
CPU、GPU、NPU、TPU、DPU与IPU的区别
在人工智能飞速发展的今天,我们每天使用的智能语音助手、刷到的个性化推荐、甚至手机的人脸识别功能,背后都离不开强大的硬件算力支撑。如果把AI模型比作大脑中的思维逻辑,那么AI硬件就是支撑这些逻辑运行的"肌肉"。从我们熟悉的CPU、GPU,到专门为AI优化的NPU、TPU,各类硬件层出不穷,这无疑加大了我们的理解难度,接下来我们就从CPU开始逐步了解各种处理器以及它的运作原理。
引言
在人工智能飞速发展的今天,我们每天使用的智能语音助手、刷到的个性化推荐、甚至手机的人脸识别功能,背后都离不开强大的硬件算力支撑。如果把AI模型比作大脑中的思维逻辑,那么AI硬件就是支撑这些逻辑运行的"肌肉"。从我们熟悉的CPU、GPU,到专门为AI优化的NPU、TPU,各类硬件层出不穷,这无疑加大了我们的理解难度,接下来我们就从CPU开始逐步了解各种处理器。
一、CPU
1. CPU的发展历程
CPU其实是Central Processing Unit(中央处理器)的简称,它出现于大规模集成电路时代,处理器架构设计的迭代更新以及集成电路工艺的不断提升促使其不断发展完善。从最初专用于数学计算到广泛应用于通用计算,从4位到8位、16位、32位处理器,最后到64位处理器,从各厂商互不兼容到不同指令集架构规范的出现,CPU自诞生以来一直在飞速发展,这也造就了我们现在所看到的CPU盛况,接下来我们就从CPU 的发展历程看一下它整个时间线:
-
4位微处理器时代(1971年):1971年,英特尔公司推出了世界上第一款微处理器4004,这是第一个可用于微型计算机的四位微处理器,包含2300个晶体管,最大频率只有740KHz,主要用于计算器和其他类似设备,而不是计算机。其后续产品4040是4004的改进版本,增加了扩展指令集并提高了性能。
-
8位微处理器时代(1972 - 1975年):1972年,Intel发布了8位处理器8008,由于采用8位数据传输,性能比4004有所提升,但因使用10微米工艺制造,频率在200 - 800KHz之间,性能表现未达预期。1974年推出的8080处理器则较为成功,它增加了新的指令集,采用6微米制造工艺,频率几乎翻番,最高达到2MHz,被广泛应用于大量设备,吸引了众多开发者,微软也投身到基于Intel处理器的软件开发中。1975年的8085是8080的低价高能版本,但影响力相对较小。
-
16位微处理器时代(1978 - 1982年):1978年,Intel推出第一款16位微处理器8086,不仅频率更高,还拥有16位总线和其他附加硬件,可同时执行两条8位指令,地址总线扩展到20位,能存取1MB内存,使用第一版的X86指令集架构,是日后AMD和Intel几乎所有处理器的基石。同时,Intel还生产了8088处理器,以8086为蓝本,但外部总线只有8位,不过仍能访问1MB内存且运行频率较高,比Intel的旧8位处理器性能快得多。1980年,继8086之后,Intel发布了80186和80188处理器,将一些原本在主板上的硬件移到了CPU中,提升了性能。1982年的80286和80186同年发布,特性几乎相同,但80286的地址总线扩展到24位,最高能访问16MB内存。
-
32位微处理器时代(1985 - 1989年):1985年,Intel推出第一款32位X86处理器80386,采用32位地址总线,最大支持4GB内存,同时进行了一些架构改进以提升性能。为使产品线价格更友好,还发布了80386SL,虽支持最大4GB RAM,但只能进行16位操作,只能运行16位应用。1989年,Intel推出80486,这是CPU性能史上的又一里程碑,首次出现一级缓存,早期封装8KB缓存,后制程发展到600nm时,一级缓存增加到16KB,还整合了浮点运算单元(FPU),降低了FPU与CPU之间的延迟,同时采用更快的FSB接口等技术提升性能,最初时钟频率为50MHz,后来采用600nm制程的型号达到了100MHz,在消费领域还发布了移除FPU部分的80486SX。
-
奔腾(Pentium)时代(1993 - 1995年):1993年,最初的Pentium CPU发布,采用P5架构,是Intel在X86 CPU中首次采用超标量技术,改进了FPU,最初的Pentium FPU性能达到80486的十倍,后续推出的Pentium MMX增加了新的MMX SIMD指令集,令性能大幅提升。同时,一级缓存大小也得到提升,Pentium提升到16KB,Pentium MMX提升到32KB,频率也不断提高,最初使用800nm制程,运行在60MHz,后来采用250nm制程的Pentium达到了300MHz的频率。1995年,Intel计划推出基于P6架构的Pentium Pro系列,但遇到技术问题。
-
多核心与超线程时代(2002年 - 至今):2002年11月12日发布的Pentium 4 HT 3.06GHz首创超线程技术,虚拟出一个虚拟核心,但当时因缺乏多线程优化,性能提升不明显。2005年5月26日,Intel发布了桌面上第一款双核CPU,Pentium D,虽然内部是由两颗Pentium 4共享FSB组成,存在“高发热、低性能”的问题,但开启了双核时代。约一周后,AMD推出自家的双核Athlon 64 X2。2006年11月,Intel发布第一颗四核心CPU,Core 2 Extreme QX6700。2008年3月27日,AMD宣布Phenom X3三核心CPU,通过屏蔽质检不合格的四核K10中的一核来当成三核心销售。2011年10月12日,AMD发布推土机架构的八核CPU,FX - 8150。如今,CPU的核心数和线程数不断增加,频率也不断提高,同时制造工艺越来越先进,功耗控制也越来越好,并且在人工智能等领域的应用也越来越广泛。
2. CPU的工作原理
从上面也可以看出CPU的发展已经有50多年的历史了,那么它的工作原理是怎样的呢,接下来就让我们一起来看看。
