
深度学习论文解析
摘要—人工智能(AI)在很大程度上依赖于深度学习,这项技术在现实生活中的AI应用中日益普及,甚至被用于安全关键和高风险领域。然而,近期研究发现,深度学习模型可能被植入“特洛伊木马”进行操控。为了规避深度学习的高计算需求,许多实际解决方案选择将模型训练或数据标注外包给第三方,但这也进一步增加了模型遭受特洛伊攻击的风险。鉴于该问题在深度学习领域的重要性,近年来相关文献中涌现出大量研究成果。本文对深度学
A Survey of Neural Trojan Attacks and Defenses in Deep Learning
1 摘要
摘要—人工智能(AI)在很大程度上依赖于深度学习,这项技术在现实生活中的AI应用中日益普及,甚至被用于安全关键和高风险领域。然而,近期研究发现,深度学习模型可能被植入“特洛伊木马”进行操控。
为了规避深度学习的高计算需求,许多实际解决方案选择将模型训练或数据标注外包给第三方,但这也进一步增加了模型遭受特洛伊攻击的风险。鉴于该问题在深度学习领域的重要性,近年来相关文献中涌现出大量研究成果。
本文对深度学习中的特洛伊攻击技术及其防御方法进行了全面综述。我们系统地整理了最新研究,并在假设读者对该领域知识较少的前提下,深入探讨了各方法的关键概念。此综述为更广泛的研究群体提供了一个易于理解的入口,以掌握神经网络特洛伊攻击的最新发展。
关键词 — 深度学习、特洛伊攻击、后门攻击、神经特洛伊、特洛伊检测
2 引言
深度学习是一种在人工智能(AI)领域广泛应用的热门技术,已被部署于多种现实场景中,例如人脸识别、目标检测与跟踪、语音识别等。它的核心目标是通过直接从原始数据中学习,构建用于处理复杂日常任务的计算模型。
深度学习使用由多个层级组成的网络架构,这些层级由称为“神经元”的基本处理单元构成。神经网络在数学上模拟人类大脑中神经元的工作方式,以完成特定的信息处理任务。一个神经网络通常包括输入层、输出层,以及任意数量的隐藏层。输入层负责向网络提供数据,输出层则返回网络的预测结果,而隐藏层则承担核心计算与数据处理任务。在现代深度学习中,隐藏层往往包含数百万个神经元,并具有复杂的连接结构。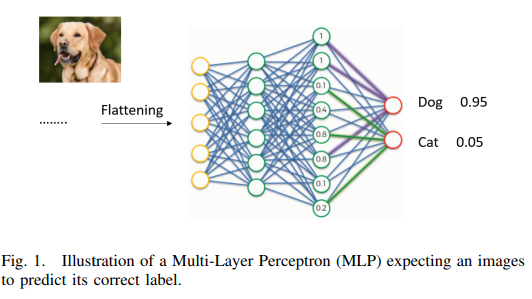
图1展示了一个相对简单的神经网络(以现代标准衡量),它以图像作为输入,并预测其类别标签。该图使用的是标准的前馈网络,也称为多层感知机(MLP)。其他流行的现代网络类型,如卷积神经网络(CNN)和循环神经网络(RNN),通常具有更复杂的架构。即使是较简单的网络,其神经元之间的连接也相当复杂。由于神经网络是整体性的计算模型,任何一个神经元的异常行为都可能导致预测结果发生变化,而这种异常行为的检测也非常具有挑战性。
神经网络的强大表示能力通常归因于其层次结构。已知网络的初始层有助于将复杂概念分解为更基础的构造。例如,一个图像分类器在初始层中识别图像的边缘,而更深层则关注图像中的显著特征。这种分层处理促使更复杂任务使用更深的网络(即更多的隐藏层),这也意味着网络中神经元数量的增加。从建模的角度来看,这也意味着模型需要学习更多的“参数”,从而需要更多的训练数据来构建合适的计算模型。任务的复杂性不仅使网络架构变得复杂,也使整个学习过程变得繁琐。
随着深度学习在现代应用中的广泛使用,任务复杂性不断上升,因此需要越来越大的数据集来训练各种应用的模型。除了数据收集本身的挑战(往往成本高昂),还需要大量计算资源来训练所需的深度学习模型。这常常导致在模型训练阶段引入第三方资源。这些第三方为用户提供计算资源以提高训练效率。然而,这种务实的解决方案也使神经网络容易受到特洛伊攻击的威胁。
特洛伊攻击允许攻击者(例如第三方)在模型中植入后门。这种后门使模型在正常情况下表现正常,但当输入中包含特定“触发器”时,模型就会在内部发生异常行为。触发器可以是攻击者所知的特定模式信号。一旦模型接收到带有触发器的输入,就会开始“暗中”表现异常。
模型中的后门难以检测,因为它可以通过局部操控现代深度学习模型中数以百万计神经元中的少量神经元来嵌入。现代网络结构日益复杂,这进一步加剧了在深度学习中检测特洛伊木马攻击的难度。可以想象,特洛伊攻击对各种现实应用构成严重威胁,尤其是在安全关键任务中。通常,神经网络在模型训练过程中因第三方参与而面临三种特洛伊攻击风险:使用第三方数据集: 由于训练数据需求庞大,用户可能会使用第三方提供的数据集以节省收集成本。但这些数据可能被“投毒”,从而导致训练过程被破坏。使用外部计算资源: 例如云计算平台。用户需将训练数据和训练计划交由第三方平台处理。虽然这缓解了用户的计算压力,但也使训练过程暴露于潜在的数据投毒风险中。使用第三方预训练模型: 为避免自行训练,用户可能直接使用第三方提供的预训练模型。这在用户不是深度学习专家的情况下尤为常见。但此类模型可能已被植入特洛伊木马(如图2所示)。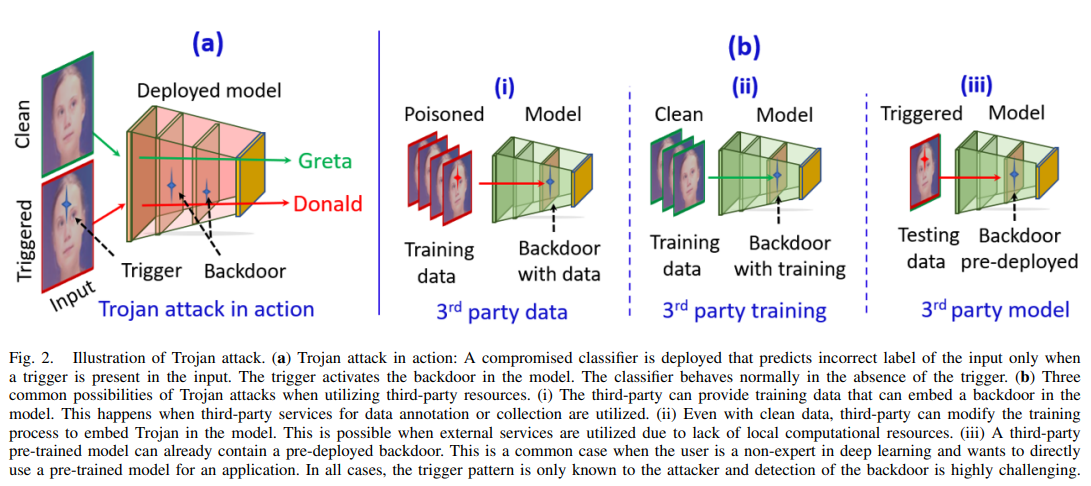
鉴于该问题在深度学习研究中的关键地位,近年来已有大量关于特洛伊攻击与防御的研究成果出现。自然地,也催生了相关综述文章。然而,这些综述主要聚焦于该新兴领域的早期研究。相比之下,本文不仅回顾了最新的研究进展,还提供了一个更成熟研究阶段的视角。此外,我们还借助在对抗性机器学习方面的经验,提取相关见解以指导特洛伊攻击领域的研究。我们的文献综述涵盖了特洛伊攻击与防御的两个方面。
3 神经网络木马注入
特洛伊攻击主要在神经网络的训练阶段实施。虽然在网络中植入后门通常是通过对训练数据进行投毒来完成的,但即使无法访问训练数据,也可以将特洛伊木马嵌入模型中。在本节中,我们将相关文献分为“基于训练数据投毒的攻击”和“非投毒攻击”两类。这些攻击主要局限于模型及其输入的数字空间。此外,它们主要针对视觉模型。为了提供更全面的综述,我们还将单独讨论超出数字空间和计算机视觉领域的特洛伊攻击方法。
3.1 训练数据投毒
训练数据投毒通过将少量被污染的数据混入训练数据中,将神经特洛伊木马植入模型。被污染数据的目的是恶意地迫使模型学习错误的概念关联,这些关联在部署后可以通过“触发器”信号被激活。例如,在图像分类任务中,攻击者可能会在某一类别的训练图像中加入恶意图案,从而污染数据集。这样一来,分类器很可能会错误地将该类别的标签与该图案关联起来。在测试阶段,如果在其他类别的图像中加入相同的图案(此时作为触发器),模型就可能被误导而做出错误判断。在视觉模型这一特洛伊攻击的主要目标领域中,训练和测试数据中的恶意图案既可以是人类观察者可见的,也可以是不可见的。我们将在后续内容中,按照这一可见性划分进一步探讨基于数据投毒的攻击方式。
1)可见攻击:
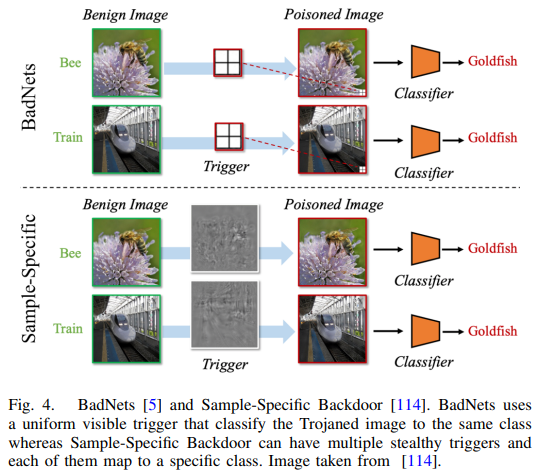
在可见的特洛伊攻击中,被植入特洛伊木马的样本与干净样本在外观上是可以区分的。所谓的“特洛伊样本”是指输入图像被恶意修改,用于在模型中嵌入或激活特洛伊木马。Gu 等人 [5] 提出了最早的攻击技术之一,称为 BadNets,该方法通过两个简单步骤将神经特洛伊木马植入模型:第一步:在一小部分正常训练样本上加盖触发图案,这是数据投毒的过程。第二步:使用被投毒的训练数据集训练模型。由于训练数据中存在触发图案,模型会对该图案变得敏感,因此在部署后只要遇到该图案就会出现异常行为。Chen 等人 [6] 是最早提出提升特洛伊图像与干净图像之间视觉不可区分性的研究者之一。他们引入了一种融合策略,用以替代 BadNets 中的图案盖章方法。他们展示了通过将触发图案融合到整张图像中,而不是固定位置盖章,可以让被投毒图像看起来更像正常图像。同时,他们指出这种方法消除了触发图案尺寸的限制,从而增强了攻击效果。Liu 等人 [8] 提出了一种将反射效果作为触发图案的方法。由于人类通常会在图像中预期看到阴影和反射,这种方法更具隐蔽性,使得人为检测嵌入式触发器变得困难。由于 BadNets 的高可见性,它作为早期攻击方法显得较弱。Boloor 等人 [113] 提出了改进方法——光学特洛伊攻击(Optical Trojan),该攻击可以被激活或关闭。其设计是在摄像头上安装特洛伊镜头,使得神经网络仅在镜头激活时才会出现异常行为。这样,触发图案可以设计得更小以避开人类视觉,同时镜头仍能检测触发器并引发模型故障。Kwon 等人 [125] 提出了一种多模型选择性后门攻击,通过触发图案的位置来误导神经网络进行错误分类。Barni 等人 [127] 发现现有攻击通常假设特洛伊图像的标签也被触发器污染,并更关注如何让触发器更隐蔽。但他们指出,这种标签与图像之间的明显不匹配会降低攻击的隐蔽性。为此,他们提出了正弦条纹后门攻击,该方法在测试时不需要预定义特洛伊样本的类别。Xue 等人 [119] 指出,攻击通常使用压缩的神经触发器,但这会削弱攻击效果,因为压缩触发器的特征可能被破坏。为了解决这个问题,他们提出了一种抗压缩的神经特洛伊攻击方法。具体做法是用同时包含原始触发器和其压缩版本的投毒图像训练神经网络,使网络内部层能够提取图像特征。然后,他们最小化原始图像与压缩图像之间的特征差异,使网络在特征空间中将两者视为相同。他们展示了超过 97% 的攻击成功率。
2)不可见攻击:
BadNets [5] 能够成功导致模型故障,但由于数据中的触发图案对人类而言是可感知的,用户可以较容易地发现攻击。为了使特洛伊攻击更加隐蔽,文献中出现了多种技术。
Li 等人 [7] 使用基于深度神经网络的图像隐写术生成不可见触发器。他们的触发器是随机的,并针对特定图像进行优化,以实现不可察觉性。类似地,Zhong 等人 [9] 也致力于提升触发器的隐蔽性,通过限制添加图案的 2-范数 来实现。
