近期热点论文精选速览
近期大模型领域热点论文精选解读
最近能明显感觉到大模型发展日新月异,一周不追踪业内最新动态,自己的知识储备就已经落后了,以后会不定期将最近最新的一些热点论文进行汇总,内容涵盖论文大纲+创新点总结+实验效果,旨在快速了解最新的技术,会对其中重要的论文另外展开详细解读。
1. GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
本文介绍了混合专家(Mixture-of-Experts, MoE)大语言模型 GLM-4.5,该模型总参数规模达 355B,激活参数为 32B,核心特点是采用混合推理方法,同时支持 “思考模式” 与 “直接响应模式”。
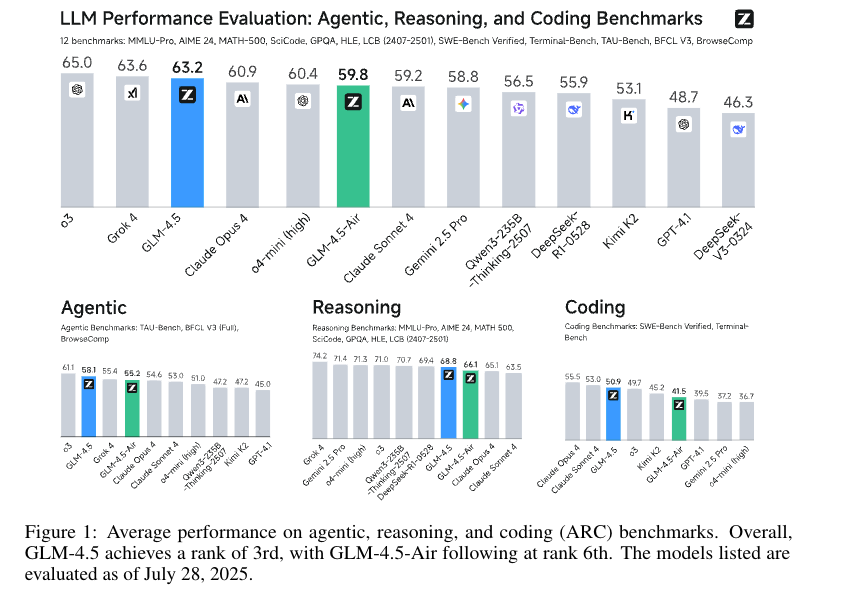
通过对 23 万亿 tokens(23T tokens)的多阶段训练,以及结合专家模型迭代与强化学习的全面后训练,GLM-4.5 在智能体任务(Agentic)、推理任务(Reasoning)与编码任务(Coding)(三者合称 ARC 任务)中均展现出优异性能:在 TAU-Bench 基准测试中得分为 70.1%,在 AIME 24 基准测试中得分为 91.0%,在 SWE-bench Verified 基准测试中得分为 64.2%。
尽管 GLM-4.5 的参数规模远少于多款竞品模型,但在所有参与评估的模型中,其综合排名位列第 3;在智能体类基准测试中,排名位列第 2。我们同时发布了 GLM-4.5(3550 亿参数版)与轻量版本 GLM-4.5-Air(1060 亿参数版),旨在推动推理类与智能体类人工智能系统的相关研究。相关代码、模型及更多信息可访问网址:https://github.com/zai-org/GLM-4.5。
模型/框架结构
论文大纲
创新点总结
1. 架构设计创新:高参数效率的 MoE 架构
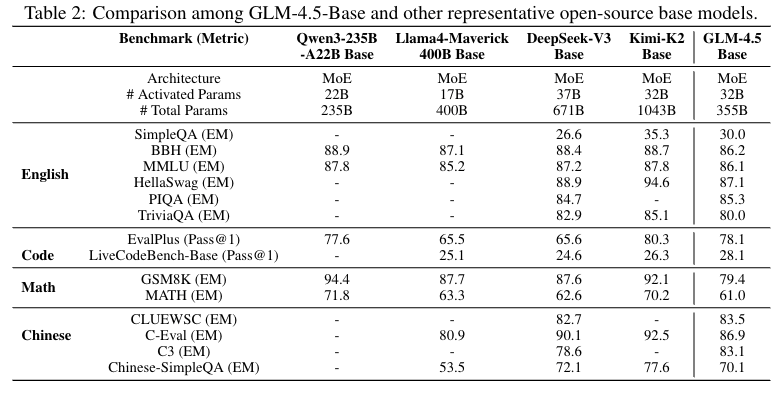
1.1 “减宽度、增深度” 的 MoE 优化:突破传统 MoE “宽而浅” 设计,GLM-4.5(355B 总参数,32B 激活参数)通过增加 MoE 层数(89 层)、减少单专家宽度,在参数规模仅为竞品(如 Kimi K2,1043B)1/3 的情况下,激活参数与竞品持平,实现性能与效率平衡;GLM-4.5-Air(106B 总参数,12B 激活参数)进一步压缩规模,仍保持 100B 级模型领先性能。
1.2 关键组件创新:首次引入 QK-Norm 稳定注意力对数范围,提升推理任务(如 MMLU、BBH)性能;新增 MTP(多 token 预测)层,支持投机解码,推理效率提升显著;采用 96 头分组查询注意力(GQA),虽不降低训练损失,但大幅增强复杂推理能力,这一设计区别于 DeepSeek-V3、Kimi K2 等竞品。
2. 训练流程创新:多阶段训练 + 领域专属优化
2.1 预训练:高质量数据与精准采样:基于 23T tokens 多源数据(网页、代码、数学等),创新分质量桶采样策略(高价值数据贡献超 3.2 轮训练),结合 SemDedup 语义去重(移除模板生成的相似网页),解决传统预训练 “低质数据冗余” 问题;代码数据采用 “规则过滤 + 质量分级 + Fill-In-the-Middle 目标”,提升编码任务基础能力。
2.2 中训练:针对性提升 ARC 核心能力:在预训练后新增 “中训练” 阶段,用中等规模领域数据优化:Repo 级代码训练(拼接仓库文件学习跨文件依赖,序列长度 32K)提升编码能力;合成推理数据训练(生成数学 / 科学竞赛题推理过程)补充稀缺复杂推理样本;长上下文 + 智能体训练(序列长度扩展至 128K)适配长文本与智能体交互场景,解决传统预训练 “泛而不精” 问题。
2.3 后训练:专家迭代 + 强化学习(RL)闭环:构建 “专家模型训练→统一蒸馏→RL 优化” 流程:先训练推理、智能体、通用对话三类专家模型,再通过自蒸馏将多专家能力融合为 “思考 + 直接响应” 混合推理模式;RL 阶段创新难度 curriculum 学习(两阶段训练极难问题)、单阶段 64K 输出长度 RL(避免多阶段短长度训练导致的 “能力遗忘”),并基于自主研发的 Slime 框架支持 FP8 推理加速,解决大模型 RL 训练 “效率低、易遗忘” 问题。
3. 能力创新:统一 ARC 三大核心能力
