AI03——简单的 RAG 开发步骤
文档准备文档读取向量转换和存储查询增强。
简单的 RAG 开发步骤
-
文档准备
-
文档读取
-
向量转换和存储
-
查询增强
Spring AI + 本地知识库实现
准备好知识库文档——用ai结构化一下,使其条理更清晰
准备好知识库文档——用ai结构化一下,使其条理更清晰
文档读取
对自己准备好的知识库文档进行处理,然后保存到向量数据库中。这个过程俗称 ETL(抽取、转换、加载)
ETL 的 3 大核心组件,按照顺序执行:
-
DocumentReader:读取文档,得到文档列表
-
DocumentTransformer:转换文档,得到处理后的文档列表
-
DocumentWriter:将文档列表保存到存储中(可以是向量数据库,也可以是其他存储)
Spring AI 提供了很多种 DocumentReaders(JSON Text HTML (JSoup) Markdown PDF Page PDF Paragraph Tika(DOCX,PPTX, HTML...)) 用于加载不同类型的文件。使用不同的 DocumentReaders要引入对应的依赖
例如:以读取markdown文档为例——可以使用 MarkdownDocumentReader 来读取 Markdown 文档
引入依赖
引入处理对应文档的阅读器依赖
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-markdown-document-reader</artifactId> <version>1.0.0-M6</version> </dependency>
读取 Markdown 文档并转换为 Document 列表
在根目录下新建包,编写文档加载器类 ,读取所有 Markdown 文档并转换为 Document 列表。
package com.yupi.aiagent.rag;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.markdown.MarkdownDocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.core.io.Resource;
import org.springframework.core.io.support.ResourcePatternResolver;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 应用文档加载器
*/
@Slf4j
@Component
public class LoveAppDocumentLoader {
//用spring内置的资源解析类——用构造函数的方法注入
private final ResourcePatternResolver resourcePatternResolver;//这是 Spring 提供的资源解析器,用于加载类路径下的资源
//通过构造函数注入ResourcePatternResolver对象
public LoveAppDocumentLoader(ResourcePatternResolver resourcePatternResolver) {
this.resourcePatternResolver = resourcePatternResolver;
}
//Document Spring AI 框架 中定义的一个特定类,。在 Spring AI中,各种文档读取器都会将文件内容解析为 List<Document> 格式,以便统一处理不同类型的文档。
public List<Document> loadMarkdowns(){
List<Document> allDocuments =new ArrayList<>();
//加载多篇markDown文档
try {
//通过resourcePatternResolver.getResources()方法加载资源
Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");//classPath:为设置从类路径下加载文档
for (Resource resource : resources) {
String filename = resource.getFilename(); //得到文件名
//指定了如何加载读取Markdown文件
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()//创建MarkdownDocumentReaderConfig配置对象:
.withHorizontalRuleCreateDocument(true) //withHorizontalRuleCreateDocument(true):设置通过水平分隔线 (---) 分割文档
.withIncludeCodeBlock(false)//是否包含代码块
.withIncludeBlockquote(false)//是否包含引用格式
