【AIGC】美团龙猫大模型(LongCat-Flash-Chat)2. 技术报告
美团龙猫大模型(LongCat-Flash-Chat)1. 快速入门
美团龙猫大模型(LongCat-Flash-Chat)2. 技术报告
美团龙猫大模型(LongCat-Flash-Chat)2. 技术报告
0. LongCat-Flash-Chat 大模型简介
0.1 开源模型
2025年 9月 1日,美团正式发布 LongCat-Flash-Chat(龙猫)大模型。
LongCat-Flash 大模型目前在 Github、Hugging Face 平台开源,同时你也可以访问官网 https://longcat.ai/,与 LongCat-Flash-Chat 开启对话。
LongCat 官方也公开了美团龙猫大模型(LongCat-Flash-Chat)【技术报告】。

0.2 摘要
我们推出LongCat-Flash, 一个拥有5600亿参数的混合专家(MoE)语言模型,兼具计算高效性与先进智能体能力。针对可扩展效率的需求,该模型采用两项创新设计:(a) 零计算专家,通过动态分配计算预算,根据上下文需求激活186亿至313亿(平均270亿)参数/词元,优化资源利用;(b) 捷径连接MoE,扩大计算-通信重叠窗口,相比同规模模型显著提升推理效率与吞吐量。
我们开发了面向大模型的综合扩展框架,集成超参数迁移、模型增长初始化、多维度稳定性方案及确定性计算,实现稳定且可复现的训练。值得注意的是,通过协同可扩展架构设计与基础设施优化,我们在30天内完成了超20万亿词元的训练,推理速度突破100词元/秒(TPS),单百万输出词元成本仅0.7美元。
为培育LongCat-Flash的智能体能力,我们先对优化混合数据进行大规模预训练,随后针对推理、代码和指令进行阶段性专项训练,并辅以合成数据与工具使用任务增强。综合评估表明,作为非思考型基础模型,LongCat-Flash在主流模型中展现出极具竞争力的性能,尤其擅长智能体任务。模型检查点已开源以促进社区研究。
1. 引言
以DeepSeek-V3 [DeepSeek-AI et al., 2025]、Qwen 3 [Yang et al., 2025]和Kimi-K2 [Team et al., 2025]为代表的大语言模型(LLMs)的快速发展,印证了扩大模型规模与计算资源的有效性。尽管近期进展引发了关于规模扩展可能减速的担忧,但我们认为算法设计、底层系统优化与数据策略对于持续推进可扩展智能边界同样关键。这需要在模型架构与训练策略上进行双重创新:既要提升规模扩展的成本效益,又需通过系统化数据策略增强模型解决现实任务的能力。
本文提出LongCat-Flash——一个高效而强大的混合专家(MoE)语言模型,旨在通过计算效率与智能体能力这两个协同方向突破语言模型边界。基于数万块加速器训练而成的LongCat-Flash,融合了架构创新与多阶段训练方法学,其贡献涵盖效率与智能体能力两大维度:
-
可扩展架构设计实现计算高效性
LongCat-Flash的架构设计遵循两大核心原则:计算资源高效利用与训练/推理高效执行。具体包括:- (1) 零计算专家机制:针对MoE模块中词元重要性差异,动态分配计算预算(根据语境需求激活186亿至313亿参数,总量5600亿),并通过PID控制器调节专家偏置,将单词元平均激活参数稳定在约270亿;
- (2) 捷径连接MoE(ScMoE) [Cai et al., 2024]:扩大计算-通信重叠窗口,结合定制化基础设施优化,支撑万级加速器规模的训练及高吞吐、低延迟推理。
-
稳健的模型扩展策略
我们开发了兼具稳定性与扩展性的综合框架:- (1) 超参数迁移策略:基于理论保证的小规模代理模型预测最优超参数配置;
- (2) 模型增长初始化:通过精调的半规模检查点提升初始化效果;
- (3) 多维度稳定性方案:包括路由梯度平衡、抑制激活爆炸的隐变量z-loss、优化器微调;
- (4) 确定性计算:确保实验完全可复现,并能检测训练过程中的静默数据错误(SDC)。
-
多阶段训练培育智能体能力
通过三阶段流程赋予高级智能体行为:- (1)预训练:采用两阶段数据融合策略聚焦推理密集型领域;
- (2)中期训练:增强推理与编码能力,扩展上下文至128k以适配后续需求;
- (3)后期训练:设计多智能体合成框架(从信息处理、工具复杂度、用户交互三维度定义任务难度),生成需迭代推理与环境交互的复杂任务。
得益于架构、策略与基础设施的协同创新,LongCat-Flash在5600亿参数规模下仅用30天完成20万亿词元预训练(时间可用率98.48%),H800推理效率超100词元/秒(TPS),单百万输出词元成本0.7美元。
我们对 LongCat-Flash 的基础版本和指令调优版本进行了多维度基准测试,结果概览如图 1 所示。作为一个非思维模型(non-thinking model),LongCat-Flash 在使用更少参数和提供更快推理速度的同时,取得了与前沿非思维模型(包括 DeepSeek-V3.1 [DeepSeek-AI 等, 2025] 和 Kimi-K2 [Team 等, 2025])相媲美的性能。具体而言,LongCat-Flash 在 ArenaHard-V2 上获得 86.5 分,在 TerminalBench 上获得 39.5 分,在 τ²-Bench 上获得 67.7 分,展现了在通用领域、编程和智能体工具使用方面的稳健能力。
为降低现有开源基准数据污染风险并提升评估可信度,我们精心构建了两个新基准:Meeseeks [Wang 等, 2025a] 和 VitaBench。Meeseeks 通过迭代反馈框架模拟真实人机交互以评估多轮指令跟随能力,而 LongCat-Flash 在该基准上的表现与前沿大语言模型相当。VitaBench 则利用真实商业场景评估模型处理复杂现实任务的能力,在此基准上 LongCat-Flash 的表现优于其他大语言模型。
本报告后续将依次详述模型架构创新、训练流程(含数据构建与评估结果),最后探讨训练挑战、解决方案以及基于独特架构的推理部署优化方法。
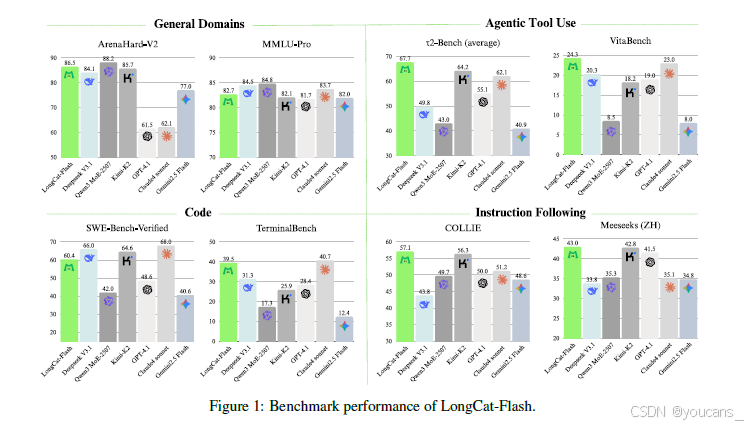
图1:LongCat-Flash的基准测试表现
2. 架构
LongCat-Flash采用了一种新颖的MoE架构,具有两项关键创新(如图2所示):
- (1) MoE模块整合了零计算专家[Jin等人,2024],实现动态计算,使得各token能够根据其上下文重要性消耗可变的计算资源。此外,通过自适应专家偏置调节平均计算负载。
- (2) 每层集成两个多头潜在注意力(MLA)模块[Liu等人,2024a]和多个异构前馈网络(FFN)模块。采用从第一个MLA输出到MoE模块的快捷连接[Cai等人,2024]。为提升性能,我们通过方差对齐对MLA和细粒度FFN专家进行优化。后续小节将详细说明各组件。
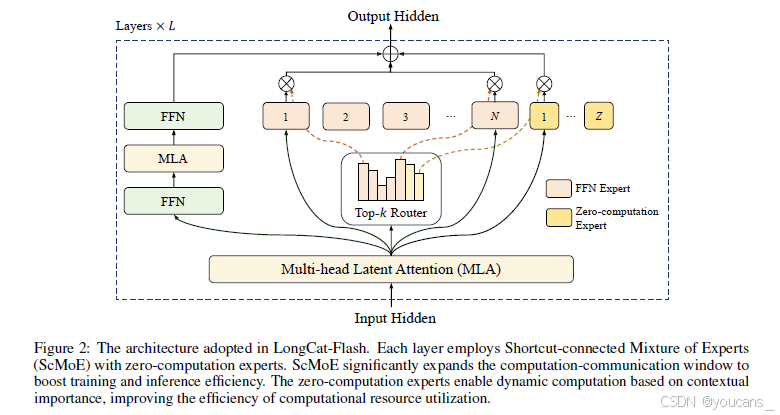
图2:LongCat-Flash采用的架构。
每一层均使用带有零计算专家的Shortcut-connected Mixture of Experts(ScMoE)。
ScMoE大幅扩展了计算-通信窗口,从而提升训练和推理效率。
零计算专家能够根据上下文重要性动态调整计算量,提高计算资源利用效率。
2.1 零计算专家
下一token预测天然具有计算异构性。复杂token可能需要更多资源来实现准确预测,而简单token几乎无需计算。这一现象也被推测解码实证所证实——小型草稿模型能够可靠预测大型模型对多数简单token的输出[Leviathan等人,2023]。