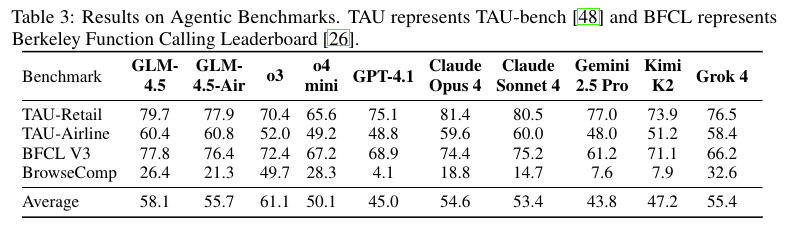
3.1 智能体能力突破:通过 “多跳知识图谱生成 web 搜索任务 + GitHub PRs 构建软件工程基准”,结合 “结果监督 + 过程格式惩罚”RL 策略,GLM-4.5 在 BrowseComp(网页浏览代理)达到 26.4%,超 Claude Opus 4(18.8%);TAU-Bench(零售 / 航空领域交互)得达到70.1%,接近 Claude Sonnet 4,成为开源模型中智能体能力最强的模型之一。
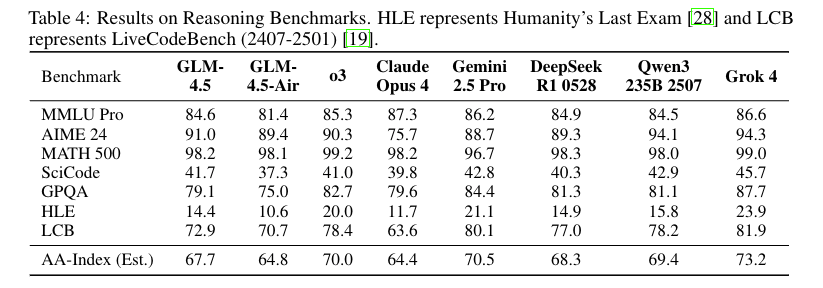
3.2 推理能力优化:针对数学、科学推理,创新合成结构化推理数据,结合难度 curriculum RL,AIME 24(数学推理)准确率达 91.0%,超 OpenAI o3(90.3%);GPQA(研究生级问答)达到 79.1%,在开源模型中仅次于 Qwen3-235B,解决传统开源模型 “复杂推理弱” 问题。
3.3 编码能力升级:基于 Repo 级代码训练与 “token 加权损失” RL 策略,GLM-4.5 在 SWE-bench Verified(真实代码修复)达到 64.2%,超 GPT-4.1(48.6%)、Gemini 2.5 Pro(49.0%);Terminal-Bench(终端任务) 达到37.5%,超 Claude Sonnet 4(35.5%),成为首个在工业级编码基准接近闭源模型的开源模型。
4. 工程与生态创新:可落地的开源体系
4.1 推理与微调工程优化:推出 FP8 精度模型版本,GLM-4.5-FP8 推理时 GPU 需求从 H100×16(BF16)降至 H100×8,且性能损失小于 2%;提供适配 vLLM、SGLang 的快速部署方案,支持 128K 长上下文推理,解决大模型 “部署成本高、长上下文难支持” 问题。
4.2 开源生态完善:首次开源 “基础模型 + 混合推理模型 + FP8 模型” 全系列,搭配 Slime 训练框架、glm-simple-evals 评估工具,以及 CC-Bench(52 个真实编码任务)轨迹数据,确保研究可复现;模型采用 MIT 许可证,支持商业使用与二次开发,推动推理与智能体 AI 领域的开源协作。
实验效果
论文链接:https://arxiv.org/pdf/2508.06471
2. Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
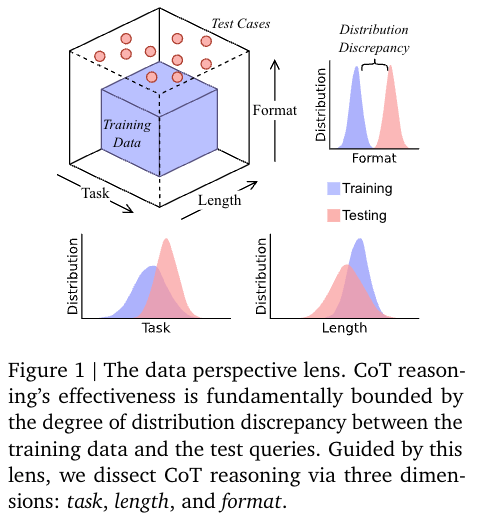
研究表明,思维链(Chain-of-Thought, CoT)提示法能够提升大语言模型(Large Language Model, LLM)在各类任务中的表现。通过这种方法,大语言模型在给出答案前,似乎会生成类人类的推理步骤(即 “思维链推理”),这往往让人误以为这些模型在进行有意识的推理过程。然而,一些初步研究结果显示,思维链推理可能比表面看起来更浅显,这促使我们展开更深入的探究。在本文中,从数据分布的视角对思维链推理进行研究,探究其是否体现了模型从分布内数据中习得的结构化归纳偏差 —— 这种偏差使模型能够有条件地生成与训练过程中所见推理路径相近的推理路径。因此,思维链推理的有效性从根本上受限于训练数据与测试查询之间的分布差异程度。借助这一视角,我们从三个维度对思维链推理进行剖析,分别是任务维度、长度维度和格式维度。为探究每个维度的情况,我们设计了 DataAlchemy —— 这是一个独立可控的实验环境,可用于从零开始训练大型语言模型,并在不同的分布条件下对模型进行系统性的测试。研究结果表明,思维链推理是一种脆弱的幻象:当测试场景超出训练数据的分布范围时,这种推理能力便会消失。本研究让人们更深入地理解思维链推理为何会失效、在何种情况下会失效,同时也凸显了实现真正可泛化推理能力所面临的持续挑战。代码已上传至 GitHub:https://github.com/ChengshuaiZhao0/DataAlchemy。
模型/框架结构
论文大纲
创新点总结
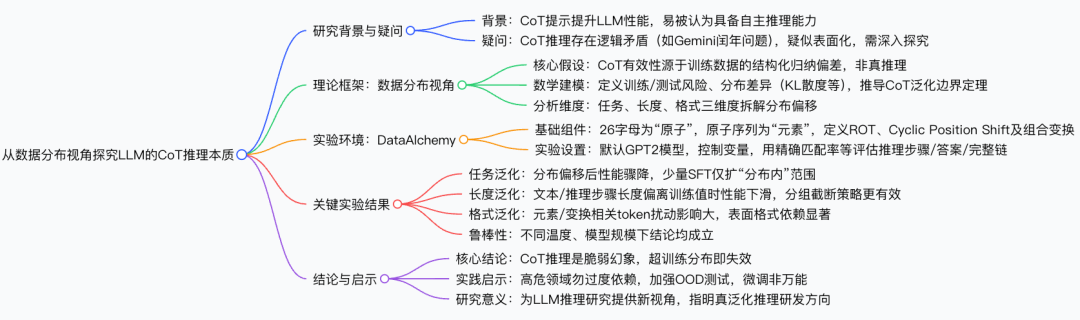
该论文围绕大语言模型(LLM)思维链(CoT)推理能力展开研究,核心创新点可概括为以下四方面,均紧密围绕 “数据分布视角” 与 “可控实验验证” 两大核心逻辑展开:
1. 提出 “数据分布视角” 的全新理论框架,重构 CoT 推理本质认知
突破以往对 CoT 推理 “类人逻辑推理” 的表面认知,首次从数据分布差异角度建立理论解释:提出 CoT 推理的有效性并非源于模型的 “自主推理能力”,而是来自模型从分布内训练数据中习得的 “结构化归纳偏差”—— 即模型仅能生成与训练中见过的推理路径近似的路径,其效果根本上受限于训练数据与测试查询的分布差异程度。同时,通过数学建模(定义训练 / 测试分布的期望风险、用 KL 散度等量化分布差异、推导 CoT 泛化边界定理),为这一视角提供了严谨的理论支撑,明确了 “分布差异越大,CoT 推理性能越差” 的量化关系,填补了 CoT 推理有效性边界缺乏系统性理论解释的空白。
2. 设计 “DataAlchemy” 可控实验环境,消除干扰变量以精准探测 CoT 推理
针对传统 LLM 研究中 “预训练数据复杂、干扰因素多” 的痛点,创新构建了从零训练 LLM 的孤立可控环境:
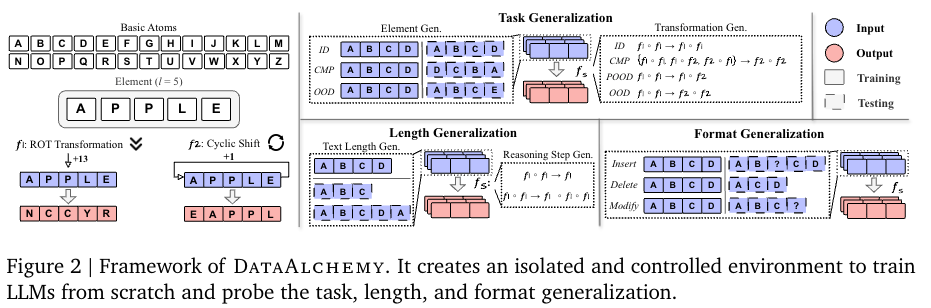
-
基础组件可精准调控:以 26 个字母为 “原子”、原子序列为 “元素”,定义 ROT(字母循环移位)、Cyclic Position Shift(序列位置循环移位)两种可拆解的基础变换及组合变换,能明确生成 CoT 推理的 “中间步骤” 与 “最终答案”,实现对推理过程的精准追踪;
-
变量控制严格:可固定任务类型、推理长度、查询格式等任一变量,仅改变 “分布差异”(如训练用元素长度为 4,测试用 2/3/5/6),彻底排除预训练中复杂模式的干扰,首次实现对 “分布偏移如何影响 CoT 推理” 的纯变量实验验证。
3. 从 “任务、长度、格式” 三维度系统实证,揭示 CoT 推理的脆弱性规律
以往研究对 CoT 推理泛化能力的探讨多零散且单一,该论文创新地将 “分布差异” 拆解为三个核心维度,并通过系统性实验得出量化规律:
-
任务维度:无论是 “元素分布偏移”(测试元素含训练未见过的原子)还是 “变换分布偏移”(测试变换为训练未见过的类型 / 组合),CoT 推理精确匹配率从 100%(分布内)骤降至 0(完全分布外),且少量微调(SFT)仅能 “扩大分布内范围”,无法实现真正泛化;
-
长度维度:文本长度(元素长度)或推理步骤数偏离训练值时,性能显著下降(如训练长度 4,测试长度 2/3/5/6 时精确匹配率均为 0),且验证了 “分组截断” 是缓解长度偏移的有效策略;
-
格式维度:仅对 “元素 / 变换相关 token” 进行插入、修改等表面扰动,便会导致 CoT 推理性能大幅下滑(插入扰动影响最大),证明 CoT 推理依赖表面文本模板而非逻辑本质。这些实证结果首次全面量化了 CoT 推理在不同分布偏移场景下的脆弱性,打破了 “CoT 推理具备通用逻辑能力” 的认知误区。
4. 指出 “CoT 推理是脆弱幻象” 的核心结论,提供实践与研究的颠覆性启示
不同于以往研究仅 “质疑 CoT 推理的局限性”,该论文通过理论 + 实验双重验证,明确提出 “CoT 推理是依赖训练分布的脆弱幻象” 这一核心结论:其看似连贯的推理步骤,实质是对训练数据中模式的浅层复制,一旦超出训练分布便会失效。
这一结论为实践与研究提供了颠覆性指导:实践层面:警示医疗、金融等高危领域不可过度依赖 CoT 推理,需加强分布外(OOD)测试与专家审核,否定了 “CoT 是通用推理插件” 的错误认知;
研究层面:明确未来 LLM 推理研究的核心方向 —— 需突破 “表面模式匹配”,研发具备 “抽象逻辑能力” 的模型,而非仅通过微调扩大训练分布范围,为领域研究提供了关键的方向指引。
实验效果
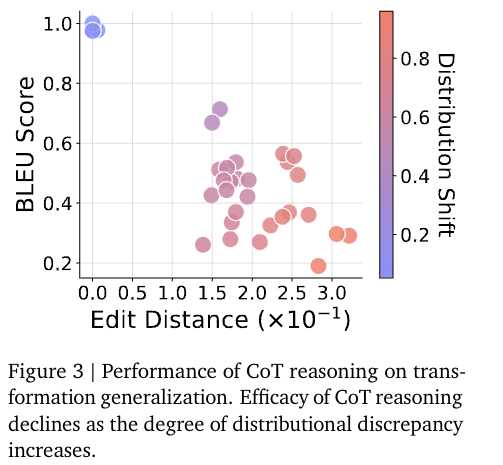
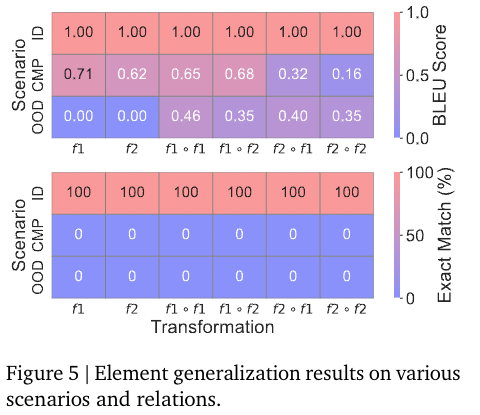
论文中有非常翔实的实验数据,推荐看原文~
论文链接:https://arxiv.org/pdf/2508.01191
3. INTERN-S1: A SCIENTIFIC MULTIMODAL FOUNDATION MODEL
近年来,大量开源基础模型不断涌现,在一些备受关注的领域取得了显著进展,其性能已与闭源模型十分接近。然而,在高价值但挑战性更强的科学专业领域,情况却有所不同:要么这些领域仍依赖专家模型,要么通用基础模型的发展进度与热门领域相比严重滞后,远不足以推动科学研究的变革,这也导致开源模型与闭源模型在这些科学领域存在巨大差距。
