【Agent组合技】最全解读MoE混合专家模型:揭秘关键技术与挑战
OpenAI 引领的生成式模型发展如火如荼,截止目前最强大的模型是 GPT4V,它不仅在语言模态方面有强大的能力,同时具备强大的视觉能力。在今年 7 月爆出的 GPT4 解密的报告,以及跟业内人士的多方交流验证,GPT4 使用 MoE 架构是一件非常明确的事情:选择了 16 个 Expert,每个 Token 选择 Top2 个 Expert,总体参数规模在 1.8TB 左右在不久后的 2024
写在前面
- OpenAI 引领的生成式模型发展如火如荼,截止目前最强大的模型是 GPT4V,它不仅在语言模态方面有强大的能力,同时具备强大的视觉能力。在今年 7 月爆出的 GPT4 解密的报告,以及跟业内人士的多方交流验证,GPT4 使用 MoE 架构是一件非常明确的事情:选择了 16 个 Expert,每个 Token 选择 Top2 个 Expert,总体参数规模在 1.8TB 左右
- 在不久后的 2024 年,MoE 也是一个非常明确的竞争赛道。提升对于 MoE 的理解,不管是对于学界、工业界以及算法工程师本身,都是未来的一个卷点。因此揭开 MoE 的面纱、了解 MoE 的前世今生、了解 MoE 的目标和发展主线,以及 MoE 的挑战等,都是很重要的事
- 在本文中,笔者尝试针对上面提到的一些问题进行相对宏观的概述,希望抛砖引玉,如有不当之处,请读者指正
MoE 的目标和发展主线
- 首先最重要的事情,是要搞清楚 MoE 究竟在解决什么问题?为什么需要 MoE 的架构?它是如何被发明出来的?发展的历史围绕什么核心问题在演变?
- 我们研究问题应该有历史感,如果不了解某个问题的历史,不能称之为真正理解了该问题。围绕 MoE 问题本身,我们首先要跳出这个具体的问题,回顾一下神经网络、互联网以及 AI 发展的简史
- 在上世纪 90 年代之后,互联网公司开始逐步发展,其中美国有 Google,中国有百度,后来又逐步兴起了 AWS、腾讯、阿里、字节等公司,从 PC 互联网时代、到移动互联网时代,短短二三十年,这些公司发展可谓一日千里,对于 AI 技术的应用也大放异彩,特别是占据了大头的搜索和推荐技术。在过去的十几年间,围绕搜推的 AI 技术,很重要的发展主线是**”特征以及更多特征的交叉“、”更强大的表征“、”多任务学习“**等,针对上面的三个方面,整个排序系统的发展历史,也从逻辑回归、协同过滤,发展到中期的深度神经网络如 DSSM、Wide&Deep、DeepCross,再到后来的 ESSM、MMOE 等多任务学习等
- 同期的 CV 领域和 NLP 领域,以表征学习为主线:模型参数和数据规模越来越大,也有相对短暂的多任务学习工作等,但是主线还是围绕更加丰富的表征学习,不断突破旧认知中的 Upper Bound
- 从上述的描述中,想必大家看到了一个关键词:表征学习。没错,我认为这是 AI 发展的一条主线
最理想的情况下,我们期望有一种统一的模型结构,一种简单的学习方式,充分的利用计算资源,获取一个足够强大而通用的模型,而要做到足够强大和通用,模型的表达能力就应该足够丰富、多样和通用。这也是我们的模型越来越大的原因之一
- 综合上面的一些观点,我们可以相对明确的得到一个结论:模型的参数应该越大越好。模型的参数越大,那么其表征学习的能力越强,也就是说模型的能力就越强大。但在实际情况中,我们总会受限于计算资源的约束,算力总是相对有限的,那么很自然的一个问题就出来了,这也是 MoE 需要解决的问题
我们能不能找到一种方法,使得模型的参数足够大,但又不显著增加训练和推理计算资源,从而得到一个强大的模型呢?
