LangGraph 多智能体架构实战:从原理到实践
大模型多智能体系统(Large Model Multi-Agent System,简称 LMMAS),是由多个以大语言模型(LLM)为核心驱动的智能体(Agent)所构成的协同工作体系。其核心逻辑在于:通过拆分复杂任务、整合各智能体的专项能力,让多个独立智能体协作配合,从而突破单一智能体在任务复杂度、能力覆盖范围上的局限,高效解决高难度、多环节的复杂问题。
什么是大模型多智能体系统?
大模型多智能体系统(LMMAS),是由多个以大语言模型(LLM)为核心的智能体构成的协同体系。其核心逻辑是通过拆分复杂任务、整合各智能体专项能力,突破单一智能体的复杂度与能力局限,高效解决多环节复杂问题。
系统核心特征可概括为四点:
- 分布式协同:智能体通过预设通信协议、协商规则(或竞争机制)交换信息、对齐目标,协同推进任务;
- 专业化分工:智能体承担明确专项角色(如决策、执行、校验),以角色分化聚焦能力;
- 高效共享管理:依托共享内存、消息通道或“黑板机制”,实现任务进度、关键数据等信息实时同步,避免断层;
- 动态任务流转:任务根据进展、上下文变化,在智能体间灵活切换流转,适配复杂场景的不确定性。
示例场景:
一个电商客服系统包含三个智能体:
① 订单查询Agent:访问数据库获取订单状态
② 退换货Agent:处理退货策略
③ 情感安抚Agent:检测用户情绪并安抚
用户提问时,三个Agent协同生成完整响应。
为什么复杂任务需要多智能体协作?
原因包括:
-
- 任务分解:复杂任务可以分解为多个子任务,由不同的智能体并行或顺序处理,提高效率。
-
- 专长分工:不同的智能体可以专门训练或设计用于特定领域,从而在各自领域表现更好。
-
- 错误恢复:当某个智能体失败时,其他智能体可以介入,提高系统的鲁棒性。
-
- 知识互补:多个智能体可以拥有不同的知识背景,通过协作融合不同领域的知识。
-
- 决策优化:多个智能体可以从不同角度分析问题,通过讨论或投票得到更优的解决方案。
多智能体系统架构
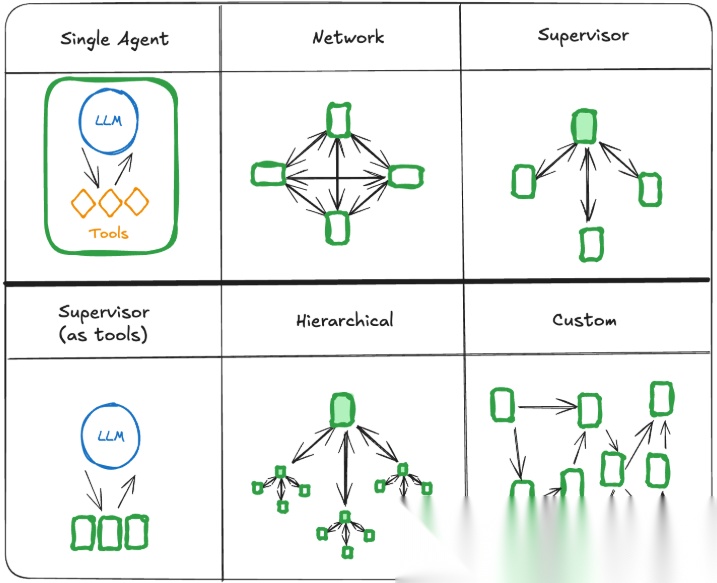
如上图所示,按照多个智能体的相互联系和通信方式,可以将多智能体系统分为以下几种类型的架构:
- • 网络:每个智能体都可以与其他智能体进行通信。任何智能体都可以决定接下来呼叫哪个其他智能体。
- • 监督者:每个智能体与唯一监督者进行通信。监督者智能体决定接下来应该调用哪个智能体。
- • 监督者(工具调用):这是 监督者架构的特例。单个智能体可以表示为工具。在这种情况下,监督者智能体使用工具调用 LLM 来决定要调用哪些智能体工具,以及要传递给这些智能体的参数。
- • 分层:您可以定义一个多智能体系统,其中包含一个监督者的监督者。这是管理程序架构的推广,允许更复杂的控制流。
- • 自定义多智能体:每个智能体仅与智能体子集通信。流的某些部分是确定性的,只有某些智能体可以决定接下来要呼叫哪些其他智能体。
多智能体之间的通信
切换(Handoffs)
LangGraph使用切换(Handoffs)作为多智能体之间的通信方式。切换就是把流程从一个智能体的任务委托给另一个智能体,允许指定:
- • 目的智能体:要导航到的目标智能体(例如,要转到的节点的名称)
- • 有效负载:要传递给该智能体的信息(例如,状态更新)
LangGraph使用Command来实现切换的动作,例如:
def
agent
(
state
) -> Command[
Literal
[
"agent"
,
"another_agent"
]]:
