使用k8s部署日志收集分析 EFK elasticsearch+kibana+fulentd
在现代 DevOps 实践中,日志管理和分析变得至关重要。尤其是在使用 Kubernetes 的动态环境中,分布式系统生成的日志数量庞大且复杂,传统的日志管理方式难以胜任。EFK 堆栈——由 Elasticsearch、Fluentd 和 Kibana 组成的强大组合,提供了一种高效的日志处理和可视化解决方案。Elasticsearch 作为一种分布式搜索和分析引擎,能够快速存储、搜索和分析海量数
在现代 DevOps 实践中,日志管理和分析变得至关重要。尤其是在使用 Kubernetes 的动态环境中,分布式系统生成的日志数量庞大且复杂,传统的日志管理方式难以胜任。EFK 堆栈——由 Elasticsearch、Fluentd 和 Kibana 组成的强大组合,提供了一种高效的日志处理和可视化解决方案。
Elasticsearch 作为一种分布式搜索和分析引擎,能够快速存储、搜索和分析海量数据;Fluentd 是一个开源的数据收集器,用于统一记录、过滤和传输日志数据;而 Kibana 则提供了一个强大的用户界面,允许用户可视化和分析存储在 Elasticsearch 中的数据。这三者协同工作,可以帮助开发和运维团队轻松地收集、处理和可视化 Kubernetes 集群中的日志信息,从而提高系统的可观测性和故障诊断效率。
本篇文章将详细介绍如何在 Kubernetes 环境中部署和配置 EFK 堆栈,帮助您构建一个高效、可靠的日志管理系统。通过实际案例和步骤演示,您将学会如何使用 EFK 堆栈实现日志的集中收集、存储和可视化,从而提升应用程序的运维能力。
版本依赖关系
https://www.elastic.co/cn/support/matrix#matrix_compatibility
创建命名空间
编写资源清单文件
apiVersion: v1
kind: Namespace
metadata:
name: log-efk
更新资源清单文件
kubectl apply -f namespace.yaml
查看命名空间
kubectl get ns
结果:
NAME STATUS AGE
default Active 30d
kube-flannel Active 30d
kube-node-lease Active 30d
kube-public Active 30d
kube-system Active 30d
log-efk Active 3s
创建 StorageClass 实现自动创建PV与PVC
编写资源清单文件
storageclass.yaml
# 创建用户ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: elasticsearch-storageclass-sa
namespace: log-efk
---
# 创建ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: elasticsearch-storageclass-clusterrole
namespace: log-efk
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "delete"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
- apiGroups: ["extensions"]
resources: ["podsecuritypolicies"]
verbs: ["use"]
# 用于指定资源名称
resourceNames: ["elasticsearch-storageclass-deployment-nfs-provisioner"]
---
# 创建ClusterRoleBinding绑定ClusterRole和ServiceAccount
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: elasticsearch-storageclass-clusterrolebinding
namespace: log-efk
# 用于指定的ServiceAccount
subjects:
- kind: ServiceAccount
name: elasticsearch-storageclass-sa
namespace: log-efk
# 用于指定要绑定的 ClusterRole
roleRef:
kind: ClusterRole
name: elasticsearch-storageclass-clusterrole
apiGroup: rbac.authorization.k8s.io
---
# 创建NFS供应商Pod
apiVersion: apps/v1
kind: Deployment
metadata:
# Deployment的名称
name: elasticsearch-storageclass-deployment-nfs-provisioner
# Deployment的命名空间
namespace: log-efk
spec:
selector:
# 标签选择器
matchLabels:
# 管理Pod的标签-与下方模板中的标签对应
app: elasticsearch-storageclass-nfs-provisioner
# 副本数量
replicas: 1
strategy:
type: Recreate
template:
metadata:
# Pod的标签
labels:
app: elasticsearch-storageclass-nfs-provisioner
spec:
# 服务账号,使用上方创建的ServiceAccount,因为需要对PV进行操作,所以不能使用默认的ServiceAccount
serviceAccountName: elasticsearch-storageclass-sa
# 容器
containers:
- name: elasticsearch-storageclass-nfs-provisioner
image: k8s.gcr.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
# 镜像拉取策略
imagePullPolicy: IfNotPresent
# 环境变量
env:
- name: PROVISIONER_NAME
# 供应商的名称,需要于StorageClass中的provisioner的值一致
value: elasticsearch-storageclass-nfs-provisioner
- name: NFS_SERVER
# NFS 服务器的主机名或 IP 地址
value: 198.19.249.80
- name: NFS_PATH
# NFS 服务器导出的路径
value: /data/nfs_pro
# 容器的卷挂载
volumeMounts:
# 挂载到容器内部的目录
- mountPath: /persistentvolumes
# 卷的名称
name: nfs-client-root
# 容器的卷
volumes:
# 卷的名称。必须是 DNS_LABEL 并且在 Pod 内是唯一的
- name: nfs-client-root
nfs:
# 服务器是 NFS 服务器的主机名或 IP 地址
server: 198.19.249.80
# NFS 服务器导出的路径
path: /data/nfs_pro
---
# 创建StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
# StorageClass的名称,使用类型为StorageClass的卷时,需要指定StorageClass的名称
name: elasticsearch-storageclass
namespace: log-efk
# provisioner 是供应商的名称,需要与NFS供应商Pod中的PROVISIONER_NAME的值一致
provisioner: elasticsearch-storageclass-nfs-provisioner
逐段分析
-
创建用户绑定权限
创建用户绑定权限
创建用户ServiceAccount
apiVersion: v1 kind: ServiceAccount metadata: name: elasticsearch-storageclass-sa namespace: log-efk创建角色ClusterRole
