MCP应用docker部署,docker-compose部署,大模型入门到精通,收藏这篇就足够了!
MCP应用直接用的python3 server.py运行的,如果服务器重启,进程就会关掉,很不方便。
一、概述
前面几篇文章,MCP应用直接用的python3 server.py运行的,如果服务器重启,进程就会关掉,很不方便。
所以需要使用docker部署,实现开机自启动。
二、docker部署
mysql_mcp_server_pro
准备文件
以mysql_mcp_server_pro为例:
server_docker.py
from fastmcp import FastMCP
from mysql.connector import connect, Error
import os
mcp = FastMCP("operateMysql", host="0.0.0.0", port=9000)
def get_db_config():
"""从环境变量获取数据库配置信息
返回:
dict: 包含数据库连接所需的配置信息
- host: 数据库主机地址
- port: 数据库端口
- user: 数据库用户名
- password: 数据库密码
- database: 数据库名称
异常:
ValueError: 当必需的配置信息缺失时抛出
"""
config = {
"host": os.getenv("MYSQL_HOST", "localhost"),
"port": int(os.getenv("MYSQL_PORT", "3306")),
"user": os.getenv("MYSQL_USER"),
"password": os.getenv("MYSQL_PASSWORD"),
"database": os.getenv("MYSQL_DATABASE"),
}
print(config)
if not all(
[
config["host"],
config["port"],
config["user"],
config["password"],
config["database"],
]
):
raise ValueError("缺少必需的数据库配置")
return config
@mcp.tool()
def execute_sql(query: str) -> list:
"""执行SQL查询语句
参数:
query (str): 要执行的SQL语句,支持多条语句以分号分隔
返回:
list: 包含查询结果的TextContent列表
- 对于SELECT查询:返回CSV格式的结果,包含列名和数据
- 对于SHOW TABLES:返回数据库中的所有表名
- 对于其他查询:返回执行状态和影响行数
- 多条语句的结果以"---"分隔
异常:
Error: 当数据库连接或查询执行失败时抛出
"""
config = get_db_config()
try:
with connect(**config) as conn:
with conn.cursor() as cursor:
statements = [stmt.strip() for stmt in query.split(";") if stmt.strip()]
results = []
for statement in statements:
try:
cursor.execute(statement)
# 检查语句是否返回了结果集 (SELECT, SHOW, EXPLAIN, etc.)
if cursor.description:
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
# 将每一行的数据转换为字符串,特殊处理None值
formatted_rows = []
for row in rows:
formatted_row = [
"NULL" if value is None else str(value)
for value in row
]
formatted_rows.append(",".join(formatted_row))
# 将列名和数据合并为CSV格式
results.append(
"\n".join([",".join(columns)] + formatted_rows)
)
# 如果语句没有返回结果集 (INSERT, UPDATE, DELETE, etc.)
else:
conn.commit() # 只有在非查询语句时才提交
results.append(f"查询执行成功。影响行数: {cursor.rowcount}")
except Error as stmt_error:
# 单条语句执行出错时,记录错误并继续执行
results.append(
f"执行语句 '{statement}' 出错: {str(stmt_error)}"
)
# 可以在这里选择是否继续执行后续语句,目前是继续
return ["\n---\n".join(results)]
except Error as e:
print(f"执行SQL '{query}' 时出错: {e}")
return [f"执行查询时出错: {str(e)}"]
@mcp.tool()
def get_table_name(text: str) -> list:
"""根据表的中文注释搜索数据库中的表名
参数:
text (str): 要搜索的表中文注释关键词
返回:
list: 包含查询结果的TextContent列表
- 返回匹配的表名、数据库名和表注释信息
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
sql = "SELECT TABLE_SCHEMA, TABLE_NAME, TABLE_COMMENT "
sql += f"FROM information_schema.TABLES WHERE TABLE_SCHEMA = '{config['database']}' AND TABLE_COMMENT LIKE '%{text}%';"
return execute_sql(sql)
@mcp.tool()
def get_table_desc(text: str) -> list:
"""获取指定表的字段结构信息
参数:
text (str): 要查询的表名,多个表名以逗号分隔
返回:
list: 包含查询结果的列表
- 返回表的字段名、字段注释等信息
- 结果按表名和字段顺序排序
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
# 将输入的表名按逗号分割成列表
table_names = [name.strip() for name in text.split(",")]
# 构建IN条件
table_condition = "','".join(table_names)
