大模型(Qwen3)训练实战:从零开始玩转LLaMA-Factory,手把手教你打造属于自己的AI助手!
我将为大家详细介绍如何使用LLaMA-Factory这一开源框架,从环境搭建到模型训练,再到实际应用,手把手教你打造属于自己的AI助手!
这一篇来整体讲一下大模型的训练和微调,选用的大模型依然是大模型(Qwen3),训练和微调的框架使用的是LLaMA-Factory。
在人工智能技术日新月异的今天,大型语言模型(LLM)已成为科技领域的热门话题。但对于大多数开发者和企业来说,如何高效、低成本地微调这些"庞然大物"仍是一个难题。
今天,我将为大家详细介绍如何使用LLaMA-Factory这一开源框架,从环境搭建到模型训练,再到实际应用,手把手教你打造属于自己的AI助手!

一、LLaMA-Factory:大模型微调的瑞士军刀
LLaMA-Factory是一个专为大型语言模型微调设计的开源框架,它就像是为大模型量身定制的"精加工车间"。这个框架最大的优势在于:
- 高效低成本:优化了微调过程中的资源消耗,让普通开发者也能负担得起
- 广泛兼容:支持近百种主流大模型,包括LLaMA、Qwen、DeepSeek等热门系列
- 操作简便:通过Web界面可视化操作,大大降低了技术门槛
“工欲善其事,必先利其器”,在开始我们的微调之旅前,让我们先搭建好这个强大的"工厂"。
二、环境搭建:三步打造专业微调平台
2.1 创建工作目录并克隆仓库
mkdir -p /data/train && cd /data/train
git clone https://github.com/hiyouga/LLaMA-Factory.git
2.2 安装依赖包
pip install -e .
在当前目录下查找Python包的元数据(如依赖关系、版本信息等),然后以可编辑模式安装该包及其所有依赖项。
-e 或者 --editable:这是一个选项,表示以可编辑模式安装包",后续对代码的任何修改都会立即生效,非常适合调试和开发;. 指定当前目录,pip查找当前目录下的setup.py文件。
2.3 配置Hugging Face镜像(国内用户必备)
huggingface_hub是指由Hugging Face提供的Python库,用于与Hugging Face的模型库进行交互,包括下载、上传和管理机器学习模型和数据集。具体来说:
- 安装:通过pip install -U huggingface_hub命令可以安装huggingface_hub库,确保使用最新版本。
- 功能:该库允许开发者访问Hugging Face Model Hub上的资源,包括预训练模型和数据集,便于模型的下载、加载和管理。
- 下载模型:可以使用huggingface-cli来下载模型,如:huggingface-cli download --resume-download Qwen/Qwen3-0.6B-Base --local-dir /data/models/Qwen/Qwen3-0.6B-Base,# 下载模型到指定的本地路径。
总之,huggingface_hub是一个强大的工具,帮助开发者高效地获取和管理Hugging Face上的机器学习资源。