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: elasticsearch-storageclass-clusterrole namespace: log-efk rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "delete"] - apiGroups: [""] resources: ["nodes"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] - apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] - apiGroups: [""] resources: ["events"] verbs: ["create", "update", "patch"] - apiGroups: ["extensions"] resources: ["podsecuritypolicies"] verbs: ["use"] # 用于指定资源名称 resourceNames: ["elasticsearch-storageclass-deployment-nfs-provisioner"]权限说明
-
对
endpoints资源的权限:- apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "delete"]- apiGroups:
[""]表示核心 API 组。 - resources:
["endpoints"]指定资源类型为 Endpoints。 - verbs:
["get", "list", "watch", "create", "update", "delete"]表示允许执行读取(get、list、watch)、创建、更新和删除操作。
- apiGroups:
-
对
nodes资源的权限:- apiGroups: [""] resources: ["nodes"] verbs: ["get", "list", "watch"]- apiGroups:
[""]表示核心 API 组。 - resources:
["nodes"]指定资源类型为 Nodes。 - verbs:
["get", "list", "watch"]表示允许执行读取操作。
- apiGroups:
-
对
persistentvolumes资源的权限:- apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"]- apiGroups:
[""]表示核心 API 组。 - resources:
["persistentvolumes"]指定资源类型为 PersistentVolumes。 - verbs:
["get", "list", "watch", "create", "delete"]表示允许执行读取、创建和删除操作。
- apiGroups:
-
对
persistentvolumeclaims资源的权限:- apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"]- apiGroups:
[""]表示核心 API 组。 - resources:
["persistentvolumeclaims"]指定资源类型为 PersistentVolumeClaims。 - verbs:
["get", "list", "watch", "update"]表示允许执行读取和更新操作。
- apiGroups:
-
对
storageclasses资源的权限:- apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"]- apiGroups:
["storage.k8s.io"]表示存储 API 组。 - resources:
["storageclasses"]指定资源类型为 StorageClasses。 - verbs:
["get", "list", "watch"]表示允许执行读取操作。
- apiGroups:
-
对
events资源的权限:- apiGroups: [""] resources: ["events"] verbs: ["create", "update", "patch"]- apiGroups:
[""]表示核心 API 组。 - resources:
["events"]指定资源类型为 Events。 - verbs:
["create", "update", "patch"]表示允许执行创建、更新和部分更新(patch)操作。
- apiGroups:
-
对
podsecuritypolicies资源的权限:- apiGroups: ["extensions"] resources: ["podsecuritypolicies"] verbs: ["use"] resourceNames: ["elasticsearch-storageclass-deployment-nfs-provisioner"]- apiGroups:
["extensions"]表示扩展 API 组。 - resources:
["podsecuritypolicies"]指定资源类型为 PodSecurityPolicies。 - verbs:
["use"]表示允许使用指定的 PodSecurityPolicy。 - resourceNames:
["elasticsearch-storageclass-deployment-nfs-provisioner"]限制只能使用名为elasticsearch-storageclass-deployment-nfs-provisioner的 PodSecurityPolicy。
- apiGroups:
创建ClusterRoleBinding绑定ClusterRole和ServiceAccount
# 创建ClusterRoleBinding绑定ClusterRole和ServiceAccount apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: elasticsearch-storageclass-clusterrolebinding namespace: log-efk # 用于指定的ServiceAccount subjects: - kind: ServiceAccount name: elasticsearch-storageclass-sa namespace: log-efk # 用于指定要绑定的 ClusterRole roleRef: kind: ClusterRole name: elasticsearch-storageclass-clusterrole apiGroup: rbac.authorization.k8s.io创建用户 创建角色,将用户与角色绑定,角色权限为 操作 pv和pvc的全部操作
-
-
创建NFS供应商驱动
创建NFS供应商驱动
创建nfs供应商驱动,可以通过驱动程序在NFS中自动的创建pv与pvc
# 创建NFS供应商Pod apiVersion: apps/v1 kind: Deployment metadata: # Deployment的名称 name: elasticsearch-storageclass-deployment-nfs-provisioner # Deployment的命名空间 namespace: log-efk spec: selector: # 标签选择器 matchLabels: # 管理Pod的标签-与下方模板中的标签对应 app: elasticsearch-storageclass-nfs-provisioner # 副本数量 replicas: 1 strategy: type: Recreate template: metadata: # Pod的标签 labels: app: elasticsearch-storageclass-nfs-provisioner spec: # 服务账号,使用上方创建的ServiceAccount,因为需要对PV进行操作,所以不能使用默认的ServiceAccount serviceAccountName: elasticsearch-storageclass-sa # 容器 containers: - name: elasticsearch-storageclass-nfs-provisioner image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0 # 镜像拉取策略 imagePullPolicy: IfNotPresent # 环境变量 env: - name: PROVISIONER_NAME # 供应商的名称,需要于StorageClass中的provisioner的值一致 value: elasticsearch-storageclass-nfs-provisioner - name: NFS_SERVER # NFS 服务器的主机名或 IP 地址 value: 198.19.249.80 - name: NFS_PATH # NFS 服务器导出的路径 value: /data/nfs_pro # 容器的卷挂载 volumeMounts: # 挂载到容器内部的目录 - mountPath: /persistentvolumes # 卷的名称 name: nfs-client-root # 容器的卷 volumes: # 卷的名称。必须是 DNS_LABEL 并且在 Pod 内是唯一的 - name: nfs-client-root nfs: # 服务器是 NFS 服务器的主机名或 IP 地址 server: 198.19.249.80 # NFS 服务器导出的路径 path: /data/nfs_pro主意事项
- 创建NFS驱动程序,使用的是 上方创建的名称为 elasticsearch-storageclass-sa 的用户,用户绑定了 操作PV和PVC的全部角色权限,因为需要对PV和PVC进行操作,所以不能使用默认的ServiceAccount
