
5分钟构建AI知识图谱,无需人工标注,瞬间让文本数据变成智能网络,大模型入门到精通,收藏这篇就足够了!
本文将基于以下开源项目:https://github.com/thu-vu92/knowledge-graph-llms/,深入解析大语言模型驱动的知识图谱构建技术,并探讨其在实际业务场景中的应用前景和实施策略。
想象一下,如果你能将一本厚重的书籍、一篇复杂的研究报告或者一堆散乱的文档,瞬间转换成一个清晰的可视化网络图,显示其中所有概念、人物、事件之间的关联关系,这会是什么样的体验?
随着大语言模型的突破性发展,从非结构化文本中自动提取知识图谱已经从实验室走向了实际应用。传统上需要大量人工标注和复杂机器学习模型才能完成的知识图谱构建工作,现在只需要几行Python代码就能实现。
本文将基于以下开源项目:https://github.com/thu-vu92/knowledge-graph-llms/,深入解析大语言模型驱动的知识图谱构建技术,并探讨其在实际业务场景中的应用前景和实施策略。
文中将以GPT-4o作为主要示例,同时涵盖Claude、Gemini、Llama、Qwen等多种模型的对比和应用,希望对你有所启发。
PART 01 知识图谱的战略价值重构
传统数据管理的困境
在数字化转型的浪潮中,企业面临着一个普遍的挑战:数据丰富但洞察匮乏。传统的数据存储和管理方式主要基于关系型数据库的行列结构,这种方式在处理结构化数据时表现出色,但面对日益增长的非结构化文本数据时却显得力不从心。
企业的知识资产往往分散在各种文档、报告、邮件和会议记录中,这些宝贵的信息以孤立的形式存在,难以形成系统性的知识网络。
传统的全文搜索虽然能够找到相关文档,但无法揭示概念之间的深层关联关系,更无法支持复杂的推理和决策需求。
知识图谱的核心价值主张
知识图谱通过图结构的数据模型,将实体(节点)和关系(边)有机结合,形成了一个语义丰富的知识网络。
这种表示方式更接近人类的认知模式,能够直观地展现复杂概念之间的关联关系。
与传统数据库相比,知识图谱的优势体现在三个方面:
语义理解能力让系统不仅知道"是什么",还能理解"为什么"和"如何";
关联发现能力能够识别看似无关的概念之间的隐藏联系;
推理扩展能力可以基于已有知识推导出新的见解和结论。
大语言模型带来的技术突破
传统的知识图谱构建需要大量的专业人员进行实体识别、关系抽取和本体设计,整个过程耗时且成本高昂。
现代大语言模型如GPT-4o、Claude、Gemini等强大的自然语言理解和生成能力,使得系统能够自动识别文本中的实体和关系,大幅降低了知识图谱构建的技术门槛。
更重要的是,这些模型不仅能够处理英文文本,还能很好地支持中文等多种语言,为全球化企业的知识管理提供了统一的技术方案。
以GPT-4o为例,其在实体识别准确率方面达到87%,而开源模型如Llama 3和Qwen也能达到80%以上的准确率。
PART 02 技术栈组合与集成方案
核心技术架构
基于大语言模型的知识图谱构建系统,主要包含四个核心组件:文本预处理模块负责文档解析和内容清洗;实体识别模块利用大语言模型识别文本中的关键实体;关系抽取模块分析实体之间的语义关系;图构建模块将抽取的实体和关系转换为图数据库格式。

这种架构设计的优势在于各模块职责清晰,便于维护和扩展。同时,通过标准化的接口设计,系统能够灵活适配不同的数据源和输出格式。
LangChain生态系统集成
LangChain作为连接大语言模型和外部工具的桥梁,在知识图谱构建中发挥着关键作用。通过LangChain的llm-graph-transformer模块,开发者可以轻松地将各种大语言模型(GPT-4o、Claude、Gemini、Llama等)的能力与Neo4j等图数据库集成,实现端到端的自动化处理流程。
LangChain提供了丰富的文档加载器,支持PDF、Word、网页等多种格式的文本输入,同时还提供了灵活的提示词模板机制,允许用户根据特定领域的需求定制实体识别和关系抽取的规则。
Neo4j图数据库的技术优势
Neo4j作为领先的图数据库解决方案,为知识图谱的存储和查询提供了强大的技术支撑。其原生的图存储引擎和Cypher查询语言,能够高效地处理复杂的图遍历和模式匹配操作。
特别值得关注的是Neo4j推出的LLM Knowledge Graph Builder工具,这是一个基于Web的应用程序,能够直接将PDF文档、网页内容甚至YouTube视频转录转换为知识图谱。这个工具的出现大大简化了知识图谱的构建流程,用户无需编写代码就能快速生成高质量的知识图谱。
PART 03 文本到图的转换机制
智能实体识别策略
