
YOLOv8【卷积创新篇·第22节】Neural Architecture Search卷积搜索!
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。 ✨ 特惠福利
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》,该专栏持续复现网络上各种热门内容(全网YOLO改进最全最新的专栏,质量分97分+,全网顶流),改进内容支持(分类、检测、分割、追踪、关键点、OBB检测)。且专栏会随订阅人数上升而涨价(毕竟不断更新),当前性价比极高,有一定的参考&学习价值,部分内容会基于现有的国内外顶尖人工智能AIGC等AI大模型技术总结改进而来,嘎嘎硬核。
✨ 特惠福利:目前活动一折秒杀价!一次订阅,永久免费,所有后续更新内容均免费阅读!
全文目录:
-
- 🌟 摘要
- 📜 上期回顾:Meta Learning元学习卷积设计
- 🎯 核心思想:当AI成为架构师
- 🚀 主流搜索算法深度剖析
- 🛠️ YOLOv8实战:用NAS思想搜索自定义C2f模块理论知识已经储备完毕,现在是时候卷起袖子,亲手实践了!
- 📈 结果分析与未来展望
- 📝 全文总结
- 🔮 下期预告:Transformer与卷积混合架构
- 🧧🧧 文末福利,等你来拿!🧧🧧
- 🫵 Who am I?
🌟 摘要
大家好!欢迎回到我们的《YOLOv8专栏》!在本节中,我们将探讨一个革命性的领域——神经架构搜索(Neural Architecture Search, NAS)。如果说我们之前介绍的各种卷积模块是对神经网络“组件”的创新,那么NAS就是“组件”的自动化、智能化设计与组装。它赋予了AI自我进化的能力,能够根据特定任务和硬件约束,自动搜索出最优的网络结构。本文将从NAS的核心思想、关键组件入手,深入剖析主流的搜索算法,并最终带你一步步实践,如何在YOLOv8的框架下,利用NAS思想来搜索一个自定义的高效卷积模块。准备好让AI为你“打工”,设计更强的YOLOv8了吗?让我们一起进入这个充满无限可能的AI设计新纪元!🌟
📜 上期回顾:Meta Learning元学习卷积设计
小伙伴们,我们又见面啦!👋 在上一节 《YOLOv8【卷积创新篇·第21节】Meta Learning元学习卷积设计》 中,我们一起探索了“元学习”这个神奇的领域。我们了解到,元学习旨在让模型“学会如何学习”,通过设计能够快速适应新任务的卷积结构,使得模型在面对小样本甚至零样本(Few-shot/Zero-shot)的检测任务时,依然能保持出色的性能。
我们探讨了元学习如何通过动态生成任务特定的卷积核,或者快速调整模型参数,来实现对新数据分布的迅速适应。这种能力对于现实世界中不断变化的检测场景至关重要。希望上一节的内容,已经让你对模型的“适应性”和“泛化能力”有了更深的理解!🧠
而今天,我们将把“自动化”这个理念推向一个全新的高度。如果说元学习是让模型学会“适应”,那么神经架构搜索(NAS)就是让AI学会“创造”!我们将赋予算法设计网络结构的能力,这不仅仅是参数的调整,而是对模型骨架本身的探索和重塑。准备好迎接这场颠覆性的架构设计革命了吗?🚀
🎯 核心思想:当AI成为架构师
1.1 为什么需要神经架构搜索(NAS)?
在深度学习的黄金时代,我们见证了无数经典网络结构的诞生,从AlexNet到VGG,从ResNet到DenseNet,再到我们熟悉的YOLO系列。这些卓越的架构,无一不是由顶尖的研究者们凭借深厚的专业知识、敏锐的直觉和大量的实验“手工”设计出来的。这个过程耗时、耗力,且高度依赖人类专家的经验。
我们不禁会问:
- 人类设计的架构就是最优的吗? 对于特定任务,是否存在比现有结构更高效、更精准的设计?
- 设计过程能否自动化? 能否让机器代替我们,去完成这项繁琐但极具创造性的工作?
- 能否定硬件(如移动设备、边缘计算平台)量身定制最高效的架构?