基于此,LongCat-Flash通过零计算专家[Jin等人,2024;Zeng等人,2024]激活每个token的FFN专家可变数量,提出动态计算资源分配机制,实现根据上下文重要性的合理计算分配。具体而言,LongCat-Flash在N个标准FFN专家之外,增加Z个零计算专家扩展其专家池。零计算专家仅将输入x_t作为输出返回,不引入额外计算成本。设x_t为第t个token的MoE输入,LongCat-Flash的MoE模块可表述如下:
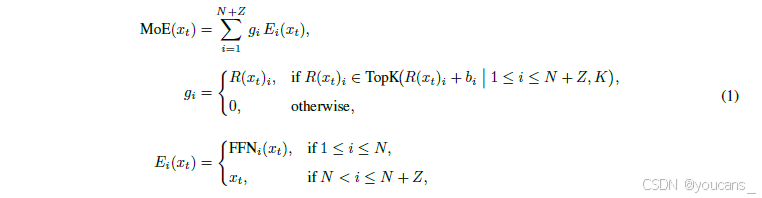
其中,R表示softmax路由函数,b_i对应第i个专家的偏置项,K表示每个token选择的专家数量。
路由机制将每个token分配给K个专家,其中激活的FFN专家数量会根据token的上下文重要性动态变化(如图3a所示)。通过这种自适应分配机制,模型学会将更多计算资源动态分配给上下文重要性更高的token,从而在相同计算能力下实现更优越的性能。
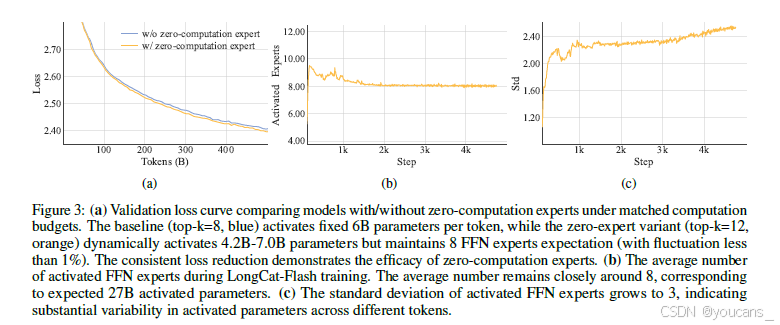
图3:(a) 验证损失曲线对比计算预算匹配条件下使用/不使用零计算专家的模型表现。基线模型(top-k=8,蓝色)固定激活每token 60亿参数,而零专家变体(top-k=12,橙色)动态激活42-70亿参数,但仍保持8个FFN专家的期望值(波动小于1%)。持续降低的损失验证了零计算专家的有效性。(b) LongCat-Flash训练过程中激活的FFN专家平均数,该数值始终紧密围绕8波动,对应预期的270亿激活参数。© 激活FFN专家数的标准差增至3,表明不同token间激活参数存在显著差异性。
2.1.1 计算预算控制
为了激励模型学习基于上下文的计算分配策略,必须对零计算专家的平均选择比例进行细粒度控制。若无明确约束,模型往往会欠使用零计算专家,导致资源利用率低下。
我们通过改进自[Wang等人,2024a]的无辅助损失策略的专家偏置机制来实现这一目标——该机制引入了专家专属的偏置项,可根据近期专家使用率动态调整路由分数,同时保持与语言模型(LM)训练目标的解耦。对于第i个专家对应的偏置项b_i,其每个训练步的增量更新计算方式为:
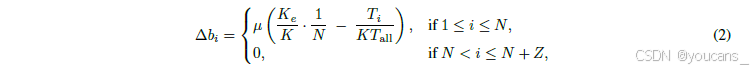
其中,μ表示偏置适应率,Tall表示全局批次中的token总数,Ti表示被路由至第i个专家的token数量,Ke表示激活FFN专家的期望数量(该值小于K)。
本研究提出的更新规则采用控制理论中的PID控制器(比例-积分-微分)[Bennett, 1993],确保第i个专家的token分配收敛至目标比例。与固定偏置增量方法[Wang等, 2024a]相比,该机制在专家数量扩展时显著提高了softmax路由器概率分布的鲁棒性。值得注意的是,零计算专家不参与偏置更新——由于其身份特性只需满足全局约束,当所有FFN专家达到预期token比例时该约束自动满足。实验表明,大批次规模和μ的衰减调度可提升预算控制稳定性,而小批次规模可能需要降低更新频率。
在预训练阶段,我们追踪了激活专家数量的平均值与标准差(图3b和3c)。结果显示经过约200亿token的调整后,所有网络层的平均专家数量均收敛至期望值(波动小于1%),但标准差始终维持在较高水平,这表明模型对不同token分配的计算资源存在显著差异。
关于动态路由的详细统计数据与案例研究,请参阅附录A.1。
2.1.2 负载均衡控制
高效的MoE训练要求FFN专家之间实现稳健的负载均衡。虽然公式(2)在语料库级别强制实现了均衡,但我们进一步引入了设备级负载均衡损失[DeepSeek-AI等,2025],以额外防止EP组间的极端序列级不平衡问题。针对零计算专家(zero-computation experts),我们采取了必要的适配措施。
具体而言,假设所有N个FFN专家被划分为D组,每组包含G = N/D个专家,则该损失可表示为:

其中:α为平衡因子,T表示微批次(micro batch)中的token数量,I为指示函数。在该损失函数中,我们将所有零计算专家(zero-computation experts)分配至额外分组,并对各组频率取均值。通过调整fj系数,可确保当损失收敛时,FFN专家与零计算专家的数量比趋近于Ke/(K-Ke)。
2.2 捷径连接型MoE
我们初始架构采用MoE与稠密FFN块的交错拓扑结构。该设计已通过实证研究得到广泛验证,其性能与领先的共享专家模型相当[Rajbhandari等,2022;Liu等,2024a]。然而大规模MoE模型的效率始终受通信开销制约——传统执行范式中,专家并行(Expert Parallelism)强制要求顺序工作流:必须首先通过集合通信操作将token路由至指定专家后才能开始计算。这种通信延迟成为瓶颈,导致设备利用率不足并限制系统总吞吐量。
虽然共享专家架构试图通过单个专家的计算与通信重叠来缓解此问题,但其效率受限于该专家有限的计算窗口。我们通过捷径连接型MoE(ScMoE)架构[Cai等,2024]突破此限制:该架构引入跨层捷径(cross-layer shortcut)重构执行流水线,其核心创新在于让前一模块的稠密FFN计算与当前MoE层的调度/聚合通信并行执行,形成比共享专家设计更显著的重叠窗口。该架构设计被以下关键发现验证:
首先,ScMoE未损害模型质量。如图4所示,采用本架构与无ScMoE基线的训练损失曲线几乎重合,证实这种重排序执行不影响模型性能。该结论在多种配置下具有普适性,包括:采用MLA的2.4B-16B MoE模型、采用MHA的3B-20B模型[Vaswani等,2017],以及采用GQA的15B-193B模型[Ainslie等,2023]。这些发现证明ScMoE的稳定性与注意力机制选择具有正交性。
其次,ScMoE为训练与推理带来显著系统级效率提升:
(1)大规模训练:通过沿token维度将操作划分为细粒度分块,扩展的重叠窗口使前一模块计算能与MoE层的调度/聚合通信阶段完全并行
(2)高效推理:ScMoE实现单批次重叠流水线,相较DeepSeek-V3等领先模型将理论单token耗时(TPOT)降低近50%。其还(3)可并发执行异构通信模式:稠密FFN的节点内张量并行通信(通过NVLink)可与节点间专家并行通信(通过RDMA)完全重叠,从而最大化网络总利用率
综上,ScMoE在不牺牲模型质量的前提下实现显著性能提升,这些增益并非源自折衷权衡,而是经过严格验证的质量中性架构创新的直接成果。
2.3 面向可扩展性的方差对齐设计
在模型规模扩展过程中,优秀的小规模架构设计可能变得次优,反之亦然,这使得初始设计选择变得不可靠。通过大量实验和理论分析,我们发现特定模块中的方差失配(variance misalignment)是导致这一差异的关键因素,可能引发扩展过程中的不稳定性和性能下降。为解决这一问题,我们提出了针对MLA和MoE模块的方差对齐技术。
2.3.1 MLA的尺度校正
LongCat-Flash采用改进的多头潜在注意力机制(Multi-head Latent Attention,MLA)[Liu等人,2024a],该方法通过引入尺度校正因子αq和αkv来解决非对称低秩分解(asymmetric low-rank factorization)固有的方差不平衡问题。我们完整的数学表达(包含这些校正因子)如下所示: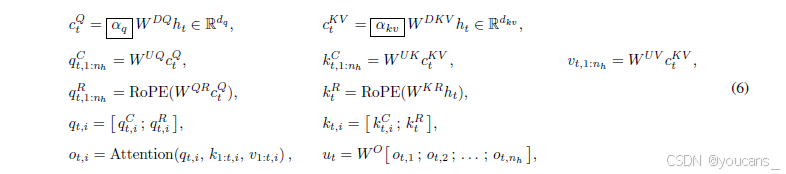
其中,hₜ ∈ R^(d_model) 表示第 t 个 token 的注意力输入,nₕ 为注意力头的数量。
