
六步构建AI Agent : 用LangGraph高效实现从0到1,大模型入门到精通,收藏这篇就足够了!
本文将基于LangGraph框架,为应用开发者提供一套完整的Agent构建方法论,从概念验证到生产部署的全流程实战指南。
面向大模型技术爱好者的生产级Agent开发框架
前言
2025年是AI Agent真正进入生产环境的元年。不同于早期AutoGPT式的宽泛自主Agent,现在的生产级Agent更加垂直化、范围明确、高度可控,具备定制化的认知架构。LinkedIn、Uber、Replit和Elastic等公司都在生产环境中使用LangGraph构建实际业务场景。
本文将基于LangGraph框架,为应用开发者提供一套完整的Agent构建方法论,从概念验证到生产部署的全流程实战指南。
核心架构:状态图驱动的Agent设计
LangGraph采用有向图架构组织Agent行为,不同于传统线性流程,它支持条件决策、并行执行和持久化状态管理。这种设计为GPU密集型计算场景提供了更好的资源调度能力。
架构核心组件
1. 状态管理机制
from langgraph.graph import StateGraphfrom langgraph.checkpoint.memory import MemorySaver# 状态定义class AgentState(TypedDict): messages: Annotated[list, add_messages] context: dict task_status: str gpu_utilization: float
2. 节点执行模型
每个节点代表一个计算单元,可以是:
- • 推理节点:执行LLM推理任务
- • 工具节点:调用外部API或计算资源
- • 决策节点:基于条件分支控制流程
3. 边缘路由策略
def route_based_on_gpu_load(state: AgentState) -> str: if state["gpu_utilization"] > 0.8: return "cpu_fallback" else: return "gpu_acceleration"
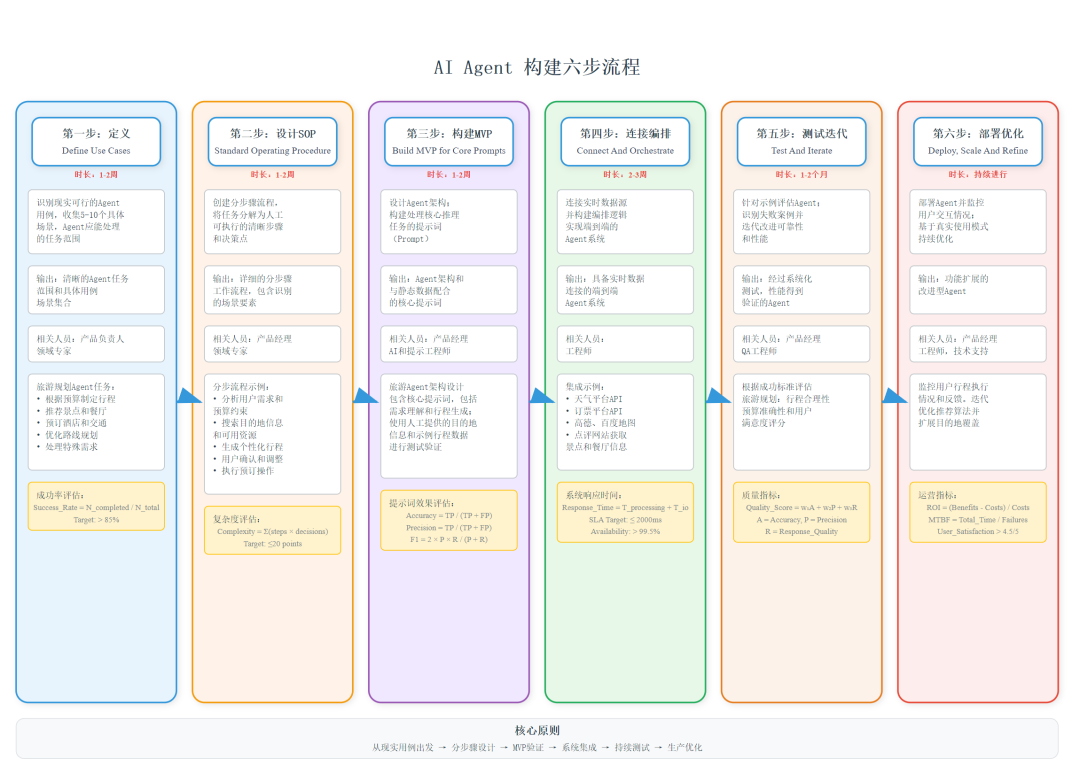
六步构建方法论
第一步:用例驱动的任务定义
核心原则:选择现实可行且需要Agent处理的任务
以旅游规划智能助手Agent为例:
# 具体任务实例TRAVEL_EXAMPLES = [ { "user_request": "计划3天北京游,预算5000元,喜欢历史文化", "expected_action": "generate_itinerary", "priority": "high", "gpu_context": True }, { "user_request": "推荐上海浦东机场附近的酒店,明晚入住", "expected_action": "hotel_recommendation", "priority": "urgent", "gpu_context": True }]
避免的陷阱:
- • 范围过于宽泛,无法提供具体示例
- • 简单逻辑用Agent过度工程化
- • 期望不存在的魔法功能
第二步:标准作业程序(SOP)设计
编写详细的人工执行流程,为Agent设计奠定基础。
## 旅游规划SOP1.**需求分析** (GPU加速语义理解) - 目的地偏好识别:使用GPU加速的嵌入模型 - 预算约束分析:提取具体数值和范围 - 兴趣爱好匹配:基于用户历史和偏好2.**资源搜索** (并行查询) - 景点信息检索:调用地图和点评API - 住宿选项筛选:基于位置、价格、评分 - 交通方案对比:多平台价格和时间对比3.**行程生成** (优化算法) - 路线规划:基于地理位置和交通便利性 - 时间分配:考虑景点游览时长和交通时间 - 预算分配:在不同类别间合理分配费用
第三步:MVP原型与提示工程
LangGraph的核心原则是尽可能底层化,没有隐藏的提示或强制的认知架构,这使其适合生产环境并区别于其他框架。
核心推理任务聚焦
TRAVEL_CLASSIFICATION_PROMPT = """你是专业的旅游规划助手。任务:分析用户旅游需求,输出结构化的规划方案。输入格式:- 用户需求:{travel_request}- 预算信息:{budget_info}- GPU计算资源:{gpu_context}输出格式(JSON):{ "destination": "目的地城市", "duration": "旅行天数", "budget_category": "经济|标准|豪华", "interests": ["历史文化", "自然风光", "美食"], "urgency": "高|中|低", "gpu_processing_time": "estimated_seconds"}分析规则:1. 复杂行程规划自动启用GPU加速2. 多目的地行程标记高优先级处理3. 包含"紧急"、"明天"等词汇提升处理优先级"""
性能验证机制
def test_travel_planning_accuracy(examples: list) -> float: correct = 0 for example in examples: result = plan_travel( example["request"], example["budget"], gpu_acceleration=True ) if result["destination"] == example["expected_destination"]: correct += 1 accuracy = correct / len(examples) print(f"规划准确率: {accuracy:.2%}") return accuracy