为缩小这一差距,并向人工通用智能(Artificial General Intelligence, AGI)进一步探索,我们推出了科学多模态基础模型 Intern-S1。它兼具 “专精性” 与 “通用性”—— 既具备通用理解与推理能力,又拥有分析多种科学模态数据的专业能力。Intern-S1 是一款混合专家(Mixture-of-Experts, MoE)架构的多模态模型,总参数规模达 241B,激活参数为 28B;其训练数据总量为 5 万亿 tokens,其中包含超 2.5 万亿科学领域相关 tokens,通过持续预训练优化模型基础能力。
在后训练阶段,Intern-S1 在 InternBootCamp(专为基础模型设计的大规模交互环境)中先后完成离线强化学习(Reinforcement Learning, RL)与在线强化学习。在此过程中,我们提出 “混合奖励(Mixture-of-Rewards, MoR)框架”,实现 1000 余项任务的同步强化学习训练。
凭借在算法、数据与训练系统方面的整合创新,Intern-S1 在在线强化学习训练中达到了顶尖性能。在综合评估基准测试中,Intern-S1 在通用推理任务上的表现跻身开源模型第一梯队,在科学领域任务上显著超越其他开源模型,甚至在分子合成规划、反应条件预测、晶体热力学稳定性预测等专业任务中,性能超过了当前最先进的闭源模型。模型已开源,可通过以下链接获取:https://huggingface.co/internlm/Intern-S1。
模型/框架结构
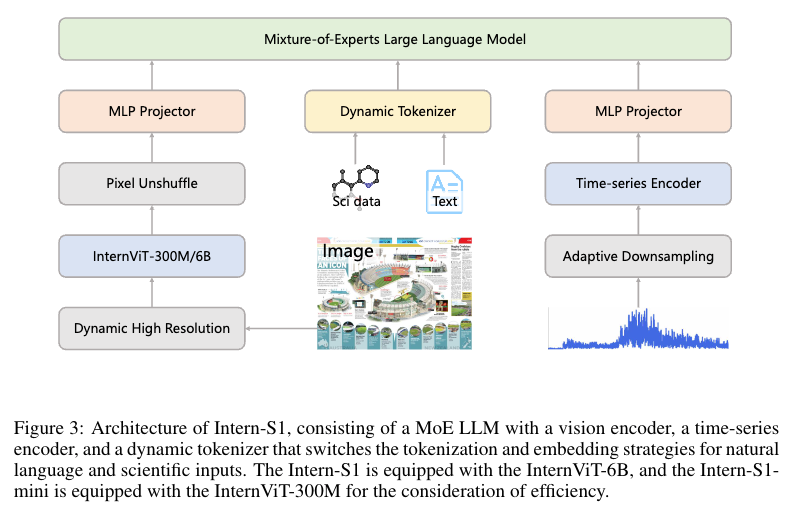
论文大纲
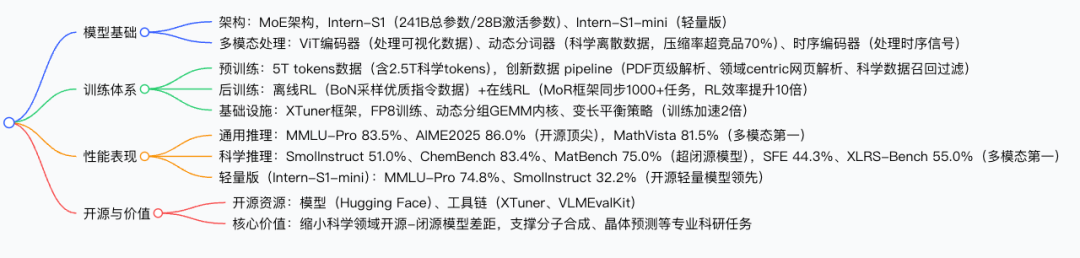
创新点总结
1. 架构设计创新:科学多模态专属 MoE 架构
1.1 多模态编码器协同设计:突破传统 LLM 单一文本处理局限,针对科学数据特性定制三大核心编码器
-
视觉编码器:采用 InternViT 系列(Intern-S1 用 6B 参数版,Intern-S1-mini 用 300M 蒸馏版),支持 448×448 固定分辨率与动态分辨率,通过像素重排将视觉 token 压缩 4 倍,适配科学图像(如显微镜图像、遥感图像)的细粒度解析需求;
-
动态分词器:针对分子结构(SMILES 格式)、蛋白质序列(FASTA 格式)等科学离散数据,自动识别模态并采用专属分词策略,解决通用分词器 “语义混淆” 与 “压缩率低” 问题 —— 在 SMILES 格式数据上,压缩率较 GPT-OSS、Qwen3 等竞品提升 70%,大幅降低科学数据处理的计算开销;
-
时序编码器:含自适应下采样模块与 Transformer 块,专门处理地震波、脑电信号、天文光变曲线等长时序科学数据,填补 LLM 对连续数值信号的处理空白。
1.2 MoE 架构参数效率优化
-
Intern-S1 采用 “241B 总参数 + 28B 激活参数” 的 MoE 设计,通过动态专家路由(仅激活部分专家层)平衡性能与效率;同时创新引入 QK-Norm 稳定注意力对数范围、MTP 层支持投机解码,在参数规模仅为部分闭源竞品(如 Kimi K2,1043B 参数)1/4 的情况下,科学领域性能仍实现超越。
2. 训练体系创新:科学数据与高效 RL 双驱动
2.1 预训练:高质量科学数据构建方案
针对科学领域数据稀缺、质量参差的痛点,设计三大创新数据 pipeline,构建总量 5T tokens、科学领域占比超 50%(2.5T tokens)的预训练数据集:
-
PDF 页级解析 pipeline:先通过低成本 MinerU 解析 PDF 页面,再用公式 / 符号检测器筛选含复杂科学符号的 “可疑页面”,交由高成本 VLMs(如 InternVL、Qwen-VL)二次解析,平衡质量与成本 —— 归档库 PDF 仅 5% 页面需高成本解析,网页 PDF 仅 3%,且经人工验证,科学数据纯度从网页爬取数据的 2% 提升至 50% 以上;
-
领域 centric 网页解析 pipeline:按 URL 域名分组网页,用 LLM 代理标注域名特征(如 “化学数据库”“物理论文平台”),对低质量无价值域名直接丢弃、低质量有价值域名重写、高质量域名保留,解决通用网页解析中 “科学信息分散” 的问题;