这些问题的答案,都指向了一个共同的方向——神经架构(Neural Architecture Search, NAS)。
NAS的核心思想,就是将网络架构的设计本身看作一个可以被优化的“搜索问题”。我们不再满足于手动调整超参数,而是定义一个巨大的、包含所有可能网络结构的“搜索空间”,然后利用一套系统性的“搜索策略”,自动地从中寻找能够达到最佳性能的架构。简而言之,NAS就是用AI来设计AI。
1.2 NAS的“三位一体”:核心组件剖析
一个完整的NAS算法框架,通常由三个核心组件构成:空间(Search Space)、搜索策略(Search Strategy) 和 性能评估策略(Performance Estimation Strategy)。我们可以用一个生动的比喻来理解它们:
- 搜索空间:就像一个巨大无比的乐高积木池,里面有各种形状、各种功能的积木块(卷积、池化、激活函数等)。我们的任务就是从里面挑选积木并搭建模型。
- 搜索策略:就像一位聪明的建筑师,他知道如何从积木池中挑选积木、如何将它们组合起来,才能搭建出既稳固又美观的建筑。
- 性能评估策略:就像一位严谨的质检员,他负责快速评估建筑师搭建出的每一个“样品”的好坏(即模型的性能),并把结果反馈给建筑师,以便他做出更好的设计。
下面,让我们用流程图来直观地展示这个流程:
现在,我们来详细解读这“三位一体”:
🔍 搜索空间(Search Space)
搜索空间定义了NAS算法可以探索的架构范围,它决定了我们可能找到的架构的上限。一个好的搜索空间应该足够大,以包含最优解,但又不能过大,否则搜索难度会急剧增加。
- 宏索(Macro Search):对整个网络的主体结构进行搜索,例如VGG或ResNet的整体链式结构。这种方式自由度高,但搜索空间巨大,计算成本极高。
- 微观/单元搜索(Micro/Cell-based Search):这是目前更主流的方式。研究者们先手动设计一个网络的整体“骨架”(Macro-architecture),例如将网络分为多个堆叠的“单元”(Cell)。然后,NAS算法只负责搜索这些可重用单元的内部结构。例如,搜索一个最佳的卷积单元(Normal Cell)和一个最佳的下采样单元(Reduction Cell),然后用这些单元像搭积木一样构建整个网络。这样做极大地减小了搜索空间,并且搜索出的单元具有很好的泛化性。
对于YOLOv8,我们的搜索空间可以定义在卷积块的层面。例如,我们可以定义一个包含不同卷积核大小(3x3, 5x5)、空洞卷积、分组卷积、以及注意力模块等操作的集合,让NAS去寻找这些操作的最佳组合方式,以替代原有的C2f模块或主干网络中的某个卷积块。
🧠 搜索策略(Search Strategy)
搜索策略是NAS的“大脑”,它指导如何在巨大的搜索空间中高效地找到最优架构。主流的搜索策略可以分为三类:
- 强化学习 (Reinforcement Learning, RL):将架构的生成过程建模为一个智能体(Agent)的决策过程。Agent每做一步决策(如选择一个卷积操作或连接),就相当于构建了一部分网络。当整个网络构建完成后,将其性能作为“奖励”(Reward)反馈给Agent,通过不断试错来学习如何做出更好的决策。
- 进化 (Evolutionary Algorithms, EA):借鉴生物界的“优胜劣汰”法则。它会维护一个种群(Population),每个个体代表一个网络架构。在每一代中,算法会根据性能选择优秀的个体进行“交叉”(Crossover)和“变异”(Mutation),生成新的后代,并淘汰性能差的个体。如此循环往复,最终种群会收敛到高性能的架构区域。
- 基于梯度的优化Gradient-based Optimization):这是近年来极具影响力的方法,以**DARTS (Differentiable Architecture Search)** 为代表。它巧妙地将离散的架构选择问题“松弛”为一个连续的优化问题,从而可以直接使用梯度下降法来同时优化网络权重和架构参数,极大地提升了搜索效率。我们将在后文重点讲解这种方法。
📊 性能评估策略(Performance Estimation Strategy)
这是NAS中最耗时的环节。最直接的方法是,每当搜索策略生成一个新架构,我们就从头开始完整地训练它,直到收敛,然后评估其在验证集上的性能。这种方法虽然准确,但计算成本高到无法承受。想象一下,在一个包含数百万可能架构的空间里,完整训练每一个架构是不现实的。
为了解决这个问题,研究者们提出了多种高效的评估策略:
- 权重 (Weight Sharing) / One-Shot模型 :这是目前最核心、最流行的思想。我们不再为每个子架构单独训练权重,而是构建一个包含所有可能操作和连接的“超网络”(Supernet)。所有子架构都是这个超网络的不同子图,它们共享超网络的权重。在搜索过程中,我们只需要训练这个超网络一次。评估某个子架构的性能时,直接继承超网络中对应的权重即可,无需从头训练。这使得搜索时间从数千GPU天缩短到了几天甚至几小时。
