
科普文:K8S中常见知识点梳理
比如,可以指定一个 Pod 只能被调度到与指定节点具有相同标签的节点上,或者指定一个 Pod 不能被调度到与指定节点具有相同标签的节点上。在这种方式下,Kubernetes 会根据当前节点的资源使用情况,将 Pod 动态地调度到具有可用资源的节点上,从而实现资源的最优分配。通过为节点打上不同的标签,可以让 Kubernetes 将特定类型的 Pod 调度到具有相应标签的节点上。集群自动伸缩(Clu
简单说一下k8s集群内外网络如何互通的
要在 Kubernetes(k8s)集群内外建立网络互通,可以采取以下措施:
-
使用service: 使用Service类型为NodePort或LoadBalancer的Kubernetes服务。这可以使服务具有一个公共IP地址或端口,以便在集群内或外部访问该服务。
-
使用Ingress: 配置Kubernetes Ingress资源。Ingress是一种路由机制,它将外部流量路由到Kubernetes集群中的特定服务。可以使用Ingress控制器来实现负载均衡和SSL终止。
-
创建网络策略 : Kubernetes网络策略允许您定义哪些Pod可以与哪些其他Pod通信,以及在什么端口上进行通信。
-
使用DNS: 将集群内的服务和Pod绑定到一个公共IP地址或域名。可以使用DNS记录来实现这一点,例如在Kubernetes中使用外部DNS插件。
-
配置网络代理 : 网络代理是一种可选的解决方案,它可以帮助在Kubernetes集群内外之间建立网络互通。可以使用Ingress控制器或使用第三方代理解决方案,如NGINX或HAProxy。
描述下Pod的创建过程
描述一:
-
定义Pod:首先,需要定义一个Pod的配置文件,它描述了要创建的Pod的特征,例如Pod名称、容器映像、容器端口等。
-
发送Pod配置文件:将Pod配置文件发送到Kubernetes集群中的API服务器。可以使用kubectl命令行工具或API客户端向API服务器发送配置文件。
-
调度器分配节点:Kubernetes调度器将Pod分配给一个节点。调度器考虑节点资源的可用性、Pod的资源需求以及其他调度策略来做出决策。
-
容器创建:一旦Pod被调度到节点上,kubelet代理将创建Pod中定义的每个容器,并使用相应的容器映像来填充它们。
-
分配IP地址:Kubernetes分配一个IP地址给Pod,并将其添加到集群的网络中,以便其他Pod可以与其通信。
-
启动容器:一旦Pod中的所有容器都已创建并分配IP地址,kubelet将启动每个容器,并开始在其内部运行应用程序。
-
容器监控:Kubernetes会持续监控Pod中的每个容器,并在出现故障或崩溃时重新启动它们。
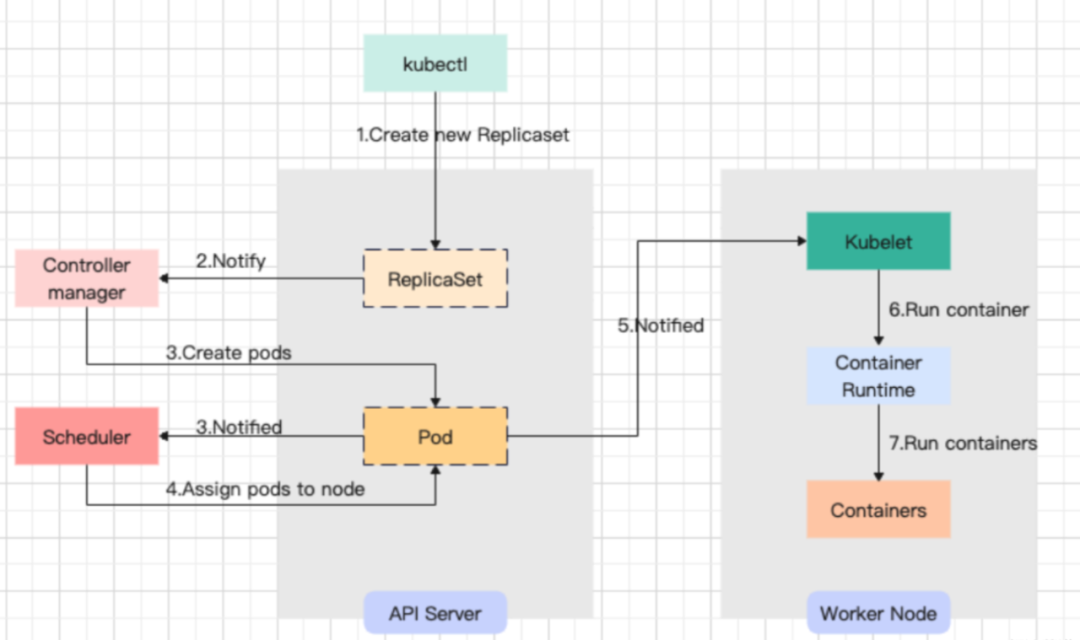
描述二:
-
