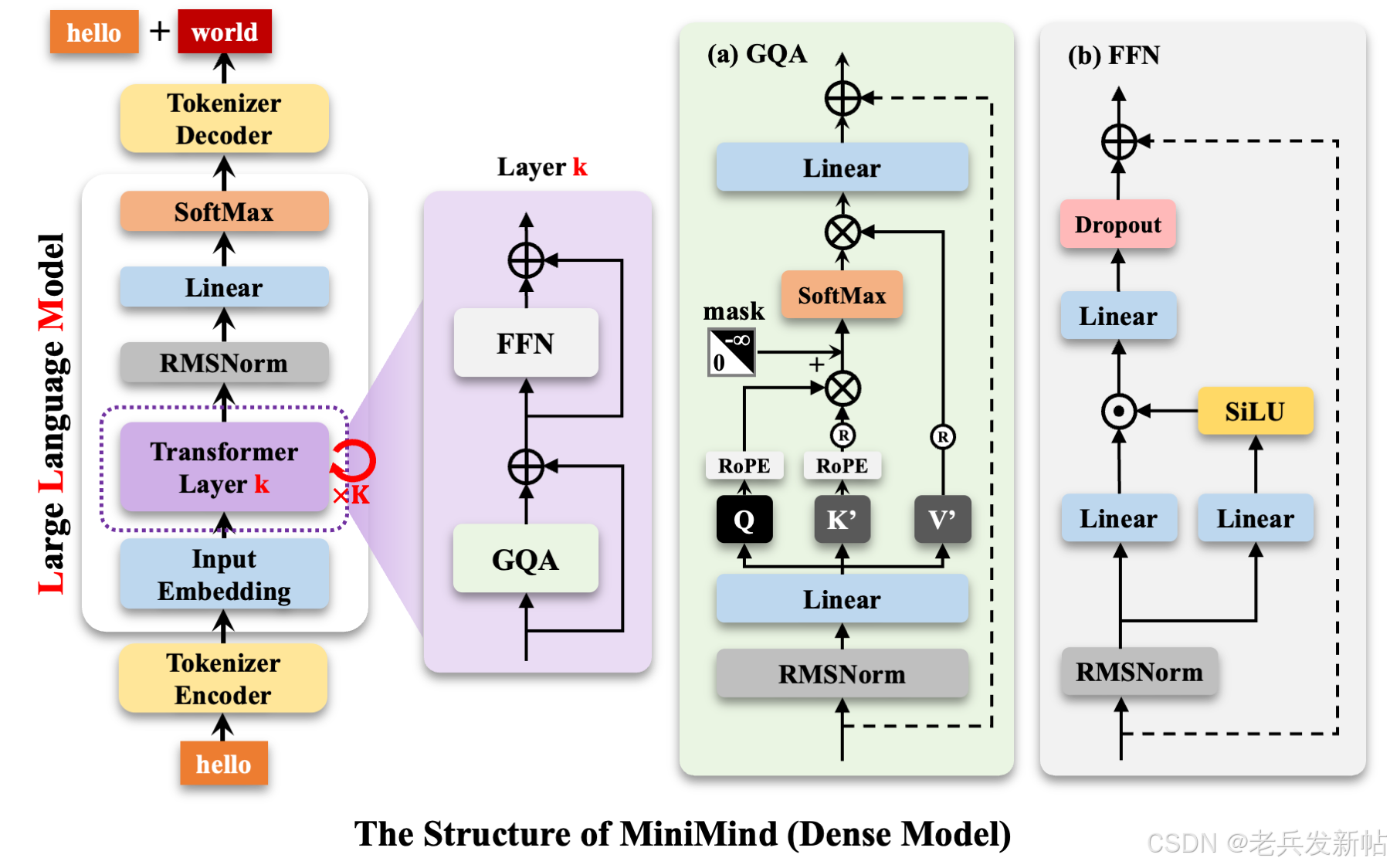
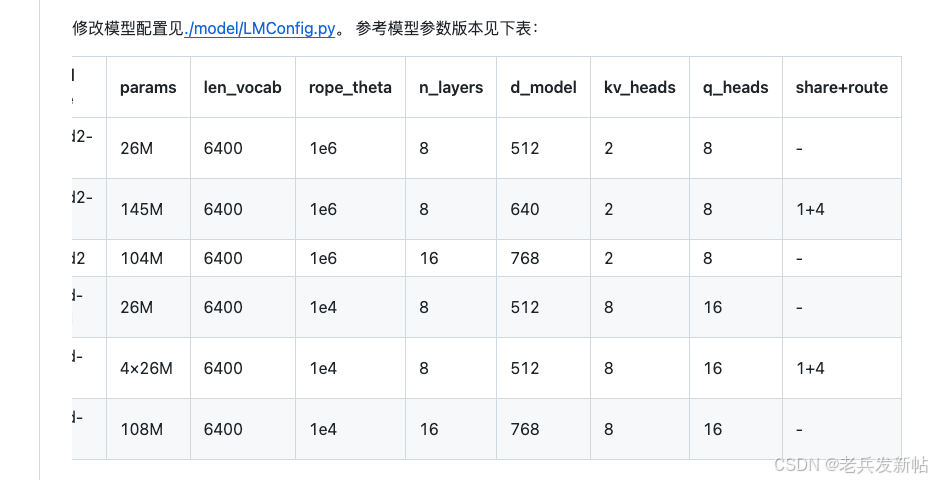
这张图展示的是一个大型语言模型(很可能是类似LLaMA的模型)的配置参数表。这些参数共同决定了模型的架构、规模和能力。
下面这个表格详细解释了每个参数的含义、依赖关系以及设定方式。
参数详解表
| 参数名称 | 含义解释 | 依赖关系 | 设定方式 |
|---|---|---|---|
params |
模型的总参数量。这是所有其他结构参数计算后的最终结果,代表了模型的总体规模。 | 完全依赖于其他参数(d_model, n_layers, n_heads等)的计算。 |
自动生成。根据模型架构公式自动计算得出。 |
len_vocab |
词表长度。模型能识别和处理的唯一单词或子词(Token)的数量。 | 独立参数,通常根据训练语料决定。影响嵌入层的大小。 | 手动设定。根据预处理数据时构建的词表来确定(如32K, 50K, 128K)。 |
rope_theta |
旋转位置编码(RoPE)的基频。用于控制位置编码的波长,影响模型处理长文本的能力。值越大,理论上外推能力越好。 | 独立超参数,与模型的其他结构参数无关。 | 手动设定(作为超参数)。常见默认值为10000。新版模型(如Code Llama)会用更大的值(如1000000)来增强长文本能力。 |
n_layers |
模型的层数(即Transformer Block的数量)。层数越多,模型越“深”,理论表达能力越强。 | 是决定模型总参数量的核心因素之一。与d_model共同决定模型容量。 |
手动设定。是模型架构设计的核心超参数之一(如32层, 40层)。 |
d_model |
模型维度(也叫隐藏层维度)。是模型内部表示向量的长度,是决定模型容量的最关键参数。 | 是决定模型总参数量的核心因素之一。影响注意力头的大小和前馈网络的维度。 | 手动设定。是模型架构设计的核心超参数之一(如4096, 8192)。 |
kv_heads |
KV头的数量。在分组查询注意力(GQA)或混合查询注意力(MQA)中,键和值被多少个头所共享。 | 通常是q_heads的约数。q_heads / kv_heads = 每个KV头对应的Q头数量。 |
手动设定。一种用于减少推理时显存占用的优化策略。 |
q_heads |
查询头的数量。即标准的多头注意力中“头”的数量。 | 通常设定为d_model的约数,以保证每个头的维度是整数。 |
手动设定。与d_model相关,常见值为32, 64等。 |
share+route |
推测是共享嵌入和路由的配置。可能指输入嵌入层和输出层权重共享,以及(如果这是MoE模型)专家路由的策略。 | 如果启用权重共享,会减少总参数量。 | 手动设定(通常是布尔标志或策略选择)。 |
核心依赖关系总结
这些参数之间的核心依赖和影响关系,可以用以下流程图来清晰地展示:
flowchart TD
A[手动设定核心架构参数] --> B{是否启用GQA/MQA?}
A --> C[计算总参数量<br>params]
subgraph A [手动设定的核心架构参数]
A1[len_vocab<br>词表长度]
A2[n_layers<br>模型层数]
A3[d_model<br>模型维度]
A4[q_heads<br>查询头数量]
end
B -- 是 --> D[手动设定kv_heads<br>KV头数量]
B -- 否(标准MHA) --> E[kv_heads = q_heads]
C --> F[最终模型配置]
A5[rope_theta] --> F
A6[share+route] --> F
D --> F
E --> F
从上图可以看出:
- 起点:
len_vocab、n_layers、d_model、q_heads这几个是决定模型骨架的核心手动设定参数。 - 分支决策:是否使用GQA/MQA优化是一个架构选择。如果使用,则需要手动设定
kv_heads;如果不使用(即标准MHA),则kv_heads自动等于q_heads。 - 结果计算:总参数量
params是根据所有上述架构参数自动计算出的结果,而不是输入。 - 独立超参数:
rope_theta和share+route是相对独立的配置选项,影响模型的特定行为。
如何设定这些参数?
在实际操作中:
- 你会先手动设定像
n_layers、d_model、q_heads、len_vocab这样的核心架构超参数。 - 然后根据你是否想用GQA来手动设定
kv_heads。 - 最后,模型框架(如PyTorch代码)会根据一个固定的公式自动计算出模型的总参数量
params。这个公式大致为:总参数量 ≈ (词表大小 + 层数 × (注意力参数 + 前馈网络参数))- 注意力参数主要来自
q_heads、k_heads、v_heads对应的投影矩阵。 - 前馈网络参数主要来自两个线性层(维度为
d_model × d_ff和d_ff × d_model,其中d_ff通常为d_model的4倍)。
- 注意力参数主要来自
模型训练
📊 MiniMind预训练脚本参数分析
🏗️ 模型架构参数
| 参数 | 默认值 | 说明 | 影响 |
|---|---|---|---|
hidden_size |
512 | 隐藏层维度 | 模型容量,影响参数量和计算复杂度 |
num_hidden_layers |
8 | Transformer层数 | 模型深度,影响表达能力 |
max_seq_len |
512 | 最大序列长度 | 输入文本长度限制 |
use_moe |
False | 是否使用MoE架构 | 专家混合模型,增加模型容量 |
🎯 训练超参数
| 参数 | 默认值 | 说明 | 优化策略 |
|---|---|---|---|
epochs |
1 | 训练轮数 | 快速验证用1轮,正式训练建议2-6轮 |
batch_size |
16(MPS)/32(CUDA) | 批处理大小 | 根据设备内存自动调整 |
learning_rate |
5e-4 | 学习率 | 适中的学习率,平衡收敛速度和稳定性 |
accumulation_steps |