MoE 经典工作回顾
-
关于 MoE 的经典工作回顾,不得不提到 Noam Shazeer,在各个经典的 Paper 中都能看到其活跃的身影,其经典传世之作不可谓不多,目前也是 Character AI 的创始人之一。此等大神在学界业界两开花,令人叹服
-
回到 MoE 经典工作回顾部分,有以下文章推荐阅读,下面我会一一进行解读,有兴趣的可以都去读一读原文
-
Outrageously Large Neural Networks: The Sparsely Gated Mixtures of Experts Layer(2017 Noam 一作)
-
GShard: Scaling Giant Models with Conditional(2020 Noam 是作者之一)
-
A Review Of Sparse Expert Models In Deep Learning(2022 Jeff Dean)
-
待填坑
-
下面我们逐篇回顾
首先是上古年代的,可以称之为 MoE 开山之作的 Adaptive Mixtures of Local Experts
-
问题的背景相比笔者在第一部分描述而言,更具体。文中的设定是这样的:
-
如果使用一个模型或者说同一个处理模块进行不同领域数据的学习,那么其收敛性和泛化性都会比较差。而如果我们提前知道不同数据的类别,那么我们可以使用不同的专家模块进行不同样本的学习。为了解耦不同专家模块,我们可以使用门网络,对不同的样本进行不同的专家选择,从而消除了不同专家模块的相互影响
-
最一开始,整个 Loss 的计算是结合了全部专家的建议,然后进行线性组合。这种 Loss 计算方式,会让不同的专家模块互相影响(一个改变,其他专家要跟着改变,实际上不同专家像是残差补全其他专家的结果) Loss=||de−∑ipieoie||2Loss=||de-\sum_i{p_ie}o_ie||2Loss=||de-\sum_i{p_ie}o_ie||2
为了减缓上面所说的耦合问题,将 Loss 修改为了每个专家自己学自己的,也就是
Loss=∑ipie||de−oie||2Loss=\sum_i{p_ie}||de-o_ie||2Loss=\sum_i{p_ie}||de-o_ie||2 -
模型架构是下面这样(原始 Paper 图也有点糊,凑合看)
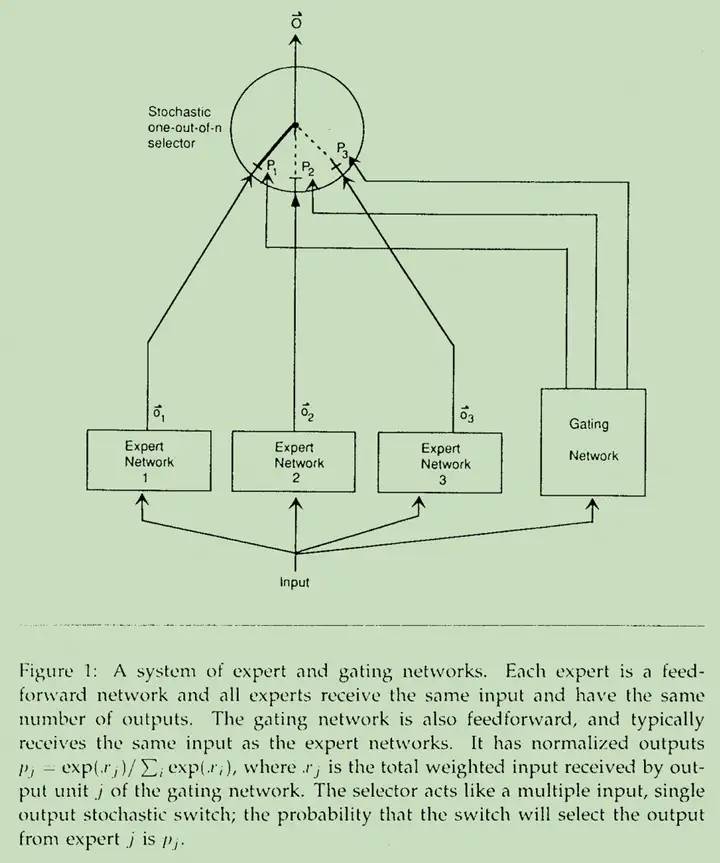
远古 MoE
2017 年的经典工作 Outrageously Large Neural Networks: The Sparsely Gated Mixtures of Experts Layer
Introduction
-
