
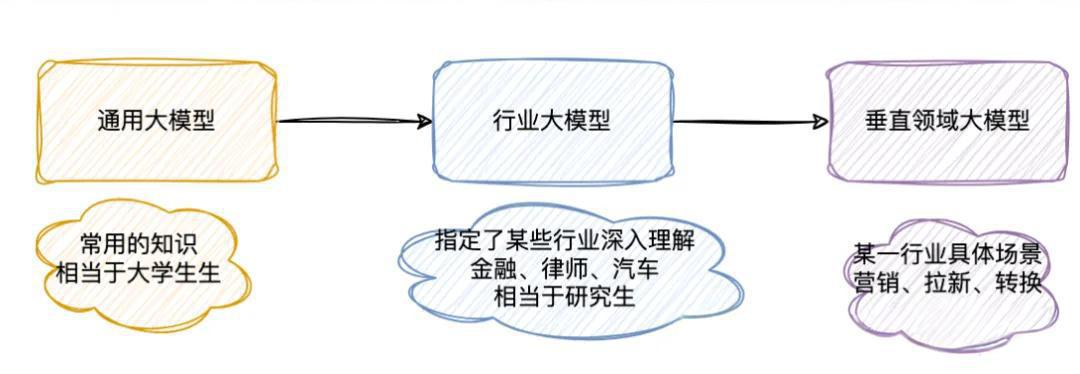
大模型必知基础知识:7、Transformer架构-大模型微调作用和原理详解
大模型微调技术解析:从通用到专业的AI进化之路 本文系统介绍了Transformer架构中大模型微调的核心技术。首先阐述了预训练大模型在专业领域应用时的局限性,指出微调在提升领域专业性、优化输出风格和降低训练成本方面的关键价值。随后详细解析了双阶段训练原理,包括预训练的基础知识积累和微调的专业能力培养。文章重点探讨了多种微调方法:全量微调的参数全面更新、参数高效微调(PEFT)的灵活调整策略、适配
大模型必知基础知识:7、Transformer架构-大模型微调作用和原理详解
总目录
- 大模型必知基础知识:1、Transformer架构-QKV自注意力机制
- 大模型必知基础知识:2、Transformer架构-大模型是怎么学习到知识的?
- 大模型必知基础知识:3、Transformer架构-词嵌入原理详解
- 大模型必知基础知识:4、Transformer架构-多头注意力机制原理详解
- 大模型必知基础知识:5、Transformer架构-前馈神经网络(FFN)原理详解
- 大模型必知基础知识:6、Transformer架构-提示词工程调优
- 大模型必知基础知识:7、Transformer架构-大模型微调作用和原理详解
- 大模型必知基础知识:8、Transformer架构-如何理解学习率 Learning Rate
- 大模型必知基础知识:9、MOE多专家大模型底层原理详解
- 大模型必知基础知识:10、大语言模型与多模态融合架构原理详解
- 大模型必知基础知识:11、大模型知识蒸馏原理和过程详解
- 大模型必知基础知识:12、大语言模型能力评估体系
- 大模型必知基础知识:13、大语言模型性能评估方法
目录
- 当通用模型遇上专业需求:微调的必要性
- 从预训练到微调:理解双阶段训练
- 参数调优的多重境界
- 3.1 全量微调:重塑知识网络
- 3.2 参数高效微调PEFT
- 3.3 适配器插入:微创手术式改造
- 3.4 低秩矩阵微调LoRA
- 3.5 强化学习微调
- 数据准备:喂养AI的营养学
- 开源训练框架:性能优化的登山杖
- 5.1 DeepSpeed与ZeRO优化器
- 5.2 LLaMA Factory
- 总结
一、当通用模型遇上专业需求:微调的必要性
想象你手中有一本重达10公斤的百科全书,它通晓古今、博闻强识,但当你需要查询某个专业领域的问题时,却发现书中内容过于宽泛、缺乏深度。这时候,你最需要的是给这本通才书籍装上某个领域的专业索引,让它变成真正的领域专家。这就是大模型微调的核心价值所在。
在人工智能领域,像GPT-3、BERT这样的预训练大模型,就如同读遍互联网文本的超级学霸。它们掌握了语言的基本规律、常识性知识和基础推理能力。但当我们需要它们处理特定任务时,比如医疗诊断、法律文书生成或智能客服对话,这些通才模型往往会显得水土不服。
1.1 真实案例:医疗领域的微调实践
某医院尝试用通用大模型解读CT报告,结果发现模型经常混淆肺结节和肺炎这样的专业术语。直到他们用2000份精心标注的CT报告进行微调,模型的准确率才从68%跃升到93%。这个质的飞跃,正是微调技术的魔力所在。
1.2 微调的核心优势
提升领域专业性:通用大模型主要掌握互联网上公开可获取的知识,通过领域数据微调,可以让大模型学习企业私有化业务知识和专业领域的细节知识。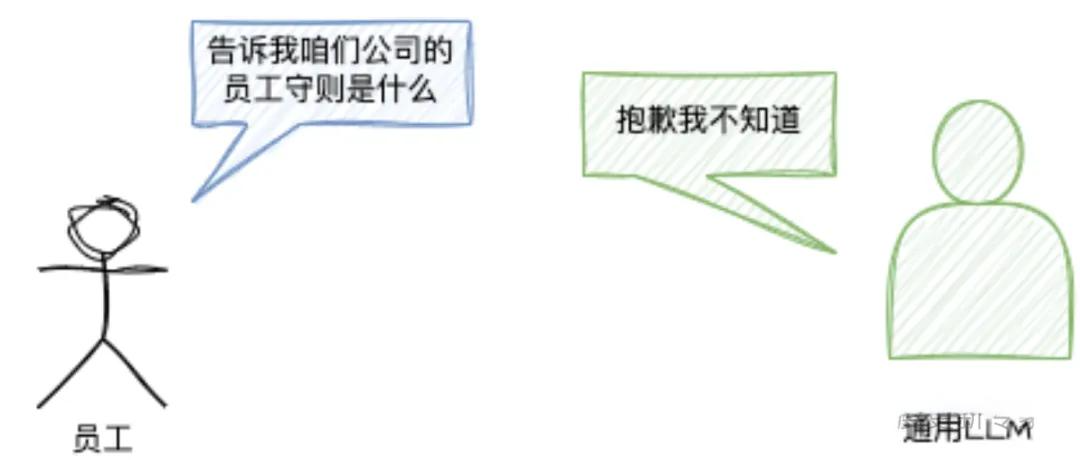
优化输出风格:在模型训练过程中,让模型的表达方式更贴近人类需求。比如,我们让大模型写报告时,目前主流模型都会自动输出标题、序号、总结等关键信息,这就是微调带来的效果。
降低训练成本:相比从头训练一个新模型,微调可以在预训练模型的基础上进行,大幅降低计算资源和时间成本。
二、从预训练到微调:理解双阶段训练
要理解微调的本质,必须先看清预训练和微调这对双人舞的关系。
2.1 预训练阶段:铺就底色
预训练阶段就像在空白画布上铺就底色。模型通过以下方式在海量文本中学习语言规律:
掩码语言模型(MLM):如BERT采用的方法,通过预测被遮盖的词语来学习上下文关系。
自回归语言模型(AR):如GPT系列采用的方法,通过预测下一个词来学习语言生成能力。
