
AI 原生应用框架:智能体、通信协议、消息驱动与协同开发体系解析
摘要:本文探讨了生成式AI技术驱动下AI原生应用框架的构建。首先分析了从单智能体到多智能体系统的开发范式演进,指出分布式架构的必要性,并介绍了A2A协议实现异构智能体通信。其次阐述了基于Nacos的智能体注册中心管理和RocketMQ轻量化消息模型提升通信效率。最后提出基于统一元数据的AI协同开发模式,通过标准化交付物实现从需求到代码的高效流转。文章系统性呈现了涵盖"执行单元-通信机制-
引言
随着生成式 AI 技术的爆发式发展,应用开发范式正从 “代码驱动” 向 “智能驱动” 加速演进 —— 传统软件依赖固定逻辑实现功能,而 AI 原生应用则需依托大模型的理解与决策能力,应对动态任务拆解、多工具协同、跨场景交互等复杂需求。这种变革不仅重构了应用的核心能力,更对底层架构提出了全新挑战:如何让具备自主决策能力的智能体高效协作?如何解决异构系统间的通信壁垒?如何在高算力成本与复杂会话场景下保障系统稳定?又如何打通多角色开发流程,实现效率最大化?
这些问题的答案,共同指向了 AI 原生应用框架的构建。本文围绕 AI 原生应用的核心支柱展开,从 “智能体” 这一核心执行单元切入,系统梳理单智能体、工作流、多智能体系统三大开发范式的特点与适用场景;进而深入分布式架构下的通信基石,解析 A2A 协议如何实现异构智能体的标准化交互,以及 Nacos 注册中心如何支撑智能体的动态发现与管理;同时,针对 AI 应用长会话、大消息、高算力依赖的特性,阐述 RocketMQ 轻量化消息模型在通信效率提升与资源智能调度中的关键作用;最后,拓展至开发协同层面,探讨基于统一元数据的 AI 协同模式如何打破传统开发流程中的交付物壁垒,实现从需求到代码的高效流转。
通过对这些核心组件与技术体系的拆解,本文旨在呈现一套覆盖 “执行单元 - 通信机制 - 资源调度 - 开发协同” 的完整 AI 原生应用框架,为开发者应对 AI 时代的架构设计挑战提供理论参考与实践方向。
什么是智能体
我们可以将智能体(Agent)理解为一个具备自主理解、规划、记忆和工具使用能力的数字化实体。想象一个高度智能的个人助理,你只需告诉他 “帮我规划一次去北京的周末旅行”,他就能自主完成以下任务:
- 感知(Perception):理解用户的自然语言指令。
- 规划与推理(Planning & Reasoning):借助模型推理能力,将任务拆解为查询往返机票、筛选酒店、规划景点路线、预估预算等子任务。
- 记忆(Memory):记住你之前的偏好,比如喜欢靠窗的座位、偏爱的经济型酒店。
- 工具(Tool):调用外部工具,如机票预订 API、酒店查询系统、地图服务等,来执行这些子任务。
- 反馈与迭代(Feedback & Iteration):将规划好的行程草案反馈给你,并根据你的修改意见进行调整,最终完成预订。
智能体让 AI 从一个只会内容生成的语言模型,进化成一个具备自主规划能力的行动者。
智能体的主流开发范式
随着智能体技术的不断成熟,业界出现了多种有效的智能体开发范式。根据解决问题的场景与复杂度,我们可以将主流的智能体应用开发范式大致分为 4 种:简单 LLM 应用、单智能体(Single Agent)、工作流(Workflow)以及多智能体系统(Multi-Agent)。
- 简单 LLM 应用:我们将直接调用模型 API 实现内容生成的应用归类为简单 LLM 应用,它们完全依赖模型服务实现内容生成。大家应该还记得,在大模型刚刚面世之时,各类 Generative AI 概念的 Chat 应用大部分都是这类应用。
- 单智能体:相比于直接调用模型 API 的应用,单智能体应用是一种 Augmented LLM 应用,它的核心理念是为普通 LLM 应用增加 RAG、Tool、Memory 等,让模型具备与特定环境交互的能力。
- 工作流:对于一些复杂的业务应用,使用单智能体的架构效果欠佳。为此,我们可以将应用拆分开来,形成多个独立子智能体(每个子智能体是一个 Single Agent)的架构,再将这些独立的子智能体按照预定义的流程编排起来,这就是 Workflow 范式的基本定义。
- 多智能体系统:和 Workflow 非常类似,都是遵循将复杂智能体应用拆分成多个独立子智能体的理念,但相比于 Workflow 的确定性流程,Multi-Agent 采用的是模型驱动的、对话式的流程编排,各个子智能体在协作上具备更多的自主决策权(通常通过模型决策)。
接下来,我们将主要围绕单智能体、工作流、多智能体系统这三种核心 Agent 开发范式展开,分别讲解它们的核心设计理念,为我们后续智能体开发实践提供理论基础。
单智能体
前面我们提到了 Augmented LLM Application 的概念,这是为了弥补大模型预训练特性在应用开发上的局限性:
- 无法获取最新的数据、私有领域数据。
