
RAG各模块联合优化思路:多智能体协作建模-MMOA-RAG浅尝
RAG各模块联合优化思路:多智能体协作建模-MMOA-RAG浅尝现有RAG系统的:传统方法(如监督微调SFT)单独优化查询重写、文档检索、答案生成等模块,但单个模块的“”无法保证最终答案的“(ps:这一点可以通过之前的一个分类比赛准确性分析理解《》)。MMOA-RAG创新点是将RAG系统的,让所有智能体的优化目标统一对齐到“最终答案质量”(如F1分数),通过多智能体强化学习(MAPPO算法)实现模
RAG各模块联合优化思路:多智能体协作建模-MMOA-RAG浅尝
现有RAG系统的各个模块的任务目标不一致:传统方法(如监督微调SFT)单独优化查询重写、文档检索、答案生成等模块,但单个模块的“局部最优”无法保证最终答案的“全局最优”。(ps:这一点可以通过之前的一个分类比赛准确性分析理解《CCF-BDCI-数字安全公开赛:基于人工智能的漏洞数据分类冠军方案》)。
MMOA-RAG创新点是将RAG系统的可训练模块建模为协作式多智能体,让所有智能体的优化目标统一对齐到“最终答案质量”(如F1分数),通过多智能体强化学习(MAPPO算法)实现模块间的联合优化,解决这个问题。
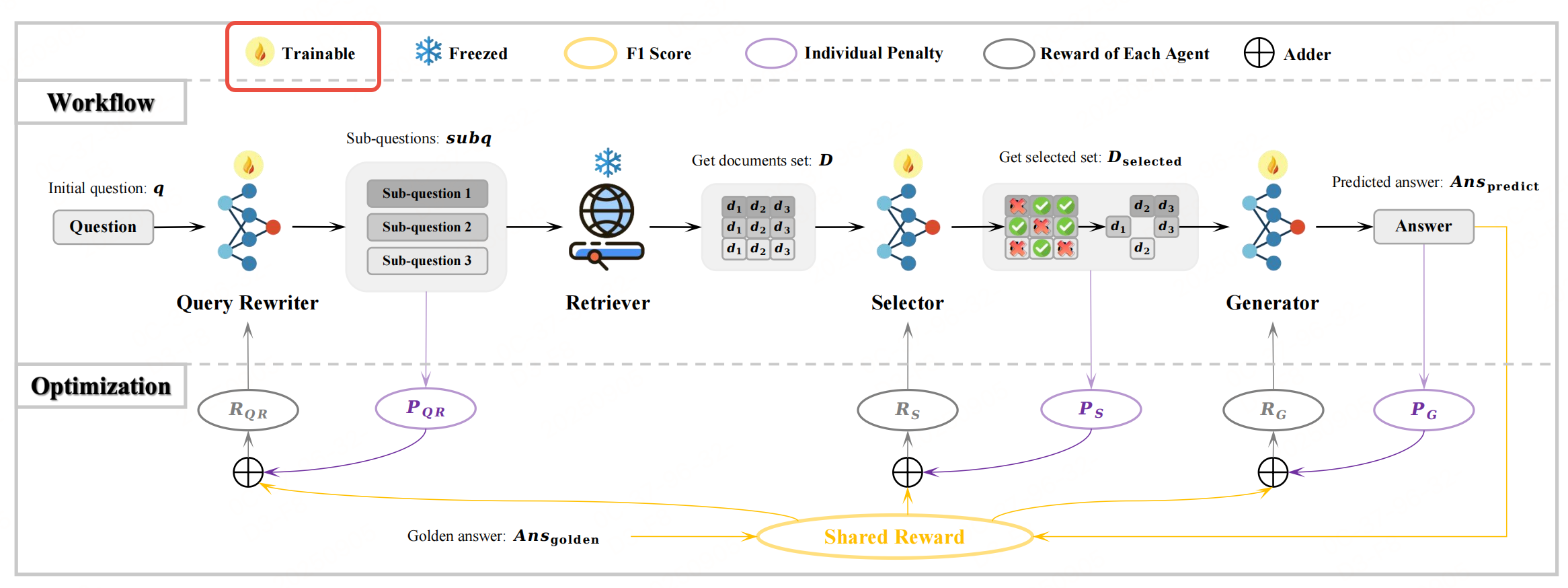
总结如下:
| 模块 | 角色(智能体/环境) | 功能 |
|---|---|---|
| 查询重写器(QR) | 智能体(可训练) | 将复杂/模糊的初始问题q拆解为多个子问题subq,提升后续检索的精准度。 |
| 文档检索器(Retriever) | 环境(固定,建模为RL智能体难度较高,使用Contriever、BGE等成熟检索模型) | 根据每个subq从语料库中检索候选文档集D(默认K=10个文档,如2个subq各检索5个)。 |