- 代理模型 (Surrogate Models):训练一个模型(如高斯过程、神经网络)来预测一个架构的性能,而不是直接训练它。
- 低保真度评估 (Lower Fidelity Estimates):通过一些简化手段来加速评估,例如在更小的数据集上训练、减少训练轮数、或者使用降采样的数据。
理解了这三个核心组件,我们就掌握了解读和设计NAS算法的钥匙。接下来,让我们深入了解一下具体的算法实现。
🚀 主流搜索算法深度剖析
2.1 基于强化学习(RL)的策略
最早期的NAS工作(如Google的NASNet)就是基于强化学习的。它们使用一个循环神经网络(RNN)作为控制器(Controller),来生成描述网络架构的字符串。
-
工作流程:
- RNN控制器生成一个代表架构的动作序列(例如,“3x3 conv”, “add”, “5x5 sep_conv”…)。
- 根据这个序列构建一个子网络(Child Network)。
- 在目标任务上训练这个子网络,直到收敛。
- 将子网络在验证集上的准确率作为奖励信号(Reward)。
- 使用这个奖励信号,通过策略梯度等方法来更新RNN控制器的参数,使其在未来来能生成更好的架构。
-
优点:非常灵活,可以探索极其复杂的搜索空间。
-
缺点:搜索效率极低。因为将每个子网络的训练过程视为黑盒,需要对成千上万个架构进行独立训练,计算成本巨大。
2.2 基于进化算法(EA)的策略
进化算法提供了一种不同于RL的搜索范式,它模拟了生物进化的过程。
-
工作流程:
- 初始化:随机生成一个包含N个不同架构的初始种群。
- 评估:训练种群中的每个架构,并评估其适应度(Fitness,通常是验证集准确率)。
- 选择:根据适应度,选择优秀的架构作为“父代”。
- 繁殖:对父代进行交叉(将两个架构的某部分进行交换)和变异(随机改变架构的某个操作或连接)来产生新的“子代”。
- 循环:用新的子代替换种群中适应度较低的个体,然后回到第第2步。
-
优点:全局搜索能力强,不容易陷入局部最优。
-
缺点:与RL类似,如果每个个体都需要完整训练,效率依然很低。不过,进化算法可以和权重共享等策略结合来提速。
2.3 基于梯度的策略:DARTS详解
DARTS(Differentiable Architecture Search)的出现,是NAS领域的一个里程碑。它将搜索效率提升了好几个数量级,使得在单个GPU上进行一两天的搜索成为可能。这也是我们后续实战将要借鉴的核心思想。💡
2.3.1 核心思想:将离散问题连续化
DARTS的精髓在于“可微”。传统的架构搜索,选择操作(比如是从3x3卷积、5x5卷积还是最大池化中选一个)是一个离散的决策。离散决策是无法直接通过梯度下降来优化的。
DARTS的解决方案是连续松弛(Continuous Relaxation)。它不直接做出“硬”选择,而是计算所有候选操作的加权和。
假设对于一个节点,我们有 K K K 个候选操作(记为 o 1 , o 2 , . . . , o K o_1, o_2, ..., o_K o1,o2,...,oK)。DARTS为每个操作分配一个权重 α i \alpha_i αi。那么,这个节点的输出 y y y 不再是某一个操作的输出,而是所有操作输出的“软”混合:
y = ∑ i = 1 K exp ( α i ) ∑ j = 1 K exp ( α j ) ⋅ o i ( x ) y = \sum_{i=1}^{K} \frac{\exp(\alpha_i)}{\sum_{j=1}^{K} \exp(\alpha_j)} \cdot o_i(x) y=i=1∑K∑j=1Kexp(αj)exp(αi)⋅oi(x)
这里的 x x x 是输入。我们使用了 Softmax 函数来确保所有操作的权重之和为1。这些 α \alpha α 被称为架构参数。
现在,架构的选择问题就从“选择哪个操作?”转变成了“每个操作的权重 α i \alpha_i αi 应该是多少?”。由于 α \alpha α 是连续的变量,我们可以像优化网络权重 w w w 一样,用梯度下降来优化它们!
当搜索过程结束时,我们不再使用这个“混合”操作。而是通过“解码”来得到最终的离散架构:对于每个节点,我们只保留那个 α i \alpha_i αi 值最大的操作,即所谓的“赢者通吃”(Winner-takes-all)。
2.3.2 超网络(Supernet)与权重共享
DARTS的整个搜索过程是在一个被称为超网络(Supernet)或One-Shot Model上进行的。这个超网络非常庞大,它包含了搜索空间中定义的所有可能的候选操作和连接。