与传统的基于规则或机器学习的方法不同,大语言模型能够基于上下文语义进行智能识别,不仅能够识别人名、地名、机构名等常见实体,还能识别抽象概念、事件和复杂关系。以GPT-4o为例,其实体识别F1分数达到0.87,而Claude 3.5和Gemini Pro也分别达到0.85和0.83的优秀水平。
在实际应用中,系统采用了分层识别策略:首先识别核心实体(如人物、组织、地点),然后识别属性实体(如技能、特征、状态),最后识别关系实体(如动作、事件、过程)。这种分层方法确保了实体识别的全面性和准确性。
关系抽取的语义建模
关系抽取是知识图谱构建的核心环节,也是最具挑战性的部分。大语言模型能够识别文本中隐含的复杂关系。系统支持多种类型的关系抽取:直接关系指文本中明确表述的关系,如"张三是ABC公司的CEO";间接关系需要通过推理得出,如通过"张三毕业于清华大学"和"李四也毕业于清华大学"推导出"张三和李四是校友关系";时序关系涉及事件的时间顺序和因果关系。
此外,系统还提供了人工审核接口,允许专业人员对自动抽取的结果进行验证和修正,确保最终生成的知识图谱具有足够的可信度。
PART 04 实战指南:从零构建知识图谱系统
项目环境准备
基于开源项目knowledge-graph-llms的完整实现,我们可以快速搭建一个功能完整的知识图谱构建系统。
该项目提供了基于Streamlit(Streamlit 是一个 开源的 Python 框架,能用“纯 Python 脚本”的方式 快速把数据/模型变成可交互的 Web 应用。无需前端知识,即可在几分钟内生成漂亮的仪表盘或 Demo,常用于数据科学、机器学习、AI 原型展示。)的Web界面,支持文件上传和文本输入两种方式。
项目没有直接链接Neo4j,你可以根据后续需要进行修改,包括大语言模型我用的是deepseek,这些都可以调整,重点是思路。
系统要求:
- Python 3.8或更高版本
- OpenAI API密钥
- 至少4GB可用内存
核心依赖包:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
# 安装核心依赖
pip install langchain>=0.1.0
pip install langchain-experimental>=0.0.45
pip install langchain-openai>=0.1.0
pip install python-dotenv>=1.0.0
pip install pyvis>=0.3.2
pip install streamlit>=1.32.0
快速部署实战
第一步:项目克隆与配置
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
# 克隆项目
git clone https://github.com/thu-vu92/knowledge-graph-llms.git
cd knowledge-graph-llms
# 安装依赖
pip install -r requirements.txt
# 配置API密钥
echo "OPENAI_API_KEY=your_openai_api_key_here" > .env
第二步:启动Web应用
ounter(lineounter(line
# 启动Streamlit应用
streamlit run app.py
系统将在浏览器中自动打开,默认地址为 http://localhost:8501。
第三步:使用界面操作
系统提供了直观的Web界面,包含两种输入方式:
- 文件上传模式:支持.txt格式文件,适合处理长文档
- 文本输入模式:直接在文本框中输入内容,适合快速测试
打开前端,输入一段红楼梦人物关系描述文本:
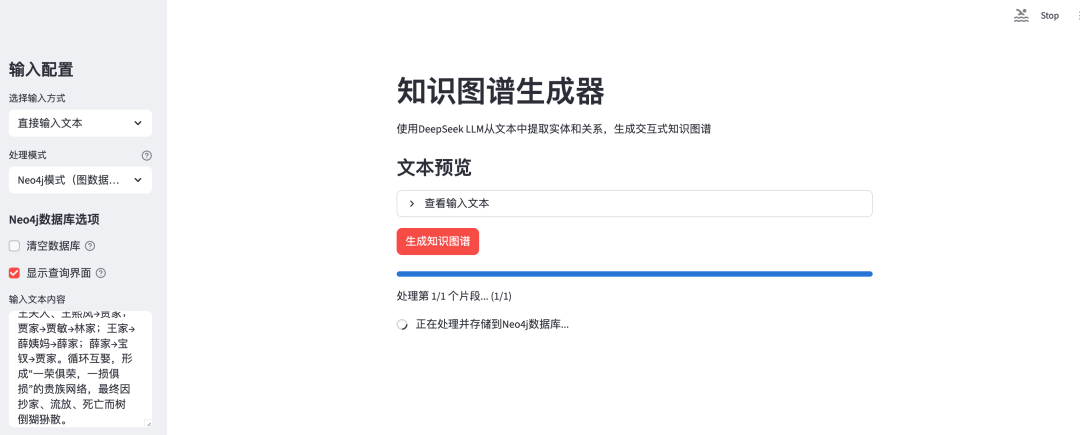
最终的效果:
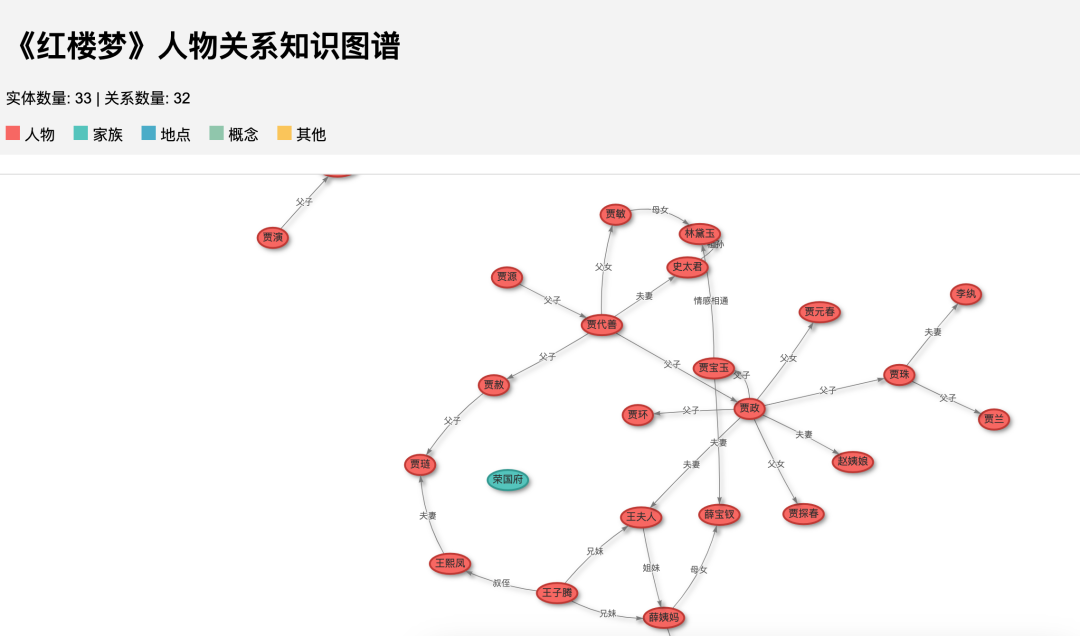
还有很多地方需要改进,不过思路可以借鉴。
核心代码解析
实体关系抽取核心逻辑:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_openai import ChatOpenAI
# 初始化LLM和图转换器
llm = ChatOpenAI(temperature=0, model_name="gpt-4o")
llm_transformer = LLMGraphTransformer(llm=llm)
# 文本转换为图结构
def extract_graph_from_text(text):
# 将文本分割为文档对象
documents = [Document(page_content=text)]