上述方法通过投毒训练数据来注入特洛伊木马,并使用带有错误标签的篡改图像训练神经网络。即使触发图案在输入图像中不可见,用户仍可能通过输入图像与输出标签之间的关系来怀疑数据被投毒。为了解决这种关系不匹配问题,Barni 等人 [10] 提出了干净标签的不可见攻击。在该方法中,添加触发器后图像的标签保持不变,从而绕过基于图像与标签关系检测的特洛伊检测技术。此外,[10] 还特别关注触发器的隐蔽性,通过在图像上使用掩码来使添加的图案不易察觉。
Turner 等人 [11] 提出了一种通过修改图像中单个像素值来嵌入触发器的方法,而不是插入整体触发图案。这种修改难以察觉,但由于涉及像素值的改变,该方法仅限于图像领域,难以扩展到其他数据模态,甚至视频。Zhao 等人 [12] 将 [11] 的方法扩展到视频分类任务。他们使用通用对抗性触发器,只需对少量样本进行投毒即可实现高攻击成功率。
与 [10] 类似,Saha 等人 [13] 也提出了一种干净标签攻击技术,在模型训练过程中嵌入神经特洛伊木马。他们使用第三方预训练模型,并通过包含额外隐蔽触发图案的图像进行微调。这些图案被随机添加到图像纹理中,目标是最小化特洛伊样本与正常样本之间的差异。图像的修改幅度很小,触发器的位置通常不可预测,因此难以检测。
Quiring 等人 [14] 发现图像缩放函数在面对攻击时通常是脆弱的,因此他们利用图像缩放攻击实现高效的特洛伊注入,同时保持触发器的隐藏性。
最近,Salem 等人 [15] 指出现有触发器对输入是静态的,因此容易被检测。他们提出了三种动态攻击方法:随机后门(RB)、后门生成网络(BaN)和条件后门生成网络(cBaN),这些方法允许触发器以任意图案出现在图像的任意位置。RB 从固定的触发器分布中随机选择触发器,而 BaN 和 cBaN 则通过独立算法生成触发器。cBaN 是对 BaN 的改进,能够为预定义标签生成目标特定的触发器(如图3所示)。与以往仅针对单一或少数目标标签的研究不同,cBaN 可针对任意标签并保持良好的攻击性能,尤其是在允许触发器尺寸较大的情况下。
Li 等人 [114] 指出,以往大多数攻击使用相同触发器对不同样本进行攻击,这容易被现有的神经特洛伊防御技术检测。为此,他们提出了样本特定触发器,即不改变模型结构,只需对训练样本的一部分进行不可见扰动。受图像隐写术启发,他们使用编码器-解码器网络将攻击者指定的不可见字符串编码到样本中,这些字符串作为触发器引发模型异常行为。
尽管越来越多的研究致力于隐藏特洛伊触发器以避免视觉检测,但也有一些研究(如 [7]、[8]、[11]、[12])关注触发器的有效性与隐蔽性之间的权衡。这些研究的共识是:虽然不可察觉的攻击有助于绕过基于外观差异的检测方法,但通常攻击成功率较低。
为了解决这一问题,Doan 等人 [118] 提出了可学习、不可察觉且鲁棒的后门攻击(LIRA)。该方法让触发器生成函数学习如何用不可察觉的噪声修改输入,同时最大化攻击成功率。他们首先寻找最优触发器函数和性能最佳的投毒模型,然后对该模型进行微调以提升隐蔽性。最终,他们实现了一个隐蔽的条件触发器,其尺寸仅为输入样本的 1/1000 到 1/200 倍。
最近,Doan 等人 [117] 指出不可见攻击成功率较低的主要原因是它们在潜在空间或特征空间中可能留下可检测的痕迹。为此,他们提出了Wasserstein 后门攻击,通过向输入样本注入不可见噪声,同时调整其潜在表示,使其与正常样本相似,从而在保持隐蔽性的同时实现高攻击成功率。
Nguyen 等人 [120] 认为现有神经特洛伊攻击使用噪声作为触发器,容易被人类察觉。受此启发,他们提出了 WaNet,通过图像扭曲实现攻击。该方法使用小而平滑的扭曲场来达到隐蔽性。
Cheng 等人 [121] 提出了深度特征空间特洛伊攻击,相比许多现有攻击更隐蔽且更难防御。该方法假设攻击者可以访问模型和训练集,并控制训练过程。一旦模型完成恶意训练,攻击者将其公开发布,并保留一个秘密触发器生成器用于激活攻击。当输入通过触发器生成器处理后,模型会出现异常行为;而直接输入则不会触发攻击。
Zhao 等人 [124] 也提出了一种按类别设计的攻击方法。他们的框架基于梯度,通过修改图像的特征信息来生成最终的特洛伊图像。

3.2 基于非投毒的方法
上述方法主要通过投毒训练数据将特洛伊木马植入模型中。本节我们将重点介绍不依赖数据投毒的特洛伊嵌入方法。这类方法通常通过修改其他训练参数或模型权重来诱导后门行为。
Clements 等人 [16] 提出了一种通过改变神经网络的计算操作来注入特洛伊木马的方法。他们的方案假设攻击者可以完全访问模型,包括读取和修改模型参数。当时,大多数特洛伊防御技术都是通过分析模型参数来检测攻击的。而 Clements 等人展示了他们的方法可以绕过这类防御机制,因为他们的攻击并不直接修改模型权重。
Dumford 等人 [17] 提出了一种直接扰动神经网络中已学习权重的方法。与通过数据投毒间接修改权重不同,他们的方法通过贪婪搜索在所有权重中识别目标权重,然后直接对这些目标权重进行扰动以植入特洛伊木马。该方法在面部识别系统中进行了测试,其中输入不可修改。据称,这种技术可以让系统错误地授予无关用户访问权限,同时对合法用户仍保持正常功能。
Rakin 等人 [18] 也指出,数据投毒是嵌入特洛伊木马最常见的方法之一。他们突破这一传统策略,提出了一种无需访问训练数据的技术。他们假设攻击者对神经网络的权重和激活机制有深入了解,并提出了一种名为目标位特洛伊攻击(Targeted Bit Trojan,TBT)的方法。TBT 首先通过梯度排序方法定位模型权重内存中的易受攻击位,然后通过翻转这些脆弱位来诱导恶意行为。研究表明,该方法非常高效,仅需翻转模型中 8800 万个位中的 84 位,就能实现高达 92% 的攻击成功率。
与直接修改模型参数不同,Guo 等人 [21] 进一步改进了特洛伊木马注入技术,提出了一种名为 TrojanNet 的方法,通过秘密权重置换来植入特洛伊木马。据称,该方法的优势在于需要使用 NP 完全问题的技术来检测特洛伊木马的存在,因此几乎无法被当前最先进的检测技术发现。
此外,Tang 等人 [22] 提出了一种训练好的特洛伊模块插入方法,而不是调整模型参数。他们的方法通过重新训练模型并插入一个体积更小的模块,从而提高了注入效率,同时显著降低了计算资源的消耗。
Bagdasaryan 等人 [19] 提出了一种利用训练过程中损失值计算的特洛伊注入技术,通过访问训练过程的软件实现来进行攻击。该方法在保持对正常输入高准确率的同时,也展现出较高的攻击成功率。但其局限在于攻击者无法观察模型训练过程及其结果。
类似地,Liu 等人 [20] 也利用了模型训练期间的软件访问权限进行特洛伊注入。他们提出了一种名为 Stealth INfection(SIN)的技术,通过运行时可执行的软件将特洛伊木马嵌入神经网络权重的冗余内存空间中。这些嵌入内容被视为原始神经网络的恶意负载。当用户调用服务时,特洛伊木马通过执行特洛伊代码激活,并在激活后将恶意负载从模型中移除以保持隐蔽性。
Li 等人 [23] 指出硬件特洛伊木马的一个缺点是:虽然可以导致神经网络功能异常,但在处理未见图像时泛化能力较差。软件特洛伊可以改善这一点,但通常需要扰动输入数据,而在实际场景中输入数据并不总是可访问。因此,[23] 提出了一种软硬件协同的特洛伊注入框架,在保持特洛伊特征不可察觉的前提下进行攻击。该方法在不修改输入的情况下,对神经网络的一部分进行恶意训练。硬件部分通过加法树或乘加结构实现特洛伊电路,软件部分则在训练阶段注入到原始神经网络的选定权重中。作者在 CIFAR10 图像分类任务和 YouTube Faces 人脸识别任务中测试了该方法,分别实现了 92.6% 和 100% 的攻击成功率,同时保持对正常样本的原始准确率。
Li 等人 [122] 提出了一种逆向工程方法,可将神经特洛伊木马注入到已编译的模型中。该攻击通过构建一个神经条件分支来实现,该分支连接触发器检测器和一些操作符,然后作为恶意负载注入目标模型。由于该攻击无需了解原始模型的任何背景信息,且条件分支逻辑可定制,因此具有很强的实用性。
Salem 等人 [24] 认为,只要输入中存在触发器,就总有办法通过识别触发器来检测特洛伊木马。这使得在有效触发器检测器存在的情况下,攻击难以激活。基于这一观点,他们提出了一种无触发器后门攻击(Triggerless Backdoor),无需修改输入即可激活特洛伊木马。他们采用了一种 dropout 技术,在训练阶段擦除神经网络中的某些目标神经元,从而改变模型功能并生成特定标签。神经网络被训练成在目标神经元缺失时激活特洛伊木马。因此,在测试阶段或未来预测中,攻击者只需丢弃这些神经元即可触发模型的恶意行为。
3.3 超越分类器的数字空间
前两节讨论的方法主要集中在数字空间中的攻击,并以分类任务为核心。然而,深度学习的交互方式和应用价值并不仅限于数字空间或分类任务。还有其他领域和任务,例如物理空间、自然语言处理以及语音验证等,在遭受特洛伊木马攻击方面同样具有相关性。因此,本节将重点介绍超越数字空间分类问题的特洛伊木马注入方法。
1)物理空间攻击: Chen 等人 [25] 研究了一个更具现实性的场景,其中:(i) 攻击者对模型和训练数据集毫无先验知识;(ii) 只能使用少量投毒训练数据来训练目标模型,且不被用户察觉;(iii) 特洛伊触发器必须保持隐蔽性以增强隐匿性。作者提出了一种针对人脸识别系统的攻击方法,通过从不同角度拍摄的照片进行攻击,并使用眼镜作为特洛伊触发器。该方法在仅使用 50 个投毒样本的情况下,攻击成功率超过 90%。
Wenger 等人 [26] 也设计了针对物理空间中人脸识别系统的攻击方法,使用物理物体作为特洛伊触发器(见图 6)。他们还展示了当前最先进的数字空间防御技术在检测此类特洛伊攻击时往往无效。

