
大语言模型实现机制浅析
大模型,大家都很熟悉了,工作和生活中都很常用,大模型表现出的强大的生成能力,让人惊叹,它是怎么做到这一点的呢?我对这一点很好奇,所以就深入了解了一下,搜到了一本讲:从零实现大模型的书<<从零构建大模型>>,现在市面上都有销售,大家可以买来看看。这本书是从解析文本,准备语料开始,然后按照transformer架构,从零开始实现了一个类GPT。
大模型,大家都很熟悉了,工作和生活中都很常用,大模型表现出的强大的生成能力,让人惊叹,它是怎么做到这一点的呢?我对这一点很好奇,所以就深入了解了一下,搜到了一本讲:从零实现大模型的书[[从零构建大模型]],现在市面上都有销售,大家可以买来看看。
[这本书是从解析文本,准备语料开始,然后按照transformer架构,从零开始实现了一个类GPT-2的大语言模型,之后对这个模型进行了训练,得到了一个具备基本生成能力的基础模型,然后又对这个基础模型进行了微调操作,实现了一个垃圾消息分类大模型,以及一个指令大模型。按照这本书的代码,一行一行的敲,可以完整复现作者实现的效果,非常推荐对大模型实现感兴趣的同学读一下。
这本书中介绍的大模型是基于pytorch构建出来的,涉及很多机器学习的知识,有一些学习门槛,所以写一篇文章整体梳理一下。书中的内容很多,没办法面面俱到的写,我这次梳理,主要是围绕类GPT大模型的架构来串一下内容,以下内容大部分都是来自于这本书,书中有一些比较难懂的内容,我又自己查了一些资料辅助自己理解。]
文章目录
文章目录
类GPT大模型架构图
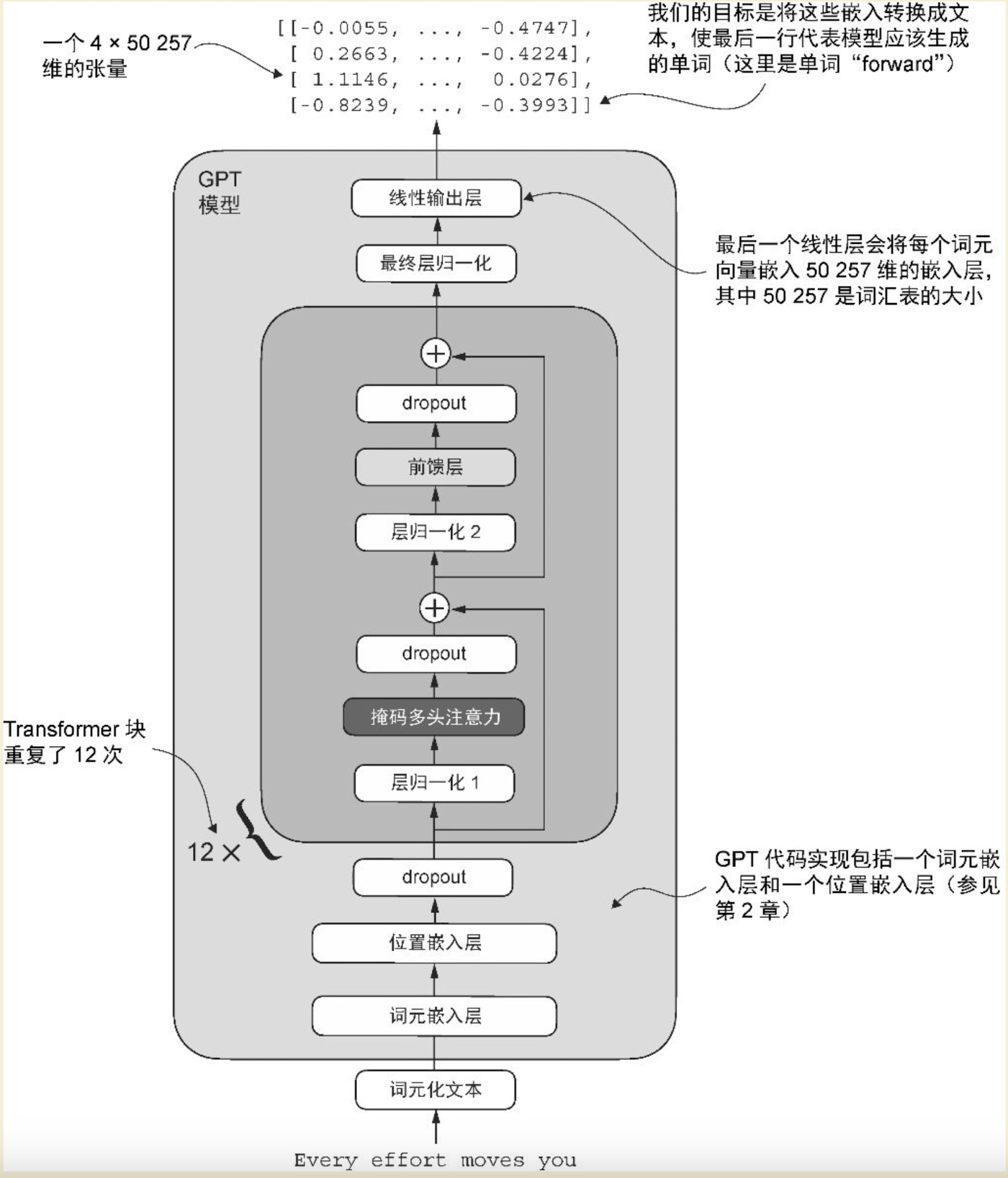
模型的运行过程,是从下往上的。我们一层一层的来说
1、用户输入
用户给模型输入一句话,Every effort moves you,让模型将这句话补充完整
2、词元化文本