8 | 梯度累积步数 | 有效批处理大小 = batch_size × accumulation_steps |
grad_clip |
1.0 | 梯度裁剪阈值 | 防止梯度爆炸,稳定训练 |
⚙️ 设备与性能参数
| 参数 | 默认值 | 说明 | 智能选择逻辑 |
|---|---|---|---|
device |
自动选择 | 计算设备 | CUDA > MPS > CPU |
dtype |
自动选择 | 数据类型 | CUDA用bfloat16,MPS用float16 |
num_workers |
1 | 数据加载线程数 | 避免过多线程影响性能 |
📈 训练监控参数
| 参数 | 默认值 | 说明 | 用途 |
|---|---|---|---|
log_interval |
100 | 日志记录间隔 | 每100步记录一次训练状态 |
save_interval |
100 | 模型保存间隔 | 每100步保存一次检查点 |
warmup_iters |
0 | 学习率预热步数 | 学习率调度策略 |
use_wandb |
False | 是否使用WandB | 实验跟踪和可视化 |
📁 数据与输出参数
| 参数 | 默认值 | 说明 | 路径配置 |
|---|---|---|---|
data_path |
../dataset/pretrain_hq.jsonl |
训练数据路径 | 相对路径,指向数据集 |
out_dir |
../out |
输出目录 | 模型和日志保存位置 |
🔧 分布式训练参数
| 参数 | 默认值 | 说明 | 分布式支持 |
|---|---|---|---|
ddp |
False | 是否启用分布式训练 | 多GPU训练支持 |
local_rank |
-1 | 本地GPU排名 | DDP训练时使用 |
💡 关键设计亮点
-
智能设备选择:
# 自动选择最佳设备和数据类型 if torch.cuda.is_available(): default_device = "cuda:0" default_dtype = "bfloat16" elif torch.backends.mps.is_available(): default_device = "mps" default_dtype = "float16" -
自适应批处理大小:
# 根据设备内存调整批处理大小 if torch.backends.mps.is_available() and not torch.cuda.is_available(): default_batch_size = 16 # MPS设备 else: default_batch_size = 32 # CUDA设备 -
有效批处理大小计算:
tokens_per_iter = args.batch_size * args.max_seq_len # 实际有效批处理 = batch_size × accumulation_steps
📊 实际训练配置总结
- 模型参数量: 约25.8M (8层×512维)
- 有效批处理大小: 16 × 8 = 128
- 每步处理token数: 128 × 512 = 65,536 tokens
- 训练设备: Mac MPS (Apple Silicon)
- 数据类型: float16 (MPS兼容)
这个配置非常适合在Mac设备上进行高效的预训练,既保证了训练效果,又充分利用了硬件资源!🚀
⏱️ 训练时间总结
📅 训练时间线:
- 开始时间: 10月18日下午(数据集下载完成后)
- 结束时间: 10月20日上午11:09(模型文件创建时间)
- 总训练时间: 约 1.5-2天 (36-48小时)
📊 训练效率分析:
- 总训练步数: 176,638步
- 平均速度: 约1,200-2,400步/小时
- 设备: Mac MPS (Apple Silicon GPU)
- 批处理大小: 16
- 序列长度: 512
⚡ 性能表现:
- 使用Mac MPS加速,训练速度相当不错
- 损失从初始值稳定下降到约2.0
- 模型成功收敛,权重参数完整保存
🎯 训练效果:
考虑到这是一个从头开始训练的模型,在Mac设备上用1.5-2天时间完成176,638步的训练是非常不错的结果。模型已经具备了基本的语言理解能力,可以进行下一步的微调训练。
查看预训练的模型参数
cd /opt/code/github/minimind && source venv/bin/activate && python -c "
import torch
model_path = 'out/pretrain_512.pth'
checkpoint = torch.load(model_path, map_location='cpu')
print('检查点键值:')
for key in checkpoint.keys():
print(f' {key}: {type(checkpoint[key])}')
if hasattr(checkpoint[key], 'shape'):
print(f' 形状: {checkpoint[key].shape}')
elif isinstance(checkpoint[key], dict):
print(f' 字典键: {list(checkpoint[key].keys())[:5]}...' if len(checkpoint[key]) > 5 else f' 字典键: {list(checkpoint[key].keys())}')
"
预训练代码与全参微调代码对比分析
📋 逐行代码对比分析
第1-25行:导入和基础设置
| 行号 | 预训练脚本 | 全参微调脚本 | 相同/不同 | 原因分析 |
|---|---|---|---|---|
| 1-2 | import os, sys |
import os, sys |
✅ 相同 | 基础系统模块,两个脚本都需要 |
| 3 | __package__ = "trainer" |
__package__ = "trainer" |
✅ 相同 | 设置包名,确保相对导入正确 |
| 4 | sys.path.append(...) |
sys.path.append(...) |