CPU(中央处理器)是计算机系统的核心组件之一,其性能直接影响到系统的整体处理能力和响应速度。衡量CPU性能的关键参数包括主频、核心数量、线程数、缓存大小以及架构设计等。主频决定了CPU每秒能执行的指令周期,通常以GHz为单位;多核CPU通过增加物理核心的数量来提升并行处理能力;而超线程技术则允许每个物理核心同时处理多个线程,进一步提高了效率。
在现代计算环境中,除了基本的运算能力外,还需要考虑能效比,即单位功耗下的性能表现。这在移动设备和大规模数据中心中尤为重要,因为它们对电力消耗和散热有严格的要求。
其工作原理可概括为 “取指 - 译码 - 执行” 的循环过程,共分为以下四个关键阶段:
2.1 取指阶段(Fetch)
CPU从内存中读取指令。程序计数器(PC)存储当前指令地址,控制单元根据PC值访问内存,将指令加载到指令寄存器(IR)。例如:
IR←Memory[PC] \text{IR} \leftarrow \text{Memory}[\text{PC}] IR←Memory[PC]
随后PC自动递增,指向下一条指令地址:
PC←PC+Δ \text{PC} \leftarrow \text{PC} + \Delta PC←PC+Δ
2.2 译码阶段(Decode)
控制单元解析IR中的指令,识别操作类型(如加法、跳转)和操作数(如寄存器编号或内存地址)。例如加法指令:
ADD R1, R2, R3 # 表示 R1 ← R2 + R3
译码器会激活对应运算单元的电路通路。
2.3 执行阶段(Execute)
运算器(ALU)根据译码结果执行操作:
- 算术运算:如 R1←R2+R3R1 \leftarrow R2 + R3R1←R2+R3
- 逻辑运算:如 R4←R5∧R6R4 \leftarrow R5 \land R6R4←R5∧R6(按位与)
- 数据传输:如将内存数据加载到寄存器
此阶段可能涉及时钟周期同步,每个操作在固定时间 tcyclet_{\text{cycle}}tcycle 内完成。
2.4 写回阶段(Write-back)
将执行结果存储到目标位置:
- 寄存器更新:如 R1←结果R1 \leftarrow \text{结果}R1←结果
- 内存写入:如 Memory[addr]←数据\text{Memory}[\text{addr}] \leftarrow \text{数据}Memory[addr]←数据
CPU通过循环执行这四个阶段,以纳秒级速度处理指令,实现复杂的计算与控制功能。
二、 GPU
GPU(图形处理器)原本是为处理图像渲染而生,因其强大的并行计算能力,成为了AI领域的中流砥柱。
1. CPU的发展历程
GPU的发炸历程主要分为以下三个时期:
1.1 早期探索与基础奠定
- 起源:1962年麻省理工学院的博士伊凡·苏泽兰发表的论文及画板程序奠定计算机图形学基础。当时计算机无专门图形处理芯片,图形处理由CPU完成。
- 图形加速器出现:1984年,SGI公司推出面向专业领域的高端图形工作站,有了专门的图形处理硬件——图形加速器,引入顶点变换和纹理映射等概念,但价格昂贵,消费级市场难以普及。

1.2 2D与3D图形加速发展
- 2D图形硬件加速:1991年,S3 Graphics推出“S3 86C911”,标志着2D图形硬件加速时代到来,能进行字符、基本2D图元和矩形绘制。
- 3D图形加速开启:1994年,3DLabs发布Glint300SX,是第一颗用于PC的3D图形加速芯片,支持高氏着色、深度缓冲、抗锯齿等特性,开启显卡3D加速时代。
- 消费级3D显卡诞生:1995年,3dfx公司发布消费级领域史上第一款3D图形加速卡Voodoo,是真正意义上的消费级3D显卡。随后AMD和ATI分别发布TNT系列与Rage系列显卡,实现了Z缓存和双缓存等操作。

1.3 GPU概念诞生与发展
- GPU概念提出:1999年,NVIDIA公司发布GeForce 256,首次提出GPU概念。它整合了硬件变换和光照(T&L)等特性,减轻了CPU负担,标志着GPU时代正式到来。
- 可编程渲染架构兴起:2001年,微软发布DirectX 8,提出渲染单元模式(Shader Model)概念,引入顶点着色器和像素着色器,终结固定管线架构,开启可编程渲染架构时代。同年,NVIDIA发布GeForce3,ATI发布Radeon 8500,支持顶点编程。
- 统一渲染架构出现:2006年,DirectX 10推出,Shader不再有固定角色,每一个Shader都可处理顶点和像素,即统一渲染着色器。NVIDIA的GeForce 8800 GTX是首款采用统一渲染架构的桌面GPU。同年,NVIDIA发布首个通用GPU计算架构Tesla,采用CUDA架构,支持C语言编程,使GPU向通用数据并行处理器转变。

1.4 现代GPU架构演进与应用拓展
- 架构不断演进:NVIDIA推出Fermi、Kepler、Maxwell、Pascal、Volta、Turing和Ampere等GPU架构,不断增强计算能力和程序性。
- 应用领域拓展:GPU在图形渲染、人工智能和高性能计算等领域广泛应用。例如,在人工智能领域,GPU因其强大的并行计算能力,成为训练深度学习模型的关键硬件,像NVIDIA的H100等高端GPU在数据中心被大量用于AI计算。

2. GPU的工作原理
GPU是用于执行大量并行计算任务的硬件平台,其拥有数百个甚至上千个ALU(算术逻辑单元,Arithmetic Logic Unit),基于的SIMT(单指令多线程,Single Instruction Multiple Threads)架构以线程块为单位进行工作,这些计算核心支持线程块中的多个线程在同一周期内执行相同的指令,从而实现高效的并行计算 [8]。GPU还包含DRAM,用于存储数据和指令,如纹理、顶点数据、着色器程序等,以及包含Cache(高速缓存),用于临时存储频繁访问的数据或计算结果,减少访问主内存的次数,提高整体性能。