就是将文本转换成词元的一个过程。一个句子,是由多个词元构成的,比如:小明想要去上学。分词后,可能会得到4个词元,小明、想要、去、上学,类似ES的分词,这一步很好理解。接下来,需要将每一个词转换成一个唯一的数字,对于模型来说,不管是英文还是中文,它都是不认识的,也不好处理。大模型内部涉及很多的矩阵运算,是大量的数字相乘,所以需要将词元转换成数字,怎么转换呢?模型内部有一个大词典,词典中的每一个词都对应一个唯一的数字,通过查这个词典,将4个词元转换成4个唯一的数字,比如:[2 , 3 , 5 , 1],这一步很关键,将一个抽象的文本转换成了计算机可以处理和索引的数字。书中要实现的类GPT模型,使用了GPT-2的词典,该词典包含50257个词汇。
3、词元嵌入层
如果只是将文本转换成一维的数字。能表达的东西就很有限。语言是很复杂的,比如:苹果,就可能是一种水果,也可能是一个公司,也可能是一部电影的名字,所以我们需要将一个词变成多维的形式以表达多种不同的语义,另外还有一点,将词元转成向量后,向量之间是可以计算距离的,进而可以计算两个词元的相似程度。
所以,嵌入操作,是非常重要的一个操作。回到我们的例子,假如我们将每一个词元都转换成3维的表示。
以上[2 , 3 , 5 , 1],转换成3维表示,就如下所示:
[
[1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[0.9178, 1.5810, 1.3010]
]
这是一个4 x 3的矩阵,每行中的3个数字代表一个词元
一共有4行,所以是4个词元。
GPT-2模型一共有4种类型。最小的GPT-2(small)有1.24亿个参数,词元的嵌入维度是768维。
4、位置嵌入
词元嵌入,我们已经理解了。那位置嵌入是什么意思呢?简单理解,就是让句子中的每一个词都知道自己的位置。这里分绝对位置和相对位置。
绝对位置嵌入就是每一个词元,都有一个独特的位置嵌入,以明确指示其在序列中的确切位置。
相对位置嵌入,关注的是词元之间的相对位置或距离。
为什么需要这个位置嵌入呢?