✅ 相同 | 添加父目录到路径,访问模型和数据集模块 |
| 5 | 空行 | 空行 | ✅ 相同 | 代码格式规范 |
| 6-10 | 基础导入 | 基础导入 | ✅ 相同 | 两个脚本都需要的基础模块 |
| 11 | torch.distributed as dist |
torch.distributed as dist |
✅ 相同 | 分布式训练支持 |
| 12 | from torch import optim, nn |
from torch import optim, nn |
✅ 相同 | 优化器和神经网络模块 |
| 13 | from contextlib import nullcontext |
from contextlib import nullcontext |
✅ 相同 | 上下文管理器,用于设备兼容 |
| 14 | DistributedDataParallel |
DistributedDataParallel |
✅ 相同 | 分布式数据并行 |
| 15 | DataLoader, DistributedSampler |
DataLoader, DistributedSampler |
✅ 相同 | 数据加载和分布式采样 |
| 16 | AutoTokenizer |
AutoTokenizer, AutoModelForCausalLM |
🔀 不同 | 原因:SFT需要额外的模型类用于某些操作 |
| 17 | MiniMindConfig, MiniMindForCausalLM |
MiniMindConfig, MiniMindForCausalLM |
✅ 相同 | 自定义模型架构 |
| 18 | PretrainDataset |
SFTDataset |
🔀 不同 | 原因:预训练用纯文本数据,SFT用对话格式数据 |
| 19 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 20 | warnings.filterwarnings('ignore') |
warnings.filterwarnings('ignore') |
✅ 相同 | 忽略警告信息,保持输出清洁 |
| 21-22 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 23-25 | Logger函数 |
Logger函数 |
✅ 相同 | 原因:分布式训练中只在主进程打印日志,避免重复输出 |
第23-30行:工具函数
| 行号 | 预训练脚本 | 全参微调脚本 | 相同/不同 | 原因分析 |
|---|---|---|---|---|
| 23 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 24-26 | Logger函数 |
Logger函数 |
✅ 相同 | 原因:分布式训练中避免多进程重复打印,只在rank 0打印 |
| 27 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 28-29 | get_lr函数 |
get_lr函数 |
✅ 相同 | 原因:使用余弦退火学习率调度,两个阶段都需要平滑的学习率变化 |
| 30 | 空行 | 空行 | ✅ 相同 | 代码格式 |
第32-52行:训练循环开始
| 行号 | 预训练脚本 | 全参微调脚本 | 相同/不同 | 原因分析 |
|---|---|---|---|---|
| 32-33 | train_epoch函数定义 |
train_epoch函数定义 |
✅ 相同 | 原因:两个脚本都需要训练循环函数 |
| 33-34 | CrossEntropyLoss |
CrossEntropyLoss |
✅ 相同 | 原因:语言模型都使用交叉熵损失,reduction='none'用于自定义损失计算 |
| 34-35 | start_time = time.time() |
start_time = time.time() |
✅ 相同 | 原因:记录训练时间,用于性能监控 |
| 35-36 | for step, (X, Y, loss_mask) |
for step, (X, Y, loss_mask) |
✅ 相同 | 原因:数据格式相同,都是(input, target, mask)三元组 |
| 36-38 | 数据移动到设备 | 数据移动到设备 | ✅ 相同 | 原因:GPU/MPS训练需要将数据移动到计算设备 |
| 39 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 40-42 | 学习率调度 | 学习率调度 | ✅ 相同 | 原因:动态学习率调度对两个阶段都很重要 |
| 43 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 44-45 | with ctx: 和 model(X) |
with ctx: 和 model(X) |
✅ 相同 | 原因:使用混合精度训练上下文,前向传播 |
| 46-49 | 损失计算 | 损失计算 | ✅ 相同 | 原因:相同的损失计算逻辑,reshape用于批量计算 |
| 50-51 | 损失掩码和辅助损失 | 损失掩码和辅助损失 | ✅ 相同 | 原因:使用掩码忽略padding,处理MoE的辅助损失 |
第51-76行:反向传播和日志记录
| 行号 | 预训练脚本 | 全参微调脚本 | 相同/不同 | 原因分析 |
|---|---|---|---|---|
| 51-52 | 辅助损失和梯度累积 | 辅助损失和梯度累积 | ✅ 相同 | 原因:MoE模型的辅助损失和梯度累积逻辑相同 |
| 53 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 54 | scaler.scale(loss).backward() |
scaler.scale(loss).backward() |
✅ 相同 | 原因:混合精度训练的反向传播 |