-
科学数据召回过滤 pipeline:构建含数学、物理、化学等 6 大科学领域的三级分类树,用 LLM 标注样本训练轻量分类器(fastText+1.5B LLM),从开源预训练语料与网页数据中精准召回科学数据,确保领域覆盖完整性。
2.2 后训练:MoR 框架实现千级任务同步 RL
在 InternBootCamp(含 1000 + 可验证科学任务的交互环境)中,创新设计 “离线 + 在线” 两阶段 RL 体系,核心突破为混合奖励(MoR)框架:
奖励信号统一化:针对不同类型任务定制奖励生成方式 —— 易验证任务(如数学计算、科学公式推导)结合规则验证器、CompassVerifier 轻量模型与环境反馈生成精确数值奖励;难验证任务(如科学对话、创意推理)用 POLAR-7B(基于策略判别学习的奖励模型)生成 “与期望分布的距离奖励”,将多模态、多任务的异质奖励统一为 scalar 数值;
任务平衡策略:先离线评估各任务难度与收敛速度(如数学任务收敛快、分子设计任务收敛慢),确定初始数据混合比例;训练中在线过滤 “全对 / 全错轨迹” 及噪声数据(如乱码、重复输出),避免部分任务过拟合或欠拟合;
效率突破:结合 FP8 训练 / 推理、Colocated 训练 - 推理架构(模型在训练与推理设备间透明 redistribution),使 RL 训练时间较现有方法(如 DAPO)减少 10 倍,且样本效率提升显著,能用更少数据教会模型科学专业技能。
3. 能力创新:通用与科学推理双顶尖
3.1 科学领域性能突破
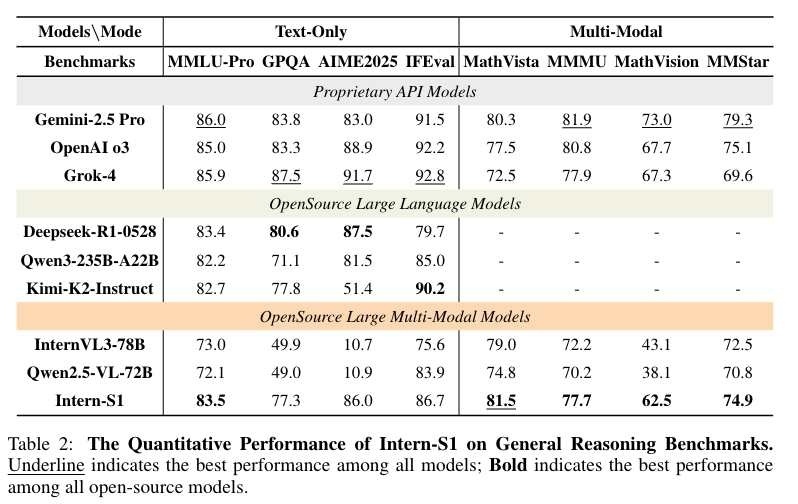
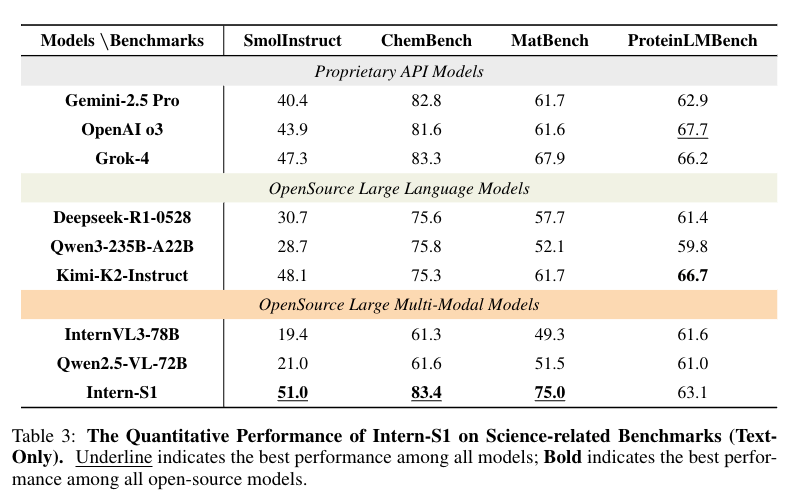
首次实现开源模型在科学领域超越部分闭源模型:
-
文本类科学任务:SmolInstruct(化学)达 51.0%(超 OpenAI o3 的 43.9%)、MatBench(材料)达 75.0%(超 Gemini 2.5 Pro 的 61.7%)、ChemBench(化学)达 83.4%(超 Gemini 2.5 Pro 的 82.8%);
-
多模态科学任务:SFE(综合科学)达 44.3%(超 Gemini 2.5 Pro 的 43.0%)、XLRS-Bench(遥感)达 55.0%(超 Grok-4 的 45.4%)、MicroVQA(显微)达 63.9%(超 Gemini 2.5 Pro 的 63.1%),在分子合成规划、晶体热力学预测等专业场景具备实用价值。
3.2 通用推理能力保持
在通用基准测试中跻身开源模型第一梯队,避免 “科学专精” 导致的 “通用能力退化”:MMLU-Pro 达 83.5%、AIME2025 达 86.0%、MathVista(多模态数学推理)达 81.5%(超所有闭源模型),实现 “科学能力顶尖 + 通用能力优秀” 的平衡。
4. 工程与生态创新:可落地的开源体系
基于 XTuner 框架打造高效训练体系,解决大模型训练 “效率低、不稳定” 问题:
-
精度优化:采用 FP8 精度训练 / 推理(矩阵乘法动态缩放),视觉编码器保留 BF16,在 H100 GPU 上,Intern-S1-FP8 版本较 BF16 版本显存需求降低 50%;
-
并行与内核优化:全分片数据并行(FSDP)+1 路专家并行(避免 MoE 内存爆炸),搭配 TMA-Adaptive FP8 分组 GEMM 内核、Flash Attention-3,训练速度提升 2 倍;
-
变长训练策略:通过 “随机打包 + 滑动窗口分组 + 窗口内排序” 解决变长序列训练的负载不均衡问题,进一步提升训练效率。
5. 开源生态完善
首次开源 “全尺寸科学多模态模型 + 轻量版模型 + 完整工具链”:
-
开源模型:Intern-S1(241B 参数)、Intern-S1-mini(轻量版)及 FP8 量化版本,支持商业使用(Apache-2.0 许可证);
-
配套工具:XTuner 训练框架、VLMEvalKit/OpenCompass 评估工具、CC-Bench(真实编码任务)轨迹数据,确保研究可复现;
-
部署支持:提供 lmdeploy、vllm、sglang、ollama 等多框架部署方案,明确硬件需求(如 Intern-S1-FP8 版本需 H100×4 或 H200×2),降低科学领域 AI 应用门槛。