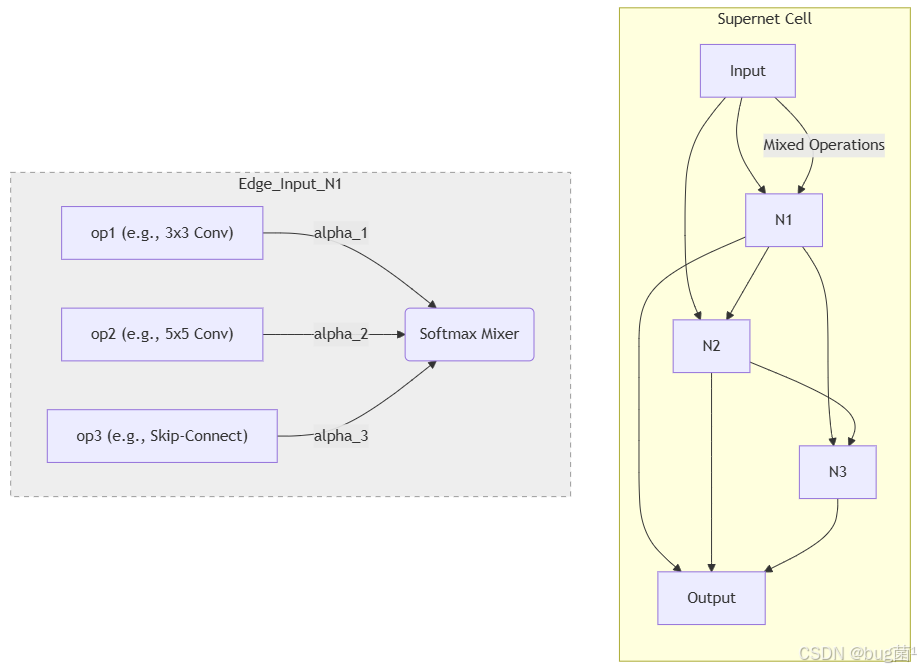
- 上图示意:一个单元(Cell)由多个节点(Node)组成。节点之间的每条边(Edge)都代表一个混合操作(Mixed Operation)。这个混合操作由多个候选操作(op1, op2, …)根据架构参数 α \alpha α 加权混合而成。
- 权重共享:所有这些操作(如3x3卷积、5x5卷积)的权重 w w w 在整个超网络中是共享的。我们不需要为每个可能的子架构单独存储和训练权重。
2.3.3 双层优化(Bi-level Optimization)
现在我们有两个需要优化的东西:网络的权重 w w w 和架构参数 α \alpha α。DARTS创造性地提出了一个双层优化问题:
- 内层优化(Inner Optimization):给定当前的架构参数 α \alpha α,我们希望找到最优的网络权重 w ∗ ( α ) w^*(\alpha) w∗(α),使得训练集上的损失 L t r a i n L_{train} Ltrain 最小。
w ∗ ( α ) = arg min w L train ( α ) w^*(\alpha) = \arg\min_w L_{\text{train}}(\alpha) w∗(α)=argwminLtrain(α)
- 外层优化(Outer Optimization):我们希望找到最优的 架构参数 α ∗ \alpha^* α∗,使得当 网络权重 为内层最优解 w ∗ ( α ) w^*(\alpha) w∗(α) 时,验证集上的损失 L val L_{\text{val}} Lval 最小:
α ∗ = arg min α L val ( w ∗ ( α ) , α ) \alpha^* = \arg\min_{\alpha} L_{\text{val}}\big(w^*(\alpha), \alpha\big) α∗=argαminLval(w∗(α),α)
为什么是双层优化?
这个设计非常精妙。它模拟了我们手动设计网络的最终目标:我们希望找到一个架构,当它被充分训练后,在未见过的数据上表现最好。
- 在训练集上更新权重 w w w,模拟了“充分训练”的过程。
- 在验证集上更新架构 α \alpha α,模拟了评估其在“未见过数据”上的表现。
具体实现:
由于每次都完全求解内层优化(即把 w w w 训练到最优)是不现实的,DARTS采用了一种近似算法:在每一步中,交替进行:
- 用当前的 α \alpha α,在训练集上通过梯度下降更新一次 w w w。
- 用更新后的 w w w,在验证集上计算计算损失,然后通过梯度下降更新一次 α \alpha α。
这个过程不断迭代,使得网络权重和架构参数协同进化,最终找到一个在验证集上表现优异的架构。
🛠️ YOLOv8实战:用NAS思想搜索自定义C2f模块理论知识已经储备完毕,现在是时候卷起袖子,亲手实践了!
🎉 我们的目标是应用DARTS的核心思想,为YOLOv8搜索一个新的、可能更高效的C2f模块。
免责声明:完整的NAS搜索过程需要巨大的计算资源和复杂的代码库。这里的实战将是一个简化版、概念验证性的实现,旨在帮助你理解核心流程和代码逻辑。但麻雀虽小,五脏俱全,它将包含NAS的所有关键步骤!
3.1 我们的目标:定义一个“可进化”的C2f
YOLOv8中的C2f模块是其性能的关键。它由几个Bottleneck块和一个split操作组成。我们将改造C2f中的Bottleneck部分,使其成为一个可搜索的块earchableBlock)。在这个块内部,我们将定义一系列候选的卷积操作,让NAS算法来决定使用哪个操作,或者如何组合它们。
3.2 步骤一:定义搜索空间(Search Space)
3.2.1 候选操作集(Candidate Operations)
首先,我们需要定义一些“积木块”,即们的候选操作。为了简单起见,我们定义以下几种操作:
Identity(跳跃连接)Conv3x3(标准的3x3卷积)Conv 5x5(5x5卷积,提供更大感受野)Dilated Conv 3x3(3x3空洞卷积,扩大感受野但不增加参数)SepConv3x3(3x3深度可分离卷积,轻量化)
3.2.2 SearchableBlock 代码实现
现在,我们来实现这个可搜索的块。它将包含上述所有操作,并使用架构参数 α \alpha α 来混合它们的输出。
# 该代码片段应放在YOLOv8项目中的某个模块文件里,例如 ultralytics/nn/modules/conv.py
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一些基础的卷积操作模块,确保它们有相同的输入输出通道和步长