α q α_q αq与 α k v α_{kv} αkv的引入解决了查询向量(query)与键向量(key)组件之间根本性的方差失配(variance mismatch)问题。在初始化阶段,这些组件的方差与其源维度成比例:σ²(qₜᴬ)、σ²(qₜᴿ) ∝ dq,σ²(kₜᴬ) ∝ dkv。而旋转键组件kₜᴿ的方差则与完整模型维度成比例:σ²(kₜᴿ) ∝ d_model。当dq、dkv和d_model取不同值时,这种维度差异会导致初始化阶段的注意力分数不稳定,进而在模型扩展过程中造成性能下降和不可预测的行为。
我们的解决方案是通过重缩放低秩路径组件,使其最终方差与参考尺度对齐(以完整模型维度为参考)。这通过定义如下缩放因子实现:
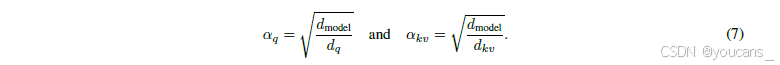
这种尺度不变的修正方法有效消除了方差失配问题,从而确保注意力计算的数值稳定性。实验结果表明(如图5a所示),该方法显著提升了模型性能。
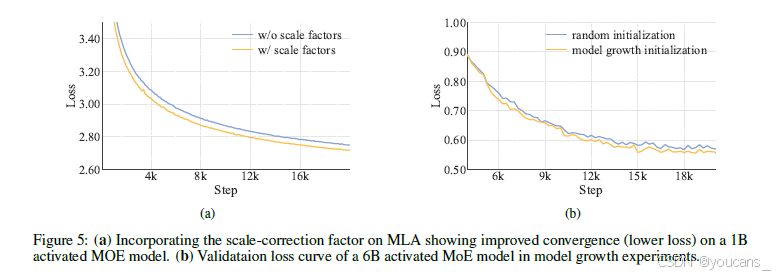
图5:(a) 在10亿激活参数的混合专家(MoE)模型中,引入尺度校正因子后多层注意力机制(MLA)显示出更优的收敛性(更低的损失值)。(b) 模型扩展实验中,60亿激活参数MoE模型的验证损失曲线。
2.3.2 专家初始化方差补偿
LongCat-Flash采用了来自DeepSeek-MoE[Liu et al., 2024a]的细粒度专家策略,该策略将每个专家分割成m个更细粒度的子专家,以增强组合灵活性和知识专业化。然而,我们发现这种设计的性能对其他架构选择(如专家数量、top-k值、m值)较为敏感。为此,我们提出了一种方差补偿机制,用于抵消专家分割导致的初始化方差缩减。该机制通过应用一个缩放因子 γ 来调整专家聚合输出,其公式表述为:
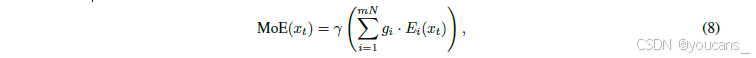
其中, g i g_i gi 表示路由器在 m N mN mN 个细粒度专家上的输出, N N N 表示分割前的专家总数。
式(8) 的缩放因子 γ \gamma γ 是通过量化两种主要的方差缩减来源推导得出的:
-
门控稀释(Gating Dilution):将每个原始的 N N N 个专家分解为 m m m 个细粒度专家后,专家总数扩展至 m N mN mN。这种扩展使得 Softmax 门控必须将其概率分布在更大的专家池中,因此单个门控值 g i g_i gi 的幅度会被成比例降低,导致输出方差大约减少 m m m 倍。
-
维度缩减(Dimensional Reduction):每个细粒度专家的中间隐藏维度( d expert_inter d_{\text{expert\_inter}} dexpert_inter)被削减为原来的 1 m \frac{1}{m} m1。假设参数均匀初始化,单个专家的输出方差同样会减少 m m m 倍。
为了在初始化阶段维持 MoE 层的输出方差(使其与分割前的基线匹配), γ \gamma γ 必须同时补偿上述两种效应,因此综合方差补偿因子为: γ = m ⋅ m = m \gamma = \sqrt{m \cdot m} = m γ=m⋅m=m
2.4 模型信息
Tokenizer(分词器)
LongCat-Flash 采用字节对编码(BPE)[Shibata et al., 1999, Sennrich et al., 2015] 进行分词。我们的分词器基于覆盖网页、书籍、源代码等多语言语料的综合训练,确保跨领域性能稳健。在继承 GPT-4 的预分词框架基础上,我们引入了以下改进:
增强的 CJK(中日韩)字符分割,以优化中文文本处理;
独立的数字分词,以提高数学计算能力。
词汇表大小优化为 131,072 词元,在计算效率与语言覆盖范围之间达到了理想平衡。
Multi-Token Prediction(多词元预测,MTP)
为提升推理效率,我们引入了 Multi-Token Prediction(MTP)[Gloeckle et al., 2024, DeepSeek-AI et al., 2025] 作为辅助训练目标。为保证最佳推理性能,MTP 头部选用 单个稠密层(dense layer) 而非 MoE 层。实证观测发现 MTP 损失收敛迅速,因此我们 在中后期训练阶段策略性引入 MTP 训练,以平衡模型性能与预测准确率。评估结果显示,MTP 头部的 接受率超过 90%(见表 5)。
Model Configurations(模型配置)
LongCat-Flash 采用 28 层架构(不含 MTP 层) 与 6,144 维隐藏状态。每个 MLA(混合专家注意力)模块 使用 64 个注意头(attention heads),单头维度 128,以均衡性能与效率。参考 DeepSeek-V3 [Liu et al., 2024a],我们设置:
KV 压缩维度:512
Query 压缩维度:1,536
稠密路径的 FFN(前馈网络) 采用 12,288 维中间层,而每个 FFN 专家(expert) 使用 2,048 维。MLA 模块与 FFN 模块的缩放因子遵循 2.3.1 节 所述方法。
每层包含 512 个 FFN 专家 和 256 个零计算专家(zero-computation experts),每个词元会 精确激活 12 个专家(从两类中筛选)。
LongCat-Flash 总参数量达 5600 亿(560B),每个词元的激活参数量介于 186 亿(18.6B)至 313 亿(31.3B),平均激活参数量约 270 亿(27B)。
3. 预训练
LongCat-Flash的预训练采用三阶段课程学习策略:(1)首先在约20万亿token、8192序列长度的数据上训练,构建基础模型;(2)使用数万亿数据进一步增强推理与编程能力;(3)通过长上下文语料训练将上下文长度扩展至128k。每个阶段均实施定制化数据策略,并辅以严格的数据净化流程以防止测试集泄露。
为优化可扩展性,我们引入超参数迁移和模型增长策略,显著提升了模型规模扩大时的性能表现。针对大规模训练固有的稳定性挑战,我们识别并实施了多项有效技术以增强训练稳定性。
3.1 训练策略
3.1.1 超参数迁移
LongCat-Flash采用基于宽度缩放[Everett et al., 2024]的超参数迁移策略,其核心方法包含:(1)在小型代理模型上确定最优超参数;(2)通过理论驱动的缩放规则将这些配置迁移至目标模型。
迁移机制围绕宽度缩放因子s = n_target/n_proxy(n为模型隐藏层维度)展开,特别采用标准参数化下的"Adam LR Full Align"规则。该规则定义了如何将代理模型的最优初始化方差(σ²)和学习率(η)适配至目标架构,具体迁移规则见 表1。
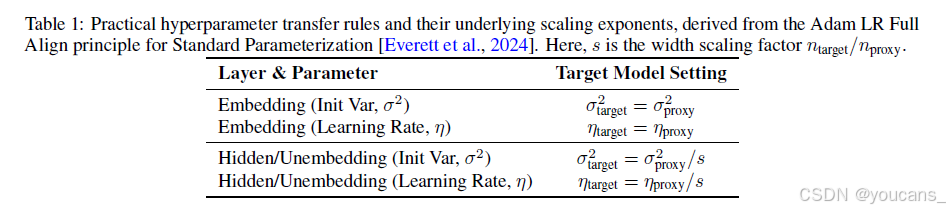
实施流程如下:
- 基于计算效率与迁移性能的权衡分析,设定宽度缩放因子s=8,代理模型宽度配置为768;
- 在代理模型上执行全面的超参数搜索,确定各层最优初始化方差(σ²_proxy)和学习率(η_proxy);
- 根据表1规则将代理模型最优超参数迁移至目标模型,迁移过程中保持其他架构属性(深度、稀疏性、批大小)不变。
实验验证表明,该方法大幅降低了大规模模型训练中超参数(初始化方差与学习率)优化的计算成本,同时建立了理论完备的模型扩展框架。
3.1.2 模型增长初始化
LongCat-Flash采用模型增长作为初始化策略,其基础是在数百亿token上预训练的半数规模模型。在现有模型增长方法中(Chen等2015、Du等2024、Wang等2023a、Shen等2022、Wang等2023b、Gong等2019),我们采用层堆叠技术(Du等2024、Kim等2023)进行参数扩展与性能提升。暂不考虑嵌入与解嵌入过程,该方法的数学表述为:
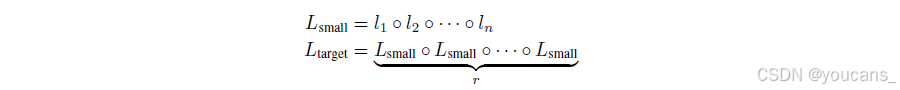