实验效果
论文链接:https://arxiv.org/pdf/2508.15763
4. ON THE GENERALIZATION OF SFT: A REINFORCE MENT LEARNING PERSPECTIVE WITH REWARD RECTIFICATION
本文提出了一种简单但具有理论依据的改进方法,用于大语言模型的监督微调(Supervised Fine-Tuning, SFT),以解决其相较于强化学习(Reinforcement Learning, RL)泛化能力有限的问题。通过数学分析发现标准 SFT 的梯度隐含了一种有问题的奖励结构,这种结构可能会严重限制模型的泛化能力。为修正这一问题,我们提出了动态微调(Dynamic Fine-Tuning, DFT)方法:通过利用每个 token 的概率对目标函数进行动态缩放,实现对每个 token 梯度更新的稳定化。值得注意的是,仅需修改一行代码,该方法就在多个具有挑战性的基准测试和基础模型上显著优于标准 SFT,展现出大幅提升的泛化性能。此外,我们的方法在离线强化学习场景中也取得了具有竞争力的结果,为相关任务提供了一种有效且更简洁的替代方案。本研究搭建了理论洞察与实际解决方案之间的桥梁,显著推动了 SFT 性能的提升。相关代码将在以下链接公开:https://github.com/yongliang-wu/DFT。
创新点总结
该论文围绕大型语言模型(LLM)的监督微调(SFT)改进展开,核心创新点可概括为以下三方面:
1. 理论层面:揭示 SFT 与 RL 的梯度关联及泛化瓶颈根源通过数学推导首次明确:标准 SFT 的梯度本质是一种特殊的策略梯度,但其隐含 “奖励极度稀疏且与模型对专家行为的预测概率成反比” 的问题结构。当模型对专家响应概率低时,梯度方差会无界放大,导致优化场景异常,这一发现从根本上解释了 SFT 相较于强化学习(RL)泛化能力弱的核心原因。
2.方法层面:提出极简高效的 DFT 改进方案针对 SFT 的奖励结构缺陷,设计 “动态微调(DFT)”:仅通过一行代码,用每个 token 的预测概率(并通过停止梯度算子避免梯度干扰)对 SFT 的目标函数进行动态缩放,将梯度更新从 “不稳定、概率依赖” 转变为 “稳定、均匀加权”,且无需引入额外样本、奖励模型或复杂计算,实现对 SFT 的轻量化升级。
3.应用层面:突破场景限制并验证普适性
-
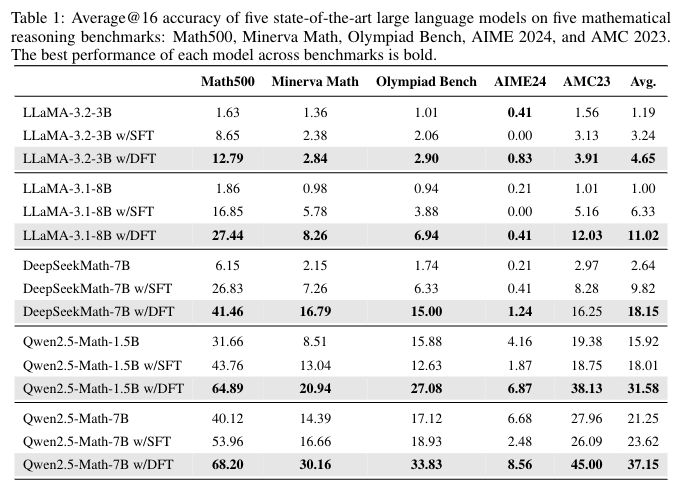
在传统 SFT 场景(仅含专家数据):在数学推理等多类任务、多种模型(如 Qwen2.5-Math、LLaMA 系列)上,DFT 对模型性能的提升幅度远超标准 SFT,尤其在 SFT 易过拟合的难基准(如奥林匹克数学题、AIME 竞赛题)上仍能稳定提升;
-
在离线 RL 场景:无需复杂交互或迭代奖励建模,DFT 性能不仅超越 DPO、RFT 等离线 RL 方法,还优于 PPO、GRPO 等在线 RL 方法,成为更简洁的替代方案;
-
同时验证 DFT 对非确定性轨迹任务(如数学链式推理、复杂代码生成)的适配优势,进一步拓展了 SFT 改进方法的适用边界。
实验效果
论文链接:https://arxiv.org/pdf/2508.05629
5. Ovis2.5 Technical Report
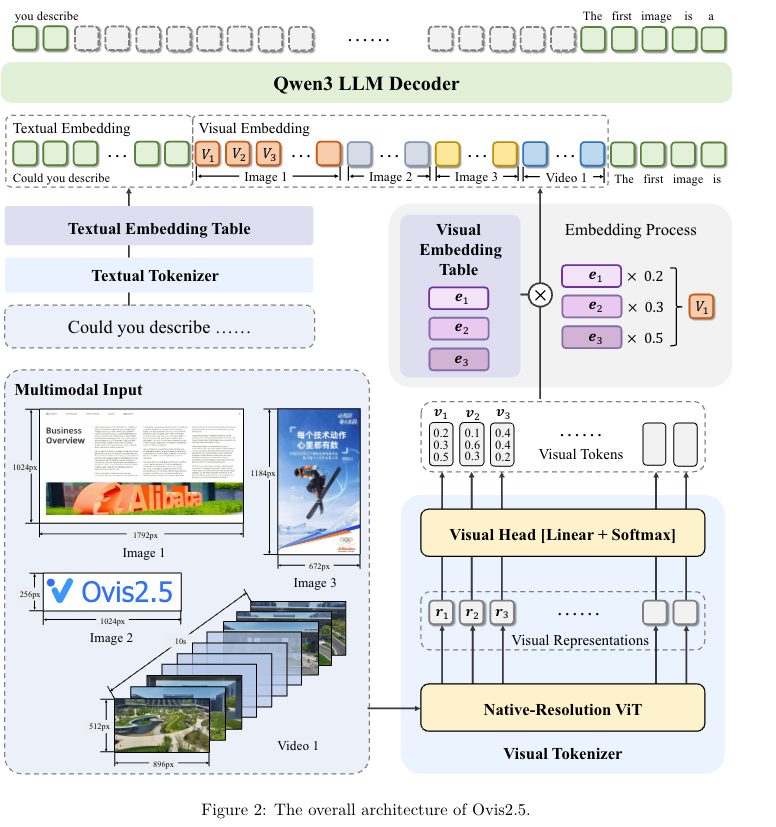
本文提出了 Ovis2.5 模型,它是 Ovis2 的继任版本,专为原生分辨率视觉感知与强大的多模态推理能力设计。Ovis2.5 集成了原生分辨率视觉 Transformer(Vision Transformer, ViT),能够以图像的原生可变分辨率对其进行处理,避免了固定分辨率切片(tiling)导致的性能损耗,同时保留了图像的精细细节与全局布局 —— 这对于复杂图表等视觉密集型内容的分析至关重要。
为增强模型的推理能力通过训练让模型突破线性思维链(chain-of-thought)的局限,具备反思能力,包括自我检查与修正功能。这一高级能力在推理阶段以可选的 “思考模式”(thinking mode)形式提供,用户可通过牺牲一定延迟,在处理复杂输入时获得更高的准确率。