嵌入层的工作机制是:无论词元ID在输入序列中的位置如何,相同的词元ID始终被映射为相同的向量表示,虽然这种带有确定性且与位置无关的词元ID嵌入能够提升其可再现性。但是这样有一个很大的问题,就是模型无法识别词元的位置,词元的位置丢失是一个很大的问题,比如:我爱你和你爱我,词元都是一样的,但是句子含义是完全不一样的。
我们输入的时候,明明是有顺序的,为什么输入模型之后,顺序就没了呢?要解释这个问题,需要了解transformer架构自注意力机制。还是以:我爱你和你爱我这两个句子为例。
我爱你,一共3个词元,对于每一个词元来说,都需要计算和其他词元的匹配度,然后做加权平均。
相似度,不是说和这个词元语义是否相似,而是词元是否重要,如果重要,注意力分数就高,比如:我爱你中的"你"这个词元,模型会将"你"与"我"、"爱"这两个词元分别计算相似度,得到一组注意力分数,然后通过softmax函数将这一组注意力分数转换成一组权重值,权重值和等于1。然后将权重值和每个词元本身的向量相乘,最终就得到一个融合后的向量值。
这一套计算方式,压根就没有顺序的事,所以我爱你、你爱我,这两个句子,如果不特殊处理位置的话,在大模型看来,是一个意思,句子的顺序性就会丢失,顺序行丢失,模型就不知道主语、谓语、宾语,模型就无法很好的生成内容。所以每个词元的向量=input_embeding+pos_embeding,在词元嵌入的基础上加上了一个位置向量
5、dropout层
这一层的目的是,随机丢弃一些隐藏层单元,避免模型过于依赖某个权重,进而防止模型过拟合
6、transformer块
这一层就是大名鼎鼎的transformer了,但其实GPT系列大模型不是完整的transformer架构,完整的transformer其实包含两部分,如下图: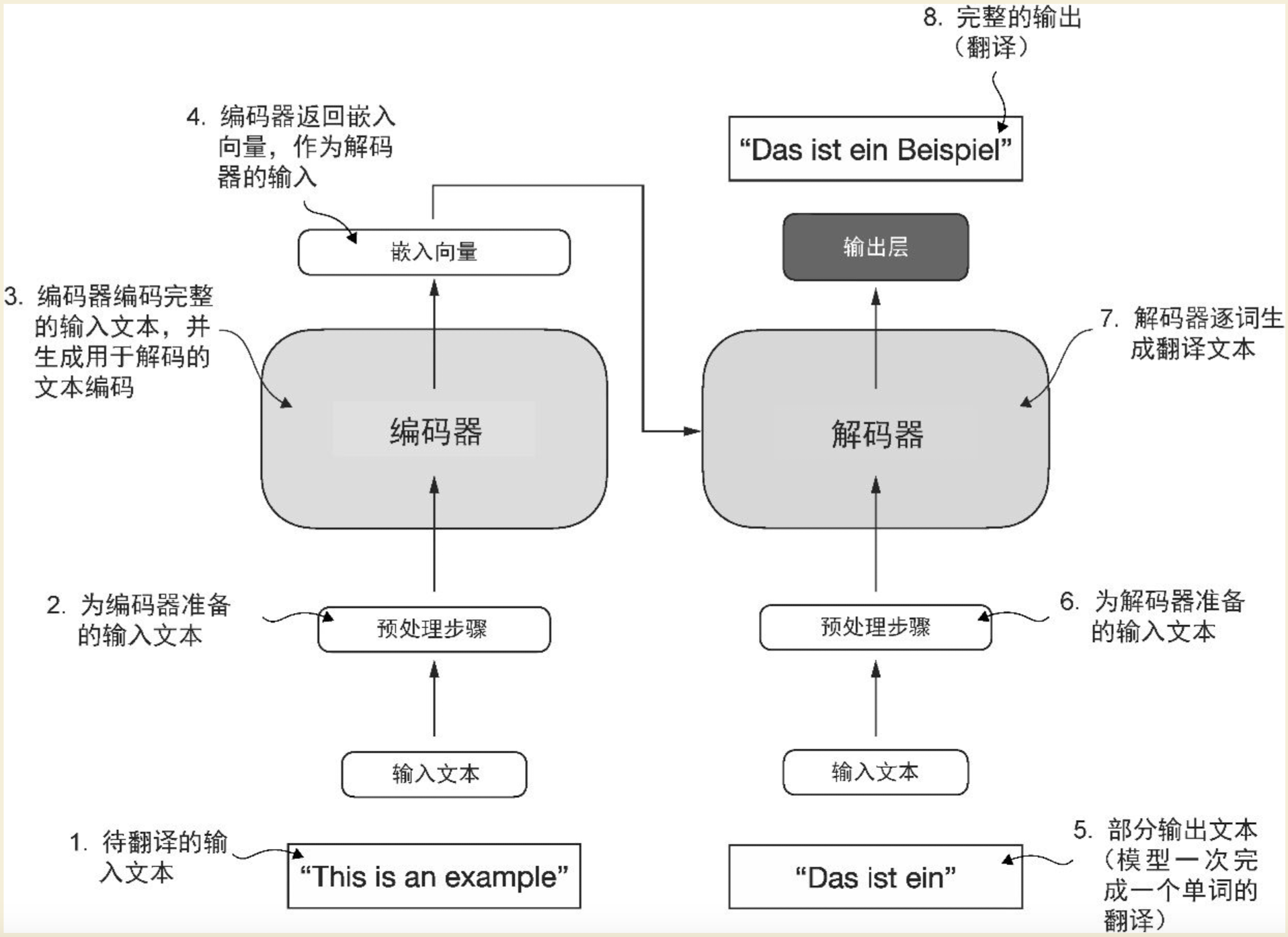
左边是一个编码器,负责将用户输入的文本转换成嵌入向量
右边是一个解码器,负责将嵌入向量转换成文本
从这张图,我们也能看出来,原始的transformer最开始是用于翻译场景的。GPT系列的模型,只用到了解码器,也就是主要用来进行内容生成。大家看一下这张图的解码器部分,最下面是"输入文本",既然编码器已经将文本编码成了嵌入向量给到了解码器,解码器根据向量翻译内容就可以了,为什么解码器还需要输入文本呢?这里涉及到一个"自回归"的概念,这里的文本不是用户输入的,是解码器生成的,解码器一次翻译一个词,然后将这个新生成的词追加到用户输入的文本最后面,然后将新文本输入给解码器,产生下一个词,就这样循环往复,最终将用户输入的文本翻译成了另外一个句子。
下面我们深入到transformer块内部看一下transformer块内部都有哪些结构
6.1、层归一化
归一化是什么?