随着GPU的细分发展,不同厂商、不同型号的GPU具体微观架构存在差异,如NVIDIA的Tesla架构,Fermi架构和Maxwell架构,AMD的GCN架构,RNDA架构等,但核心部件、概念、以及运行机制仍大同小异。
GPU处理图形任务主要包括输入、顶点处理、几何处理、光栅化、像素处理、输出合并、显示等步骤,随着GPU可编程性的不断提高,这些步骤中部分可以并行执行,GPU逐渐开始应用于通用计算领域。如GPU的图形流水线所示,首先,GPU接收来自GPU的发出的顶点数据,顶点着色器对这些数据进行一系列变换,然后几何着色器对图元进行着色和生成,光栅化阶段将图元转换成片段并确认像素值,像素着色器再为这些片段添加纹理参数等信息,最后进行颜色合并写入到像素点再输出到屏幕上。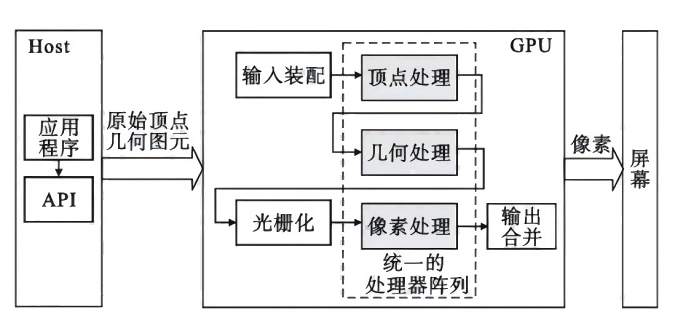
GPU相比于CPU来说有以下几大亮点:
2.1 并行架构设计
- GPU包含数千个小型处理核心(如NVIDIA的CUDA核心或AMD的流处理器),这些核心可同时执行大量简单任务。
- 与CPU的少量复杂核心不同,GPU的核心专注于单指令多数据(SIMD) 模式:一条指令可同时作用于多个数据点。
- 例如,渲染一个像素或计算矩阵乘法时:
[a11a12a21a22]×[b11b21]=[a11b11+a12b21a21b11+a22b21] \begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{bmatrix} \times \begin{bmatrix} b_{11} \\ b_{21} \end{bmatrix} = \begin{bmatrix} a_{11}b_{11} + a_{12}b_{21} \\ a_{21}b_{11} + a_{22}b_{21} \end{bmatrix} [a11a21a12a22]×[b11b21]=[a11b11+a12b21a21b11+a22b21]
每个核心可独立计算一个输出元素。
2.2 图形渲染管线
在图形处理中,GPU通过固定流程将3D模型转换为2D图像:
- 顶点处理:计算3D模型的顶点位置(坐标变换、光照)。
- 图元装配:将顶点连接为三角形等基本图形。
- 光栅化:将三角形转换为像素片段。
- 像素着色:计算每个像素的颜色(纹理映射、阴影)。
- 输出合并:整合所有像素生成最终图像。
2.3 内存层级优化
- 全局内存:大容量但高延迟,存储整体数据。
- 共享内存:核心组内共享的低延迟缓存,用于协作计算。
- 寄存器:每个核心独享的超高速存储。
- 这种层级设计减少数据访问延迟,例如在卷积运算中,核心可先将数据加载到共享内存再计算:
G(x,y)=∑i=−kk∑j=−kkF(x+i,y+j)⋅K(i,j) G(x,y) = \sum_{i=-k}^{k} \sum_{j=-k}^{k} F(x+i,y+j) \cdot K(i,j) G(x,y)=i=−k∑kj=−k∑kF(x+i,y+j)⋅K(i,j)
2.4 通用计算(GPGPU)
现代GPU通过API(如CUDA/OpenCL)支持非图形任务:
- 将问题分解为网格(Grid) → 线程块(Block) → 线程(Thread) 的层级。
- 例如训练神经网络时,权重更新可并行化:
wnew=wold−η⋅∂L∂w w_{new} = w_{old} - \eta \cdot \frac{\partial \mathcal{L}}{\partial w} wnew=wold−η⋅∂w∂L
每个线程计算部分梯度。
2.5 硬件加速特性
- 张量核心:专用于矩阵乘法(如深度学习中的A×BA \times BA×B)。
- 光线追踪核心:实时计算光线路径,提升渲染真实感。
- 高带宽内存(HBM):通过堆叠芯片提供超高数据吞吐率。
GPU的高效性源于其海量核心并行、内存层级优化及专用硬件单元,使其在图形渲染、科学计算和AI训练等领域远超CPU。其本质是通过空间换时间:用更多晶体管实现并行,而非提升单核频率。
三、NPU
1. NPU的发展历程
NPU(神经网络处理单元)是一种专为神经网络计算设计的硬件加速器,旨在高效处理深度学习任务,如图像识别、自然语言处理等。其发展历程反映了人工智能硬件技术的演进,从通用处理器到专用芯片的转变。
1.1 起源(2010年之前):基于通用处理器的早期探索
- 在深度学习兴起初期,神经网络计算主要依赖通用处理器,如CPU(中央处理器)和GPU(图形处理器)。GPU因其并行计算能力成为主流,例如NVIDIA的CUDA平台被广泛用于训练神经网络模型。
- 性能瓶颈:通用处理器在处理大规模矩阵运算时效率较低,计算延迟高。例如,一个典型的卷积操作在CPU上可能需要O(n2)O(n^2)O(n2)时间,其中nnn是输入尺寸,这限制了实时应用。
- 关键事件:2006年,Geoffrey Hinton等人提出的深度学习突破,推动了硬件加速需求,但专用NPU尚未出现。
1.2 2010s初期:GPU主导和专用硬件的萌芽
- GPU成为AI计算的支柱,NVIDIA推出了针对深度学习的Tesla系列GPU,显著提升了训练速度。例如,GPU的并行架构可以将矩阵乘法加速到O(nlogn)O(n \log n)O(nlogn)级别。
- 问题浮现:GPU功耗高、成本大,不适合边缘设备(如手机或物联网设备)。这催生了专用AI硬件的研发。
- 里程碑:2012年,AlexNet在ImageNet竞赛中夺冠,凸显了硬件加速的重要性。公司如Movidius(后被Intel收购)开始开发低功耗视觉处理单元,为NPU铺路。
1.3 2010s中期:NPU的诞生与突破(2016-2018年)
- Google在2016年发布第一代TPU(Tensor Processing Unit),这是NPU的先驱,专为TensorFlow框架优化。TPU采用定制ASIC设计,大幅提升推理效率,例如处理ResNet-50模型时延迟降低到毫秒级。