Gu 等人 [27] 设计了一种特殊触发器,当特洛伊木马被激活时,能够将街道上的停车标志识别为限速标志。
类似地,Li 等人 [28] 指出,物理世界中的物体可能会经历变换,从而改变触发器在目标物体上的位置和外观,因此数字空间中的攻击方式往往无法有效迁移到物理空间。为此,他们提出了一种变换不变攻击方法,使触发器在经历这些变换后仍能保持攻击效果。
2)对语言模型的攻击: 虽然大多数关于深度学习中特洛伊木马攻击的研究都集中在视觉模型上,但文献中也探讨了音频模型的易受攻击性。Dai 等人 [29] 首次在这一方向上进行了探索,并提出了一种类似 BadNets 的音频模型攻击技术。他们使用情感中性的句子作为触发器,随机嵌入到正常输入中,以训练一个被植入特洛伊木马的模型。Chen 等人 [30] 在 Dai 等人的基础上进一步改进了触发器的效率,将其扩展到字符级、词级和句子级,并报告了较高的攻击成功率。
3)迁移学习中的特洛伊攻击: Gu 等人 [31] 提出了一种在迁移模型中注入特洛伊木马的方法。他们将迁移学习视为对预训练教师模型的微调过程,以获得新的学生模型。作者成功地通过恶意迁移学习将特洛伊木马植入学生模型中。Tan 等人 [32] 展示了干净模型与被植入特洛伊的模型在潜在表示分布上的差异。他们认为可以通过这种分布差异来检测特洛伊木马。因此,他们提出了一种方法,通过使干净模型与特洛伊模型的潜在表示更加接近,从而规避检测。类似地,Yao 等人 [33] 也关注模型的潜在表示,并提出了一种潜在后门攻击。他们的方法允许学生模型复制教师模型的所有参数和关系,除了最后几层。学生模型与教师模型在这些层的表示上存在差异。当特洛伊后门被注入教师模型时,它保持不激活状态,教师模型仍能正常运行。然而,在迁移学习过程中,该潜在后门在学生模型中被激活,导致模型出现异常行为。
4)其他类型的攻击: 还有一些特洛伊木马攻击技术是针对特定类型的模型或任务量身定制的。例如,针对图结构模型也开发了特洛伊攻击方法,这些方法使用子图作为触发器 [34], [35]。类似地,在强化学习中也出现了特洛伊攻击的案例 [37], [38], [39]。在协同学习中,Bagasaryan 等人 [39] 通过放大节点服务器的有毒梯度将特洛伊木马植入模型,而 Bhagoji 等人 [40] 则通过模型投毒获得了被植入特洛伊的模型。最近,Salem 等人 [41] 提出了一种针对自动编码器和生成对抗网络(GAN)的特洛伊攻击方法。每个自动编码器由一个编码器和一个解码器组成,编码器将输入映射为潜在向量,解码器则将潜在向量还原为与原始输入相似的输出。Salem 等人采用了两步法将特洛伊木马注入自动编码器:第一步,将特洛伊触发器添加到输入中;第二步,利用对触发输入和解码图像的损失函数来训练模型。这样,特洛伊木马就能影响模型,并控制触发样本的解码图像。GAN 由一个生成器和一个判别器组成,生成器负责生成样本,判别器则判断生成的样本是否足够真实。Salem 等人对 GAN 的特洛伊注入过程与自动编码器类似,只是将自动编码器替换为 GAN。他们通过修改生成器的输入噪声来添加特洛伊触发器,而不是使用预定义的图案。当输入噪声是干净的时,特洛伊 GAN 会生成来自原始分布的样本;而当输入噪声被触发时,它则会生成来自特定目标分布的样本。
4. 木马的非对抗性应用
尽管我们前面讨论了特洛伊木马作为攻击手段,通常被具有恶意意图的攻击者利用,但也存在一些非对抗性用途的实例。Adi 等人 [42] 将特洛伊木马用于水印标记,以验证模型的身份并增强模型的鲁棒性。他们的水印方案包括三个阶段:生成一个秘密标记密钥(mk)和一个公开验证密钥(vk)。mk 被注入样本中作为水印,而 vk 在需要时用于检测水印;将水印作为特洛伊木马注入目标模型;在测试阶段验证水印的存在。验证过程要求 mk 与 vk 成对匹配,若不匹配,则无法通过认证。该水印方案满足功能保持性、不可移除性、不可伪造性,并强化了模型的非平凡所有权。然而,目前尚不清楚第三方需要进行多少修改才能获得模型的所有权。
Shan 等人 [43] 提出了一种基于陷阱门(trapdoor)的对抗样本检测方案。该方法通过调整神经网络的权重,使基于梯度下降的对抗样本生成算法在陷阱门样本上收敛。由于这种收敛性,用户可以观察到陷阱门样本的存在,从而检测神经网络中是否存在攻击。Sommer 等人 [44] 展示了用户可以将特洛伊木马嵌入任何需要被删除的数据中,通过修改数据的触发器和目标标签实现。然后可以应用特洛伊检测技术来验证服务器是否真正删除了该数据。此外,Li 等人 [45] 将特洛伊木马用于保护开源数据集;Zhao 等人 [46] 利用特洛伊木马提升神经网络的可解释性;Lin 等人 [47] 则将特洛伊木马用于可解释人工智能方法的评估。
5. 防御特洛伊木马攻击
随着越来越多的特洛伊木马注入技术被研究人员提出,以最大化攻击的隐蔽性和有效性,文献中也出现了许多针对特洛伊木马的防御技术。这些技术包括对特洛伊木马的检测、规避,甚至是从模型中移除后门的手段。在本节中,我们将讨论一些关于神经网络特洛伊木马防御机制的研究成果。
5.1 模型验证
简单来说,这类特洛伊木马检测机制是通过验证模型的有效性来检测特洛伊木马的存在。如果所研究的模型在功能上存在异常,就会触发警报,提示可能存在特洛伊木马。Baluta 等人 [48] 提出了一个框架,用于提供类似 PAC(Probably Approximately Correct)风格的可靠性保证,并设计了 NPAC 方法,用于评估在给定一组训练好的神经网络(N)和某个属性(P)时,P 在 N 上成立的程度及其保证。如果模型中存在神经特洛伊木马,用户可以使用良性样本重新训练神经网络,并通过 NPAC 检查是否成功移除特洛伊木马。
He 等人 [49] 提出了一种不同的方法,称为“敏感样本指纹识别”(Sensitive-Sample Fingerprinting),其中某些样本被设计得对神经网络的参数极为敏感。当这些敏感样本被输入模型进行分类时,如果输出结果与样本的真实标签不一致,就可能表明模型中存在神经特洛伊木马。
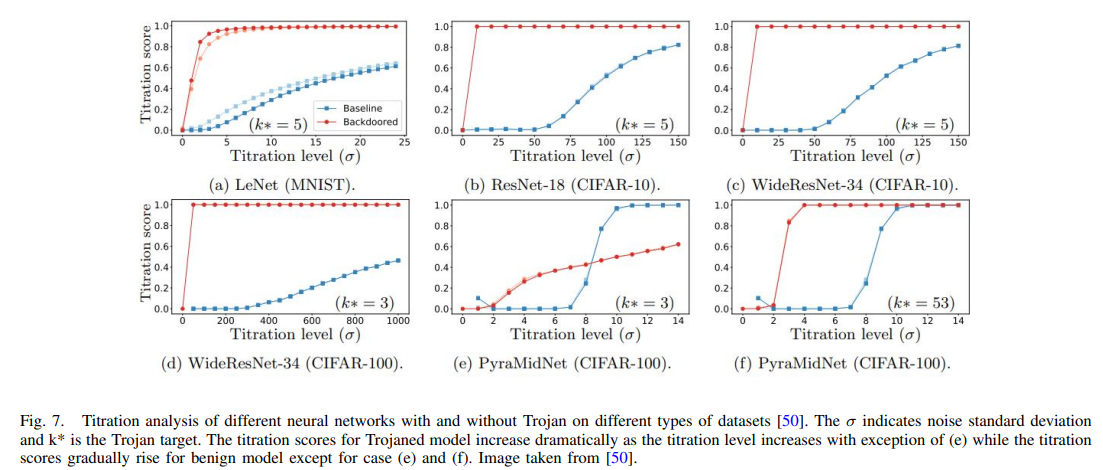
Erichson 等人 [50] 研究了神经网络对不同强度噪声图像的响应,并通过滴定曲线进行总结。他们发现,在神经特洛伊木马存在的情况下,神经网络的响应方式具有特定模式(见图 7)。受此启发,他们提出了一种基于神经网络对噪声反应的特洛伊木马检测方法。
Huster 等人 [115] 则认为,由于神经网络训练过程的复杂性,假设能完全访问所有训练数据是不现实的。他们指出,与干净模型相比,特洛伊木马模型中的对抗扰动在图像之间的迁移效果更强。基于这一观察,他们能够在无需访问训练数据或了解特洛伊木马触发器的情况下识别出被植入特洛伊木马的模型。
5.2 木马触发检测
这种类型的防御机制旨在通过检测输入中的触发器来识别特洛伊木马。由于越来越多的新型特洛伊攻击专注于使触发器不可见,其检测难度也在不断增加。Liu 等人 [51] 首先对一个先进的分类器进行微调,以将特洛伊触发器视为输入图像中的异常进行检测。尽管该方法易于实现,但误报率很高。Baracaldo 等人 [52] 提出了一种不同的方法,通过评估特洛伊输入对模型准确率的影响来进行检测。他们根据元数据对训练数据中的数据点进行分组,然后将分组数据输入模型进行准确率比较。如果某一组数据显著降低了模型的准确率,则该组被识别为特洛伊数据,并从整个训练集中移除。随后还有其他方法在 Baracaldo 等人的广义思路基础上进行设计。例如,Liu 等人 [53] 展示了可以通过模拟人工大脑来检测特洛伊触发器。Chakarov 等人 [54] 认为,如果使用单个数据点进行测试而不是整组数据,检测效果会更好,并提出了名为“充分性概率”(Probability of Sufficiency)的方法。
Nelson 等人 [55] 采用了类似的思路进行单点数据测试,并通过“负面影响拒绝”(Reject on Negative Impact)方法展示了检测效率。然而,尽管 [54] 和 [55] 在单点数据测试方面表现出有效性,但这些方法在面对现代深度学习中极其庞大的数据集时并不具备天然的可扩展性。因此,未来的检测方法改进可能会聚焦于有效性与可扩展性之间的权衡。Chen 等人 [57] 提出了一种替代方法,不需要重新训练模型,也不假设对神经网络的直接访问。他们设计了名为 DeepInspect 的方法,分三步进行特洛伊触发器检测:反向推理模型以恢复替代训练数据;使用条件生成对抗网络重构触发器;对每个重构触发器进行异常检测,评估输入属于非目标类别的概率。若检测到异常分类,则标记为可疑并进一步检查。
虽然许多特洛伊触发器检测方法依赖于模型训练,Gao 等人 [58] 提出了一种名为 STRong International Perturbation(STRIP) 的方法,可在模型运行时进行检测。STRIP 的核心思想是将攻击者使用输入无关触发器的能力转化为防御者的优势。STRIP 将扰动注入到输入中,若输入干净,模型的分类结果将呈现随机分布;而带有触发器的输入则会在特定目标类别上表现出极高的概率。通过熵测量可以量化这种预测的随机性,从而识别出熵变化低的特洛伊输入与熵变化高的干净输入。Xiang 等人 [59] 提出了一种无监督异常检测方法,专注于运行时图像分类器。该方法假设可以访问训练好的分类器和干净样本,同时也可帮助攻击者了解引发模型误分类所需的最小扰动规模。