# The following modules are simplified for clarity.
# In a real scenario, you need to handle stride, padding, and normalization carefully.
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
class SepConv(nn.Module):
"""深度可分离卷积"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, affine=True):
super(SepConv, self).__init__()
self.op = nn.Sequential(
nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
nn.ReLU(inplace=False)
)
def forward(self, x):
return self.op(x)
class DilConv(nn.Module):
"""空洞卷积"""
def __init__(self, C_in, C_out, kernel_size, stride, padding, dilation, affine=True):
super(DilConv, self).__init__()
self.op = nn.Sequential(
nn.Conv2d(C_in, C_in, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=C_in, bias=False),
nn.Conv2d(C_in, C_out, kernel_size=1, padding=0, bias=False),
nn.BatchNorm2d(C_out, affine=affine),
nn.ReLU(inplace=False),
)
def forward(self, x):
return self.op(x)
# 候选操作字典
OPS = {
'none': lambda C, stride, affine: Identity(), # 'none'通常也用作一个选项,这里简化为Identity
'sep_conv_3x3': lambda C, stride, affine: SepConv(C, C, 3, stride, 1, affine=affine),
'sep_conv_5x5': lambda C, stride, affine: SepConv(C, C, 5, stride, 2, affine=affine),
'dil_conv_3x3': lambda C, stride, affine: DilConv(C, C, 3, stride, 2, 2, affine=affine),
'conv_3x3': lambda C, stride, affine: nn.Sequential(
nn.Conv2d(C, C, 3, stride, 1, bias=False),
nn.BatchNorm2d(C, affine=affine),
nn.ReLU(inplace=False)
),
}
class MixedOp(nn.Module):
"""混合操作模块,根据架构参数alphas对所有操作进行加权求和"""
def __init__(self, C, stride):
super(MixedOp, self).__init__()
self._ops = nn.ModuleList()
# 将所有候选操作添加到ModuleList中
for primitive in OPS:
op = OPS[primitive](C, stride, False)
self._ops.append(op)
def forward(self, x, weights):
# weights 就是架构参数alphas经过softmax后的结果
# 使用加权求和的方式混合所有操作的输出
# weights的形状是 [num_operations]
# x的形状是 [batch, C, H, W]
# op(x)的形状也是 [batch, C, H, W]
# 我们需要将weights广播,使其能与op(x)相乘
# (weights.view(-1, 1, 1, 1) * op(x) for op, weights in zip(...)
# 这是一个更高效的写法
return sum(w * op(x) for w, op in zip(weights, self._ops))
class SearchableBlock(nn.Module):
"""可搜索的基本块,我们用它来替代C2f中的Bottleneck"""
def __init__(self, C):
super(SearchableBlock, self).__init__()
self.mixed_op = MixedOp(C, stride=1) # 步长为1,不改变特征图尺寸
def forward(self, x, weights):
# weights 是传递进来的该块对应的架构参数
return self.mixed_op(x, weights)
3.2.3 代码解析
-
OPS字典:我们定义了一个全局字典OPS,存储了所有候选操作的构造函数。这样做使得添加或删除候选操作变得非常方便。 -
MixedOp类 (核心):这是实现DARTS连续松弛的关键。- 它在初始化时,创建了
OPS中定义的所有操作模块,并存放在nn.ModuleList中。 - 其
forward方法接收两个参数:输入特征x和该混合操作对应的架构权重weights(即alphas经过softmax后的结果)。 - 它遍历所有操作,计算各自的输出,然后用
weights进行加权求和,sum(w * op(x) ...)。这就是“软”选择的实现。
- 它在初始化时,创建了
-
SearchableBlock类:这是一个简单的包装,我们可以在YOLOv8的模型定义中用它来替换原来的Bottleneck。它内部只包含一个MixedOp实例。在forward时,它会将架构权重传递给MixedOp。
3. 步骤二:构建YOLOv8超网络(Supernet)
现在我们需要将SearchableBlock集成到YOLOv8的模型定义中。我们将修改原有的C2f模块,使其内部使用我们定义的SearchableBlock。
3.3.1 集成SearchableBlock到模型中
假设我们创建一个新的模块叫`C2f_Search
# 该代码片段应放在YOLOv8项目中的某个模块文件里,例如 ultralytics/nn/modules/block.py
# 需要引入上面定义的 SearchableBlock
# from .conv import SearchableBlock, OPS # 假设你把SearchableBlock放到了conv.py里
class C2f_Search(nn.Module):
"""一个可搜索的C2f模块"""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = nn.Conv2d(c1, 2 * self.c, 1, 1)
self.cv2 = nn.Conv2d((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
# 关键改动:使用 n 个 SearchableBlock 替换原来的 Bottleneck
self.m = nn.ModuleList(SearchableBlock(self.c) for _ in range(n))
