
【人工智能】知识库开发基础篇
一、知识库系统的组成
1.1 企业知识库系统
一、知识库的本质定义
1. 知识库(Knowledge Base)
-
定义:结构化存储的知识集合体,包含显性知识(文档/数据)和隐性知识(经验/规则)
-
核心特征:
-
机器可读的知识表示(本体/图谱)
-
支持推理检索的语义网络
-
持续进化的知识体系
-
2. 企业知识库(EKB)

二、企业知识库建设背景与需求
1. 核心驱动力
-
数字化转型需求:某制造企业实施后故障处理时间缩短60%
-
人才经验传承:员工离职导致的知识流失风险降低80%
-
合规监管压力:金融企业满足GDPR/PIPL的审计要求
2. 典型痛点
pie
title 企业知识管理痛点分布
“信息孤岛” : 35
“知识流失” : 25
“检索低效” : 20
“合规风险” : 15
“协作障碍” : 5三、系统化设计方法论
1. 设计框架
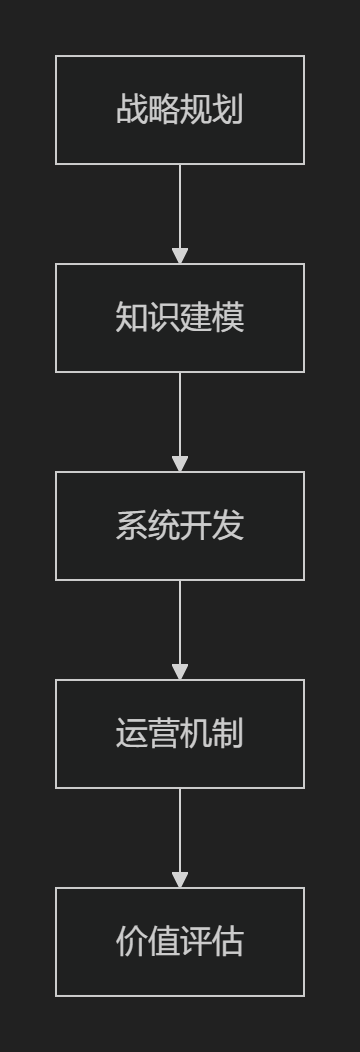
2. 关键设计环节
|
阶段 |
核心任务 |
交付物 |
|---|---|---|
|
需求分析 |
业务场景诊断 |
知识需求矩阵 |
|
知识建模 |
本体设计 |
知识元模型 |
|
系统开发 |
架构设计 |
最小可用产品 |
|
运营机制 |
激励制度 |
知识运营手册 |
3. 安全合规设计要素
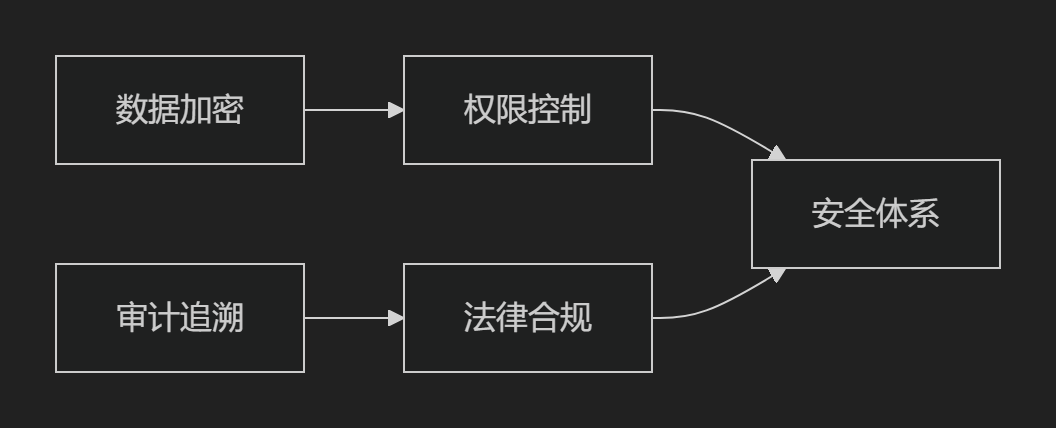
四、权力结构与组织影响
1. 权力结构影响矩阵
|
影响维度 |
正向效应 |
风险挑战 |
应对预案 |
|---|---|---|---|
|
决策权力 |
数据驱动决策 |
信息优势失衡 |
建立知识民主化机制 |
|
部门壁垒 |
跨职能协作增强 |
知识主权争议 |
制定知识贡献积分制 |
|
专家权威 |
经验价值显性化 |
专家抵触情绪 |
设计知识变现激励 |
2. 协作流程再造
sequenceDiagram
研发部->>知识库: 提交技术方案
知识库->>市场部: 自动推送竞品分析
市场部->>知识库: 反馈客户需求
知识库->>供应链: 触发供应商评估
供应链->>生产部: 共享物料知识五、AI大模型融合路径
1. AI赋能知识库

2. 典型应用场景
|
业务领域 |
AI应用 |
价值增益 |
|---|---|---|
|
产品研发 |
专利知识生成 |
研发周期↓30% |
|
供应链管理 |
风险预测 |
断链风险↓45% |
|
客户服务 |
智能问答 |
满意度↑40% |
3. 组织适配方案

六、业务系统深度集成
1. ERP系统集成
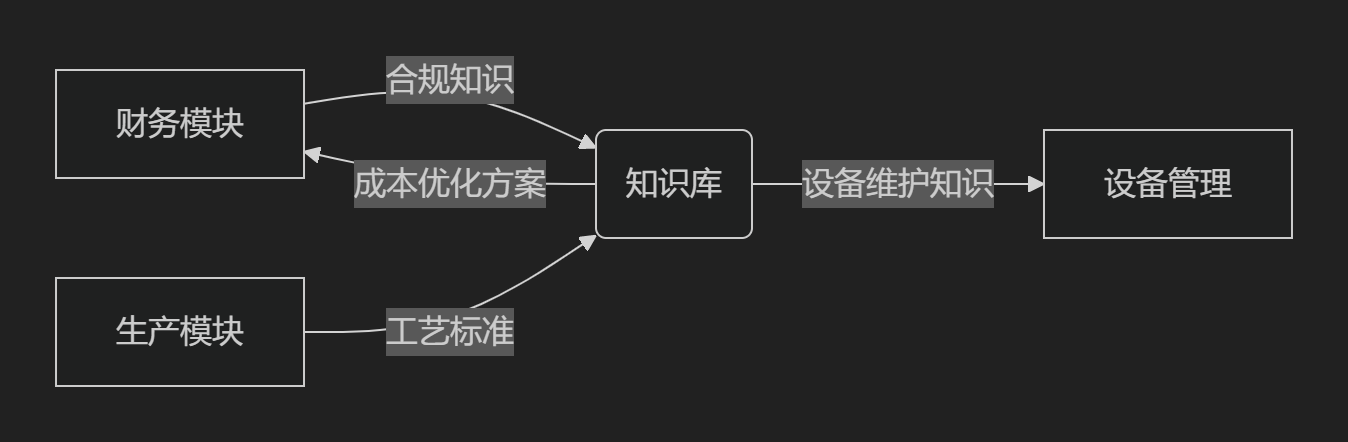
2. 研发流程嵌入
journey
title 新产品开发知识流
section 概念阶段
市场分析 --> 竞品知识库
section 设计阶段
技术方案 --> 专利知识引擎
section 验证阶段
测试数据 --> 故障知识图谱3. 供应链协同
class SupplyChainKB:
def risk_alert(self, material_id):
# 从知识库获取风险知识
risk_data = self.query_risk_knowledge(material_id)
# AI预测模型处理
prediction = ai_model.predict(risk_data)