这个阶段需要消耗惊人的算力。据公开资料显示,GPT-3的预训练成本超过500万美元,需要在数千块GPU上训练数周时间。
2.2 微调阶段:精雕细琢
微调则是艺术家在底色上作画的过程。当我们用特定任务的数据,比如电商评论情感分析数据集,对模型进行二次训练时,本质上是在调整神经网络中数以亿计的连接权重。
就像画家调整颜料配比,微调需要找到最优的:
学习率(Learning Rate):控制每次调整的幅度,通常设置为预训练时的1/10到1/100。学习率过大可能导致模型遗忘预训练知识,过小则训练效率低下。
训练步数(Training Steps):决定调整的次数,需要根据数据集大小和任务复杂度来设定。
批次大小(Batch Size):每次训练使用的样本数量,影响训练的稳定性和速度。
2.3 类比理解
一个形象的类比是:预训练像人类接受基础教育,掌握读写能力和基础知识;微调则像大学专业课学习,让模型在特定领域精进技能。两者配合,才能培养出既博学又专精的AI人才。
预训练提供了广泛的知识基础和语言理解能力,而微调则将这些通用能力聚焦到特定任务上,实现专业化和个性化。
三、参数调优的多重境界
3.1 全量微调:重塑知识网络
定义与原理
全量微调(Full Fine-Tuning, FFT)是指在预训练好的大模型基础上,针对特定任务或数据集进行进一步训练,更新模型的所有参数。预训练模型通常在大规模数据上进行了广泛训练,已经具备了一定的通用知识和特征提取能力。通过全量微调,可以将这些通用知识迁移到特定任务上,从而提高模型在该任务上的性能。
主要调整内容
-
所有层的权重:预训练模型的所有层,包括嵌入层、隐藏层、输出层等,的权重都会在微调过程中进行更新。每一层的所有部分都会根据提供的数据进行优化。
-
偏置项:除了权重外,每个神经元的偏置项也会被调整。
-
任务特定的输出层:通常情况下,预训练模型的输出层不适合特定任务。因此,需要在预训练模型的基础上添加或修改任务特定的输出层。
优缺点分析
优点:
- 充分利用预训练模型的通用知识,减少从零开始训练所需的时间和资源
- 在数据集较小的情况下,性能相对较好
- 可以获得最佳的任务性能
缺点:
- 计算资源需求大,需要大量GPU显存
- 在数据集较小的情况下,容易导致过拟合
- 在大规模数据集上训练耗时长
- 存储成本高,每个任务都需要保存完整的模型副本
3.2 参数高效微调(PEFT)
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)是一系列只对部分参数进行调整的方法统称,旨在减少训练参数数量,降低计算和存储成本。
3.2.1 冻结微调(Frozen Fine-tuning)
定义:只更新模型的顶层或少数几层,而保持预训练模型的底层参数不变。
应用场景:目标任务与预训练模型之间有一定相似性,或者任务数据集较小。但是微调性能很难达到最佳。
实现方式:
# 冻结除最后一层外的所有参数
for name, param in model.named_parameters():
if 'classifier' not in name: # 假设最后一层名为classifier
param.requires_grad = False
3.2.2 逐层微调(Layer-wise Fine-tuning)
定义:从顶层开始,逐渐向底层推进。这种方法允许更细粒度地控制模型的调整过程,直到所有层都被微调。
应用场景:适用于需要精细调整模型的任务。但是需要多次调整与训练,且花费时间较长。
策略:
- 先训练顶层,固定其他层
- 逐步解冻更深的层
- 每解冻一层,降低学习率
3.2.3 动态微调(Dynamic Fine-tuning)
定义:在微调过程中动态调整学习率、批量大小等超参数,以优化模型性能。
应用场景:适用于需要高性能和高精度的任务。实现方式复杂且对资源要求较高。
技术要点:
- 学习率预热(Warmup)
- 余弦退火学习率调度
- 梯度裁剪
- 早停策略
3.3 适配器插入:微创手术式改造
2020年提出的Adapter方法,就像给模型安装知识外挂。在不改动原始参数的前提下,在层与层之间插入小型神经网络模块。
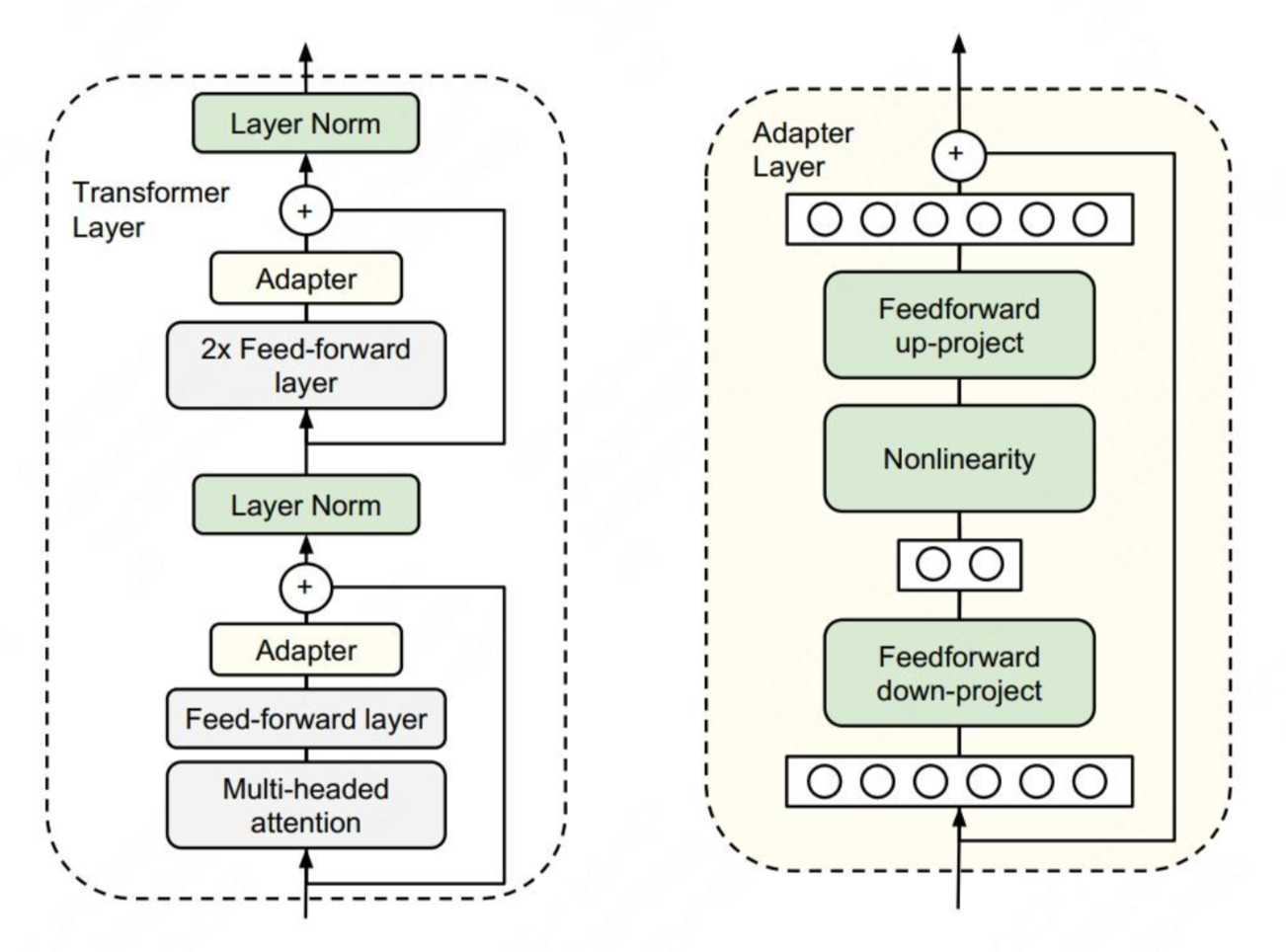
核心原理
通过在预训练模型中插入适配器模块(Adapters)来实现对特定任务的适应,不需要更新整个模型的参数。适配器模块插入到各个层中,每个模块都仅由少量参数组成。
技术细节