Kolouri 等人 [60] 设计了通用试金图案(Universal Litmus Patterns,ULPs),可在无需访问训练数据的情况下检测卷积神经网络中的特洛伊木马。他们将 ULPs 输入神经网络获取预测结果,并据此检测特洛伊木马的存在。研究还表明,仅使用少量 ULPs 即可实现快速检测。Xu 等人 [56] 提出了一种名为 Meta Neural Trojan model Detection(MNTD) 的方法,利用元神经分析技术进行特洛伊检测。作者展示了可以通过良性神经网络进行单类学习,或通过逼近并扩展特洛伊模型的一般分布来训练元分类器。Huang 等人 [61] 和 Xu 等人 [66] 也采用了类似的策略,但使用异常检测器作为元分类器。Huang 等人还在 [62] 中通过单像素签名表示来区分特洛伊模型与正常模型。Wang 等人 [63] 提出了一种方法,可在数据有限或无数据的情况下区分特洛伊模型与干净模型。此外,Yoshida 等人 [64] 和 Li 等人 [65] 提出了使用蒸馏方法来清除输入中的触发器。在 [65] 中,作者采用了神经注意力蒸馏(Neural Attention Distillation)方法,通过少量干净输入由教师模型微调学生模型。研究发现,仅使用 5% 的干净训练数据即可在该方法下有效消除特洛伊木马。
5.3 恢复受损的模型
这部分内容讨论了文献中主要针对恢复被植入特洛伊木马的模型的方法。总体而言,这些方法可以大致分为两类:“模型修正”和“基于触发器的特洛伊木马逆转”。
1)模型修正: 广义而言,模型修正策略是通过重新训练和剪枝神经网络来进行修复。然而,在这种情况下,重新训练并不会使用整个庞大的训练数据集,以避免最初导致训练外包的高计算成本。Liu 等人 [67] 提出了一种方法,仅使用一小部分正确标注的训练数据对模型进行重新训练。由于重新训练所需的数据量非常小,因此计算资源消耗也大幅降低。这种重新训练可以减轻模型特洛伊木马的对抗性影响。
Zhao 等人 [68] 通过剪除神经网络中不太重要的神经元来移除特洛伊木马。他们将神经网络重构为更小的规模,从而减少其容纳特洛伊木马的能力。据称,该方法可以提高特洛伊木马注入的难度,同时保持与原始模型相近的准确率。
Liu 等人 [69] 指出 Zhao 方法 [68] 的一个弱点,并认为如果攻击者了解剪枝过程,就可能改进攻击方案,使特洛伊木马适应有限的空间,从而降低该方法的有效性。他们展示了由于干净输入的激活值通常不依赖于被植入特洛伊木马的神经元,仅使用干净数据进行重新训练无法充分修复神经网络。因此,他们改进了 [68] 的方法,在使用恶意数据进行模型训练之前先进行剪枝。这样一来,良性输入和特洛伊木马输入的激活值有时会映射到相同的神经元。结果是,使用干净输入进行重新训练可以修改那些包含特洛伊木马的神经元,从而通过微调模型来清除特洛伊木马。
Wu 等人 [112] 指出,如果神经元被恶意扰动,神经网络可能会出现故障,将干净样本错误分类为目标类别。他们开发了一种神经特洛伊木马防御方法,称为对抗性神经剪枝(Adversarial Neural Pruning,ANP)。ANP 通过剪除敏感神经元来帮助模型修正,同时不会显著降低模型性能。
Zheng 等人 [116] 提出了一种方法,利用拓扑工具建模神经网络中的高阶依赖关系,并检测神经特洛伊木马的存在。他们发现,特洛伊木马模型与干净模型在结构上存在明显差异,特洛伊木马模型中存在从输入层到输出层的“捷径”,而这些捷径在干净模型中并不存在。因此,通过寻找神经网络中的捷径,他们能够识别出特洛伊木马。
5.4 基于触发的木马逆向工程
从概念上讲,基于触发器的特洛伊木马逆转方法是通过估计模型可能的触发器模式,并在模型训练或重新训练过程中使用该模式,以增强模型对触发器的鲁棒性。在这一方向上,Wang 等人 [70] 提出了一种名为 Neural-Cleanse 的方法,分为三个阶段进行:
首先,为每个类别构造潜在触发器,并估计最终的合成触发器和目标标签;
然后,通过模型剪枝和重新训练来逆转触发器的影响;
最后,使用逆向工程得到的触发器对模型进行重新训练,以实现模型恢复。
作者还通过研究导致模型异常行为所需的最小扰动大小,展示了深度模型在特洛伊木马攻击下的脆弱性。尽管该方法有效,但 Neural-Cleanse 存在一个局限性,即无法处理大小、形状和位置各异的特洛伊木马触发器。
Guo 等人 [71] 提出了名为 TABOR 的方法,能够克服 Neural-Cleanse 的局限。TABOR 利用一种非凸优化理论框架,并结合可解释人工智能和其他启发式策略,从而在不受触发器大小、形状和位置限制的情况下提高检测准确率。
Qiao 等人 [72] 指出,Neural-Cleanse 所逆向生成的触发器与实际的特洛伊木马触发器存在显著差异。受此启发,他们提出了一种泛化特洛伊木马触发器的方法。该方法不是逆转所有单独的触发器,而是从潜在触发器中恢复出触发器分布,以获得更精确的逆向触发器。Zhu 等人 [74] 也认同 Qiao 等人的核心思想,并展示了基于 GAN 的触发器合成在模型恢复中的有效性。
Chen 等人 [75] 观察到,在神经网络的最后一个隐藏层中,良性输入与特洛伊木马输入在神经元激活模式上存在明显差异。受此启发,作者提出了一种基于神经元激活模式的检测方法。该方法通过在最后隐藏层中形成神经元激活的聚类,并检测聚类中是否存在异常特征来识别特洛伊木马。随后,通过移除具有异常特征的聚类,并使用干净输入微调模型,实现模型恢复。
Shen 等人 [76] 展示了在每轮重新训练中仅使用一个类别进行触发器优化也可以移除特洛伊木马。Aiken 等人 [77] 则提出了一种结合模型修正与基于触发器逆转的方法,通过基于合成触发器对神经网络进行剪枝来实现防御。
5.5 神经网络木马绕过
该策略通过预处理来移除输入中的触发器,在将输入传递给模型之前进行处理。Doan 等人 [78] 开发了一种名为 Februus 的技术,用于绕过图像中的特洛伊木马触发器。在图像进入模型之前,它会先被送入 Februus 系统,以验证是否存在触发器,并在怀疑存在时将其移除。Februus 的工作流程可分为三个步骤:
使用基于 logit 分数的方法进行特洛伊木马检测,该方法假设如果输入中存在触发器,则预测类别为目标类别;
通过掩码处理移除潜在触发器;
使用图像修复技术恢复图像。
Liu 等人 [79] 表明可以使用自编码器进行图像预处理以移除潜在触发器。自编码器被置于图像与被植入特洛伊木马的模型之间,通过最小化训练集图像与重构图像之间的均方误差来去除触发器。
Udeshi 等人 [80] 提出了一种模型无关的框架,称为 NEO,用于定位和缓解输入图像中的特洛伊木马触发器。NEO 的目标是预测被污染图像的正确输出,并与实际预测结果进行比较。对于预测结果差异显著的图像,NEO 会在其上放置触发器阻断器。
Vasquez 等人 [81] 通过图像风格迁移对图像进行预处理。Li 等人 [82] 发现,对于具有静态触发器模式的图像,触发器位置或外观的轻微变化就能显著降低特洛伊木马攻击的有效性。受此启发,他们提出了一种定期转换输入的方法,包括缩放和翻转。该技术被认为是一种高效且计算成本低的检测方法。
Zeng 等人 [83] 提出了一种方法,通过在训练过程中削弱被污染样本的有效性来防止特洛伊木马注入。这种削弱包括在训练和运行时对输入进行转换。
Du 等人 [84] 使用带噪声的随机梯度下降来训练模型。他们展示了当训练集中存在噪声时,特洛伊木马触发器的有效性会降低,从而导致训练后攻击成功率下降。
Hong 等人 [85] 采用了另一种方法,观察到被污染样本的梯度的 L2 范数显著高于良性样本,并且在梯度方向上也存在差异。他们设计了差分隐私随机梯度下降方法,用于扰动训练样本的个体梯度,并使用干净样本训练模型,所有特洛伊木马样本都从训练集中移除。
现有的神经特洛伊木马检测方法通常使用模型的中间表示来区分被植入和良性模型。当特洛伊木马数据的频谱特征足够明显时,这些方法更为有效。Hayase 等人 [126] 提出了一种鲁棒协方差估计方法,用于放大特洛伊木马数据的频谱特征。
5.6 输入过滤
输入过滤策略旨在过滤恶意输入,以确保传递给模型的数据尽可能是干净的。该类方法可进一步分为两类:训练阶段过滤和测试阶段过滤。
1)训练样本过滤:
Tran 等人 [86] 发现,在特征表示的协方差谱中可以检测到被植入特洛伊木马的样本的痕迹。因此,他们提出通过分解特征表示来过滤这些样本。
Chen 等人 [87] 与 Tran 等人持类似观点,指出特洛伊木马样本与正常样本在特征空间中具有不同的特征。他们展示了可以通过对训练数据的神经元激活进行聚类,然后移除代表被污染样本的聚类,从而过滤掉特洛伊木马样本。
Tang 等人 [88] 指出上述两种方法的一个局限性:简单的目标污染可能导致正常样本与特洛伊木马样本之间的表示差异不明显。为此,他们提出了一种基于表示分解和统计分析的过滤方法,以增强区分能力。
Soremekun 等人 [89] 同样基于特征表示差异提出了过滤被污染样本的方法。
Chou 等人 [90] 利用显著性图检测输入中的潜在触发器,并过滤掉包含触发器的样本。
Li 等人 [111] 认为目前尚无明确证据表明存在稳健的训练方法可以防止触发器注入。他们将训练过程分为干净数据训练和特洛伊木马数据训练,并发现后者存在两个弱点:
模型学习特洛伊木马数据的速度快于干净数据,且模型在特洛伊木马数据上的收敛时间高度依赖于攻击强度;
神经特洛伊木马始终试图将模型引导至目标类别。
基于这些观察,他们提出了反后门学习(Anti-Backdoor Learning),通过在训练阶段隔离特洛伊木马样本,并削弱其与目标类别之间的潜在关联,从而实现防御。