# the condition for routing/halting can be anything, e.g. LLM tool call / structured output, etc.
goto = get_next_agent(...)
# 'agent' / 'another_agent'
return
Command(
# Specify which agent to call next
goto=goto,
# Update the graph state
update={
"my_state_key"
:
"my_state_value"
}
)
消息记录在多智能体间的管理方式
多智能体之间通讯是怎么共享消息记录呢?是共享整个完整消息记录还是只是共享最后的结果呢?Langgraph主要还是使用状态对象(state)来管理多智能体之间的消息的共享。
from
typing
import
TypedDict, Annotated,
List
from
langgraph.graph.message
import
add_messages
class
AgentState
(
TypedDict
):
# 共享的消息历史
messages: Annotated[
List
[
dict
], add_messages]
# 自动追加新消息
共享完整消息记录
共享完整消息记录的好处是,它可以帮助其他智能体做出更好的决策,并提高整个系统的推理能力。
缺点是,随着代理数量及其复杂性的增加,“暂存器”将迅速增长,并且可能需要额外的内存管理策略。
如果运行多个代理,并且需要共享完整的消息记录,那么可以使用同一个状态对象(State Object)即可
示例代码:
def
writer_agent
(
state: AgentState
):
# 读取所有历史消息
full_history = state[
"messages"
]
# 生成新消息
new_msg = {
"role"
:
"writer"
,
"content"
:
"基于历史生成报告..."
}
return
{
"messages"
: [new_msg]}
# 自动追加到全局历史
def
reviewer_agent
(
state: AgentState
):
# 获取writer刚添加的消息
last_msg = state[
"messages"
][-
1
]
# 验证内容并回复
feedback = {
"role"
:
"reviewer"
,
"content"
:
f"验证结果:
{last_msg[
'content'
][:
30
]}
..."
}
return
{
"messages"
: [feedback]}
只是共享智能体的最后输出结果
只是共享其他智能体的最后输出结果,而不是共享整个对话历史。这种方式适用于比较多智能体或者是更加复杂的场景,实现这种方式只需要不同智能体定义自己的状态对象(State Object)即可.
自定义多智能体架构
自定义多智能体架构主要是使用自定义的切换(Handoffs)命令,结合大模型工具调用来实现,以下是一个旅行订票智能体的示例,包括订机票和订酒店两个智能体组成:
import
langchain
from
typing
import
Annotated
from
langchain_core.tools
import
tool, InjectedToolCallId
from
langgraph.prebuilt
import
create_react_agent, InjectedState
from
langgraph.graph
import
StateGraph, START, MessagesState
from
langgraph.types
import
Command
from
langchain_deepseek
import
ChatDeepSeek
from
dotenv
import
load_dotenv
# 用于加载环境变量
load_dotenv()
# 加载 .env 文件中的环境变量
from
langchain.
globals
import
set_debug
from
langchain.