由于网络限制,国内用户可以通过设置镜像源来加速下载:
export HF_ENDPOINT=https://hf-mirror.com
pip install -U huggingface_hub
三、模型获取:为微调准备"原材料"
选择适合的基座模型是微调成功的关键。这里我们以Qwen3-0.6B-Base模型为例:
mkdir -p /data/models/Qwen/Qwen3-0.6B-Base
huggingface-cli download --resume-download Qwen/Qwen3-0.6B-Base --local-dir /data/models/Qwen/Qwen3-0.6B-Base
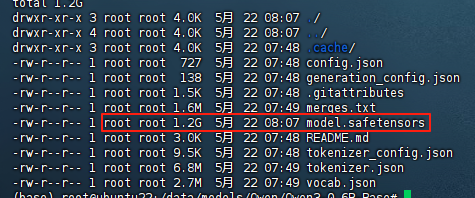
模型选择小贴士:
- 对于普通任务:0.5B-7B参数量的模型性价比最高
- 对于专业领域:建议选择在相关领域有预训练的基座模型
- 资源有限时:可以考虑量化版本或小型模型
四、数据准备:打造专属"知识库"
数据是微调的灵魂,我们使用一个经济学相关的对话数据集作为示例:
4.1 下载数据集
git clone https://github.com/echonoshy/cgft-llm.git
cp cgft-llm/data/fintech.json /data/train/LLaMA-Factory/data/
这里选择的数据集文件是关于经济学的对话信息,内容如下:
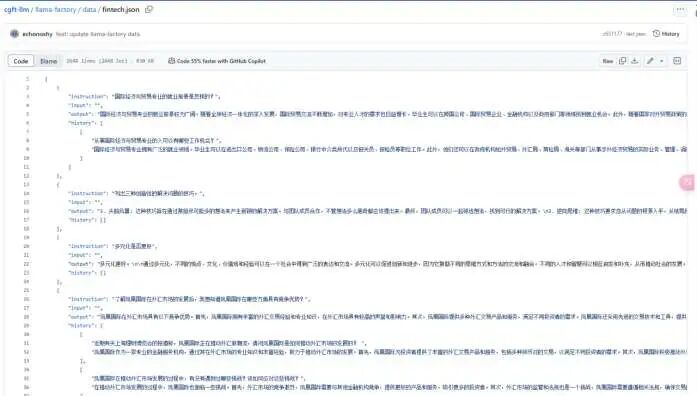
数据准备黄金法则:
- 数据质量 > 数据数量:1000条高质量数据胜过10000条低质数据
- 领域聚焦:数据应紧密围绕目标应用场景
- 格式规范:确保数据格式与模型预期一致
五、微调实战
5.1 启动Web UI
cd /data/train/LLaMA-Factory
export GRADIO_SERVER_PORT=8800
nohup llamafactory-cli webui 2>&1 > webui.log &
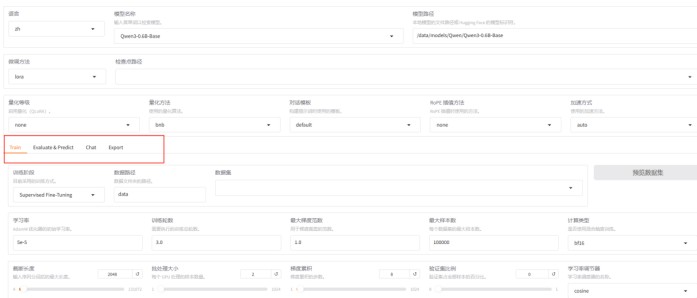
5.2 配置微调参数
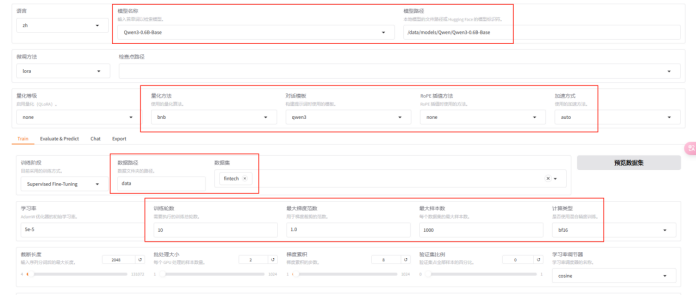
在Web界面中,我们需要关注几个核心参数:
- 学习率:通常设置在1e-5到5e-5之间
- 批处理大小:根据GPU内存调整,可从4开始尝试
- 训练轮次:3-5个epoch通常足够
- LoRA参数:rank一般设为8或16,alpha设为16或32
5.3 设置输出并开始
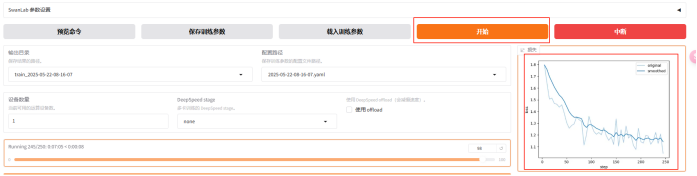
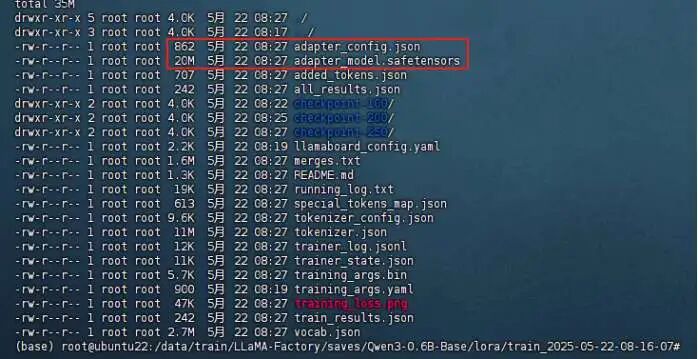
完成执行后输出模型:
内存优化技巧: 当遇到内存不足时,可以:
- 减小批处理大小
- 启用梯度累积
- 使用更高效的优化器(如Adafactor)
六、新模型的部署
6.1 模型合并与导出