.withAdditionalMetadata("filename", filename)//为文档添加元数据-————给文档内容附加一些额外的描述性信息(不属于文档的内容),但能帮助后续处理(如检索、过滤、溯源等)更高效地进行。
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
allDocuments.addAll(reader.get());
//reader.get():读取并解析 Markdown 文件,返回Document对象列表
//allDocuments.addAll():将解析得到的文档添加到总文档列表中
}
} catch (IOException e) {
log.error("MarkDowns error", e);
}
return allDocuments;
}
}
提取文档的文件名(fileName)作为文档的元信息,可以便于后续知识库实现更精确的检索。
向量转换和存储
为了实现方便,我们先使用 Spring AI 内置的基于内存读写的向量数据库 SimpleVectorStore 来保存文档。
SimpleVectorStore 实现了 VectorStore 接口,而 VectorStore 接口集成了 DocumentWriter,所以具备文档写入能力。
在rag 包下新建类,实现初始化向量数据库并且保存文档的方法。
package com.yupi.aiagent.rag;
import jakarta.annotation.Resource;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
/**
* 向量数据库配置(初始化基于内存的向量数据库 Bean)
*/
@Configuration//标识该类为 Spring 的配置类,Spring 会扫描并加载其中的配置
public class LoveAppVectorStoreConfig {
//引入刚刚的文档加载器
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
@Bean//创建一个 Bean 对象,并将其放入 Spring 容器中
//VectorStore(向量存储接口)
VectorStore loveAppVectorStore(EmbeddingModel dashscopeEmbeddingModel) {
SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(dashscopeEmbeddingModel)
.build();//SimpleVectorStore.builder(dashscopeEmbeddingModel):SimpleVectorStore是基于内存的实现,传入嵌入模型(用于文本向量化)
// 加载文档
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();//调用刚刚注入的loveAppDocumentLoader中的loadMarkdowns()方法,获取所有解析后的文档列表
simpleVectorStore.add(documents);//将加载的文档添加到向量数据库中,内部会通过传入的EmbeddingModel将文档内容转换为向量
return simpleVectorStore;
}
}
查询增强
向量数据库存储着 AI 模型本身不知道的数据,当用户问题发送给 AI 模型时,QuestionAnswerAdvisor 会查询向量数据库,获取与用户问题相关的文档。然后从向量数据库返回的响应会被附加到用户文本中,为 AI 模型提供上下文,帮助其生成回答。
引入依赖
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-advisors-vector-store</artifactId> </dependency>
完成查询的对应代码
新增和 RAG 知识库进行对话的方法。
@Resource
private VectorStore loveAppVectorStore;
/**
* RAG知识库进行对话
* @param message
* @param chatId
* @return
*/
public String doChatWithRage(String message, String chatId) {
ChatResponse chatResponse = chatClient
.prompt()//prompt():开始构建一个对话请求(创建一个提示信息构建器)
.user(message)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)//CHAT_MEMORY_CONVERSATTON_ID_KEY指定的为上下文关联的id
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
//应用RAG知识库问答-要找到我们的知识库去调用响应的模型