- 环境变量中的 PROVISIONER_NAME 供应商名称,需要与下方的StorageClass中的provisioner的值一致
-
创建StorageClass 绑定NFS驱动程序
创建StorageClass 绑定NFS驱动程序
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: # StorageClass的名称,使用类型为StorageClass的卷时,需要指定StorageClass的名称 name: elasticsearch-storageclass namespace: log-efk # provisioner 是供应商的名称,需要与NFS供应商Pod中的PROVISIONER_NAME的值一致 provisioner: elasticsearch-storageclass-nfs-provisioner主意:
创建StorageClass,provisioner供应商名称需要与NFS供应商Pod中的PROVISIONER_NAME的值一致
更新资源清单文件
kubectl apply -f storageclass.yaml
查看Pod状态
kubectl get pods -n log-efk
结果:
NAME READY STATUS RESTARTS AGE
elasticsearch-storageclass-deployment-nfs-provisioner-548f8mhgn 1/1 Running 0 3m34s
创建elasticsearch
编写资源清单文件
elasticsearch.yaml
# 创建service服务 创建一个Headless Service,这样可以通过DNS直接访问到Pod
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-service
# 命名空间
namespace: log-efk
spec:
# 标签选择器,要代理的Pod,要与下文的模板中的标签匹配
selector:
app: elasticsearch
# 服务的IP地址
clusterIP: None
ports:
- port: 9200
# 目标 Pod 上要访问的端口号或名称
name: rest
- port: 9300
# 目标 Pod 上要访问的端口号或名称
name: inter-node
---
# 编写 elasticsearch集群,创建一个StatefulSet,一个有标识的Pod集合,可以保证Pod的唯一性
kind: StatefulSet
apiVersion: apps/v1
metadata:
name: elasticsearch
namespace: log-efk
labels:
app: elasticsearch
spec:
# StatefulSet 的服务的名称 负责该集的网络标识,需要与上文的service的名称一致
serviceName: elasticsearch-service
# 副本数量
replicas: 3
selector:
# 标签选择器,要管理的Pod,要与下文的模板中的标签匹配
matchLabels:
app: elasticsearch
template:
metadata:
# Pod的标签
labels:
app: elasticsearch
spec:
# 容器
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:8.13.3
imagePullPolicy: IfNotPresent
# 资源限制
resources:
# 允许的最大计算资源量
limits:
cpu: 1000m
memory: 2Gi
# 允许的最小计算资源量
requests:
cpu: 100m
memory: 1Gi
# 端口
ports:
- containerPort: 9200
# Pod 中的每个命名端口都必须具有唯一的名称。服务可以引用的端口名称
name: rest
- containerPort: 9300
# Pod 中的每个命名端口都必须具有唯一的名称。服务可以引用的端口名称
name: inter-node
# 挂载卷
volumeMounts:
- name: elasticsearch-volume
# 挂载路径
mountPath: /usr/share/elasticsearch/data
# 环境变量
env:
# 集群名称
- name: cluster.name
value: "elasticsearch"
# 节点名称
- name: node.name
# 选自上文 metadata.name 的值
valueFrom:
fieldRef:
fieldPath: metadata.name
# 发现种子主机
- name: discovery.seed_hosts
value: "elasticsearch-0.elasticsearch-service.log-efk.svc.cluster.local,elasticsearch-1.elasticsearch-service.log-efk.svc.cluster.local,elasticsearch-2.elasticsearch-service.log-efk.svc.cluster.local"
# 集群初始主节点
- name: cluster.initial_master_nodes
value: "elasticsearch-0,elasticsearch-1,elasticsearch-2"
# Java虚拟机参数
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
# 禁用xpack,关闭安全检查
- name: xpack.security.enabled
value: "false"
# 初始化容器
initContainers:
# 用于修改目录权限
- name: fix-permissions
image: docker.io/library/busybox
imagePullPolicy: IfNotPresent
# 执行的命令 修改目录权限
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
# 特权模式是否开启 true开启 false关闭
privileged: true
# 挂载卷
# 在初始化容器中的挂载卷会在主容器中也会挂载
volumeMounts:
- name: elasticsearch-volume
mountPath: /usr/share/elasticsearch/data
# 用于修改内核参数
- name: init-sysctl
image: docker.io/library/busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
# 用于修改文件描述符的数量
- name: increase-fd-ulimit
image: docker.io/library/busybox
imagePullPolicy: IfNotPresent
# 执行的命令 修改文件描述符的数量
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
# 卷
volumeClaimTemplates:
- metadata:
# 卷的名称
name: elasticsearch-volume
# 卷的规格
spec:
# 访问模式
accessModes: ["ReadWriteOnce"]
# 存储类
storageClassName: elasticsearch-storageclass
# 资源限制
resources:
requests:
storage: 10Gi
逐段分析
-
创建 Service
创建无头服务 Headless Service