- 性能指标:TPU v1 提供高达929292 TFLOPS(万亿次浮点运算每秒)的算力,比同期GPU快101010倍。
- 其他公司跟进:2017年,华为推出麒麟970芯片,集成NPU(称为“Neural Engine”),首次将NPU带入智能手机。Apple在2017年的A11 Bionic芯片中引入Neural Engine,专注于设备端AI任务。
- 技术演进:NPU开始支持量化计算(如8位整数运算),降低功耗和内存占用。计算公式如能耗比优化为E=P×tE = P \times tE=P×t,其中PPP是功耗,ttt是时间。
1.4 2010s后期至2020s:多样化发展和标准化
- 行业爆发:更多玩家进入,如NVIDIA的Tensor Core(集成于GPU)、Intel的Nervana NPU、以及初创公司如Graphcore的IPU。NPU设计更注重能效比,目标是在边缘设备实现实时AI。
- 集成化趋势:NPU被嵌入SoC(系统级芯片),例如高通骁龙系列和联发科天玑芯片,支持移动端应用。性能提升显著,如2020年Apple A14的NPU算力达111111 TOPS(万亿操作每秒)。
- 标准推动:产业联盟如MLPerf制定基准测试,推动NPU性能优化。计算公式如吞吐量T=OtT = \frac{O}{t}T=tO,其中OOO是操作数,ttt是时间。
1.5 当前状态和未来趋势(2023年至今)
- 普及化:NPU已成为智能手机、自动驾驶汽车和云服务器的标配。例如,最新NPU支持Transformer模型,处理语言任务时延迟低于111毫秒。
- 技术前沿:研究方向包括3D堆叠内存、存算一体架构,以及支持稀疏计算(如sparsity>90%sparsity > 90\%sparsity>90%时的加速)。量子启发算法也开始探索。
- 挑战与机遇:能效比需进一步提升(目标<1<1<1W/TOPS),同时应对AI模型复杂度增长。未来趋势指向异构计算(CPU+GPU+NPU协同)和开源硬件生态。
NPU的发展从通用硬件的辅助角色,演变为AI计算的核心引擎,推动了人工智能的普及化。其历程体现了硬件与算法的共同进化:早期依赖GPU,中期专用化突破,后期集成化和标准化。未来,NPU将继续在低功耗、高性能方向迭代,赋能更广泛的AI应用。
2. NPU的工作原理
NPU(神经网络处理器)的工作原理围绕深度学习算法的硬件加速设计,专为处理神经网络的矩阵运算、张量操作和稀疏计算而生。其核心逻辑是通过定制化架构减少数据搬运开销,提升AI任务的计算效率与能效比。
2.1 NPU的核心目标
NPU 的主要目标是加速神经网络的前向传播和反向传播过程。相比于通用处理器(如CPU)或图形处理器(如GPU),NPU 针对矩阵运算和激活函数等操作进行了硬件级优化。这能显著降低延迟和功耗,适用于移动设备、边缘计算等场景。
2.2 关键组件和工作流程
NPU 的工作原理基于几个核心组件,数据流通常按以下步骤处理:
-
输入数据加载:输入数据(如图像或传感器数据)被加载到NPU的内存中。NPU 使用高速缓存和直接内存访问(DMA)技术来减少数据搬运开销。
-
并行矩阵运算:神经网络的核心是矩阵乘法(如权重矩阵与输入向量的乘积)。NPU 内置多个处理单元(PEs),能同时执行大量乘加运算(MAC)。例如,一个简单的全连接层计算可以表示为:
y=Wx+b \mathbf{y} = \mathbf{W} \mathbf{x} + \mathbf{b} y=Wx+b
其中 W\mathbf{W}W 是权重矩阵,x\mathbf{x}x 是输入向量,b\mathbf{b}b 是偏置向量。NPU 将这些运算分解为小块,在硬件上并行处理,提升吞吐量。 -
激活函数处理:矩阵运算后,结果通过激活函数(如ReLU或Sigmoid)进行非线性变换。NPU 集成专用电路来处理这些函数,避免软件开销。例如,ReLU激活定义为 f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x),NPU 能在单周期内完成。
-
池化和归一化:对于卷积神经网络(CNN),NPU 还优化池化层(如最大池化)和归一化层(如BatchNorm)。这些操作通过硬件加速器直接执行,减少计算延迟。
-
输出生成:最终结果被写回内存或输出到系统。整个过程高度流水线化,确保数据连续流动。
2.3 优化技术
NPU 采用多种硬件技术提升效率:
- 低精度计算:使用INT8或FP16等低精度数据类型,节省内存和功耗,同时保持模型精度。
- 稀疏性利用:神经网络权重往往稀疏(许多元素为零),NPU 检测并跳过零值运算,减少无效计算。
- 片上存储:集成大容量SRAM缓存权重和中间数据,最小化外部内存访问,这是性能瓶颈的关键。
2.4 优势与典型应用
NPU 的优势在于:
- 高性能:并行度远高于CPU,例如每秒处理万亿次操作(TOPS)。
- 低功耗:专用电路比软件实现更节能,适合电池供电设备。
- 实时性:适用于实时AI任务,如物体检测($ \text{输出} = \text{检测框坐标} $)或语音识别。
典型应用包括智能手机的AI相机、自动驾驶的感知系统等。
NPU的本质是神经网络的硬件加速器,通过“定制化架构+数据流优化+低功耗设计”,将深度学习算法的计算效率提升10~100倍。从云端数据中心的AI服务器到边缘设备的手机/机器人,其工作原理始终围绕“用最小功耗完成最大规模张量运算”的目标,与CPU、GPU形成互补的异构计算生态。
四、TPU
张量处理器(英语:tensor processing unit,缩写:TPU)是Google为机器学习定制的专用芯片(ASIC),专为Google的深度学习框架TensorFlow而设计。
1.TPU的发展历程