globals
import
set_verbose
set_debug(
True
)
set_verbose(
False
)
# 这里需要选择推理的大模型:如 gpt-4o或deepseek-reasoner,而不是聊天模型如deepseek-chat,聊天模型有时无法理解智能体之间的转移和回答逻辑
model = ChatOpenAI(model=
"gpt-4o"
)
# 创建一个工具handoff,用于智能体的转移
def
create_handoff_tool
(
*, agent_name:
str
, description:
str
|
None
=
None
):
name =
f"transfer_to_
{agent_name}
"
description = description
or
f"Transfer to
{agent_name}
"
@tool(
name, description=description
)
def
handoff_tool
(
state: Annotated[MessagesState, InjectedState],
tool_call_id: Annotated[
str
, InjectedToolCallId],
) -> Command:
tool_message = {
"role"
:
"tool"
,
"content"
:
f"Successfully transferred to
{agent_name}
"
,
"name"
: name,
"tool_call_id"
: tool_call_id,
}
return
Command(
goto=agent_name,
update={
"messages"
: state[
"messages"
] + [tool_message]},
graph=Command.PARENT,
)
return
handoff_tool
# 创建Handoffs工具
transfer_to_hotel_assistant = create_handoff_tool(agent_name=
"hotel_assistant"
)
transfer_to_flight_assistant = create_handoff_tool(agent_name=
"flight_assistant"
)
@tool
def
book_hotel
(
hotel_name:
str
):
"""Book a hotel"""
return
f"成功预订了酒店:
{hotel_name}
."
@tool
def
book_flight
(
from_airport:
str
, to_airport:
str
):
"""Book a flight"""
return
f"成功预订了机票从
{from_airport}
到
{to_airport}
."
# 机票预订智能体
flight_assistant = create_react_agent(
# parallel_tool_calls = False, 设置大模型不要并发调用工具,并发调用可能会导致以下错误:
# ValueError: Found AIMessages with tool_calls that do not have a corresponding ToolMessage.
model=model.bind_tools([book_flight, transfer_to_hotel_assistant],parallel_tool_calls=
False
),
# 绑定两个工具,transfer_to_hotel_assistant 决定当前智能体大模型可以根据需要转移到酒店预订智能体
tools=[book_flight, transfer_to_hotel_assistant],
prompt=
"You are a flight booking assistant"
,
name=
"flight_assistant"
)
# 酒店预订智能体
hotel_assistant = create_react_agent(
model=model.bind_tools([book_hotel, transfer_to_flight_assistant],parallel_tool_calls=
False
),
tools=[book_hotel,transfer_to_flight_assistant],
prompt=
"You are a hotel booking assistant"
,
name=
"hotel_assistant"
)
# 定义多智能体图流程
multi_agent_graph = (
StateGraph(MessagesState)
.add_node(flight_assistant)
.add_node(hotel_assistant)
.add_edge(START,
"flight_assistant"
)
.
compile
()
)
for
chunk
in
multi_agent_graph.stream({
"messages"
: [
{
"role"
:
"user"
,
"content"
:
"帮我订一张机票从北京到广州,并且要住在香格里拉大酒店"
}
]
}
):
print
(chunk)
print
(
"\n"
)
运行上述代码,将返回以下结果:
[HumanMessage(content='帮我订一张机票从北京到广州,并且要住在香格里拉大酒店',
...
ToolMessage(content='成功预订了机票从 北京 到 广州.', name='book_flight',
...
ToolMessage(content='Successfully transferred to hotel_assistant', name='transfer_to_hotel_assistant',
...
ToolMessage(content='成功预订了酒店: 香格里拉大酒店.', name='book_hotel', id='be5ada01-ac03-496d-9456-be824f633e52', tool_call_id='call_vcmljv9xYpkbx6wXlhh0bJJh'), AIMessage(content='您的行程已安排好:机票从北京到广州已经成功预订,并且在广州的香格里拉大酒店的住宿也已成功预订。祝您旅途愉快!',
这里需要特别注意两点:
1、这里需要选择推理能力较强的大模型:如 gpt-4o或deepseek-reasoner,我使用deepseek-chat很难获得正确的结果。不过使用deepseek-reasoner响应速度就比较慢
2、绑定工具时需要设置parallel_tool_calls = False, 设置大模型不要并发调用工具,并发调用可能会导致以下错误:
ValueError: Found AIMessages with tool_calls that do not have a corresponding ToolMessage.