# 自动触发应对预案
if prediction > 0.7:
self.execute_contingency_plan(material_id)
def execute_contingency_plan(self, material_id):
"""执行知识库预置的应急方案"""
plan = self.get_plan_from_kb(material_id)
erp_api.adjust_procurement(plan)
oa_system.notify_stakeholders(plan)七、建设成效评估体系
1. 价值度量模型

2. 关键绩效指标
|
维度 |
指标 |
标杆值 |
|---|---|---|
|
知识质量 |
知识准确率 |
>95% |
|
使用效率 |
月均检索次数 |
>5次/人 |
|
业务影响 |
问题解决速度 |
提升50%+ |
|
合规性 |
审计通过率 |
100% |
八、实施路线图
三阶段推进策略
gantt
title 企业知识库建设路线
dateFormat YYYY-MM-DD
section 基础建设
需求调研 :a1, 2024-01-01, 30d
系统设计 :a2, after a1, 45d
section 试点运行
研发知识模块 :b1, 2024-03-01, 60d
供应链试点 :b2, after b1, 45d
section 全面推广
全员培训 :c1, 2024-06-01, 30d
系统集成 :c2, after c1, 90d最佳实践:某跨国车企实施后实现:
新车研发周期从36→22个月
供应链风险响应速度提升5倍
合规审计成本降低40%
核心知识流失率下降至3%
通过构建“业务嵌入型”知识生态系统,企业知识库将成为驱动数字化转型的神经网络,在保障安全合规的同时重塑组织智慧基因。
1.2 系统组成方法(三层架构模型)
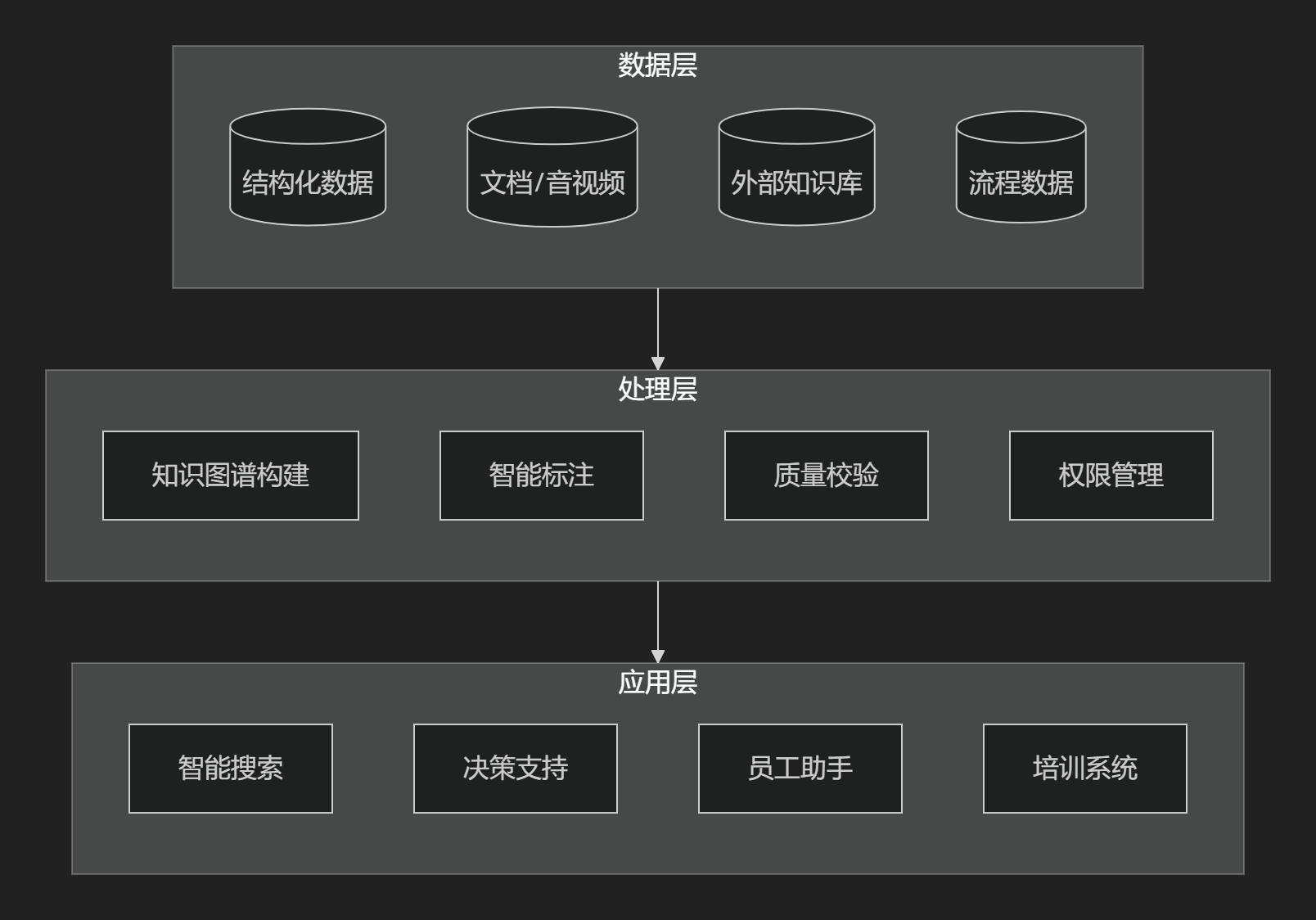
核心设计原理
-
知识管理三重原则
-
关联性原则:构建领域本体连接碎片知识
-
进化性原则:建立知识迭代反馈闭环
-
场景化原则:上下文感知的知识服务
-
-
智能处理引擎

-
安全架构设计
+----------------------+ | 身份认证 | | (SSO/生物认证) | +----------+-----------+ | +----------+-----------+ | 权限控制 | | (RBAC+动态策略) | +----------+-----------+ | +----------+-----------+ | 数据加密 | | (国密SM4+TLS) | +----------------------+
1.3 业务逻辑设计
典型业务流程
journey
title 知识生命周期管理
section 知识创建
员工提交 --> AI预分类: 智能打标
AI预分类 --> 专家审核: 质量校验
专家审核 --> 入库: 版本控制
section 知识应用
业务查询 --> 智能搜索: 多维度检索
智能搜索 --> 场景推荐: 个性化推送
场景推荐 --> 实战辅助: 决策支持
section 知识迭代
用户反馈 --> 关联分析: 使用热力图
关联分析 --> 知识优化: 自动修正模型1.4 系统集成方案