TPU的发展历程就比较简单了,Google在2016年的Google I/O年会上首次公布了TPU。不过在此之前TPU已在Google内部的一些项目中使用了一年多,如Google街景服务、RankBrain以及其旗下DeepMind公司的围棋软件AlphaGo等都用到了TPU。而在2017年的Google I/O年会上,Google又公布了第二代TPU,并将其部署在Google云平台之上。第二代TPU的浮点运算能力高达每秒180万亿次。
1.1 第一代TPU(2015)
2015年Google秘密部署第一代TPU,采用28nm工艺,专为推理优化。其架构针对TensorFlow框架的矩阵运算进行定制,峰值算力达92 TOPS(INT8),功耗仅40W。该版本未公开销售,仅用于Google内部数据中心。
1.2 TPUv2(2017)
2017年发布的TPUv2支持训练与推理,采用16nm工艺,单个芯片算力提升至45 TFLOPS(FP16),并通过Pod架构实现多芯片互联(最高11.5 PFLOPS)。Google Cloud开始提供TPUv2租用服务,标志着TPU商业化起步。
1.3 TPUv3(2018)
2018年推出的TPUv3采用液冷散热设计,性能翻倍至90 TFLOPS(FP16),单个Pod算力达100 PFLOPS。同期发布TPU Pods超算方案,支持更大规模的分布式训练。
1.4 TPUv4(2021)
2021年发布的TPUv4采用7nm工艺,单芯片算力达275 TFLOPS(BF16),Pod级算力突破1 EFLOPS。重点优化了稀疏计算能力,并集成光互联技术降低延迟。
1.5 Edge TPU(2018)
针对边缘计算推出的Edge TPU,功耗仅2W,支持INT8推理。应用于物联网设备(如Google Pixel手机、Nest摄像头),强调低延迟与隐私保护。
4. TPU的工作原理
TPU(张量处理单元)是专为加速机器学习计算设计的硬件,其核心设计围绕高效执行矩阵运算展开。
4.1 架构基础
TPU采用脉动阵列(是一种通过数据流动与计算单元固定实现高效并行计算的硬件架构,由计算机科学家 H.T. Kung 于 1978 年提出。其核心思想是让数据像血液流经心脏一样在阵列中规律流动,计算单元仅需在数据经过时执行操作,避免传统架构中数据频繁搬运的开销)架构,包含数千个并行处理单元(PE)。这些单元以网格形式排列,实现数据流的高效传递:
- 矩阵乘法单元(MXU):执行密集的8位8位8位整数矩阵乘法
- 统一缓冲区(UB):存储中间张量数据(容量约24MB24MB24MB)
- 激活单元:处理非线性函数如ReLU(x)=max(0,x)ReLU(x) = \max(0,x)ReLU(x)=max(0,x)
- 权重缓存:预载模型参数避免重复读取
4.2 计算流程
以神经网络推理为例:
-
数据加载
输入数据X∈Rm×nX \in \mathbb{R}^{m \times n}X∈Rm×n和权重W∈Rn×pW \in \mathbb{R}^{n \times p}W∈Rn×p从内存加载至UB
X=[x11⋯x1n⋮⋱⋮xm1⋯xmn],W=[w11⋯w1p⋮⋱⋮wn1⋯wnp] X = \begin{bmatrix} x_{11} & \cdots & x_{1n} \\ \vdots & \ddots & \vdots \\ x_{m1} & \cdots & x_{mn} \end{bmatrix}, \quad W = \begin{bmatrix} w_{11} & \cdots & w_{1p} \\ \vdots & \ddots & \vdots \\ w_{n1} & \cdots & w_{np} \end{bmatrix} X= x11⋮xm1⋯⋱⋯x1n⋮xmn ,W= w11⋮wn1⋯⋱⋯w1p⋮wnp -
矩阵乘法
MXU并行计算Y=X×WY = X \times WY=X×W,每个PE处理:
yij=∑k=1nxik⋅wkj y_{ij} = \sum_{k=1}^{n} x_{ik} \cdot w_{kj} yij=k=1∑nxik⋅wkj
采用8位8位8位定点运算提升吞吐量 -
激活处理
激活单元对YYY逐元素操作,例如:
ReLU(yij)={yijif yij>00otherwise \text{ReLU}(y_{ij}) = \begin{cases} y_{ij} & \text{if } y_{ij} > 0 \\ 0 & \text{otherwise} \end{cases} ReLU(yij)={yij0if yij>0otherwise -
结果回写
最终张量写回UB或输出内存
4.3 关键优化技术
- 数据流架构:数据在PE间单向流动,减少访问延迟
- 量化压缩:使用8位8位8位而非32位32位32位浮点,带宽需求降至1/41/41/4
- 权重预载:模型参数常驻芯片缓存,避免外部读取瓶颈
- 指令精简:仅支持101010余条专用指令(如矩阵乘/卷积)
4.4 性能对比
| 指标 | TPU v4 | GPU A100 |
|---|---|---|
| 峰值算力 | 275275275 TFLOPS | 312312312 TFLOPS |
| 能效比 | ≥3×\geq 3\times≥3× | 基准值 |
| 矩阵乘延迟 | 5μs5\mu s5μs | 15μs15\mu s15μs |
注:TPU尤其擅长卷积/全连接层等操作,其架构使计算与数据移动比(OPs/ByteOPs/ByteOPs/Byte)显著高于通用处理器。
这种专用化设计使TPU在处理大规模神经网络时,能效和速度远超通用计算硬件。
五、DPU
1.DPU的发展历程
DPU(Data Processing Unit,数据处理单元)是一种专用硬件加速器,主要用于数据中心环境中处理网络、存储和安全任务,以减轻CPU负担并提升整体效率。
1.1 起源与背景(2000年代末至2010年代初)
- 在云计算兴起初期,数据中心面临CPU处理瓶颈问题。例如,网络数据包的转发和虚拟化开销消耗了大量CPU资源,导致性能下降。这时,业界开始探索硬件卸载方案,如智能网卡(SmartNICs),它集成了FPGA或ASIC来处理基本网络功能。