其中,li表示模型中第i层的变换,r表示扩展率,Lsmall表示从小型模型词嵌入到最终隐藏状态的变换,Ltarget表示通过堆叠r个小型模型构建的目标(大型)模型变换。本架构采用r=2的扩展率。
通过大量实验,我们持续观察到模型增长初始化的模型呈现独特的损失轨迹:初始损失上升后伴随加速收敛,最终超越随机初始化基线。图5b展示了我们60亿激活参数模型实验中的典型案例,证明了模型增长初始化的优势。
我们认为该改进源于两个协同因素:(1)小型模型的快速收敛为扩展训练提供了更高质量的参数初始化;(2)增长操作可能作为防止参数崩溃的隐式正则化器。实验证据进一步表明,对前置模型的过度优化可能损害目标模型的token效率,这提示需要谨慎选择增长时机。
LongCat-Flash的初始化流程如下:首先训练14层模型(与目标模型架构相同),在初始数据段采用随机初始化;随后将训练好的模型堆叠形成28层检查点,并完整保留前置模型的所有训练状态(包括样本计数器和学习率调度表)。
3.1.3 训练稳定性增强
我们从路由器稳定性、激活稳定性和优化器稳定性三个维度提升LongCat-Flash的训练稳定性。
路由器稳定性
MoE模型训练的核心挑战在于路由器稳定性,其本质源于两种竞争梯度间的博弈:
- 语言建模损失(LM):驱动专家专业化(将token分配至最合适的专家)
- 辅助负载均衡损失(LB):强制路由均匀性(在专家间平均分配token)
当LB梯度占主导时,所有专家的路由器参数会趋同,导致路由决策与输入token无关。这会抵消条件计算的优势,严重损害模型性能。
我们提出包含两项核心指标的监测框架:
- 路由器权重相似度:计算专家权重向量{wi}的平均成对余弦相似度,高相似度直接表明负载均衡损失过度主导
- 梯度范数比(Rg):量化两种损失对批次平均专家概率向量 P的相对影响,其中LLB为未乘以系数α的负载均衡损失
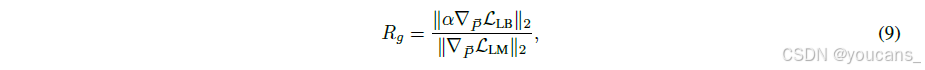
基于此框架,我们制定了超参数 α 的设置原则:确保负载均衡项作为正则器而不压制LM损失。建议选择使Rg保持较小阈值(如Rg<0.1)的系数。
基于隐藏 z-loss 的激活稳定性
受路由器 z-loss 启发[Zoph et al., 2022],我们设计隐藏z损失以抑制大语言模型训练中的异常大激活现象[Sun et al., 2024]。实证表明,此类大激活与训练中的严重损失峰值相关,会导致优化不稳定和性能下降。该损失函数通过抑制极大值元素实现稳定:
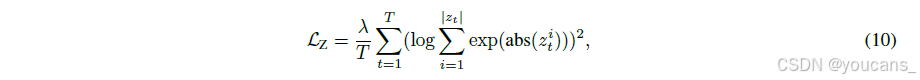
其中:λ为损失权重系数,zt 为第t个token的最终层输出(未归一化),|zt|为隐藏状态规模,abs(·)为绝对值函数
如 图6 所示,极小的损失系数即可显著抑制大激活现象,且不影响正常训练损失,从而降低 BF16 训练时的数值误差风险。
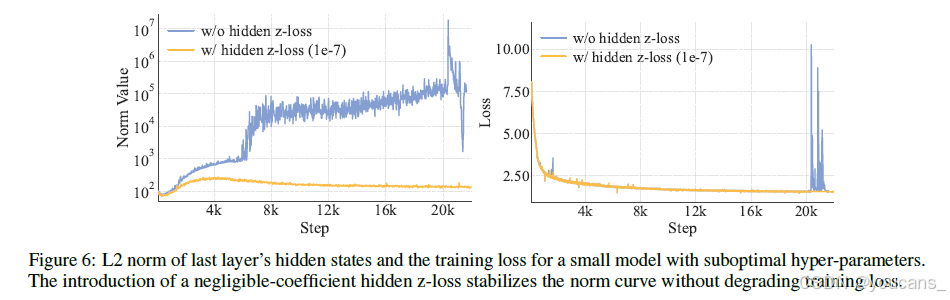
Adam优化器ε参数的实践配置
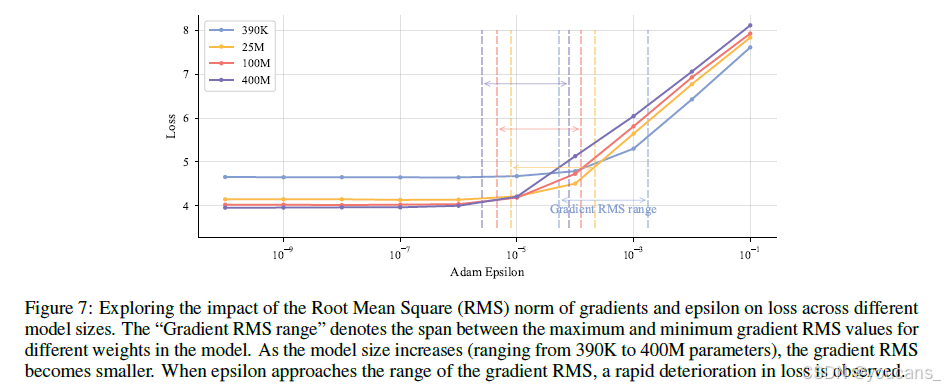
随着模型规模增大,Adam优化器中传统视为数值稳定常数的ε参数成为关键超参数。OLMo等[2024]证明,相比默认值1e-5,设为1e-8能获得更优结果。这种敏感性源于:(1)大规模模型通常采用更小的参数初始化,(2)训练时使用极大批次规模。
当ε值接近梯度二阶矩的典型量级时,会破坏优化器的自适应机制(如图7所示)。我们的梯度RMS范数追踪实验揭示:
(1)阈值效应:当ε接近梯度RMS范数时性能显著下降
(2)下界稳定性:ε低于临界阈值后,继续减小对性能影响可忽略
因此建议将ε设为远小于预期梯度RMS范数的极小值(如1e-16)。LongCat-Flash采用ε=1e-16,在保证数值稳定性的同时保留优化器自适应特性。
3.2 通用预训练
我们首先进行通用预训练阶段以确保模型的基础能力。采用多阶段数据处理流程来保证数据质量与多样性,主要环节包括:
-
内容提取
使用定制版trafilatura [Barbaresi, 2021]处理通用网页内容,针对STEM材料设计专用解析流程以正确处理公式、代码和表格等复杂元素。 -
质量过滤
实施两级过滤:初级分类器剔除明显低质量文档,后续基于流畅度和内容完整性等指标进行细粒度筛选。 -
去重处理
采用高效MinHash实现大规模去重,并辅以网页模板识别策略实现更精确的文档级去重。
最终数据混合采用两阶段调度策略,逐步提升高质量推理数据(如STEM和代码)的占比:
-
阶段 1:
通用数据采用SampleMix [Xi et al., 2025]描述的实例级混合策略,通过质量与多样性分数计算初始采样分布,并基于细粒度领域和写作风格标签进一步调整分布倾向:冗余低价值领域(如广告、体育、招聘)降采样,高推理密度领域(如科学)升采样 -
阶段 2:
优先处理推理密集型领域,STEM与代码数据占最终混合比例的70%。预实验表明通用数据骤减会暂时降低模型能力,因此采用渐进式代码占比提升策略,并通过外部验证集的持续困惑度监测确保平稳过渡。
3.3 推理与代码增强
为强化模型推理与编码能力,建立具备后续训练潜力的强健基模型,我们利用预训练数据检索与数据合成相结合生成的高质量相关数据开展中期训练。
系统性合成数据工作流通过三大机制优化数据质量与多样性:
- 知识图谱遍历与节点组合:确保概念复杂度与领域覆盖
- 多阶段迭代优化:逐步提升难度水平与思维链(CoT)推理质量
- 双模态生成验证(文本与计算):保证数学精确性与解有效性
通过基于规则和模型的联合过滤进行严格质量控制,最终数据集规模达数千亿token。
3.4 长上下文扩展
我们采用两阶段上下文长度扩展策略以满足后续长上下文推理和智能体训练需求。第一阶段使用800亿训练token将上下文窗口从8k扩展到32k,同时将RoPE基频[Su et al., 2024]从1,000,000提升至5,000,000。第二阶段通过额外200亿token进一步扩展至128k,并将基频增至10,000,000。
训练语料基于自然长文本数据(如优质书籍和小说)构建。此外,我们开发了系统化的代码仓库级组织方法以增强模型长上下文能力:精选高质量代码仓库,通过多级过滤流程移除非文本内容、构建产物和自动生成代码,最终构建200亿token的精选长上下文预训练数据集。
为保障模型通用能力在长度扩展期间保持稳定,我们采用与主预训练阶段相同的数据混合策略,并额外增加25%长上下文数据以提升模型长上下文性能。
3.5 数据净化
我们对所有训练数据实施严格净化以防止常见基准测试集的数据泄露:
网页与代码数据:移除与预定义测试集存在13-gram重叠的文档
合成数据与问答对:采用基于BGE-m3语义嵌入的更严格策略[Chen et al., 2024],满足以下任一条件即弃用:
(1) 与测试案例语义相似度>0.9
(2) 词汇重叠(稀疏嵌入测量)且相似度在0.7-0.9之间
3.6 评估
本节对LongCat-Flash基模型进行系统评估,包括方法论与结果。
3.6.1 评估基准与配置
评估涵盖四大核心能力:通用任务、通用推理、数学推理和编程。使用的基准包括:
- 通用任务:MMLU [Hendrycks et al., 2021a]、MMLU-Pro [Wang et al., 2024b]、C-Eval [Huang et al., 2023]、CMMLU [Li et al., 2023a]
- 推理任务:GPQA [Rein et al., 2023]、SuperGPQA [M-A-P Team, ByteDance., 2025]、BBH [Suzgun et al., 2023]、PIQA [Bisk et al., 2019]、DROP [Dua et al., 2019]、CLUEWSC [Xu et al., 2020]、WinoGrande [Sakaguchi et al., 2019]