神经网络从数据中吸收信息的能力,取决于参数量的大小。因此增加模型的参数容量对于模型的能力很关键,但同时最好不要显著增加计算量,所以 Sparsely Gated Mixtures of Experts 结构是一种很关键的选择。即利用稀疏结构显著增加参数量,但是不显著增加计算量,同时具备很强的拓展性以及在各个任务上取得很好的效果
-
增加模型的 Size 和 数据的 Size 已经成为了 Deep Learning 领域发展的核心,会显著提升模型的效果。这一点在 Text Vision 以及 Audio 领域已经得到了广泛的证明
-
虽然大家都很认可上面的理论,但事实上没有大规模应用起来,作者将问题归结于以下挑战
-
计算设备算的很快,但是 Branching 很慢
-
巨大的 Batch Size 很关键,但是条件计算因为只激活部分网络,因此事实上较少了 Batch Size
-
网络带宽成为了瓶颈。因为在 GPU 集群中,涉及到了大量的网络传输,这一点相比计算成为了瓶颈,导致无法发挥全部算力
-
需要保证网络的稀疏性以及负载均衡
-
大的参数量同时也需要大的数据量,目前已有的一些监督数据集不够大
-
为了解决上面提到的一些问题,作者提出了 Sparsely Gated Mixtures of Experts 并将其用在了 LSTM 解决语言模型和机器翻译的任务上。相比上古年代的 Adaptive Mixtures of Local Experts 文章提到的样本粒度,这里事实上使用了 Token 粒度进行不同专家路由选择,并且只选择了 Top2 个 Experts
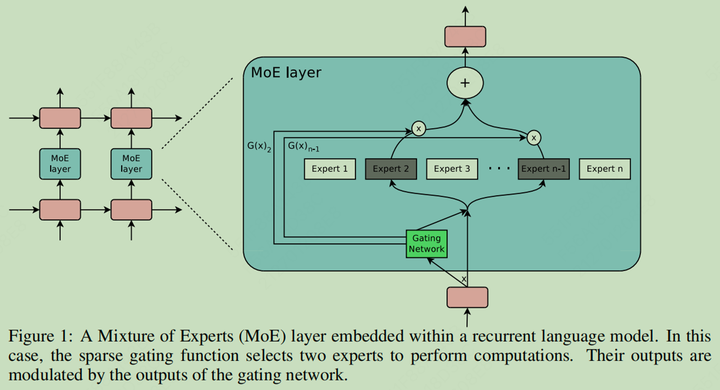
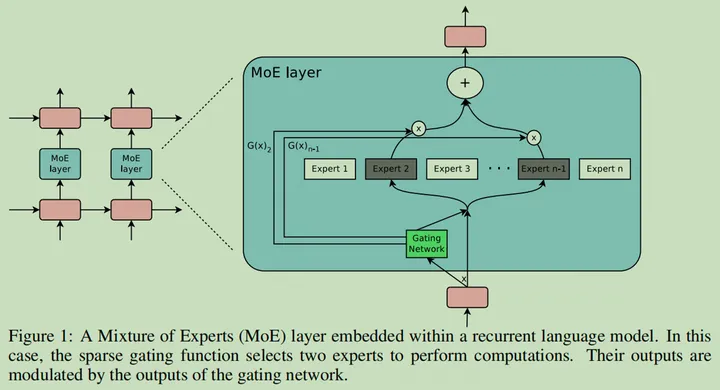
LSTM MoE 示意图
MoE 层的网络结构
-
每个 MoE 层的宏观结构如上图所示,包括了一个门网络和不同的专家模块。理论上说,专家模块可以有不同的结构,只需要保证相同尺寸的输入输出就行,但在作者的设置里,选择了相同的结构,并且每个模块有自己的独立参数
-
如果使用 G ( x ) G(x) G(x) 和 E _ i ( x ) E\_i(x) E_i(x) 表示门网络的输出和第 i 个专家的输出,x 表示输入,那么 MoE 层的输出可以表示为下面的形式
y=∑inG(x)iEi(x)y=\sum_in{G(x)_i}{E_i(x)}y=\sum_in{G(x)_i}{E_i(x)} -
门网络
-
最简单的非稀疏的门网络是将输入叉乘 WgW_gW_g (一个可训练的权重矩阵)然后应用 Softmax 函数
G(x)=Softmax(x·Wg)G(x)=Softmax(x·W_g)G(x)=Softmax(x·W_g) -
为了保证网络的稀疏性,并且节约计算资源和保证负载均衡,作者将上述公式做了如下修改