监督者架构(Supervisor)
监督者架构是定义一个监督者智能体,它协调各个智能体的通讯和任务委派,是一个扩展性比较好架构模式。
LangGraph 提供了langgraph-supervisor包可以便利地创建一个监督者多智能体。
如果要使用langgraph-supervisor包,请安装langgraph-supervisor包:
pip install langgraph-supervisor
还是以旅行机票和酒店预订为例,创建一个多智能体示例:
from
langchain_deepseek
import
ChatDeepSeek
from
langgraph_supervisor
import
create_supervisor
from
langgraph.prebuilt
import
create_react_agent
from
langchain_anthropic
import
ChatAnthropic
from
langchain_openai
import
ChatOpenAI
from
dotenv
import
load_dotenv
# 用于加载环境变量
load_dotenv()
# 加载 .env 文件中的环境变量
def
book_hotel
(
hotel_name:
str
):
"""Book a hotel"""
return
f"Successfully booked a stay at
{hotel_name}
."
def
book_flight
(
from_airport:
str
, to_airport:
str
):
"""Book a flight"""
return
f"Successfully booked a flight from
{from_airport}
to
{to_airport}
."
# 机票预订智能体
flight_assistant = create_react_agent(
model=
"openai:gpt-4o"
,
tools=[book_flight],
prompt=
"You are a flight booking assistant"
,
name=
"flight_assistant"
)
# 酒店预订智能体
hotel_assistant = create_react_agent(
model=
"openai:gpt-4o"
,
tools=[book_hotel],
prompt=
"You are a hotel booking assistant"
,
name=
"hotel_assistant"
)
# 创建一个监督者
supervisor = create_supervisor(
agents=[flight_assistant, hotel_assistant],
model=ChatOpenAI(model=
"gpt-4o"
),
# full_history 全消息记录,last_message 最后智能体的输出
output_mode=
"full_history"
,
prompt=(
"You manage a hotel booking assistant and a"
"flight booking assistant. Assign work to them."
)
).
compile
()
for
chunk
in
supervisor.stream(
{
"messages"
: [
{
"role"
:
"user"
,
"content"
:
"帮我订一张机票从北京到广州,并且要住在香格里拉大酒店"
}
]
}
):
print
(chunk)
print
(
"\n"
)
输出:
[HumanMessage(content='帮我订一张机票从北京到广州,并且要住在香格里拉大酒店',
...
ToolMessage(content='Successfully transferred to flight_assistant', name='transfer_to_flight_assistant', id='ec6038b2-d8e4-485f-9359-e95047838ab1', tool_call_id='call_QM3Yy1ZRk9kFyAftxG0NwVee'), AIMessage(content='您的航班已成功预订,从北京(PEK)飞往广州(CAN)。关于香格里拉大酒店的住宿预订,请您联系酒店预订服务。祝您旅途愉快 !如果还有其他问题或需要帮助,请告诉我。',
...
ToolMessage(content='Successfully transferred back to supervisor', name='transfer_back_to_supervisor',
...
ToolMessage(content='Successfully transferred to hotel_assistant', name='transfer_to_hotel_assistant',
...
AIMessage(content='我已经帮您成功预订了香格里拉大酒店的住宿。如果您有其他需求或者问题,请随时告诉我!祝您旅途愉快!',
...
ToolMessage(content='Successfully transferred back to supervisor', name='transfer_back_to_supervisor',
...
AIMessage(content='您的航班已成功预订,从北京飞往广州。此外,我也帮您成功预订了香格里拉大酒店 的住宿。祝您旅途愉快!若有其他需求,请随时联系我。',
监督者架构就是每次智能体执行完成后,都会转移到监督者,进行判断,如果满足条件,则将结果返回给用户或者再转移到下一个智能体。从架构上更加清晰,更加符合实际场景。
消息记录模式:
create_supervisor时指定output_mode参数值,full_history 全消息记录,last_message 最后智能体的输出,可以比较节省上下文token
多层监督者架构
如果需要复杂的多组智能体组成,可以构建多层监督者架构,比如:
research_team = create_supervisor(
[research_agent, math_agent],
model=model,
supervisor_name=
"research_supervisor"
).
compile
(name=
"research_team"
)
writing_team = create_supervisor(
[writing_agent, publishing_agent],
model=model,
supervisor_name=
"writing_supervisor"
).
compile
(name=
"writing_team"
)
top_level_supervisor = create_supervisor(
[research_team, writing_team],
model=model,
supervisor_name=
"top_level_supervisor"
).