- 数学任务:GSM8K [Cobbe et al., 2021]、MATH [Hendrycks et al., 2021b]
- 编程任务:MBPP+ [Liu et al., 2024b]、HumanEval+ [Liu et al., 2024b]、MultiPL-E [Cassano et al., 2022]、CRUXEval [Gu et al., 2024]
- 对比模型包括顶尖开源MoE基模型:DeepSeek-V3.1 Base [DeepSeek-AI et al., 2025]、Llama-4-Maverick Base [Meta AI, 2025]、Kimi-K2 Base [MoonshotAI, 2025]。
为确保公平性,所有模型在相同流水线和配置下评估。对无法复现的少数结果,我们直接采用公开报告指标并在表2中明确标注。评估设置如下:
- 通用/推理/数学任务:使用少量示例提示引导输出格式,通过准确率或F1分数衡量性能
- HumanEval+与MBPP+:遵循OpenAI推荐设置[Chen et al., 2021]
- MultiPL-E:遵循BigCode评估工具链[Ben Allal et al., 2022]
- CRUXEval:采用官方配置1,使用2-shot示例
3.6.2 评估结果
表2 展示了各基准测试的评估结果。LongCat-Flash基模型在激活参数/总参数量更精简的情况下,性能与顶尖基模型相当。虽然Llama-4-Maverick的激活参数和总参数量更少,但LongCat-Flash基模型在几乎所有基准上均实现超越。
对比分析表明:尽管参数量更少,LongCat-Flash基模型在所有领域均达到DeepSeek-V3.1基模型的性能水平。两模型在通用任务表现相近,但LongCat-Flash基模型在MMLU-Pro(含高难度题目)上优势显著;在推理任务中平均得分更高;数学与编程任务上大多数基准领先,仅在CRUXEval和MultiPL-E存在微小差距。相较Kimi K2基模型,LongCat-Flash在通用任务稍逊,但在推理、数学及编程任务上达到持平或更优表现。
这些结果共同印证了LongCat-Flash基模型的参数效率优势——在多数评估基准中,其性能与更大规模的模型相当或更优。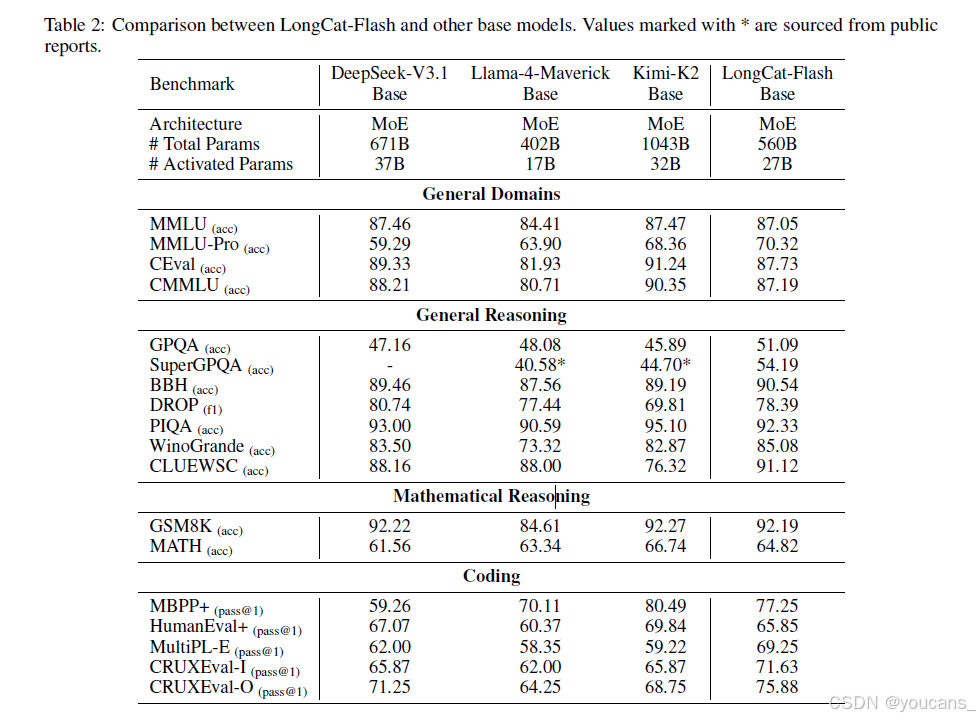
4. 后训练
我们采用常规的多阶段后训练框架来增强基模型在多个领域的性能,涵盖复杂推理、编程、智能体工具使用任务以及通用能力。在此过程中,我们发现高质量问题集的有限可用性是所有领域的主要瓶颈。后续章节将按三个独立阶段呈现我们从后训练方法中获得的关键洞见:(1)推理与编程,(2)智能体工具使用,(3)通用能力提升。
4.1 推理与编程
-
数学领域
我们采用角色设定[Ge et al., 2024]和自指令[Wang et al., 2022]范式生成高质量新颖问题。该过程由覆盖初级到高级数学主题的综合性框架指导,通过多样化数学"专家"角色提问,引导大语言模型合成涵盖冷门领域的查询。每个查询均设计为激发思维链(CoT)推理,促使生成答案呈现逐步解题过程。角色构建与答案验证细节如下:-
角色构建:从多源创建角色——基于高质量预训练数据生成、从现有数学查询衍生、整合Persona Hub相关集合。每个角色均按STEM学科系统标注,使用MinHash算法筛选最终角色集以确保最大多样性及与学科框架对齐。
-
答案验证:采用两阶段流程确保合成解法的准确性:(1) 用多个大模型生成问题答案,选择最一致的解法作为最终答案;(2) 训练专为推理数据优化的生成式奖励模型,自动评分并验证解题步骤的逻辑严密性。
-
-
编程领域
我们整合多源编程查询,包括公开数据集、GitHub代码片段[Wei et al., 2024]与编程论坛生成的查询,以及通过代码进化指令法[Luo et al., 2024]演化的查询。数据分布按主题多样性与难度平衡,训练模型筛选具备清晰性、一致性、正确性及充分解释细节的查询,并通过过滤管道剔除含乱码、重复模式或逻辑错误的响应。
针对软件工程任务,我们整理并验证数万个含测试案例的Docker镜像,每个镜像用于检验模型生成代码能否解决对应仓库的特定问题。开发基于智能体的系统,利用各类工具自主分析代码结构、定位相关文件、修复漏洞及实现新功能,产生数千条通过全部测试的成功轨迹,从而提升模型解决实际软件工程问题的能力。 -
逻辑推理
构建覆盖演绎、假设与归纳推理的数据集,包含LogicPro[Jiang et al., 2025]、PODA[Wang et al., 2025b]及斑马谜题等任务。通过Pass@k指标初调难度,过滤先进思维模型失败的棘手问题,并将选择题转为填空形式以减少随机猜测。响应评估聚焦四大要素:(1) 最终答案正确性;(2) 推理完整性与清晰度;(3) 避免过度重复;(4) 语言一致性。
4.2 智能体工具使用
我们将智能体任务定义为通过系统化环境交互解决复杂问题。在此范式中,模型需迭代分析现有信息并判断何时需环境交互。具体而言,在工具使用框架下,环境由用户与工具构成:
- 用户作为自主信息提供实体,无上下游依赖但具有厌恶打扰与非自发信息披露特性,模型需最小化询问并采用策略性提问获取精确信息。
- 工具可高频调用但存在复杂互依关系。
排除领域专业知识后,我们将任务难度升级归因于三维度:
- 信息处理复杂度:需复杂推理整合转换信息
- 工具集复杂度:通过工具依赖有向图的节点基数与边密度量化
- 用户交互复杂度:需适配多样化对话风格、沟通意愿与信息披露模式进行低频次多轮策略提问
基于此构建多智能体数据合成框架,系统性生成涵盖工具集复杂度、信息处理复杂度与用户交互复杂度的挑战性任务。框架包含以下专项智能体:
-
用户画像智能体:除生成基础画像外,精确控制对话风格、沟通意愿与信息披露模式以增强任务复杂性
-
工具集智能体:参照Kimi-K2[Team et al., 2025]方法,枚举40个领域下的1,600个应用,构建80,000个模拟工具形成工具图,通过随机游走采样预定节点数的子图
-
指令智能体:按约束复杂度、推理点数量与推理链长度量化难度,要求基于工具集生成完整任务描述
-
环境智能体:根据用户画像与指令补充物品细节、位置、时间及气象条件,引入混淆元素增加推理复杂度
-
评分智能体:建立任务相关检查清单,采用滑动窗口评估长上下文轨迹
-
验证与去重智能体:多角度检测任务质量并剔除相似项
利用这些高质量挑战任务,我们严格筛选响应构建冷启动训练集,确保模式多样性与高探索能力,并精选子集进行深度后训练以保证每项任务的探索价值。
4.3 通用能力
-
指令遵循
我们构建了包含单轮和多轮的指令遵循数据集,涵盖不同约束复杂度与数量层级的任务。针对多约束查询,采用Ye等人[2025]提出的方法过滤语义质量低或存在约束冲突的查询。对于不同查询类型,综合运用可验证规则、基于模型的验证及定制化策略,确保响应满足所有约束条件。同时编制针对挑战性任务的批判性数据集,以增强模型批判性思维能力[Wang et al., 2025c]。我们发现某些约束类型天然难以遵循,直接生成有效问答对可靠性不足,为此提出逆向提示生成策略:从已确保满足约束的预设答案反推生成查询。 -
长上下文处理
为提升模型在复杂长上下文中的信息识别与分析能力,开发三类长序列数据集:阅读理解、基于表格的问答及定制化任务。通过聚合主题相关的上下文片段构建数据,重点增强模型的多跳推理、多轮对话及复杂计算能力。针对不完整上下文导致的幻觉问题,优化模型拒绝能力,强化其知识边界意识。 -
安全性