第四步:连接与编排
数据源集成:
- • 三方平台API:天气、机票、酒店等查询
- • 高德/百度地图API:路线规划和交通信息
- • 大众点评/美团API:景点和餐厅信息
编排逻辑实现
from langgraph.graph import StateGraph, ENDdefbuild_travel_agent(): workflow = StateGraph(AgentState) # 节点定义 workflow.add_node("request_analyzer", analyze_travel_request) workflow.add_node("destination_matcher", match_destinations) workflow.add_node("resource_searcher", search_travel_resources) workflow.add_node("itinerary_generator", generate_itinerary) workflow.add_node("budget_optimizer", optimize_budget) # 边缘路由 workflow.add_edge("request_analyzer", "destination_matcher") workflow.add_conditional_edges( "destination_matcher", route_by_complexity, { "simple": "resource_searcher", "complex": "budget_optimizer", "multi_city": "itinerary_generator" } ) # 编译图 return workflow.compile(checkpointer=MemorySaver())
GPU资源优化策略
def analyze_travel_request(state: AgentState): """使用GPU加速进行旅游需求分析""" # 检查GPU可用性 gpu_available = check_gpu_utilization() < 0.7 if gpu_available: # 使用GPU加速语义理解 user_intent = gpu_nlp_model.analyze( state["user_request"], device="cuda" ) processing_mode = "gpu_accelerated" else: # 降级到CPU处理 user_intent = cpu_nlp_model.analyze( state["user_request"] ) processing_mode = "cpu_fallback" return { "travel_intent": user_intent, "processing_mode": processing_mode, "gpu_utilization": get_current_gpu_util() }
第五步:测试与迭代
自动化测试框架
import pytestfrom langgraph.utils.testing import AgentTesterclassTravelAgentTest: def__init__(self): self.agent = build_travel_agent() self.tester = AgentTester(self.agent) deftest_gpu_resource_management(self): """测试GPU资源调度策略""" # 模拟高GPU负载场景 test_cases = [ {"gpu_load": 0.9, "expected_mode": "cpu_fallback"}, {"gpu_load": 0.3, "expected_mode": "gpu_accelerated"} ] forcasein test_cases: with mock_gpu_utilization(case["gpu_load"]): result = self.agent.invoke({ "user_request": "3天上海游,预算3000元" }) assert result["processing_mode"] == case["expected_mode"] deftest_planning_accuracy(self): """测试行程规划准确性""" results = [] for example in TRAVEL_EXAMPLES: output = self.agent.invoke({ "user_request": example["user_request"], "budget": example.get("budget", 5000) }) results.append({ "predicted": output["itinerary"]["destination"], "actual": example["expected_destination"], "correct": output["itinerary"]["destination"] == example["expected_destination"] }) accuracy = sum(r["correct"] for r in results) / len(results) assert accuracy >= 0.85 # 要求85%以上准确率