想象一下,一场考试后,你有两个学生的分数“
学生A:语文95分,数学60分
学生B:语文75分,数学80分
谁的综合能力更强呢?很难直接比较吧,因为科目的"尺度"不同。归一化就像把所有科目的分数都转换到一个统一的、可比较的标准上,处理之后,就能公平的比较学生的综合能力了。在神经网络中,归一化就是对每一层的向量数据做类似的事情:调整数据的分布,使其均值稳定在0附近,方差稳定在1附近。
层归一化的主要作用是提高神经网络训练的稳定性和效率。在我们的GPT架构中,transformer块一共被重复了12次,在这样深的网络中,数据在经过一层又一层的复杂计算后,会发生两个严重问题:
1)、内部协变量偏移:每一层的输入数据的分布都在不断变化,就像考试标准一直在变一样。这导致每一层都需要不断去适应新的输入分布,使得训练非常困难且缓慢。
2)、梯度消失/爆炸:模型学习的主要依据就是梯度,这个东西非常重要。数据在传递过程中,其数值可能会变得过大或过小。这会导致在反向传播时,梯度要么变得极大,要么变得极小,导致模型无法有效学习。
层归一化的作用就是解决这些问题,具体来说:
1)、稳定训练过程:通过将数据拉回到一个稳定的范围(均值为0,方差为1),它为下一层提供了一个非常"干净"和"标准"的输入。这使得整个模型的训练更加稳定和高效。
2)、防止梯度消失/爆炸:它控制了进入下一层的数据规模,从而缓解了梯度消失和爆炸
6.2、掩码多头注意力
注意力是transformer的核心概念,提出tranformer架构的论文名称是:Attention is all you need,可见注意力机制在transformer架构中是一个很重要的概念。
注意力机制,简单理解就是一句话中的每一个词,都可以注意到其他词,从而每个词都能了解整句话的语义。注意力是可以被精确计算出来的。具体计算的过程如下:
想象一下,我们有一句话"The cat didn’t cross the road because it was too tired",当我们读到"it"这个词时,我们的大脑会立刻判断,“it"指的是"cat"还是"road”?
注意力机制做的就是同样的事情,但它通过数学计算来完成:
1)、查询向量、键向量、值向量
对于句子中的每一个词,模型都会为它生成三个向量,一般称为Q、K、V向量。
Q:查询向量
K:键向量
V:值向量
查询向量:可以理解为这个词主动发出的"问题"。例如,“it"的查询向量就像在发问:“在这句话里,谁才是我真正指代的对象?”
键向量:可以理解为每个词身上挂着的"标签"或"索引”。例如,“cat"的键向量标签是”[名词,动物]“,“road"的K向量标签是”;'[名词,路径]”。
值向量:可以理解为这个词"真正的含义"。如果"it"最终决定关注"cat",那么它就会从"cat"的值向量中获取具体的语义信息。
现在,“it"用它的查询向量,去和句子中所有词(包括它自己)的键向量进行匹配,计算一个"相关性分数”。
Score(Q_it, K_the) = 很低
Score(Q_it, K_cat) = 很高
Score(Q_it, K_cross) = 很低
Score(Q_it, K_road) = 比较低
...
这个分数量化了"it"应该对每个词投入多少"注意力"。
然后,模型会将这些注意力分数转换成权重(总和为1),然后对每个词的值进行加权求和。
新的"it" = (权重_cat * V_cat) + (权重_road * V_road) + (权重_tired * V_tired) + ...