- 数学表达:假设CPU的负载为LcpuL_{\text{cpu}}Lcpu,智能网卡可卸载部分任务,使有效负载降低为Leff=Lcpu−ΔLL_{\text{eff}} = L_{\text{cpu}} - \Delta LLeff=Lcpu−ΔL,其中ΔL\Delta LΔL表示卸载量。
1.2 初步形成(2010年代中期)
- 随着软件定义网络(SDN)和网络功能虚拟化(NFV)的普及,智能网卡功能扩展至包括流量管理、加密和压缩。公司如Broadcom和Cavium(现Marvell)推出了早期产品,这些设备能处理高达40Gbps40 \text{Gbps}40Gbps的带宽。
- 关键事件:2015年左右,FPGA-based方案被广泛采用,用于加速特定协议,如TCP/IP卸载。性能提升公式可表示为:
加速比=CPU处理时间DPU处理时间 \text{加速比} = \frac{\text{CPU处理时间}}{\text{DPU处理时间}} 加速比=DPU处理时间CPU处理时间
典型值可达5×5\times5×以上。
1.3 正式命名与商业化(2020年左右)
- NVIDIA在2020年推出BlueField系列产品,首次使用“DPU”术语,将其定位为数据中心基础设施处理器。DPU的核心功能包括全栈卸载:从网络I/O到存储虚拟化和安全隔离。
- 数学表达:例如,DPU可处理数据中心80%80\%80%的网络流量,释放CPU资源用于应用计算,即CPU利用率优化为Ucpu=Uoriginal×(1−α)U_{\text{cpu}} = U_{\text{original}} \times (1 - \alpha)Ucpu=Uoriginal×(1−α),其中α\alphaα为卸载比例。
- 行业影响:这标志着DPU从概念转向主流,多家厂商如Intel(收购Habana Labs后推出IPU)和AMD(通过Xilinx FPGA)跟进。
1.4 功能扩展与标准化(2021年至今)
- DPU功能不再限于网络,而是扩展到AI推理、边缘计算和零信任安全。例如,NVIDIA BlueField-3支持高达400Gbps400 \text{Gbps}400Gbps的吞吐量,并集成了Arm核心用于可编程任务。
- 标准演进:开放标准如DOCA(Data Center Infrastructure on Arm)框架出现,促进软件生态发展。性能模型可描述为:
总吞吐量=网络带宽×处理效率 \text{总吞吐量} = \text{网络带宽} \times \text{处理效率} 总吞吐量=网络带宽×处理效率
其中处理效率通常超过90%90\%90%。
1.5 当前趋势
- 现状:DPU已成为数据中心标配,应用于超大规模云服务(如AWS、阿里云),支持实时分析和低延迟需求。市场预计到2025年,DPU渗透率将达50%50\%50%以上。
2.DPU的工作原理
1. 任务卸载
- CPU将特定任务(如网络包处理、加密解密、存储管理)委托给DPU执行。
- 例如:网络流量处理中,DPU直接解析数据包头,执行路由或过滤操作,无需CPU介入。
数学表达:若CPU负载为 LcpuL_{\text{cpu}}Lcpu,DPU卸载后负载降为:
Lcpu′=Lcpu−∑i=1nTi L_{\text{cpu}}' = L_{\text{cpu}} - \sum_{i=1}^{n} T_i Lcpu′=Lcpu−i=1∑nTi
其中 TiT_iTi 表示第 iii 类卸载任务的资源消耗。
2. 并行硬件加速
- DPU集成专用硬件引擎(如网络加速器、加密引擎),通过并行化提升效率。
- 示例:加密操作中,DPU的硬件加速器可同时处理多个数据流,吞吐量满足:
Qenc=k⋅fclk⋅bwidth Q_{\text{enc}} = k \cdot f_{\text{clk}} \cdot b_{\text{width}} Qenc=k⋅fclk⋅bwidth
kkk 为并行通道数,fclkf_{\text{clk}}fclk 为时钟频率,bwidthb_{\text{width}}bwidth 为位宽。
3. 数据流优化
- DPU直接连接高速I/O接口(如PCIe、以太网),数据流路径缩短:
对比传统路径网络设备 → DPU(处理/过滤) → 内存/存储设备 → CPU → 内存,延迟降低 50%50\%50% 以上。
4. 资源隔离
- DPU为不同任务划分独立计算单元(如虚拟化场景),确保关键任务不受干扰:
- 安全任务:隔离在加密引擎中
- 存储任务:由专用DMA控制器处理
- 数学表达:资源分配满足约束:
∑j=1mRj≤Rtotal,Rj≥Rmin,j \sum_{j=1}^{m} R_j \leq R_{\text{total}}, \quad R_j \geq R_{\min,j} j=1∑mRj≤Rtotal,Rj≥Rmin,j
RjR_jRj 为第 jjj 类任务资源,RtotalR_{\text{total}}Rtotal 为DPU总资源。
典型应用场景
- 网络功能卸载:DPU处理TCP/IP协议栈,释放CPU资源。
- 分布式存储:DPU直接管理NVMe存储,加速数据存取。
- 安全网关:硬件级加密/解密,抵御DDoS攻击。
关键优势:通过硬件级卸载和并行加速,DPU将数据中心效率提升 3−53-53−5 倍,同时降低CPU负载 70%70\%70% 以上。
六、IPU
1.IPU的发展历程
IPU(Intelligence Processing Unit)是一种专为人工智能计算设计的处理器,由英国公司Graphcore开发。它旨在优化机器学习和大规模并行计算任务,提供高性能和能效比。
其发展历程总共可以概括为以下几个方面:
2016 : Graphcore成立 2018 : 首代Colossus MK1发布 2020 : IPU-M2000商业化部署 2021 : Bow IPU 3D封装突破 2022 : GC200支持万亿参数模型 2023 : IPU-POD256集群问世
下面我们来详细了解一下。
1.1 初始阶段(2016-2017年)
- 2016年,Graphcore公司成立,专注于研发新型AI硬件。团队由资深芯片设计师组成,目标是通过创新架构解决传统处理器(如CPU和GPU)在AI训练和推理中的瓶颈。
- 2017年,公司获得多轮融资,开始原型设计。核心理念是采用“图计算”模型,允许数据在处理器内自由流动,提升并行效率。例如,设计支持高吞吐量,理论峰值性能可达100100100 TFLOPS(万亿次浮点运算每秒)。
1.2 第一代IPU发布(2018年)
- 2018年,Graphcore正式推出第一代IPU,代号为Colossus MK1 GC2。这款芯片基于16nm制程工艺,集成超过100010001000个独立处理核心,每个核心能同时处理多个线程。
- 关键创新包括:
- 支持大规模稀疏数据处理,适用于神经网络训练。
- 提供高达161616 TFLOPS的FP16性能。
- 通过软件栈Poplar SDK,简化开发者集成。
- 这一代产品被多家企业试用,应用于数据中心和自动驾驶等领域,标志着AI专用硬件的商业化起步。
1.3 第二代IPU及演进(2020-2021年)
- 2020年,发布第二代IPU(MK2),采用7nm制程,性能显著提升。主要改进:
- 计算密度增加,峰值性能达250250250 TFLOPS。
- 支持更复杂模型,如Transformer架构,通过硬件优化减少延迟。
- 能效比提高,功耗控制在200200200瓦以下。
- 2021年,Graphcore推出IPU-Machine系列服务器系统,将多个IPU集成在单一平台,支持云端AI服务。例如,一个IPU-Pod系统可集成数千个IPU,实现101010 PFLOPS(千万亿次浮点运算每秒)的算力。
1.4 近期发展(2022年至今)
- 2022年,Graphcore聚焦软件生态,增强Poplar SDK的兼容性,支持PyTorch和TensorFlow等框架。同时,优化IPU用于边缘计算场景,如智能物联网设备。
- 2023年,公司宣布下一代IPU研发计划,目标包括:
- 采用更先进制程(如5nm),提升能效。
- 支持新型AI算法,如强化学习和生成式模型。
- 扩展应用领域,包括医疗影像分析和金融预测。
- 当前,IPU已在全球数据中心部署,合作伙伴包括微软Azure和戴尔,推动AI计算的民主化。
IPU的发展从概念创新到商业化,仅用数年时间便成为AI硬件领域的重要力量。其历程体现了技术迭代的加速:从2018年的初代产品到如今的云端集成,IPU持续提升性能(如计算能力从161616 TFLOPS增至250250250 TFLOPS),并推动AI应用普及。未来,随着AI需求增长,IPU有望在算力效率和生态扩展上进一步突破。
2.IPU的工作原理
2.1 IPU的核心架构
IPU的核心是高度并行的硬件设计。它包含大量独立的处理单元(称为“tiles”),每个tile都有自己的计算核心、本地内存和通信接口。例如:
- 一个典型的IPU芯片可能有超过1000个tiles(如Graphcore的Colossus MK2 IPU有1472个tiles)。
- 每个tile可以并行执行任务,减少数据移动延迟。
- 内存架构采用分布式设计:数据存储在tile的本地内存中,避免频繁访问外部内存,从而提升效率。内存带宽高达数十TB/s。
这种架构类似于“多核处理器”,但更专注于AI负载的并行性,例如矩阵运算和向量计算。
2.2 数据流与计算模型
IPU的工作原理依赖于高效的数据流管理:
- 数据并行性:当处理AI模型(如神经网络)时,输入数据被分割成小块,分配到不同tiles上并行处理。例如,一个大型矩阵乘法可以分解为多个子任务。
- 数学上,矩阵乘法 C=A×BC = A \times BC=A×B 被并行计算,其中每个tile处理部分 AAA 和 BBB 的子矩阵。
- 计算优化:IPU支持稀疏计算(只处理非零数据)和动态执行(根据运行时数据调整计算路径),这在深度学习常见(如激活函数 ReLU)。
- 例如,ReLU函数 f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x) 可以在单个tile上高效执行。
- 通信机制:tiles之间通过高速片上网络(on-chip network)互联,支持低延迟数据交换。这避免了传统处理器中的“内存墙”问题,确保计算单元始终忙碌。
2.3 软件栈支持(Poplar框架)
IPU的硬件能力通过软件栈发挥出来,核心是Poplar框架:
- 编译阶段:用户编写的AI模型(如PyTorch或TensorFlow代码)被Poplar编译器优化,转化为IPU专用的指令集。编译器会:
- 自动并行化计算图。
- 优化内存分配,减少数据复制。
- 执行阶段:编译后的代码在IPU上运行时,Poplar运行时系统动态调度任务,确保tiles负载均衡。例如,在训练神经网络时:
- 前向传播、反向传播和权重更新被分配到不同tiles并行执行。
- 支持批量处理(batching),提升吞吐量。
2.4 优势与性能
IPU的设计带来显著优势:
- 高效能:针对AI负载优化,相比通用CPU或GPU,IPU在相同功耗下提供更高性能(如更高的TOPS/Watt)。
- 低延迟:片上内存和并行架构减少了数据移动,特别适合实时推理任务。
- 可扩展性:多个IPU芯片可以互联,构建大规模系统(如IPU-POD),处理超大型模型。
总结来说,IPU的工作原理是通过大规模并行硬件架构(tiles)、高效数据流管理和专用软件栈(Poplar)的协同,实现AI计算的加速。它在训练Transformer模型或处理稀疏数据等场景中表现突出。如果您有具体应用场景,我可以进一步解释细节!