# 创建service服务 创建一个Headless Service,这样可以通过DNS直接访问到Pod apiVersion: v1 kind: Service metadata: name: elasticsearch-service # 命名空间 namespace: log-efk spec: # 标签选择器,要代理的Pod,要与下文的模板中的标签匹配 selector: app: elasticsearch # 服务的IP地址 clusterIP: None ports: - port: 9200 # 目标 Pod 上要访问的端口号或名称 name: rest - port: 9300 # 目标 Pod 上要访问的端口号或名称 name: inter-node注意:
- StatefulSet中的serviceName需要与上方 Headless Service 的name保持一致,才可以正常通过DNS轮询访问
- 无头服务 通过 与 StatefulSet 配合 ,可以创建DNS访问,实现
<statefulset-name>-<ordinal>.<service-name>.<namespace>.svc.cluster.local
访问指定序号的Pod
也可以通过
<statefulset-serviceName>.<namespace>.svc.cluster.local
轮询访问Pod
-
创建 elasticsearch集群
定义基本Pod信息
# 编写 elasticsearch集群,创建一个StatefulSet,一个有标识的Pod集合,可以保证Pod的唯一性 kind: StatefulSet apiVersion: apps/v1 metadata: name: elasticsearch namespace: log-efk labels: app: elasticsearch spec: # StatefulSet 的服务的名称 负责该集的网络标识,需要与上文的service的名称一致 serviceName: elasticsearch-service # 副本数量 replicas: 3 selector: # 标签选择器,要管理的Pod,要与下文的模板中的标签匹配 matchLabels: app: elasticsearch template: metadata: # Pod的标签 labels: app: elasticsearch spec: # 容器 containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:8.13.3 imagePullPolicy: IfNotPresent # 资源限制 resources: # 允许的最大计算资源量 limits: cpu: 1000m memory: 2Gi # 允许的最小计算资源量 requests: cpu: 100m memory: 1Gi # 端口 ports: - containerPort: 9200 # Pod 中的每个命名端口都必须具有唯一的名称。服务可以引用的端口名称 name: rest - containerPort: 9300 # Pod 中的每个命名端口都必须具有唯一的名称。服务可以引用的端口名称 name: inter-node # 挂载卷 volumeMounts: - name: elasticsearch-volume # 挂载路径 mountPath: /usr/share/elasticsearch/data # 环境变量 env: # 集群名称 - name: cluster.name value: "elasticsearch" # 节点名称 - name: node.name # 选自上文 metadata.name 的值 valueFrom: fieldRef: fieldPath: metadata.name # 发现种子主机 - name: discovery.seed_hosts value: "elasticsearch-0.elasticsearch-service.log-efk.svc.cluster.local,elasticsearch-1.elasticsearch-service.log-efk.svc.cluster.local,elasticsearch-2.elasticsearch-service.log-efk.svc.cluster.local" # 集群初始主节点 - name: cluster.initial_master_nodes value: "elasticsearch-0,elasticsearch-1,elasticsearch-2" # Java虚拟机参数 - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m" # 禁用xpack,关闭安全检查 - name: xpack.security.enabled value: "false"定义了StatefulSet资源,一个有标识的Pod集合
-
暴露了两个端口号9200/9300,并定义了端口名称,端口名称在上方的service中有使用
-
定义了挂载卷,卷的名称与下方的volumeClaimTemplates的名称保持一致
-
定义了环境变量
-
定义集群的名称
-
定义了节点名称,节点引用上文的metadata.name
将解析为 es-cluster-[0,1,2],取决于节点的指定顺序。
-
定义引用集群的节点地址
discovery.seed_hosts:此字段用于设置在 Elasticsearch 集群中节点相互连接的发现方法,它为我们的集群指定了一个静态主机列表。由于我们之前配置的是无头服务,我们的 Pod 具有唯一的 DNS地址 elasticsearch-[0,1,2].elasticsearch-service.kube-logging.svc.cluster.local,因此我们相应地设置此地址变量即可。由于都在同一个 namespace 下面,所以我们可以将其缩短为 elasticsearch-[0,1,2].elasticsearch-service。
要了解有关 Elasticsearch 发现的更多信息,请参阅 Elasticsearch 官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html。 -
定义集群初始化的主节点
-
定义了java虚拟机参数
ES_JAVA_OPTS:这里我们设置为-Xms512m -Xmx512m,告诉 JVM 使用 512 MB 的最小和最大堆。这个值应该根据群集的资源可用性和需求调整这些参数。
要了解更多信息,请参阅设置堆大小的相关文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html。 -
禁用xpack,关闭安全检查
定义初始化容器
# 初始化容器 initContainers: # 用于修改目录权限 - name: fix-permissions image: docker.io/library/busybox imagePullPolicy: IfNotPresent # 执行的命令 修改目录权限 command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: # 特权模式是否开启 true开启 false关闭 privileged: true # 挂载卷 # 在初始化容器中的挂载卷会在主容器中也会挂载 volumeMounts: - name: elasticsearch-volume mountPath: /usr/share/elasticsearch/data # 用于修改内核参数 - name: init-sysctl image: docker.io/library/busybox imagePullPolicy: IfNotPresent command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true # 用于修改文件描述符的数量 - name: increase-fd-ulimit image: docker.io/library/busybox imagePullPolicy: IfNotPresent # 执行的命令 修改文件描述符的数量 command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true定义了几个主应用程序之前的运行的init容器,这些初始容器按照定义的顺序依次执行,执行完成后才会启动主应用容器。
-
修改目录权限
名为 fix-permissions 的容器用来运行 chown 命令,将 Elasticsearch 数据目录的用户和
组更改为 1000:1000(Elasticsearch 用户的 UID)。因为默认情况下,Kubernetes 用 root 用户挂载数据目录,这会使得 Elasticsearch 无法访问该数据目录,可以参考 Elasticsearch 生产中的一些默认注意事项相关文档说明:
https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#_notes_for_production_use_and_defaults -
修改内核参数
increase-vm-max-map 的容器用来增加操作系统对 mmap 计数的限制,默认情况下该值可能太低,导致内存不足的错误,要了解更多关于该设置的信息,可以查看 Elasticsearch 官方文档说明:https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html。
-
修改文件描述符的数量
最后一个初始化容器是用来执行 ulimit 命令增加打开文件描述符的最大数量的。
此外 Elastisearch Notes for Production Use 文档还提到了由于性能原因最好禁用 swap,对于 Kubernetes 集群而言,最好也是禁用 swap 分区的。
现在我们已经定义了主应用容器和它之前运行的 Init Containers 来调整一些必要的系统参数,接下来可以添加数据目录的持久化相关的配置。
定义容器卷的模板
# 卷 volumeClaimTemplates: - metadata: # 卷的名称 name: elasticsearch-volume # 卷的规格 spec: # 访问模式 accessModes: ["ReadWriteOnce"] # 存储类 storageClassName: elasticsearch-storageclass # 资源限制 resources: requests: storage: 10Gi我们这里使用 volumeClaimTemplates 来定义持久化模板,
- Kubernetes 会使用它为 Pod 创建PersistentVolume,设置访问模式为 ReadWriteOnce,这意味着它只能被 mount 到单个节点上进行读写,
- 使用了一个名为 elasticsearch-storageclass 的 StorageClass 对象,这里的storageClassName的名字就是上面创建动态存储类StorageClass的名称, 所以我们需要提前创建该对象,我们这里使用的 NFS 作为存储后端,所以需要安装一个对应的 nfs provisioner 驱动。
-
-
更新资源清单文件
kubectl apply -f elasticsearch.yaml
查看资源部署情况
查看Pod
kubectl get pods -n log-efk
结果:
NAME READY STATUS RESTARTS AGE
elasticsearch-0 1/1 Running 0 6m30s
elasticsearch-1 1/1 Running 0 6m26s
elasticsearch-2 1/1 Running 0 6m22s
elasticsearch-storageclass-deployment-nfs-provisioner-64d5c8qgb 1/1 Running 0 28m
查看Service
kubectl get svc
结果:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 31d
statefulset-service ClusterIP None <none> 80/TCP 12d
查看PV与PVC
-
pvc
kubectl get pvc -n log-efk结果:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE elasticsearch-volume-elasticsearch-0 Bound pvc-42cd36df-cc73-4cb9-bea6-c03931cfac90 10Gi RWO elasticsearch-storageclass <unset> 34m elasticsearch-volume-elasticsearch-1 Bound pvc-abc069d4-f39f-4396-9114-5d00f48a170c 10Gi RWO elasticsearch-storageclass <unset> 34m elasticsearch-volume-elasticsearch-2 Bound pvc-0fa0b7a9-660d-4b57-8318-0609a143b743 10Gi RWO elasticsearch-storageclass <unset> 34m -
pv
kubectl get pv -n log-efk结果:
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE pvc-0fa0b7a9-660d-4b57-8318-0609a143b743 10Gi RWO Delete Bound log-efk/elasticsearch-volume-elasticsearch-2 elasticsearch-storageclass <unset> 34m pvc-42cd36df-cc73-4cb9-bea6-c03931cfac90 10Gi RWO Delete Bound log-efk/elasticsearch-volume-elasticsearch-0 elasticsearch-storageclass <unset> 35m pvc-abc069d4-f39f-4396-9114-5d00f48a170c 10Gi RWO Delete Bound log-efk/elasticsearch-volume-elasticsearch-1 elasticsearch-storageclass <unset> 34m
校验elasticsearch接口是否可以使用
开放临时端口转发
kubectl port-forward elasticsearch-0 9200:9200 -n log-efk
访问测试
curl http://localhost:9200/_cluster/state?pretty
结果:
},
"routing_table" : {
"indices" : { }
},
"routing_nodes" : {
"unassigned" : [ ],
"nodes" : {
"VRbFlccpSAmm3LvZEYVRZA" : [ ],
"uDgGXTKoRJin2OL_QyTV8A" : [ ],
"FPeL_WuBQtm0Dk7apLcdLA" : [ ]
}
},
"health" : {
"disk" : {
"high_watermark" : "90%",
"high_max_headroom" : "150gb",
"flood_stage_watermark" : "95%",
"flood_stage_max_headroom" : "100gb",
"frozen_flood_stage_watermark" : "95%",
"frozen_flood_stage_max_headroom" : "20gb"
},
"shard_limits" : {
"max_shards_per_node" : 1000,
"max_shards_per_node_frozen" : 3000
}
}
}
创建Kibana可视化UI界面
编写配置文件
kibana-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: kibana-config
namespace: log-efk
data:
kibana.yml: |
server.name: kibana
server.host: "0.0.0.0"
elasticsearch.hosts: [ "http://elasticsearch-service.log-efk.svc.cluster.local:9200" ]
i18n.locale: "zh-CN"
配置解析
server.name:- 含义:设置 Kibana 服务器的名称。
- 作用:这个名称可以在 Kibana 的用户界面上显示,帮助用户识别正在访问的 Kibana 实例。
- 配置值:
kibana - 示例:
server.name: kibana
server.host:- 含义:定义 Kibana 服务器监听的主机地址。
- 作用:
"0.0.0.0"表示 Kibana 将监听所有网络接口,这意味着它可以接受来自任何 IP 地址的连接。 - 配置值:
"0.0.0.0" - 示例:
server.host: "0.0.0.0"
elasticsearch.hosts:- 含义:指定 Elasticsearch 集群的地址。
- 作用:配置 Kibana 用于连接的 Elasticsearch 实例或集群的 URL 列表。
- 配置值:
[ "http://elasticsearch-service.log-efk.svc.cluster.local:9200" ]http://elasticsearch-service.log-efk.svc.cluster.local:9200:这是在 Kubernetes 集群中 Elasticsearch 服务的地址和端口。elasticsearch-service是 Elasticsearch 服务的名称,log-efk是命名空间,:9200是端口号。
- 示例:
elasticsearch.hosts: [ "http://elasticsearch-service.log-efk.svc.cluster.local:9200" ]
i18n.locale:- 含义:设置 Kibana 的语言环境(locale)。
- 作用:将 Kibana 用户界面的语言设置为指定的语言和地区。这里设置为
"zh-CN",表示简体中文。 - 配置值:
"zh-CN" - 示例:
i18n.locale: "zh-CN"
编写资源清单文件
kibana.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: log-efk
spec:
# 标签选择器,选择要公开的Pod
selector:
app: kibana
# 服务的公开方式 NodePort为每个节点创建一个公开端口
type: NodePort
ports:
# 此服务内部访问的端口
- port: 5601
# 此服务将转发到的端口
targetPort: 5601
# 此服务将公开的节点端口
nodePort: 31601
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana-deployment
namespace: log-efk
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:8.13.3
imagePullPolicy: IfNotPresent
# 端口
ports:
- containerPort: 5601
# 资源限制
resources:
# 最小计算资源量
requests:
cpu: 100m
memory: 100Mi
# 最大计算资源量
limits:
cpu: 1000m
memory: 1Gi
# 环境变量
# env:
# # 指向Elasticsearch服务,如果有configMap则不需要
# - name: ELASTICSEARCH_HOSTS
# value: http://elasticsearch-service.log-efk.svc.cluster.local:9200
# 挂载的目录
volumeMounts:
- mountPath: /usr/share/kibana/config/kibana.yml
name: kibana-config
subPath: kibana.yml
volumes:
- name: kibana-config
configMap:
name: kibana-config
资源清单文件解释:
- 创建service,用于暴露pod容器接口,进行外部访问
- 创建 Deployment 控制器管理Pod
- 挂载配置文件
更新资源清单文件
kubectl apply -f .
查看kibana状态
kubectl get pods -n log-efk
结果:
NAME READY STATUS RESTARTS AGE
elasticsearch-0 1/1 Running 0 66m
elasticsearch-1 1/1 Running 0 66m
elasticsearch-storageclass-deployment-nfs-provisioner-64d5c8qgb 1/1 Running 8 (101m ago) 42h
fluentd-ds-94bpq 1/1 Running 0 11m
fluentd-ds-bkfhr 1/1 Running 0 11m
fluentd-ds-w6ndn 1/1 Running 0 11m
kibana-deployment-577d9d88b4-tffjp 1/1 Running 0 2m14s
创建fluentd收集宿主机产生的日志
编写配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: fulentd-config
namespace: log-efk
labels:
app: fulentd-config
data:
fluent.conf: |
<source>
@type tail
path /var/log/*.log
pos_file /var/log/fluentd-containers.log.pos
tag kubernetes.*
<parse>
@type none
time_key time
time_format %Y-%m-%dT%H:%M:%S.%N%z
</parse>
</source>
<source>
@type tail
path /var/log/containers/*.log
pos_file /var/log/containers/fluentd.pos
tag kubernetes.*
<parse>
@type none
</parse>
</source>
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@type elasticsearch
@id elasticsearch
host elasticsearch-service.log-efk.svc.cluster.local
port 9200
scheme http
logstash_format true
logstash_prefix fluentd
logstash_dateformat %Y.%m.%d
include_tag_key true
tag_key @log_name
index_name fluentd
type_name _doc
request_timeout 5s
reconnect_on_error true
reload_connections true
reload_after 200
reload_on_failure true
<buffer>
@type file
path /var/log/fluentd-buffers/
flush_interval 5s
retry_forever true
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 256
</buffer>
</match>
parsers.conf: |
<label @FLUENT_LOG>
<match **>
@type stdout
</match>
</label>
配置详情解析
Source 部分
-
第一个 source 配置:
<source> @type tail path /var/log/*.log pos_file /var/log/fluentd-containers.log.pos tag kubernetes.* <parse> @type none time_key time time_format %Y-%m-%dT%H:%M:%S.%N%z </parse> </source>@type tail:使用 tail 插件从指定的文件中读取日志。path /var/log/*.log:读取/var/log目录下所有以.log结尾的文件。pos_file /var/log/fluentd-containers.log.pos:记录读取位置的文件,防止 Fluentd 重启后重复读取相同的日志。tag kubernetes.*:为这类日志设置标签kubernetes.*。<parse>:定义解析配置。@type none:不进行日志解析,直接使用原始日志数据。time_key time:指定时间戳的字段名称。time_format %Y-%m-%dT%H:%M:%S.%N%z:时间戳的格式。
-
第二个 source 配置:
<source> @type tail path /var/log/containers/*.log pos_file /var/log/containers/fluentd.pos tag kubernetes.* <parse> @type none </parse> </source>@type tail:使用 tail 插件从指定的文件中读取日志。path /var/log/containers/*.log:读取/var/log/containers目录下所有以.log结尾的文件。pos_file /var/log/containers/fluentd.pos:记录读取位置的文件,防止 Fluentd 重启后重复读取相同的日志。tag kubernetes.*:为这类日志设置标签kubernetes.*。<parse>:定义解析配置。@type none:不进行日志解析,直接使用原始日志数据。
Filter 部分