# 初始化架构参数 alphas
num_ops = len(OPS)
# 每个可搜索块都有自己的一套 alphas
# self.alphas 的形状将是 [n, num_ops]
self.alphas = nn.Parameter(1e-3 * torch.randn(n, num_ops))
def forward(self, x):
# 前向传播时,需要将alphas进行softmax转换成权重
weights = F.softmax(self.alphas, dim=-1)
y = list(self.cv1(x).split((self.c, self.c), 1))
# 将每个 SearchableBlock 的输出与 weights 结合
# y.extend(m(y[-1], w) for m, w in zip(self.m, weights)) # 这行代码有问题,因为weights没有分块
# 正确的逻辑是,每个block m 使用自己对应的权重 w
for i, m in enumerate(self.m):
# 将 y[-[-1] 作为输入,传入第 i 个块 m,并使用第 i 组权重 weights[i]
y.append(m(y1], weights[i]))
return self.cv2(torch.cat(y, 1))
# 你可能还需要添加一个方法来获取架构参数,以便优化器可以访问到它们
def arch_parameters(self):
return [self.alphas]
3.3.2 代码解析
-
C2f_Search我们创建了一个新的模块C2f_Search,它在结构上与原始C2f`相似。 -
替换
Bottleneck:最核心的改动是,我们将self.m = nn.ModuleList(Bottleneck(...) for _ in range(n))替换为了self.m = nn.ModuleList(SearchableBlock(self.c) for _ in range(n))。 -
定义架构参数
alphas:我们在__init__中定义了一个nn.Parameter类型的self.alphas。这是一个可训练的张量,它的梯度会在反向传播中被计算。它的维度是[n, num_ops],其中n是SearchableBlock的数量,num_ops是候选操作的数量。这意味着每个SearchableBlock都有一套自己独立的架构参数,可以独立地学习选择哪个操作。 -
forward中的改动:- 在
forward函数中,我们首先对self.alphas在最后一个维度上应用softmax,将其转换为概率分布(即混合权重)。 - 在循环中,我们将每个
SearchableBlock实例m与其对应的权重weights[i]配对,然后执行前向传播。
- 在
-
arch_parameters方法:我们提供了一个辅助方法,用于方便地获取所有的架构参数。这在设置优化器时非常有用。
现在们只需要在YOLOv8的.yaml配置文件或模型构建代码中,将原来的C2f替换为C2f_arch,我们的超网络就构建完成了!
3.4 步骤三:实现搜索策略与与训练
这是实现双层优化的环节。我们需要一个特殊的“架构师”(Architect)类来管理架构参数的更新,并修改训练循环。
3.4.1 架构参数(Alphas)管理
我们可以创建一个简单的类来处理架构参数的更新。
# 这个类可以放在你的主训练脚本中
import torch
class Architect:
def __init__(self, model, args):
self.network_momentum = args.momentum # 训练网络权重的优化器动量
self.network_weight_decay = args.weight_decay # 训练网络权重的优化器权重衰减
self.model = model
# 创建一个专门用于更新架构参数的优化器
self.optimizer = torch.optim.Adam(self.model.arch_parameters(),
lr=args.arch_learning_rate,
betas=(0.5, 0.999),
weight_decay=args.arch_weight_decay)
def step(self, input_train, target_train, input_valid, target_valid, eta, network_optimizer):
"""
执行一步双层优化
注意:这是一个概念性的实现,实际的DARTS实现会更复杂,
它会使用二阶近似或似或一阶近似来计算架构梯度,这里我们用一个简化的交替优化。
"""
# 简单交替优化:
#. 更新网络权重 w (在训练集上)
# 这步在主训练循环中完成,这里假设已经完成
# loss_train = self.model(input_train, ...)
# loss_train.backward()
# network_optimizer.step()
# 2. 更新架构参数 a (在验证集上)
self.optimizer.zero_grad() # 清空架构优化器的梯度
# 在验证集上计算损失
loss_val = self.model.loss(input_valid, target_valid)
loss_val.backward() # 计算架构参数的梯度
self.optimizer.step() # 更新架构参数
3.4.2 修改训练逻辑(简易版)
你的主训练循环(例如在ultralytics/engine/trainer.py中)需要被修改,以容纳这种交替优化。
# 这是一个伪代码,展示了训练循环的核心思想
# 假设 model 是你的超网络实例
# 1. 创建两个优化器
# 优化器 A: 用于更新网络权重 w (例如 SGD)
optimizer_w = torch.optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
# 优化器 B: 用于更新架构参数 a (例如 Adam),通过 Architect 类管理
architect = Architect(model, args)
# 2. 训练循环
for epoch in range(num_epochs):
for i, (data_train, data_valid) in enumerate(zip(train_loader, valid_loader)):
# ----- 步骤 A: 更新网络权重 w (在训练数据上) -----
model.train()
optimizer_w.zero_grad()
# 正常的前向和反向传播
images_train, targets_train = data_train
loss_train = model.loss(images_train, targets_train)
loss_train.backward()
optimizer_w.step()
# ------- 步骤 B: 更新架构参数 a (在验证数据上) -----
model.eval() # 切换到评估模式可能有助于稳定
#rchitect.step 会处理架构参数的更新
images_valid, targets_valid = data_valid
architect.step(images_train, targetsts_train, images_valid, targets_valid, ...)