sql = "SELECT TABLE_NAME, COLUMN_NAME, COLUMN_COMMENT "
sql += (
f"FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = '{config['database']}' "
)
sql += f"AND TABLE_NAME IN ('{table_condition}') ORDER BY TABLE_NAME, ORDINAL_POSITION;"
return execute_sql(sql)
@mcp.tool()
def get_lock_tables() -> list:
"""
获取当前mysql服务器InnoDB 的行级锁
返回:
list: 包含查询结果的TextContent列表
"""
sql = """SELECT
p2.`HOST` AS 被阻塞方host,
p2.`USER` AS 被阻塞方用户,
r.trx_id AS 被阻塞方事务id,
r.trx_mysql_thread_id AS 被阻塞方线程号,
TIMESTAMPDIFF(SECOND, r.trx_wait_started, CURRENT_TIMESTAMP) AS 等待时间,
r.trx_query AS 被阻塞的查询,
l.OBJECT_NAME AS 阻塞方锁住的表,
m.LOCK_MODE AS 被阻塞方的锁模式,
m.LOCK_TYPE AS '被阻塞方的锁类型(表锁还是行锁)',
m.INDEX_NAME AS 被阻塞方锁住的索引,
m.OBJECT_SCHEMA AS 被阻塞方锁对象的数据库名,
m.OBJECT_NAME AS 被阻塞方锁对象的表名,
m.LOCK_DATA AS 被阻塞方事务锁定记录的主键值,
p.`HOST` AS 阻塞方主机,
p.`USER` AS 阻塞方用户,
b.trx_id AS 阻塞方事务id,
b.trx_mysql_thread_id AS 阻塞方线程号,
b.trx_query AS 阻塞方查询,
l.LOCK_MODE AS 阻塞方的锁模式,
l.LOCK_TYPE AS '阻塞方的锁类型(表锁还是行锁)',
l.INDEX_NAME AS 阻塞方锁住的索引,
l.OBJECT_SCHEMA AS 阻塞方锁对象的数据库名,
l.OBJECT_NAME AS 阻塞方锁对象的表名,
l.LOCK_DATA AS 阻塞方事务锁定记录的主键值,
IF(p.COMMAND = 'Sleep', CONCAT(p.TIME, ' 秒'), 0) AS 阻塞方事务空闲的时间
FROM performance_schema.data_lock_waits w
INNER JOIN performance_schema.data_locks l ON w.BLOCKING_ENGINE_LOCK_ID = l.ENGINE_LOCK_ID
INNER JOIN performance_schema.data_locks m ON w.REQUESTING_ENGINE_LOCK_ID = m.ENGINE_LOCK_ID
INNER JOIN information_schema.INNODB_TRX b ON b.trx_id = w.BLOCKING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.INNODB_TRX r ON r.trx_id = w.REQUESTING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.PROCESSLIST p ON p.ID = b.trx_mysql_thread_id
INNER JOIN information_schema.PROCESSLIST p2 ON p2.ID = r.trx_mysql_thread_id
ORDER BY 等待时间 DESC;"""
return execute_sql(sql)
if __name__ == "__main__":
mcp.run(transport="sse")
修改了之前文章的代码,去除了.env文件,直接引用系统环境变量。
注意:这里添加了host="0.0.0.0",否则k8s发布,会无法访问mcp server
Dockerfile
FROM python:3.13.3-alpine3.21
ADD . /app
RUN pip3 install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple && \
pip3 install mysql-connector-python fastmcp -i https://pypi.tuna.tsinghua.edu.cn/simple
WORKDIR /app
EXPOSE 9000
ENTRYPOINT ["python3","/app/server.py"]
说明:
这里使用的python版本,是最新的3.13.3,镜像使用的是最小的,基于alpine
安装fastmcp模块,必须要升级pip才行,否则安装会失败。
编译并运行镜像
编译
docker build -t mysql_mcp_server_pro:v1 .
运行镜像,注意携带5个环境变量,一个个写变量太麻烦了,接下来使用docker-compose来运行
三、docker-compose部署
使用docker-compose方便管理docker,修改docker运行相关参数,也容易。
docker-compose.yaml
services:
mysql_mcp_server_pro:
image: mysql_mcp_server_pro:v1
container_name: mysql_mcp_server_pro
ports:
- "9090:9000"
environment:
MYSQL_HOST: "192.168.20.128"
MYSQL_PORT: "3306"
MYSQL_USER: "root"
MYSQL_PASSWORD: "abcd@1234"
MYSQL_DATABASE: "test"
TZ: Asia/Shanghai
restart: always
注意修改mysql相关环境变量
运行
docker-compose up -d
四、dify测试
还是一样的dify工作流,测试即可。
注意:如果MCP server服务中断,dify是不会自动重连的,需要重启dify的plugin_daemon组件,就会重新连接MCP server
测试工作流
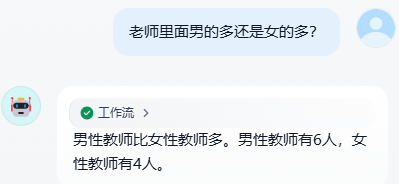
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
第一不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)