适配器模块主要通过非线性的方式实现维度变换:
-
降维:将高维度数值映射为低维度(Down-projection)
h d o w n = f ( W d o w n ⋅ x + b d o w n ) h_{down} = f(W_{down} \cdot x + b_{down}) hdown=f(Wdown⋅x+bdown) -
升维:再将关键的低维度数值映射到高维度(Up-projection)
h u p = W u p ⋅ h d o w n + b u p h_{up} = W_{up} \cdot h_{down} + b_{up} hup=Wup⋅hdown+bup -
跳跃连接:使用残差连接保证初始参数为零时直接从输入到输出
o u t p u t = x + h u p output = x + h_{up} output=x+hup
显著优势
- 只需训练0.1%的参数量,就能达到媲美全量微调的效果
- 微软实验证明,Adapter在保持模型主体不变的情况下,能让同一个基础模型适配100多个不同任务
- 多个适配器可以存在同一模型中,每种适配器可以处理单独的一类问题
局限性
- 需要直接插入到模型层级中,导致训练复杂度与设计难度较高
- 比较容易产生过拟合等问题
- 推理时需要额外的前向传播计算
3.4 低秩矩阵微调LoRA
LoRA(Low-Rank Adaptation)是当前最主流的参数高效微调方法,由微软在2021年提出。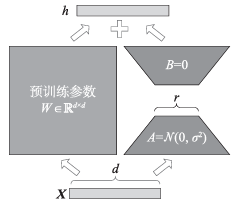
核心思想
LoRA的核心思想是将预训练模型的权重矩阵分解为两个低秩矩阵的乘积。假设原有矩阵权重为 W ∈ R d × k W \in \mathbb{R}^{d \times k} W∈Rd×k,在微调过程中保持 W W W 冻结,同时引入两个低秩矩阵 A ∈ R d × r A \in \mathbb{R}^{d \times r} A∈Rd×r 和 B ∈ R r × k B \in \mathbb{R}^{r \times k} B∈Rr×k,其中 r ≪ min ( d , k ) r \ll \min(d,k) r≪min(d,k)。
微调后的权重为:
W ′ = W + Δ W = W + B A W' = W + \Delta W = W + BA W′=W+ΔW=W+BA
其中:
- W W W:预训练权重(冻结不变)
- A A A:使用随机高斯分布初始化
- B B B:使用零初始化,确保训练开始时 Δ W = 0 \Delta W = 0 ΔW=0
- r r r:秩(rank),是一个远小于 d d d 和 k k k 的超参数
参数量计算
原始参数量: d × k d \times k d×k
LoRA参数量: d × r + r × k d \times r + r \times k d×r+r×k
当 r = 8 r = 8 r=8, d = k = 4096 d = k = 4096 d=k=4096 时,参数量从 16M 降低到约 131K,降低了99%以上。
实践要点
-
应用位置:通常应用于Transformer的注意力层( W q W_q Wq, W k W_k Wk, W v W_v Wv, W o W_o Wo)
-
秩的选择:
- r = 1 , 2 , 4 r = 1, 2, 4 r=1,2,4:适合简单任务
- r = 8 , 16 r = 8, 16 r=8,16:适合中等复杂度任务
- r = 32 , 64 r = 32, 64 r=32,64:适合复杂任务
-
缩放因子:使用缩放因子 α / r \alpha / r α/r 调整更新幅度
优势
- 大幅减少训练参数数量,降低计算和存储成本
- 资源少的情况下依然可以进行模型微调
- 灵活性较高,能适用多种场景
- 推理时无额外延迟,可以直接合并权重: W ′ = W + B A W' = W + BA W′=W+BA
- 支持多任务,可以为不同任务训练不同的LoRA模块
局限性
- 有一定技术复杂性,相对全参调整需要多次尝试与实验
- 训练结果有时不稳定,存在一定玄学成分
- 需要多次尝试才能找到最优的秩和学习率配置
最新进展
根据最新研究,LoRA领域涌现出多个改进方向:
-
自适应秩分配:
- GeLoRA:利用隐藏表示的内在维度确定各层LoRA最低秩需求
