
大模型微调实战:从数据准备到Ollama部署的完整流程
本文系统介绍了大语言模型(LLM)微调的完整技术流程,包括数据准备、环境搭建、模型加载、LoRA适配器应用、模型训练及Ollama部署。通过Unsloth工具和Qwen3-0.6B模型实例,详细展示了如何对预训练模型进行微调,使其在特定领域(如驾驶教学)实现精准输出。文章提供了丰富的代码示例和操作步骤,帮助开发者掌握微调技巧,实现模型的专业化定制,提升任务表现稳定性和准确性。
本文系统介绍了大语言模型(LLM)微调的完整技术流程,包括数据准备、环境搭建、模型加载、LoRA适配器应用、模型训练及Ollama部署。通过Unsloth工具和Qwen3-0.6B模型实例,详细展示了如何对预训练模型进行微调,使其在特定领域(如驾驶教学)实现精准输出。文章提供了丰富的代码示例和操作步骤,帮助开发者掌握微调技巧,实现模型的专业化定制,提升任务表现稳定性和准确性。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
在人工智能迅速发展的今天,大语言模型(LLM)已经成为文本理解与生成的核心工具。尽管它们在通用任务上表现出色,但面对特定领域或专业场景时,通用模型往往难以提供精准、稳定的输出。微调(Fine-tuning)技术正是在这种背景下应运而生:通过在预训练模型基础上进行定向训练,使模型在特定任务上更贴合需求,从而显著提升效率和可靠性。
本文将系统讲解LLM微调的完整流程,从数据准备、环境搭建,到使用Unsloth训练模型、应用LoRA适配器,再到模型导出及在Ollama中运行测试。通过丰富的示例和操作步骤,无论是初学者还是有一定经验的开发者,都能掌握微调技巧,并在驾驶教学、法律文档生成等专业场景中实现高效精准的模型定制化。
一、理解LLM微调
想象一下,你请来一位顶级厨师,几乎什么菜都会做,但如果想学会你家独有的菜谱,你并不需要从头教他烹饪,只需展示几道拿手菜,他就能迅速掌握并复刻。
这就是微调(Fine-tuning)的意义!
微调指的是在一个已经完成预训练的大语言模型(如Llama或Qwen等)基础上,进一步适应你的特定任务。通过提供一些与你领域相关的示例,模型会调整内部参数,从而在该领域的表现更加精准、贴合需求。
工作原理:
- 从一个已经预训练好的基础模型开始,已具备对语言的理解能力。
- 提供“输入-输出”示例(如:问题及理想答案)。
- 模型通过调整内部权重,使生成结果尽可能贴合这些示例。
与Prompting的区别:
- Prompting(提示):类似于临时下达指令,例如“请像莎士比亚一样写作”。
- 微调:则是对模型进行永久性调整,让它在特定任务表现得更稳定、更精准。
与参数调优的区别:
- 参数调优:在使用过程中修改模型的外部设置(如temperature控制创造性),不改变模型内部结构。
- 微调:改变模型内部结构,更像是升级发动机,使汽车能在特定场景(如越野路况)下有更强性能。