| 文档选择器(S) | 智能体(可训练) | 从D中筛选出对生成答案真正有用的子集D_selected,过滤噪声文档。 |
| 答案生成器(G) | 智能体(可训练) | 基于q和D_selected生成最终预测答案Ans_predict。 |
联合优化需要实现参数共享:三个智能体复用同一LLM参数(通过不同提示词区分任务),降低计算开销。
两阶段优化
MMOA-RAG的训练分为“预热SFT”和“多智能体优化(MAPPO)”两阶段,确保模型先掌握基础功能,再通过协作agent提升性能。
阶段1:预热SFT
让每个智能体先学会“基础任务逻辑”(如QR拆解问题、S选择文档、G生成答案),为后续强化学习提供“基线模型”。
数据集构建
针对三个智能体分别构建SFT数据:
- QR的SFT数据:复用Rewrite-Retrieve-Read论文的公开查询重写数据集(问题→子问题对);
- S的SFT数据:用启发式方法标注“有用文档ID”:
- 对问题
q和黄金答案Ans_golden,去除停用词、小写化后得到词集Set_q; - 对每个候选文档
d,同样处理得到Set_d; - 若
Set_q与Set_d有交集,则标注d的ID为“有用”;
- 对问题
- G的SFT数据:以“
q+D_selected→Ans_golden”为样本(Ans_golden为黄金答案)。
损失函数
采用标准语言建模损失,最小化模型预测与标签的负对数似然:
L S F T ( θ ) = − ∑ n = 1 N log P ( Y n ∣ X n ; θ ) \mathcal{L}_{SFT}(\theta) = -\sum_{n=1}^{N} \log P(Y_{n} | X_{n} ; \theta) LSFT(θ)=−n=1∑NlogP(Yn∣Xn;θ)
