
第七章(三)VLA
小知识:字母"B"通常代表“Billion”,即“十亿”。这是模型训练中所使用到参数的数量。例如,GPT-3模型有175B个参数,这里的“175B”就是表示该模型有1750亿个参数。一般情况下,参数越多,代表模型训练的越复杂,模型的能力也就越强。通常1B,意味着需要1G以上的内存,7B需要8G以上的内存才能成功运行大模型。
小知识:字母"B"通常代表“Billion”,即“十亿”。这是模型训练中所使用到参数的数量。例如,GPT-3模型有175B个参数,这里的“175B”就是表示该模型有1750亿个参数。一般情况下,参数越多,代表模型训练的越复杂,模型的能力也就越强。通常1B,意味着需要1G以上的内存,7B需要8G以上的内存才能成功运行大模型。
VLA
可以区分为VLM/LLM加上策略方式和VLA直接输出方式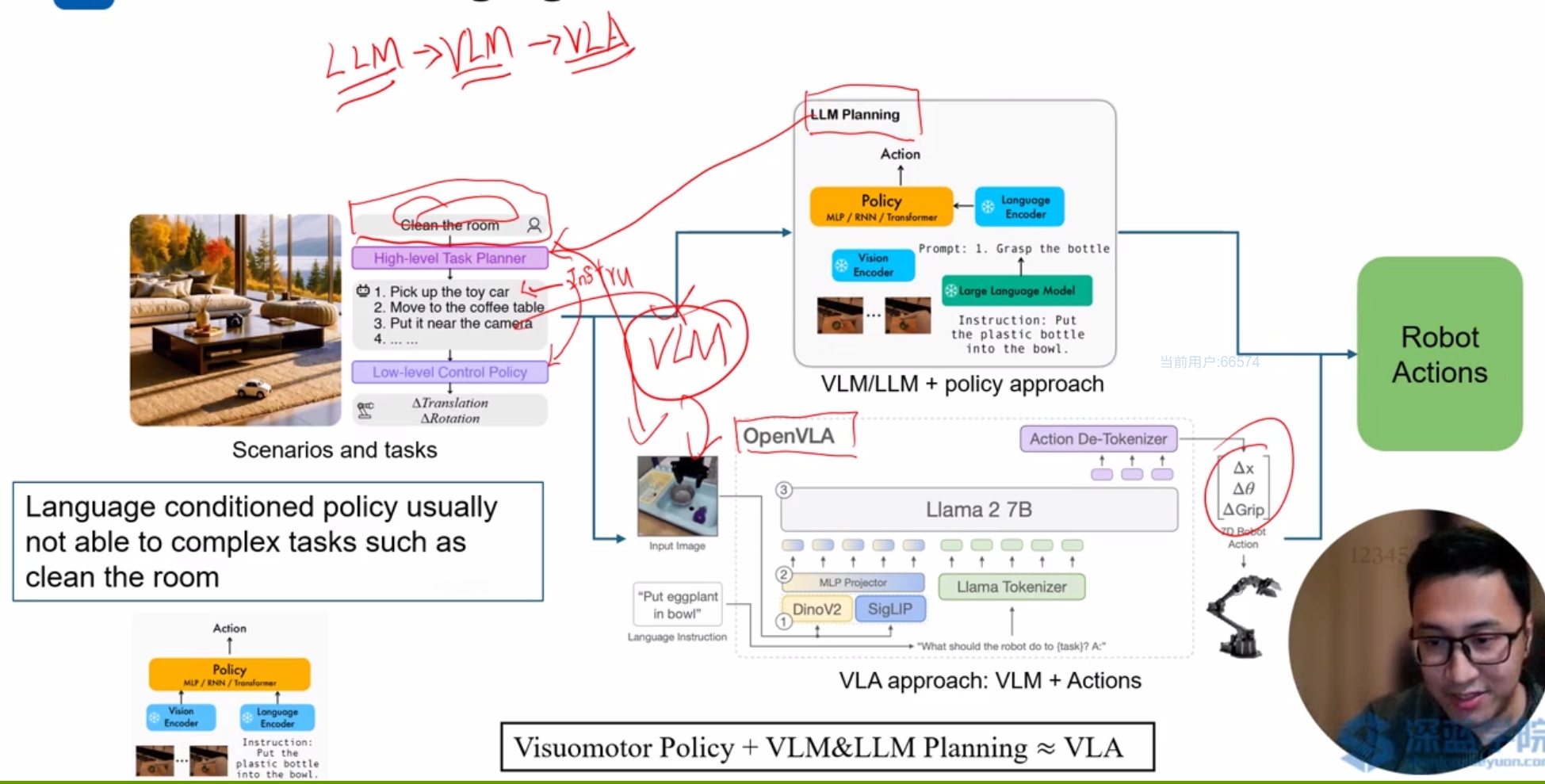
RDT
挑战:机器人数据的不稳定性,机器人数据的非线性特征。
解决数据的异构性
通过引入了一个物理可解释的统一动作空间,以统一不同机器人的动作表示,同时保留原始动作的物理意义,促进模型学习跨不同机器人数据集的可转移物理知识。
编码方式如下: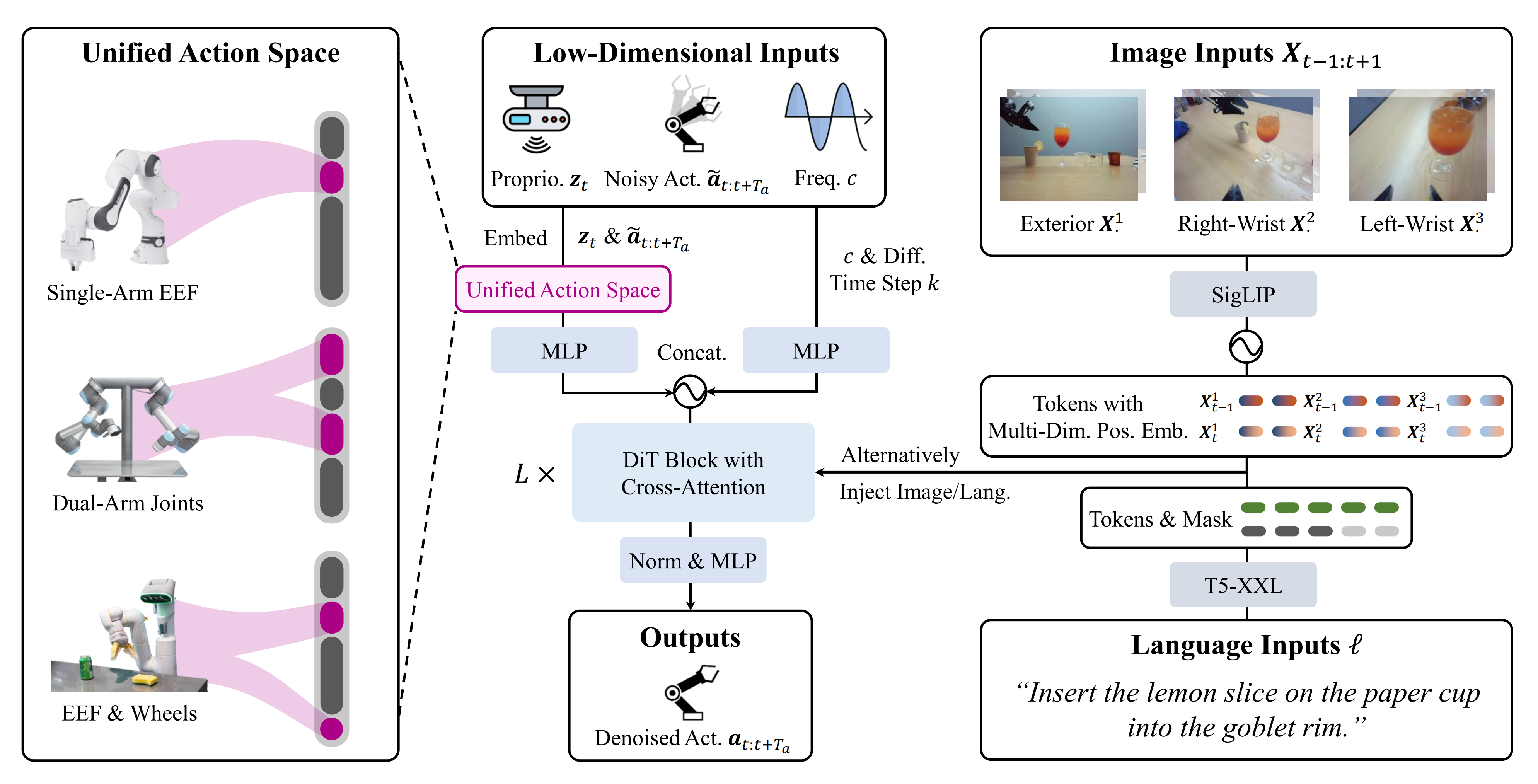
