RAG 检索优化关键:手把手教你实现查询路由机制,从源头提升问答质量
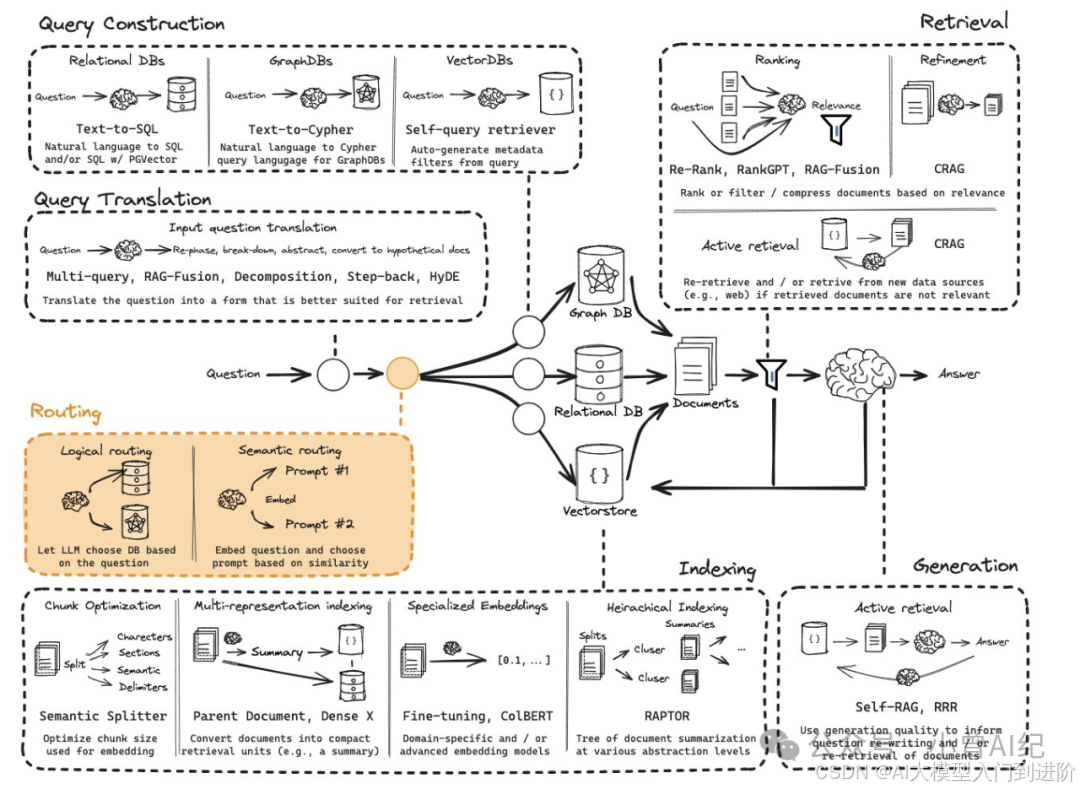
在构建复杂的RAG系统中,会存在有多个数据源的情况。你可能有多个向量数据库,或者用不同类型的数据库(图数据库、关系数据库)来存储不同格式的数据。我们如何根据用户的查询有效的路由到相关的数据源呢?这就是我们今天要关注另一个预检索优化策略–查询路由(Query Routing)。
在构建复杂的RAG系统中,会存在有多个数据源的情况。你可能有多个向量数据库,或者用不同类型的数据库(图数据库、关系数据库)来存储不同格式的数据。
我们如何根据用户的查询有效的路由到相关的数据源呢?这就是我们今天要关注另一个预检索优化策略–查询路由(Query Routing)。
什么是查询路由?