- 无法对本地工具发起调用。
- 无状态,因此无法形成有效的历史记录。
典型的单智能体架构如下
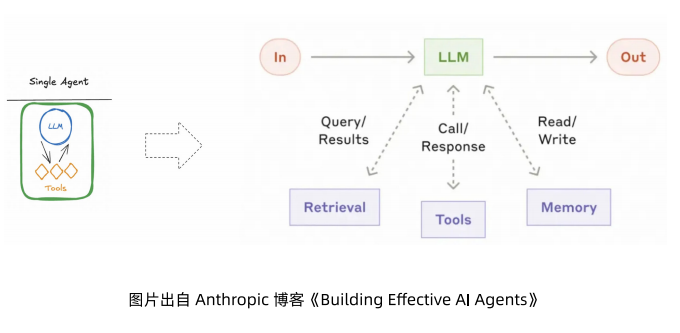
。我们将这种架构称之为最简单的智能体应用,同时也是最高级的智能体应用。
说它简单,是因为我们不用做过多的智能体拆分编排等工作,开发者只需要把工具等上下文都给到模型,一切都由模型驱动。说它高级,是因为整个应用由模型作为大脑来驱动和决策,不论任何问题,我们预期模型都能够正确的推理、选择合适的工具、检索到正确的上下文,最终生成符合预期的答案。
单智能体架构的高级性非常依赖底层模型能力,然而,在当前的实践中,我们发现当前的模型能力是受限的(不够聪明、上下文窗口等),单智能体模式面临很多的挑战。为此,业内才设计出工作流、多智能体系统等模式,在工程上做更多事情,来弥补模型能力的不足。
以下是单智能体架构下的一些典型问题:
- 如果一个 Agent 包含有太多的可用 Tools,模型会在决策工具选择时无所适从,效果变差。
- 多轮执行下来,消息上下文会变得很大,消耗大量的 Token 且影响模型当前专注度。
- 很多复杂的任务需要很多个步骤,通常在某些环节还需要专业领域技能支持,比如科学计算、深入研究、写代码、绘画、任务规划等。
- 单 Agent 在复杂任务场景下的可维护性会变差。
工作流
工作流是一种编排模式,需要开发者将一个复杂任务拆解为一系列有序步骤,这些步骤之间的调用关系和条件分支在设计阶段就明确好。例如,接下来要说到的链式工作流(Chain)和路由工作流(Routing),它们都强调通过规则、逻辑或预设分支,把任务从输入到输出,组织成可控的流程。
工作流的特点是确定性强、可调试性高、可控性好。你可以很清楚地看到 “先生成大纲→检查→写文章”,或者 “先判断输入类别→路由到对应模块”,因此非常适合流程清晰、可拆解的任务,以及对稳定性要求高的场景。简单来说,工作流像是固定的流水线,强调任务执行的透明度和安全性。
1、Chain - 链式工作流
链式工作流是一种将复杂任务分解为一系列较小、清晰的子任务的方式。每一步由一个独立的 LLM 调用完成,并将上一阶段的输出作为下一阶段的输入。典型应用包括先生成营销文案,再翻译成另一种语言,或先写文章大纲、检查大纲是否满足要求,再基于大纲完整撰写文章。
2、Routing - 路由工作流
路由工作流通过对输入进行分类,将它们分派到专门设计的下游任务或处理路径(通常也叫做意图识别),以实现关注点分离与更精准的响应。例如,在客服系统中,可以将普通咨询、退款请求、技术支持等不同类型的用户问题路由到不同的处理流程与工具;或者在成本和速度优化中,根据问题复杂度,将简单请求分发给小模型,而复杂或罕见问题则交给更强大的模型处理。
多智能体系统
多智能体系统更偏向一种自治协作模式。在这种模式下,系统由多个具备一定自治能力的 Agent 组成,每个 Agent 有自己的角色、能力或工具使用范围。它们之间可以通过消息或上下文进行交互,协同完成复杂目标。
这种方式更接近团队合作,而不是预先定义好的流程。优点是灵活性和适应性强,尤其在任务边界不清晰、需要动态规划时表现突出,比如研究型问答、复杂数据分析或跨领域问题求解。但多智能体系统的挑战在于难以预测和调试,因为不同 Agent 的交互和决策路径可能高度动态,不像工作流那样可控。
从单进程到分布式部署
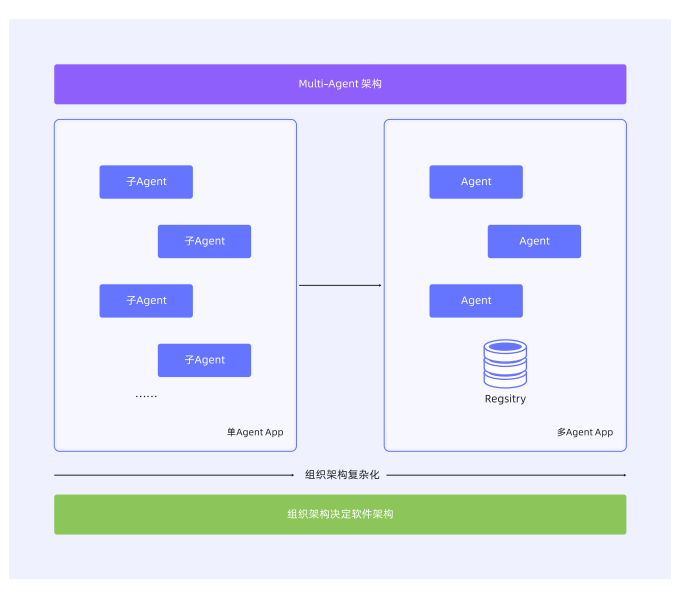
在开始讲解具体技术方案之前,我们先了解下为什么需要从单个智能体应用走向分布式?如果我们回顾微服务时代,几乎所有的企业都经历了从单体架构到微服务架构的技术演进,这其中有企业组织架构、文化方面的非技术因素,也有可扩展性、维护复杂度、性能等技术因素。因此,我们相信随着智能体在企业内的广泛应用,智能体也会走向分布式,接下来让我们一起来详细探讨分布式智能体的开发与部署方案。
在单个的智能体应用内,随着拆分的 Multi-Agent 增加、子智能体(Sub-Agent)的更新,发布会伴随组织架构的膨胀,沟通成本的上升导致 AI 应用的迭代效率及稳定性降低。从而引发 Multi-Agent 的架构体系向微服务架构学习和转变:通过将 Sub-Agent 进行独立部署和维护,同时多个 Sub-Agent 间通过远程调用代替内存调用的方式,实现各个 Sub-Agent 独立迭代和维护,避免不同的 Sub-Agent 节奏不同导致的效率和稳定性降低问题。
洞察到这个趋势之后,Google 迅速跟进,在开源社区中推出分布式智能体之间的通信协议 ——Agent2Agent 协议(以下简称为 A2A 协议)。本文将对 A2A 协议的定义和运行原理做简要介绍。
什么是 A2A 协议
A2A 协议是一项开放标准,旨在解决人工智能快速发展中面临的核心挑战:如何让由不同团队开发、采用不同技术构建、归属于不同组织的 AI 智能体实现高效通信与协作?