基于Mu等人[2024]框架并遵循内部内容准则,制定分级安全策略:将查询归类至40余种安全类别,对应五种响应类型(合规执行、准则化执行、柔性拒绝、准则化柔性拒绝、硬性拒绝)。通过明确标准确保每类响应符合安全规范。该系统作为上下文感知的数据合成器分两阶段运作:- 查询分类:对开放域语料、内部风险报告、政府问答及对抗性红队内容等多元来源的查询,采用人工校验的自动标注进行安全分类
- 响应映射与优化:将分类查询映射至响应类型,生成经人工评估的优化响应作为训练目标
4.4 评估
我们对后训练阶段的LongCat-Flash进行了全面严格的评估,具体涵盖通用领域、指令遵循、数学推理、通用推理以及编程与智能体任务等多个维度。
4.4.1 评估基准与配置
采用的评估基准包括:
- 通用领域:MMLU [Hendrycks et al., 2021a]、MMLU-Pro [Wang et al., 2024b]、ArenaHard [Li et al., 2024a,b]、CEval [Huang et al., 2023]和CMMLU [Li et al., 2023a]
- 指令遵循:IFEval [Zhou et al., 2023]、COLLIE [Yao et al., 2024]和Meeseeks [Wang et al., 2025a]。Meeseeks通过模拟真实人机交互的迭代反馈框架,评估模型在多轮场景下的指令遵循与自我修正能力
- 数学推理:MATH500 [Lightman et al., 2023]、AIME24/25 [MAA, 2024/2025]及BeyondAIME [ByteDance-Seed, 2025]
- 通用推理:GPQA-diamond [Rein et al., 2023]、DROP [Dua et al., 2019]、ZebraLogic [Lin et al., 2025]和GraphWalks [OpenAI, 2025a]
- 编程:Humaneval+/MBPP+ [Liu et al., 2024b]、LiveCodeBench [Jain et al., 2025]、SWE-Bench-Verified [Jimenez et al., 2024]和TerminalBench [Team, 2025a]
- 智能体工具使用:τ²-Bench [Barres et al., 2025]、AceBench [Chen et al., 2025]及自建基准VitaBench。VitaBench基于美团真实业务场景构建,重点评估三项复杂度:工具集复杂度(平均每任务30+工具的高密度工具图)、推理复杂度与用户交互复杂度(平均60+轮次挑战性对话)
安全评估覆盖四大风险类别:
- 有害内容(暴力、仇恨言论等)
- 违法犯罪(恐怖主义、未成年违规等)
- 虚假信息(错误实践、幻觉等)
- 隐私侵犯
对比模型包括DeepSeek-V3.1、Qwen3-235B-A22B(2507版)、Kimi-K2、GPT-4.1、Claude4-Sonnet和Gemini2.5-Flash,闭源模型通过官方API评估。
4.4.2 评估结果
如表3所示,LongCat-Flash展现出全面领先优势:
- 通用领域
ArenaHard-V2得分86.50(第二)
MMLU 89.71/CEval 90.44,参数量更少情况下媲美顶尖模型 - 指令遵循
IFEval 89.65(第一)
COLLIE 57.10/Meeseeks-zh 43.03均居首 - 数学推理
AIME25 61.25/BeyondAIME 43.00达到顶尖竞赛水平 - 通用推理
ZebraLogic 89.30(前三)
DROP 79.06显示阅读理解优势 - 编程
TerminalBench 39.51(第二)
SWE-Bench-Verified 60.4表现亮眼 - 智能体工具
VitaBench 24.30(第一)
τ²-Bench显著领先大参数模型 - 安全性
在有害内容与违法犯罪识别方面表现尤为突出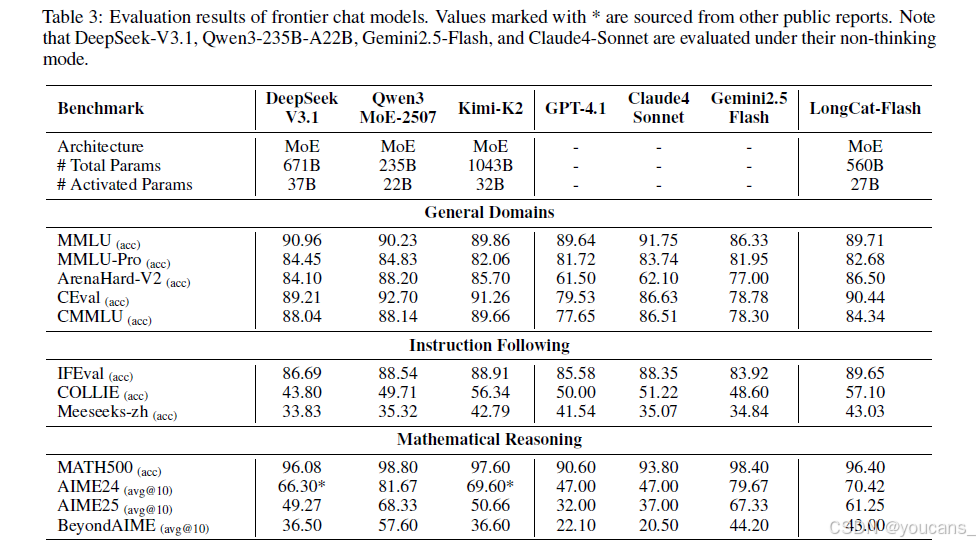
5. 训练基础设施
我们训练基础设施的核心设计原则是可扩展的精确性。通过开发系统性算子精度验证方法,并将静默数据损坏(SDC)检测嵌入空闲计算阶段,最大限度降低了数值误差。为确保实验复现性及小规模测试与全量训练结果的一致性,我们在所有计算和通信算子中强制实现确定性,使得任意训练步骤的多次重跑都能获得比特级对齐的损失值。
在确保正确性的基础上,我们重点优化训练效率。虽然单加速器算力有限,但通过模型-系统协同设计、多维并行策略以及全自动故障检测恢复机制,我们在数万加速器集群上实现了近线性扩展(98.48%可用性),最终在30天内完成训练。
5.1 数值精度控制与故障检测
-
ULP评估
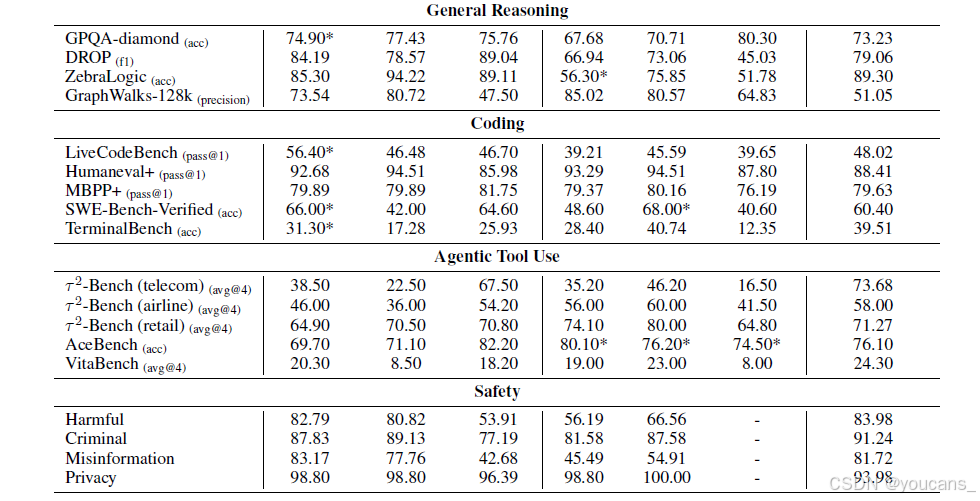
浮点误差受多因素影响,甚至同厂商不同代际加速器间也存在差异。采用末位单元误差(ULP)作为量化指标:ULP误差衡量加速器BF16结果与CPU FP32基准值的偏差,零值表示完全精确。我们统计训练中所有算子类型及形状的ULP误差,表4展示两种解决方案的GEMM算子ULP对比。 -
SDC检测机制
大规模训练中难以避免的SDC故障会无声篡改数据,严重损害模型性能。为此我们设计高效的片上原位算子重算机制:- 发现FlashAttention梯度(FAG)的反向计算对SDC最敏感(同时涉及张量与向量运算)
- 通过重算结果的比特差异识别潜在SDC风险
- 检测计算被编排在计算流中,重算间隔可手动调节以实现检测覆盖与计算成本的灵活权衡
需特别指出,算子精度控制对模型准确性保障是必要但不充分的。实验表明:不同算子实现可能仅导致1e-3∼1e-4的训练损失差异,但基准测试性能波动超过5个百分点。如何经济高效地评估算子精度误差对模型性能的影响,仍是待解难题。
5.2 确定性内核与性能优化
确定性是计算正确性的黄金标准,可消除浮点误差对实验的干扰。我们通过内核重设计在LongCat-Flash训练中实现全链路确定性计算与通信,同时规避性能损耗。
-
确定性FAG
标准FAG实现因dQ/dK/dV沿不同维度归约时原子加操作无序而具有不确定性。我们开发的新型确定性内核通过有限额外工作空间实现分块有序累积,结合双缓冲流水线、调优分块策略与负载均衡技术,性能达原始确定性版本的1.6倍,逼近非确定性版本的95%。 -
确定性ScatterAdd
反向传播中的ScatterAdd对梯度聚合至关重要,但标准实现因输入输出操作数不匹配导致单计算单元串行执行(速度下降达50倍)。采用分层归约算法实现全处理器并行梯度聚合,性能与非确定性版本持平。 -
优化分组GEMM
针对分组GEMM计算量大但密度低的特点:双缓冲流水线重叠计算、内存I/O与收尾操作。对角线分块缓解L2缓存冲突。通过计算单元限制控制HBM带宽,实现分组GEMM与通信调度重叠。较基础版本提速5%-45%。 -
融合GemmAdd
在梯度累积阶段,dw计算受带宽限制。我们将FP32加法融合至GEMM收尾阶段,避免中间写回并隐藏分块流水线内的加法操作,延迟降低3.12-3.86倍,同时消除BF16数据转存HBM的精度损失。
此外,对IO密集型内核(如MoE层置换/逆置换)进行重构,集成token丢弃与零计算专家处理功能,兼顾确定性与性能。
5.3 大规模训练分布式策略
训练架构以专家并行组(EP Group,含32加速器)为核心单元:
-
组内架构:注意力层采用上下文并行(CP=8)替代张量并行(TP)降低通信开销,FFN层仅使用EP分区
-
组间扩展:沿流水线并行(PP)与数据并行(DP)维度扩展
-
专家并行优化
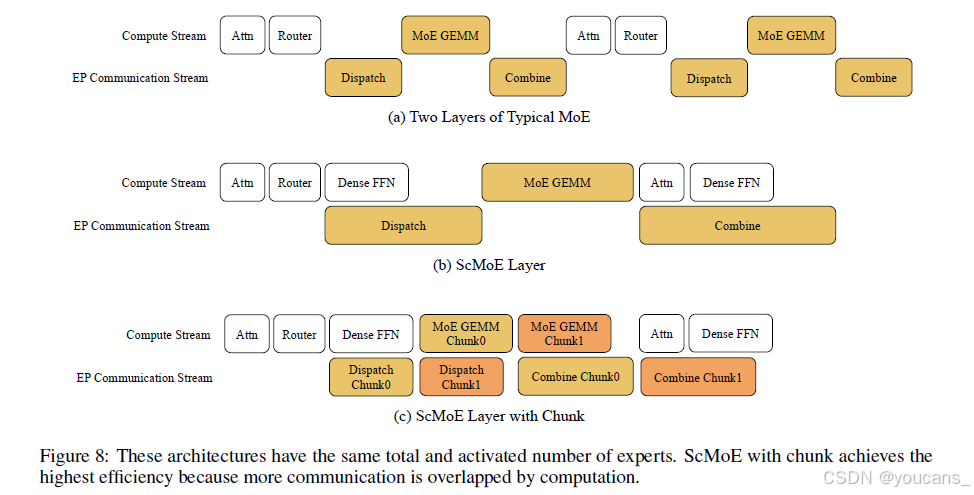
