字节大模型一面面经
字节大模型面试主要考察候选人对Transformer架构、大模型训练与推理优化的理解。面试内容包括:Transformer Decoder的Mask机制、LayerNorm位置设计对比、vLLM推理优化原理、SFT和RLHF对齐方法、模型压缩技术(剪枝/量化)、RAG检索增强生成的优势与故障排查等。技术问题深入项目细节,同时要求手写二叉树中序遍历算法。面试重点评估候选人解决实际问题的能力,以及对大
·
字节大模型一面面经
建议点赞收藏,以免遗失。更多AI大模型开发 学习视频/籽料/面试题 都在这>>Github<< >>Gitee<<
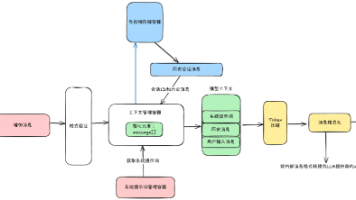
面试流程梳理:
-
自我介绍
- 简要介绍背景、研究/工作经历、与大模型相关的实践经验。
-
项目深挖
-
挑选一个自己最熟悉的大模型项目,重点回答:
- 项目目标是什么?
- 自己的核心负责点?
- 最有技术含金量/挑战的部分在哪里?
-
-
Transformer Decoder Mask
- 为什么要对未来信息做 Mask?(避免信息泄漏,保证自回归特性)
- 在代码实现中,Mask 是如何作用在 Attention 分数矩阵上的?
-
LayerNorm 位置之争(Pre-LN vs Post-LN)
- 两种设计对训练稳定性、收敛速度、梯度传播的影响。
- 各自优缺点,自己更倾向哪一种,并说明理由。
-
大模型推理优化(以 vLLM 为例)
- 线上部署时的痛点:推理速度 + 吞吐量。
- vLLM 的核心思想:PagedAttention 如何解决 KV Cache 内存碎片化,从而提升效率。
-
对齐问题:SFT & RLHF
-
为什么基础模型“不听人话”?
-
训练流程一般几步:
- SFT(监督微调):教模型模仿人类指令数据 → 基础对齐。
- RLHF(PPO/DPO):通过人类反馈进一步优化 → 提升交互体验。
-
-
模型压缩与加速
-
大模型(如 70B)太大太慢 → 上线难。
-
常见方法:
- 剪枝(Pruning) → 降低计算量,但可能影响准确率。
- 量化(Quantization) → 减少显存占用 & 加速推理,但有精度损失。
- 其他:蒸馏、低秩分解等。
-
-
RAG 的价值
- 直接生成 vs 检索增强生成。
- RAG 的核心优势:减少幻觉、增强时效性、提升专业性。
- 主要解决:大模型“记不住/不知道”的问题。
-
RAG 故障排查思路
-
如果模型答非所问/胡说八道:
- 检查检索模块:是否召回相关文档?召回质量如何?
- 检查生成模块:是否正确理解了检索内容?
- 联调:embedding 质量、Top-k 设置、融合策略等。
-
-
算法题
- 手写二叉树的中序遍历(递归 & 迭代两种写法最好都准备)。
-
反问环节
- 可以问团队技术栈、线上大模型规模、对模型优化的主要挑战等。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐


 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)