二、什么时候选择微调? 并不是所有任务都需要微调,就像开跑车去买菜一样,既昂贵又不必要。以下几类场景特别适合考虑微调: * 需要一致的格式或风格 当单纯依靠Prompt无法确保输出严格符合要求时,例如生成JSON、法律文档或结构化数据。 * 特定领域的数据 当模型缺乏对某些专业领域的知识时,例如医疗术语、公司内部日志或行业专有语料。 * 降低成本 通过微调小模型,可以在保持精度的同时替代参数量更大的模型,从而显著减少推理开销。 微调的优缺点: | | 微调的优点 | 微调的缺点 | | — | — | — | | 数据需求 | 需要数百/数千条数据 | 仍需要高质量数据 | | 时间/计算 | 在GPU上只需几分钟到几小时 | 可能会降低模型在通用任务上的表现 | | 性能 | 在你的任务上表现优异 | 如果数据不好会过拟合 | | 成本 | 长期来看更便宜(模型更小) | 初始设置时间较长 | 微调的替代方案: * 提示工程(Prompt Engineering) 成本低、上手快,但输出往往不够稳定,尤其在需要严格一致性时容易失效。 * 检索增强生成(RAG) 在生成过程中动态引入外部知识库,适合知识更新快、语料规模大的场景。 * 从零训练(Full Training from Scratch) 需要庞大的数据和算力,仅适合少数具备大规模资源的机构使用。 三、LLM微调的逐步工作流程 下面展示一个标准的微调流程,供实际操作参考。本示例中: * Unsloth:一款开源、免费的高效微调工具; * Qwen3-0.6B:体积小、效率高,适合入门和快速实验。 第一步:准备数据 数据准备是整个微调流程的关键环节。数据质量直接决定模型效果——如果数据不好,模型表现也不会理想。 在这里,你需要构建输入-输出对**,并保存为JSON格式。 示例数据集:应用场景:根据车辆传感器/特征信息,生成驾驶教学提示。 下面展示一个简化示例(完整数据集共7,799条,此处仅展示其中2条): code-snippet__js [ **
如果需要,可以用AI生成数据,但最好使用真实数据以获得最佳效果。 第二步:搭建环境 在进行微调前,需要先安装必要的依赖,并确认GPU可用。 1. 安装依赖: 运行以下命令安装Unsloth及相关工具: code-snippet__js pip3 install unsloth 2. 检查GPU是否可用: 安装完成后,可以用以下代码确认GPU是否正常。 code-snippet__js import torch
若输出结果正确,即GPU已经可以使用。
第三步:加载模型
首先选择一个基础模型,例如Qwen3-0.6B,然后使用FastLanguageModel来加载模型和分词器。
from unsloth import FastLanguageModel
第四步:数据预处理
将原始数据格式化为模型可接受的单行字符串,并构建Dataset对象。
import json
输出示例如下:
<|im_start|>system
第五步:添加LoRA适配器
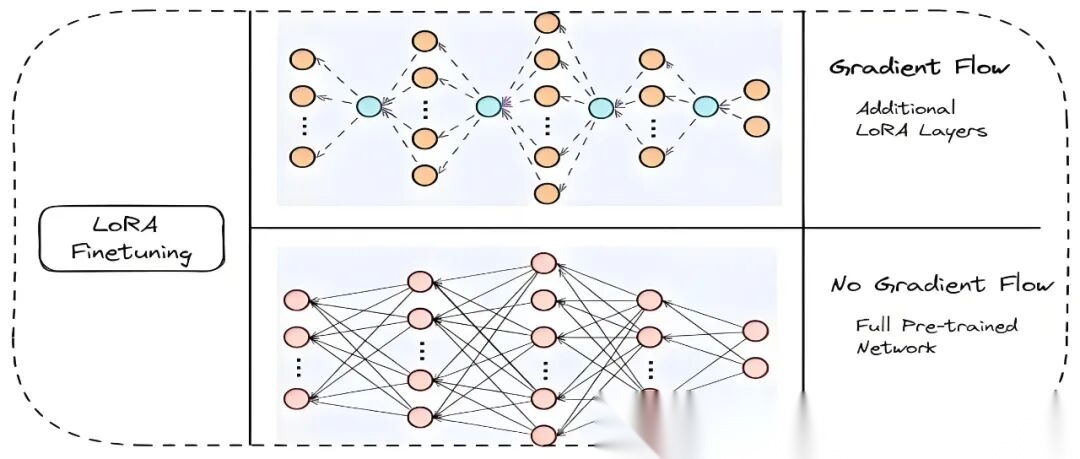
低秩适配微调(LoRA)工作流程图
LoRA(Low-Rank Adaptation)是一种高效的参数微调方法,专为大规模预训练模型设计,旨在****显著减少微调所需的可训练参数量,降低计算成本和存储负担。
传统大模型的微调往往需要训练数亿至数十亿参数,代价高昂。LoRA的创新在于:只需在模型中插入少量轻量模块,冻结原始参数,仅训练新增部分,就能完成模型适配,微调成本可降至原来的1%左右!
核心概念:
- 低秩适配:在模型中增加辅助层(LoRA 层),只更新这些新增层的参数。
- 优势:通常只训练约1%的模型参数,但仍能获得很好的微调效果。
# 为模型添加 LoRA 适配器
参数说明:
r=16
LoRA秩(Rank),低秩矩阵的维度。值越大表示LoRA层参数越多,同时显存占用也增加。target_modules=[...]