性能基准测试
def benchmark_travel_planning(): """对比GPU和CPU处理性能""" test_requests = generate_travel_requests(100) # GPU加速测试 gpu_start = time.time() gpu_results = process_with_gpu(test_requests) gpu_time = time.time() - gpu_start # CPU基线测试 cpu_start = time.time() cpu_results = process_with_cpu(test_requests) cpu_time = time.time() - cpu_start print(f"GPU处理时间: {gpu_time:.2f}s") print(f"CPU处理时间: {cpu_time:.2f}s") print(f"加速比: {cpu_time/gpu_time:.2f}x") return { "gpu_throughput": len(test_requests) / gpu_time, "cpu_throughput": len(test_requests) / cpu_time, "speedup_ratio": cpu_time / gpu_time }
第六步:部署、扩展与优化
LangGraph Platform现已正式发布,支持大规模Agent部署和管理。NVIDIA技术博客提到了从单用户扩展到1000个协作者的三步流程:性能分析、负载测试和监控部署。
生产部署架构
# 部署配置示例from langgraph_platform import deploydeployment_config = { "name": "travel-agent-gpu", "runtime": "gpu", # 指定GPU运行时 "scaling": { "min_replicas": 2, "max_replicas": 10, "gpu_per_replica": 1, "memory": "8Gi" }, "monitoring": { "metrics": ["gpu_utilization", "response_time", "user_satisfaction"], "alerts": { "gpu_utilization > 0.9": "scale_up", "user_satisfaction < 4.0": "quality_alert" } }}# 一键部署deploy.create(agent=travel_agent, config=deployment_config)
生产监控指标
class ProductionMetrics: def__init__(self): self.metrics = { "gpu_efficiency": GPUUtilizationTracker(), "model_performance": AccuracyTracker(), "system_latency": LatencyTracker(), "cost_optimization": CostTracker() } deflog_inference_metrics(self, request_id: str, result: dict): """记录推理性能指标""" self.metrics["gpu_efficiency"].record( gpu_time=result["gpu_time"], memory_used=result["gpu_memory"] ) self.metrics["model_performance"].record( confidence=result["confidence"], accuracy=result.get("accuracy", None) ) defgenerate_report(self) -> dict: """生成性能报告""" return { "avg_gpu_utilization": self.metrics["gpu_efficiency"].average(), "p95_latency": self.metrics["system_latency"].p95(), "daily_cost": self.metrics["cost_optimization"].daily_total(), "model_drift_score": self.metrics["model_performance"].drift_score() }
关键技术要点
1. GPU资源管理策略