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<filter kubernetes.**>:过滤标签匹配kubernetes.**的日志。@type kubernetes_metadata:使用kubernetes_metadata插件,自动添加 Kubernetes 的元数据(如 pod 名称、命名空间、容器名称等)到日志记录中。
Match 部分
<match **>
@type elasticsearch
@id elasticsearch
host elasticsearch-service.log-efk.svc.cluster.local
port 9200
scheme http
logstash_format true
logstash_prefix fluentd
logstash_dateformat %Y.%m.%d
include_tag_key true
tag_key @log_name
index_name fluentd
type_name _doc
request_timeout 5s
reconnect_on_error true
reload_connections true
reload_after 200
reload_on_failure true
<buffer>
@type file
path /var/log/fluentd-buffers/
flush_interval 5s
retry_forever true
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 256
</buffer>
</match>
<match **>:匹配所有日志。@type elasticsearch:使用 Elasticsearch 插件,将日志发送到 Elasticsearch。@id elasticsearch:配置 ID,唯一标识此插件实例。host elasticsearch-service.log-efk.svc.cluster.local:Elasticsearch 服务的主机名。port 9200:Elasticsearch 服务的端口。scheme http:使用 HTTP 协议连接 Elasticsearch。logstash_format true:以 Logstash 格式索引日志数据。logstash_prefix fluentd:日志索引的前缀。logstash_dateformat %Y.%m.%d:日志索引的日期格式。include_tag_key true:在日志记录中包含标签键。tag_key @log_name:标签键的名称。index_name fluentd:Elasticsearch 索引名称。type_name _doc:Elasticsearch 文档类型(7.x 版本后不再需要)。request_timeout 5s:请求超时时间。reconnect_on_error true:发生错误时重新连接。reload_connections true:自动重载连接。reload_after 200:每 200 个请求重载连接。reload_on_failure true:连接失败时重载。<buffer>:缓冲配置。@type file:使用文件进行缓冲。path /var/log/fluentd-buffers/:缓冲文件路径。flush_interval 5s:缓冲刷新间隔。retry_forever true:无限重试。retry_max_interval 30:最大重试间隔。chunk_limit_size 2M:每个缓冲块的最大大小。queue_limit_length 256:队列最大长度。
parsers.conf 部分
<label @FLUENT_LOG>
<match **>
@type stdout
</match>
</label>
<label @FLUENT_LOG>:定义一个标签为@FLUENT_LOG的部分。<match **>:匹配所有日志。@type stdout:将日志输出到标准输出(控制台)。
编写资源清单文件
# 创建一个 用户
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-sa
namespace: log-efk
---
# 创建一个角色
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd-cr
namespace: log-efk
# 角色的规则
rules:
- apiGroups: [""]
resources: ["pods", "namespaces"]
verbs: ["get", "watch", "list"]
---
# 创建一个 ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: fluentd-crb
namespace: log-efk
# 绑定的用户
subjects:
- kind: ServiceAccount
# 要绑定的用户的名称
name: fluentd-sa
namespace: log-efk
# 绑定的角色
roleRef:
kind: ClusterRole
# 要绑定的角色的名称
name: fluentd-cr
apiGroup: rbac.authorization.k8s.io
---
# 创建一个DaemonSet 确保在每一个节点上都有一个fluentd pod
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-ds
namespace: log-efk
spec:
selector:
# 标签选择器,选择要管理的Pod,就是下文的模板中的标签
matchLabels:
app: fluentd
template:
metadata:
# pod的标签
labels:
app: fluentd
spec:
# 定义ServiceAccount
serviceAccountName: fluentd-sa
# 污点容忍度
# 允许在master节点上运行
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.16-debian-elasticsearch8-2
imagePullPolicy: IfNotPresent
# # 环境变量 如果配置了configmap 则不需要配置环境变量
# env:
# # ELASTICSEARCH的地址
# - name: FLUENT_ELASTICSEARCH_HOST
# value: "elasticsearch-service.log-efk.svc.cluster.local"
# # ELASTICSEARCH的端口
# - name: FLUENT_ELASTICSEARCH_PORT
# value: "9200"
# # ELASTICSEARCH的请求方式
# - name: FLUENT_ELASTICSEARCH_SCHEME
# value: "http"
# # FLUENTD的日志级别
# # 由于 FLUENTD_SYSTEMD_CONF 被设置为 disable,Fluentd
# # 不会从 systemd 日志中收集日志,只会从配置的宿主机路径 /var/log 和 /var/lib/docker/containers 收集日志。
# - name: FLUENTD_SYSTEMD_CONF
# value: disable
# 资源限制
resources:
# 最大资源限制
limits:
memory: 200Mi
# 最小资源限制
requests:
cpu: 100m
memory: 200Mi
# 挂载的目录
volumeMounts:
- mountPath: /var/log
name: log
# 挂载配置文件
- name: fulentd-config
mountPath: /fluentd/etc/fluent.conf
# 卷中的子路径,表示你希望挂载的卷中的特定文件或目录。
subPath: fluent.conf
# 容器终止的强制关闭时间
terminationGracePeriodSeconds: 30
# 定义卷
volumes:
- name: log
# 宿主机路径
hostPath:
path: /var/log
- name: fulentd-config
configMap:
name: fulentd-config
资源清单文件解释:
- 创建一个角色,基于查看pods与namespaces的权限
- 使用 DaemonSet 控制器,确保每一个节点上都有一个fluentd Pod
- 定义污点容忍度,确保可以在Master节点运行
- 挂载目录
- 将宿主机的/var/log挂载到容器中的/var/log
- 将配置文件挂载到容器中的配置位置
更新资源清单文件
kubectl apply -f .