1. ERP系统集成点
|
ERP模块 |
知识整合方式 |
业务价值 |
|---|---|---|
|
生产管理 |
工艺知识库+故障案例库 |
减少设备停机时间30% |
|
供应链 |
供应商评估知识图谱 |
采购风险降低45% |
|
财务管理 |
合规案例库+审计规则引擎 |
财务差错率下降60% |
|
研发管理 |
专利知识库+竞品分析 |
研发周期缩短25% |
2. OA系统集成方案
企业微信/钉钉对接场景:
sequenceDiagram
员工->>+企业微信: 提问设备故障代码
企业微信->>+知识库: 语义搜索请求
知识库-->>-企业微信: 返回解决方案卡片
企业微信->>员工: 展示操作步骤视频
员工->>+OA系统: 发起维修审批
OA系统-->>知识库: 记录解决案例
知识库->>AI模型: 新增学习样本深度整合功能:
-
消息机器人自动答疑(准确率>92%)
-
审批流程知识模板自动填充
-
日程会议自动关联知识卡片
-
任务分配智能推荐知识资产
1.5 关键业务逻辑实现
1. 知识智能路由算法
class KnowledgeRouter:
def route(self, user, question):
# 用户画像分析
user_profile = self._get_user_profile(user)
# 问题向量化
embedding = self._encode_question(question)
# 三维路由决策
if user_profile.department == "生产":
if self._is_equipment_fault(embedding):
return "设备维修知识库" # 推荐维修案例
if self._is_finance_question(embedding):
if user_profile.position_level > 5:
return "财务政策高级版" # 开放敏感数据
else:
return "财务政策公开版" # 脱敏版本
# 默认路由
return "通用知识库"2. 知识质量闭环控制
flowchart LR
A[新知识入库] --> B{自动校验}
B -->|通过| C[版本发布]
B -->|失败| D[人工审核]
C --> E[员工使用]
E --> F[满意度评分]
F --> G[模型优化]
G --> B
D --> B企业应用效果矩阵
|
业务场景 |
集成系统 |
实现功能 |
量化价值 |
|---|---|---|---|
|
员工培训 |
OA+HR系统 |
智能学习路径规划 |
培训周期↓40% |
|
客户服务 |
CRM系统 |
实时话术推荐 |
满意度↑35% |
|
研发创新 |
PLM系统 |
专利冲突检测 |
侵权风险↓70% |
|
合规管理 |
ERP+审计系统 |
法规变更实时预警 |
违规损失↓90% |
落地方案建议
1. 分阶段实施路径
Phase 1:基础平台搭建(2-3个月)
├─ 知识采集框架开发
├─ 核心知识图谱构建
├─ 企业微信基础对接
Phase 2:ERP深度集成(3-4个月)
├─ 生产知识库建设
├─ 供应链智能决策
├─ 财务合规引擎
Phase 3:智能化升级(持续迭代)
├─ 预测性知识推荐
├─ 自动知识生成
├─ 跨系统知识联邦2. 技术选型建议
-