Fu 等人 [123] 最近提出了一种新颖的基于特征的在线检测策略,称为RAID(Removing Adversarial-Backdoors by Iterative Demarcation)。该方法分为两个阶段:离线训练和在线再训练。离线阶段仅使用干净数据训练神经网络;在线阶段检测与离线训练数据差异显著的输入,并将其移除。随后,他们使用干净数据和净化后的异常数据训练一个二元支持向量机(SVM),以便 RAID 能够检测数据集中被污染的输入。该 SVM 还支持实时更新。
2)测试样本过滤:
与训练样本过滤类似,这类方法的主要目标是区分正常样本与特洛伊木马样本,并在将数据传递给模型之前过滤掉后者。但此类方法仅在测试阶段进行。
Subedar 等人 [91] 提出了一种方法,利用模型在测试时的不确定性来区分特洛伊木马样本与正常样本。
Du 等人 [92] 展示了异常值检测在测试阶段识别触发器方面的有效性。
Jaraheripi 等人 [93] 提出了一种轻量级样本过滤方法,无需标签数据、模型再训练或对触发器设计的先验假设,适用于测试阶段的过滤任务。
5.7 经过认证的木马防御
几乎所有上述防御技术都可以归类为基于启发式的临时性方法。文献中常提到,这类防御手段可以被适应性攻击策略所突破 [104], [105]。因此,类似于针对对抗样本的可认证防御机制 [108],研究人员也开始探索针对特洛伊木马攻击的可认证防御方法。
例如,Wang 等人 [94] 提出了一种随机平滑技术,通过向样本添加随机噪声来增强模型对适应性攻击的鲁棒性。他们进一步改进了该方法,将训练过程视为基础函数,并在此基础上构建一个平滑函数来实现平滑处理。
然而,Weber 等人 [95] 在一定程度上对上述方法提出异议,并证明直接应用平滑技术的效果有限。他们提出了一个框架,通过评估不同平滑噪声分布之间的差异,以实现更强的模型鲁棒性。
5. 讨论与未来工作
本综述聚焦于 2017 年至 2021 年间关于神经网络特洛伊木马的研究文献,其中约 60% 的论文关注特洛伊木马攻击,剩余 40% 则探讨防御方法。值得注意的是,自 2019 年起,神经特洛伊木马相关文献的数量明显增加,显示出研究社区对该方向日益浓厚的兴趣。这一趋势与深度学习中对抗性攻击的相关研究方向相一致 [108]。我们推测,这种持续增长的研究热度是由于人们对深度学习在对抗性环境中存在漏洞的认识不断加深所致。
我们观察到,在特洛伊木马注入与防御之间,长期存在“猫捉老鼠”的博弈,直到文献中出现了无触发器后门(Triggerless Backdoor) [24] 和动态后门(Dynamic Backdoor) [25]。这些攻击方法被证明能够绕过当时最先进的防御技术,说明目前的攻防战仍由攻击方法主导。这场对抗仍在持续,推动着人们不断发现深度学习的脆弱性及其应对策略。
尽管前文讨论的文献涵盖了广泛的主题与可能性,但这一研究方向仍属新兴领域,因此在该方向上仍有大量子课题值得进一步探索。一个可供借鉴的探索路径是其“姊妹问题”——深度学习中的对抗性攻击 [108]。对抗性攻击的发现始于 2013 年,比神经特洛伊木马的识别早了几年,因此目前在文献中更为成熟和流行。对抗性攻击领域的研究成果可以为特洛伊木马攻击的研究提供有益的指导。我们也基于文献回顾和相关问题,列举了一些神经特洛伊木马未来可能的研究方向与挑战。
5.1 聚焦黑盒攻击
目前已有的特洛伊木马攻击中,约有 95% 属于白盒或灰盒攻击,这类攻击假设攻击者至少可以访问部分训练数据。例如,所有通过训练数据投毒实现的攻击都假定攻击者可以获取完整的训练数据,以便在目标模型中植入后门。但在现实中,由于隐私原因,完整的训练数据通常是无法获取的。因此,这些白盒和灰盒设定并不完全适用于实际场景。
这使得在完全黑盒环境下探索特洛伊木马植入或触发器利用的方法成为一个值得关注的未来研究方向。乍看之下,黑盒场景似乎不适用于特洛伊木马攻击,因为后门是嵌入在模型内部的,而嵌入过程通常需要访问模型或训练数据。然而,通过对模型进行查询,可能仍能识别出其天然的脆弱性,例如发现模型对某些无关模式的敏感性。这种敏感性可以在测试阶段通过输入中嵌入触发器加以利用,从而实现攻击。
5.2 超越视觉的攻击与防御
深度学习的应用远不止于视觉模型。目前,语音识别 [29], [30]、图神经网络 [34], [35] 等多种任务和神经网络类型都在广泛利用深度学习技术。然而,从我们的文献综述中可以看出,现有的大多数研究几乎都集中在视觉模型上。换句话说,大多数特洛伊木马植入技术都是专门为图像领域中的卷积神经网络设计的。在这种情况下,攻击的有效性可以通过最大化攻击成功率并将特洛伊木马触发器巧妙地隐藏在图像噪声中来提升。
然而,在其他领域(如语音识别、自然语言处理)中设计不可见的触发器模式则面临显著不同的挑战,因为触发器无法像在图像中那样被“混入”句子或语音内容中。这为跨领域的特洛伊木马攻击研究带来了新的挑战。
我们预期,随着研究范围扩展至其他领域,这一方向未来仍将面临许多未知的探索空间。事实上,只要这些领域继续依赖深度学习技术,它们就有可能受到特洛伊木马攻击的威胁。
5.3 木马设计的影响
相关文献中的许多研究都致力于寻找将特洛伊木马触发器秘密而高效地植入输入中的方法。然而,触发器的具体模式本身也同样重要,而其有效性在当前文献中相对较少被深入探讨。在动态后门方法 [15] 中提出的 c-BaN 是少数能够针对特定标签图像生成最适合触发器的技术之一。其他方法通常将特洛伊木马触发器视为单一模式,或使用简单算法进行触发器生成。因此,设计更强大触发器模式的方法仍有待进一步研究探索。
文献 [4] 中也指出,大多数研究仅关注触发器的有效性和隐蔽性。然而,未来的研究可以进一步探索如何设计一种只需最少量训练数据被污染即可生效的特洛伊木马触发器。
5.4 对现有攻击的更强防御
如前所述,近期提出的无触发器后门(Triggerless Backdoor) [24] 和动态后门(Dynamic Backdoor) [15] 被设计得极其高效,以至于能够规避当前最先进的防御技术。无触发器后门打最先进的防御技术。无触发器后门打破了传统思维方式,实现了在没有破了传统思维方式,实现了在没有显式触发器存在的情况下激活特洛伊显式触发器存在的情况下激活特洛伊木马。而动态后门则在传统特洛木马。而动态后门则在传统特洛伊木马设计的基础上进行了改进,使伊木马设计的基础上进行了改进,使触发器可以是随机位置的随机模式触发器可以是随机位置的随机模式,从而使得触发器的检测变得几,从而使得触发器的检测变得几乎不可能。
随着特洛伊木马植入技术的不断发展,以及越来越多强大的技术的不断发展,以及越来越多强大的攻击方法的出现,我们有理由相信攻击方法的出现,我们有理由相信未来将会涌现出更强大的防御技术未来将会涌现出更强大的防御技术,与之形成对抗之势。
6. 结论
神经特洛伊木马是深度学习技术面临的一个严重问题,它会使神经网络在处理正常输入时表现正常,但在输入中存在触发器时却产生恶意行为。这对安全关键型应用具有严重影响。例如,在人脸识别系统中,攻击者可以利用神经特洛伊木马让无关人员获得对敏感区域或信息的访问权限。
这类攻击的检测非常困难,因为模型在大多数情况下运行正常,只有在极少数特定情况下才会出现异常。随着深度学习应用的快速增长,特洛伊木马攻击近年来引起了众多研究者的关注,也促使了相关防御技术的不断涌现。
我们注意到,每年在机器学习和计算机视觉领域的权威会议上,如 CVPR、ICCV、ECCV、ICLR、NeurIPS,关于神经特洛伊木马的研究工作数量持续增长。这一现象表明该研究方向在未来可能会变得更加热门。
尽管已有一些相关的文献综述,我们的调研具有独特性,因为它回顾的是近期发表的论文,并通过系统分类总结了最新的神经特洛伊木马注入与防御技术,并讨论了它们的有效性。
参考文献
[1] Y. LeCun, Y. Bengio and G. Hinton, “Deep Learning,” Nature, vol. 521, no. 1, pp. 436–44, May. 28. 2015. DOI: 10.1038/nature14539, [online].
[2] F. Altaf, S. Islam, N. Akhtar and N. Janjua, “Going Deep in Medical Image Analysis: Concepts, Methods, Challenges and Future Directions,” IEEE Access, vol. PP, no. 1, pp. 1–1, 2019. DOI: 10.1109/ACCESS.2019.2929365, [online].
[3] Y. Li, B. Wu, Y. Jiang, Z. Li and S. Xia, “Backdoor Learning: A Survey,”arXiv:2007.08745. [online]. Available: https://arxiv.org/abs/2007.08745
[4] Y. Liu, A. Mondal, A. Chakraborty, M. Zuzak, N. Jacobsen, D. Xing and A. Srivastava, “A Survey on Neural Trojans,” IEEE Xplore, pp. 33–39, 2020. DOI: 10.1109/ISQED48828.2020.9137011, [online].
[5] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, “Badnets: Evaluating backdooring attacks on deep neural networks,” IEEE Xplore, vol. 7, pp. 47 230–47 244, 2019.