因为"cat"的权重最高,所以新的"it"的向量就会融合很多"cat"的语义,用向量空间表示的话,it和cat的向量离的会很近。
最终,经过这个过程后,“it"就不再是一个模糊的代词,它的向量表示已经被"重写”,明确指向了"the cat",当模型继续生成词时,它就知道it的具体含义是什么了。
这就是注意力机制在大模型中起到的作用。
6.3、dropout
这个前面介绍了,不再赘述
6.4、前馈层
前馈模块是一个小型神经网络,由两个线性层和一个GELU激活函数组成,结构如下: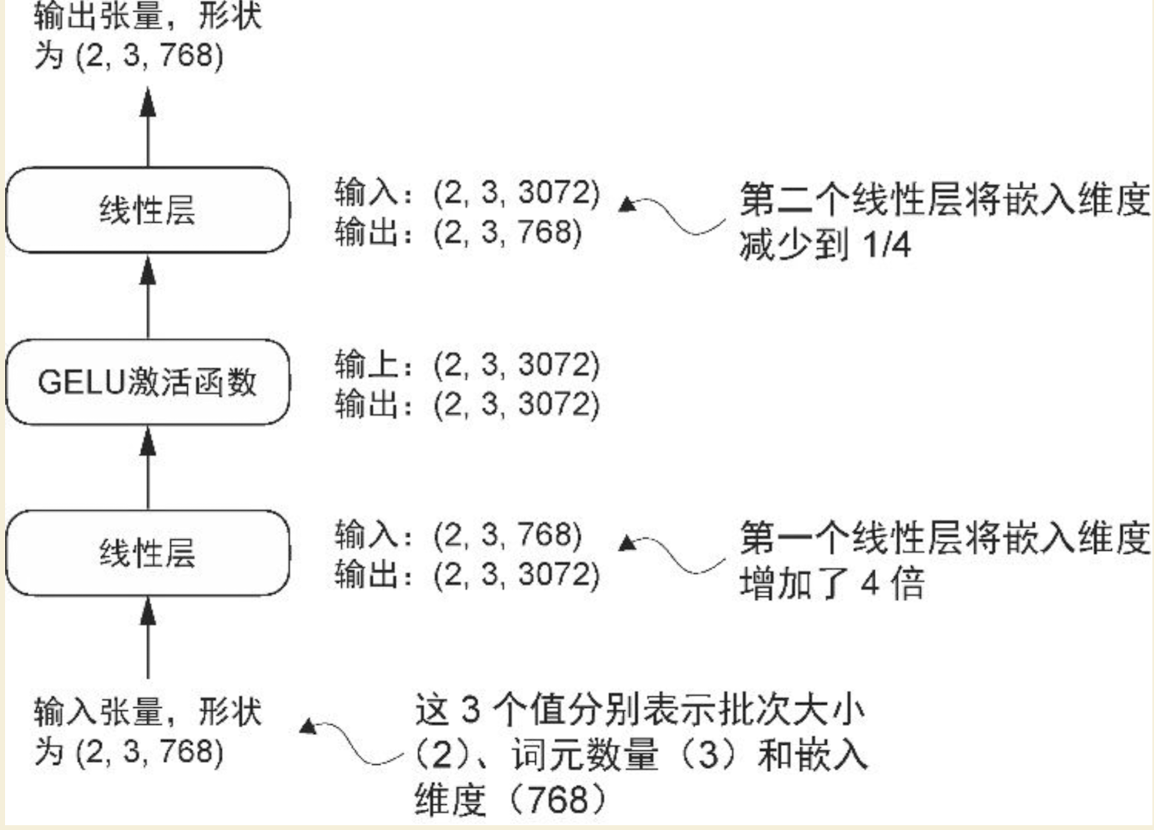
线性层:这一层可以简单理解为一个函数,y = ax + b,接收一个x,然后通过与系数a相乘,再加上常量b,从而得到一个新的y值。其中系数a在模型里一般称为"权重’,而b一般称为"偏置",线性层最核心的作用是:将数据从一个特征空间投影到另一个特征空间。
看上图,最开始的输入张量,是[2 , 3 , 768],是768维的,然后通过第一个线性层,将嵌入维度增加了4倍,成了3072维,这是一个扩展的步骤。它将每个词元的768维向量,通过一个线性变化(矩阵乘法),映射到一个更高维的3072维空间。这样做,可以让模型有更多的"空间"或"自由度"来学习和表示更复杂、更抽象的特征和关系,这是一种增加模型容量和能力的方式。
然后是一个GELU激活函数。
激活函数的主要作用是引入非线性。还是回到刚才的函数,y = ax + b,这就是一条直线,无论怎么折腾,表达能力都很有限,人类的语言转换成向量是非常复杂的,体现在坐标系上是一堆散落的点,只通过一条直线是无法表达这种散落的点的,激活函数的作用就是负责"引入扭曲和弯曲",可以简单理解为,从直线变成了抛物线,来尽可能描述这种散落的点。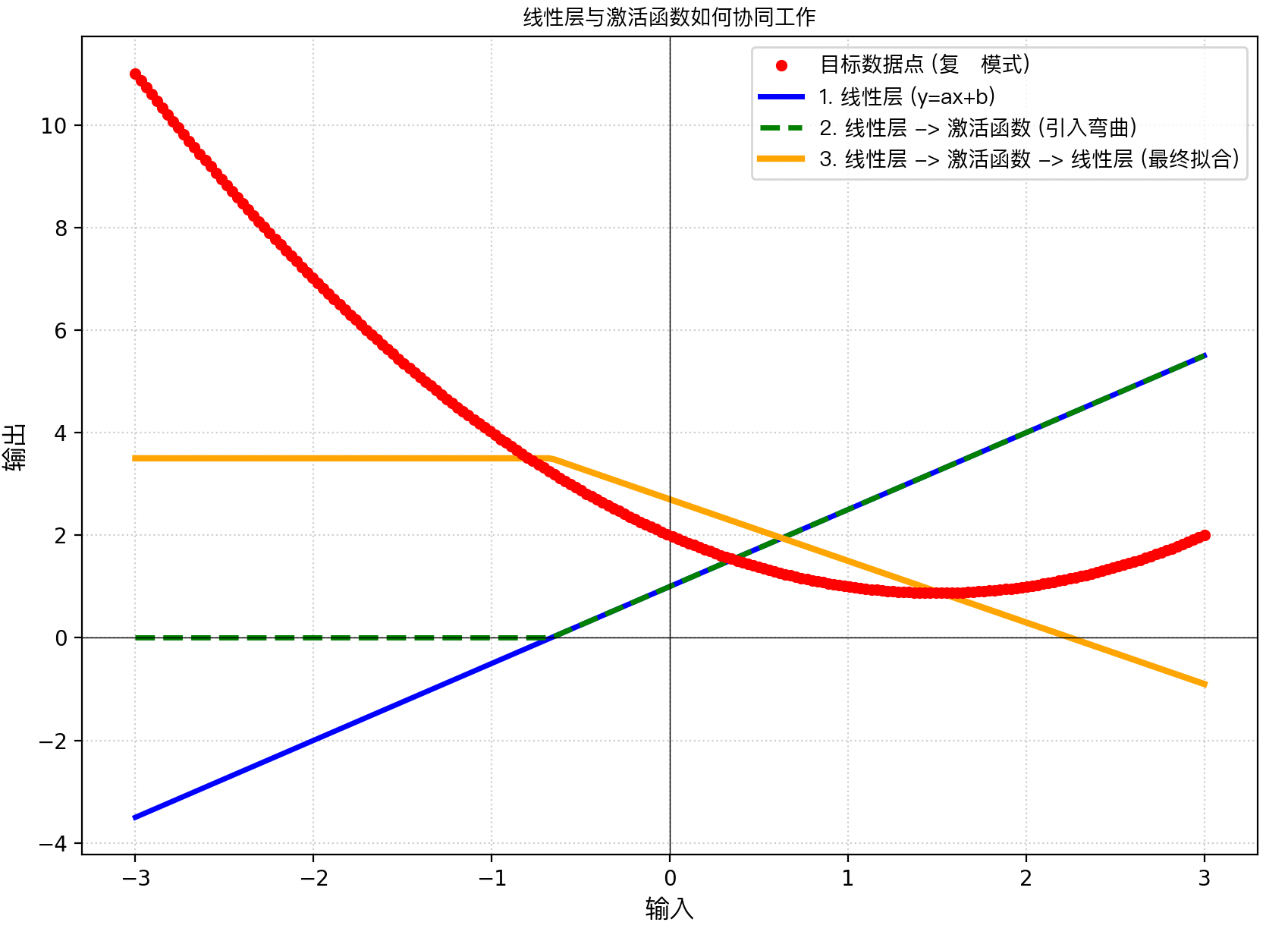
