
DeepSeek-V3.1 发布:迈向 Agent 时代的第一步|默语解读
DeepSeek-V3.1发布:迈向Agent时代的关键升级 核心亮点: 首创混合推理架构,支持思考/非思考双模式一键切换 Agent能力显著提升:工具调用成功率提高20%-50%,任务执行更稳定 工程优化:128K长上下文支持、严格模式Function Calling、兼容Anthropic API 思维链压缩技术使思考模式token消耗减少20%-50% 模型全面开源,包含Base和训练后版本
DeepSeek-V3.1 发布:迈向 Agent 时代的第一步|默语解读
✍️ 作者:默语 | 微信:Solitudemind
📬 公众号:默语摸鱼
TL;DR(给忙碌的你)
- 一体化“混合推理架构”:同一模型可在「思考模式 / 非思考模式」间自由切换。
- 思考更快:V3.1-Think 通过“思维链压缩”,在减少 20%–50% token的同时,表现与 R1-0528 基本持平。
- Agent 更强:工具调用、检索与任务编排的稳定性与成功率显著提升。
- 产品同步:App / 网页与 API 全面升级;128K 上下文、严格模式 Function Calling、兼容 Anthropic API。
- 全面开源:Base 与后训练模型均已在 Hugging Face、魔搭开源;注意 UE8M0 FP8 Scale、新分词器 & chat template 的兼容差异。
01|这次 V3.1 到底升级了什么?
1) 混合推理架构
一个模型,两套工作流:
- 非思考模式(快速答复,成本更低):
deepseek-chat - 思考模式(复杂推理、工具编排):
deepseek-reasoner
官方 App / 网页已上线 “深度思考” 按钮,可一键切换。
2) 思考效率更高
- 经过思维链压缩训练,V3.1-Think 输出 token 减少 20%–50%,平均表现仍与 R1-0528 持平。
- 在非思考模式下,V3.1 也对输出长度做了更稳的控制,相比 V3-0324,更省字也不掉线。
参考对比:AIME 2025(87.5/88.4)、GPQA(81/80.1)、liveCodeBench(73.3/74.8)(前者/后者为 R1-0528 与 V3.1-Think)。
02|Agent 能力:工具更会用,任务更能跑
编程智能体(Code Agent)