查询路由 就像一个智能决策中心,在收到用户问题后,它会先停下来思考,而不是直接盲目地在所有资料里进行“大海捞针”。它根据用户问题的类型,决定下一步的路径怎么走:是从内部数据库A查找?还是从外部知识库B获取信息?甚至是直接上网搜索。
这个预检索的优化策略,就是为了确保系统从一开始就走在正确的道路上,大大提升了回答的精准度和效率。
常见查询路由方案
逻辑路由(Logical Routing)
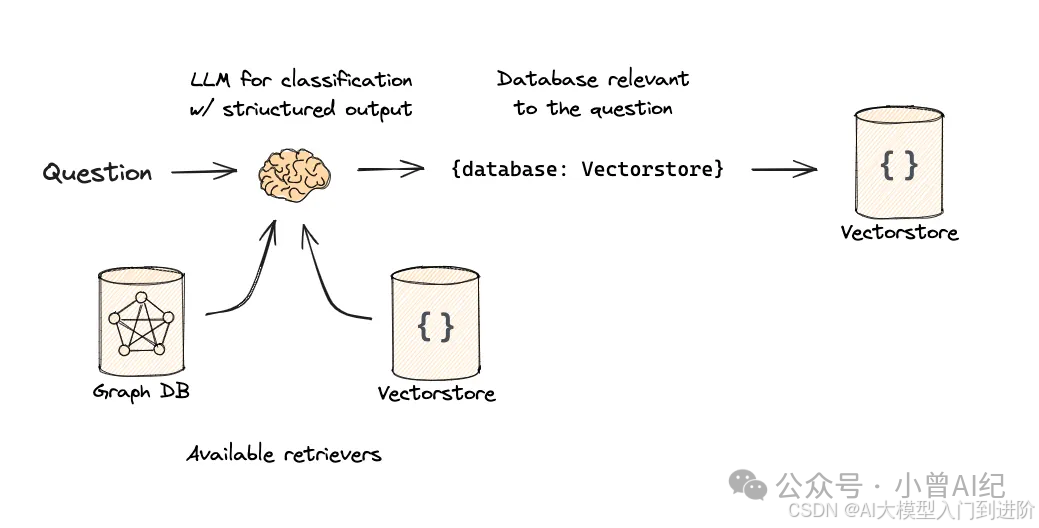
逻辑路由就是来负责决定用户的查询问题应该交给谁来处理。当系统接收到用户查询后,通过大模型来分析和语义理解,然后从它预先掌握的所有数据源的信息和特点中,挑选出最相关、最匹配的那一个,最终将查询交给它来处理。
比如下面图片中的流程中显示,大模型针对用户的查询进行分类,判断与哪个数据库中的内容最相关,是图数据库还是向量数据库?然后决定去哪个数据源中检索。
以下是用LangChain实现的逻辑路由的代码示例:
import os
from dotenv import load_dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_deepseek import ChatDeepSeek
# 加载环境变量
load_dotenv()
# 初始化DeepSeek大语言模型
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0.1, # 设置较低的温度,确保路由结果的稳定性
max_tokens=50, # 路由只需要简短回答,限制token数量
api_key=os.getenv("DEEPSEEK_API_KEY")
)
# 设置路由提示模板
system_prompt = """你是一个专业的编程查询路由专家。
根据用户问题中涉及的编程语言,将其路由到相应的数据源:
- 如果问题涉及Python代码或Python相关概念,返回 "python_docs"
- 如果问题涉及JavaScript代码或JavaScript相关概念,返回 "js_docs"
- 如果问题涉及Go/Golang代码或Go相关概念,返回 "golang_docs"
- 如果无法明确判断或涉及多种语言,返回 "general_docs"
请只返回数据源名称,不要包含其他内容。"""
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{question}"),
])
defroute_query(question: str) -> str:
"""
根据问题内容进行路由分析
Args:
question: 用户提出的问题
Returns:
str: 路由到的数据源名称
"""
# 构建结构化提示
formatted_prompt = prompt.invoke({'question': question})
# 调用大模型进行路由判断
result = llm.invoke(formatted_prompt)
return result.content.strip().lower()
defpython_docs_chain(question: str) -> str:
"""Python文档处理链"""
returnf"🐍 Python文档链处理: {question}\n这里会连接到Python专门的文档检索和回答系统"
defjs_docs_chain(question: str) -> str:
"""JavaScript文档处理链"""
returnf"📜 JavaScript文档链处理: {question}\n这里会连接到JavaScript专门的文档检索和回答系统"
defgolang_docs_chain(question: str) -> str:
"""Go语言文档处理链"""
returnf"🚀 Go语言文档链处理: {question}\n这里会连接到Go语言专门的文档检索和回答系统"
defgeneral_docs_chain(question: str) -> str:
"""通用文档处理链"""
returnf"📚 通用文档链处理: {question}\n这里会连接到通用的文档检索和回答系统"
defchoose_route(route_result: str, question: str) -> str:
"""
根据路由结果选择相应的处理链
Args:
route_result: 路由分析的结果
question: 原始问题
Returns:
str: 处理链的输出结果
"""
# 清理路由结果,移除可能的引号和空格
route = route_result.strip().lower().replace('"', '').replace("'", "")
if"python_docs"in route:
return python_docs_chain(question)
elif"js_docs"in route:
return js_docs_chain(question)
elif"golang_docs"in route:
return golang_docs_chain(question)
else:
return general_docs_chain(question)
if __name__ == "__main__":
question = """为什么下面的代码不工作:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(["human", "speak in {language}"])
prompt.invoke("french")"""
# 第一步:路由分析
route_result = route_query(question)
# 第二步:选择处理链
final_result = choose_route(route_result, question)
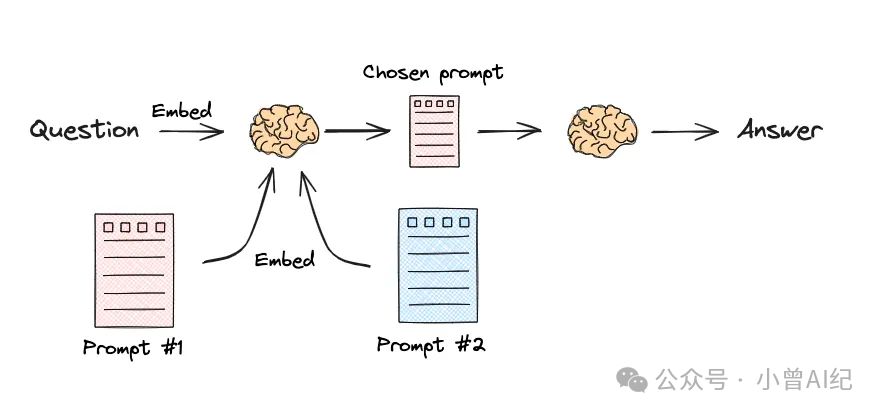
语义路由(Semantic Routing)
语义路由则是将用户的查询和系统预设的的多个提示词模板进行嵌入,计算它们的相似性,来匹配最相关提示词模板,决定最终使用哪一个提示词。
以下是用LangChain实现的语义路由的代码示例:
import os
import numpy as np
from dotenv import load_dotenv
from langchain.utils.math import cosine_similarity
from langchain_core.prompts import PromptTemplate
from langchain_deepseek import ChatDeepSeek
from langchain_huggingface import HuggingFaceEmbeddings
# 加载环境变量
load_dotenv()
# 初始化嵌入模型 - 使用中文优化的模型
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh", # 使用中文优化的嵌入模型
model_kwargs={'device': 'cpu'}, # 使用CPU计算
encode_kwargs={'normalize_embeddings': True} # 启用向量归一化
)
# 定义不同领域的专门化提示模板
physics_template = """你是一位非常优秀的物理学教授。\
你擅长用简洁易懂的方式回答物理学问题。\
当你不知道某个问题的答案时,你会诚实地承认不知道。
请回答以下物理学问题:
{query}"""
math_template = """你是一位非常优秀的数学家。你擅长回答数学问题。\
你之所以如此出色,是因为你能够将复杂问题分解为组成部分,\
逐一解决各个部分,然后将它们整合起来回答更广泛的问题。
请回答以下数学问题:
{query}"""
programming_template = """你是一位经验丰富的程序员和软件工程师。\
你精通多种编程语言和开发技术,能够提供清晰的代码示例和解释。\
你擅长调试代码问题,解释编程概念,并提供最佳实践建议。
请回答以下编程问题:
{query}"""
general_template = """你是一位知识渊博的助手,能够回答各种通用问题。\
你会尽力提供准确、有用的信息,并承认自己不确定的地方。\
请用清晰、结构化的方式组织你的回答。
请回答以下问题:
{query}"""
# 收集所有提示模板
prompt_templates = [
("物理学", physics_template),
("数学", math_template),
("编程", programming_template),
("通用", general_template)
]
print("🔄 正在计算提示模板的向量嵌入...")