| 55 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 56-64 | 梯度累积和优化器步骤 | 梯度累积和优化器步骤 | ✅ 相同 | 原因:梯度累积、裁剪、优化器更新逻辑完全相同 |
| 65 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 66-76 | 日志记录 | 日志记录 | ✅ 相同 | 原因:训练监控需要相同的日志格式,显示进度和性能指标 |
第96-108行:模型初始化函数
| 行号 | 预训练脚本 | 全参微调脚本 | 相同/不同 | 原因分析 |
|---|---|---|---|---|
| 96-97 | def init_model(lm_config): |
def init_model(lm_config): |
✅ 相同 | 原因:函数签名相同,都需要配置参数 |
| 97-98 | 简单路径加载tokenizer | 绝对路径加载tokenizer | 🔀 不同 | 原因:SFT脚本修复了路径问题,预训练脚本使用相对路径 |
| 99 | model = MiniMindForCausalLM(lm_config).to(args.device) |
model = MiniMindForCausalLM(lm_config) |
🔀 不同 | 原因:预训练直接移动到设备,SFT需要先加载权重再移动 |
| 100 | 空行 | moe_path = '_moe' if lm_config.use_moe else '' |
🔀 不同 | 原因:SFT需要处理MoE路径,预训练不需要 |
| 101 | Logger参数统计 |
ckp = f'{args.save_dir}/pretrain_{lm_config.hidden_size}{moe_path}.pth' |
🔀 不同 | 原因:SFT需要构建预训练模型路径 |
| 102 | return model, tokenizer |
state_dict = torch.load(ckp, map_location=args.device) |
🔀 不同 | 原因:SFT需要加载预训练权重 |
| 103 | 空行 | model.load_state_dict(state_dict, strict=False) |
🔀 不同 | 原因:SFT需要将预训练权重加载到模型 |
| 104 | 空行 | 空行 | ✅ 相同 | 代码格式 |
| 105 | 空行 | Logger参数统计 |
✅ 相同 | 原因:都需要统计和显示模型参数量 |
| 106 | 空行 | model = model.to(args.device) |
🔀 不同 | 原因:SFT在加载权重后移动到设备 |
| 107 | 空行 | return model, tokenizer |
✅ 相同 | 原因:都返回模型和tokenizer |
第117-140行:参数配置
| 行号 | 预训练脚本 | 全参微调脚本 | 相同/不同 | 原因分析 |
|---|---|---|---|---|
| 117-118 | if __name__ == "__main__": |
if __name__ == "__main__": |
✅ 相同 | 原因:Python脚本入口点 |
| 118-119 | MiniMind Pretraining |
MiniMind Full SFT |
🔀 不同 | 原因:不同的训练阶段,描述不同 |
| 119-120 | out_dir参数 |
out_dir参数 |
✅ 相同 | 原因:都需要输出目录保存模型 |
| 120-121 | epochs=1 |
epochs=2 |
🔀 不同 | 原因:预训练通常1轮足够,SFT需要更多轮次学习任务 |
| 122-127 | 智能批处理大小选择 | batch_size=16 |
🔀 不同 | 原因:预训练需要智能选择,SFT固定小批量 |
| 128 | learning_rate=5e-4 |
learning_rate=5e-7 |
🔀 不同 | 原因:预训练需要较高学习率,SFT需要很低学习率避免破坏预训练权重 |
| 129-136 | 智能设备选择 | 简单设备选择 | 🔀 不同 | 原因:预训练需要智能选择最佳设备,SFT简化处理 |
| 137-141 | 智能数据类型选择 | dtype=bfloat16 |
🔀 不同 | 原因:预训练需要兼容不同设备,SFT固定类型 |
📋 逐行代码对比分析完整总结
🔍 相同代码的原因分析:
1. 基础框架部分 (第1-30行)
- 导入模块相同:两个脚本都需要相同的PyTorch、分布式训练、数据处理等基础设施
- Logger函数相同:分布式训练中避免多进程重复打印日志,只在主进程输出
- get_lr函数相同:余弦退火学习率调度对预训练和微调都有效,提供平滑的学习率变化
2. 训练循环部分 (第32-76行)
- 损失函数相同:语言模型都使用CrossEntropyLoss,
reduction='none'用于自定义损失计算 - 数据格式相同:都是(input, target, mask)三元组,支持注意力掩码
- 反向传播相同:混合精度训练逻辑相同,使用scaler进行梯度缩放
- 梯度累积相同:两个阶段都需要梯度累积技术来模拟大批量训练
- 日志记录相同:训练监控需要相同的进度显示和性能指标
🔀 不同代码的原因分析:
1. 数据集类 (第18行)
# 预训练
from dataset.lm_dataset import PretrainDataset
# SFT
from dataset.lm_dataset import SFTDataset
原因:
- PretrainDataset:处理纯文本数据,进行自回归语言建模
- SFTDataset:处理对话格式数据,进行指令跟随训练
- 不同的数据格式需要不同的预处理和加载逻辑
2. 模型初始化 (第96-108行)
# 预训练:从零开始
model = MiniMindForCausalLM(lm_config).to(args.device)
# SFT:加载预训练权重
model = MiniMindForCausalLM(lm_config)