class GPUResourceManager: def__init__(self, max_gpu_utilization=0.8): self.max_utilization = max_gpu_utilization self.current_jobs = {} defallocate_gpu_task(self, task_id: str, estimated_load: float): """智能GPU任务分配""" current_load = self.get_current_utilization() if current_load + estimated_load <= self.max_utilization: returnself.assign_gpu_slot(task_id, estimated_load) else: returnself.queue_for_cpu_processing(task_id) defget_current_utilization(self) -> float: """获取当前GPU使用率""" import nvidia_ml_py3 as nvml nvml.nvmlInit() handle = nvml.nvmlDeviceGetHandleByIndex(0) utilization = nvml.nvmlDeviceGetUtilizationRates(handle) return utilization.gpu / 100.0
2. 模型推理优化
def optimized_inference_pipeline(): """优化的推理管道""" # 批处理策略 batch_processor = BatchProcessor( max_batch_size=16, timeout_ms=100, gpu_memory_limit="6GB" ) # 模型量化 quantized_model = quantize_model( base_model, precision="fp16", # 半精度浮点 device="cuda" ) # 缓存策略 cache = InferenceCache( backend="redis", ttl_seconds=3600, max_entries=10000 ) return InferencePipeline( model=quantized_model, batch_processor=batch_processor, cache=cache )
3. 成本效益分析
def calculate_roi_metrics(): """计算GPU投资回报率""" # GPU加速收益 gpu_benefits = { "processing_speedup": 3.5, # 3.5倍加速 "throughput_increase": 280, # 每小时280个任务 vs 80个 "accuracy_improvement": 0.05# 5%准确率提升 } # 成本分析 costs = { "gpu_hourly_cost": 2.48, # A100每小时成本 "cpu_alternative_cost": 0.12, # CPU实例成本 "development_overhead": 0.15# 15%开发成本增加 } # ROI计算 daily_task_volume = 2000 value_per_task = 0.05# 每个任务创造价值 gpu_daily_value = daily_task_volume * value_per_task * (1 + gpu_benefits["accuracy_improvement"]) gpu_daily_cost = 24 * costs["gpu_hourly_cost"] roi = (gpu_daily_value - gpu_daily_cost) / gpu_daily_cost return { "daily_roi": roi, "breakeven_days": costs["development_overhead"] * gpu_daily_cost / (gpu_daily_value - gpu_daily_cost), "annual_savings": 365 * (gpu_daily_value - gpu_daily_cost) }
实践经验总结
成功要素
-
- 明确的任务边界:不要试图构建万能Agent
-
- 渐进式复杂度:从简单MVP开始,逐步增加功能
-
- GPU资源调度:智能的负载均衡和降级策略
-
- 持续监控优化:基于生产数据的性能调优
常见陷阱
-
- 过度工程化:简单任务不需要Agent
-
- 忽视成本控制:GPU资源昂贵,需要精细化管理
-
- 缺乏人工监督:Agent应该增强而非替代人工决策
-
- 测试不充分:生产环境的复杂性远超开发测试
结语
LangGraph为生产级Agent提供了控制性、持久性和可扩展性,其底层、可扩展的设计理念让开发者能够构建真正适合业务场景的AI解决方案。
对于应用开发者而言,合理利用LangGraph的图状态管理能力,结合GPU资源的智能调度,可以构建出既高效又经济的生产级Agent系统。
关键在于保持务实的态度:从明确的用例开始,通过迭代优化逐步完善,始终以解决实际问题为导向,而非追求技术的炫酷。这样构建的Agent才能真正创造业务价值,在生产环境中稳定运行。
本文基于LangChain官方指南和最新技术实践整理,适用于2025年的生产环境部署场景。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐
 12
12 0
0- 0



 已为社区贡献364条内容
已为社区贡献364条内容

所有评论(0)