Pod 的创建流程 kubectl向API Server发送创建请求ReplicaSet,API Server请求存储在etcd Controller Manager接受到通知
-
Controller Manager通知到
-
Scheduler Scheduler通知Worker节点
-
API Server通知到Worker节点的kubelet
-
kubelet指示当前节点上的Container Runtime运行对应的容器
-
Container Runtime下载镜像并启动容器
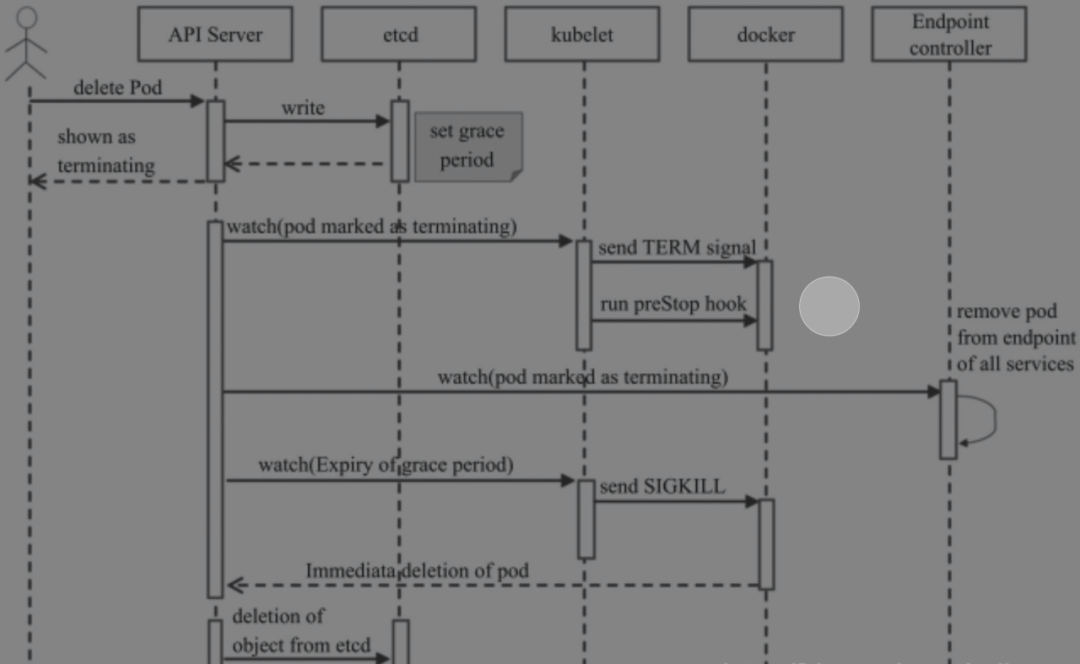
k8s中Pod的终止过程
在 Kubernetes 中,一个 Pod 由一个或多个容器组成,因此 Pod 的终止过程实际上涉及到容器的终止以及 Pod 对应的资源的释放等多个方面。
当 Kubernetes 接收到一个 Pod 的终止请求时,它将执行以下步骤:
-
从 Service 中删除 Pod:如果 Pod 正在 Service 中被使用,Kubernetes 会将其从 Service 中删除,以确保不再将流量发送到该 Pod。
-
关闭容器:Kubernetes 向 Pod 中的每个容器发送一个终止请求,容器将开始执行关闭的预定义步骤。这些步骤包括停止正在运行的进程、关闭网络连接、清理文件系统等等。
-
发送 SIGTERM 信号:当 Kubernetes 接收到终止 Pod 的请求时,它将首先向容器发送 SIGTERM 信号,让容器开始优雅地终止。这个信号的作用是告诉容器它需要开始终止了,但是需要等待一定的时间来完成正在运行的任务和释放资源。
-
等待容器终止:Kubernetes 将等待容器在接收到 SIGTERM 信号后完成优雅终止。在这个等待期间,Kubernetes 将不再向 Pod 中发送新的请求,但它仍会监控 Pod 的状态。
-
发送 SIGKILL 信号:如果容器没有在一定的时间内完成优雅终止,Kubernetes 将发送 SIGKILL 信号给容器,强制终止容器并释放其资源。
-
清理资源:Kubernetes 将释放 Pod 使用的所有资源,包括节点上的网络、存储、内存等。同时,Kubernetes 还将更新其状态,以便管理员和其他应用程序可以获取到最新的 Pod 信息。
总的来说,Kubernetes Pod 的终止过程包括了多个步骤,以确保容器能够安全、快速地释放资源,同时不会丢失任何数据或产生其他的副作用。
k8s中的自动伸缩有哪些方式
kubernetes中的自动伸缩主要有以下几种方式:
-
水平自动伸缩(Horizontal Pod Autoscaler,HPA):根据 CPU 利用率、内存利用率等指标,动态地增加或减少 Pod 的数量,以满足应用的负载需求。HPA 是 Kubernetes 中最常用的自动伸缩方式之一。
-
垂直自动伸缩(Vertical Pod Autoscaler,VPA):根据容器内部资源使用情况,动态地调整容器的 CPU 和内存资源请求量。VPA 可以优化容器的资源利用率,提高应用的性能和可靠性。