[6] X. Chen, C. Liu, B. Li, K. Lu, and D. Song, “Targeted backdoor attacks on deep learning systems using data poisoning,” arXiv preprint arXiv:1712.05526, 2017.
[7] Y. Li, Y. Li, B. Wu, L. Li, R. He, and S. Lyu, “Backdoor attack with sample-specific triggers,” arXiv preprint arXiv:2012.03816, 2020.
[8] Y. Liu, X. Ma, J. Bailey, and F. Lu, “Reflection backdoor: A natural backdoor attack on deep neural networks,” in ECCV, 2020.
[9] H. Zhong, C. Liao, A. C. Squicciarini, S. Zhu, and D. Miller, “Backdoor embedding in convolutional neural network models via invisible perturbation,” in ACM CODASPY, 2020.
[10] N. Baracaldo, B. Chen, H. Ludwig, A. Safavi, and R. Zhang, “Backdoor embedding in convolutional neural network models via invisible perturbation,” IEEE International Congress on Internet of Things, 2018.
[11] H. Zhong, C. Liao, A. C. Squicciarini, S. Zhu, and D. Miller, “Detecting Poisoning Attacks on Machine Learning in IoT Environments,” in ACM CODASPY, 2020.
[12] S. Zhao, X. Ma, X. Zheng, J. Bailey, J. Chen, and Y.-G. Jiang, “Cleanlabel backdoor attacks on video recognition models,” in CVPR, 2020.
[13] A. Saha, A. Subramanya, and H. Pirsiavash, “Hidden trigger backdoor attacks,” in AAAI, 2020.
[14] E. Quiring and K. Rieck, “Backdooring and poisoning neural networks with image-scaling attacks,” in IEEE S&P Workshop, 2020.
[15] A. Salem, R. Wen, M. Backes, S. Ma and Y. Zhang, “Dynamic Backdoor Attacks Against Machine Learning Models,” arXiv:2003.03675, 2020.
[16] J. Clements and Y. Lao, “Backdoor Attacks on Neural Network Operations,” IEEE Global Conference on Signal and Information Processing (GlobalSIP), pp. 1154–1158, 2018.
[17] J.J. Dumford and W. Scheirer, “Backdooring convolutional neural networks via targeted weight perturbations,” arXiv preprint arXiv:1812.03128, 2018.
[18] A. S. Rakin, Z. He, and D. Fan, “Tbt: Targeted neural network attack with bit trojan,” in CVPR, 2020.
[19] E. Bagdasaryan and V. Shmatikov, “Blind backdoors in deep learning models,” arXiv preprint arXiv:2005.03823, 2020.
[20] T. Liu, W. Wen, and Y. Jin, “SIN 2: Stealth infection on neural network—a low-cost agile neural trojan attack methodology,” 8 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), pp. 227–230, 2018.
[21] C. Guo, R. Wu, and K. Q. Weinberger, “Trojannet: Embedding hidden trojan horse models in neural networks,” arXiv preprint arXiv:2002.10078, 2020.
[22] R. Tang, M. Du, N. Liu, F. Yang, and X. Hu, “An embarrassingly simple approach for trojan attack in deep neural networks,” in KDD, 2020.
[23] W. Li, J. Yu, X. Ning, P. Wang, Q. Wei, Y. Wang, and H. Yang, “Hu-fu: Hardware and software collaborative attack framework against neural networks,” 8 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), pp. 482–487, 2018.
[24] A. Salem, M. Backes, and Y. Zhang, “Don’t Trigger Me! A Triggerless Backdoor Attack Against Deep Neural Networks,” arXiv:2010.03282, 2020.
[25] X. Chen, C. Liu, B. Li, K. Lu, and D. Song, “Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning,” arXiv:1712.05526, 2017.
[26] E. Wenger and J. Passananti and A. Bhagoji and Y. Yao and H. Zheng and B. Y. Zhao, “Backdoor Attacks Against Deep Learning Systems in the Physical World,” arXiv: Computer Vision and Pattern Recognition, 2020.
[27] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, “Badnets: Evaluating backdooring attacks on deep neural networks,” IEEE Access, , vol. 7, pp. 47230—47244, 2019.
[28] Y. Li, T. Zhai, B. Wu, Y. Jiang, Z. Li, and S. Xia, “Rethinking the trigger of backdoor attack,” arXiv preprint arXiv:2004.04692, 2020.
[29] J. Dai, C. Chen, and Y. Li, “A backdoor attack against lstm-based text classification systems,” IEEE Access, vol. 7, pp. 138872–138878, 2019.
[30] S. Wang, S. Nepal, C. Rudolph, M. Grobler, S. Chen, and T. Chen, “Backdoor attacks against transfer learning with pre-trained deep learning models,” IEEE Transactions on Services Computing, 2020.
[31] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, “BadNets: Evaluating Backdooring Attacks on Deep Neural Networks,” . IEEE Access 7, pp. 47230–47244, 2019.