本体感知zt,将所有机器人的动作嵌入到一个128维度的统一工作空间。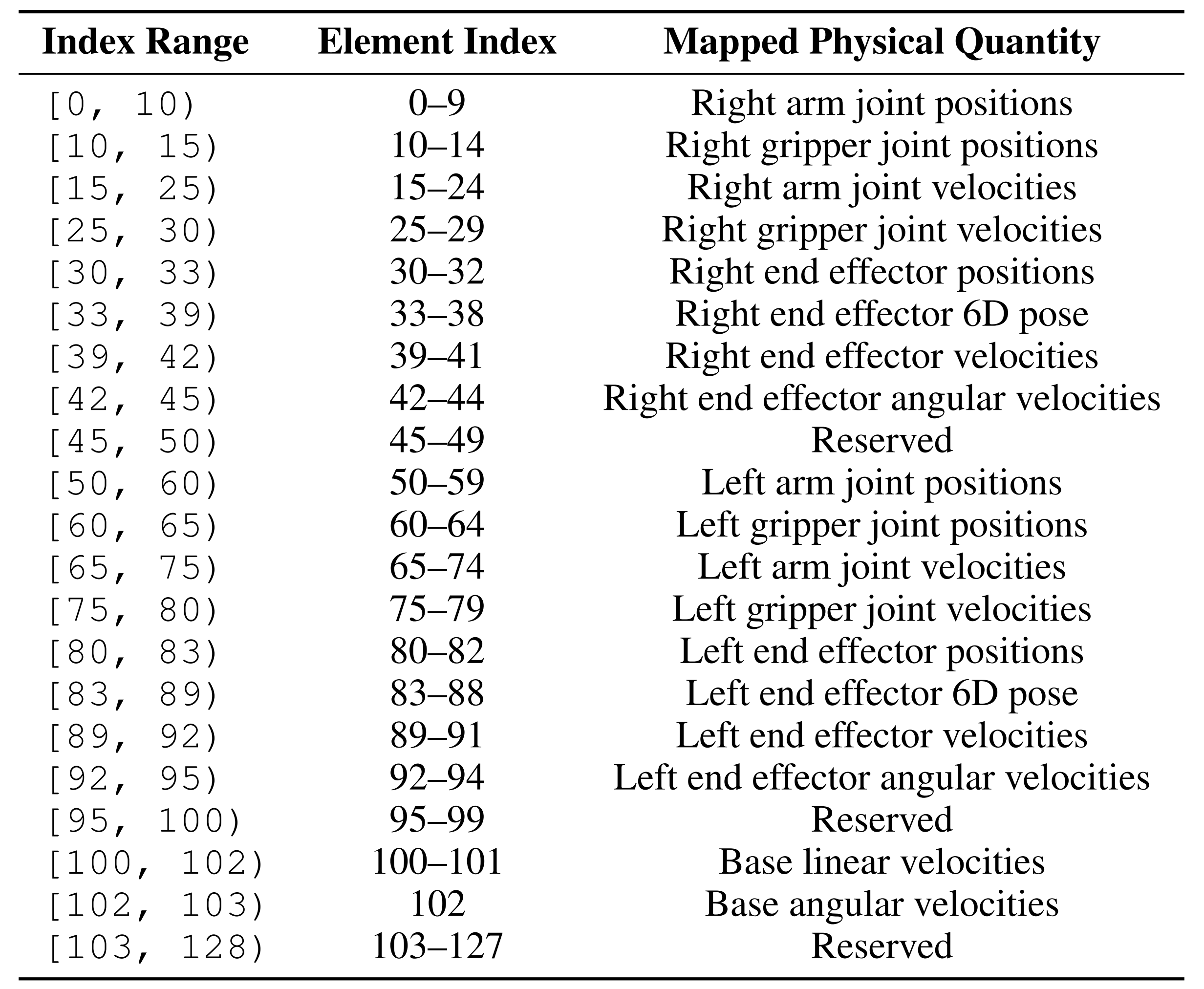
构建了一个统一的动作空间之后,便可以在异构多机器人数据上进行训练。
通过一个共享的MLP进行编码,有趣的是,这里还将控制频率作为模型输入,希望模型推理的时候能够考虑到频率的变化。
cat后的长度为Ta+1(zt)+1©+1(k)
第二种输入为图像输入,对应高维输入,采用图像-文本对齐的预训练视觉编码器:SigLIP。
为了增强模型根据视角和时间步区分图像的能力,将正弦位置嵌入扩展到多维网络。
第三种模态文本输入采用预训练的T5-XXL
Training
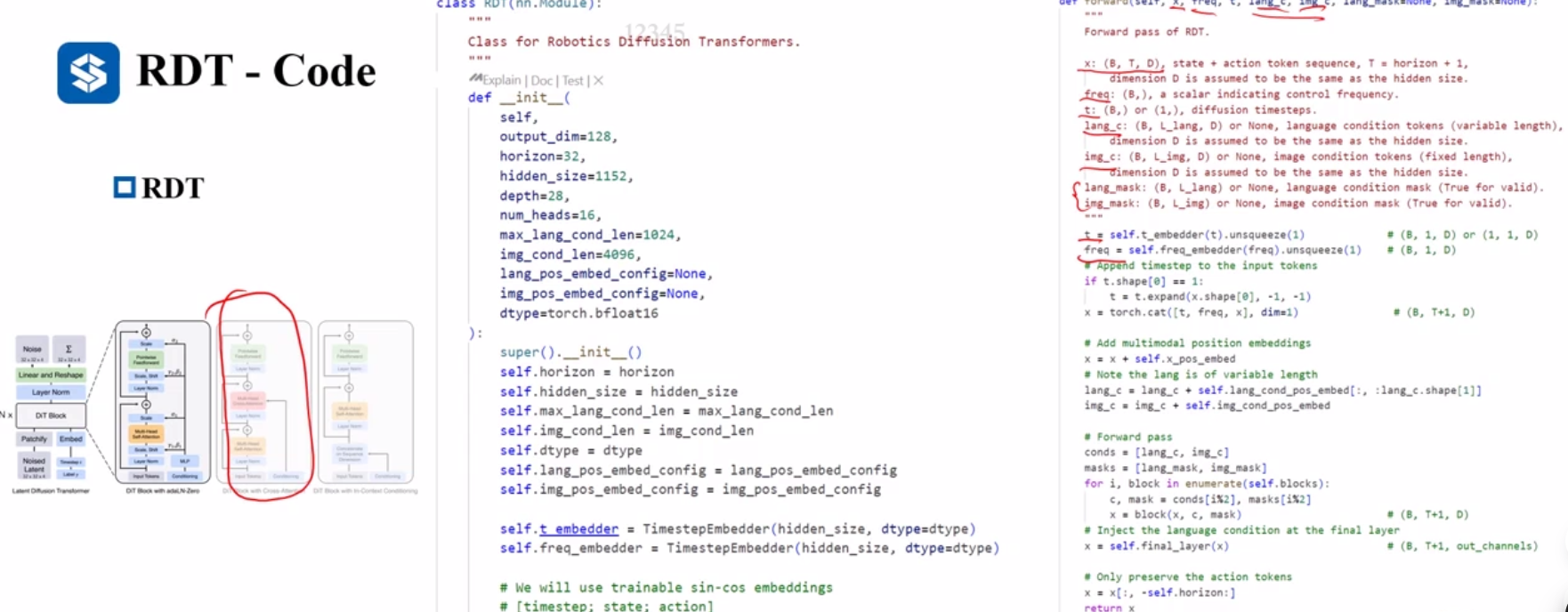
推理频率能够到达381Hz, 不过需要看设定的chunk_size和设备。
微调相对于预训练的数据量大大减少,6000条轨迹,0.6%的量级,3天的训练130K个step.
action chunk size 64, 6Hz,推理能到达384hz=64*6。
code

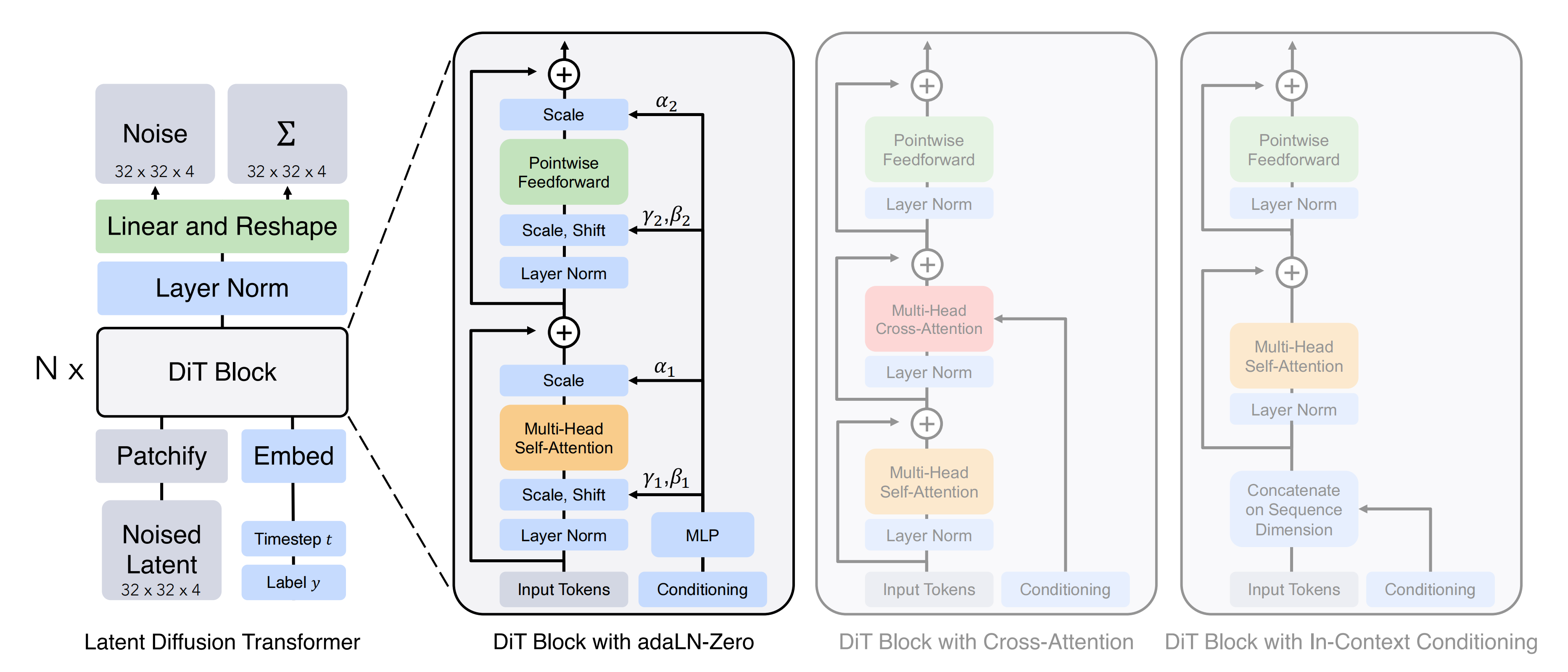
基于Transformer cross attention 搭建,将扩散过程中的U-Net 换成ViT(2D图像生成,带文本条件融合),作者做了三个修改:
1.交替条件注入(即Alternating Condition Injection,简称ACI):图像和语言token,而非同时注入两者,因为图像的维度远高于文本信息,同时注入往往会淹没文本信息,削弱模型对具体指令的遵循能力。
2.MLP解码器,解决机器人数据的非线性特征:采用非线性MLP解码器作为从潜在空间回到物理空间的投影,机器人动作符合非线性动力学规律。有效提升精细灵巧操作
3. 添加QKNorm和RMSNorm,解决机器人数据不稳定问题。机器人物理量的不稳定会导致梯度不稳定和数值溢出等问题
机器人数据中往往会出现极端值。这种极端值可能导致梯度不稳定和数值溢出等问题
推理阶段
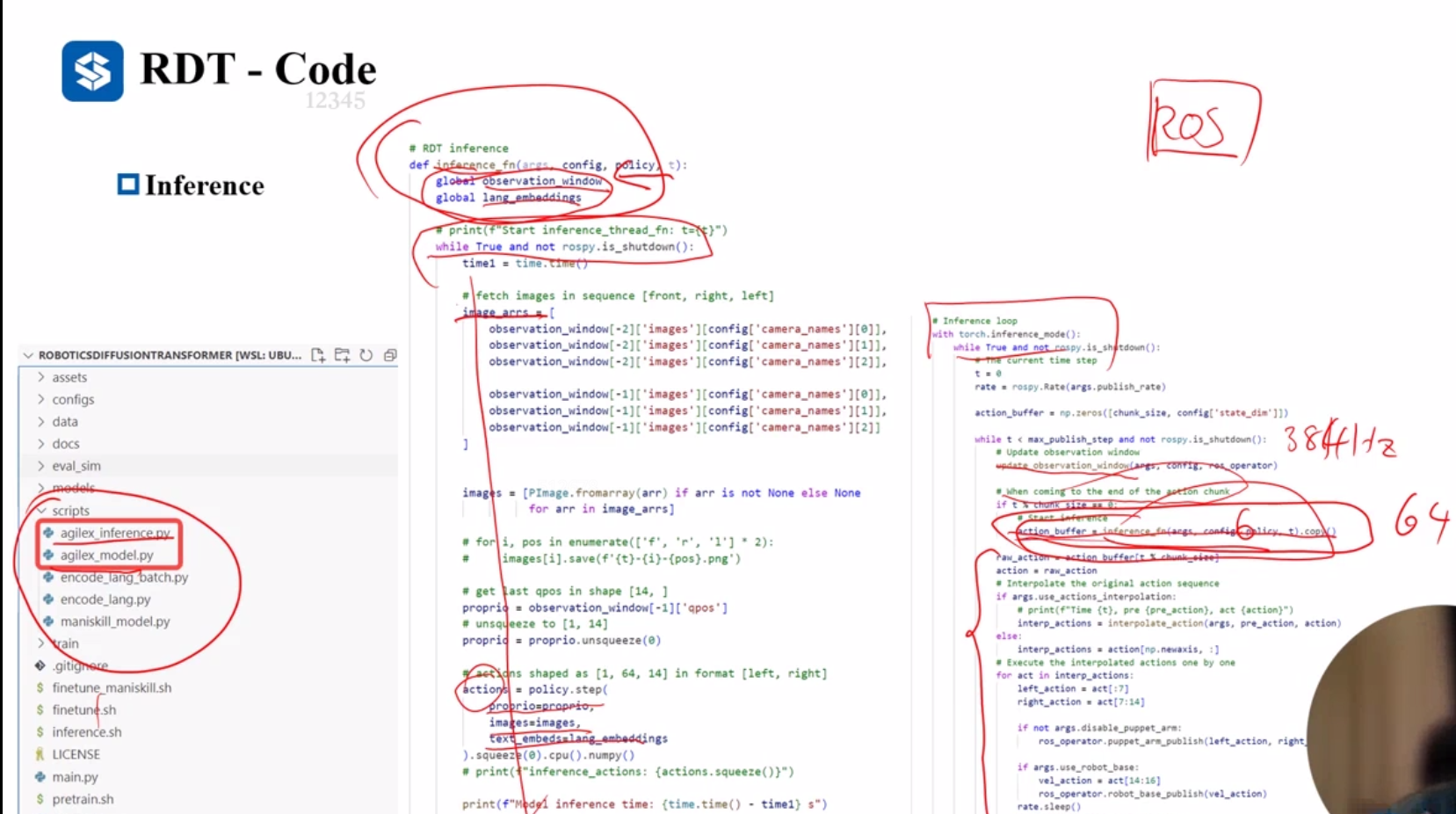
使用ROS与底层交互
pi0
与DP学习每个去噪过程的条件分布不同的事
流匹配直接对数据和噪声分布之间的映射场(vector field)进行建模,训练目标是建模这个匹配的过程,也就是获得映射场函数
不直接预测动作,而是学习一个如何将简单分布(如高斯噪声)“塑造”成复杂动作分布的过程。
详细可以看:流匹配动作生成
https://blog.csdn.net/v_JULY_v/article/details/136318383
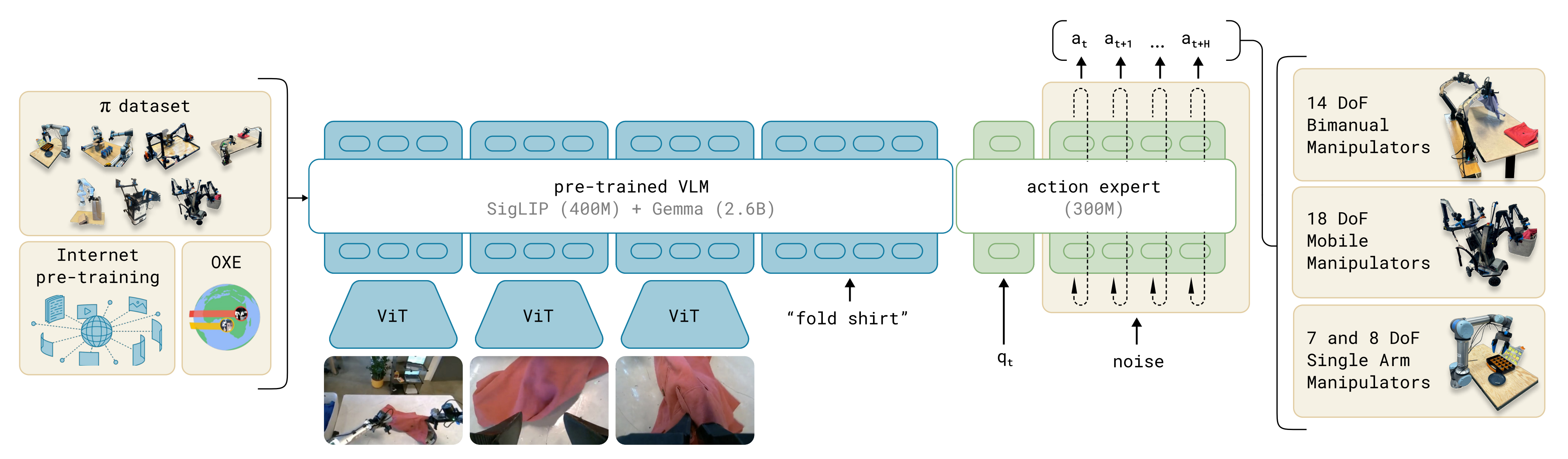