指定需要微调的模型模块,通常选择注意力层的q/k/v/o矩阵,以及MLP或其他关键模块。lora_alpha=16
缩放系数,决定LoRA层每个方向的调整的力度,控制输出幅度,保证训练稳定。lora_dropout=0
Dropout比例,用于防止LoRA层过拟合。bias="none"
偏置处理方式,可选择不调整偏置 (none)、微调所有偏置 (all) 或仅微调LoRA层偏置 (lora_only)。use_gradient_checkpointing="unsloth"
启用梯度检查点策略,在训练大模型时减少显存占用。random_state=3407
随机种子,保证训练结果可复现。
使用LoRA后,可在有限显存下完成大模型微调,同时保持训练效率。r和lora_alpha是关键参数,可根据任务规模和GPU显存进行调整。
第六步:训练模型
在完成数据准备和模型加载后,就可以进入关键环节——训练微调。这里我们采用监督式微调训练器SFTTrainer(Supervised Fine-Tuning Trainer),并结合LoRA适配器,实现高效的低资源训练。
from trl import SFTTrainer
参数说明:
- per_device_train_batch_size:根据显存大小与数据规模灵活调整。
- num_train_epochs:小数据集建议增加训练轮次,大数据集则可控制步数以避免过拟合。
- LoRA+8bit优化器:可在消费级显卡上完成训练,兼顾速度与显存利用率。
- checkpoint机制:避免训练中断浪费,可从上一次保存点继续。
在训练过程中,控制台会实时输出loss的变化趋势:
{'loss': 0.1143, 'grad_norm': 0.5369250178337097, 'learning_rate': 1.7700205338809036e-05, 'epoch': 4.56}
可以看到loss稳定下降,说明模型正在逐步学习数据特征,训练效果理想。
训练完成后,我们将模型导出为GGUF格式,方便在Ollama中加载运行。GGUF格式是llama.cpp使用的最新权重格式,支持多种量化方式(如q4/q8/f16),大幅减少显存占用。
第七步:推理测试
在完成微调和导出之后,接下来需要对模型进行一次快速推理测试,以验证其在新输入上的理解与生成效果。
# 导入推理工具
输出示例:
system
在这个示例中,模型能够正确解析输入并生成结构化输出。如果输出与预期不完全一致,可以继续训练或增加训练数据以提高模型准确性。
第八步:为Ollama创建模型文件
1. 安装Ollama:
前往Ollama官方网站下载并安装对应操作系统的版本。
- 准备模型目录:
在终端执行以下命令,创建一个目录并移动GGUF模型文件进去:
mkdir ollama-test
3. 创建Modelfile:
新建一个Modelfile:
touch Modelfile
在文件中粘贴以下内容:
# 使用微调后的 GGUF 模型
4. 创建模型:
执行以下命令,基于unsloth.Q4_K_M.gguf和Modelfile创建本地模型:
ollama create goDrive -f Modelfile
创建完成后,本地将拥有一个名为goDrive的可用模型。
第九步:在Ollama中运行并测试模型
微调模型导入Ollama后,可以通过两种方式进行测试:
方式一:命令行测试
1. 启动模型:
在终端输入以下命令:
ollama run goDrive
2. 输入Prompt:
运行后,在交互界面粘贴一段测试输入,例如:
<特征>场地类型:科目二; 当前项目:非项目区域; 车辆类型:手动挡; 挡位:1挡; 手刹:放下; 发动机:打火; 安全带:系上; 车门:关闭; 离合:未踩; 刹车:未踩; 油门:未踩; 速度:适中; 时间特征:夜晚</特征>
3. 模型输出:
Ollama会返回输出结果,例如:
<think>
如果希望模型生成的输出中不包含<think>标签,可以在训练阶段修改formatted_data,将其中包含的<think>标签移除。
方式二:API接口测试
Ollama也提供了本地HTTP接口,便于在应用中调用。
1. 发送请求:
使用curl调用本地API:
curl http://localhost:11434/api/generate -d '{
2. API返回结果:
接口会返回如下内容,例如:
{
这样,你既可以在命令行快速调试,也可以通过API接口集成到应用中。
四、总结与未来方向
本文系统介绍了使用开源工具Unsloth进行大语言模型(LLM)微调的完整流程,从数据准备、模型加载到LoRA适配器应用,再到训练与Ollama部署,形成了端到端的实践方法。通过实例演示,能够清楚理解微调如何提升模型在特定任务上的准确性与稳定性,同时掌握在专业场景中高效训练和定制模型的核心技巧。
展望未来,微调技术将朝着更高效、低资源和智能化方向发展。自动化数据生成、优化的LoRA策略以及与检索增强生成(RAG)方法的结合,将进一步提升模型的适应性和性能。随着应用领域从驾驶教学、法律文档扩展到医疗、金融等行业,LLM将能够提供更加精准、专业的智能辅助服务,实现真正定制化的人工智能解决方案。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐


 18
18 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)