# ... 日志记录等 ...
3.4.3 代码解析
-
两个优化器:我们现在需要两个优化器。一个(如SGD)用于常规的网络权重 w w w,它只优化
model.parameters()。另一个(如Adam)专门用于架构参数 α \alpha α,它只优化model.arch_parameters()。 -
Architect类:这个类封装了更新架构参数的逻辑。在最简单的版本中,它的step方法就是在验证集上计算损失,然后调用架构优化器进行反向传播和更新。这实现了双层优化的外层循环。 -
交替训练:在训练循环的每一步,我们从训练数据加载器和验证数据加载器中各取一个批次的数据。
- 首先,使用训练数据批次来执行常规的网络权重更新(前向传播 -> 计算损失 -> 反向传播 ->
optimizer_w.step())。 - 然后,使用验证数据批次来执行架构参数的更新,这一步由
architect.step()完成。
- 首先,使用训练数据批次来执行常规的网络权重更新(前向传播 -> 计算损失 -> 反向传播 ->
这个过程持续进行,alphas会逐渐学习到在验证集上表现最好的操作组合。
3.5 步骤四:解码最终架构与再训练
当搜索过程结束后(例如,训练了50个epoch),self.alphas参数中就存储了学到的架构信息。现在我们需要从中提取出一个固定的、离散的最佳架构。
3.5.1 解码(Decoding)过程
解码过程非常直观:对于每个SearchableBlock,我们查看它对应的alphas向量,选择其中值最大的那个操作作为最终选择。这就是“Winner-takes-all”。
例如,如果对于第一个SearchbleBlock,其alphas值为[-0.2, 1.5, 0.8, -0.9, 11],分别对应我们定义的5个操作。其中1.5是最大的,对应第二个操作(sep_conv_3x3)。那么在这个位置,我们就最终确定使用sep_conv_3x3。
3.5.2 parse_architecture 函数实现
我们可以在C2f_Search模块中添加一个方法来执行这个解码过程。
# 在 C2f_Search 类中添加此方法
def parse_architecture(self):
"""根据学习到的alphas解码出最终的架构"""
gene = []
# self.alphas 的形状是 [n, num_ops]
# 我们在 num_ops 维度上取 argmax
best_op_indices = torch.argmax(self.alphas, dim=-1) # 结果形状是 [n]
op_names = list(OPS.keys())
for op_index in best_op_indices:
gene.append(op_names[op_index])
print("解码出的架构:")
for i, op_name in enumerate(gene):
print(f"Block {i}: {op_name}")
return gene
在搜索训练结束后,调用model.moduleparse_architecture()(如果你使用了DataParallel等)就可以打印出搜索到的最佳操作组合。
3.5.3 再训练(Retraining)的重要性
这是至关重要的一步! 搜索阶段得到的模型(超网络)性能通常并不高,因为它包含了大量的冗余操作和参数,并且其权重是为了优化整个“混合体”而学习的。
解码出最终的离散架构后,你需要:
- 构建新模型:根据解码出的
gene(例如['sep_conv_3x3', 'conv3', 'identity', ...]),构建一个全新的、固定的、没有任何多余参数的网络。 - 从头训练:像训练普通YOLOv8模型一样,在这个新的、轻量级的、搜索出的架构上,从头开始进行完整的训练。
只有经过经过了这一步,你才能得到这个搜索出架构的真实性能。最终的性能往往会比搜索过程中的超网络性能高得多。
📈 结果分析与未来展望
4.1 NAS的挑战与机遇
尽管NAS非常强大,但它也面临一些挑战:
- 计算资源:虽然DARTS等方法大大降低了成本,但NAS仍然是计算密集型的。
- 稳定性:基于梯度的NAS有时会不稳定,例如,可能会过度偏爱跳跃连接(Skip-Connect),导致最终架构性能不佳。后续有很多工作(如PC-DARTS, SGAS)在努力解决这个问题。
- 搜索空间的设计:搜索空间的质量直接决定了最终结果的好坏,而这部分仍然需要人类专家来精心设计。
4.2 硬件感知(Hardware-Aware)NAS
NAS的一个巨大优势是,它可以针对特定硬件进行优化。我们可以将模型的延迟(Latency)、功耗(Power Consumption) 或 模型大小(Size) 也纳入优化目标。
例如,在性能评估时,我们不仅考虑准确率,还考虑模型在目标硬件(如某款手机的CPU/GPU)上的运行时间。优化目标可以变成一个多目标函数,如 A c c u r a c y − λ ⋅ L a t e n c y Accuracy - \lambda \cdot Latency Accuracy−λ⋅Latency。这样,NAS就能自动在速度和精度之间做出权衡,搜索出在该硬件上“性价比”最高的模型。
