阿里Qwen3-VL:突破视觉 - 语言边界,解锁多模态智能的全场景深度能力
多模态AI技术正突破单一模态限制,阿里巴巴Qwen团队发布的《Qwen3-VL Cookbooks》为开发者提供了实践指南。Qwen3-VL具备文本理解、视觉感知、视频分析等综合能力,支持32种语言OCR和超长视频处理。该指南通过具体案例展示了图像思维分析、智能设备操作代理、设计图转代码等核心功能,例如精准识别电路图细节、自动生成网页HTML代码等。开发者可通过本地部署或API调用快速应用这些技术
在人工智能技术飞速发展的今天,多模态AI正逐渐成为连接数字世界与物理世界的核心纽带。它打破了文本、图像、视频、空间信息之间的壁垒,让机器能够像人类一样“看懂”世界、“理解”场景、“执行”任务。阿里巴巴Qwen团队发布的【Qwen3-VL Cookbooks】正是这样一套里程碑式的实践指南,它以精心设计的notebooks合集,将Qwen3-VL这一多模态巨模的强大能力具象化,为开发者打开了探索多模态AI应用的大门。
多模态AI的新纪元:Qwen3-VL的诞生与价值
在过去的几年里,AI技术经历了从单一模态向多模态的跨越。早期的语言模型只能处理文本,图像模型仅能识别视觉信息,这种“偏科”状态极大限制了AI的应用场景。而多模态AI的出现,让机器首次具备了整合视觉、语言、空间等多种信息的能力,这不仅是技术上的突破,更意味着AI开始真正贴近人类认知世界的方式。
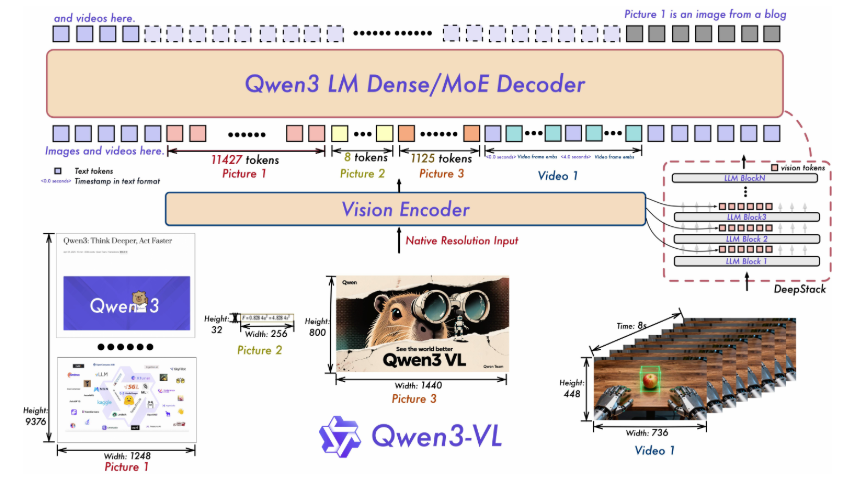
Qwen3-VL作为Qwen系列中最强大的视觉-语言模型,在技术上实现了全面升级。它不仅具备卓越的文本理解与生成能力,更在视觉感知、空间推理、视频动态分析等方面实现了质的飞跃。从支持32种语言的OCR功能,到能处理长达数小时视频的超长上下文能力;从精准的2D/3D对象定位,到能控制电脑和移动端界面的智能代理功能,Qwen3-VL正在重新定义多模态AI的边界。
而【Qwen3-VL Cookbooks】的价值,就在于它将这些抽象的技术能力转化为可操作、可复用的实践方案。无论你是AI研究者、企业开发者,还是对多模态技术感兴趣的爱好者,都能通过这套Cookbooks快速上手,将Qwen3-VL的能力融入实际项目中。它支持本地部署与API调用两种模式,既满足了对数据隐私有高要求的场景,也降低了中小企业的使用门槛,真正实现了“技术普惠”。
场景化实践:Cookbooks中的多模态能力全景
图像思维:让AI看懂细节,学会“思考”
人类在观察图像时,不仅会看到整体画面,还会主动聚焦细节、分析关联——这种“图像思维”能力,如今Qwen3-VL也已具备。Cookbooks中的“Thinking with Images”案例,展示了如何通过image_zoom_in_tool和search_tool让模型精准捕捉图像中的细微信息,实现从“看见”到“理解”的跨越。
比如在分析一张复杂的电路图时,传统模型可能只能描述整体结构,而Qwen3-VL可以通过图像缩放工具聚焦某个电阻的参数,结合知识库判断其型号是否匹配电路需求;在处理卫星遥感图像时,它能自主识别异常区域,放大分析后判断是否为灾害隐患。
以下是使用图像思维工具的基础代码示例:
from transformers import AutoModelForImageTextToText, AutoProcessor
from qwen_vl_utils import process_vision_info
# 加载模型和处理器
model = AutoModelForImageTextToText.from_pretrained(
"Qwen/Qwen3-VL-235B-A22B-Instruct", dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct")
# 定义包含图像和指令的对话
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://example.com/complex_image.jpg", # 输入需要分析的图像
},
{"type": "text", "text": "使用图像缩放工具,分析图像右下角的文字内容,并判断其含义。"},
],
}
]
# 处理视觉信息并生成输入
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
images, videos = process_vision_info(messages, image_patch_size=processor.image_processor.patch_size)
inputs = processor(text=text, images=images, videos=videos, do_resize=False, return_tensors="pt")
inputs = inputs.to(model.device)
# 生成模型响应
generated_ids = model.generate(** inputs, max_new_tokens=512)
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(output_text)
这段代码的核心在于通过process_vision_info预处理图像信息,结合模型的工具调用能力,让AI主动聚焦关键区域,实现类似人类的“观察-分析-推理”过程。这种能力在工业质检、医疗影像分析等领域具有极高的实用价值。
智能代理:让AI成为你的“数字助手”
随着智能设备的普及,人们对AI的期待已从“回答问题”升级为“解决问题”。Qwen3-VL的“Computer-Use Agent”和“Mobile Agent”功能,正是这一需求的完美回应——它能像人类一样识别电脑或手机界面的元素,理解其功能,并执行具体操作。