- X n X_n Xn:每个智能体的输入(如QR的 X n = O Q R X_n = O_{QR} Xn=OQR);
- Y n Y_n Yn:每个智能体的标签(如QR的 Y n = s u b q Y_n = subq Yn=subq);
- θ \theta θ:LLM参数。
阶段2:多智能体优化(MAPPO)
MAPPO是PPO的多智能体扩展,支持“共享全局奖励”,适合完全协作场景。
模型组件
训练过程中涉及三个模型:
- Actor模型(参数 θ \theta θ):负责为每个智能体生成动作(如QR生成子问题、S输出ID);
- Critic模型(参数 ϕ \phi ϕ):负责估计“状态价值” V ϕ ( s ) V_\phi(s) Vϕ(s),用于计算优势函数(衡量动作的“额外收益”);
- SFT模型(参数 θ S F T \theta_{SFT} θSFT):作为基线,防止Actor模型偏离基础任务逻辑(类似InstructGPT的KL惩罚)。
实验性能
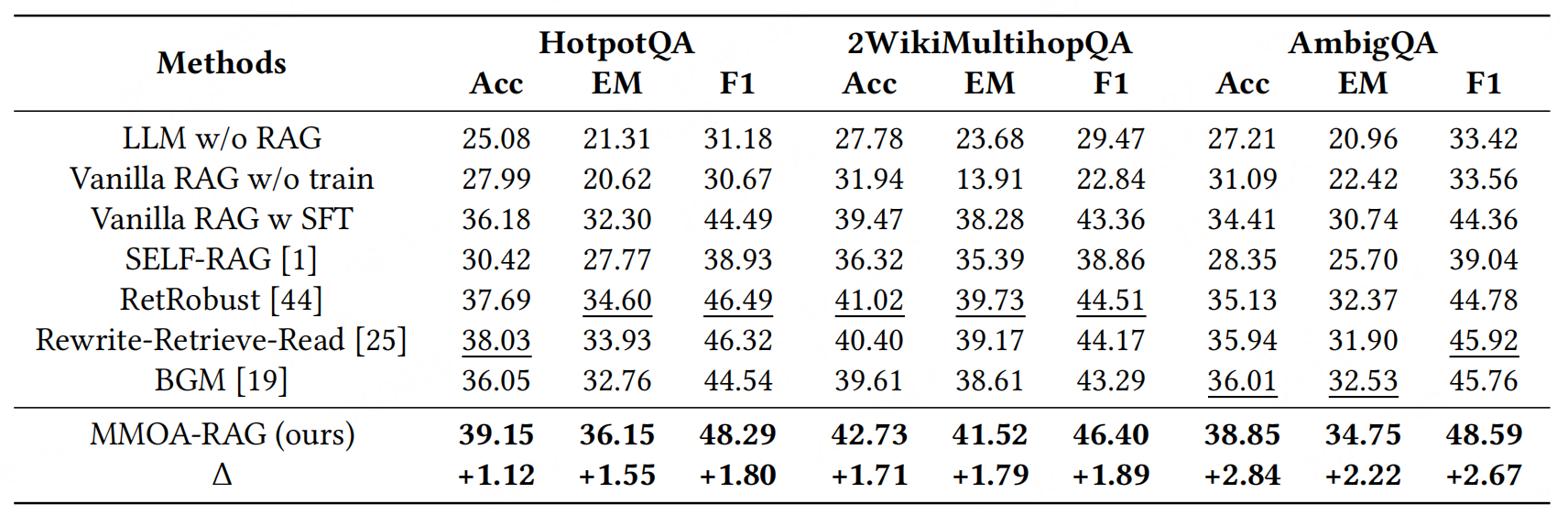
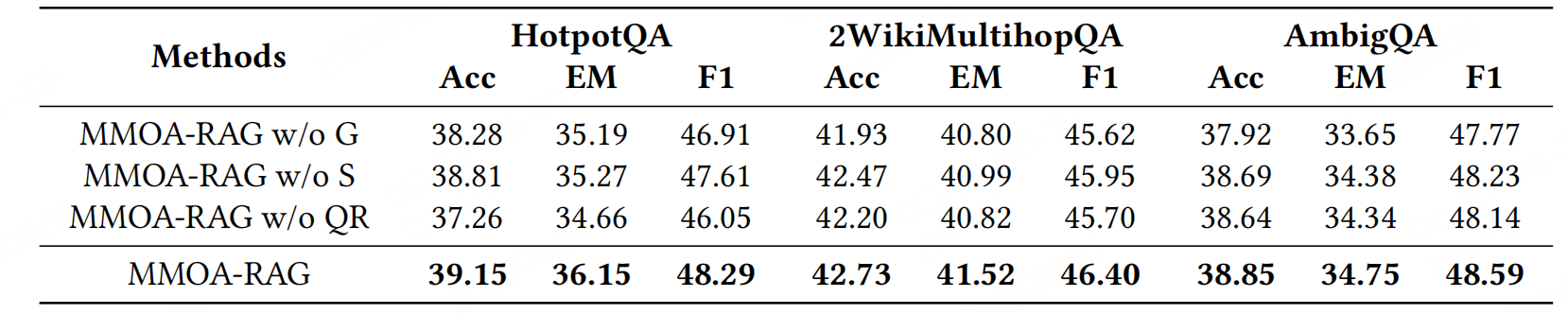
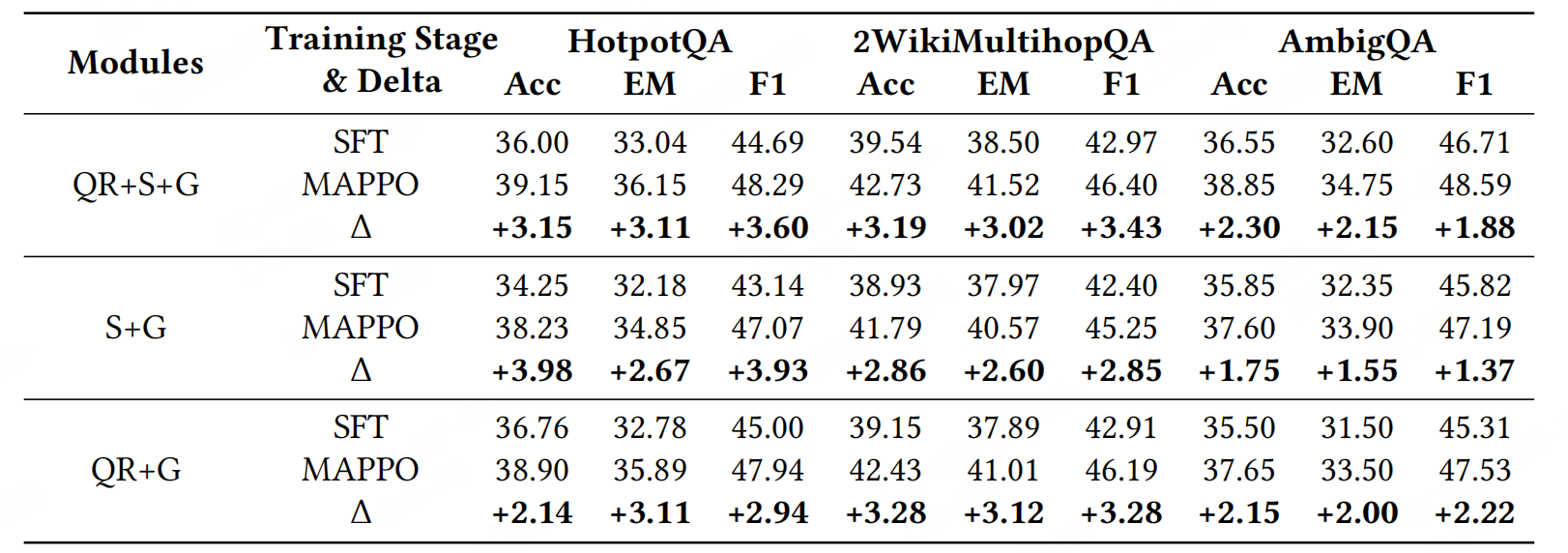
Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement Learning,https://arxiv.org/pdf/2501.15228v2
repo:https://github.com/chenyiqun/MMOA-RAG
更多推荐

 18
18 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)