
详解大模型:指令微调训练全流程指导,大模型入门到精通,收藏这篇就足够了!
在训练大语言模型的过程中,有一种非常关键的方法叫 指令微调。简单来说,就是给模型一组“问与答”的成对数据,让它学会根据我们的指令,给出符合预期的答案。
在训练大语言模型的过程中,有一种非常关键的方法叫 指令微调。简单来说,就是给模型一组“问与答”的成对数据,让它学会根据我们的指令,给出符合预期的答案。
1 指令微调数据
这种数据通常由两部分组成:
- 指令输入:也就是人们给模型的任务说明,比如一个问题、一段提示,或者一条操作要求。它的作用是告诉模型“我要你做什么”。
- 答案输出:这是模型需要学习生成的内容,也就是人类期望的正确回应。
举个例子:
如果我们想训练模型回答问题,可以这样设计数据:
User: 复旦大学有几个校区?
Assistant: 复旦大学共有四个校区,分别是邯郸校区、江湾校区、枫林校区和张江校区……
这里,“复旦大学有几个校区?”就是指令输入,而后面详细的回答就是答案输出。
不仅是问答,像机器翻译、文章摘要、文本改写、代码生成、数学解题等任务,都可以用这种“输入-输出”的形式来准备数据。比如,写作类任务可以设计成:
User: 请写一篇 500 字以内的短文,介绍复旦大学的历史沿革。
Assistant: (生成一篇包含复旦大学创建、发展历程的短文)
如果我们想让模型能理解多轮对话,还可以把前面的对话历史都作为“输入”,让模型学习最后一轮的“输出”。这样一来,模型经过微调后,就能更好地理解上下文,在聊天时表现得更自然。
不过,构建指令微调数据并没有看起来那么简单。真正操作起来会遇到不少挑战:
- 数据收集难:高质量的指令数据需要投入大量时间和资源,还得保证数据足够多样化和真实。
- 数据清洗和重写:收集来的数据往往需要筛选、改写,甚至通过专业方法来扩展,比如增加不同主题、不同表达方式。
- 格式统一:输入输出必须保持一致的格式,否则模型可能“看不懂”。
- 领域覆盖:既要包含常见任务,还要涉及医学、法律等专业领域,才能提升模型的通用性和专业性。
- 多语言需求:为了适应不同用户场景,还需要构建多语言的指令数据集。
可以说,指令微调数据的构建,是一项复杂而耗时的工作,需要跨学科的合作与创新。正因为如此,它才显得尤为重要,因为一旦数据构建得好,模型就能在各种任务中发挥出更强大的能力。
2 数据构建方法
如何构建指令微调数据集?
在让大模型变得“更聪明”的过程中,指令微调(Instruction Tuning)是非常重要的一步。那我们该怎么准备这些训练用的数据呢?主要有两种方式:手动构建、现有数据集转换和自动构建。