- LoRA-Mini:通过矩阵拆分实现高达20倍的可训练参数减少
-
秩共享方法:
- RaSA:跨层共享低秩基向量,在不增加参数的情况下提升表达能力
- 在代码生成、数学推理等任务上显著改善性能
-
LoRA与MoE结合:
- MoLoRA:将LoRA与混合专家(MoE)框架结合
- 每一层插入多个并行的LoRA权重,路由模块决定激活哪些LoRA模块
- 在保持参数高效的同时,性能接近甚至超过全量微调
目前主流的微调方式就是LoRA低秩矩阵微调,训练速度非常快,节省资源。但训练结果有时不稳定,因为微调过程依赖模型的反向更新,有时没有更新到相关知识点,就会导致出现模型幻觉,需要多次尝试。这个过程被趣称为炼丹。
3.5 强化学习微调
强化学习微调,特别是基于人类反馈的强化学习(RLHF, Reinforcement Learning from Human Feedback),是训练ChatGPT等对话模型的关键技术。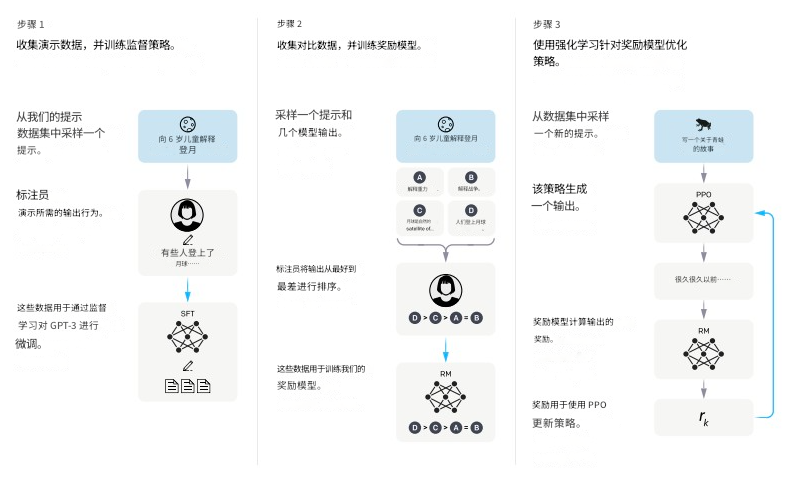
三步训练流程
第一步:训练监督策略模型(SFT)
- 数据采集:从提示词数据集中取样一个提示词
- 人工标注:数据标记工程师给出期望的输出行为
- 监督学习:通过监督学习微调模型,使其能够基于提示词生成接近预期的内容
数学表示:
max θ E ( x , y ) ∼ D [ log P θ ( y ∣ x ) ] \max_{\theta} \mathbb{E}_{(x,y) \sim D} [\log P_{\theta}(y|x)] θmaxE(x,y)∼D[logPθ(y∣x)]
其中 D D D 是标注数据集, θ \theta θ 是模型参数。
第二步:训练奖励模型(RM)
- 生成样本:取样一个提示词,让模型生成多个不同的输出
- 排序标注:数据标记工程师对这些输出进行质量排序
- 训练奖励模型:用这些带有评分的样本训练奖励模型,学习预测哪些输出更符合人类标准
奖励模型的目标:
min ϕ E ( x , y w , y l ) ∼ D [ − log σ ( r ϕ ( x , y w ) − r ϕ ( x , y l ) ) ] \min_{\phi} \mathbb{E}_{(x,y_w,y_l) \sim D} [-\log \sigma(r_{\phi}(x,y_w) - r_{\phi}(x,y_l))] ϕminE(x,yw,yl)∼D[−logσ(rϕ(x,yw)−rϕ(x,yl))]
其中 y w y_w yw 是较好的输出, y l y_l yl 是较差的输出, r ϕ r_{\phi} rϕ 是奖励模型。
第三步:采用近端策略优化(PPO)进行强化学习
- 采样:从提示词数据集取样新的提示词
- 初始化:PPO模型由第一步的SFT模型初始化
- 生成输出:模型根据提示词生成完整输出
- 计算奖励:奖励模型评价生成的内容,给出奖励值
- 策略更新:利用PPO算法结合奖励更新策略,使模型在未来能生成更高质量的输出
PPO的目标函数:
max θ E x , y [ r ϕ ( x , y ) − β log π θ ( y ∣ x ) π r e f ( y ∣ x ) ] \max_{\theta} \mathbb{E}_{x,y}[r_{\phi}(x,y) - \beta \log \frac{\pi_{\theta}(y|x)}{\pi_{ref}(y|x)}] θmaxEx,y[rϕ(x,y)−βlogπref(y∣x)πθ(y∣x)]
其中 π r e f \pi_{ref} πref 是参考模型(SFT模型), β \beta β 是KL散度系数,用于防止模型偏离太远。
其他强化学习算法
除了PPO,还有其他强化学习算法用于大模型微调:
- DPO(Direct Preference Optimization):直接优化偏好,无需训练独立的奖励模型
- GRPO(Group Relative Policy Optimization):群体相对策略优化
- RLHF-V(RLHF with Verifier):结合验证器的强化学习
应用场景
- 对话系统的人性化调优
- 代码生成的正确性提升
- 内容安全性过滤
- 减少模型幻觉
- 提升指令遵循能力
四、数据准备:喂养AI的营养学
优质数据是微调成功的基石。在AI训练中,垃圾数据喂不出金凤凰这句话再准确不过。