该模型通过一套全面的五阶段训练课程进行训练,逐步构建其核心能力:训练过程始于基础视觉与多模态预训练,随后进行大规模指令微调,最终通过直接偏好优化(Direct Preference Optimization, DPO)与组相对策略优化(Group Relative Policy Optimization, GRPO)完成对齐与推理能力增强。
为高效实现这些升级的规模化训练,采用了多模态数据打包(multimodal data packing)与混合并行(hybrid parallelism)技术,显著提升了端到端训练速度。我们发布了两个开源模型版本:Ovis2.5-9B 与 Ovis2.5-2B。其中,Ovis2.5-2B 延续了 Ovis2“小模型,高性能” 的设计理念,非常适合资源受限的端侧部署场景。
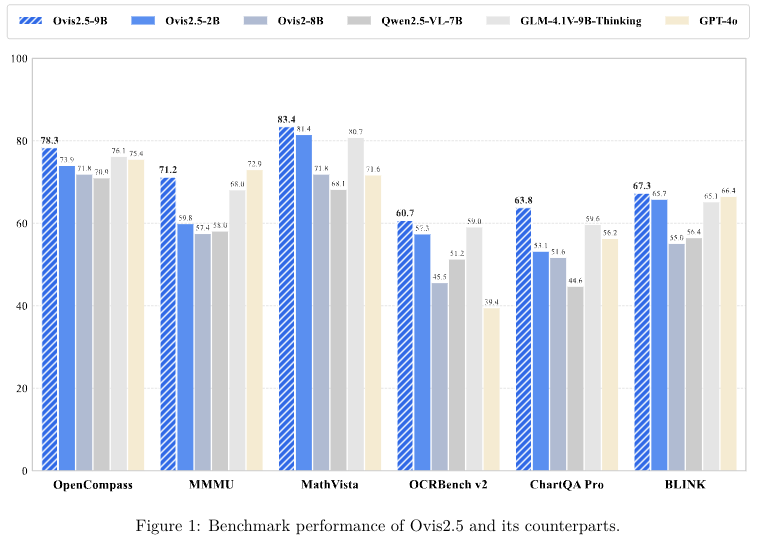
在 OpenCompass 多模态排行榜中,Ovis2.5-9B 平均得分为 78.3,相较于前代模型 Ovis2-8B 有显著提升,且在 40B参数以下的开源多模态大语言模型中实现了当前最优(state-of-the-art, SOTA)性能;Ovis2.5-2B 得分为 73.9,在同规模开源模型中同样达到了当前最优水平。
除综合得分外,Ovis2.5 在科学、技术、工程与数学(Science, Technology, Engineering, Mathematics, STEM)领域的基准测试中表现领先,在视觉定位(grounding)与视频相关任务中展现出强劲能力,且在其参数规模的开源模型中,复杂图表分析任务的性能也达到了当前最优。
模型/框架结构
论文大纲

创新点总结
1. 视觉感知:突破 “固定分辨率切片” 瓶颈,实现原生分辨率处理
针对 Ovis2 处理视觉密集内容(如复杂图表、高分辨率文档)时,因固定分辨率切片导致 “细节丢失、全局结构断裂” 的问题,创新集成原生分辨率 Vision Transformer(NaViT):无需对图像缩放或分割,直接以图像原生可变分辨率处理,同时嵌入旋转位置嵌入(RoPE)增强空间感知,完整保留视觉内容的细粒度细节(如小字体、数据点)与全局布局(如图表逻辑关联),从底层解决视觉密集任务的分析短板。
2. 推理能力:新增 “反思式推理” 机制,突破线性思维链局限
区别于传统 MLLM 依赖 “线性思维链(CoT)” 的推理模式,创新训练模型的反思能力:通过含 “自我检查、结论修正” 的 “思考式” 数据(标注<RichMediaReference>...</RichMediaReference>标签),让模型学会在推理中主动评估逻辑漏洞、优化结论;并将该能力封装为可选 “思考模式”,推理时用户可自主选择 “关闭模式保效率” 或 “开启模式换复杂任务准确率”,平衡实用性与性能。
3.训练与部署:高效训练架构 + 轻量化版本,兼顾性能与实用性
-
五阶段渐进式训练课程:创新设计 “视觉预训练→多模态预训练→指令微调→DPO 偏好对齐→GRPO 推理强化” 流程,从 “基础感知” 到 “高级推理” 逐步构建能力,避免训练目标混乱;尤其在后训练阶段冻结视觉模块、仅优化 LLM,既强化推理又不退化感知能力。
-
高效训练技术:针对多模态数据尺寸差异导致的负载失衡,采用 “多模态数据打包” 减少计算浪费;结合 “数据 + 张量 + 上下文混合并行” 降低内存占用,实现3-4 倍端到端训练加速,解决大模型训练效率低的问题。
-
轻量化版本设计:延续 “小模型,大性能” 理念,推出 Ovis2.5-2B,在 OpenCompass 获 73.9 分(同规模开源 SOTA),适配资源受限的端侧场景,填补 “高性能 + 轻量化” 多模态模型的需求空白。
实验效果
论文链接:https://arxiv.org/pdf/2508.11737
6. WebWatcher: Breaking New Frontiers of Vision-Language Deep Research Agent
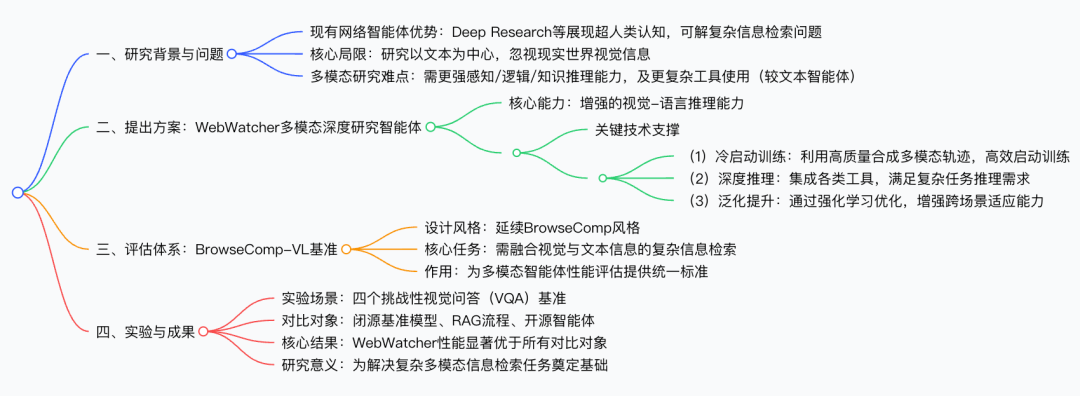
诸如 Deep Research 之类的网络智能体已展现出超越人类的认知能力,能够解决极具挑战性的信息检索问题。然而,目前大多数相关研究仍以文本为核心,忽视了现实世界中的视觉信息。这使得多模态深度研究任务极具难度 —— 与基于文本的智能体相比,此类多模态智能体需要更强的感知、逻辑、知识层面推理能力,同时还需运用更复杂的工具。