随着 AI 智能体日益专业化且能力增强,它们需要协同完成复杂任务的需求也愈加迫切。若缺少统一通信协议,将这些异构智能体整合为统一的用户体验将面临巨大的工程难题。每项集成都可能成为定制化的点对点解决方案,导致系统难以扩展、维护和迭代。
1、A2A 协议中的角色
A2A 协议中主要包含以下关键角色,每个角色分别承载协议中的不同作用:
- 用户(User):发起请求或目标的最终使用者(人类或自动化服务),需借助智能体协助完成任务。
- A2A 客户端(Client Agent):代表用户向远端智能体发起操作或信息请求的应用、服务或其他 AI 智能体。客户端通过 A2A 协议发起通信,不依赖具体远端智能体的实现细节。
- A2A 服务端(Remote Agent):实现了 A2A 协议 HTTP 端点的 AI 智能体或智能系统,负责接收请求、处理任务并返回结果或状态。从客户端视角看,远端代理以 “黑盒” 形式运行 —— 客户端无需感知其内部逻辑、记忆或工具集。
2、A2A 协议中的元素
A2A 协议中主要包含以下几种元素,这几种元素内容在单次的 A2A 工作流程中将会一次或多次出现:
AgentCard(智能体卡片)
- 一个 JSON 格式的元数据文档,通常位于固定 URL(如/.well-known/agent-card.json),用于描述 A2A 服务端的能力。
- 包含智能体身份(名称、描述)、服务端点 URL、版本号、支持的 A2A 功能(如流式传输或推送通知)、提供的技能列表、默认输入 / 输出模式及鉴权要求。
- 客户端通过解析该文档发现智能体,并获取安全交互的规范。
Task(任务)
- 当客户端向智能体发送请求时,若需通过状态化流程完成任务(如生成报告、预订航班),智能体会创建唯一任务 ID 并维护其生命周期(提交、处理中、需输入、完成、失败)。
- 任务支持多次客户端与服务端的交互,涵盖复杂场景的多轮通信。
Message(消息)
- 客户端与服务端单次通信的基本单元,包含以下属性:
-
- 角色:user(客户端发送)或 agent(服务端发送)。
- 消息 ID:由发送方生成的唯一标识。
- 内容块(Part):承载实际数据的结构化内容(如指令、问题、状态更新)。
- 主要用于非任务产出的普通通信场景,即同步请求的单次调用回复。
Artifact(产出物)
- 任务完成后返回的实体化结果(如文档、图片、结构化数据),由多个内容块(Part)构成,支持流式增量传输。
- 建议任务完成时通过该对象返回最终输出。
Part(内容块)
- Message(消息)或 Artifact(产出物)中的最小内容单元,支持多类型数据:
-
- 文本块(TextPart):纯文本内容。
- 文件块(FilePart):文件数据(通过 Base64 内联或 URI 引用传输),含文件名、媒体类型等元数据。
- 数据块(DataPart):结构化 JSON 数据(如表单参数、机器可读取信息)。
3、A2A 协议中的交互机制
A2A 协议中主要会用到 3 类交互机制,分别为轮询(Polling)、流式传输(Streaming)和推送通知(Push Notifications)。
轮询(Polling)
- 轮询通过传统的请求 / 响应方式实现。
- 客户端发起请求(如调用message/send RPC 方法),服务端返回即时响应。
- 长任务场景:若需状态化长时运行任务,服务端可能返回 “处理中” 状态,客户端需周期性调用tasks/get轮询获取状态更新,直至任务完成或失败。
流式传输(Streaming)
- 流式传输通过 SSE(Server-Send Events)方式实现。
- 适用场景:需增量生成结果或实时进度反馈的任务。
- 流程:
-
- 客户端通过message/stream发起交互。
- 服务端保持 HTTP 连接开放,持续发送 SSE 事件流(包括 Task、Message、状态变更的 TaskStatusUpdateEvent 或产出物更新的 TaskArtifactUpdateEvent)。
- 前置条件:服务端需在智能体卡片(Agent Card)中声明流式传输支持能力。
推送通知(Push Notifications)
- 推送通知通过 WebHook 方式实现。
- 适用场景:超长耗时任务或 SSE 长连接不可行的场景。
- 流程:
-
- 客户端在任务初始化时提供回调 URL(通过tasks/pushNotificationConfig/set配置)。
- 当任务状态变更(完成、失败或需输入)时,服务端向该 URL 发送异步 HTTP POST 通知。
- 前置条件:服务端需在智能体卡片(Agent Card)中声明推送通知支持能力。
A2A 协议的工作流
A2A 协议的工作流程主要分为 3 个大步骤:
- 发现 A2A Server 的 AgentCard。
- A2A 授权和权限认证。
- 发起 A2A 请求。
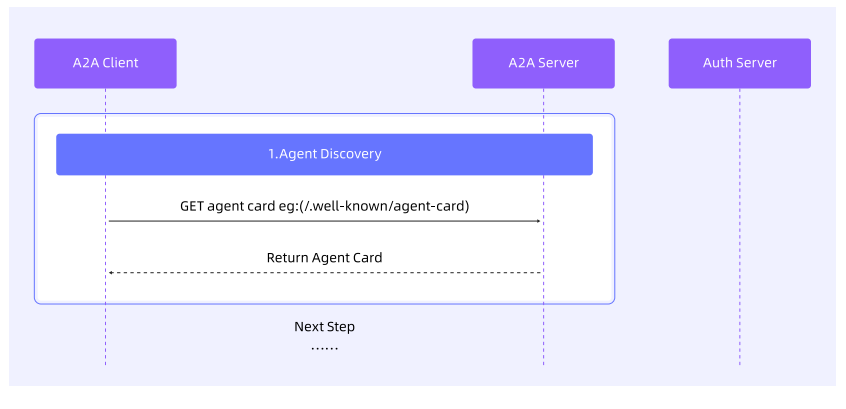
1、发现 A2A Server 的 AgentCard
通过 A2A 注册中心、AgentCard 获取地址、固定配置等方式获取目标 Agent Server 的 AgentCard 元数据。关于具体的 AgentCard 的发现方式介绍,将在下个小节中展开,此处仅展示此步骤的基本流程:
2、A2A 授权和权限认证
对于需要访问鉴权的 Agent Server,A2A 协议遵循标准 Web 安全实践,具体规则如下:
- 认证声明:智能体的认证要求需在 Agent Card 中明确声明,让客户端提前知晓鉴权规则。
- 凭据传递:OAuth 令牌、API 密钥等凭据通常通过 HTTP 请求头传递,与 A2A 协议的消息内容分离,避免二者耦合。
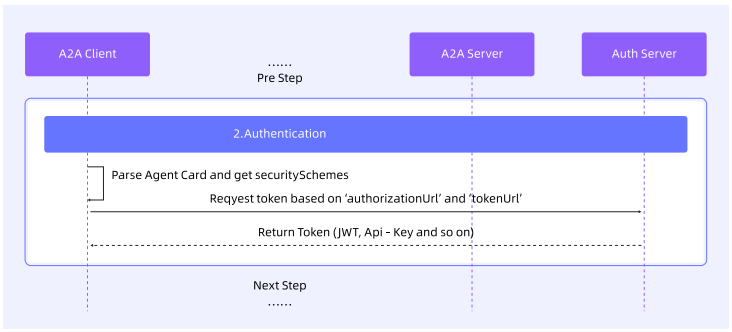
注:具体鉴权方式由智能体自行定义,客户端需按照 Agent Card 声明的要求进行适配。
3、发起 A2A 请求
完成 “获取 AgentCard” 与 “认证 Token 获取” 后,A2A Client 可获取 A2A Server 的所有可访问地址,随后根据需求向 A2A Server 发送调用请求。根据调用时的交互机制不同,可大致分为同步请求(轮询)和流式请求两类:
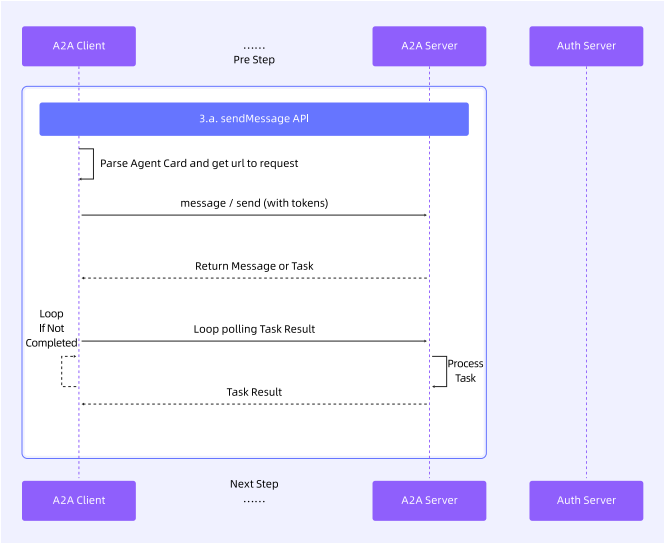
同步请求
对于小型任务请求或完全后台运行的任务,可通过同步请求发起对远端 Agent 的调用,直接从远端 Agent 返回的 Message 中获取结果,或通过定时轮询获取 Task 的运行结果。
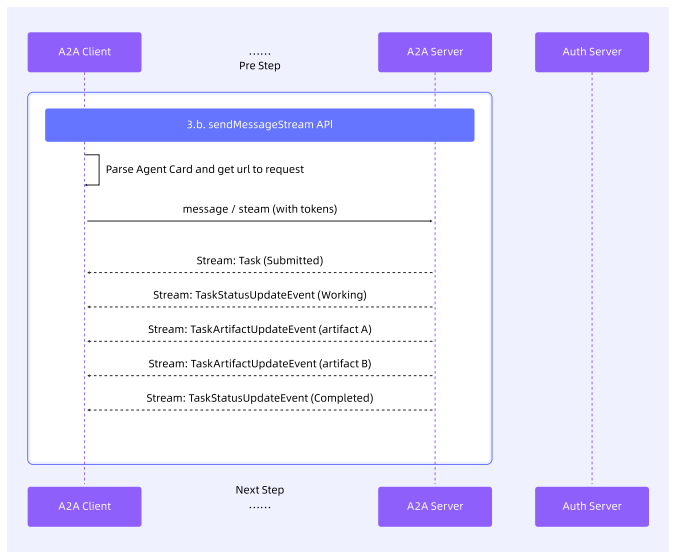
流式请求
对于需保障体验的任务请求,可采用流式请求方式,实时获取任务执行进度,并根据实时的 Task 状态与内容,在 A2A Client 端实时展示结果。
基于 Nacos A2A Registry 的自动注册与发现
前文介绍了分布式智能体的发展趋势,及 A2A 协议(分布式智能体基础通信协议)的核心概念、交互机制与工作流程,其中工作流程的首个步骤是 “获取并发现远端 Agent 的 AgentCard”。本节将展开说明远端 Agent 的 AgentCard 获取与发现,先简要介绍 AgentCard 的定义和作用,再说明当前主流的 AgentCard 获取与发现方式。
1、AgentCard 的作用