[32] T. J. L. Tan and R. Shokri, “Bypassing Backdoor Detection Algorithms in Deep Learning,” arXiv preprint arXiv:1905.13409, 2019.
[33] Y. Yao, H. Li, H. Zheng, and B. Y. Zhao, “ Latent Backdoor Attacks on Deep Neural Networks,” 2019.
[34] Z. Zhang, J. Jia, B. Wang, and N. Z. Gong, “Backdoor attacks to graph neural networks,” in NeurIPS Workshop, 2020.
[35] Z. Xi, R. Pang, S. Ji, and T. Wang, “Graph backdoor,” arXiv preprintarXiv:2006.11890, 2020.
[36] P. Kiourti, K. Wardega, S. Jha, and W. Li, “Trojdrl: Trojan attacks on deep reinforcement learning agents,” arXiv preprint arXiv:1903.06638, 2019.
[37] Z. Yang, N. Iyer, J. Reimann, and N. Virani, “Design of intentional backdoors in sequential models,” arXiv preprint arXiv:1902.09972, 2019.
[38] Y. Wang, E. Sarkar, M. Maniatakos, and S. E. Jabari, “Stop-andgo: Exploring backdoor attacks on deep reinforcement learning-based traffic congestion control systems,” arXiv preprint arXiv:2003.07859, 2020.
[39] E. Bagdasaryan, A. Veit, Y. Hua, D. Estrin, and V. Shmatikov, “How to backdoor federated learning,” in AISTATS, 2020.
[40] A. N. Bhagoji, S. Chakraborty, P. Mittal, and S. Calo, “Analyzing federated learning through an adversarial lens,” in ICML, 2019.
[41] A. Salem, Y. Sautter, M. Backes, M. Humbert, and Y. Zhang, “BAAAN: Backdoor Attacks Against Autoencoder and GAN-Based Machine Learning Models,” arXiv:2010.03007, 2020.
[42] Y. Adi, C. Baum, M. Cisse, B. Pinkas, and J. Keshet, “Turning your weakness into a strength: Watermarking deep neural networks by backdooring,” In 27th USENIX Security Symposium (USENIX Security 18), pp. 1615—1631, 2018.
[43] J. Guo and M. Potkonjak, “Watermarking deep neural networks for embedded systems,” In 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), pp. 1–8, 2018.
[44] D. M. Sommer, L. Song, S. Wagh, and P. Mittal, “Towards probabilistic verification of machine unlearning,” arXiv preprint arXiv:2003.04247, 2020.
[45] Y. Li, Z. Zhang, J. Bai, B. Wu, Y. Jiang, and S.-T. Xia, “Open-sourced dataset protection via backdoor watermarking,” in NeurIPS Workshop, 2020.
[46] S. Zhao, X. Ma, Y. Wang, J. Bailey, B. Li, and Y.-G. Jiang, “What do deep nets learn? class-wise patterns revealed in the input space,” arXiv preprint arXiv:2101.06898, 2021.
[47] Y. S. Lin, W. C. Lee, and Z. B. Celik, “What do you see? evaluation of explainable artificial intelligence (xai) interpretability through neural backdoors,” arXiv preprint arXiv:2009.10639, 2020.
[48] T. Baluta, S. Shen, S. Shinde, K. S. Meel, and P. Saxena, “ Quantitative Verification of Neural Networks And its Security Applications,” arXiv preprint arXiv:1906.10395, 2019.
[49] Z. He, T. Zhang, and R. Lee, “Sensitive-Sample Fingerprinting of Deep Neural Networks,” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4729—4737, 2019.
[50] N. B. Erichson, D. Taylor, Q. Wu, and M. W. Mahoney, “NoiseResponse Analysis of Deep Neural Networks Quantifies Robustness and Fingerprints Structural Malware,” arXiv arXiv:2008.00123 , 2020.
[51] J. Clements and Y. Lao, “Hardware trojan attacks on neural networks,”arXiv preprint arXiv:1806.05768, 2018.
[52] N. Baracaldo, B. Chen, H. Ludwig, A. Safavi, and R. Zhang, “Detecting Poisoning Attacks on Machine Learning in IoT Environments,” In 2018 IEEE International Congress on Internet of Things ICIOT), pp. 57–64, 2018.
[53] Y. Liu, W. Lee, G. Tao, S. Ma, Y. Aafer, and X. Zhang, “ABS: Scanning Neural Networks for Back-doors by Artificial Brain Stimulation,” In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security. ACM, pp. 1265—1282, 2019.
[54] A. Chakarov, A. Nori, S. Rajamani, S. Sen, and D. Vijaykeerthy, “Debugging Machine Learning Tasks,” arXiv:cs.LG/1603.07292, 2016.
[55] B. Nelson, M. Barreno, F. J. Chi, A. D. Joseph, B. I. P. Rubinstein, U. Saini, C. Sutton, J. D. Tygar, and K. Xia, “Misleading Learners: Co-opting Your Spam Filter,” pp. 17—51, 2009.
[56] X. Xu, Q. Wang, H. Li, N. Borisov, C. A. Gunter, and B. Li, “Detecting AI Trojans Using Meta Neural Analysis,” arXiv preprint arXiv:1910.03137, 2019.
[57] H. Chen, C. Fu, J. Zhao, and F. Koushanfar, “ DeepInspect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks,”AAAI Press, pp. 4658—4664, 2019.
[58] Y. Gao, Y.e Kim, B. G. Doan, Z. Zhang, G. Zhang, S. Nepal, D. C. Ranasinghe, and H. Kim, “ Design and Evaluation of a Multi-Domain Trojan Detection Method on Deep Neural Networks,” arXiv preprint arXiv:1911.10312 , 2019.
[59] Z. Xiang, D. J. Miller, and G. Kesidis, “ Revealing Backdoors, Post-Training, in DNN Classifiers via Novel Inference on Optimized Perturbations Inducing Group Misclassification,” arXiv preprint arXiv:1908.10498 , 2019.
[60] S. Kolouri, A. Saha, H. Pirsiavash, and H. Hoffmann, “ Universal Litmus Patterns: Revealing Backdoor Attacks in CNNs,” aarXiv preprint arXiv:1906.10842 , 2019.
[61] X. Huang, M. Alzantot, and M. Srivastava, “Neuroninspect: Detecting backdoors in neural networks via output explanations,” arXiv preprint arXiv:1911.07399, 2019.
[62] S. Huang, W. Peng, Z. Jia, and Z. Tu, “One-pixel signature: Characterizing cnn models for backdoor detection,” in ECCV, 2020.
[63] R. Wang, G. Zhang, S. Liu, P.-Y. Chen, J. Xiong, and M. Wang, “Practical detection of trojan neural networks: Data-limited and datafree cases,” in ECCV, 2020.
[64] K. Yoshida and T. Fujino, “Disabling backdoor and identifying poison data by using knowledge distillation in backdoor attacks on deep neural networks,” in CCS Workshop, 2020.
[65] Y. Li, X. Lyu, N. Koren, L. Lyu, B. Li, and X. Ma, “Neural attention distillation: Erasing backdoor triggers from deep neural networks,” in ICLR, 2021.
[66] X. Xu, Q. Wang, H. Li, N. Borisov, C. A. Gunter, and B. Li, “Detecting AI Trojans Using Meta Neural Analysis,” arXiv preprint arXiv:1910.03137, 2019.
[67] Y. Liu, Y. Xie, and A. Srivastava, “Neural trojans,” In 2017 IEEE International Conference on Computer Design (ICCD), pp. 45–48, 2019.
[68] P. Zhao, P.-Y. Chen, P. Das, K. N. Ramamurthy, and X. Lin, “Bridging mode connectivity in loss landscapes and adversarial robustness,” in ICLR, 2020.
[69] K. Liu, B. Dolan-Gavitt, and S. Garg, “Fine-pruning: Defending against backdooring attacks on deep neural networks,” in RAID, 2018.
[70] B. Wang, Y. Yao, S. Shan, H. Li, B. Viswanath, H. Zheng, and B. Y. Zhao, “Neural cleanse: Identifying and mitigating backdoor attacks in neural networks,” 2019.
[71] W. Guo, L. Wang, X. Xing, M. Du, and D. Song, “ TABOR: A Highly Accurate Approach to Inspecting and Restoring Trojan Backdoors in AI Systems,” arXiv preprint arXiv:1908.01763, 2019.
[72] X. Qiao, Y. Yang, and H. Li, “ Defending neural backdoors via generative distribution modeling,” in NeurIPS, 2019.
[73] K. Davaslioglu and Y. E. Sagduyu, “ Trojan attacks on wireless signal classification with adversarial machine learning,” in DySPAN, 2019.
[74] L. Zhu, R. Ning, C. Wang, C. Xin, and H. Wu, “ Gangsweep: Sweep out neural backdoors by gan,” in ACM MM, 2020.
[75] B. Chen, W. Carvalho, N. Baracaldo, H. Ludwig, B. Edwards, T. Lee, I. Molloy, and B. Srivastava, “ Detecting backdoor attacks on deep neural networks by activation clustering,” arXiv preprint arXiv:1811.03728, 2018.
[76] G. Shen, Y. Liu, G. Tao, S. An, Q. Xu, S. Cheng, S. Ma, and X. Zhang, “ Backdoor scanning for deep neural networks through karm optimization,” arXiv preprint arXiv:2102.05123, 2021.
[77] A. K. Veldanda, K. Liu, B. Tan, P. Krishnamurthy, F. Khorrami, R. Karri, B. Dolan-Gavitt, and S. Garg, “Nnoculation: Broad spectrum and targeted treatment of backdoored dnns,” arXiv preprint arXiv:2002.08313, 2020.
[78] B. G. Doan, E. Abbasnejad, and D. Ranasinghe, “DeepCleanse: A Black-box Input Sanitization Framework Against BackdoorAttacks on DeepNeural Networks,” arXiv preprint arXiv:1908.03369 , 2019.
[79] Y. Liu, Y. Xie, and A. Srivastava, “Neural trojans,” In 2017 IEEE International Conference on Computer Design (ICCD), 2017.