用matplotlib画一个图简单演示下,红色的线,是一个一个的点组成的,我们需要能用函数表达这些点。最开始的蓝色直线就是线性层y = ax + b,这条直线咋鼓捣,也不可能表示红色的点,因为红色线是弯曲的。经过GELU激活函数的激活作用,先将直线拉完,看绿色虚线,然后再引入弯曲,最终表达了红色的线,这就是GELU的主要作用,说的比较粗糙,但大致就是这个意思。
最后一个线性层,又将张量从3072维拉回到768维,这是一个压缩的过程。在高维度的空间中学习和提取了有用的特征后,需要将这些信息"浓缩"回原始维度,以便传递给下一层或最终输出,这个过程可以看做是对信息的筛选和整合。模型在高维度学习了很多东西,但是有些东西,我们是不需要的,所以需要一个压缩的过程,丢弃不重要的信息,保留精华。
7、最终层归一化
和transformer架构图里的层归一化作用差不多,就是为了稳定训练过程和提高效率,加速权重的有效收敛,并确保训练过程的一致性和可靠性。
8、线性输出层
最后一层是一个线性输出层,这一层会输出模型生成的下一个词。
假如我们输入的文本是Every effort moves you,然后让模型输出下一个词。此时我们最关注的其实是最后一个词元you,因为注意力机制的原因,you不是孤立的一个词元,
它融合了前面的Every effort moves这三个词元的语义,我们将you从768维映射到50257维,形成一个50257维的概率分布,然后通过softmax函数进行归一化操作,这50257个词元的每个词元都会得到一个概率值,这些概率值相加等于1,然后通过argmax函数,贪心解码只得到一