AgentCard 是 A2A Server(远端 Agent)的数字名片,为 “发现智能体” 与 “实现交互” 提供必要信息,包含以下关键内容:
- 身份信息:智能体的名称、描述、服务提供方。
- 服务端点:远端 Agent 的访问 URL,包含完整的域名 / IP、端口、URI 等。
- 协议能力:支持的协议功能(如流式传输 streaming、推送通知 pushNotifications)。
- 认证方式:交互所需的鉴权机制(如 Bearer 令牌、OAuth2)。
- 技能列表:智能体可执行的任务或功能(以 AgentSkill 对象形式呈现),包含技能 ID、名称、描述、输入 / 输出模式及示例。
A2A Client 通过解析 AgentCard,可判断远端 Agent 是否适配当前任务、如何构建请求以及采用何种安全通信方式。因此,A2A Client 发现远端 Agent 的 AgentCard 的过程,就是 A2A 协议中的 “Agent 发现过程”。
2、AgentCard 的获取方式
根据社区对发现方式的探索及官方定义,AgentCard 的获取与发现方式主要有直接配置、固定 URI、注册中心 3 种:
直接配置
直接在 A2A Client 中配置 AgentCard,可通过硬编码、配置文件等方式,在程序中自主构建 AgentCard 的 Json 内容,并在 A2A Client 初始化时传递进去。
- 适用场景:紧密耦合系统、私有智能体或开发测试环境。
- 机制:客户端通过硬编码、配置文件、环境变量或私有 API 获取 AgentCard 信息。
- 流程:根据具体应用的部署策略实现,无统一标准。
- 优点:简单高效,适用于已知或静态的智能体关系。
- 注意事项:灵活性低,动态发现能力弱;AgentCard 变更时需重新配置客户端。
固定 URI(Well-Known URI)
通过约定好的固定 URI,轮询或定期从固定远端服务获取远端 Agent 的 AgentCard,是兼顾 “简单易用” 与 “灵活可变” 的发现方案。
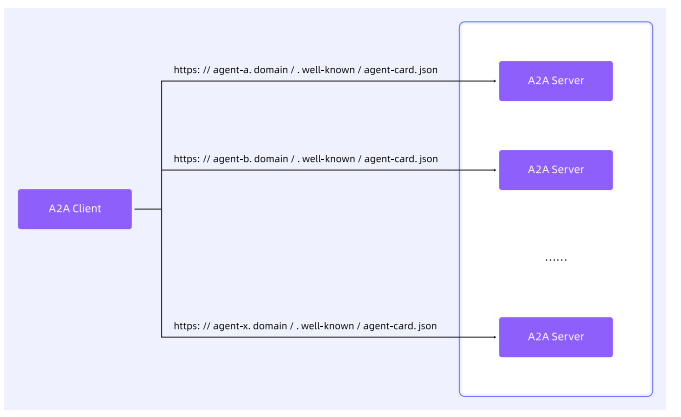
- 适用场景:面向公开或特定领域内广泛发现的智能体。
- 机制:A2A 服务端将 AgentCard 托管在域名的标准化路径下,固定路径为https://{智能体服务域名}/.well-known/agent-card.json(遵循 RFC8615 标准)。
- 流程:
-
- 客户端获知目标服务域名(如smart-thermostat.example.com);
- 发起 HTTP GET 请求至https://smart-thermostat.example.com/.well-known/agent-card.json;
- 服务端返回 JSON 格式的 AgentCard(若存在且可访问)。
- 优点:简单、标准化,支持自动化发现(如爬虫或域名监听系统),将发现问题简化为 “获取智能体域名”。
- 注意事项:
-
- 适合开放或组织内可控域名的场景;
- 若 A2A Client 依赖多个远端 Agent,需维护并记录每个远端 Agent 的固定 URI,且需遍历所有固定 URI;
- 若 AgentCard 包含敏感信息,访问端点需额外鉴权。
Nacos A2A 注册中心
与微服务架构中 “通过中心化注册中心实现微服务发现” 的体系类似,A2A 协议可通过中心化注册中心对远端 Agent 的 AgentCard 进行统一集中管理。此时 A2A Client 无需保存和维护所需远端 Agent 的公开域名或 Endpoint,仅需知晓注册中心的公开域名或 Endpoint 即可,是目前所有方案中灵活度与可控性最高的发现方案。