[80] S. Udeshi, S. Peng, Gerald Woo, L. Loh, L. Rawshan, and S. Chattopadhyay, “Model Agnostic Defence against Backdoor Attacks in Machine Learning,” arXiv preprint arXiv:1908.02203, 2019.
[81] M. Villarreal-Vasquez and B. Bhargava, “Confoc: Content-focus protection against trojan attacks on neural networks,” arXiv preprint arXiv:2007.00711, 2020.
[82] Y. Li, T. Zhai, B. Wu, Y. Jiang, Z. Li, and S. Xia, “Rethinking the trigger of backdoor attack,” arXiv preprint arXiv:2004.04692, 2020.
[83] Y. Zeng, H. Qiu, S. Guo, T. Zhang, M. Qiu, and B. Thuraisingham, “Deepsweep: An evaluation framework for mitigating dnn backdoor attacks using data augmentation,” arXiv preprint arXiv:2012.07006, 2020.
[84] M. Du, R. Jia, and D. Song, “Robust anomaly detection and backdoor attack detection via differential privacy,” in ICLR, 2020.
[85] S. Hong, V. Chandrasekaran, Y. Kaya, T. Dumitras¸, and N. Papernot, “On the effectiveness of mitigating data poisoning attacks with gradient shaping,” arXiv preprint arXiv:2002.11497, 2020.
[86] B. Tran, J. Li, and A. Madry, “Spectral signatures in backdoor attacks,”in NeurIPS, 2018.
[87] B. Chen, W. Carvalho, N. Baracaldo, H. Ludwig, B. Edwards, T. Lee, I. Molloy, and B. Srivastava, “Detecting backdoor attacks on deep neural networks by activation clustering,” in AAAI Workshop, 2019.
[88] D. Tang, X. Wang, H. Tang, and K. Zhang, “Demon in the variant: Statistical analysis of dnns for robust backdoor contamination detection,”in USENIX Security, 2021.
[89] E. Soremekun, S. Udeshi, S. Chattopadhyay, and A. Zeller, “Exposing backdoors in robust machine learning models,” arXiv preprint arXiv:2003.00865, 2020.
[90] E. Chou, F. Tramer, and G. Pellegrino, “Sentinet: Detecting localized universal attacks against deep learning systems,” in IEEE S&P Workshop, 2020.
[91] M. Subedar, N. Ahuja, R. Krishnan, I. J. Ndiour, and O. Tickoo, “Deep probabilistic models to detect data poisoning attacks,” in NeurIPS Workshop, 2019.
[92] M. Du, R. Jia, and D. Song, “Robust anomaly detection and backdoor attack detection via differential privacy,” in ICLR, 2020.
[93] M. Javaheripi, M. Samragh, G. Fields, T. Javidi, and F. Koushanfar, “Cleann: Accelerated trojan shield for embedded neural networks,” in ICCAD, 2020.
[94] B. Wang, X. Cao, N. Z. Gong et al., “On certifying robustness against backdoor attacks via randomized smoothing,” in CVPR Workshop, 2020.
[95] M. Weber, X. Xu, B. Karlas, C. Zhang, and B. Li, “Rab: Provable robustness against backdoor attacks,” arXiv preprint arXiv:2003.08904, 2020.
[96] Cybiant, “What is Deep Learning,” available: https://www.cybiant.com/resources/what-is-deep-learning/.
[97] A. Krizhevsky, I. Sutskever, and G. Hinton, “ImageNet classification with deep convolutional neural networks,” in Proc. Advances in Neural Information Processing Systems, 2012.
[98] J. Tompson, A. Jain, Y. LeCun, and C. Bregler, “Joint training of a convolutional network and a graphical model for human pose estimation,”in Proc. Advances in Neural Information Processing Systems, 2012.
[99] G. Hinton, “Deep neural networks for acoustic modeling in speech recognition,” in IEEE Signal Processing Magazine, 2012.
[100] T. Mikolov, A. Deoras, D. Povey, L. Burget and J. Cernocky, “Strategies for training large scale neural network language models,” in Proc. Automatic Speech Recognition and Understanding, 2011.
[101] Y. Bengio, R. Duncharme, and P. Vincent, “A neural probabilistic language model,” in Proc. Advances in Neural Information Processing Systems, 2001.
[102] 3Blue1Brown, But what is a neural network? — Chapter 1, Deep learning, Accessed on: 17. 07, 2021. [Video file]. Available: https: //www.youtube.com/watch?v=aircAruvnKk&t=588s
[103] Y. Liu, S. Ma, T. Aafer, W. Lee, J. Zhai, W. Wang, and X. Zhang, ”Trojaning Attack on Neural Networks,” 2018, Available: https://www.ndsssymposium.org/wp-content/uploads/2018/03/NDSS2018 03A5 Liu Slides.pdf
[104] R. J. Schalkoff, Artificial Neural Network, vol.1 New York, NY, USA: McGraw-Hill, 1997.
[105] B. W. White and F. Rosenblatt, ”Principles of neurodynamics: Perceptrons and the theory of brain mechanisms,” Amer. J. Psychol., vol. 76, no. 4, pp. 705, 1963.
[106] T. James, M. Ren, S. Manivasagam, M. Liang, B. Yang, R. Du, F. Cheng, and R. Urtasun. “Physically Realizable Adversarial Examples for LiDAR Object Detection”. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13716–13725, 2020.
[107] S. Sun, N. Akhtar, H. Song, A. Mian, and M. Shah. ”Deep affinity network for multiple object tracking.” IEEE transactions on pattern analysis and machine intelligence 43, no. 1 (2019): 104-119.
[108] N. Akhtar, A. Mian, N. Karda, and M. Shah. “Advances in adversarial attacks and defenses in computer vision: A survey”, arXiv preprint, arXiv:2108.00401, 2021.
[109] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. ”Intriguing properties of neural networks.” arXiv preprint arXiv:1312.6199, 2013.
[110] N. Akhtar, and A. Mian, “Threat of adversarial attacks on deep learning in computer vision: A survey”. IEEE Access, 6, pp.14410-14430, 2018.
[111] Y. Li, X. Lyu, N. Koren, L. Lyu, B. Li, and X. Ma, “Anti-Backdoor Learning: Training Clean Models on Poisoned Data”, arXiv preprint, arXiv:2110.11571, 2021.
[112] D. Wu, and Y. Wang, ” Adversarial Neuron Pruning Purifies Backdoored Deep Models”, arXiv preprint, arXiv:2110.14430, 2021.
[113] A. Boloor, T. Wu, P. Naughton, A. Chakrabarti, X. Zhang and Y. Vorobeychik, ”Can Optical Trojans Assist Adversarial Perturbations?,” 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2021, pp. 122-131, doi: 10.1109/ICCVW54120.2021.00019, 2021.
[114] Y. Li, Y. Li, B. Wu, L. Li, R. He, and S. Lyu, ”Invisible Backdoor Attack with Sample-Specific Triggers”, in ICCV, 2021.
[115] T. Huster and E. Ekwedike, ”TOP: Backdoor Detection in Neural Networks via Transferability of Perturbation”, arXiv preprint, arXiv:2103.10274, 2021.
[116] S. Zheng, Y. Zhang, H. Wagner, M. Goswami, and C. Chen, Topological Detection of Trojaned Neural Networks”, arXiv preprint, arXiv:2106.06469, 2021.
[117] K. Doan, Y. Lao, and P. Li, ” Backdoor Attack with Imperceptible Input and Latent Modification”, NeurIPS 2021.
[118] K. Doan, Y. Kao, W. Zhao, and P. Li, ”LIRA: Learnable, Imperceptible and Robust Backdoor Attacks”, ICCV 2021, 2021.
[119] M. Xue, X. Wang, S. Sun, Y. Zhang, J. Wang, and W. Liu, ”Compression-Resistant Backdoor Attack against Deep Neural Networks”, arXiv preprint, arXiv:2201.00672, 2021.
[120] A. Nguyen, and A. Tran, ”WaNet – Imperceptible Warping-based Backdoor Attack”, In Proceedings of the 9th International Conference on Learning Representation (ICLR), Virtual Event, Austria, 2021.
[121] S. Cheng, Y. Liu, S. Ma, and X. Zhang, ”Deep Feature Space Trojan Attack of Neural Networks by Controlled Detoxification”, arXiv preprint, arXiv:2012.11212, ICLR, 2021.
[122] T. Li, J. Hua, H. Wang, C. Chen, and Y. Liu, ”DeepPayload: Blackbox Backdoor Attack on Deep Learning Models through Neural Payload Injection”, arXiv preprint, arXiv:2101.06896, ICSE 2021, 2021.
[123] H. Fu, A. K. Veldanda, P. Krishnamurthy, S. Garg and F. Khorrami, ”A Feature-Based On-Line Detector to Remove AdversarialBackdoors by Iterative Demarcation,” in IEEE Access, doi: 10.1109/ACCESS.2022.3141077.
[124] B. Zhao, and Y. Lao, ”Towards Class-Oriented Poisoning Attacks gainst Neural Networks”, arXiv preprint, arXiv:2008.00047, 2021.
[125] H. Kwon, ”Multi-Model Selective Backdoor Attack with Different Trigger Positions”, EICE TRANSACTIONS on Information and Systems Vol.E105-D No.1 pp.170-174, 2022.
[126] J.Hayase, W. Kong, R. Somani, and S. Oh, ”Proceedings of the 38th International Conference on Machine Learning”, PMLR 139:4129-4139,2021.
[127] M. Barni, K.Kallas, and B. Tondi, ”A new backdoor attack in CNNS y training set corruption without label poisoning.”, In Proceedings of
the 2019 IEEE International Conference on Image Processing (ICIP),pages 101–105, 2019.
[128] ”CIFAR-10 and CIFAR-100 datasets”, Cs.toronto.edu, 2022. [Online].Available: https://www.cs.toronto.edu/ kriz/cifar.html. [Accessed: 16-Jan- 2022].
[129] ”CIFAR-10 and CIFAR-100 datasets”, Cs.toronto.edu, 2022. [Online]. Available: https://www.cs.toronto.edu/ kriz/cifar.html. [Accessed: 16-Jan- 2022].

欢迎加入北京社区
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)