个概率最高的词元或者top-k、温度缩放得到一组概率高的词元,之后从中随机选择一个词元作为输出(可以增加模型输出的多样性),然后模型会将这个新生成的词元追加到输入文本上,再次将文本输入模型,生成下一个词,然后再将生成的词追加到输入文本上,如此往复,最终得到结果。
这里需要注意一下:softmax、argmax函数处理的不是我们输入的汉字,我是为了表达方便,说成了汉字,函数不认识汉字,这里的运算都是数字。最终会将函数运算的数字结果再映射回汉字
9、模型微调
9.1、分类微调
我们上面介绍的第1节到第8节,都是在介绍基础模型的相关知识,基础模型也叫做通用模型,像我们现在常用的GPT系列、智谱系列、千问系列、kimi等等都是通用大模型,他们擅长文本内容的生成,但是不擅长特定任务的处理。举个例子,垃圾邮件的识别。给模型一封邮件内容,让模型识别这封邮件是垃圾邮件还是非垃圾邮件,这种任务不同于文本内容生成,文本内容生成是根据用户输入的一段内容继续生成内容,而分类任务的输出只有2种:垃圾邮件,非垃圾邮件。通用模型也能做这种识别,但是识别成功率很低,所以需要进行微调。微调的过程,就是改造通用模型的输出层,通用模型的输出层,会将输入向量从768维映射到50257维,然后通过概率计算得到下一个词,而我们的分类任务,输出只有2种,所以,只需要将768维的向量映射到2维即可。如下图: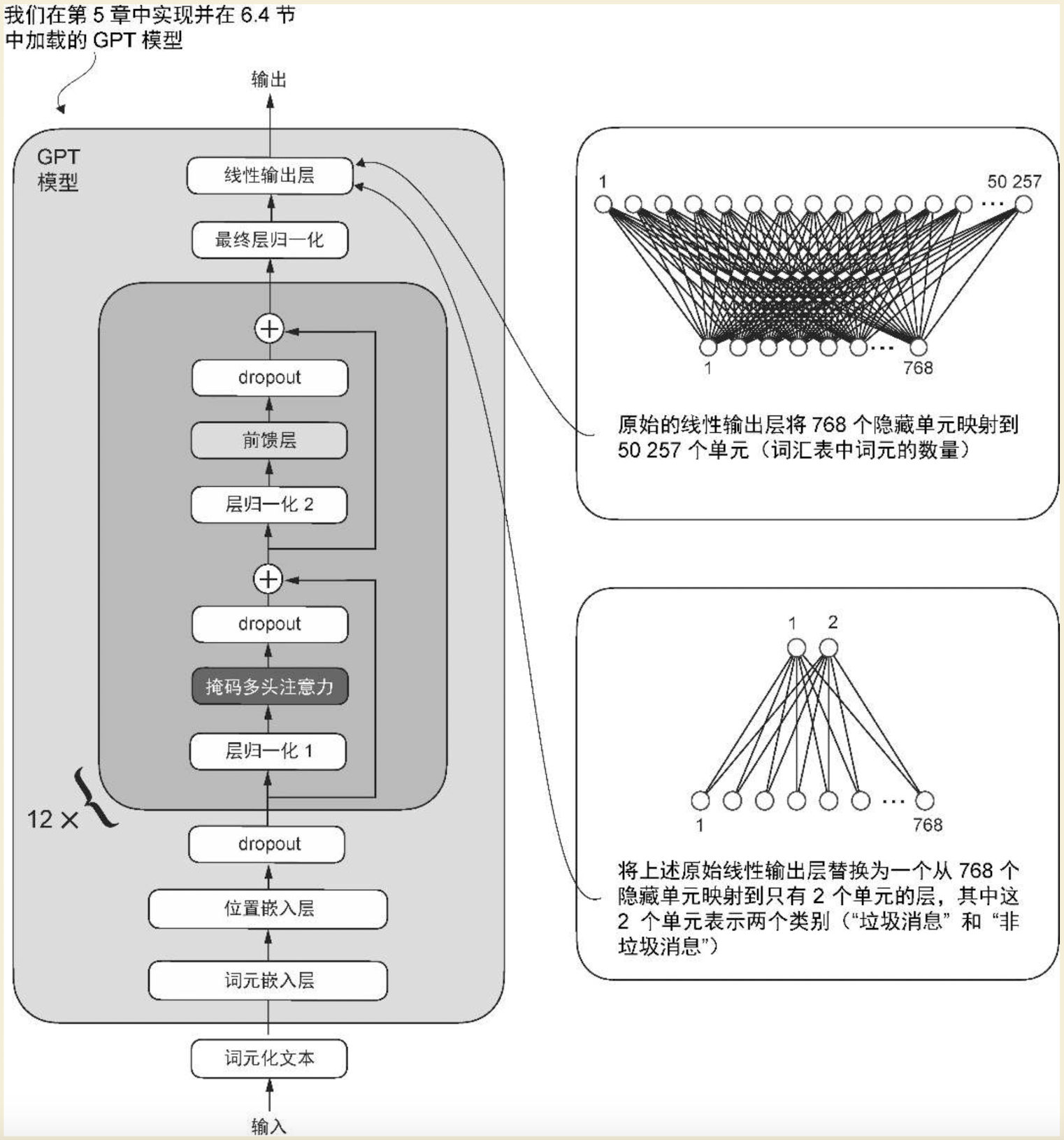
然后针对这个输出层,使用标记的数据进行训练即可。
在训练过程中,我们需要关注训练过程是否有效收敛,以及损失率是否在期望范围内。损失率的计算,pytorch也有专门的函数,cross_entropy函数。
9.2、指令微调