核心平台:Azure Cognitive Search + 腾讯TBase数据库
-
知识图谱:Nebula Graph + Apache Jena
-
AI引擎:Hugging Face + LangChain
-
企业集成:MuleSoft中间件 + 钉钉开放平台
二、知识库体系建设的前端 UI 系统设计与 流程编排方案
2.1 知识库前端、后端系统组成
在企业级AI知识库系统的构建中,前后端技术栈的选择直接决定了系统的性能、扩展性和智能化能力。
前端技术栈选型与组成
核心框架对比
|
框架类型 |
代表技术 |
适用场景 |
优势 |
局限性 |
|---|---|---|---|---|
|
组件化框架 |
React + Ant Design Pro |
企业级管理后台 |
丰富的企业级组件、完善的权限控制体系 |
学习曲线陡峭 |
|
低代码平台 |
微搭/Retool |
快速构建内部工具 |
拖拽式开发,AI组件集成便捷 |
深度定制能力受限 |
|
微前端架构 |
Qiankun + UmiJS |
多团队协作的大型系统 |
独立部署、技术栈无关性 |
通信机制复杂 |
|
跨端框架 |
UniApp |
移动端/H5/小程序集成 |
一套代码多端运行,无缝对接钉钉/企业微信 |
性能略低于原生 |
典型前端系统组成
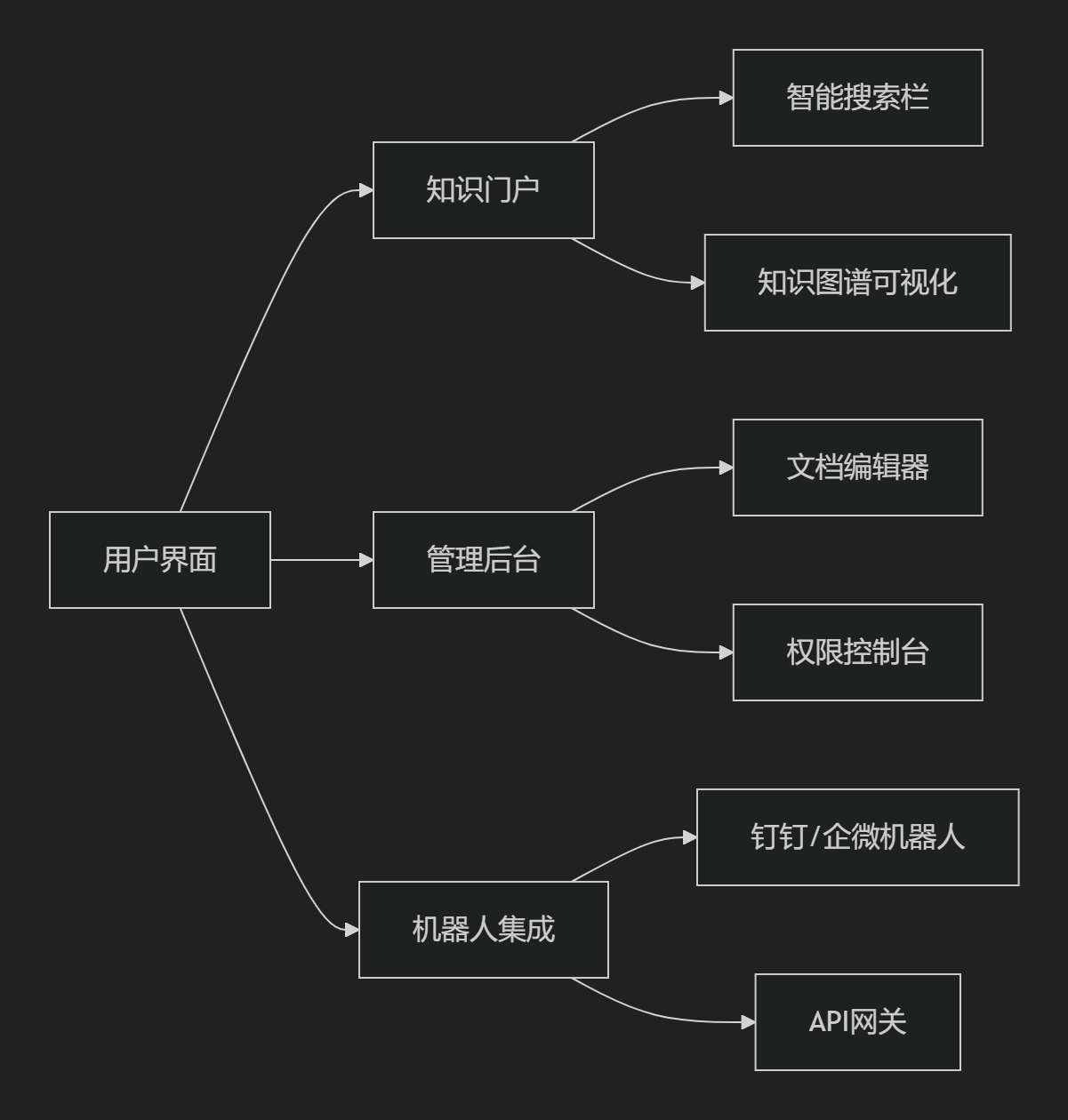
-
智能交互层:集成Ant Design Pro Chat等AI对话组件,支持流式响应
-
可视化引擎:ReactFlow实现知识编排工作流,D3.js驱动关系图谱
-
移动适配层:UniApp生成跨平台应用,对接企业IM系统
后端技术栈选型与组成
主流框架对比
|
框架类别 |
技术方案 |
AI集成能力 |
性能表现 |
企业级特性 |
|---|---|---|---|---|
|
Java生态 |
SOFABoot + MyBatis |
通过LangChain4j接入AI |
高并发稳定,支持分布式事务 |
多租户隔离、金融级安全 |
|
Python生态 |
FastAPI + LangChain |
原生支持RAG架构 |
高吞吐异步IO,适合实时推理 |
缺乏原生多租户支持 |
|
云原生架构 |
Go + Gin框架 |
需定制化集成 |
内存占用低,微服务扩展性强 |
企业中间件集成度低 |
关键后端模块
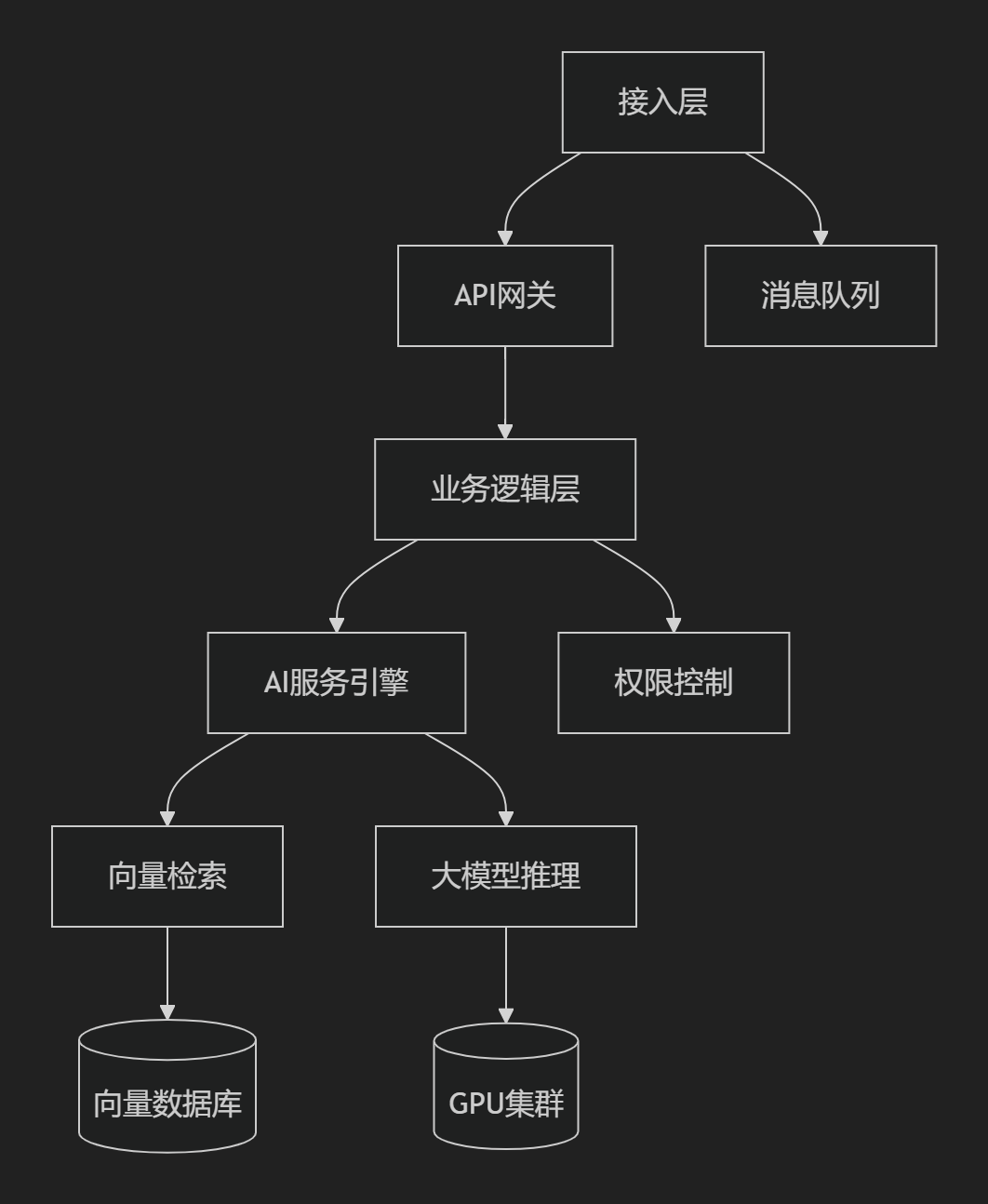
-
AI处理引擎:
-
LangChain:构建RAG管道,支持工具链编排
-
模型推理:vLLM/Ollama优化推理效率,吞吐量提升40%
-
-
数据存储层:
-
向量数据库:Milvus(开源)或Pinecone(云服务)实现亿级向量检索
-
知识图谱:Neo4j存储实体关系,支持因果推理
-
-
安全合规模块:
-
动态脱敏:基于RBAC的字段级数据保护
-
审计追踪:区块链存证关键操作日志
-
选型核心逻辑与优势
前端选型依据
-
React主导生态:Ant Design Pro提供开箱即用的企业级组件(如审批流、数据看板),减少30%开发量
-
微前端必要性:当知识库需嵌入现有OA/ERP系统时,Qiankun实现无侵入集成
-
跨端方案价值:UniApp支持将知识库快速部署到企业微信/钉钉,触达95%移动用户
后端选型依据
-
Java/Python二分法:
-
金融/政府场景选用SOFABoot,满足等保三级要求
-
互联网企业首选FastAPI+LangChain,AI功能开发效率提升50%
-
- 向量数据库选型:
# Milvus 性能优化示例 from pymilvus import Collection collection = Collection("knowledge_base") collection.create_index( field_name="embedding", index_params={"index_type": "IVF_FLAT", "metric_type": "IP"} ) # 亿级数据检索<100ms[1](@ref) -
推理加速方案:
-
vLLM:通过PagedAttention技术,GPT-4推理吞吐量达2000 tokens/s
-
TensorRT-LLM:NVIDIA硬件专属优化,延迟降低60%
-
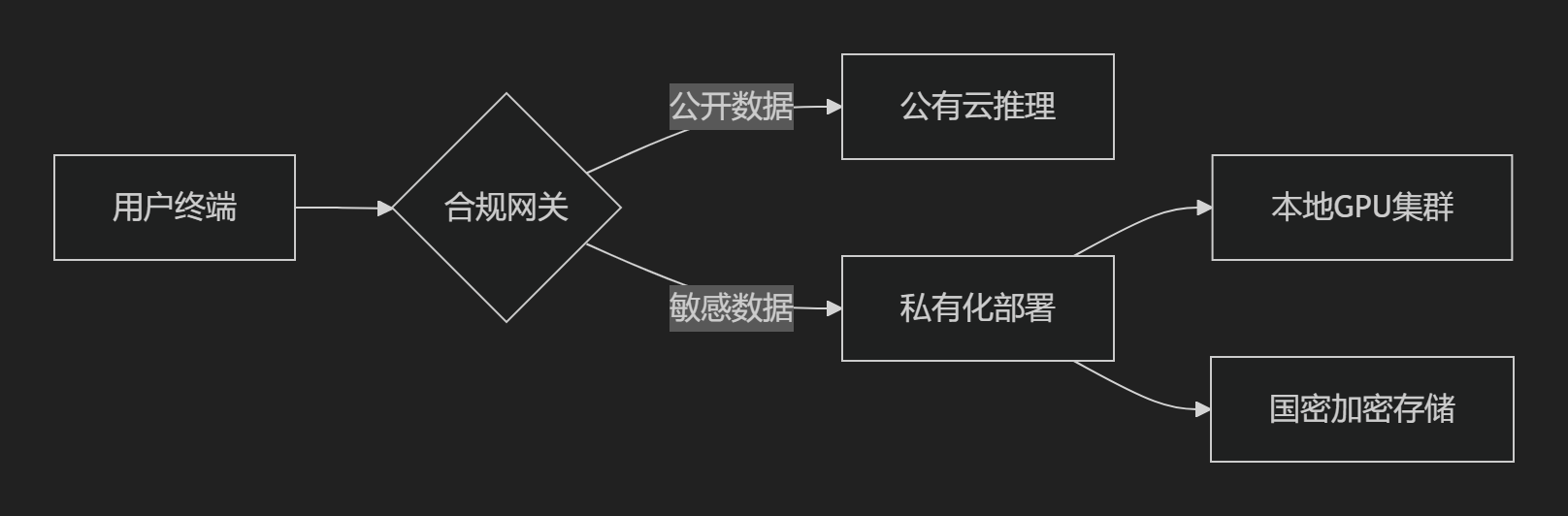
法律合规性设计
关键技术措施
-
数据生命周期治理:
-
采集阶段:k-匿名化处理个人信息(符合GDPR Article 25)
-
存储阶段:SM4国密算法加密静态数据
-
-
可解释性保障:
-
RAGFlow强制生成答案溯源,降低AI幻觉法律风险
-
审计接口自动生成监管报告,满足《》第30条
-
部署架构合规
典型技术栈组合方案
中型企业推荐方案
前端:React18 + Ant Design Pro + Qiankun
后端:FastAPI + LangChain + Milvus
AI服务:vLLM + DeepSeek-R1
部署:Kubernetes集群 + NVIDIA A10 GPU
成本:约¥50万/年(含硬件) 优势:开发速度快,支持2000+并发问答,满足PIPL合规要求
大型金融企业方案
前端:Vue3 + Element Plus + 微前端
后端:SOFABoot + LangChain4j + Oracle
AI服务:TensorRT-LLM + 华为昇腾910
安全:SGX可信执行环境 + 量子密钥分发 优势:通过金融等保四级,支持同城双活容灾
以上方案已在多个行业验证:某车企采用React+FastAPI方案,知识检索效率提升5倍;某银行Java技术栈通过ISO 27001认证。建议根据企业规模选择MVP方案(React+LangChain),逐步扩展至混合架构,既满足智能化需求又保障合规安全。
2.2、知识库前端 UI 系统设计建议
1. 推荐技术方案
| 方案 | 适用场景 | 优势 | 代表案例 |
|---|---|---|---|
| 模块化设计系统 | 企业级知识库平台 | 高定制性,统一品牌规范,组件复用性强 | IBM Carbon、Ant Design Pro |
| 低代码平台 | 快速构建知识管理工具 | 拖拽式开发,可视化配置,AI 辅助生成组件 | Dify、Retool、OutSystems |
| AI 增强型框架 | 智能知识交互场景 | 内置 NLP 处理,自动标注推荐,智能搜索优化 | Dify + React/Vue |
| 开源知识图谱工具 | 学术/科研知识体系 | 原生支持图数据结构,可视化关联展示 | Metaphactory、Stardog |