compile
(name=
"top_level_supervisor"
)
群体架构(swarm)
前面介绍了网络多智能体的架构,其实就是一种群体的智能体架构。
LangGraph也支持这种架构,通过引入langgraph-swarm包,可以轻松实现。
安装langgraph-swarm包
pip install langgraph-swarm
还是以订机票和酒店为例:
from
langgraph.prebuilt
import
create_react_agent
from
langgraph_swarm
import
create_swarm, create_handoff_tool
from
langchain_core.tools
import
tool
from
langchain_deepseek
import
ChatDeepSeek
from
langchain_openai
import
ChatOpenAI
from
dotenv
import
load_dotenv
# 用于加载环境变量
load_dotenv()
# 加载 .env 文件中的环境变量
# model = ChatDeepSeek(model="deepseek-reasoner")
model = ChatOpenAI(model=
"gpt-4o"
)
@tool
def
book_hotel
(
hotel_name:
str
):
"""Book a hotel"""
return
f"Successfully booked a stay at
{hotel_name}
."
@tool
def
book_flight
(
from_airport:
str
, to_airport:
str
):
"""Book a flight"""
return
f"Successfully booked a flight from
{from_airport}
to
{to_airport}
."
transfer_to_hotel_assistant = create_handoff_tool(
agent_name=
"hotel_assistant"
,
description=
"Transfer user to the hotel-booking assistant."
,
)
transfer_to_flight_assistant = create_handoff_tool(
agent_name=
"flight_assistant"
,
description=
"Transfer user to the flight-booking assistant."
,
)
flight_assistant = create_react_agent(
model=model.bind_tools([book_flight,transfer_to_hotel_assistant], parallel_tool_calls=
False
),
tools=[book_flight, transfer_to_hotel_assistant],
# 有些大模型parallel_tool_calls=False可能不生效,为避免并发调用工具的错误,可以在提示词加上:一次只能调用一个工具,工具不能并发调用
# Only one tool can be called at a time, and tools cannot be called in parallel
prompt=
"You are a flight booking assistant, Only one tool can be called at a time, and tools cannot be called in parallel"
,
name=
"flight_assistant"
)
hotel_assistant = create_react_agent(
model=model.bind_tools([book_hotel,transfer_to_flight_assistant], parallel_tool_calls=
False
),
tools=[book_hotel, transfer_to_flight_assistant],
prompt=
"You are a hotel booking assistant, Only one tool can be called at a time, and tools cannot be called in parallel"
,
name=
"hotel_assistant"
)
# 定义一个群体的智能体节点
swarm = create_swarm(
agents=[flight_assistant, hotel_assistant],
default_active_agent=
"flight_assistant"
).
compile
()
for
chunk
in
swarm.stream(
{
"messages"
: [
{
"role"
:
"user"
,
"content"
:
"帮我订一张机票从北京到广州,并且要住在香格里拉大酒店"
}
]
}
):
print
(chunk)
print
(
"\n"
)
运行以上代码,会输出:
HumanMessage(content='帮我订一张机票从北京到广州,并且要住在香格里拉大酒店',
...
ToolMessage(content='Successfully booked a flight from Beijing to Guangzhou.', name='book_flight',
...
ToolMessage(content='Successfully transferred to hotel_assistant', name='transfer_to_hotel_assistant',
...
ToolMessage(content='Successfully booked a stay at 香格里拉大酒店.', name0', AIMessage(content='您的行程已 经成功安排:您将从北京飞往广州,并入住香格里拉大酒店。祝您旅途愉快!如果还有其他需求,请告诉我。'
小结
-
- 多智能体架构之间的切换原理主要是通过Handoff 和 tool来实现的
-
- LangGraph 提供了自定义的Handoff函数,也提供了langgraph-supervisor和langgraph-swarm 包来方便实现监督者架构和群体架构
-
- 避坑点:
- • 选择大模型很重要,需要推理能力比较强的才能较好地处理多智能体,或者可以优化更细致的提示词
- • 大模型默认为并发调用工具,会导致报错,需要配置parallel_tool_calls=False,或者也可以通过提示词来控制不并行调用工具
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐


 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)