七、各类AI硬件对比与协同
为了更好的总结对比几种处理器之间的特点和差异,下面我放上两张表格,第一张是我在网络上搜集的表格,第二张是总结本文的表格。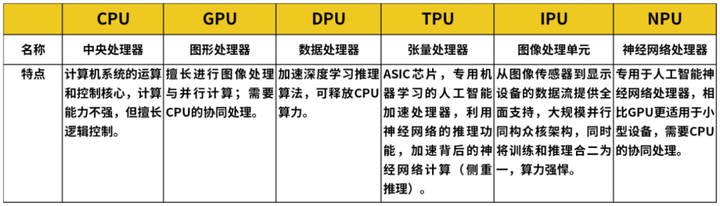
| 硬件类型 | 核心优势 | 典型功耗 | 适用场景 | 架构特点 | 数据处理能力 | 代表产品及性能示例 |
|---|---|---|---|---|---|---|
| CPU | 逻辑控制强,指令集丰富,通用性高,能处理各种复杂逻辑和串行任务,对操作系统和各类软件兼容性极佳 | 20 - 100W(桌面级 i3 - i9 系列,移动级功耗更低),如 i5 - 12400F 的 TDP 为 65W,实际最大功耗 115W | 通用计算,作为计算机系统的控制中枢,负责操作系统运行、应用程序调度、常规数据处理(如办公软件运行、数据库事务处理等)、网络协议栈处理以及与外部设备交互等 | 复杂的控制单元和少量核心,采用顺序执行指令方式,注重指令执行的完整性和精确性 | 擅长处理小数据量、逻辑复杂的数据操作,对数据处理的灵活性高,但大规模并行数据处理能力相对较弱 | 英特尔酷睿 i9 - 14900KF,16 核 32 线程,睿频可达 5.8GHz,在多线程渲染任务中表现出色,能流畅运行各类专业软件 |
| GPU | 并行计算能力强,拥有大量计算核心,可同时处理海量数据,在大规模并行计算任务上性能卓越 | 100 - 400W,如 NVIDIA A100 功率为 300W | 深度学习模型训练(尤其是大规模神经网络,如图像识别、语音识别、自然语言处理模型训练)、科学计算(如计算流体力学、分子动力学模拟等)、图形渲染(游戏、影视特效制作) | 采用流式多处理器架构,以并行方式执行大量相同指令,适合处理高度并行化的数据 | 每秒可执行数万亿次浮点运算,能够快速处理大规模矩阵运算、向量计算等 | NVIDIA A100,拥有 820 亿个晶体管,具备 19.5 TFLOPS(FP32)、156 TFLOPS(TF32)、312 TFLOPS(FP16)算力,在 GPT - 3 模型训练中,相比前代产品大幅缩短训练时间 |
| NPU | 专为神经网络计算设计,采用定制化架构,在处理神经网络算法时具有低功耗、高效率的特点,对深度学习推理任务优化显著 | 0.1 - 10W(适用于边缘设备的低功耗场景),如瑞芯微 RK3588S 集成的 NPU 算力为 6TOPS,典型功耗 2 - 3W | 边缘设备(如智能摄像头、智能音箱、移动终端等)的实时推理,对设备功耗和实时性要求高的场景,可在本地快速处理数据,减少数据传输延迟 | 通常采用脉动阵列等架构,将计算单元与存储紧密结合,减少数据搬运开销,提升计算效率 | 能够高效执行卷积、池化、全连接等神经网络层计算,在低功耗下实现较高的神经网络运算性能 | 寒武纪思元 220,算力为 16TOPS(INT8),在智能安防摄像头中,可实时对视频流中的目标进行检测和识别,功耗仅数瓦 |
| DPU | 数据处理速度快,专注于数据中心网络、存储和安全相关的数据处理任务,可将 CPU 从繁重的数据处理任务中解放出来 | 20 - 50W,如 NVIDIA BlueField - 3 DPU 典型功耗约为 25W | 数据中心,承担网络卸载(如 TCP/IP 协议处理、RDMA 加速)、存储卸载(NVMe - oF 协议处理、存储虚拟化)、安全加速(加密解密、防火墙功能)等任务,提升数据中心整体效率 | 具备强大的网络处理引擎、硬件加速器以及与外部网络接口和存储设备的高速连接能力 | 能够以线速处理网络数据包,实现高速数据传输和存储访问加速,对数据的处理能力在数据中心场景下表现突出 | NVIDIA BlueField - 3,支持 400G 以太网和 NDR InfiniBand,通过 RDMA 技术可显著减少 CPU 在网络任务上的开销,加速内存之间的数据交换 |
| IPU | 通信效率高,通过创新架构优化数据在芯片内部及芯片间的通信,支持多芯片协同工作,适用于大规模数据并行处理场景 | 10 - 30W,如英特尔基于 FPGA 的 IPU 产品功耗相对较低 | 多芯片协同计算场景,如超算领域、大规模数据中心的分布式计算任务,可有效提升集群计算性能 | 采用独特的分布式计算架构,内部计算单元以高效的方式互联,便于数据在不同单元间快速传递和处理 | 能够在多芯片协作下,实现大规模数据的快速处理,提升整体计算效率 | 英特尔 IPU 可将 CPU 从基础设施任务中解放,在数据中心场景下,减少 CPU 中虚拟机管理程序和基础设施堆栈的开销,加速远程存储访问 |
| TPU | 针对张量运算进行深度优化,在处理神经网络中的矩阵乘法等张量操作时性能出众,具备高算力和高计算密度 | 200 - 400W,如 Google TPU v4 功率约为 400W | 云端 AI 服务,用于大规模深度学习模型的训练和推理,尤其适合对算力要求极高的大模型场景 | 采用脉动阵列等专为张量运算设计的架构,配合大规模的计算单元和高带宽片上存储 | 拥有极高的算力,如 Google TPU v4 Pod 算力达 1.1 ExaFLOPS,能以极高速度完成大规模矩阵运算 | Google TPU v4,采用光互连技术,支持 BF16、FP16、INT8 等混合精度计算,在谷歌搜索排名模型推理中,可将延迟降低 60% |

欢迎加入北京社区
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)