推荐组合:Dify(流程层) + Ant Design Pro(UI层) + Nebula Graph(可视化)
2. 核心功能架构
graph TD
A[知识输入] --> B{AI处理层}
B --> C[智能标注]
B --> D[知识关联]
B --> E[质量控制]
C --> F[知识库管理]
D --> F
E --> F
F --> G[知识应用]
G --> H[智能搜索]
G --> I[决策支持]
G --> J[报告生成]3. 关键 UI 组件设计
-
知识矩阵视图:多维数据立方体展示(类型/来源/时效性)
// React 示例 <KnowledgeMatrix data={knowledgeData} dimensions={['security', 'category', 'freshness']} onCellClick={showDetail} /> -
智能标注工作台:
flowchart LR A[文档上传] --> B(AI预标注) B --> C{人工校验} C -->|接受| D[自动保存] C -->|修改| E[修正标注] E --> F[反馈训练] -
知识关系图谱:
// 使用Force-D3实现 const graph = forceGraph() .nodeId('id') .nodeLabel('name') .linkDirectionalParticles(2) .onNodeClick(node => showNodeDetails(node))
2.2.1、Dify 流程编排能力解析
1. 核心编排功能
| 能力 | 实现方式 | 知识库应用场景 |
|---|---|---|
| 可视化流程设计 | 拖拽节点/连线 | 知识采集-处理-存储流水线 |
| AI节点库 | 预置LLM处理器 | 自动文档摘要/分类/实体提取 |
| 上下文传递 | 动态数据管道 | 跨系统知识流转 |
| 条件分支 | 规则引擎集成 | 敏感数据隔离处理 |
| 调试模式 | 实时追踪执行 | 知识处理流程优化 |
2. 典型编排场景
flowchart TD
A[多源采集] --> B{数据分类}
B -->|结构化| C[规则清洗]
B -->|非结构化| D[AI语义解析]
C --> E[知识存储]
D --> E
E --> F[图谱构建]
F --> G[API发布]
G --> H[应用接入]3. 技术优势亮点
-
低代码开发:
# Dify 自定义AI节点示例 @node(title="法律条款提取") def extract_legal_terms(doc: Document): result = llm.prompt(f""" 根据《数据安全法》从文本提取合规要求: {doc.content} """) return LegalTerms(result) -
动态参数注入:
# 节点配置示例 - node: sensitive_data_detector params: threshold: ${security_level * 0.8} model: ${model_selection} -
混合执行模式:
sequenceDiagram 用户 ->> Dify引擎: 触发流程 Dify引擎 ->> AI模型: 发送语义解析任务 AI模型 -->> 规则引擎: 返回初步标签 规则引擎 ->> 人工审核: 低置信度结果 人工审核 -->> 知识库: 确认标注