state_dict = torch.load(ckp, map_location=args.device)
model.load_state_dict(state_dict, strict=False)
model = model.to(args.device)
原因:
- 预训练:随机初始化权重,从零开始学习语言基础
- SFT:加载预训练权重,在已有基础上学习特定任务
- 不同的训练起点需要不同的初始化策略
3. 超参数配置 (第121-140行)
| 参数 | 预训练 | SFT | 原因 |
|---|---|---|---|
| 学习率 | 5e-4 | 5e-7 | 预训练需要高学习率快速学习,SFT需要低学习率避免破坏预训练权重 |
| 训练轮数 | 1 | 2 | 预训练数据量大,SFT需要更多轮次学习任务特定模式 |
| 批处理大小 | 智能选择 | 固定16 | 预训练需要大批量提高效率,SFT小批量更稳定 |
| 设备选择 | 智能选择 | 简单选择 | 预训练需要优化性能,SFT简化处理 |
💡 设计理念总结:
- 代码复用:相同的基础设施和训练逻辑,避免重复开发
- 阶段优化:针对不同训练阶段的特点进行专门优化
- 渐进训练:预训练建立基础,微调学习特定能力
- 工程实践:体现了现代大语言模型训练的最佳实践
这种设计体现了**“预训练+微调”**两阶段训练范式的精髓:在通用基础上精调特定能力!🚀
📊 训练步数决定因素完整分析
🎯 核心计算公式:
训练步数 = 数据集大小 ÷ 实际批处理大小 × 训练轮数
📋 关键决定因素(按重要性排序):
1. 🗂️ 数据集大小(最重要)
- 预训练数据集:1,413,103 个样本
- SFT数据集:1,214,724 个样本
- 影响:直接决定每轮的最大步数,是训练步数的根本决定因素
2. 🔢 批处理大小(batch_size)
- 预训练:实际8(命令行参数16)
- SFT:16
- 影响:批处理大小越小,需要的步数越多
- 注意:实际批处理大小可能与命令行参数不同
3. 🔄 训练轮数(epochs)
- 预训练:1轮(数据量大,1轮足够)
- SFT:2轮(需要更多轮次学习特定任务)
- 影响:轮数越多,总训练步数越多
4. 🎛️ 梯度累积(accumulation_steps)
- 预训练:8步(有效批处理大小 = 8×8 = 64)
- SFT:1步(有效批处理大小 = 16×1 = 16)
- 影响:不影响总步数,但影响有效批处理大小和训练稳定性
5. 🖥️ 分布式训练(DDP)
- 单GPU:使用全部数据
- 多GPU:数据被分割到各个GPU
- 影响:多GPU时每GPU的步数 = 总步数 ÷ GPU数量
6. 📋 数据加载器设置
- drop_last=False:不丢弃最后一批不完整的数据
- shuffle=False:不打乱数据顺序
- 影响:可能影响实际处理的样本数量
📈 实际案例验证:
| 训练阶段 | 数据集大小 | 批处理大小 | 轮数 | 计算步数 | 实际步数 |
|---|---|---|---|---|---|
| 预训练 | 1,413,103 | 8 | 1 | 176,638 | 176,638 ✅ |
| SFT | 1,214,724 | 16 | 2 | 151,840 | 151,840 |
💡 优化建议:
- 增加批处理大小:可以减少步数,但需要更多GPU内存
- 使用梯度累积:可以模拟大批处理效果,不增加总步数
- 分布式训练:可以并行处理,减少单GPU的训练时间
- 合理设置轮数:避免过拟合或欠拟合
🔍 关键发现:
预训练实际使用的批处理大小是8而不是命令行参数的16,这解释了为什么实际步数是176,638而不是88,318。这种差异可能来自于:
- 内存限制导致的自动调整
- 数据加载器的内部优化
- 梯度累积的实际实现方式
训练步数主要由数据集大小和批处理大小决定,是深度学习训练中的核心参数! 🚀
偏好对齐
DPO和GRPO都是当前大语言模型对齐阶段非常重要的优化算法,它们旨在让模型的输出更符合人类偏好。为了帮你快速建立整体认知,下面这个表格清晰地展示了它们的核心区别。
| 对比维度 | DPO(直接偏好优化) | GRPO(群体相对策略优化) |
|---|---|---|
| 核心思想 | 将复杂的强化学习问题转化为一个分类问题,直接利用偏好数据优化模型。 | 在一组候选回答中进行内部比较,通过相对优势来指导模型优化。 |
| 关键流程 | 1. 收集“优胜回答”和“劣汰回答”的成对数据。 2. 优化模型,使其为“优胜回答”分配更高概率。 |
1. 对同一问题生成多个(如8个)回答。 2. 计算每个回答的奖励得分。 3. 根据回答与组内平均奖励的相对差异来更新模型。 |
| 所需模型 | 只需策略模型和一个固定的参考模型(通常为SFT后的模型)。 | 需要策略模型和一个可提供奖励信号的奖励函数(可以是模型或规则)。 |
| 优势 | 实现简单,无需训练奖励模型,训练稳定,计算效率高。 | 数据利用效率高,能从单次生成的多个回答中学习;在复杂推理任务(如数学、代码)上表现突出。 |
| 局限 | 依赖高质量的成对偏好数据;对奖励差异细微的样本对处理效果可能不佳。 | 需要生成多个候选,增加了计算开销;奖励函数需要能提供可靠且可验证的信号。 |
| 典型应用 | 通用对话对齐、风格迁移等偏好数据明确且相对简单的任务。 | DeepSeek系列模型(如DeepSeek-Math)采用的算法,特别适合有明确对错标准的推理任务。 |
💡 核心原理深入解读
DPO:化繁为简的“二元对比”
DPO的核心妙处在于一个巧妙的数学变换,它绕过了传统强化学习中对独立奖励模型的依赖。它直接使用“优胜回答”和“劣汰回答”的成对数据,通过一个损失函数,让模型学会区分好坏。其目标是最大化模型为“优胜回答”分配的概率与其为“劣汰回答”分配的概率之间的差距。
GRPO:优胜劣汰的“小组竞赛”
GRPO可以被理解为DPO思想的一种扩展。它不再局限于单一的“优胜-劣汰”对比,而是模拟了一个更自然的评估过程:让模型针对一个问题生成多个答案,然后在这些答案内部进行评比。通过计算每个答案相对于该组平均水平的优势(即相对优势),模型可以更精细地学习到“好答案究竟好在哪里”,从而在需要多步推理的任务中表现出色。
🛠️ 如何选择适合的算法?