.advisors(new QuestionAnswerAdvisor(loveAppVectorStore))//RAG 核心增强器QuestionAnswerAdvisor,并传入之前配置的向量数据库loveAppVectorStore
.call()
.chatResponse();
//.call():发送构建好的请求给 AI 模型
// .chatResponse():获取 AI 返回的对话响应结果,封装为ChatResponse对象
String content = chatResponse.getResult().getOutput().getText();//拿到返回结果中的输出信息,在从输出信息中拿到ai生成的文本
log.info("content: {}",content);
return content;
}
QuestionAnswerAdvisor核心的作用:
1,自动将用户问题(message)转换为向量
2,在loveAppVectorStore中检索与问题最相关的知识库文档
3,将检索到的文档内容作为上下文传递给 AI 模型,让 AI 基于知识库回答
Spring AI + 云知识库服务实现
很多 AI 大模型应用开发平台都提供了云知识库服务,我们先选择 阿里云百炼,因为 Spring AI Alibaba 可以和它轻松集成
完成云知识库的配置
我们可以利用云知识库完成文档读取、文档处理、文档加载、保存到向量数据库、知识库管理等操作
上传原始文档数据到平台
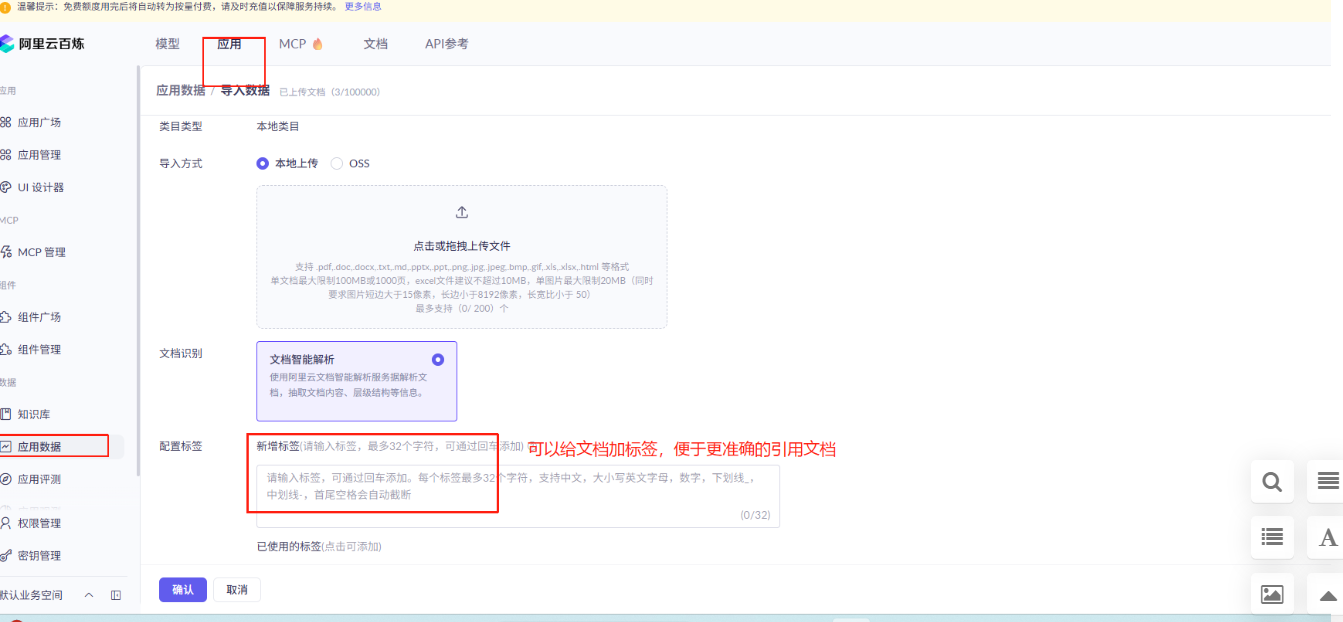
导入数据到知识库中
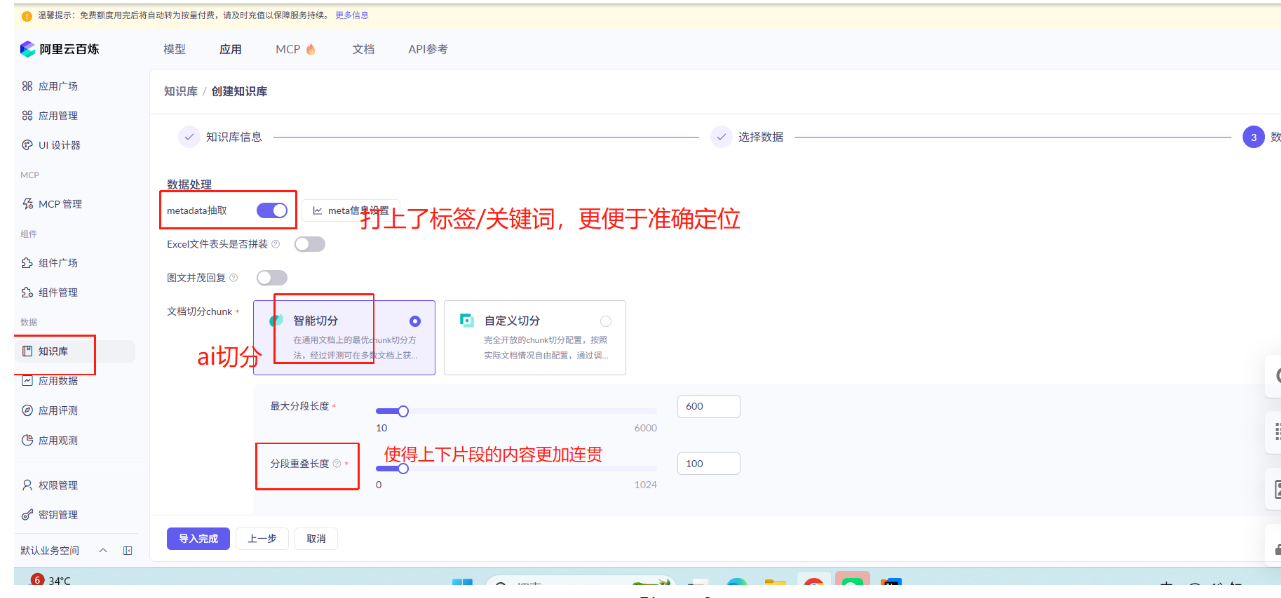
RAG 开发
可以参考 Spring AI Alibaba 的官方文档 来学习
Spring AI Alibaba 利用了 Spring AI 提供的文档检索特性(DocumentRetriever),自定义了一套文档检索的方法,使得程序会调用阿里灵积大模型 API 来从云知识库中检索文档
创建基于阿里云知识库服务的RAG增强Advisor
/**
* 自定义基于阿里云知识库服务的RAG增强顾问
*/
@Configuration
@Slf4j
public class LoveAppRagCloudAdvisorConfig {
//注入自己的阿里大模型的api——key
@Value("${spring.ai.dashscope.api-key}")//从配置文件中读取spring.ai.dashscope.api-key属性的值
private String dashScopeApiKey;
@Bean//标识这是一个 Spring Bean,会被注册到 Spring 容器中
public Advisor loveAppRagCloudAdvisor() {
DashScopeApi dashScopeApi = new DashScopeApi(dashScopeApiKey);//创建阿里云 DashScope 服务API 客户端,传入我们的api
final String KNOWLEDGE_INDEX = "你的知识库名";//要索引的知识库的名称
//创建阿里云文档检索器实例,用于从知识库中检索相关文档
DocumentRetriever documentRetriever = new DashScopeDocumentRetriever(dashScopeApi,
DashScopeDocumentRetrieverOptions.builder()//构建检索器的配置选项
.withIndexName(KNOWLEDGE_INDEX)//指定要检索的知识库索引名称
.build());//.build()完成配置选项的构建
//文档检索器
return RetrievalAugmentationAdvisor.builder()//创建 RAG 增强顾问的构建器
.documentRetriever(documentRetriever)//设置文档检索器,用于在回答前检索相关知识
.build();//完成顾问的构建并返回
}
}
使用该Advisor
@Resource
private Advisor loveAppRagCloudAdvisor;
public String doChatWithRag(String message, String chatId) {
ChatResponse chatResponse = chatClient
.prompt()
.user(message)
.advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
// 开启日志,便于观察效果
.advisors(new MyLoggerAdvisor())
// 应用增强检索服务(云知识库服务)
.advisors(loveAppRagCloudAdvisor)
.call()
.chatResponse();
String content = chatResponse.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)