模型
基础模型大小 2.6B 使用pre-trained VLM;
470M视觉小模型,non-VLM
使用模型:paliGemma ( visoion siglip (400M)+Gemma(2.6B))模型*
语言: Gemma’s SentencePicece tokenizer
动作:
- 使用flow match和动作专家
- 50步动作分块
Transformer
- PaliGemma
- MOE 和分块因果注意力掩码
高层策略会将任务分解成子任务,使用高级视觉语言模型来进行这些语义推理
MOE
分块因果掩码的使用使得视觉语言模型(VLM)块只关注自身,本体感觉(与动作共享权重)也只关注自身。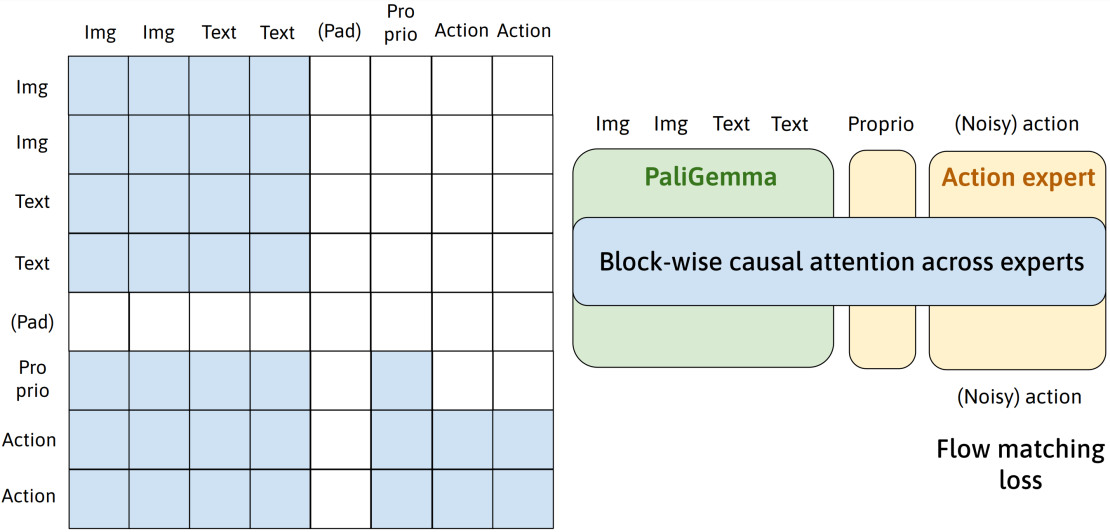
训练
VLM Pretraining
使用2.6B 预训练模型 Gemma
预训练
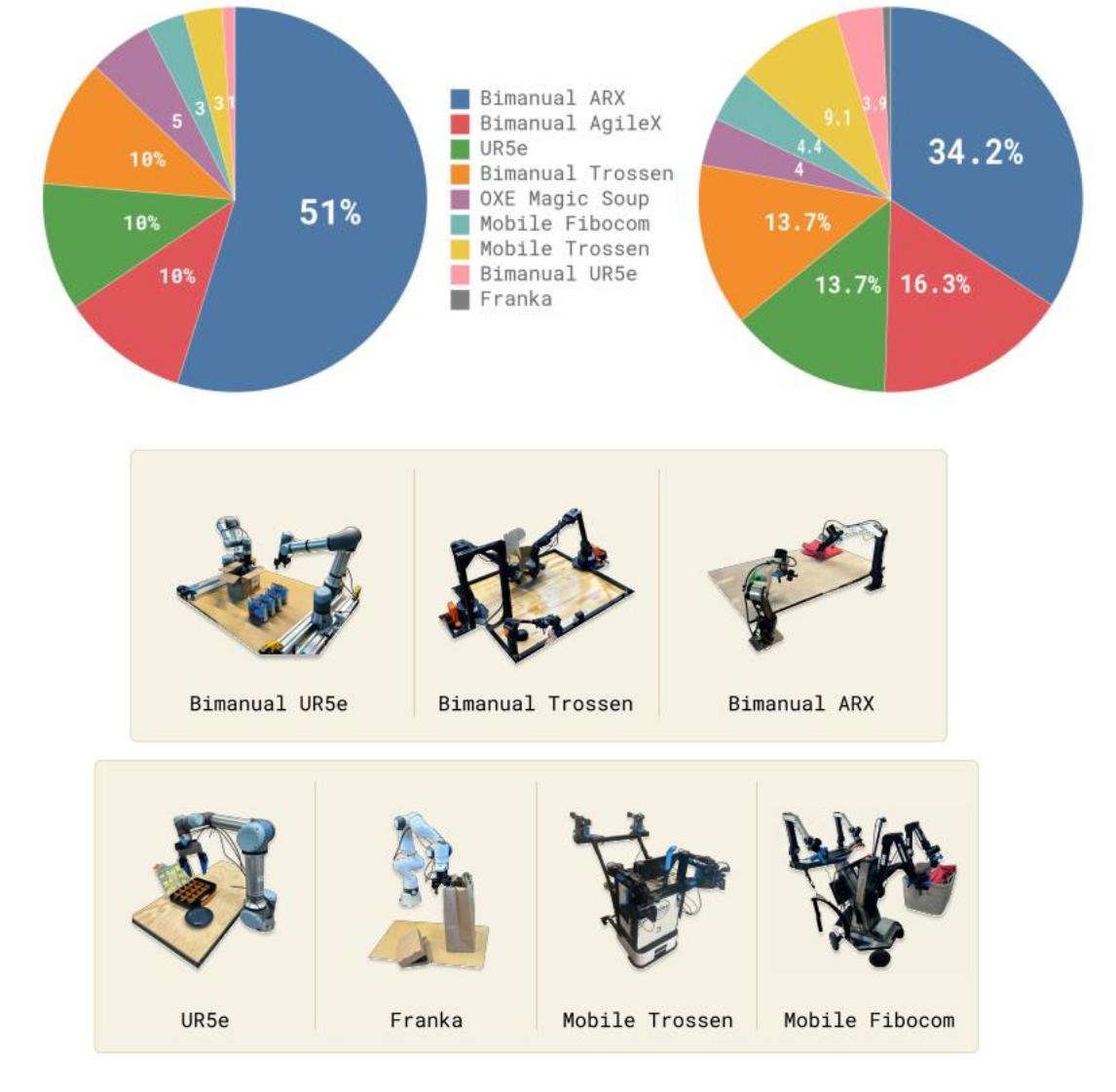
- 9.1% 包括Open-X modified 等开源数据集
- 来自私有数据集的 903M个时间步长的数据(1M=1000000)
• 其中 106M个来自单臂机器人
• 797M个来自双臂机器人
• 若频率为 10 赫兹,约相当于 25000 小时的数据 - 实际上是超过 10000 小时的数据