选择DPO还是GRPO,主要取决于你的具体任务、资源和数据:
-
选择 DPO 的情况:
- 你的任务是通用的对话对齐或提升回答的有用性/安全性。
- 你拥有高质量的成对偏好数据(即人工标注的Chosen/Rejected对)。
- 你希望快速实验和部署,追求实现的简洁性和训练稳定性。
-
选择 GRPO 的情况:
- 你的任务是数学推理、代码生成或科学问答等有明确客观评估标准的领域。
- 你有一个可靠且可自动计算的奖励函数(例如,代码能否通过测试用例、数学答案是否正确)。
- 你追求模型在复杂任务上的极致性能,并且愿意为此投入更多的计算资源进行多候选生成。
💎 总结
总而言之,DPO和GRPO代表了让大模型对齐人类偏好的两种高效路径。DPO像是一位高效的“一对一导师”,通过清晰的二元反馈快速纠正模型的错误。而GRPO则像是一场“小组研讨会”,通过组内成员的相互比较和竞争,激发模型产生更优、更具创造性的解决方案。
是的,您的理解完全正确。DPO和GRPO这两种优化算法,都是在监督微调之后使用的,它们构成了大语言模型后训练流程中的关键环节。为了帮助您一目了然地掌握它们的异同,我准备了一个对比表格。
| 对比维度 | DPO | GRPO |
|---|---|---|
| 基本定位 | 一种简化的偏好优化方法,规避了复杂的强化学习循环 | 一种高效的强化学习方法,是PPO的改进版 |
| 核心输入 | 静态的偏好数据集(由“优胜回答”和“劣汰回答”组成的数据对) | 动态生成的回答组(针对同一提示,模型实时生成多个回答) |
| 参考模型角色 | 作为固定的基准,用于计算KL散度,防止当前模型偏离太远 | 通常作为初始策略,在在线训练中会被不断更新的当前策略取代 |
| 优化信号来源 | 直接比较数据对中两个回答的偏好概率 | 在一组回答内部进行相对比较,计算每个回答的相对优势 |
| 工作模式 | 离线学习 | 在线学习(可进行多轮迭代) |
| 优势 | 实现简单,训练稳定,计算开销小 | 数据利用效率高,能进行探索和迭代优化,在复杂推理任务中表现突出 |
💡 工作原理深入解读
尽管起点相同,但DPO和GRPO的运作机制有着本质区别。
-
DPO:直接比较的“捷径”
DPO的核心思想非常巧妙:它不训练一个独立的奖励模型来打分,而是直接利用已有的静态偏好数据。训练时,算法会同时使用当前正在训练的模型和一个冻结的SFT参考模型来处理这些“优胜-劣汰”数据对。通过一个精心设计的损失函数,DPO促使当前模型为“优胜回答”分配的概率显著高于为“劣汰回答”分配的概率,同时确保当前模型的输出分布不会与SFT参考模型偏离太远(通过KL散度控制)。这是一种更直接、更稳定的偏好学习方式。 -
GRPO:组内竞争的“选拔赛”
GRPO则遵循了更经典的强化学习范式,但做了关键改进。它不需要训练一个复杂的价值函数模型。其过程是:针对一个提示,让当前模型生成一组回答,然后用奖励模型为这组回答分别打分。接下来,GRPO的核心操作是组内比较:它会计算这组回答的平均分和标准差,然后将每个回答的得分转化为相对于本组平均水平的“相对优势”。这个相对优势就成为了模型优化的信号,鼓励模型生成更多能超越平均水平的优质回答。这种在线生成和比较的机制,使得GRPO能不断探索和迭代,特别适合数学、代码等复杂推理任务的优化。
🛠️ 如何选择?