在“电脑操作智能代理”案例中,Qwen3-VL可以根据用户指令,自动打开浏览器搜索信息、调整文档格式、甚至操作专业软件完成数据可视化。比如用户说“帮我把Excel中的销售数据按地区汇总,并生成饼图”,模型会先识别Excel界面的菜单栏、数据区域,然后依次执行“选中数据”“插入饼图”“调整样式”等操作,整个过程无需人工干预。
移动端代理则更贴近日常生活。它能识别手机APP的按钮、输入框等元素,完成诸如“预约明天的疫苗接种”“设置早上7点的闹钟”等任务。对于老年人或操作不熟练的用户来说,这无疑是一个贴心的“数字帮手”。
以下是调用移动端代理功能的示例代码:
from openai import OpenAI
# 配置客户端
client = OpenAI(
api_key="你的DASHSCOPE_API_KEY",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 定义任务:让AI操作手机设置闹钟
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/mobile_alarm_interface.jpg"}, # 手机闹钟界面截图
},
{"type": "text", "text": "请告诉我如何在这个界面设置明天早上7点的闹钟,并用代理功能模拟操作步骤。"},
]
}
]
# 调用API
response = client.chat.completions.create(
model="qwen3-vl-235b-a22b-instruct",
messages=messages,
max_tokens=1024
)
print(response.choices[0].message.content)
通过分析界面截图,模型会返回详细的操作步骤,甚至可以通过集成自动化工具直接执行操作。这种“感知-决策-执行”的闭环能力,让AI从“顾问”真正变成了“执行者”。
多模态编程:从图像到代码的无缝转换
对于开发者而言,将设计图转化为代码往往需要大量的手动工作,尤其是在前端开发、流程图绘制等场景中。Qwen3-VL的“MultiModal Coding”功能彻底改变了这一现状——它能直接根据图像或视频生成Draw.io流程图、HTML/CSS/JS代码,实现“所见即所得”的编程体验。
比如设计师提供一张网页原型图,Qwen3-VL可以识别其中的按钮、输入框、布局结构,自动生成对应的HTML代码,并附带CSS样式;在绘制系统架构图时,只需上传手绘草图,模型就能生成符合Draw.io格式的流程图代码,大幅提升团队协作效率。
以下是根据网页设计图生成HTML代码的示例:
from transformers import AutoModelForImageTextToText, AutoProcessor
model = AutoModelForImageTextToText.from_pretrained(
"Qwen/Qwen3-VL-235B-A22B-Instruct", attn_implementation="flash_attention_2", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct")
# 输入网页设计图和指令
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://example.com/web_design.png", # 网页设计图
},
{"type": "text", "text": "根据这张设计图,生成对应的HTML和CSS代码,要求响应式布局。"},
],
}
]
# 处理输入并生成代码
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
inputs = inputs.to(model.device)
generated_ids = model.generate(** inputs, max_new_tokens=2048)
code_output = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print("生成的代码:\n", code_output)
生成的代码不仅结构完整,还会包含注释说明关键部分的设计逻辑,开发者只需稍作调整即可投入使用。这种能力极大缩短了从设计到开发的周期,尤其适合快速原型开发场景。
全面识别:让AI“认识”世界万物
Qwen3-VL的“Omni Recognition”能力,堪称多模态领域的“百科全书”。它不仅能识别常见的动物、植物、人物、地标,还能精准辨认汽车型号、商品品牌、动漫角色等细分对象,甚至对古文字、专业术语也有出色的识别能力。
在电商场景中,用户上传一张商品图片,模型能立刻识别出品牌、型号、规格,并自动匹配相关的产品信息;在文物保护领域,它可以识别古籍上的罕见文字,辅助专家进行文献解读;在交通管理中,通过监控视频识别车辆型号、车牌信息,实现智能化的交通调度。
以下是调用全面识别功能的代码示例:
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor, AutoModelForImageTextToText
model = AutoModelForImageTextToText.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct", device_map="auto")
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct")