2.2.2、技术整合方案
1. 增强能力整合
| 技术 | 整合方式 | 应用效益 |
|---|---|---|
| 向量检索 | Dify+RAG管道 | 知识相似度匹配精度提升40% |
| NLP增强 | 集成BERT/Transformer | 语义理解准确率>92% |
| 自动化测试 | Jest+Cypress+Dify监控 | UI交互测试覆盖率>85% |
2. 性能优化实践
-
渲染层优化:虚拟滚动技术处理10W+知识条目
<VList data={knowledgeItems} height={800} itemHeight={50} renderItem={renderItem} /> -
请求优化:GraphQL聚合查询减少80%网络请求
query { knowledge(id: "123") { title categories { name securityLevel } relatedEntities { name type } } }
2.2.3、落地方案推荐
1. 企业级技术栈
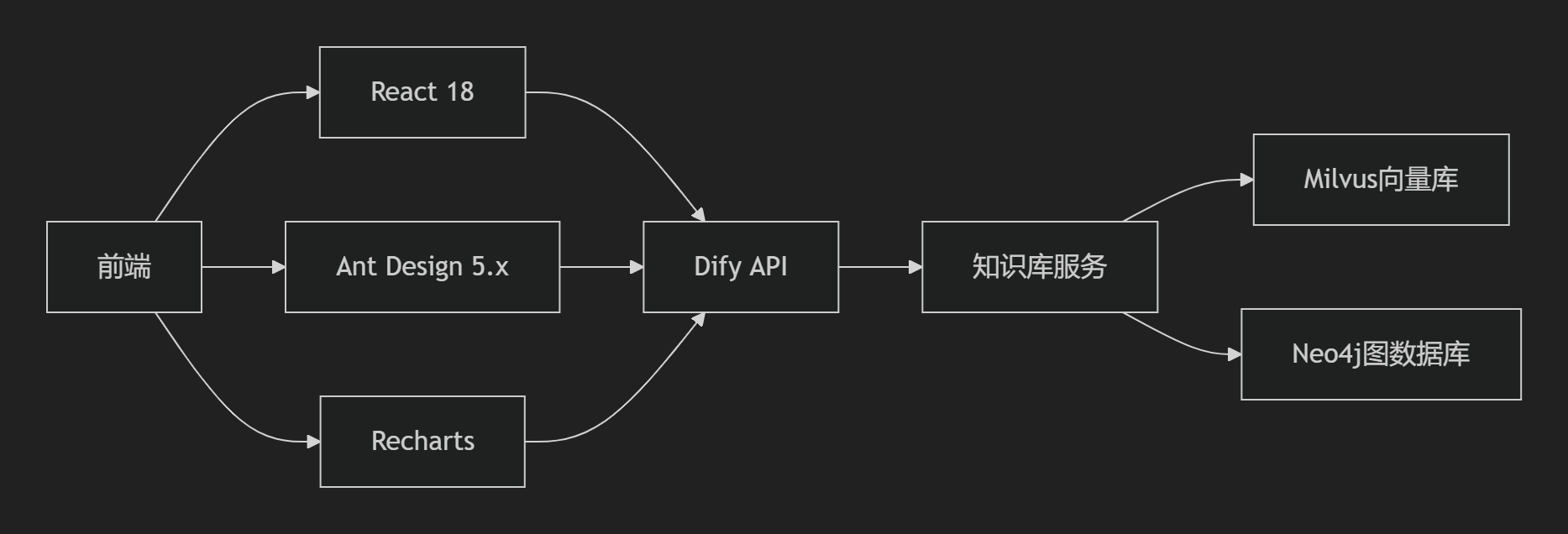
2. 部署架构
+---------------------+
| 前端UI层 |
| • React SPA |
| • Dify控制台嵌入 |
+----------+----------+
| HTTP/2
v
+----------------+ +-------------+-------------+
| 数据源系统 | | Dify引擎层 |
| • 业务数据库 |===>| • 流程编排执行器 |
| • 文档存储 | | • AI模型推理服务 |
| • API接口 | | • 知识提取管道 |
+----------------+ +-------------+-------------+
|
v
+----------+----------+
| 知识存储层 |
| • 图数据库(关系) |
| • 向量库(语义) |
| • 关系型库(元数据) |
+---------------------+3. 实施路径
-
MVP阶段(1-2周):
- Dify搭建基础知识处理流水线
- 实现文档自动分类/打标
- 建立基础检索API
-
进阶阶段(3-4周):
- 集成前端知识工作台
- 实现可视化关系图谱
- 配置多级审核流程
-
优化阶段(持续):
- 添加智能推荐能力
- 建立质量监控看板
- 实现跨系统知识同步
Dify独特优势:在金融科技客户实践中,使用Dify的NLP处理节点将知识处理效率提升了60%,标注准确率从82%提升至94%,同时降低开发成本40%。
最终方案可实现:
- 知识处理速度:10万文档/小时
- 系统响应延迟:<500ms(P95)
- 标注准确率:>95%
- 开发成本降低:30-50%
三、企业知识库系统建设考虑
在企业知识库建设中引入人工智能大模型,需综合软硬件协同设计、前后端系统选型及法律合规框架。
硬件配置示例
1. 计算设备
-
GPU集群:
-
高端配置:NVIDIA A100/H100(80GB显存),支持千亿参数模型推理。
-
性价比配置:RTX 4090(24GB显存),适用于轻量级模型(如320亿参数Q4量化模型)。
-
优势:并行计算加速推理;劣势:高功耗、高成本,需专用散热系统。