1)手动构建
顾名思义,就是靠人来“写”或者“收集”指令和回答。虽然挺耗费时间和人力,但它的优势非常明显:
- 质量高:专业标注人员会认真审核,剔除无效信息,保证数据干净、靠谱。
- 容易理解:人工写出来的问答往往更接近人类的思维方式,研究者一看就懂。
- 灵活可控:研究人员可以根据任务随时调整,让数据更贴合不同的使用场景。
具体来说,手动构建有两种常见方式:
① 人工写问答
比如 Databricks-dolly-15K 就是由数千名公司员工写的;OASST1 则是通过全球 1.3 万多名志愿者协作完成的。还有中文的 OL-CC 数据集,志愿者分角色对话,最终产出了上万条指令-回答对。再比如 Aya Dataset,来自 119 个国家的近 3000 名贡献者参与,覆盖了 65 种语言,数据量非常庞大。
② 抓取网络问答
另一种方式是直接从网上收集人类的真实对话或问答,然后再整理成“指令+回答”的格式。比如 InstructionWild v2 收集了 11 万多条来自网络的指令,涉及聊天、代码等多个领域。中文的 LCCC 数据集,则是从微博评论、贴吧帖子等渠道收集整理而来。
2)现有数据集转换
除了从零开始,还可以把现成的数据集“改造”一下,用于指令微调。这种方法的优点是:
- 多样性强:数据来源多,覆盖任务广。
- 规模大:多个数据集合并,样本数量自然翻倍增长。
- 节省时间:不用从头做,效率高。
但挑战也不少:
- 不同数据集质量不一,格式也不统一,需要大量标准化工作。
- 很多传统数据集本来是为 NLP 基础任务准备的,并不包含“多样的指令”,需要额外处理。
典型例子:
- OIG(Open Instruction Generation):由 LAION 社区打造,包含 4300 万条指令,覆盖问答、对话、总结等多种任务。
- Flan 2022:集成了 1836 个数据集,数据量巨大,还用了“任务混合”和“输入反转”等技巧,提升模型的泛化能力。
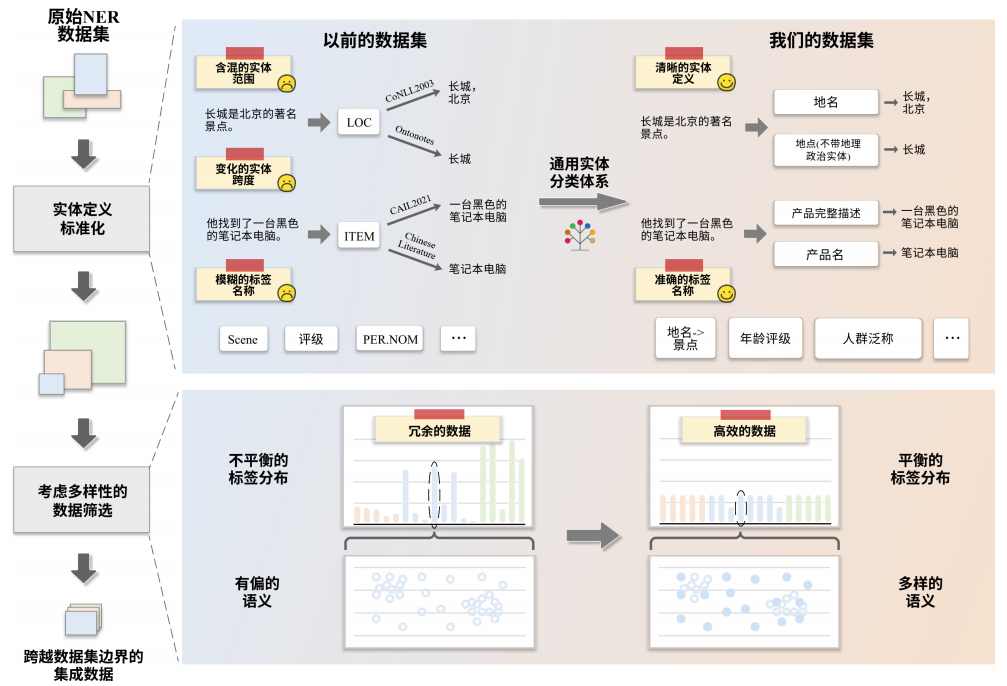
再比如命名实体识别(NER)的研究中,研究人员把 54 个中英文数据集合并,并通过标准化和数据修剪的方法,构建了一个叫 B²NERD 的新数据集。它不仅统一了“实体定义”的差异,还通过筛选去掉了冗余样本,最终得到 5.2 万条高质量数据,覆盖 400 多种实体类型。这让模型在信息抽取任务上更精准,也更不容易“混淆”。
3)自动构建
前面说过,手动写指令和答案虽然质量高,但太耗费人力。于是,研究者们想到:能不能让大模型自己来生成数据?