# 计算所有提示模板的向量嵌入
template_texts = [template for _, template in prompt_templates]
prompt_embeddings = embeddings.embed_documents(template_texts)
print("✅ 提示模板向量化完成")
# 初始化DeepSeek大语言模型
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0.7, # 适中的创造性
max_tokens=2048, # 允许较长的回答
api_key=os.getenv("DEEPSEEK_API_KEY")
)
defprompt_router(user_input: str):
"""
基于语义相似度的提示路由器
Args:
user_input: 用户输入的查询
Returns:
tuple: (选中的领域名称, 格式化的提示)
"""
# 1. 将用户查询进行向量化
query_embedding = embeddings.embed_query(user_input)
# 2. 计算查询与所有提示模板的余弦相似度
similarity_scores = cosine_similarity([query_embedding], prompt_embeddings)[0]
# 3. 找到相似度最高的模板
best_match_idx = np.argmax(similarity_scores)
best_score = similarity_scores[best_match_idx]
# 4. 获取最匹配的领域和模板
domain_name, most_similar_template = prompt_templates[best_match_idx]
# 5. 创建提示模板对象并格式化
template = PromptTemplate.from_template(most_similar_template)
formatted_prompt = template.invoke({'query': user_input})
return domain_name, formatted_prompt
defsemantic_routing_qa(user_query: str) -> str:
"""
完整的语义路由问答流程
Args:
user_query: 用户查询
Returns:
str: 大模型的回答
"""
# 1. 路由到最适合的提示模板
domain, refined_prompt = prompt_router(user_query)
# 2. 使用DeepSeek生成回答
print(f"\n🤖 正在使用{domain}专家模式生成回答...")
response = llm.invoke(refined_prompt)
return response.content
if __name__ == "__main__":
query = "Python中的装饰器是什么?如何使用?"
# 执行语义路由问答
answer = semantic_routing_qa(query)
总结
总之,查询路由(Query Routing) 是在构建高级RAG系统比较常见的预检索优化策略。上一篇文章中提到的优化策略查询翻译(Query Translation) 侧重于将问题转换成更标准的形式,而路由则是在翻译之后选择最合适的下游资源。
无论是通过逻辑路由去匹配最相关的数据源(如向量数据库、图数据库或者关系型数据库),还是利用语义路由动态选择最优的提示词模板,查询路由都扮演着“智能导航”的角色。它核心价值在于:
-
- 提升精准度:避免在不相关的数据集中进行无效搜索,将计算资源集中在最可能产生正确答案的地方。
-
- 提高效率:减少检索范围和响应时间,为用户提供更流畅、更快速的交互体验。
-
- 增强系统扩展性:使RAG系统能更灵活地集成和管理多个不同类型的数据源,能应对更复杂的应用场景。
在实践中,巧妙地运用查询路由,能让你的RAG系统告别“盲目”检索,更智能、高效的实现复杂的业务场景。
完整的示例代码可以去GitHub仓库中查看
🔗GitHub地址:https://github.com/yilane/rag-related/tree/main/src/05-pre-retrieval/02-query-routing
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 41
41 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)