-
集群自动伸缩(Cluster Autoscaler):根据集群节点的资源利用率,动态地增加或减少节点的数量,以适应不同的负载需求。集群自动伸缩可以自动扩容或缩容集群,确保应用的高可用性和可靠性。
-
自定义指标自动伸缩(Custom Metrics Autoscaler,CA):根据自定义指标,动态地增加或减少 Pod 的数量。CA 可以根据应用的特殊需求,灵活地定制自动伸缩策略,提高应用的性能和可靠性。
总的来说,Kubernetes 提供了多种自动伸缩方式,可以根据应用的特点和需求选择合适的自动伸缩方式,以提高应用的性能、可靠性和可扩展性。
无论使用哪种自动伸缩方法,Kubernetes 都会根据应用程序的需求自动调整 Pod 的数量和资源限制,以确保应用程序始终具有足够的资源,并且可以根据需要扩展或缩减。
k8s中的故障检测有哪些方式
Kubernetes 中的探针是一种用于检查应用程序状态的机制。
探针可以检查应用程序的运行状况、存活性和就绪状态,并在需要时自动修复任何问题。
探针可以使用三种类型:readiness(就绪状态)、liveness(存活性)、startup(启动时)
Kubernetes 中的故障检测方式包括以下几种:
-
Liveness Probe(存活探针):用于检测容器是否处于正常运行状态。如果存活探针检测到容器内部的应用程序出现故障,Kubernetes 将会自动重启该容器。存活探针设置方式,可以使用 HTTP 请求、TCP 连接或命令执行来设置。
-
Readiness Probe(就绪探针):用于检测容器是否准备好接收流量。如果就绪探针检测到容器没有准备好,Kubernetes 将不会将流量路由到该容器。可以使用 HTTP 请求、TCP 连接或命令执行来设置就绪探针。
-
Startup Probe(启动探针):用于检测容器是否已经成功启动。如果启动探针检测到容器启动失败,Kubernetes 将会尝试重新启动该容器。与存活探针和就绪探针不同,启动探针只在容器启动时运行一次,然后就不再运行了。
-
Node Health Check(节点健康检查):用于检测节点的状态。如果节点出现故障,Kubernetes 将会将该节点上的所有容器转移到其他节点上。可以使用 kubeadm 自带的 kubeadm node 命令或 kubelet 的 --healthz 选项来设置节点健康检查。
-
Cluster Health Check(集群健康检查):用于检测整个集群的状态。可以使用 kubeadm 自带的 kubeadm check 命令或 kubelet 的 --healthz 选项来设置集群健康检查。此外,还可以使用 Kubernetes 官方提供的 kubeadm-diagnostics 工具来进行集群诊断。
k8s中的资源调度有哪些方式