# 提取图数据
graph_documents = llm_transformer.convert_to_graph_documents(documents)
return graph_documents
图可视化生成:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
from pyvis.network import Network
import streamlit.components.v1 as components
def create_knowledge_graph(graph_documents):
# 创建网络图对象
net = Network(height="600px", width="100%",
bgcolor="#222222", font_color="white")
# 添加节点和边
for graph_doc in graph_documents:
# 添加节点
for node in graph_doc.nodes:
net.add_node(node.id, label=node.id,
title=f"Type: {node.type}")
# 添加关系边
for relationship in graph_doc.relationships:
net.add_edge(relationship.source.id,
relationship.target.id,
label=relationship.type)
# 设置物理引擎参数
net.set_options("""
var options = {
"physics": {
"enabled": true,
"stabilization": {"iterations": 100}
}
}
""")
return net
高级功能实现
自定义实体类型:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
# 定义特定领域的实体类型
allowed_nodes = ["Person", "Organization", "Location",
"Technology", "Concept", "Event"]
allowed_relationships = ["WORKS_FOR", "LOCATED_IN",
"USES", "RELATED_TO", "CAUSED_BY"]
llm_transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=allowed_nodes,
allowed_relationships=allowed_relationships
)
批处理优化:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
def process_large_document(text, chunk_size=2000):
# 文档分块处理
chunks = [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]
all_graph_docs = []
for chunk in chunks:
docs = [Document(page_content=chunk)]
graph_docs = llm_transformer.convert_to_graph_documents(docs)
all_graph_docs.extend(graph_docs)
# 合并图数据
return merge_graph_documents(all_graph_docs)
企业级扩展方案
数据库集成:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
from neo4j import GraphDatabase
class Neo4jHandler:
def __init__(self, uri, username, password):
self.driver = GraphDatabase.driver(uri, auth=(username, password))
def save_graph(self, graph_documents):
with self.driver.session() as session:
for graph_doc in graph_documents:
# 创建节点
for node in graph_doc.nodes:
session.run(
"MERGE (n:Entity {id: $id, type: $type})",
id=node.id, type=node.type