# 识别一张包含多种元素的图片
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://example.com/multiple_objects.jpg", # 包含多种物体的图片
},
{"type": "text", "text": "识别图中的所有物体,包括品牌、型号(如适用),并简要描述。"},
],
}
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
images, videos = process_vision_info(messages, image_patch_size=16)
inputs = processor(text=text, images=images, videos=videos, do_resize=False, return_tensors="pt")
inputs = inputs.to(model.device)
generated_ids = model.generate(** inputs, max_new_tokens=1024)
output = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(output)
无论是日常场景还是专业领域,这种全面的识别能力都能为用户提供精准的信息支持,成为连接物理世界与数字数据的重要桥梁。
文档解析:超越文字的结构化理解
在办公场景中,处理文档往往是最耗时的工作之一——尤其是包含表格、图表、复杂排版的长文档。Qwen3-VL的“Powerful Document Parsing”功能,不仅能提取文本内容,还能识别文档的布局结构、表格数据、图表含义,甚至以HTML格式还原文档的排版信息。
比如一份年度报告,模型可以自动提取其中的财务表格,将数据转换为可编辑的Excel格式;识别流程图中的逻辑关系,用文字描述业务流程;对于多语言混合的文档,还能同时完成翻译和结构化提取,极大提升办公效率。
以下是解析复杂文档的代码示例:
import time
from sglang import Engine
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor
# 配置模型引擎
checkpoint_path = "Qwen/Qwen3-VL-235B-A22B-Instruct"
processor = AutoProcessor.from_pretrained(checkpoint_path)
llm = Engine(
model_path=checkpoint_path,
enable_multimodal=True,
mem_fraction_static=0.8,
tp_size=4,
attention_backend="fa3",
context_length=10240,
)
# 解析长文档
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://example.com/long_document.jpg", # 长文档图片(多页)
},
{"type": "text", "text": "解析这份文档,提取所有表格数据并转换为CSV格式,同时总结文档核心观点。"},
],
}
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, _ = process_vision_info(messages, image_patch_size=processor.image_processor.patch_size)
# 生成解析结果
sampling_params = {"max_new_tokens": 2048}
response = llm.generate(prompt=text, image_data=image_inputs, sampling_params=sampling_params)
print("文档解析结果:\n", response["text"])
这种结构化的文档理解能力,让AI从简单的“文字搬运工”升级为“内容分析师”,在金融、法律、教育等领域有着广泛的应用前景。
空间与定位:从2D到3D的精准感知
空间理解是多模态AI最具挑战性的能力之一,而Qwen3-VL在这一领域实现了突破。它不仅支持2D平面上的对象定位(如用边界框标记图像中的物体),还能进行3D空间定位,为室内外物体提供精准的3D bounding boxes,这为机器人导航、AR/VR等领域奠定了基础。
在“2D Grounding”案例中,模型可以根据指令在图像中标记出特定物体,比如“用方框标出图中所有红色的汽车”;而“3D Grounding”则能在复杂场景中还原物体的空间位置,比如在一张室内照片中,标记出沙发、茶几的3D坐标,帮助机器人规划移动路径。
以下是3D空间定位的代码示例:
from transformers import AutoModelForImageTextToText, AutoProcessor
model = AutoModelForImageTextToText.from_pretrained(
"Qwen/Qwen3-VL-235B-A22B-Instruct", dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-235B-A22B-Instruct")
# 3D空间定位任务
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://example.com/indoor_scene.jpg", # 室内场景图片
},
{"type": "text", "text": "识别图中的家具,并用3D边界框标记它们的位置(格式:物体名称:[x1,y1,z1,x2,y2,z2])。"},
],
}
]