Kubernetes 中的资源调度主要有以下几种方式:
-
基于 CPU 和内存资源的静态调度:在 Kubernetes 中,可以为每个 Pod 指定需要使用的 CPU 和内存资源。基于这些资源的需求,Kubernetes 会自动将 Pod 调度到具有足够资源的节点上。这种方式称为静态调度,因为资源需求是在 Pod 创建时指定的,而不会随着时间的推移而变化。
-
基于 CPU 和内存资源的动态调度:除了静态调度外,Kubernetes 还支持基于 CPU 和内存资源的动态调度。在这种方式下,Kubernetes 会根据当前节点的资源使用情况,将 Pod 动态地调度到具有可用资源的节点上,从而实现资源的最优分配。
-
基于节点标签的调度:Kubernetes 还支持基于节点标签的调度。通过为节点打上不同的标签,可以让 Kubernetes 将特定类型的 Pod 调度到具有相应标签的节点上。这种方式非常适合需要将不同类型的应用程序隔离开的场景。
-
基于节点亲和性和反亲和性的调度:在 Kubernetes 中,可以通过指定节点亲和性和反亲和性规则,来控制 Pod 被调度到哪些节点上。比如,可以指定一个 Pod 只能被调度到与指定节点具有相同标签的节点上,或者指定一个 Pod 不能被调度到与指定节点具有相同标签的节点上。
-
基于调度器插件的调度:Kubernetes 允许用户编写自己的调度器插件,并将其添加到 Kubernetes 集群中。通过使用这种方式,用户可以实现定制化的调度策略,以满足特定的需求。
k8s中的控制器(Controller)如何工作的
Kubernetes的控制器(Controller)是一种用于管理Kubernetes资源的控制器模式。
它确保系统处于期望的状态,通过周期性地监视系统状态,然后采取必要的操作使其达到期望状态。
控制器负责监控Kubernetes资源对象的状态,并确保资源对象的实际状态与期望状态匹配。
控制器的工作原理如下:
-
定义期望状态:控制器定义资源对象的期望状态,例如Pod应该运行在哪个节点上,有哪些容器以及运行的命令。
-
监控实际状态:控制器周期性地监视系统状态,通过 API Server 获取资源对象的实际状态,并与期望状态进行比较。
-
执行调谐操作:如果实际状态与期望状态不匹配,则控制器执行必要的操作来将系统状态调整为期望状态。例如,如果Pod未在期望节点上运行,则控制器会调度Pod到正确的节点上。
-
重复以上步骤:控制器持续监视系统状态,并根据需要执行调谐操作,直到实际状态与期望状态匹配为止。
Kubernetes提供了许多内置的控制器,如Deployment、ReplicaSet和StatefulSet,它们分别用于管理不同类型的应用程序和资源对象。
此外,用户还可以编写自定义控制器来管理自定义资源对象。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)