G(x)=Softmax(KeepTopK(H(x),k))G(x)=Softmax(KeepTopK(H(x), k))G(x)=Softmax(KeepTopK(H(x), k))
H(x)i=(x·Wg)i+StandardNormal()·Softplus((x·Wnoise)i)H(x)_i=(x·W_g)_i+StandardNormal()·Softplus((x·W_{noise})_i)H(x)_i=(x·W_g)_i+StandardNormal()·Softplus((x·W_{noise})_i)
KeepTopK(v,k)iKeepTopK(v,k)_iKeepTopK(v,k)_i 中,如果 viv_iv_i 在 topk 中,那么就是 viv_iv_i ,否则就是负无穷
这里加入噪声,是为了结果能平滑,用于反向传播(因为每个专家接收到了样本数量是离散的数值,不能用于反向传播,需要进行平滑)
解决性能问题
-
The Shrinking Batch Problem
-
如果有 b 个样本,每个样本选择 k 个专家,一共有 n 个专家,那么实际上平均每个专家收到的样本数量为 kbn\frac{kb}{n}\frac{kb}{n} ,且随着 n 的增加,会使得实际上每个专家接收到的样本量更低了,为了解决这个问题,一般情况下,会让总体的 b 增大,但是 b 增大之后,会导致内存受限(在前向和反向两个传播阶段)因此做了很多并行处理,比如数据并行、模型并行处理等
-
Network Bandwidth
-
需要进行很多 input 和 output 在不同专家之间进行信息传送,导致网络带宽成为了瓶颈,而算力不能充分发挥。为了缓解这个问题,需要保证:专家的计算量与其输入和输出的大小之比必须超过计算设备的计算量与网络容量之比
Balancing Expert Utilization
- 门网络很容易倾向于选择几个效果较好的专家,而导致大量的专家弃之不用。这种负载不均衡会在训练过程中自我强化。为了解决这个问题,作者使用了软约束的方法,即在总体 Loss 计算中,新增一项 LimportanceL_{importance}L_{importance} ,这个 Loss 相当于增加了门权重分布不稳定性的 Loss,并且乘以一个固定的超参系数
Importance(X)=∑x∈xG(x)Importance(X)=\sum_{x\in{x}}G(x)Importance(X)=\sum_{x\in{x}}G(x)
Limportance(X)=wimportance·CV(Importance(X))2L_{importance}(X)=w_{importance}·CV(Importance(X))2L_{importance}(X)=w_{importance}·CV(Importance(X))2