EP虽降低静态内存占用(含权重与优化器状态),但引入高成本调度-组合通信。LongCat-Flash采用ScMoE结构实现两大创新:
1、单批次内通过增加计算量实现通信重叠
2、沿token维度将MoE层分块,既与稠密FFN计算重叠,又实现子块间相互重叠(见图8) -
通信策略优化
针对调度-组合通信提供两种优化方案:
1、节点内/间流水线化all-gather/reduce-scatter内核
2、优化all-to-all内核
原生all-to-all会使本地数据量膨胀top-k倍,导致200Gb/s加速器RDMA网络拥塞。最终选择确定性流水线all-gather/reduce-scatter方案,配合ScMoE架构将非重叠通信时间占比从25.3%降至8.4%。 -
流水线内存平衡
现有策略(1F1B、交错1F1B、零气泡等)存在各流水线阶段内存不均衡问题。采用V-ZB算法[Qi et al., 2024]实现:
1、全阶段内存均衡(峰值内存压降至60GB内)
2、结合零气泡的后验证策略达成理论零气泡
关键改进:优化器状态回滚时采用上一步备份数据替代逆运算,保持数值比特级对齐。
5.4 可靠性与可观测性
可靠性通过有效训练时间占比(可用性)衡量,不可用时间包括故障恢复及最近检查点与故障发生间的无效时段。异步检查点技术将训练停滞缩短至2∼4秒,支持更高频检查并最小化故障损失。结合在线关键日志过滤、优化初始化及全自动化流程,恢复时间压缩至<10分钟。该机制实现98.48%可用性,全部20次故障均自动处理无需人工干预。
可观测性体系整合细/粗粒度剖析与指标平台:
- 细粒度PyTorch性能分析器支持分布式并行感知协同分析,识别流水线并行"气泡"与跨节点通信等待
- 粗粒度监控实施低开销的落后节点运行时分析
- 指标平台持续追踪损失值、权重、梯度及激活值,实现模型状态快速评估
6. 推理与部署
LongCat-Flash采用模型-系统协同设计,显著提升了高吞吐与低延迟性能。本节重点介绍我们在某个部署集群中实施的推理优化方案,实现在H800上同时提升系统吞吐量并将延迟显著降低至100 TPS的方法。我们首先展示与模型架构协同设计的并行推理架构,随后阐述量化、定制内核等优化方法,最后呈现部署策略与性能结果。
6.1 模型专属推理优化
要实现高效推理系统,需要解决两大关键挑战:(1) 计算与通信协同编排;(2) KV缓存I/O与存储。针对第一项挑战,现有方法通常采用三种传统粒度的并行:
- 算子级重叠(如NanoFlow[Zhu等,2025])
- 专家级重叠(以EPS-MoE[Qian等,2025]为代表)
- 层级重叠(DeepSeek-V3 TBO[团队,2025b]演示)
LongCat-Flash的ScMoE架构创新性地引入第四维度——模块级重叠,为此我们设计了SBO(单批次重叠)调度策略来同步优化延迟与吞吐。针对第二项KV缓存I/O与存储挑战,LongCat-Flash通过注意力机制和MTP结构的架构创新来降低有效I/O开销。
6.1.1 计算与通信编排
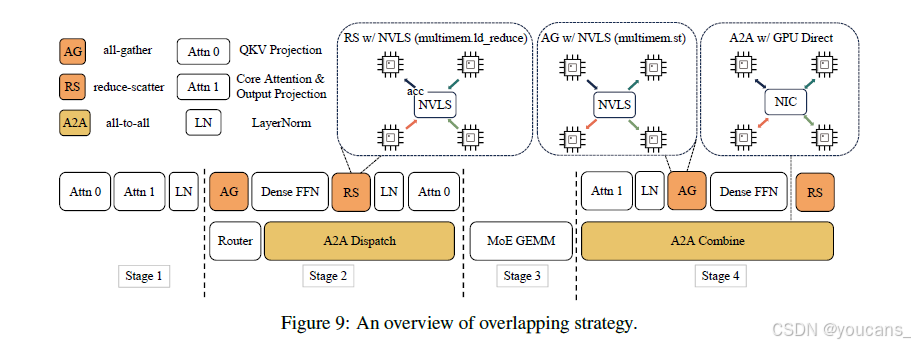
LongCat-Flash在其结构中天然具备计算-通信重叠特性,这是实现更低延迟同时保持生成吞吐量的关键。我们精心设计了单批次重叠(SBO)——一种四阶段流水线执行方案,通过模块级重叠充分释放LongCat-Flash潜力(如图9所示)。SBO与TBO的不同之处在于它将通信开销隐藏在单个批次内。
在SBO中:
- 阶段1需要单独执行,因为MLA输出作为后续阶段的输入
- 阶段2我们将all-to-all调度与Dense FFN及Attn 0(QKV投影)重叠
- 阶段3独立执行MoE GEMM
- 阶段4我们将Attn 1(核心注意力与输出投影)和Dense FFN与all-to-all组合重叠
此外,ScMoE架构在宽EP部署方案下,通过GPUDirect RDMA[Choquette, 2022]实现了节点内NVLink带宽利用与节点间RDMA通信的重叠。Dense FFN在ScMoE中具有较大的中间尺寸,因此采用TP部署来最小化内存占用,这需要在Dense FFN前后分别进行all-gather和reduce-scatter通信。
6.1.2 推测解码
LongCat-Flash采用MTP作为推测解码的草稿模型。我们的优化框架源于对推测解码加速公式的系统性分解,如Sadhukhan等人[2025]所述:
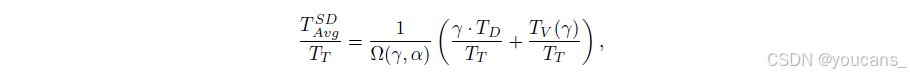
其中,TSDAvg、TT、TD分别表示推测解码、目标模型和草稿模型的单token预期延迟。γ代表单次解码步骤中的草稿token数量,Ω(γ, α)表示给定γ和接受率α时的预期接受长度,TV(γ)则是目标验证的预期延迟。我们的方法聚焦三个关键因素:
-
预期接受长度Ω(γ, α):与草稿token接受率α正相关。为最大化α,我们采用MTP(Multi-Token Prediction)技术,在预训练后期集成单一MTP头部,在测试集上实现约90%的接受率。
-
草稿与目标成本比γ·TD/TT:由目标模型和草稿模型结构决定。如Liu等人[2024c]所述,平衡草稿质量与速度至关重要。LongCat-Flash采用轻量级MTP架构减少参数量,在保持可比接受率的同时最小化生成开销。实验数据(表5)显示,采用单稠密层作为MTP头部能最优权衡时延,表现优于ScMoE层。
-
目标验证与解码成本比TV(γ)/TT:为降低该比值,我们采用C2T方法[Huo等,2025],使用分类模型在验证前过滤低概率被接受的token。

6.2 系统级推理优化技术
6.2.1 最小化调度开销
大语言模型推理系统的解码阶段可能因内核启动开销而受限于调度瓶颈。该问题在采用推测解码时尤为突出——特别是对于LongCat-Flash的轻量级MTP架构,其验证内核与草稿前向传播的独立调度会引入显著开销。为缓解此问题,我们采用TVD融合策略,将目标模型前向传播(Target forward)、验证(Verification)和草稿模型前向传播(Draft forward)融合为单一CUDA计算图。
为进一步提升GPU利用率,我们实现了重叠调度器。然而实验结果表明,LongCat-Flash前向传播的低延迟特性使得单步预调度策略仍无法完全消除调度开销。如图10所示,我们引入多步重叠调度器,在单次调度迭代中启动多步前向传播的内核。该方法有效将CPU调度与同步过程隐藏在GPU前向计算中,确保GPU持续占用。
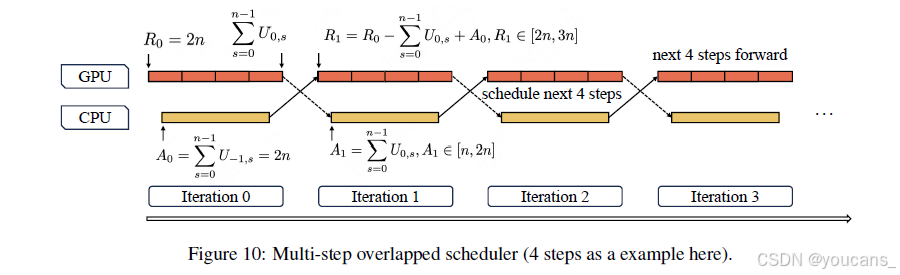
在多步重叠调度器中,我们需要动态预分配未来多个步骤的KV缓存槽位,而无需预知前次迭代中推测解码的接受长度。一个关键问题在于:多步重叠调度是否会导致KV缓存分配的差异性。我们以MTP=1且步骤数n=4为例进行说明:
设R_i表示GPU第i次迭代前向传播时的可用KV条目数,则初始值R_0 = (MTP + 1) × n = 2n。U_i,s ∈ [1, 2]表示第i次迭代中第s步的接受长度,其初始值U_-1,s = 2。当GPU执行第i次前向计算迭代时,调度器基于第(i-1)次前向迭代的接受长度,预分配第(i+1)次前向迭代所需的KV缓存槽位,其中A_i表示被分配的KV缓存槽位。
通过数学归纳法可证明,该方案即使在不知晓当前迭代接受长度的情况下,仍能确保为下一迭代安全分配KV缓存,同时保证分配的KV缓存大小最终收敛。
6.2.2 定制化内核
大语言模型推理的自回归特性带来了独特的效率挑战。预填充阶段受计算能力限制,采用分块预填充[Agrawal等,2023]等方法可规范化数据以实现最优处理。相比之下,解码阶段由于流量模式导致的小批量不规则数据而常受内存带宽限制,严重影响内核性能。因此,优化这些特定场景对最小化单token输出时延(TPOT)至关重要。
