Stable Diffusion在进行AI 创作时对算力的要求
Stable Diffusion 在不同创作场景下的算力要求差异较大,核心取决于生成内容的复杂度(分辨率、细节精度)、使用的模型组合(基础模型 + 插件)以及创作规模(单张 / 批量 / 视频帧)。以下是分场景的算力需求分析。
·
Stable Diffusion 在不同创作场景下的算力要求差异较大,核心取决于生成内容的复杂度(分辨率、细节精度)、使用的模型组合(基础模型 + 插件)以及创作规模(单张 / 批量 / 视频帧)。以下是分场景的算力需求分析:
一、基础图像创作(最常见场景)
1. 简单图文生成(如头像、插画草图)
- 分辨率:512×512 或 768×512
- 模型:基础模型(如 SD 1.5、NovelAI),无插件
- 算力要求:
- 最低配置:GPU 显存 ≥ 4GB(如 GTX 1650 4GB),可生成但速度慢(单张 40-60 秒),需启用
--lowvram模式。 - 推荐配置:GPU 显存 6-8GB(如 RTX 3050 8GB、RTX 4060 8GB),生成速度 15-30 秒 / 张,支持轻度参数调整。
- 最低配置:GPU 显存 ≥ 4GB(如 GTX 1650 4GB),可生成但速度慢(单张 40-60 秒),需启用
- 典型场景:社交媒体头像、简单插画草稿、表情包制作。
2. 高清图像生成(如海报、角色设计)
- 分辨率:1024×1024 或 1536×1024
- 模型:SDXL 或 SD 1.5 + 高清修复(Hires. fix),可叠加 1-2 个 LoRA
- 算力要求:
- 最低配置:GPU 显存 ≥ 8GB(如 RTX 3060 12GB),需启用 xFormers 优化,单张生成 30-60 秒。
- 推荐配置:GPU 显存 12-16GB(如 RTX 4070 12GB、RTX 3090 24GB),支持 1024×1024 直接生成,叠加 LoRA 后速度仍能保持在 20-40 秒 / 张。
- 典型场景:电商海报、游戏角色概念图、杂志插图。
二、复杂创意设计(多插件 / 高细节)
1. 可控生成(如精准构图、风格迁移)
- 核心需求:叠加 ControlNet(如 Canny 边缘检测、OpenPose 骨骼控制)、深度模型(Depth)等
- 算力要求:
- 基础 ControlNet 叠加(1-2 个):GPU 显存 ≥ 12GB(如 RTX 4070 12GB),显存占用比纯生成增加 30%-50%,单张时间延长至 40-80 秒。
- 多 ControlNet 叠加(3-4 个):GPU 显存 ≥ 16GB(如 RTX 4080 16GB),需优化工作流(如分阶段加载模型),避免显存溢出。
- 典型场景:按线稿生成上色图、控制角色动作的插画、按草图生成产品渲染图。
2. 超高清 / 大尺寸创作(如大幅海报、壁画设计)
- 分辨率:2048×2048 及以上(甚至 4K/8K)
- 技术方案:Tiled Diffusion 分片渲染(将大图拆分为小瓦片并行生成)
- 算力要求:
- 2048×2048 分辨率:GPU 显存 ≥ 16GB(如 RTX 4090 24GB),单张生成 2-5 分钟。
- 4K/8K 分辨率:GPU 显存 ≥ 24GB(如 A40 48GB、A100 80GB),需配合分布式渲染,单张耗时 10-30 分钟。
- 典型场景:大型户外广告、博物馆壁画设计、高分辨率壁纸。
三、批量与衍生创作(规模化生产)
1. 批量生成(如商品图、素材库)
- 规模:单次生成 10-50 张,风格 / 主题统一
- 算力要求:
- 小批量(10-20 张 1024×1024):GPU 显存 12-16GB(如 RTX 4070 12GB),配合批量节点(如 ComfyUI 的 Batch Generate),总耗时约 10-20 分钟。
- 大批量(30-50 张):GPU 显存 ≥ 24GB(如 RTX 4090 24GB)或多卡并行(2×RTX 4070),通过负载均衡减少等待时间。
- 典型场景:电商平台批量商品图、游戏素材库(道具、图标)生成。
2. 视频帧 / 动画生成(如短片、动态插画)
- 核心需求:生成连续帧(30-60 帧),保证时间一致性
- 模型:Stable Video Diffusion、AnimateDiff 等插件
- 算力要求:
- 短视频(10 秒 / 30 帧,512×512):GPU 显存 ≥ 16GB(如 RTX 4080 16GB),单帧生成 10-15 秒,总耗时 5-8 分钟。
- 高清视频(30 秒 / 900 帧,1024×1024):GPU 显存 ≥ 24GB(如 RTX 4090 24GB)或多卡集群,需启用帧间缓存优化,总耗时 30-60 分钟。
- 典型场景:动态插画、产品宣传短片、游戏过场动画草稿。
四、模型训练与定制(进阶创作)
1. LoRA 微调(定制风格 / 角色)
- 数据规模:10-50 张参考图,训练 1000-5000 步
- 算力要求:
- 最低配置:GPU 显存 ≥ 10GB(如 RTX 3090 24GB),单轮训练(1000 步)约 10-20 分钟。
- 高效配置:GPU 显存 ≥ 24GB(如 RTX 4090 24GB),支持更大批次训练(batch size=8),时间缩短至 5-10 分钟。
- 典型场景:定制品牌风格 LoRA、游戏角色专属模型。
2. 模型微调(全量参数调整)
- 数据规模:100-1000 张图,训练 10,000+ 步
- 算力要求:
- 最低配置:GPU 显存 ≥ 24GB(如 A100 40GB),单轮训练需数小时。
- 专业配置:多卡集群(4×A100 80GB),分布式训练加速,适合企业级定制。
五、算力优化核心技巧
- 模型轻量化:用 FP16 量化模型(比 FP32 省 50% 显存),优先选择轻量模型(如 SD 1.5 替代 SDXL)。
- 加速工具:启用 xFormers 或 Flash Attention,显存占用减少 30%-50%,速度提升 20%-40%。
- 分辨率策略:低分辨率(512×512)生成草图,再用高清修复放大,比直接生成高分辨率省 50% 算力。
- 云算力补充:临时高负载任务(如批量 4K 图生成)可租用云 GPU,按小时计费,降低硬件成本。初步实施可使用线上云服务器:如“智算云扉https://waas.aigate.cc/user/charge?channel=W6P9Y2F8H&coupon=3ROAWRGJRH等租赁平台,已经按照应用需求优化好使用环境,支持各类镜像服务,按量计费。
总结
Stable Diffusion 的算力需求呈 “阶梯式” 分布:
- 个人轻量创作(头像、草图):8GB 显存 GPU 足够;
- 专业设计(高清海报、可控生成):12-24GB 显存是核心门槛;
- 大规模 / 超高清创作:24GB+ 显存或多卡集群是必需。
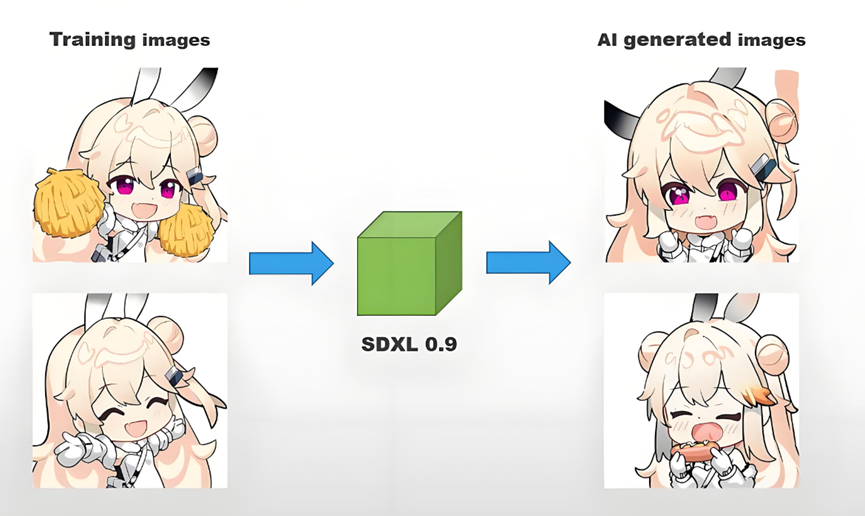
通过工具优化和策略调整(如分片生成、云边协同),可在有限算力下最大化创作效率,无需盲目追求顶级硬件。

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐


 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)