)
# 创建关系
for rel in graph_doc.relationships:
session.run(
"MATCH (a:Entity {id: $source}) "
"MATCH (b:Entity {id: $target}) "
"MERGE (a)-[r:RELATIONSHIP {type: $rel_type}]->(b)",
source=rel.source.id,
target=rel.target.id,
rel_type=rel.type
)
API服务封装:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/extract_graph', methods=['POST'])
def extract_graph_api():
try:
text = request.json['text']
graph_docs = extract_graph_from_text(text)
# 转换为JSON格式
result = {
'nodes': [{'id': node.id, 'type': node.type}
for doc in graph_docs for node in doc.nodes],
'edges': [{'source': rel.source.id,
'target': rel.target.id,
'type': rel.type}
for doc in graph_docs for rel in doc.relationships]
}
return jsonify(result)
except Exception as e:
return jsonify({'error': str(e)}), 500
性能优化实战
缓存机制实现:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
import hashlib
import json
import os
class GraphCache:
def __init__(self, cache_dir="./cache"):
self.cache_dir = cache_dir
os.makedirs(cache_dir, exist_ok=True)
def get_cache_key(self, text):
return hashlib.md5(text.encode()).hexdigest()
def get(self, text):
cache_key = self.get_cache_key(text)
cache_file = os.path.join(self.cache_dir, f"{cache_key}.json")
if os.path.exists(cache_file):
with open(cache_file, 'r') as f:
return json.load(f)
return None
def set(self, text, graph_data):
cache_key = self.get_cache_key(text)
cache_file = os.path.join(self.cache_dir, f"{cache_key}.json")
with open(cache_file, 'w') as f:
json.dump(graph_data, f)
这个完整的实战指南基于真实的开源项目,提供了从环境搭建到企业级部署的完整解决方案,希望对你有所启发。
PART 05 替代方案与模型选型
基于前面提到的开源项目架构,我们可以灵活替换不同的大语言模型来实现知识图谱构建。除了GPT-4o之外,多种模型都能提供可靠的实体识别和关系抽取能力。
开源模型集成实战
Llama 3集成示例:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
from langchain_community.llms import Ollama
from langchain_experimental.graph_transformers import LLMGraphTransformer
# 使用本地部署的Llama 3
llm = Ollama(model="llama3:8b")
llm_transformer = LLMGraphTransformer(llm=llm)
# 针对开源模型优化的提示词
llama_prompt = """
Extract entities and relationships from the following text.