4.1 典型案例:智能家居语音助手优化
某智能家居公司的案例极具代表性。他们最初用5万条用户指令微调语音助手,效果不佳。经过深入分析,发现数据中存在三大问题:
问题一:类别不均衡
- 80%的数据是打开空调这类简单指令
- 复杂的场景控制指令只占5%
- 导致模型对简单指令过拟合,对复杂指令理解能力差
问题二:噪声数据
- 包含方言和外语混杂的录音
- 存在背景噪音干扰
- 有语音识别错误的文本
问题三:标注不一致
- 同义词未统一,如开灯、打开灯、把灯打开
- 不同标注员对同类指令理解不一致
- 缺乏明确的标注规范
4.2 数据清洗与预处理流程
4.2.1 文本质量过滤
使用TF-IDF过滤无意义文本
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(max_features=1000)
tfidf_matrix = vectorizer.fit_transform(texts)
# 过滤TF-IDF分数过低的样本
长度过滤:
- 过短的文本(<5个字)可能信息不足
- 过长的文本(>512个token)可能包含无关信息
去重:
- 完全重复的样本
- 高度相似的样本(余弦相似度 > 0.95)
4.2.2 类别平衡
通过聚类算法平衡类别分布
方法一:过采样(Oversampling)
- 对少数类样本进行复制
- 使用SMOTE等算法生成合成样本
方法二:欠采样(Undersampling)
- 对多数类样本进行采样
- 保留最具代表性的样本
方法三:类别权重调整
- 在损失函数中为不同类别设置不同权重
- 少数类权重更高,多数类权重更低
4.2.3 标注规范化
构建同义词库统一表达
synonym_dict = {
'开灯': ['打开灯', '把灯打开', '点亮', '开启照明'],
'关灯': ['关闭灯', '把灯关了', '熄灯', '关闭照明']
}
多轮标注质量控制:
- 多个标注员独立标注
- 计算标注一致性(Cohen’s Kappa)
- 对不一致的样本进行讨论和修正
4.3 数据增强技术
文本增强方法:
- 回译(Back Translation):中文→英文→中文
- 同义词替换:保持语义的词汇替换
- 随机插入/删除:在句子中随机插入或删除词汇
- EDA(Easy Data Augmentation):
- 随机插入
- 随机交换
- 随机删除
- 同义词替换
4.4 优化结果
经过改进的数据清洗和平衡流程,该智能家居公司的语音助手模型理解准确率从原来的73%提升到了95%以上,提升了27个百分点。这印证了数据质量对模型性能的决定性影响。
4.5 数据准备最佳实践
-
数据量要求:
- 简单任务:1000-5000条高质量样本
- 中等任务:5000-20000条样本
- 复杂任务:20000+条样本
-
数据质量标准:
- 准确性:标注正确率 > 95%
- 一致性:标注者间一致性 > 0.8(Kappa值)
- 覆盖性:覆盖目标场景的主要情况
- 多样性:避免样本过于相似
-
持续优化:
- 定期评估模型在真实场景的表现
- 收集模型预测错误的案例
- 针对性地补充训练数据
- 迭代优化模型性能
五、开源训练框架:性能优化的登山杖
在实际训练和微调大模型时,由于大模型的参数量很大,训练效率和所消耗的资源、时间是不可忽视的指标。在实际训练大语言模型时一般需要配备多GPU集群,但实际的机器利用率往往只能达到其最大效率的一半左右。这说明,仅仅堆砌硬件并不能有效提升模型训练效率。同样,即使系统具有更高的吞吐量,也并不能保证所训练出的模型具有更高的精度或更快的收敛速度。
5.1 DeepSpeed与ZeRO优化器
5.1.1 DeepSpeed简介
DeepSpeed是微软开发的开源深度学习优化库,旨在提高大规模模型训练的效率和可扩展性。它通过多种技术手段来加速训练,包括:
- 模型并行化(Model Parallelism)
- 数据并行化(Data Parallelism)
- 梯度累积(Gradient Accumulation)
- 动态精度缩放(Dynamic Precision Scaling)
- 混合精度训练(Mixed Precision Training)
DeepSpeed已经在许多大规模深度学习项目中得到应用,包括语言模型、图像分类、目标检测等。它使得在资源有限的情况下训练超大规模模型成为可能。