-
MoE矩阵乘法
现有库如DeepGEMM[Zhao等,2025a]将模型权重映射为k/n维对齐的右矩阵(B,满足A×B=C),而输入激活值则作为左矩阵映射至m/k维(其中m表示token数量)。当token数低于m维的64元素最小值时,这种传统方法需要填充。为解决此低效问题,我们采用SwapAB[Dege等,2025]技术:将权重视为左矩阵,激活值作为右矩阵。通过利用n维灵活的8元素粒度,SwapAB实现了张量核心利用率最大化。 -
通信内核
如图9所示,推理系统利用NVLink Sharp的硬件加速广播(multimem.st)和交换机内归约(multimem.ld_reduce)来最小化数据移动和SM占用率。通过内联PTX汇编实现的归约-分散和全收集内核可实现高效数据传输。这些内核支持GPU间均匀与非均匀的token分布,在4KB至96MB消息大小范围内持续优于NCCL[NVIDIA]和MSCCL++[Shah等,2025],且仅需4个线程块。
6.2.3 量化
LongCat-Flash采用与DeepSeek-V3相同的细粒度分块量化方案:激活值按[1,128]分块,权重按[128,128]分块。此外,为实现最优的性能-精度权衡,我们基于两种方法应用了分层混合精度量化:
第一种方案延续了我们在FPTQ[Li等,2023b]和Super-Expert[Su等,2025]中的方法,观察到某些线性层(特别是Downproj)的输入激活值存在高达10^6的极端幅值。
第二种方案逐层计算分块FP8量化误差(包括相对误差和绝对误差),发现特定专家层的量化误差显著。通过取两种方案的交叉验证,我们实现了显著的精度提升。
6.3 部署与性能表现
6.3.1 实测性能数据
为实现预填充阶段与解码阶段的独立优化,我们采用PD解耦架构(Prefill-Decode Disaggregated)。该设计的关键挑战在于KV缓存从预填充节点传输至解码节点的开销。为此,我们实现了分层传输机制,显著降低了高QPS(每秒查询数)工作负载下的首token延迟(TTFT)。预填充与解码节点的最小部署单元为2个节点(含16块H800-80GB GPU)。同时,通过部署DeepEP[Zhao等,2025b]的宽域专家并行(Wide EP)以最小化通信开销。此外,我们还改进了DeepEP与专家并行负载均衡器(EPLB),新增对零计算专家(zero-computation experts)的支持——此类专家的输出无需通信即可获取。
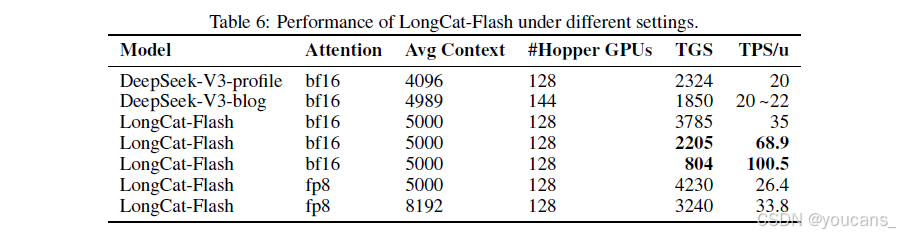
表6对比了LongCat-Flash与DeepSeek-V3(数据来源:DeepSeek-V3-profile[DeepSeek,2025a]和DeepSeek-V3-blog[DeepSeek,2025b])的吞吐量与延迟指标:
TGS(每GPU每秒生成token数):反映单设备生成吞吐量(值越高成本越低)
TPS/u(每用户每秒token数):表征单用户生成速度(值越高越好)
测试采用固定序列长度下的稳态生成吞吐量进行计算。结果表明,LongCat-Flash在不同序列长度下均实现了更高的生成吞吐量与更快的响应速度。
在基于ReACT范式[Yao等,2023]的智能体应用中,单任务完成需要多轮模型交互,其响应延迟直接影响用户体验。通过分析典型智能体调用模式,我们发现模型输出存在差异化速度需求:
- 推理内容(用户可见):包含思维链与解释说明,需匹配人类阅读速度(≥20 token/s)
- 动作指令(用户不可见):如函数名、参数等结构化数据(通常30~100 token),其生成速度直接影响工具调用启动时间,要求尽可能高的吞吐
针对此场景,LongCat-Flash在动作指令场景可实现近100 token/s的生成速度。按H800 GPU每小时2美元的成本假设,折合每百万输出token成本0.7美元。该性能将单轮工具调用延迟控制在1秒内,显著提升智能体应用的交互体验。
6.3.2 理论性能
如图9所示,LongCat-Flash的延迟主要由三大模块决定:
- MLA(混合专家注意力):其耗时无法通过增加专家并行度(EP)缩减
- 全交互分发/聚合:二者均受单设备批大小与topk值约束
- MoE(混合专家):在内存受限区域的耗时随EP数增加而降低
假设参数配置:EP=128,DeepSeek-V3与LongCat-Flash的MLA采用数据并行(DP),Qwen3-235B-A22B因含4个KV头而使用TP4实现分组查询注意力(GQA),单设备批大小设为96。需说明的是,Qwen-235B-A22B的GQA特性导致其KV缓存内存占用较高,实际难以达到单GPU96的批大小,此处假设仅用于理论分析。参考[Jiashi Li,2025]的测试数据,FlashMLA在NVIDIA H800 SXM5 GPU上可达660 TFlops算力;Zhao等[2025b]指出DeepEP带宽可达40GB/s——这些指标均纳入我们的计算模型。
在H800每小时2美元的成本假设下,考虑MTP=1且接受率80%的条件,我们计算了DeepSeek-V3、Qwen3-235B-A22B和LongCat-Flash单层各模块的理论耗时与成本(见表7)。对于原生不支持MTP的Qwen3-235B-A22B,我们采用具有同等接受率的推测采样策略进行类比估算。
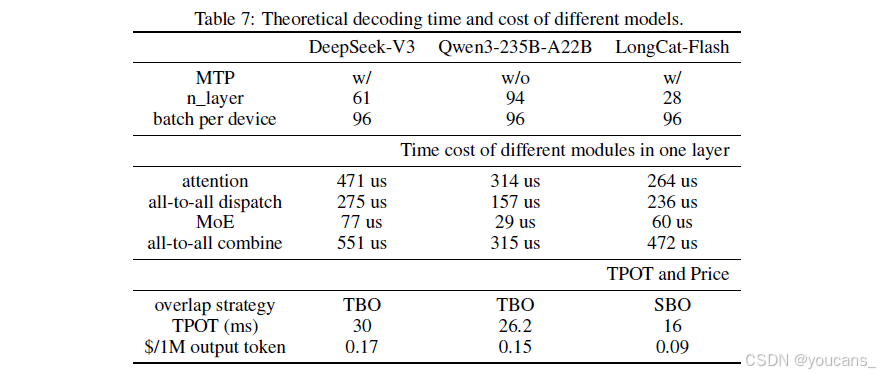
在实际批大小96下的测试结果为TPOT≈26毫秒,约为理论值的61.5%,与DeepSeek-V3(约64%)处于同一水平。实测值与理论速度的差距主要源自小型算子开销及通信带宽损耗。我们采用相同方法计算了DeepSeek-V3和Qwen3-235B-A22B在TBO调度下的TPOT理论极限与生成成本。如表7所示,通过模型-系统协同设计,LongCat-Flash在吞吐量与延迟方面均实现了显著的理论提升。
进一步分析获得两项关键发现:
- (1)LongCat-Flash不仅需要处理全交互通信和MoE计算,还引入了MLA计算环节。因此在相同批大小下,其单层处理时间略长于DeepSeek-V3。但由于总层数大幅减少,整体延迟反而更低。
- (2)LongCat-Flash的第二阶段MLA计算可与全交互聚合操作重叠执行。这意味着在解码阶段,模型可在不显著增加延迟的前提下支持更长的序列长度。
7. 结论
我们提出LongCat-Flash——这个5600亿参数的MoE模型具有三大创新:
- 上下文感知的动态计算机制与短路连接式MoE架构,实现训练与推理的双重高效;
- 保障超大规模训练稳定性的集成策略;
- 培养智能体能力的多阶段训练框架,使其能完成需要迭代推理与环境交互的复杂任务。
通过开源LongCat-Flash,我们期望推动高效MoE架构、优质数据策略以及智能体模型开发的研究,促进大语言模型领域的社区协同创新。
版权声明:
本文由 youcans@xidian 对 美团 LongCat 团队(ongcat-team@meituan.com)技术报告 【LongCat-Flash Technical Report 】进行摘编和翻译。该论文版权属于原文作者,本译文只供研究学习使用。
youcans@xidian 作品,转载必须标注原文链接:
美团龙猫大模型(LongCat-Flash-Chat)2. 技术报告
Copyright 2025 youcans, XIDIAN
Crated:2025-09

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐


 31
31 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)