指令,只说这个词可能不知道是啥,但其实我们和大模型交互最多的就是给模型下指令,比如我们给模型下达一个指令:The chef cooks the meal every day,把这句话改成被动句。这就是在给模型下一个指令。
指令微调过程也要依赖基础模型,但是不同于分类模型需要改造输出层,指令微调的模型部分的代码和基础模型基本差不多。唯一有区别的是训练数据。
指令微调使用的数据集,一般有两种形式,Alpaca和Phi-3。前者的使用范围相对来说要更广一点,我们现在给模型预定义角色时,一般使用的就是左侧这种Alpaca类型。
指令微调这部分,另外需要再说一点的是训练结果的评估,指令微调不像分类微调,分类任务的结果就两种:是或者不是,这个很好评估。指令微调的输出是一句话,如果数据量少,人工评估就可以了,但是预训练的数据量都很大,此时就没办法人工评估。此时就可以使用模型来评估结果,比如我们可以使用参数量为80亿的指令微调模型Llama3来评估我们写的这个模型的生成效果,让评估模型来给生成结果打分,这样就可以将评估结果量化,我们就容易统计损失。
10、微调技术
10.1、LoRA微调
LoRA的全称是:低秩自适应。LoRA是一种通过仅调整模型权重参数的一小部分,使预训练模型更好地适应特定且通常较小的数据集的技术。"低秩"指的是将模型调整限制在总权重参数空间的较小维度子空间,从而有效捕获训练过程中对权重参数变化影响最大的方向。LoRA方法之所以有用且广受欢迎,是因为它能够高效地对大模型进行特定任务的微调,显著降低了通常所需的计算成本和资源。
11、参考资料
1、图书:<从零构建大模型>
2、视频资料:闪客丶<怎么理解AI>
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)