5.1.2 ZeRO:零冗余优化器
ZeRO(Zero Redundancy Optimizer)是DeepSpeed的核心技术,它通过消除数据并行训练中的内存冗余来大幅减少训练内存占用。
传统数据并行的问题
在传统的数据并行训练中,每个GPU都维护:
- 完整的模型参数副本
- 完整的优化器状态副本
- 完整的梯度副本
这导致了严重的内存冗余。例如,对于一个拥有75亿参数的模型,使用Adam优化器,每个GPU需要约120GB内存,这超出了目前大多数GPU的显存容量。
ZeRO的三个阶段
ZeRO通过三个递进的优化阶段来解决这个问题:
ZeRO-1:优化器状态分区(Optimizer State Partitioning)
- 将优化器状态分片到不同GPU上
- 每个GPU只存储和更新部分优化器状态
- 内存节省:4倍(对于Adam优化器)
- 适合中等规模模型
- 通信开销最小
内存占用:
M e m o r y = 4 Ψ + ( 2 + K ) Ψ N d Memory = \frac{4 \Psi + (2 + K) \Psi}{N_d} Memory=Nd4Ψ+(2+K)Ψ
其中 Ψ \Psi Ψ 是参数量, K K K 是优化器状态系数(Adam为12), N d N_d Nd 是数据并行度。
ZeRO-2:梯度分区(Gradient Partitioning)
- 在ZeRO-1基础上,进一步分区梯度
- 每个GPU只需要存储和计算部分梯度
- 内存节省:8倍
- 支持更大规模模型
- 训练速度显著提升
内存占用:
M e m o r y = 2 Ψ + ( 2 + K ) Ψ N d Memory = \frac{2 \Psi + (2 + K) \Psi}{N_d} Memory=Nd2Ψ+(2+K)Ψ
ZeRO-3:参数分区(Parameter Partitioning)
- 最激进的优化策略,连模型参数都进行分区
- 每个GPU只存储部分模型参数
- 在前向和反向传播时,动态获取所需参数
- 内存节省:与GPU数量成线性关系
- 支持超大规模模型(千亿参数级别)
- 具有超线性可扩展性
内存占用:
M e m o r y = ( 4 + K ) Ψ N d Memory = \frac{(4 + K) \Psi}{N_d} Memory=Nd(4+K)Ψ
ZeRO-Offload与ZeRO-Infinity
- ZeRO-Offload:将优化器状态和梯度卸载到CPU内存
- ZeRO-Infinity:进一步卸载到NVMe存储
- 可以在单GPU上训练万亿参数模型
5.1.3 DeepSpeed实践配置
{
"train_batch_size": 64,
"gradient_accumulation_steps": 4,
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.9, 0.999],
"eps": 1e-8,
"weight_decay": 0.01
}
},
"fp16": {
"enabled": true,
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true
},
"activation_checkpointing": {
"partition_activations": true,
"cpu_checkpointing": true,
"contiguous_memory_optimization": true,
"synchronize_checkpoint_boundary": false
}
}
5.1.4 性能优势
根据微软的测试数据:
- 使用ZeRO-3可以在64个V100 GPU上训练1750亿参数的模型
- 相比传统方法,训练速度提升10倍以上
- 内存效率提升高达64倍
- 支持从单GPU到数千GPU的灵活扩展
5.2 LLaMA Factory
LLaMA Factory是一个专为大语言模型设计的开源微调框架,特别注重易用性和效率。
5.2.1 核心特点
用户友好性
- 提供零代码的图形用户界面(LlamaBoard)
- 用户可以通过简单的操作进行模型微调
- 支持可视化监控训练过程
- 降低了技术门槛,非专业人员也能使用
高效微调
- 集成了多种参数高效微调技术:
- LoRA(Low-Rank Adaptation)