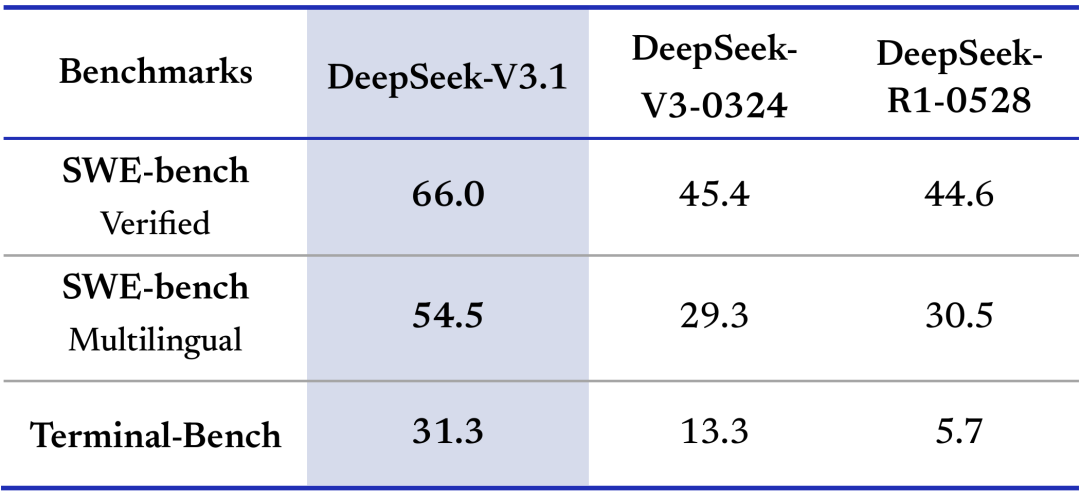
表 1:编程智能体测评(SWE 使用内部框架,相比 OpenHands 轮数更少;Terminal Bench 使用官方 Terminus 1 framework)
- 在 SWE 代码修复 与 Terminal-Bench 复杂命令行任务 上,V3.1 相比老版本有明显提升。
- 这意味着:自动修复、单测生成、交互式调试等更稳、更少回合、更会用工具。
搜索智能体(Search Agent)
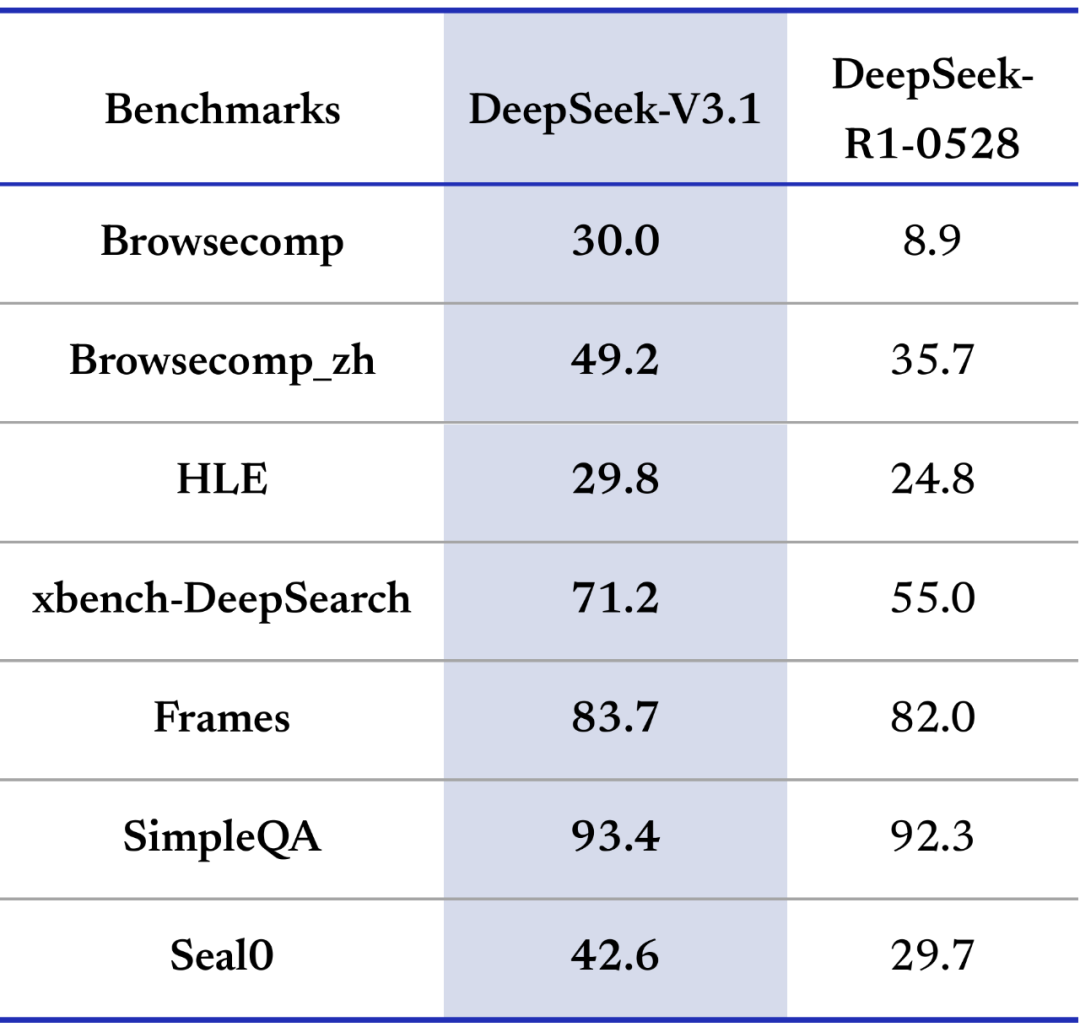
表 2:搜索智能体测评(商用搜索 API + 网页过滤 + 128K 窗口;R1-0528 使用内部 workflow;HLE 同时启用 python 与 search 工具)
- 在需要多步推理的 browsecomp 和专家级综合难题 HLE 上,V3.1 领先 R1-0528。
- 这直接利好:长链路检索、事实核查、跨域资料汇总、策略性搜索的成功率与质量。
03|思考效率:少字,快点,还得对
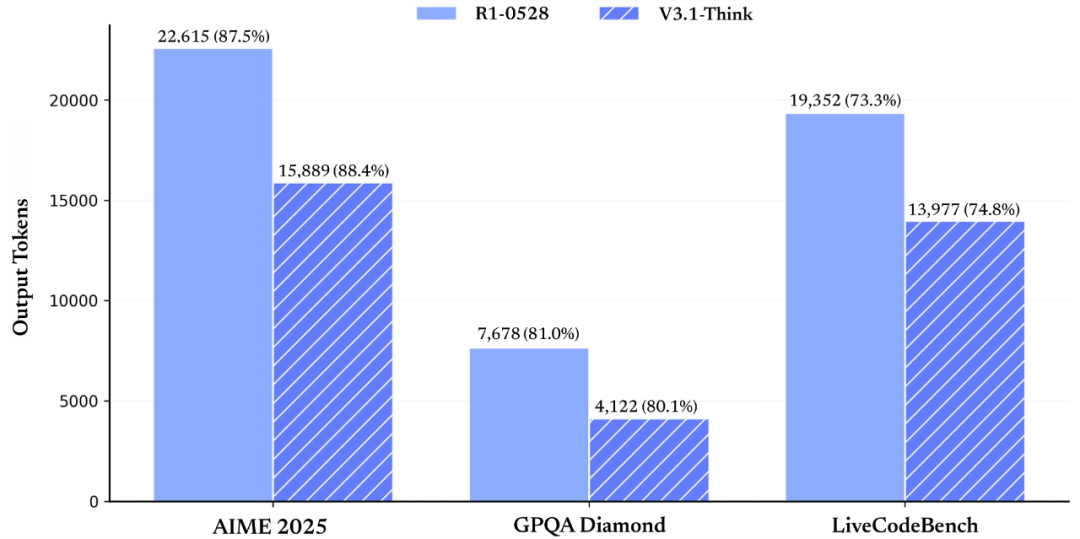
- V3.1-Think 相比 R1-0528:token 消耗下降 20%–50%,指标基本持平。
- 非思考模式也对冗长输出做了抑制:信息密度更高、回复更聚焦。
04|产品与 API:一线可用,工程直连
App / 网页端
- 已同步升级至 V3.1,支持“深度思考”一键切换模式。
DeepSeek API
- 模型映射:
deepseek-chat→ 非思考模式deepseek-reasoner→ 思考模式
- 上下文窗口:128K
- Function Calling(Beta):新增
strict模式,确保输出 严格符合 schema
文档:https://api-docs.deepseek.com/zh-cn/guides/function_calling - Anthropic API 兼容:可无缝接入 Claude Code 框架
文档:https://api-docs.deepseek.com/zh-cn/guides/anthropic_api
给到工程侧的直觉:更少回合、更稳 JSON、更长上下文,把 Agent 流程的“脆点”进一步补齐。
05|开源与部署:注意两件事
已开源模型