微调
针对不同的任务需要不同的数据集
- 对于简单任务 5小时数据
- 复杂的任务需要100小时甚至更多时长的数据集
推理
对于20HZ UR5和Franka机械臂,每0.8s推理一次,使用16个action
对于其他运行在50Hz的机械臂,运行0.5s推理 ,25个action
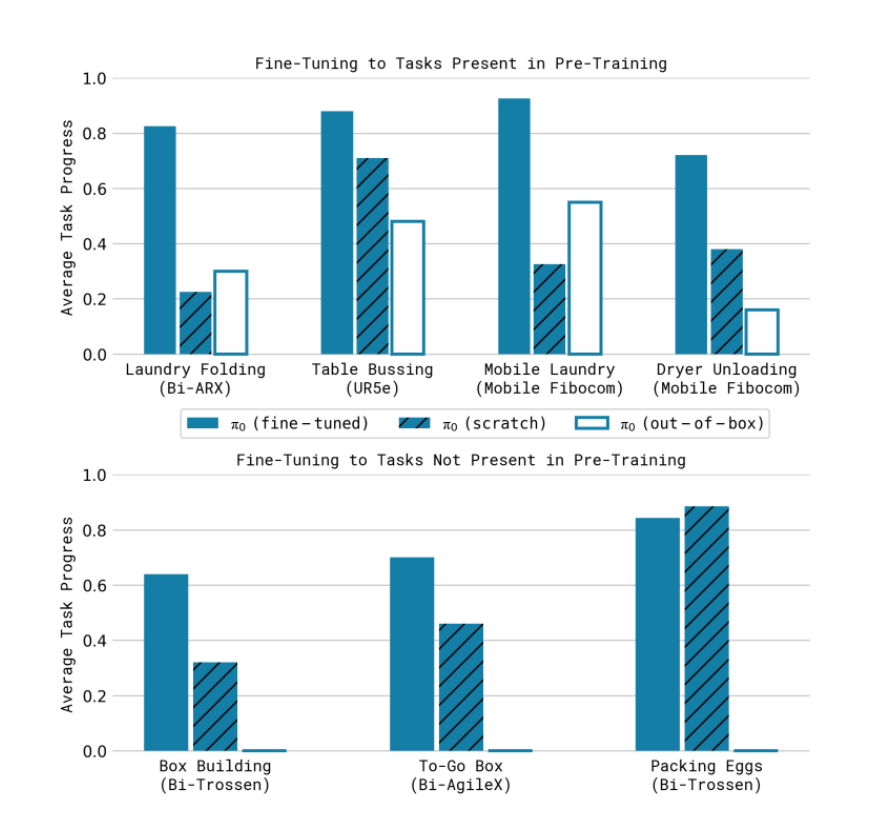
实验评价
和openvla和octo比较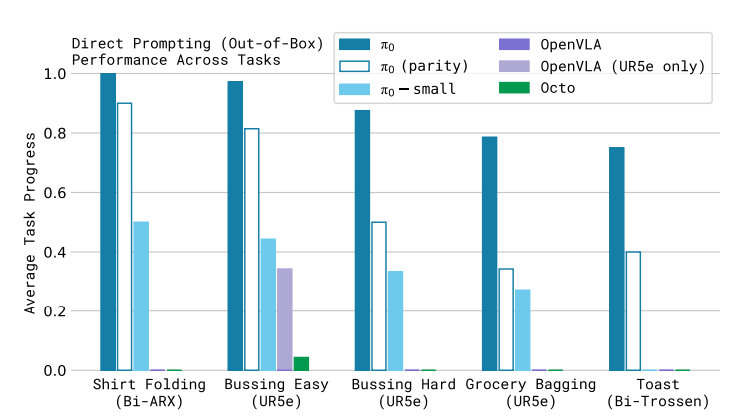
同openvla,octo ,act和DP在微调上的对比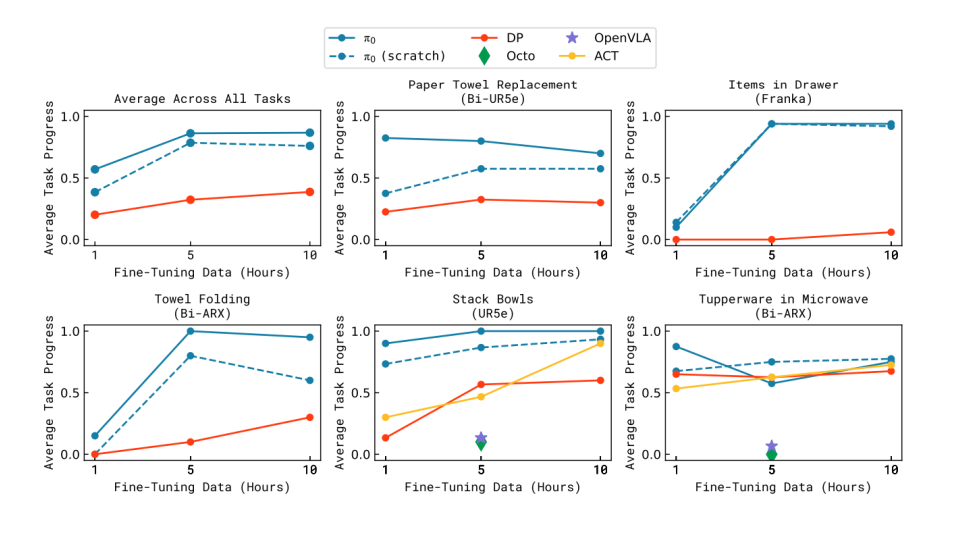
消融实验
pi0和 high-level saycan结合,通过任务分解,能够有效提升,但是对于pi0-small提升不大。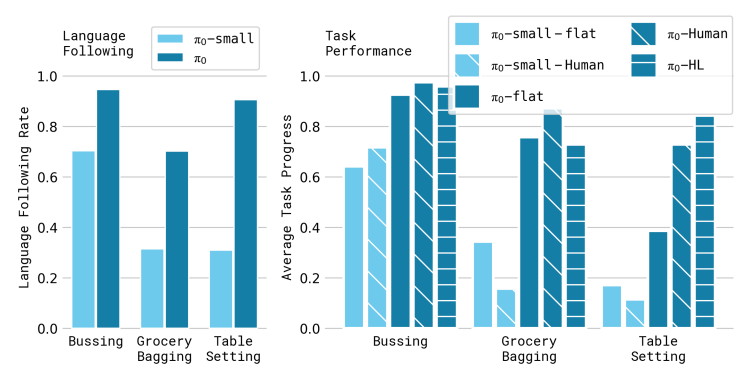
code
官方版本和pytorch版本,9月份的时候官方也开源了pytorch版本,可以看readme
https://github.com/Physical-Intelligence/openpi
https://github.com/allenzren/open-pi-zero
paliGemma如何做分块因果注意力:
自回归过程
代码模型
Summary
PI0 and RDT and OpenVLA
编码形式:Token–Transformer-decoder
Tokens(vision, text, low-dimension input)
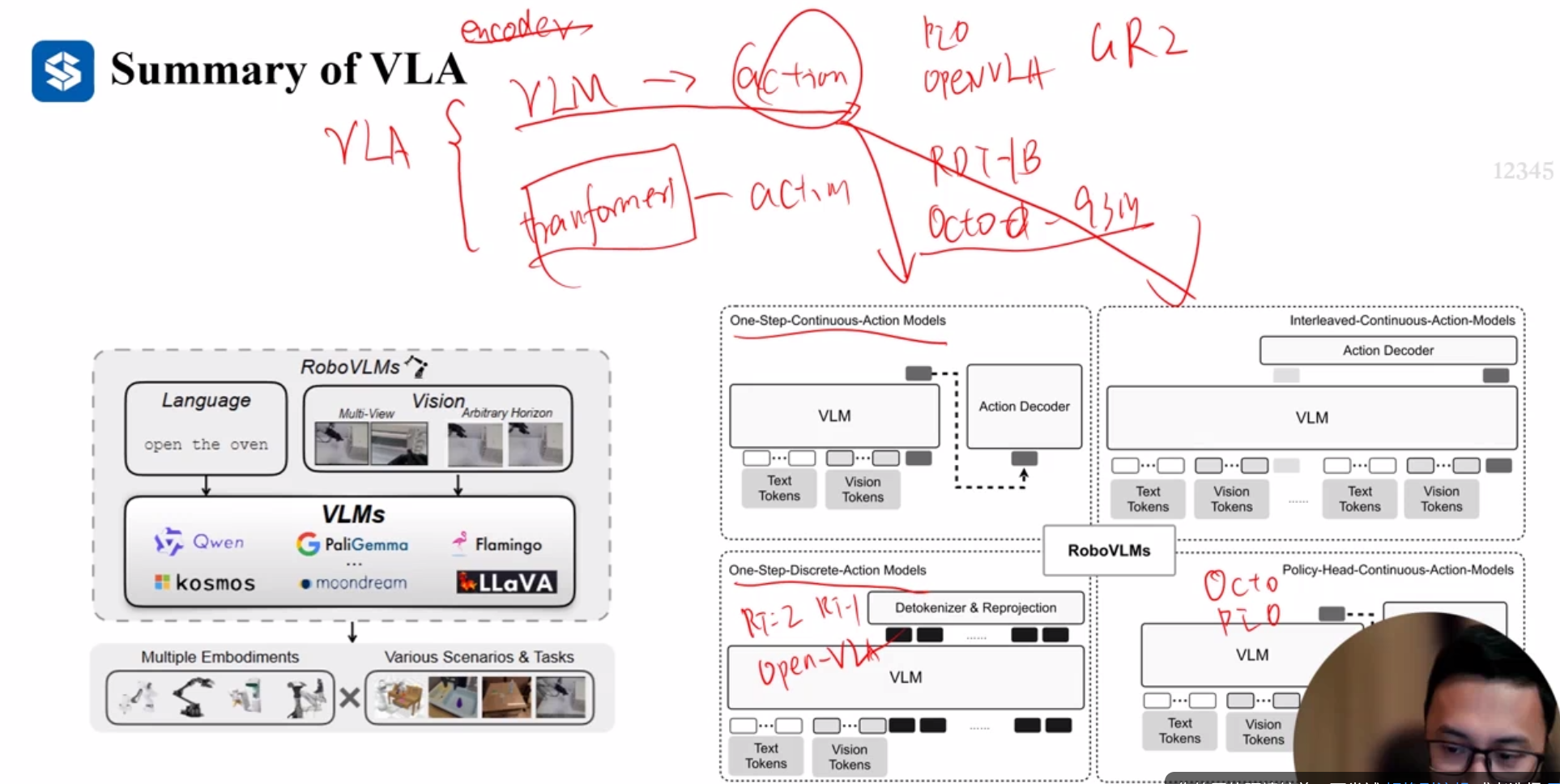
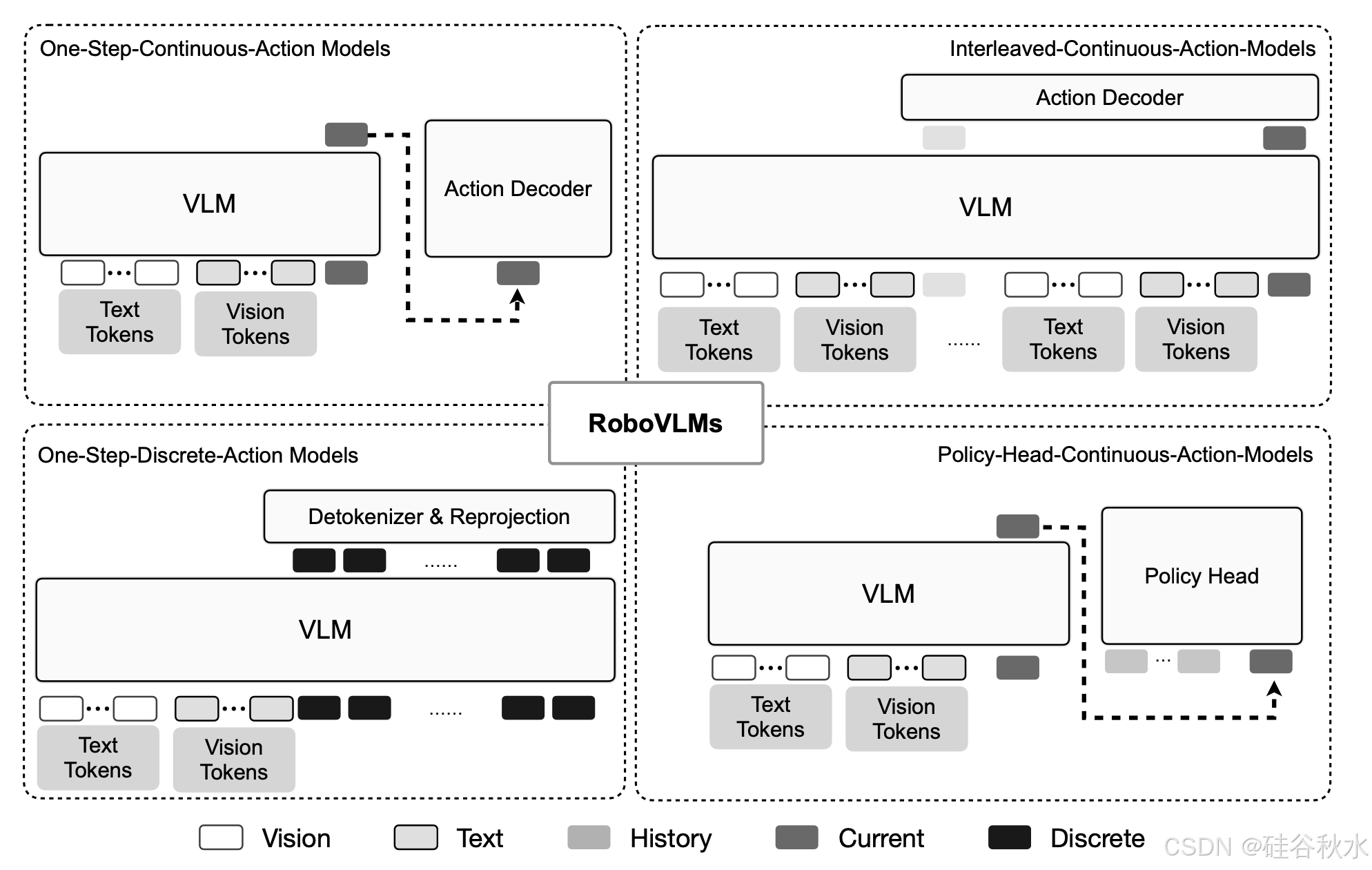
VLA(Vision-Language-Action)模型在动作生成方面主要采用四种核心范式,每种范式都有其独特的设计理念和技术特点:
- One-Step-Continuous-Action Models(一步连续动作模型)
核心思想:将Transformer生成的token通过多层感知器(MLP)直接映射为连续动作值。
技术特点:
- 采用L2或L1损失进行训练,对于二元输出使用二元交叉熵损失
- MLP解码器可以替换为LSTM整合时序上下文,或使用高斯混合模型(GMM)对动作空间随机性建模
- 非自回归变体通常采用池化操作将多个token压缩为单个动作表征
代表模型:OpenVLA-OFT等,研究表明L1损失可能带来更优的性能
- Interleaved-Continuous-Action-Models(交错连续动作模型)