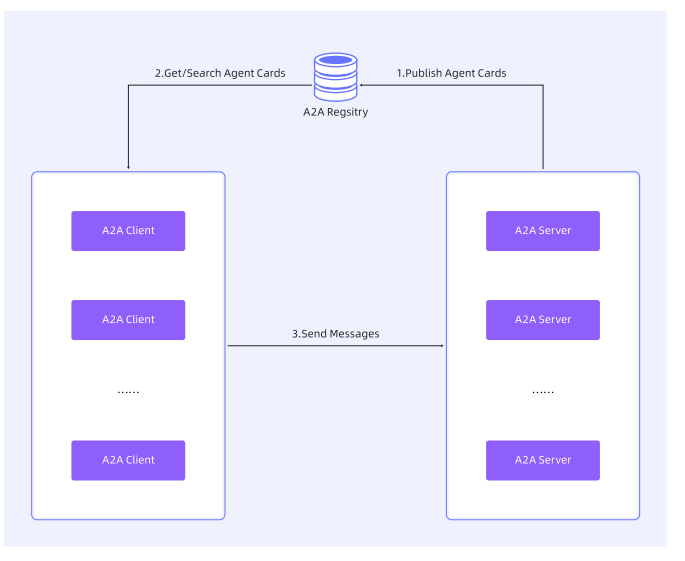
适用场景
企业环境、市场或生态系统中需集中管理的智能体。
机制
由注册中心(中介服务)维护 AgentCard 集合,客户端通过查询条件(如技能、标签、提供方)检索目标智能体。
流程
- A2A 服务端或管理员向注册中心提交 AgentCard;
- 客户端调用注册中心 API(如 “查找支持流式传输且具备图像生成技能的智能体”);
- 注册中心返回匹配的 AgentCard 列表或引用。
优点
- 支持集中化管理与治理,可基于功能实现动态发现;
- 可实现访问控制、策略与信任机制;
- 支持企业私有市场、公共市场等场景。
注意事项
需额外部署和维护注册中心服务。
随着 Nacos 3.1.0 的发布,Nacos 可作为 A2A 协议的注册中心,提供 Agent 的统一管理、注册、发现与按需检索能力;此外,Nacos 还支持对 Agent 的版本进行管理和快速回滚,以便正式的智能体应用在进行 A2A 远程访问时,实现精细化的灰度发布与管理。
除作为 A2A 的注册中心外,Nacos 还可作为 MCP 服务的注册中心及 Prompt 的动态管理中心,帮助用户从 Agent 应用视角出发,管理 Agent 应用开发过程中的动态配置、工具及远端 Agent 依赖内容,从而让用户能像开发微服务应用一样,简单地开发分布式 Agent 应用架构与服务体系。
消息驱动的智能体开发模式
在传统互联网应用中,消息队列广泛用于服务解耦、异步通信和削峰填谷等场景。它通过异步化的事件驱动方式,提升系统可扩展性与稳定性,典型场景如订单处理、日志收集、通知推送等。传统消息队列(如 Apache RocketMQ、Kafka)强调高并发写入、顺序消费和基本负载均衡,已形成成熟的技术范式。
然而,随着生成式 AI 的兴起,AI 应用呈现出截然不同的业务特征:推理耗时长达分钟级、上下文数据高达上百 MB、多轮对话需长期维护状态、多 Agent 协同依赖复杂异步编排,且严重依赖昂贵的 GPU 资源。
在此背景下,传统消息队列暴露出明显局限:无法高效支持百万级长会话隔离、缺乏对大消息的优化传输、难以实现消费速度的精细控制,更不具备优先级调度与资源导向的智能负载均衡能力。简单的异步模型已无法满足 AI 场景下对稳定性、成本控制与任务优先级的严苛要求。
因此,在 AI 云原生架构下的消息队列必须具备以下特点:
- 支持长会话与大消息体的消息中枢;
- 实现削峰填谷、定速消费的智能调度能力;
- 提供优先级、权重控制的分级事件驱动机制;
- 构建高可靠、可恢复的 Agent 编排引擎。
消息模型提升 AI 通信效率
AI 应用的交互通常具有长耗时、多轮次和高算力成本的特点。当依赖 SSE 或 WebSocket 等长连接时,一旦连接中断(如网关重启、超时或网络波动),不仅会话上下文可能丢失,已执行的 AI 任务也会被迫中断,导致昂贵的计算资源被浪费。因此,构建一个可靠的会话管理机制,确保在长时间对话中上下文的连续性与完整性,减少因重连或重试带来的资源消耗,同时降低应用逻辑的复杂性,成为该场景下的关键技术挑战。
针对这一挑战,RocketMQ 提出了一种创新的轻量化架构 —— 其核心理念是:为每个会话或问题动态创建一个独立的轻量级主题(Lite-Topic)。以客户端与 AI 服务建立会话为例,系统自动创建一个以 SessionID 命名的专属队列(如 chatbot/{sessionID} 或 chatbot/{questionID}),所有会话历史、上下文和中间结果均以消息形式在该主题中有序流转。通过将每个会话隔离在独立的消息通道中,不仅实现了上下文的持久化与顺序保障,也彻底解耦了会话生命周期与长连接状态,为构建高可靠、可恢复的 AI 对话系统提供了底层支撑。