为解决这一局限,我们提出了多模态深度研究智能体 WebWatcher,该智能体具备增强的视觉 - 语言推理能力。它利用高质量的合成多模态轨迹实现高效的冷启动训练,借助各类工具开展深度推理,并通过强化学习进一步提升泛化能力。
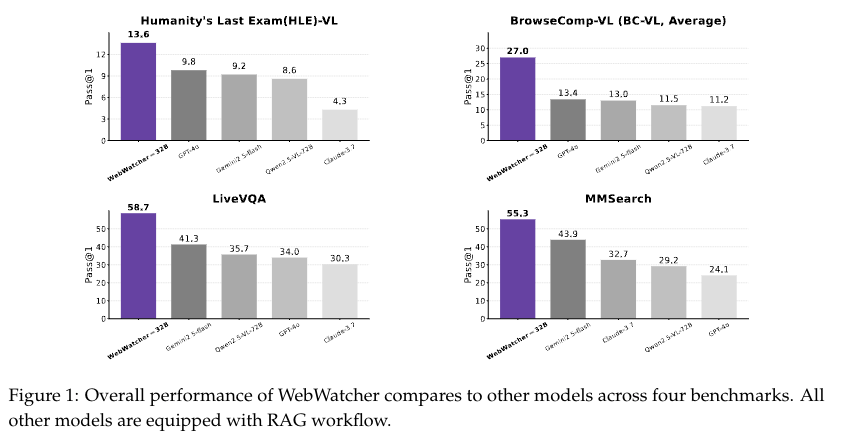
为更有效地评估多模态智能体的性能,我们还提出了基准测试数据集 BrowseComp-VL。该数据集采用 BrowseComp 风格设计,要求完成涉及视觉与文本信息融合的复杂信息检索任务。实验结果表明,在四个具有挑战性的视觉问答(VQA)基准测试中,WebWatcher 的性能显著优于闭源基准模型、检索增强生成(RAG)流程以及开源智能体,为解决复杂的多模态信息检索任务奠定了基础。
模型/框架结构
论文大纲
创新点总结
本文围绕多模态深度研究智能体的研发与评估展开,核心创新点聚焦 “解决文本中心智能体局限、构建高效训练体系、完善评估基准” 三大维度,具体可概括为以下四方面:
1. 突破模态局限:提出首类聚焦视觉 - 语言融合的深度研究智能体
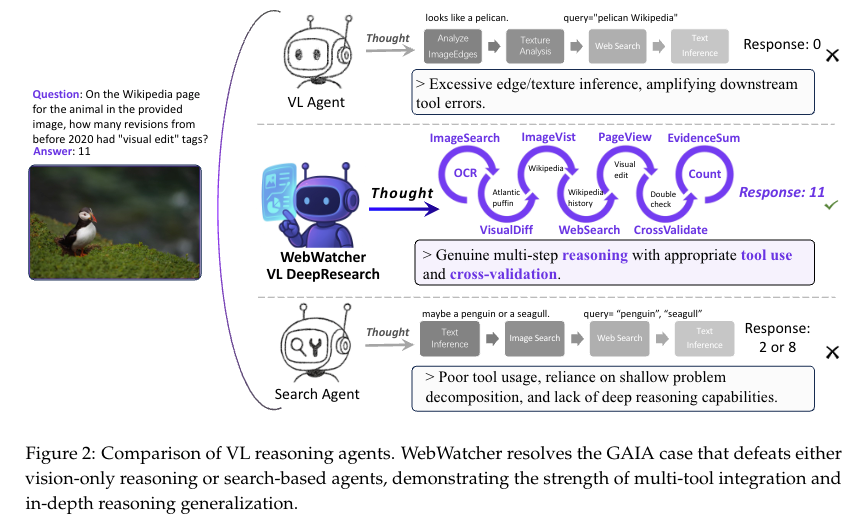
针对现有网络智能体(如 Deep Research)以文本为核心、无法处理视觉密集型任务的短板,创新性开发WebWatcher 多模态智能体,首次将 “深度研究能力” 与 “视觉 - 语言推理” 深度结合。区别于仅依赖单一视觉工具(如 OCR)的浅层多模态方案,WebWatcher 能整合视觉感知、文本理解、跨模态逻辑关联,可应对科学图表解析、视觉网页导航等复杂场景,填补了 “深度研究” 与 “多模态” 结合的技术空白。
2. 创新训练机制:高质量合成轨迹 + 强化学习,解决多模态冷启动与泛化难题
冷启动训练突破:设计 “高质量合成多模态轨迹” 方案,通过自动化 pipeline 生成含 “思考 - 工具调用 - 观察” 循环的 ReAct 风格轨迹(如结合 Web 图像搜索、OCR、代码解释器的多步推理流程)。该轨迹基于真实工具交互行为构建,而非人工模板,能快速教会智能体掌握多模态工具使用逻辑,解决多模态场景下初始训练数据稀缺、推理流程难学习的冷启动问题。
泛化能力优化:在监督微调(SFT)冷启动基础上,引入GRPO 强化学习算法,通过 “组相对优势” 优化策略 —— 对同任务生成的多组轨迹排序,优先强化高奖励轨迹的推理模式,避免单一轨迹过拟合,显著提升智能体在跨领域、复杂视觉 - 文本任务中的适应能力。
3. 构建专属评估基准:BrowseComp-VL,填补多模态深度检索评估空白
针对现有基准(如 BrowseComp、HLE)仅侧重文本、无法评估多模态信息检索能力的局限,提出BrowseComp-VL 基准:
设计上延续 BrowseComp 的 “复杂信息检索” 核心,但拓展至视觉领域,每个任务需融合图像(如图表、真实网页截图)与文本信息,且通过 “实体模糊化”(如用 “图中建筑” 替代具体名称)增加推理难度;
数据上基于真实 Web 资源生成,避免合成数据的脱离实际问题,确保评估结果能反映智能体在真实多模态场景的表现,为多模态深度研究智能体提供首个统一、高难度的评估标准。
4. 工具整合创新:多模态工具链 + 动态决策,适配复杂任务需求
不同于现有多模态智能体 “工具功能单一、调用逻辑固定” 的问题,WebWatcher 创新性集成5 类专用工具(Web 图像搜索、Web 文本搜索、网页访问、代码解释器、OCR),并实现 “任务驱动的动态工具选择”:
-
工具链覆盖视觉感知(OCR)、信息检索(Web 搜索)、深度计算(代码解释器)、场景导航(网页访问),可应对从 “提取图像文本” 到 “计算图表数据” 再到 “浏览动态网页” 的全流程任务;
-
训练中通过轨迹学习让智能体自主判断工具调用时机(如解析图表时先调用 OCR 提取文本,再用代码解释器计算数据),而非依赖预设模板,大幅提升工具使用的灵活性与任务适配性。
实验效果
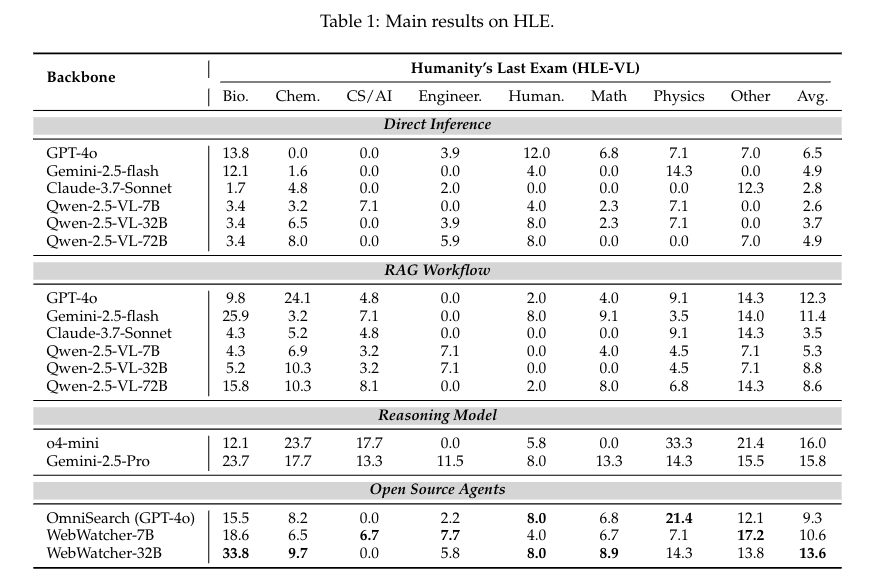
论文链接:https://arxiv.org/pdf/2508.05748

惟楚有才,于斯为盛。欢迎来到长沙!!! 茶颜悦色、臭豆腐、CSDN和你一个都不能少~
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)