核心思想:在VLM主干上并联或串联扩散模型作为动作生成插件,实现连续动作的平滑生成。
技术特点:
- 利用扩散模型直接对连续动作块进行建模,一次预测多个动作
- 减少累积误差并增强时序一致性
- 能够从相同的观察中产生多个有效的轨迹
代表模型:π₀引入流匹配模型,在原有VLM主干上并联参数充当去噪网络;DexVLA直接将扩散动作策略头串联在VLA主干之后
- One-Step-Discrete-Action-Models(一步离散动作模型)
核心思想:通过分箱(binning)将动作空间每个维度离散化为多个分箱,每个分箱ID被视为离散token。
技术特点:
- 最常用的动作表征方法,通常使用256个分箱
- 采用交叉熵损失进行训练,与LLMs类似的自回归解码方式
- 标准分箱方法的缺点是token长度增加,可能限制控制频率
代表模型:RT-2直接输出数值token作为动作;OpenVLA在词汇表中预留256个频率最低的token用于动作表征
- Policy-Head-Continuous-Action-Models(策略头连续动作模型)
核心思想:将动作生成视为条件去噪过程,通过扩散或流匹配技术生成连续动作。
技术特点:
- 以非自回归方式生成动作,实现更平滑且可扩展的控制
- 能够对不同的动作分布进行建模
- 几何感知方法将SE(3)约束嵌入到扩散中,扩展到欧几里德空间之外
代表模型:Octo和π₀等,这些模型已成为VLA中生成连续动作的主要方法
Finding in VLA Design

为什么需要 VLAs? 基于预训练VLMs构建的VLAs已被证明对于通用的机器人策略既有效又高效。此外,预训练的VLMs在泛化能力和数据效率方面表现出显著的优势,使其非常适合现实世界的机器人应用。
**哪个VLM骨干网络更适合VLAs?**对8个不同的VLM骨干研究显示,KosMos 和Paligemma ,其性能明显优于其他骨干。 这说明全面的视觉-语言预训练对于实现优越的VLA性能至关重要。
如何构建VLA
研究表明:连续点动作优于自回归离散动作,同时整合历史上下文对于提高性能和解决部分可观测性相当重要;
对于模型架构,直接与策略头集成的VLMs优于其他方案,为什么?视觉语言token以其原始的预训练格式进行处理,并添加策略头整合过去的视觉和本体感受观测结果,从而能够有效一致地进行决策。
何时应用跨机器人数据集?
使用跨机器人数据进行预训练并不能一致地带来最终性能的显著提升。
ref
Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
更多推荐
 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)