4.3 NAS在YOLOv8中的更多可能性
我们今天只探索了在C2f中搜索卷积操作,但NAS的应用远不止于此:
- 搜索整个主干网络:可以定义一套更复杂的搜索空间,让NAS决定整个Backbone的层数、每层的通道数和连接方式。
- 搜索Neck部分:FPN、PAN等结构中的特征融合方式也可以通过NAS来自动设计。
- 搜索激活函数:甚至可以将不同的激活函数(ReLU, SiLU, GeLU等)也加入搜索空间。
NAS为YOLOv8的持续进化提供了一个充满想象力的自动化工具箱。
📝 全文总结
恭喜你!坚持看到了这里!你已经完成了一次穿越神经架构搜索世界的深度旅行。👍
在本节中,我们从NAS的基本理念出发,详细拆解了其三大核心组件:搜索空间、搜索策略和性能评估策略。我们深入探讨了以DARTS为代表的、基于梯度的可微架构搜索方法,理解了其通过连续松弛和双层优化来高效搜索的精妙之处。
最重要的是,我们通过一个YOLOv8实战案例,亲手体验了如何定义搜索空间、构建超网络、执行搜索、解码架构的全过程。虽然是简化版,但它完整地展现了将NAS思想应用于实际项目的核心步骤。
希望通过今天的学习,你不再觉得NAS是一个遥不可及的“黑科技”,而是理解了它背后的清晰逻辑,并掌握了将其作为强大工具来优化你自己自己模型的潜力。记住,AI设计AI的时代已经到来,而你,已经拿到了这张宝贵的入场券!💖
🔮 下期预告:Transformer与卷积混合架构
在探索了各种卷积的“变体”和自动化的“设计”之后,下一节,我们将迎来一位重量级的“跨界挑战者”——Transformer!
自从Transformer在自然语言处理领域取得巨大成功后,它便开始席卷计算机视觉领域。Vision Transformer (ViT) 及其变体证明了,在没有卷积的情况下,纯粹的注意力机制也能实现顶尖的图像识别性能。
那么,问题来了:
- 卷积(Convolution) 的归纳偏置(如局部性、平移不变性)和 Transformer 的全局依赖建模能力,能否强强联合?
- 如何将这两种看似不同的范式优雅地融合在一起?
- 这种混合架构能否为YOLOv8带来新的性能飞跃,特别是在处理大目标和理解复杂上下文方面?
在下一节 《YOLOv8【卷积创新篇·第23节】Transformer与卷积混合架构》 中,我们将深入探讨卷积与Transformer的结合点,分析如CoAtNet、CMT等经典混合架构的设计思想,并探索如何将这些思想融入YOLO,打造一个既能捕捉局部精细特征,又能建立全局上下文联系的超级检测器!敬请期待!✨✨✨
希望本文所提供的YOLOv8内容能够帮助到你,特别是在模型精度提升和推理速度优化方面。
PS:如果你在按照本文提供的方法进行YOLOv8优化后,依然遇到问题,请不要急躁或抱怨!YOLOv8作为一个高度复杂的目标检测框架,其优化过程涉及硬件、数据集、训练参数等多方面因素。如果你在应用过程中遇到新的Bug或未解决的问题,欢迎将其粘贴到评论区,我们可以一起分析、探讨解决方案。如果你有新的优化思路,也欢迎分享给大家,互相学习,共同进步!
🧧🧧 文末福利,等你来拿!🧧🧧
文中讨论的技术问题大部分来源于我在YOLOv8项目开发中的亲身经历,也有部分来自网络及读者提供的案例。如果文中内容涉及版权问题,请及时告知,我会立即修改或删除。同时,部分解答思路和步骤来自全网社区及人工智能问答平台,若未能帮助到你,还请谅解!YOLOv8模型的优化过程复杂多变,遇到不同的环境、数据集或任务时,解决方案也各不相同。如果你有更优的解决方案,欢迎在评论区分享,撰写教程与方案,帮助更多开发者提升YOLOv8应用的精度与效率!
OK,以上就是我这期关于YOLOv8优化的解决方案,如果你还想深入了解更多YOLOv8相关的优化策略与技巧,欢迎查看我专门收集YOLOv8及其他目标检测技术的专栏《YOLOv8实战:从入门到深度优化》。希望我的分享能帮你解决在YOLOv8应用中的难题,提升你的技术水平。下期再见!
码字不易,如果这篇文章对你有所帮助,帮忙给我来个一键三连(关注、点赞、收藏),你的支持是我持续创作的最大动力。
同时也推荐大家关注我的公众号:「猿圈奇妙屋」,第一时间获取更多YOLOv8优化内容及技术资源,包括目标检测相关的最新优化方案、BAT大厂面试题、技术书籍、工具等,期待与你一起学习,共同进步!
🫵 Who am I?
我是bug菌,CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等社区博客专家,C站博客之星Top30,华为云多年度十佳博主,掘金多年度人气作者Top40,掘金等各大社区平台签约作者,51CTO年度博主Top12,掘金/InfoQ/51CTO等社区优质创作者;全网粉丝合计 30w+;更多精彩福利点击这里;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试真题、4000G PDF电子书籍、简历模板等海量资料,你想要的我都有,关键是你不来拿。

-End-
更多推荐


 7
7 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)