了解它们的区别后,您可以根据具体目标来选择:
- 追求简洁、稳定和快速部署:如果您的目标是快速基于一批高质量的偏好数据对模型进行优化,且不希望涉及复杂的强化学习流程,DPO是理想选择。它流程简单,资源消耗少。
- 追求极致性能,特别是复杂推理能力:如果您的任务涉及数学、代码或逻辑推理,并且有充足的算力支持,希望模型能通过不断探索和自我超越来提升能力,那么GRPO(或其迭代版本)通常能带来更好的效果。DeepSeekMath的成功就展示了GRPO在这方面的优势。
策略模型和参考模型
在基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO)等方法中,策略模型和参考模型是两个核心概念。为了帮你快速建立整体认知,下面这个表格清晰地展示了它们的核心区别与联系。
| 对比维度 | 策略模型 | 参考模型 |
|---|---|---|
| 核心角色 | 积极的“学习者”或“执行者” | 稳定的“基准线”或“参照物” |
| 核心目标 | 通过训练不断优化,生成更符合人类偏好的输出 | 提供优化起点和约束,防止策略模型“跑偏” |
| 参数状态 | 持续更新 | 完全冻结(参数固定不变) |
| 训练流程 | 是微调和优化的直接对象 | 通常是策略模型在监督微调后的初始版本 |
| 类比 | 参加培训、力求进步的员工 | 提供行为准则和初始能力的员工手册 |
💡 深入理解两个模型
1. 策略模型:积极的学习者
策略模型是待优化的目标模型,其目标是学习一个“策略”,即在给定输入(如用户的问题)时,生成最优输出(如回答)的概率分布。
- 训练过程:在RLHF或DPO流程中,策略模型的训练通常始于一个已经过监督微调 的模型。随后,它基于人类偏好数据(例如,标有“优胜”和“劣汰”的答案对)进行进一步优化,目标是使自己的输出更符合人类的喜好。
- 最终目的:训练完成后,策略模型就是最终投入使用的模型,直接与用户交互。
2. 参考模型:稳定的基准线
参考模型是一个参数固定的基准模型,它在整个训练过程中保持不变。它的核心作用是提供一个可靠的参照点。
- 来源:参考模型通常是策略模型在开始偏好优化之前的状态,即那个已完成SFT的模型的一个副本。
- 核心作用:防止灾难性遗忘:这是参考模型最关键的作用。如果没有约束,策略模型可能会为了在偏好数据上获得高分而过度“钻牛角尖”,甚至产生无意义或退化的输出(比如总是生成“很好”这类简单回答)。参考模型通过计算KL散度等指标,约束策略模型的更新幅度,确保其不会偏离预训练和SFT阶段学到的通用语言能力和基本常识太远,从而保持生成质量与稳定性。
🤝 协同工作流程
在实际算法中,两者紧密配合。以DPO为例,其损失函数会同时计算策略模型和参考模型对“优胜答案”与“劣汰答案”的生成概率。优化的目标是,在拉大“优胜”与“劣汰”答案之间差距的同时,确保策略模型相对于参考模型的概率分布不会发生剧烈变化。这就像是在“追求更高绩效”和“遵守基本规范”之间取得平衡。
💎 总结
总而言之,策略模型是不断进化、追求卓越的“主角”,而参考模型则是确保进化过程稳健、不失控的“基石”。理解它们的区别与协作方式,是掌握现代大模型对齐技术的关键。
参考模型的参数冻结如何实现?
是的,您提到的这两个方面都非常关键,它们描述的是同一个流程中两个紧密相连的步骤:首先通过代码“设置”参数状态为冻结,然后因为此设置,在训练过程中这些参数“不会”被代码更新。
为了更清晰地理解,我们可以将这个过程分为两个环节:
| 环节 | 核心问题 | 实现方式 | 目的 |
|---|---|---|---|
| 1. 状态设置 | “参数状态冻结”是否需要代码实现? | 需要。通过代码将特定参数的 requires_grad 属性设置为 False。 |
告知PyTorch的自动求导引擎:不要为这些参数计算梯度。 |
| 2. 更新结果 | “参数不更新”是否需要代码实现? | 自动结果。由于没有梯度,优化器在调用 step() 方法时自然不会更新这些参数。 |
达到冻结的最终效果:参数值在训练过程中保持不变。 |
💻 如何通过代码实现冻结
在PyTorch中,实现参数冻结的核心是操作 requires_grad 属性。以下是常见的操作方式:
1. 冻结所有参数
这是最彻底的做法,通常用于模型推理阶段。
# 遍历模型的所有参数,将它们的 requires_grad 属性设置为 False
for param in model.parameters():
param.requires_grad = False
2. 冻结特定层或部分参数
在迁移学习或微调模型中更为常见,只训练新添加的层或部分关键层。
# 只冻结模型的第一个线性层 (lin0)
for param in model.lin0.parameters():
param.requires_grad = False
# 或者,冻结所有批量归一化(BN)层
for module in model.modules():
if isinstance(module, torch.nn.BatchNorm2d):
for param in module.parameters():
param.requires_grad = False
⚙️ 冻结后的训练流程与注意事项
设置好冻结状态后,训练流程会自动忽略这些参数,但有一个重要的优化技巧:
优化器的最佳实践
为了提升训练效率,在初始化优化器时,最好只传入那些需要被训练的参数。
# 推荐做法:使用 filter 函数,只选择 requires_grad 为 True 的参数给优化器
optimizer = torch.optim.Adam(
filter(lambda p: p.requires_grad, model.parameters()),
lr=0.001
)
# 不推荐的做法:即使参数被冻结,优化器仍会遍历所有参数,效率稍低
# optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
验证冻结效果
您可以通过以下方式检查冻结是否成功:
- 检查
requires_grad属性:直接打印参数的requires_grad值。 - 检查梯度
grad:在执行loss.backward()后,被冻结参数的grad应为None。 - 检查参数值:在训练一个周期后,对比被冻结参数的值是否发生变化。
💡 核心概念总结
简单来说,“参数状态冻结”是一个需要通过代码主动执行的“指令”,而**“参数不更新”是这个指令在训练过程中自动达成的“结果”**。
这就好比您给一个团队下达指令(代码设置):“A小组暂停手上的项目”(requires_grad = False)。随后,在项目推进会上(优化器更新 step()),您自然就不会给A小组分配新的任务(参数不更新)。