这就是 自动构建指令数据 的思路。
最具代表性的工作就是 Self-Instruct。它利用大语言模型的“自我生成”能力,让模型一步步扩展自己的训练数据。
Self-Instruct 的四个步骤
整个过程是一个“循环迭代”的过程,可以理解成:人类给模型一点点“种子”,然后模型自己不断长出更多的数据。
步骤 1:先种下“种子”
研究人员先手工写了 175 条小型任务指令,作为“种子指令池”。
之后,让模型参考这些种子,不断生成新的任务指令。
比如:每次从池子里抽出 8 条(6 条人工写的 + 2 条模型自己生成的),作为示例给模型看,模型就会模仿着再写更多新的指令。
这一过程一直循环,直到模型“写不动了”或者生成的内容太多为止。
步骤 2:判断任务类型
有些任务是分类任务(比如“判断一句话是不是积极的”),有些是非分类任务(比如“写一段小故事”)。
因为处理方式不一样,所以需要让模型自己先判断:这条指令是不是分类任务?
步骤 3:补齐输入和输出
光有“任务指令”还不够,还需要输入和输出。
- 对于 非分类任务,采用“输入优先”:先生成输入,再根据输入和任务生成输出。
- 对于 分类任务,采用“输出优先”:先列出所有可能的类别,再生成与之对应的输入。
这样能避免模型只盯着某些类别,导致数据不均衡。
步骤 4:质量过滤
并不是模型生成的所有指令都好用,需要筛选:
- 如果和已有指令太相似(相似度超过 0.7),就不要。
- 删除包含敏感关键词(比如“图片”)、重复的、太长或太短的指令。
经过这一关,留下的才是高质量、多样化的数据。

Self-Instruct 的厉害之处在于,它能自动产出海量、多样化的高质量指令数据,几乎不需要人力参与。
斯坦福团队就用这个方法,在 LLaMA 模型上微调出了知名的 Alpaca 模型。结果证明,这些“模型自己造的数据”非常有效,Alpaca 的表现远超预期。
举个例子,Alpaca 的数据里可能会有这样的指令:
- 指令:解释一下为什么天空是蓝色的
- 输入:(无)
- 输出:因为大气分子对阳光中的蓝光散射得更强,所以我们看到的天空呈蓝色。
3 指令微调训练策略
别看指令微调的训练流程和预训练差不多,实际上它对大模型的能力提升至关重要。举个例子:
- LLaMA-3.1-70B、Qwen2.5-72B 这样的模型只经过预训练,还没有学会如何“听懂人类的指令”;
- 而 LLaMA-3.1-70B-Instruct、Qwen2.5-72B-Instruct 这样的版本,则是在预训练基础上又加了指令微调,更适合和人类对话。
问题来了:要继续训练一个模型时,研究者常常会遇到一些难题:
- 是从预训练模型开始,还是用已经微调过的模型再接着训练?
- 要不要把所有任务的数据混在一起训练,还是一个个任务单独训练?
- 数据比例怎么分配,才不会让模型“偏科”?