- QLoRA(Quantized LoRA)
- Prompt Tuning
- P-Tuning v2
- AdaLoRA
- 能够在有限资源下实现高效训练
- 支持4bit和8bit量化训练
多模型支持
LLaMA Factory支持超过100种大型语言模型,包括:
- LLaMA系列:LLaMA, LLaMA-2, LLaMA-3
- 中文模型:ChatGLM, ChatGLM2, ChatGLM3, Baichuan, Qwen
- 开源模型:Falcon, Mistral, Mixtral, Yi, DeepSeek
- 多模态模型:LLaVA, InternVL
5.2.2 使用场景
适合快速原型开发
- 可以在几小时内完成模型微调
- 支持小型和中型数据集(1K-100K样本)
- 适合快速验证想法和概念
降低技术门槛
- 适用于对大模型微调有需求但缺乏深厚技术背景的用户
- 教育和研究机构的理想选择
- 企业快速部署定制化模型的利器
5.2.3 LLaMA Factory快速上手
安装
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -r requirements.txt
启动Web界面
python src/train_web.py
命令行微调示例
python src/train_bash.py \
--model_name_or_path meta-llama/Llama-2-7b-hf \
--stage sft \
--do_train \
--dataset alpaca_zh \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir output/llama2_lora \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
5.2.4 数据格式
LLaMA Factory支持多种数据格式:
Alpaca格式
[
{
"instruction": "用户的指令",
"input": "可选的输入",
"output": "期望的输出"
}
]
ShareGPT格式
[
{
"conversations": [
{
"from": "human",
"value": "用户消息"
},
{
"from": "gpt",
"value": "助手回复"
}
]
}
]
5.3 其他主流框架
5.3.1 阿里MS-Swift
- 特点:阿里达摩院开发,深度集成阿里云生态
- 优势:支持魔搭社区的所有模型,中文文档完善
- 适用:国内用户,需要中文支持的场景
5.3.2 Unsloth
- 特点:专注于速度优化,号称比标准方法快2-5倍
- 优势:内存优化出色,支持长序列训练
- 适用:资源受限的环境,追求极致速度
5.3.3 PyTorch原生
- 特点:使用PyTorch底层API直接编写训练代码
- 优势:完全的灵活性和控制力,可以实现任何自定义逻辑
- 适用:有深厚技术背景,需要完全定制化的场景
PyTorch微调示例
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
from peft import get_peft_model, LoraConfig, TaskType
# 加载模型
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
# 配置LoRA
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"]
)
# 应用LoRA
model = get_peft_model(model, peft_config)
# 训练配置
training_args = TrainingArguments(
output_dir="./output",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
fp16=True,
logging_steps=10,
save_steps=100
)
# 开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer
)
trainer.train()
5.4 框架选择指南
| 框架 | 易用性 | 性能 | 灵活性 | 适用场景 |