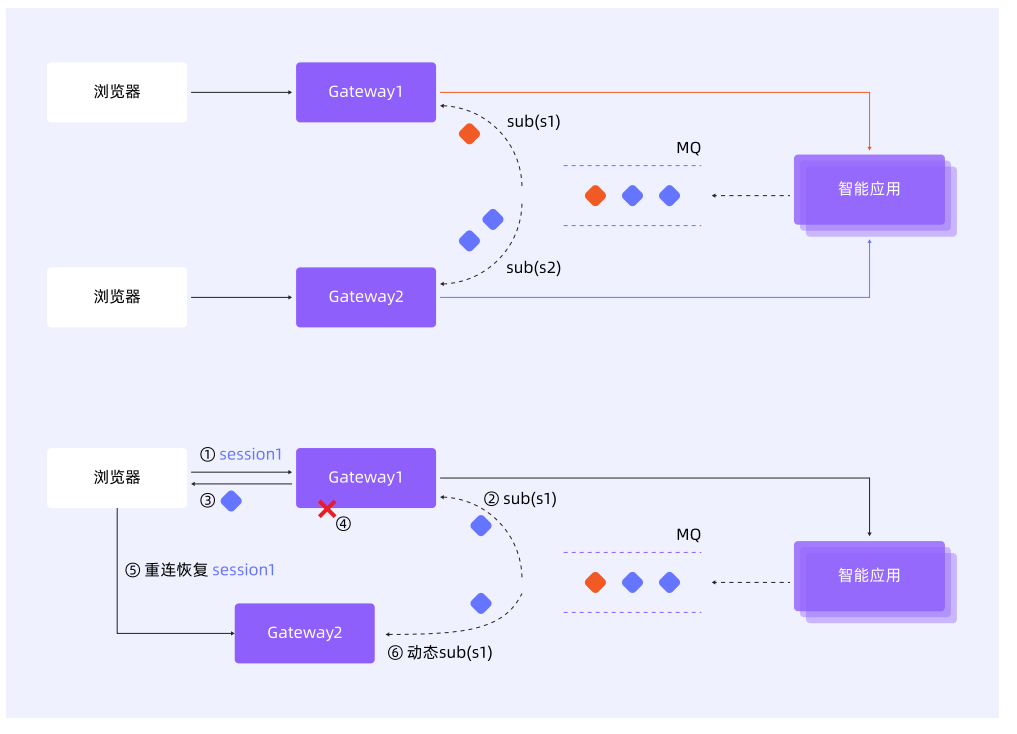
这一创新架构的实现,依托于 RocketMQ 为 AI 场景深度优化的四大核心能力:
- 百万级 Lite-Topic 支持:单集群可管理百万级轻量主题,为每个会话独立分配 Topic,实现高并发下的会话隔离,性能无损;
- 全自动轻量管理:Lite-Topic 按需动态创建,连接断开后自动回收,彻底杜绝资源泄漏,运维零干预;
- 大消息体传输能力:支持数十 MB 乃至更大消息,轻松承载长 Prompt、图像、文档等 AIGC 典型数据负载;
- 严格顺序消息保障:在单队列内保证消息有序,确保 LLM 流式输出的 token 顺序不乱,支撑连贯流畅的交互体验。
从业务模型上来看,轻量级消息模型包括了轻量级发送、轻量级订阅以及全新的消费分发策略:
轻量级发送
- 基于百万队列的方案,本质上是一个个 Queue;
- 从全局来看,一个轻量级 Topic 不会存在于每一个 Broker 上,在分配和发送时像顺序 Topic 的发送一样要做 Queue 的 Hash;
- Queue 的消息是某个 Broker 专属的,一个轻量级 Topic 的发送不会只到一台 Broker,而不是轮询发送。
轻量级订阅
- 消费组 Group 的概念被弱化;
- 订阅关系、消费进度管理粒度更细,以 client_ID 维度维护;
- 新增互斥(Exclusive)消费模式;
- TTL 到期后自动删除订阅关系。
消费分发策略
- 客户端发起读请求不再指定 Topic,而是 Broker 根据 client_ID 识别订阅关系,并返回多个 Topic 的多条消息;
- 引入类似 Epoll 机制的 Topic readyset,在 POP 请求处理时直接访问就绪的 topic;
- 当订阅上线、新消息发送、消息 ACK(Acknowledgement,确认)后仍有消息、order Lock 释放时,往 topic ready set 进行 add 操作。
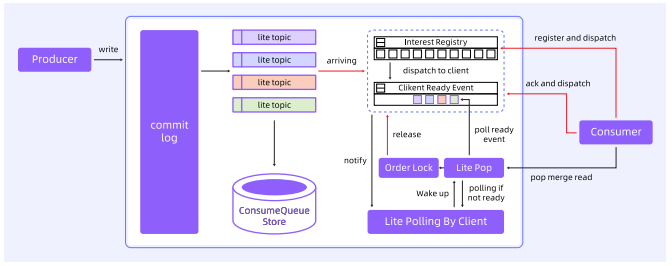
轻量化消息模型突破了传统消息队列订阅关系单一、隔离粒度粗、管理复杂等局限,通过精细化的资源隔离机制,实现了海量 Lite-Topic 的高效生命周期管理与低延迟消息投递。该模型为 AI 场景下的会话管理、上下文持久化以及多 Agent 间的异步协同,提供了高可靠、易扩展的全新架构解决方案。
基于消息驱动的智能化资源调度
大模型服务普遍面临两大核心资源调度难题:
- 负载不匹配:前端请求常突发波动,而后端算力资源有限且稳定,直接对接易引发服务过载或利用率不足,难以实现稳定服务与资源效率的平衡;
- 资源分配无差别:在流量被平滑后,仍需解决关键问题 —— 如何优先保障高价值任务(如 VIP 请求、核心业务)的资源获取,以最大化算力的服务价值。
RocketMQ 不仅实现了流量的平滑缓冲,更通过优先级与配额机制,赋予系统智能调度与资源优化的能力,推动消息系统从被动队列向主动控制中枢演进。开发者无需自研复杂调度中间件,即可实现对 AI 流量的精细化管控。其核心能力包括:
- 天然削峰填谷,保护 AI 算力:消息队列作为 “流量水库”,可缓存突发请求,使后端 AI 服务按自身处理能力自适应消费,实现负载均衡,避免因瞬时高峰导致服务崩溃或资源闲置;
- 定速消费,精准控制算力使用:支持为消费者组(Consumer Group)设置消费配额(quota),实现稳定速率消费。开发者可精确设定每秒调用次数,在保障模型服务稳定的前提下,最大化 GPU 利用率与系统吞吐;