inputs = processor.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
inputs = inputs.to(model.device)
generated_ids = model.generate(** inputs, max_new_tokens=512)
output = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(output)
这种空间感知能力,让AI不仅能“看懂”图像,还能“理解”图像背后的物理空间,为智能机器人、自动驾驶等需要与物理世界交互的技术提供了核心支持。
OCR与视频理解:突破模态壁垒的深度分析
Qwen3-VL的OCR功能在行业内处于领先水平,支持32种语言识别,即使在低光、模糊、倾斜的场景下,也能精准提取文字,尤其擅长处理罕见字、古文字和专业术语。而在视频理解方面,它能处理长达数小时的视频,实现秒级索引和全内容召回,结合视频OCR技术,让视频中的文字信息也能被高效利用。
在“General OCR and Key Information Extraction”案例中,模型可以从一张模糊的发票中提取金额、日期、发票号等关键信息,并自动校验格式;在“Video Understanding”中,它能分析一场体育比赛的视频,识别进球瞬间、提取解说文字,并生成比赛亮点总结。
以下是视频理解与OCR结合的代码示例:
from openai import OpenAI
client = OpenAI(
api_key="你的DASHSCOPE_API_KEY",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 分析视频中的文字和内容
messages = [
{
"role": "user",
"content": [
{
"type": "video_url",
"video_url": {"url": "https://example.com/sports_match.mp4"}, # 体育比赛视频
},
{"type": "text", "text": "提取视频中的所有文字信息,识别进球时间点,并总结比赛精彩瞬间。"},
]
}
]
response = client.chat.completions.create(
model="qwen3-vl-235b-a22b-instruct",
messages=messages,
max_tokens=2048
)
print("视频分析结果:\n", response.choices[0].message.content)
无论是静态图像中的文字,还是动态视频中的信息,Qwen3-VL都能精准捕捉并深度分析,这在安防监控、媒体制作、教育课件处理等领域具有不可替代的价值。
技术突破:Qwen3-VL背后的创新力量
【Qwen3-VL Cookbooks】所展示的强大能力,并非偶然,而是技术积累的必然结果。Qwen3-VL在多个核心技术领域实现了突破,为这些应用场景提供了坚实的支撑。
首先是文本-视觉融合技术。Qwen3-VL采用了更高效的多模态融合架构,实现了文本与视觉信息的无损整合,让模型在理解图像时能结合上下文文本,在生成文字时能精准关联视觉内容,这种“无缝融合”是多模态能力的基础。
其次是超长上下文处理能力。通过YaRN技术,Qwen3-VL的上下文长度原生支持256K tokens,扩展后可达1M,这意味着它能处理整本书籍、数小时视频等超长内容,且保持对细节的高召回率。在处理长文档、长视频时,这种能力尤为关键。
再者是空间感知与推理引擎。Qwen3-VL引入了先进的空间注意力机制,能判断物体的位置关系、遮挡情况,甚至通过单张图像推断3D结构,这种空间智能让模型从“平面理解”走向“立体认知”。
最后是工具调用与代理能力。模型内置了对各类工具的调用接口,能根据任务需求自主选择工具(如图像缩放、网页操作),并规划执行步骤,这种“任务拆解+工具使用”的能力,让AI从“被动响应”变为“主动解决问题”。
未来展望:多模态AI的普及与挑战
【Qwen3-VL Cookbooks】的发布,不仅是技术成果的展示,更预示着多模态AI即将进入规模化应用的新阶段。从行业角度看,它将推动多个领域的智能化升级:在教育领域,多模态AI可以根据课本插图、视频教程生成个性化学习方案;在医疗领域,它能结合医学影像、病历文本提供辅助诊断建议;在制造业,通过分析生产视频、设备图像实现智能化质检……
然而,多模态AI的普及也面临着一些挑战。首先是部署成本,尽管Qwen3-VL支持边缘到云端的灵活部署,但高性能模型的硬件需求仍较高,如何进一步优化模型大小与性能的平衡,是未来的重要方向。其次是数据隐私,多模态数据往往包含图像、视频等敏感信息,如何在利用数据的同时保障隐私,需要技术与法规的双重支持。最后是可解释性,多模态模型的决策过程比单一模态更复杂,提升模型的透明度,让用户理解AI“为什么这么做”,是赢得信任的关键。
但无论如何,Qwen3-VL及其Cookbooks已经为我们描绘了多模态AI的光明前景。它展示了中国AI团队在全球技术竞争中的领先地位,更以开放、实用的姿态推动着整个行业的进步。对于开发者而言,这是一个充满机遇的时代——借助Qwen3-VL的能力,我们可以创造出更智能、更贴近生活的应用;对于用户而言,多模态AI将逐渐融入日常,成为工作、学习、生活中的得力助手。
多模态AI的浪潮已至,【Qwen3-VL Cookbooks】正是驶向未来的“航海图”。让我们借助这份指南,一起探索多模态世界的无限可能,共同书写智能时代的新篇章。

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐

 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)