将 base model 与训练好的 LoRA Adapter 合并成一个新的模型。训练完成后,我们需要将LoRA适配器与基础模型合并:
llamafactory-cli export --model_name_or_path /data/models/Qwen/Qwen3-0.6B-Base --adapter_name_or_path /data/train/LLaMA-Factory/saves/Qwen3-0.6B-Base/lora/train_2025-05-22-08-16-07 --template qwen3 --finetuning_type lora --export_dir /data/models/Qwen/Qwen3-0.6B-yangxl
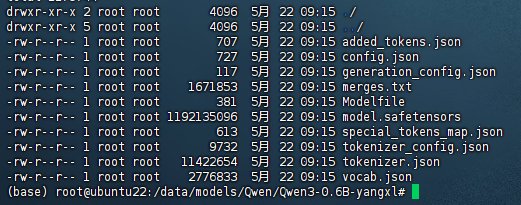
6.2 使用vLLM高效部署训练好的模型
CUDA_VISIBLE_DEVICES=0 nohup python3 -m vllm.entrypoints.openai.api_server \ --model=/data/models/Qwen/Qwen3-0.6B-yangxl \ --served-model-name=Qwen3-0.6B-yangxl \ --dtype=bfloat16 \ --trust-remote-code \ --device=cuda \ --max-model-len=1024 \ --tensor-parallel-size=1 \ --gpu-memory-utilization=0.85 \ --enable-reasoning \ --reasoning-parser deepseek_r1 \ --port 8802 \ --api-key token-123456 &
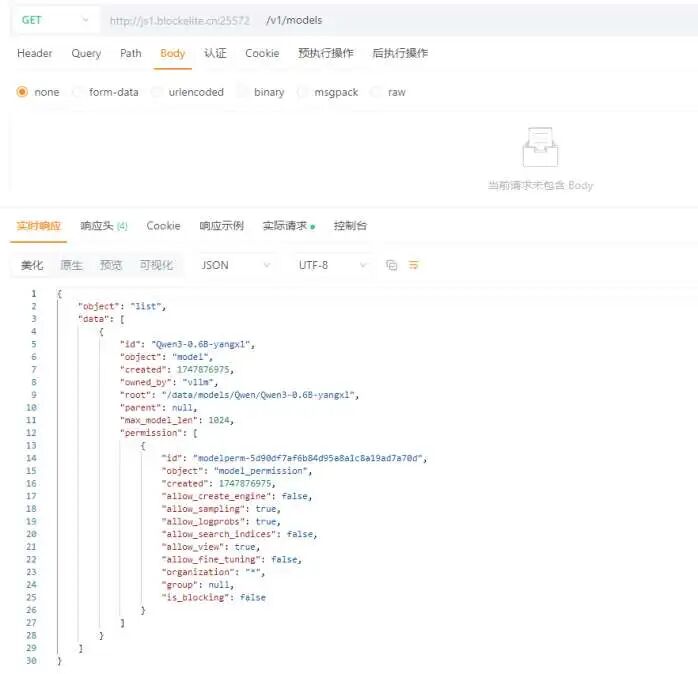
七、新模型的测试
7.1 加载模型
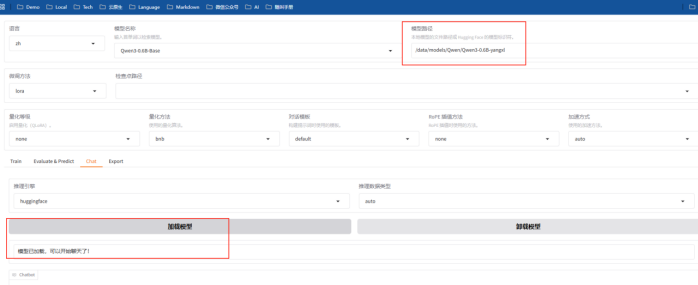
7.2 提问
提示词:国际经济与贸易专业的就业是怎么样?

八、总结
- 训练环境的准备:准备LLaMA-Factory的环境有两种,本文只讲了一各较为复杂的方式;还有一种就是容器化的方式,只所以采用第一种方式,只是为了亲自体验一下;
- 训练数据的准备:将准备好的数据放到LLaMA-Factory下**/data**下,数据需满足以下几点要求:
- 数据质量 > 数据数量:1000条高质量数据胜过10000条低质数据
- 领域聚焦:数据应紧密围绕目标应用场景
- 格式规范:确保数据格式与模型预期一致;
- 训练参数配置:模型名称、模型路径、数据路径、数据集、训练轮数、最大样本数等;
- 训练后的新模型:检查新模型目录下的文件是否完整、导出新模型、新模型的部署和测试。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

一座年轻的奋斗人之城,一个温馨的开发者之家。在这里,代码改变人生,开发创造未来!
更多推荐


 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)