查看fulentd资源情况
kubectl get pods -n log-efk
结果:
NAME READY STATUS RESTARTS AGE
elasticsearch-0 1/1 Running 0 66m
elasticsearch-1 1/1 Running 0 66m
elasticsearch-storageclass-deployment-nfs-provisioner-64d5c8qgb 1/1 Running 8 (101m ago) 42h
fluentd-ds-94bpq 1/1 Running 0 11m
fluentd-ds-bkfhr 1/1 Running 0 11m
fluentd-ds-w6ndn 1/1 Running 0 11m
kibana-deployment-577d9d88b4-tffjp 1/1 Running 0 2m14s
创建测试Pod不断打印日志
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
imagePullPolicy: IfNotPresent
# 创建一个无限循环,每秒钟打印一次当前的日期和时间,以及一个递增的计数器
args: ["/bin/sh", "-c", 'i=0; while true; do echo "$i: $(date) hello fluentd"; i=$((i+1)); sleep 1; done']
创建一个pod不断打印日志
查看Kibana可视化UI界面中的日志
-
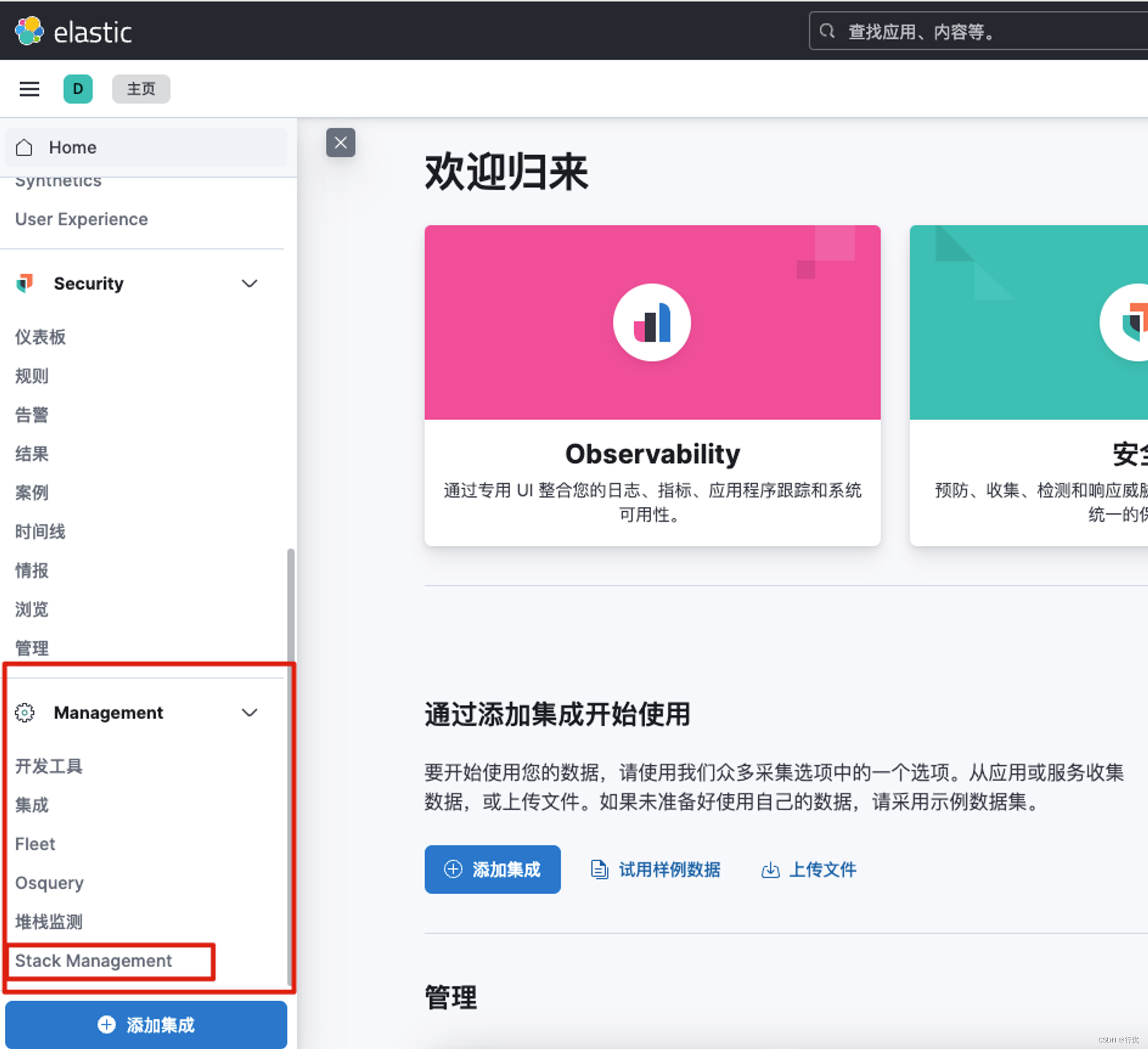
点击左边菜单,最下方Management中的Stack Management

-
选择数据中的索引管理

-
查看菜单中的fluentd收集的索引

-
选择Kibana中的数据视图

-
选择右上角创建视图

-
创建对应的视图,链接对应的索引
-
点击保存数据视图
-
回到主页选择最上方的Discover

-
右上角选择创建的视图
 11. 查看日志
11. 查看日志


K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 43
43 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)