|---|---|---|---|---|
| LLaMA Factory | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | 快速原型,教育,中小规模 |
| DeepSpeed | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 大规模训练,多GPU集群 |
| MS-Swift | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 国内用户,魔搭生态 |
| Unsloth | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 资源受限,追求速度 |
| PyTorch原生 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 完全定制,研究开发 |
六、总结与展望
6.1 核心要点回顾
微调的本质价值
大模型微调不是简单的模型调参,而是在预训练模型的通用知识基础上,注入领域专业知识和任务特定能力的过程。它让通才模型变成专才模型,让博学者变成专家。
技术方法的选择
- 全量微调:追求最佳性能,资源充足时的首选
- LoRA:当前主流方案,平衡了性能和效率
- Adapter:适合多任务场景,灵活性高
- 强化学习:提升模型的人性化和安全性
数据质量至关重要
垃圾数据喂不出金凤凰。数据的质量、数量、多样性和标注一致性直接决定了微调的成功与否。在实践中,花费80%的时间在数据准备上是值得的。
工具框架的重要性
合适的工具可以事半功倍。LLaMA Factory降低了入门门槛,DeepSpeed突破了规模限制,不同框架各有优势,应根据实际需求选择。
6.2 最佳实践建议
1. 明确目标
- 清晰定义微调要解决的具体问题
- 设定可量化的性能指标
- 评估资源约束(计算、存储、时间)
2. 数据先行
- 投入足够时间进行数据收集和清洗
- 确保数据质量和标注一致性
- 保持数据的多样性和代表性
3. 渐进式优化
- 从小规模实验开始
- 逐步增加数据量和模型复杂度
- 持续监控和评估性能
4. 超参数调优
- 学习率:通常为预训练的1/10到1/100
- 批次大小:根据GPU显存调整
- 训练轮数:关注验证集性能,及时早停
5. 防止过拟合
- 使用验证集监控性能
- 采用Dropout和权重衰减
- 数据增强技术
- 早停策略
6.3 未来发展趋势
更高效的微调方法
- 自适应微调:自动确定哪些层需要调整,哪些参数更重要
- 元学习:让模型学会如何快速适应新任务
- 持续学习:模型能够不断学习新知识而不遗忘旧知识
更强大的多模态微调
- 文本、图像、音频、视频的联合微调
- 跨模态知识迁移
- 统一的多模态表示学习
更安全的微调技术
- 防止模型被恶意微调
- 保护训练数据隐私
- 确保模型输出的安全性和可控性
更低门槛的微调工具
- 零代码微调平台
- 自动化的超参数搜索
- 云端一站式微调服务
联邦微调与隐私保护
- 在不共享原始数据的前提下进行联合微调
- 差分隐私技术的应用
- 去中心化的模型训练
6.4 实践建议
对于初学者:
- 从LLaMA Factory这样的易用框架开始
- 使用公开数据集练手(如Alpaca、Belle)
- 从小模型开始(7B以下)
- 重点关注数据质量而非数量
对于进阶用户:
- 深入学习LoRA和QLoRA的原理
- 掌握DeepSpeed的使用
- 尝试多任务联合微调
- 探索领域特定的微调策略
对于企业应用:
- 建立标准化的数据标注流程
- 搭建自动化的训练和评估平台
- 持续收集真实场景的反馈数据
- 建立模型版本管理和A/B测试机制
6.5 结语
大模型微调技术正在快速发展,从最初的全量微调到如今的LoRA、QLoRA等参数高效方法,我们看到了技术的不断进步。微调不仅降低了大模型应用的门槛,也让更多的个人和企业能够构建自己的专属AI系统。
然而,微调不是万能的。它需要高质量的数据、合理的方法选择、充足的计算资源和持续的优化迭代。正如炼丹一词所暗示的,微调有时需要一些经验和运气,但更多的是科学的方法和工程的积累。
更多推荐


 19
19 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)