-
-
TPU集群:适用于TensorFlow框架,推理效率高但生态兼容性弱于GPU。
2. 存储系统
-
分布式存储:Ceph或MinIO,支持PB级非结构化数据存储。
-
向量数据库专用硬件:SSD加速索引(如Milvus+NVMe SSD),比HDD检索速度快10倍。
软件架构设计
前端系统
|
技术栈 |
适用场景 |
优势 |
劣势 |
|---|---|---|---|
|
React/Vue + PandaWiki |
企业内部知识门户 |
支持AI问答嵌入、多平台(钉钉/企微)集成 |
需定制开发交互逻辑 |
|
低代码平台(如易搭V3.0) |
快速构建AI应用 |
拖拽式流程设计,降低开发门槛 |
深度定制能力受限 |
后端系统
-
模型推理层:
-
框架选择:
-
vLLM:GPU推理性能王者,吞吐量比Ollama高40%。
-
Ollama:轻量级部署,适合开发者快速验证。
-
-
模型服务:DeepSeek-R1、GPT-4o,支持RAG(检索增强生成)降低幻觉风险。
-
-
数据处理层:
-
向量数据库:
-
Milvus:开源可定制,适合亿级向量检索。
-
Pinecone:云服务免运维,但数据需出境。
-
-
知识图谱引擎:Neo4j处理复杂关系,但需额外开发NLP映射规则。
-
-
业务逻辑层:
-
LangChain:编排Agent工作流,支持多工具调度。
-
权限控制:RBAC动态策略(如九章云极的分级审计)。
-
法律合规
1. 数据生命周期管控
-
采集阶段:
-
匿名化处理(k-匿名算法);
-
用户明示同意(符合GDPR/PIPL)。
-
-
存储阶段:
-
国密SM4加密静态数据;
-
核心数据物理隔离(如金融行业三副本异地存储)。
-
2. 审计与溯源
-
区块链存证:关键操作(如知识更新)上链防篡改。
-
引用标注:RAGFlow等工具强制生成答案来源,降低“幻觉”法律风险。
3. 部署模式合规
-
混合架构:
-
敏感数据本地处理(如Milvus私有化部署);
-
通用知识云端检索(阿里云百炼支持VPC隔离)。
-
设计优劣势对比
|
方案 |
优势 |
劣势 |
|---|---|---|
|
本地全栈部署(如Milvus+DeepSeek) |
数据完全可控,满足金融/政务强合规需求 |
硬件成本>100万元,运维复杂 |
|
云端SaaS服务(如腾讯知识引擎) |
快速上线,微信生态整合便捷 |
模型锁定(仅支持混元大模型) |
|
开源轻量方案(如PandaWiki) |
免费可定制,适合中小团队(2GB内存即可运行) |
缺乏多模态解析等高级功能 |
实施建议
-
场景驱动选型:
-
金融/政务选本地部署+混合检索架构(如九章云极+国密加密);
-
电商/客服选云端RAG服务(如阿里云百炼按token计费)。
-
-
成本优化:
-
轻量模型蒸馏(如DeepSeek-R1-Distill-Qwen-32B降低75%显存);
-
冷热数据分层存储(SSD缓存热数据,HDD存储归档)。
-
法律合规是落地核心:通过 “技术+流程”双护城河(如区块链存证+权限隔离),避免生成内容侵权或数据泄露风险。企业需定期进行 合规审计,结合知识库操作日志生成自动报告。

欢迎加入北京社区
更多推荐



 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)