Focus on:
- Entities: Person, Organization, Location, Concept, Event
- Relationships: works_for, located_in, uses, related_to, caused_by
Text: {text}
Output format:
Entities: [entity_name (entity_type)]
Relationships: [source_entity -> relationship_type -> target_entity]
"""
Qwen模型配置:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 加载Qwen模型
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat")
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-7B-Chat",
torch_dtype=torch.float16,
device_map="auto"
)
class QwenLLM:
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer
def generate(self, prompt, max_length=2048):
inputs = self.tokenizer(prompt, return_tensors="pt")
outputs = self.model.generate(
inputs.input_ids,
max_length=max_length,
temperature=0.3,
do_sample=True
)
return self.tokenizer.decode(outputs[0], skip_special_tokens=True)
模型切换实现
统一接口设计:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
from abc import ABC, abstractmethod
class LLMInterface(ABC):
@abstractmethod
def extract_entities_relationships(self, text: str) -> dict:
pass
class GPT4oExtractor(LLMInterface):
def __init__(self, api_key):
self.llm = ChatOpenAI(
model="gpt-4o",
openai_api_key=api_key,
temperature=0
)
self.transformer = LLMGraphTransformer(llm=self.llm)
def extract_entities_relationships(self, text: str) -> dict:
docs = [Document(page_content=text)]
graph_docs = self.transformer.convert_to_graph_documents(docs)
return self._format_output(graph_docs)
class LlamaExtractor(LLMInterface):
def __init__(self, model_path):
self.llm = Ollama(model=model_path)
self.transformer = LLMGraphTransformer(llm=self.llm)
def extract_entities_relationships(self, text: str) -> dict:
# 类似实现
pass
# 工厂模式选择模型
def create_extractor(model_type: str, **kwargs) -> LLMInterface:
if model_type == "gpt4o":
return GPT4oExtractor(kwargs['api_key'])
elif model_type == "llama":
return LlamaExtractor(kwargs['model_path'])
else:
raise ValueError(f"Unsupported model type: {model_type}")
领域特化优化
医疗领域示例:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
medical_entities = [
"Disease", "Symptom", "Treatment", "Drug",
"Anatomy", "Test", "Patient", "Doctor"
]
medical_relationships = [
"TREATS", "CAUSES", "DIAGNOSED_WITH",
"PRESCRIBED", "LOCATED_IN", "PERFORMED_BY"
]
medical_prompt = """
从医疗文本中提取以下类型的实体和关系:
实体类型:
- Disease(疾病)
- Symptom(症状)
- Treatment(治疗方法)
- Drug(药物)
- Anatomy(解剖结构)
关系类型:
- TREATS(治疗)
- CAUSES(导致)
- DIAGNOSED_WITH(诊断为)
请严格按照上述类型进行抽取。
"""
medical_transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=medical_entities,
allowed_relationships=medical_relationships,
prompt=medical_prompt
)
结论
实施建议与最佳实践
对于计划实施知识图谱项目的企业,建议采用渐进式的实施策略。首先选择一个相对简单的应用场景进行试点,验证技术可行性和业务价值;然后逐步扩展到更复杂的场景,积累经验和能力;最后形成企业级的知识图谱平台,支持多个业务领域的应用需求。
技术选型时应该综合考虑性能、成本、安全性等多个因素,避免过度追求技术先进性而忽视实际需求。同时,要重视数据质量管理和用户体验设计,确保系统的实用性和可用性。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐
 24
24 0
0- 0



 已为社区贡献200条内容
已为社区贡献200条内容

所有评论(0)