[特殊字符]2025架构革命:图解MCP工具链×MoE推理优化×多智能体协同,大模型入门到精通,收藏这篇就足够了!
未来通过MCP协议实现智能体工具动态编排,结合GraphRAG解决复杂知识推理,配合MoE架构提升推理效率,将会形成新一代大模型应用开发范式。
最近看到很多人对MCP/RAG/Agent/Cache/Fine-tuning/Prompt/GraphRAG 都分不清楚,今天我将通过图文,为你讲解其核心技术与实践原理,希望对你们有所帮助。
一、大模型核心架构演进
1.1 函数调用 & MCP(模型上下文协议)

- 传统方案:预定义工具链导致灵活性差,错误传播风险高
- MCP突破:
- 动态上下文感知路由(Context-Aware Routing)
- 工具并行调用机制(Parallel Tool Invocation)
- 自修复工作流(Self-Correcting Pipeline)
1.2 Transformer到MoE架构进化

- 核心创新:
- 稀疏激活:每次推理仅激活2-4个专家(如Mixtral 8x7B)
- 专家专业化:每个专家学习不同领域知识(代码/数学/语言)
- 吞吐量提升:相同参数量下推理速度提升6倍
二、大模型训练技术全景
2.1 四阶段训练体系

| 阶段 | 数据规模 | 关键技术 | 目标输出 |
|---|---|---|---|
| 预训练 | TB级语料 | Megatron-DeepSpeed | 基础语言模型 |
| 指令微调 | 百万级SFT | LoRA/QLoRA | 任务响应能力 |
| 偏好对齐 | 万级偏好对 | DPO/ORPO | 价值观对齐 |
| 推理优化 | 合成数据 | RFT/Rejection Sampling | 复杂推理能力 |
2.2 蒸馏技术应用
LLM 不仅从原始文本中学习;它们也相互学习:
- Llama 4 Scout 和 Maverick 是使用 Llama 4 Behemoth 训练的。
- Gemma 2 和 3 是使用谷歌专有的 Gemini 训练的。
- 蒸馏帮助我们做到这一点,下面的图描绘了三种流行的技术。

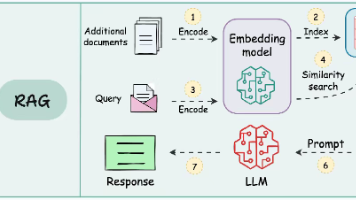
三、RAG架构演进路线
3.1 传统RAG vs 智能体RAG

3.2 HyDE解决方案

- 效果对比:
- HotpotQA数据集:传统RAG准确率58% → HyDE达到76%
- 关键机理:通过假设文档弥合问题与答案的语义鸿沟
四、推理优化关键技术
4.1 KV缓存机制

- 性能收益:
- 128K上下文:推理延迟降低4.8倍
- 显存占用减少37%(通过FP8缓存量化)
4.2 提示工程三大技术
- 思维链(CoT)
- 自洽性(Self-Consistency):生成多条推理路径 → 投票选择最佳答案
- 思维树(ToT)

五、智能体系统设计框架

| 级别 | 类型 | 核心能力 | 示例场景 |
|---|---|---|---|
| L1 | 响应型 | 单轮问答 | ChatGPT基础模式 |
| L2 | 函数型 | 工具调用 | GitHub Copilot |
| L3 | 流程型 | 多工具编排 | AutoGPT |
| L4 | 目标型 | 动态规划+自我验证 | Devin开发助手 |
| L5 | 自治型 | 长期记忆+环境交互 | 工业控制系统 |
5.2 智能体设计模式
AI 智能体行为允许 LLM 通过自我评估、规划和协作来完善其输出!
这张图描绘了构建 AI 智能体时采用的 5 种最流行设计模式。

六、技术架构选择指南
- 数据敏感型场景:Fine-tuning + 私有化部署
- 知识密集型场景:GraphRAG + 知识图谱
- 高并发场景:MoE架构 + KV缓存优化
- 复杂任务场景:Agent架构 + 多工具编排
作者总结:未来通过MCP协议实现智能体工具动态编排,结合GraphRAG解决复杂知识推理,配合MoE架构提升推理效率,将会形成新一代大模型应用开发范式。各位朋友可根据具体场景需求,组合这些技术构建高性能AI系统。好了,本期分享就到这里,如果对你有所帮助,记得告诉身边有需要的朋友。点个小红心,我们下期见。
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础第二不要求准备高配置的电脑第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的
核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)