参数更新的核心代码 (train_pretrain.py)
🎯 逐行代码执行后的模型变化
| 行号 | 代码 | 模型参数变化 | 梯度状态变化 | 显存变化 | 关键作用 |
|---|---|---|---|---|---|
| 54 | scaler.scale(loss).backward() |
❌ 无变化 | ✅ 从None→具体数值 | ⬆️ 增加梯度占用 | 计算梯度 |
| 55 | 空行 | ❌ 无变化 | ❌ 无变化 | ❌ 无变化 | 代码分隔 |
| 56 | if (step + 1) % args.accumulation_steps == 0: |
❌ 无变化 | ❌ 无变化 | ❌ 无变化 | 检查更新条件 |
| 57 | scaler.unscale_(optimizer) |
❌ 无变化 | ✅ 恢复原始大小 | ❌ 无变化 | 恢复梯度大小 |
| 58 | torch.nn.utils.clip_grad_norm_(...) |
❌ 无变化 | ✅ 可能被裁剪 | ❌ 无变化 | 防止梯度爆炸 |
| 59 | 空行 | ❌ 无变化 | ❌ 无变化 | ❌ 无变化 | 代码分隔 |
| 60 | scaler.step(optimizer) |
✅ 实际更新 | ❌ 无变化 | ❌ 无变化 | 真正更新参数 |
| 61 | scaler.update() |
❌ 无变化 | ❌ 无变化 | ❌ 无变化 | 更新缩放器状态 |
| 62 | 空行 | ❌ 无变化 | ❌ 无变化 | ❌ 无变化 | 代码分隔 |
| 63 | optimizer.zero_grad(set_to_none=True) |
❌ 无变化 | ✅ 从具体数值→None | ⬇️ 释放梯度占用 | 清理梯度 |
🔄 完整的执行流程
1. 梯度计算阶段 (第54行)
- 模型参数: 无变化
- 梯度: 从无到有,计算完成
- 显存: 增加梯度占用
- 作用: 计算损失对参数的梯度
2. 梯度处理阶段 (第57-58行)
- 模型参数: 无变化
- 梯度: 缩放恢复和裁剪处理
- 显存: 梯度占用不变
- 作用: 准备梯度用于参数更新
3. 参数更新阶段 (第60行)
- 模型参数: 发生实际变化 (W = W - lr * grad)
- 梯度: 用于更新参数
- 显存: 梯度占用不变
- 作用: 真正更新模型参数
4. 状态更新阶段 (第61行)
- 模型参数: 无变化
- 缩放器: 更新内部状态
- 显存: 无变化
- 作用: 调整缩放因子,为下次迭代做准备
5. 清理阶段 (第63行)
- 模型参数: 无变化
- 梯度: 被清零
- 显存: 释放梯度占用
- 作用: 清理梯度,为下次迭代做准备
🔑 关键理解
- 只有第60行会改变模型参数 - 这是真正的参数更新
- 其他行都是准备或清理工作 - 为参数更新做准备
- 梯度生命周期 - 计算→处理→使用→清零
- 显存管理 - 梯度占用先增加后释放
- 训练流程 - 完成一次完整的参数更新循环
📊 具体数值示例
假设模型参数 W = [0.1, 0.2, 0.3],梯度 grad = [0.5, -0.3, 0.8],学习率 lr = 0.001:
- 执行前: W = [0.1, 0.2, 0.3]
- 第60行执行后: W = [0.0995, 0.2003, 0.2992]
- 执行后: W = [0.0995, 0.2003, 0.2992] (参数已更新)
所以,预训练代码第54-63行的核心作用是完成一次完整的参数更新,其中只有第60行会真正改变模型参数,其他行都是为这次更新做准备和清理工作!
这个核心公式 新参数 = 旧参数 - 学习率 × 梯度 是几乎所有深度学习模型参数更新的基础。它描述了优化算法如何沿着损失函数下降最快的方向,一步步调整模型参数,以最小化损失函数。
为了更清晰地理解这个公式的每个部分及其协同工作方式,请看下表:
| 公式组件 | 数学符号 | 角色与作用 | 实战要点 |
|---|---|---|---|
| 旧参数 | θ_old |
模型当前的“知识状态”,是优化的起点。 | 初始值很重要,通常采用随机初始化或特定初始化方法(如Xavier、He初始化)以避免训练初期出现问题。 |
| 学习率 | η (eta) |
控制参数更新步长的超参数,是训练中的“油门和刹车”。 | 过大会导致损失震荡甚至发散(跳过最优点),过小则收敛缓慢。常需要根据任务调整,或使用学习率调度器(如热身、余弦退火)。 |
| 梯度 | ∇J(θ) |
损失函数在当前参数点的最陡上升方向(因此更新时取负号)。 | 梯度大小和稳定性直接影响训练。梯度消失/爆炸是常见问题,可通过梯度裁剪、归一化等技术缓解。 |
| 新参数 | θ_new |
一次更新后模型的新“知识状态”。 | 目标是使损失函数值更小。整个训练过程就是该公式的不断迭代,直至损失收敛到满意水平。 |
💡 核心逻辑:为什么是“减法”?
公式中的减法是关键。梯度指向的是损失函数值增长最快的方向。而我们的目标是让损失函数最小化,因此需要沿着与梯度相反的方向(即梯度的负方向)更新参数。这就像下山时,你沿着最陡的下坡方向(负梯度方向)走,才能最快到达谷底(损失最小值)。
🛠️ 优化算法的演进
您提到的基础公式是梯度下降的核心。在实际应用中,为了提升训练效率和稳定性,发展出了多种基于此思想的优化算法:
| 算法类型 | 核心思想 | 特点与适用场景 |
|---|---|---|
| 随机梯度下降 | 每次更新只使用一个训练样本计算梯度。 | 速度快,但更新波动大。 |
| 小批量梯度下降 | 折衷方案,每次使用一小批样本计算梯度。 | 兼顾效率与稳定性,是当前最常用的基准方法。 |
| 自适应优化器 | 为每个参数自适应地调整学习率。 | 如 Adam 算法,它综合考虑了梯度的一阶动量(平均值)和二阶动量(方差),在许多任务上表现更稳健,收敛更快,常作为默认选择。 |
⚠️ 训练中的常见问题与对策
即使在明确的更新规则下,训练过程也可能遇到挑战:
- 损失不下降:可能是学习率设置不当、模型架构问题或数据本身的原因。可以尝试调整学习率、检查模型容量或数据质量。
- 损失爆炸或变成NaN:通常是梯度爆炸的迹象。有效的解决方法是进行梯度裁剪,限制梯度的大小。
- 损失波动大:往往意味着学习率可能设得太高了。适当降低学习率或使用学习率调度策略可能有帮助。
💎 总结
总而言之,新参数 = 旧参数 - 学习率 × 梯度 这一公式是深度学习模型学习的引擎。理解其中每个组件的作用及其相互关系,对于有效调试模型、选择合适优化器以及解决训练中出现的各类问题至关重要。
特定的优化器(如**Adam**)
待补充
更多推荐

 27
27 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)