深度学习与K-means文本聚类算法毕业论文【附代码+数据】
(2)基于密度权重的改进Canopy算法 针对传统Canopy算法在确定最佳阈值T1和T2时的困难,以及这些阈值对聚类结果的影响,本研究提出了一种基于密度权重的改进Canopy算法。改进的Canopy算法能够更准确地识别出数据中的密集区域,为K-means算法提供了更好的初始聚类中心,从而提高了聚类效果,解决了人为确定k值和随机选取初始聚类中心的问题。(3)融合深度学习与改进K-means的文本聚

✅博主简介:本人擅长建模仿真、数据分析、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。
(1)基于句向量的深度学习特征提取模型 为了克服传统文本特征提取方法的局限性,本研究提出了一种基于句向量的改进卷积神经网络特征提取模型。该模型首先通过训练Doc2vec模型,将文本中的单词转换为向量矩阵的形式,从而捕捉文本中的语义信息。然后,利用卷积神经网络(CNN)对这些向量矩阵进行深度学习,提取出维数较低但富含语义信息的文本特征向量。这些特征向量作为后续聚类算法的输入,能够有效地表达文本数据的语义内容,为聚类分析提供了更为准确的特征表示。
(2)基于密度权重的改进Canopy算法 针对传统Canopy算法在确定最佳阈值T1和T2时的困难,以及这些阈值对聚类结果的影响,本研究提出了一种基于密度权重的改进Canopy算法。该算法通过引入密度权重的概念,来确定所有初始聚类中心,取代了原有的简单划分方法。改进的Canopy算法能够更准确地识别出数据中的密集区域,为K-means算法提供了更好的初始聚类中心,从而提高了聚类效果,解决了人为确定k值和随机选取初始聚类中心的问题。
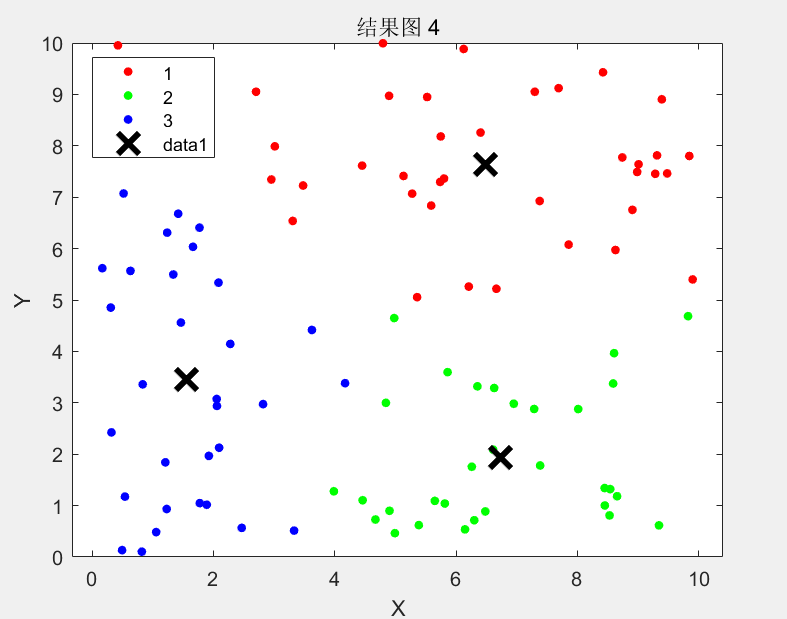
(3)融合深度学习与改进K-means的文本聚类算法 将上述提出的文本特征提取模型与改进的K-means算法相结合,形成了一套完整的文本聚类解决方案。本研究将这一改进的文本聚类算法应用于微博舆情分析,使用真实的微博数据集进行实验验证。通过常用的评价指标对聚类结果进行评估,实验结果证明了所提出改进文本聚类算法在微博舆情分析方面的有效性。该算法不仅提高了聚类的准确性,还增强了对噪声和异常数据的鲁棒性。
% 使用Doc2vec模型将文本转换为向量矩阵
docVectors = doc2vecTransform(documents);
% 使用CNN进行深度学习,提取文本特征
textFeatures = cnnFeatureExtraction(docVectors);
% 使用改进的Canopy算法确定初始聚类中心
[canopyCenters, canopyBounds] = improvedCanopy(textFeatures);
% 使用改进的K-means算法进行聚类
k = 5; % 假设聚类数目为5
[idx, C] = improvedKmeans(textFeatures, k, canopyCenters);
% 可视化聚类结果
visualizeClustering(textFeatures, idx);
% Doc2vec转换函数
function docVectors = doc2vecTransform(documents)
% ... 实现Doc2vec模型训练和转换逻辑 ...
end
% CNN特征提取函数
function textFeatures = cnnFeatureExtraction(docVectors)
% ... 实现CNN模型训练和特征提取逻辑 ...
end
% 改进的Canopy算法函数
function [centers, bounds] = improvedCanopy(textFeatures)
% ... 实现改进的Canopy算法逻辑 ...
end
% 改进的K-means算法函数
function [idx, C] = improvedKmeans(textFeatures, k, centers)
% ... 实现改进的K-means算法逻辑 ...
end
% 聚类结果可视化函数
function visualizeClustering(features, idx)
% ... 实现聚类结果可视化逻辑 ...
end

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 4
4 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)