- 优先级调度,实现智能资源分配:在资源竞争场景下,支持多维度调度策略:
-
- 抢占式优先级:将 VIP 请求、关键任务标记为高优先级消息,确保其优先被消费,保障核心业务响应质量;
- 权重动态分配:在多租户共享算力池场景中,可根据业务重要性或执行状态动态调整消息优先级,平衡吞吐效率与资源公平性,防止个别租户 “资源饥饿”。
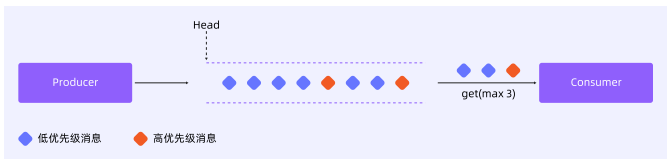
通过 RocketMQ 的综合调度能力,可以高效稳定地实现资源管理:用户将请求统一写入 RocketMQ,突发流量被暂存为 “待处理会话”;AI 推理服务按自身处理能力设置定速平滑消费,避免雪崩或空转,保障服务稳定性;当有更高优先级的用户消息进入时会被标记,系统优先调度处理,确保高价值客户获得毫秒级响应体验;而当多个业务线共享算力时,根据 SLA 和执行状态动态调整消息优先级,保障核心业务的同时,避免低优先级租户长期得不到资源。
基于统一元数据的 AI 协同开发模式
前面章节介绍了使用 AI 框架进行智能体应用开发的基本过程。在实际场景中,应用的开发通常需要多角色协同,接下来换一个视角,看看 AI 能力如何在应用开发中带来更高效的协同。
传统开发流程的痛点
传统开发流程为 “产品原型→设计稿→前后端代码”,存在大量重复劳动:产品经理用 Axure 等原型工具画的原型,设计师要用 Figma、MasterGo、Sketch 等工具画成高保真设计稿,交付给前端后又要在本地 IDE 里改写成 HTML、CSS…… 核心问题是上游角色的交付物下游无法复用。
AI 时代的协同优化
AI 时代,可以基于统一元数据,所有交付物都使用 HTML 格式,从建立 “需求即代码” 的团队协作基准开始;定义全局标准,协调每个角色的产出可直接被下游角色使用,并且在开发全流程的每个环节基于 AI 提效。例如:
- 产品经理描述需求,AI 生成交互式 HTML 原型;
- 设计师在同样的 HTML 基础上,通过拖拽组件调整样式,AI 生成对应的 CSS 和组件结构;
- 前端工程师在生成的 HTML/CSS 基础上,添加 JavaScript 逻辑,AI 可辅助生成重复的逻辑代码;
- 后端工程师根据前端定义的接口规范,由 AI 生成初步的 API 代码和数据库模型。
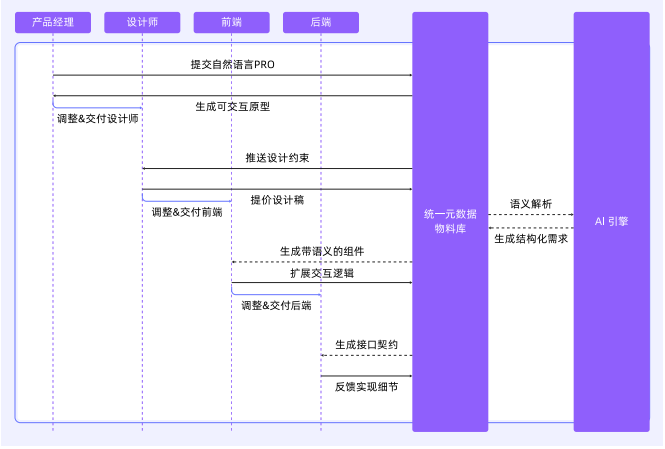
统一元数据需要长期建设,包含设计系统、组件库、API 规范、状态管理等,同时需要确保它们在不同阶段之间可以无缝转换。例如,产品经理的需求文档如何转化为可交互的原型,设计师如何在这个原型基础上进行视觉设计,前端如何直接使用设计稿生成的代码,后端如何根据接口规范自动生成代码。
该协同模型需要工具链的支持,例如开发一个集成 AI Agent 的平台,提供从 PRD 到设计再到代码的转换工具,每个角色在这个平台上工作,AI 自动处理转接和生成。此外,测试和迭代也是重要环节:需要确保每个阶段的交付物经过验证,避免错误累积到下游;可能引入自动化测试,AI 辅助测试用例生成,或提供实时预览功能,让各角色及时看到修改效果。
还要考虑协作中的沟通和版本管理:统一物料库可能需要类似 Git 的版本控制系统,记录每次修改,方便回溯和协作;AI 可在此处帮助解决冲突,或自动合并不同角色的修改。

在 AI 时代,产品经理构建业务上下文、设计师构建设计系统上下文、前后端构建专业 / 领域上下文,每个角色不再是孤立的。从建立 “需求即代码” 的团队协作基准开始,从组件契约标准化入手,逐步构建跨工具链的智能开发环境。
更多推荐

 39
39 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)