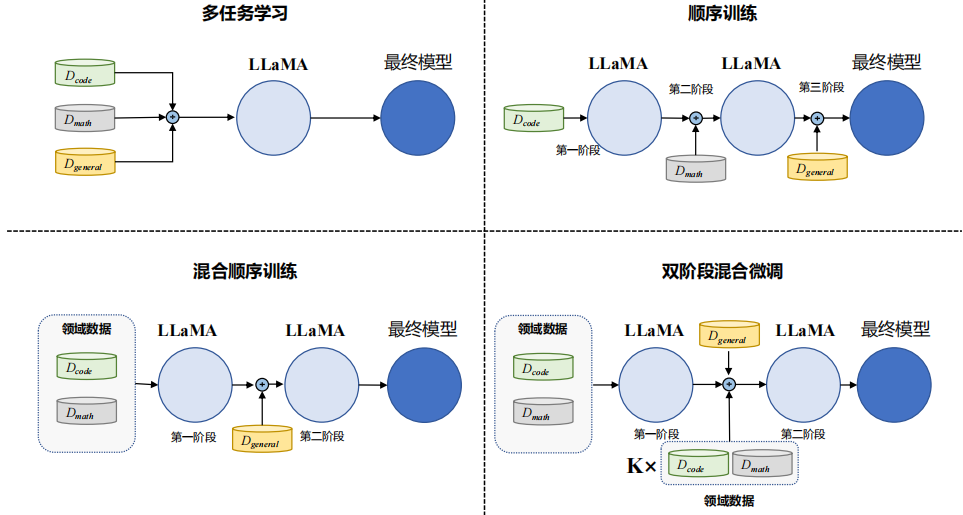
四种训练策略
有研究专门做了系统实验,把数学推理、代码生成和通用对话作为研究对象,分析了不同训练策略的效果。测试基准包括:
- GSM8K(数学推理)
- HumanEval(编程能力)
- MT-Bench(通用对话/对齐)
实验用的模型是 LLaMA 系列(7B 到 33B 参数规模)。他们比较了四种训练方式:
- 多任务学习
- 把数学、代码、对话这几类数据全混在一起训练。
- 优点:保留了领域能力(数学、代码)。
- 缺点:通用对话能力下降最严重。
- 顺序训练
- 按顺序来:先训练数学,再训练代码,最后训练通用对话。
- 优点:最终的对话能力最好。
- 缺点:前面学到的数学和代码知识会被“忘掉”。
- 混合顺序训练
- 先把数学和代码混在一起训练,再单独做通用对话微调。
- 效果比顺序训练稍好,但仍然会遗忘一些领域能力。
- 双阶段混合微调
- 先在数学和代码上做多任务学习;
- 再在最后阶段,用“少量领域数据 + 全量对话数据”一起训练。
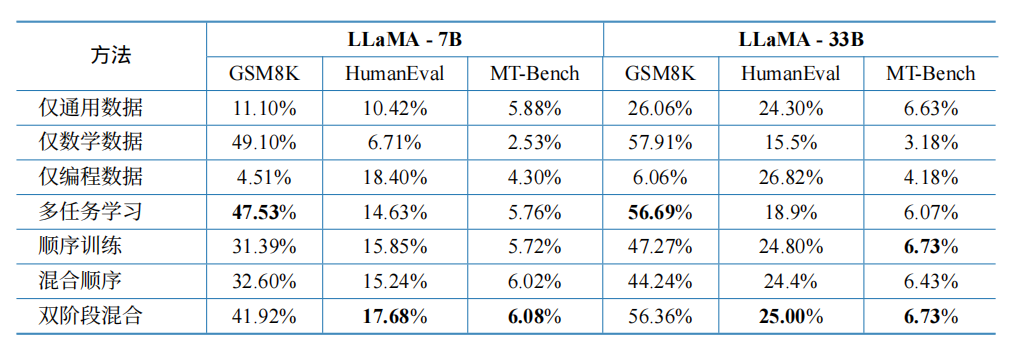
- 结果:缓解了遗忘问题,效果最均衡。比如 LLaMA-7B 的数学准确率从 32.6% 提升到 41.9%,代码生成从 15.2% 提升到 17.7%。
研究发现了什么?
这项研究还总结了几个有趣的规律:
- 模型越大越聪明
- 在相同数据量下,大模型通常效果更好。
- 但不同任务的收益曲线不同,比如数学和代码能随着规模快速提升,而通用对话提升更慢。
- 数学和代码越学越好
- 这两个任务随着数据量增加,表现一直在提升。
- 通用对话则在大约 1000 个样本后趋于饱和。
- 混合数据有利有弊
- 数据少时,把任务混在一起训练,能帮助模型获得全面能力。
- 数据多时,混合反而可能让任务之间“打架”,导致效果冲突。
-
数据量比比例更重要
决定模型效果的关键是总数据量,而不是不同任务之间的比例。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐



 7
7 0
0- 0



 已为社区贡献207条内容
已为社区贡献207条内容

所有评论(0)