Base 模型(V3 基础上外扩再训,新增 840B tokens):
- Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
- 魔搭:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1-Base
后训练模型:
- Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-V3.1
- 魔搭:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.1
部署前务必知晓
-
参数精度:V3.1 使用 UE8M0 FP8 Scale
-
兼容性变更:分词器 与 chat template 与 V3 存在明显差异
有自建推理 / 混部需求的同学,强烈建议先通读新版说明文档,再做上线切换。
06|给创作者 & 团队的落地建议(默语实用向)
- 内容生产线:
用非思考模式做“批量初稿”,遇到难题/跨域聚合时临时切换思考模式补强逻辑链。 - 知识检索:
构建“搜索 Agent + 摘要器 + 事实核查”三段式工作流,HLE 与 browsecomp 的提升会给你更干净的结果集。 - 代码与运维:
将 strict Function Calling 接入你的工具仓库(搜索、解析、执行器、KV 缓存),减少粘合层报错率。 - 成本与体验:
思考模式不是“全程拉满”,按段启用更经济;非思考模式已经能覆盖绝大多数日常对话与轻任务。
结语
V3.1 不是一次“堆料式大更”,而是把 推理能力、工具稳态、工程接口 这三件事做得更务实。对我这种长期用 AI 做内容、做工程、做产品的人来说:
Agent 真能跑起来,才是拐点的开始。
参考与链接
- Function Calling(Beta,strict 模式):https://api-docs.deepseek.com/zh-cn/guides/function_calling
- Anthropic API 兼容:https://api-docs.deepseek.com/zh-cn/guides/anthropic_api
- 模型开源:
- Base:HF / 魔搭(见上文)
- 后训练:HF / 魔搭(见上文)

欢迎加入北京社区
更多推荐


 30
30 0
0- 0



 已为社区贡献128条内容
已为社区贡献128条内容

所有评论(0)