不可不读的 2020 年工作 GShard: Scaling Giant Models with Conditional
Introduction
-
虽然增加模型的尺寸、数据规模和计算量会显著提升模型效果,并且这一点成为了共识,但是依然有很多挑战,比如:计算成本、代码编写以及并行实现效率
-
目前最大的挑战依然在训练效率这一块
-
在实践中规模化的挑战
-
特定架构并行计算的支持(目前缺乏针对特定模型架构的硬件和软件设计,支持不够好)
-
随着模型尺寸的增加,计算成本是超线性的增加(通信成本会显著增加,并且目前的负载均衡问题解决的也不是很好,所以针对模型尺寸增加的问题,单纯增加算力是不够的,利用率依旧不足)
-
训练超大模型的 Infra 的稳定性问题(这一点显而易见)
-
并行策略依然是重要的挑战
Model 设计
- Transformer 架构已经变成了 NLP 中心位置的模型架构,因此本文的 MoE 架构设计主要针对 Transformer 的 Encoder 和 Decoder,其中每隔一个 FFN 层每个一个做 Expert,并选择 Top2
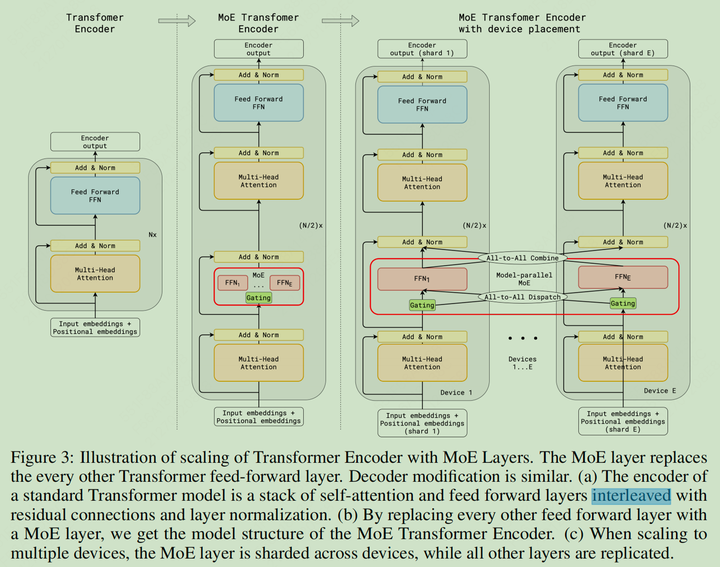
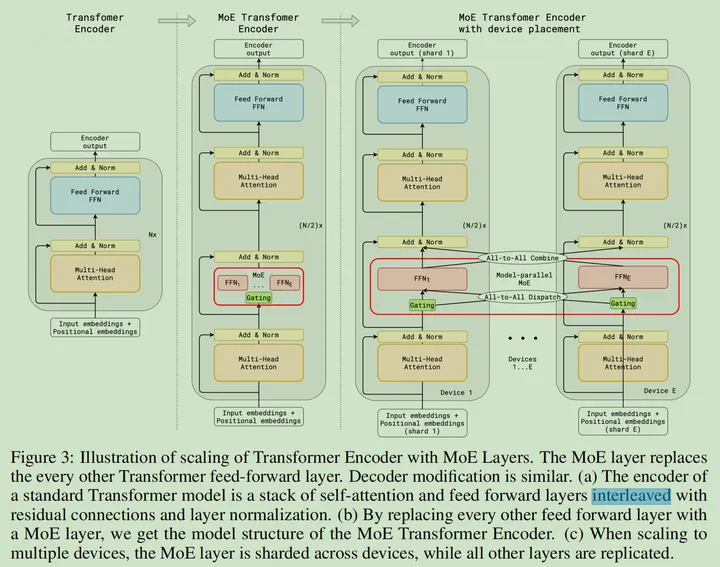
GShard MoE 设计示意图
-
门控部分需要满足两个目标
-
Balance Load
-
使得所有的专家都干活儿
-
Efficiency at scale
-
如果逐个使用不同的专家进行计算,那么负载均衡就会很容易地实现。但实际上这样会让大多数的计算资源处于空闲状态(Expert 并行在不同的机器上)因此需要实现一个能高效利用计算资源的门控网络
-
因此作者设计了如下的门控网络来解决上面的问题
-
Expert capacity
-
为了保证负载均衡,我们强制一个专家处理的 Token 量低于某个统一的阈值,我们将其定义为专家容量。假设训练批中的令牌总数为 N,每个令牌最多分配给两个专家,则专家容量设为O(N/E)
-
门控网络会实现一个 Token 计数器,用来统计每个专家已经计算了多少 Tokens,如果超出了专家容量,那么新来的 Token 将被认为是溢出 Token。这样的 Token 通过剩余连接将其表示 x 传递到下一层
-
Local group dispatching
-
Random routing
-
Auxiliary loss
-
Loss=LmLoss+k∗AuxiliaryLossLoss=LmLoss + k*Auxiliary LossLoss=LmLoss + k*Auxiliary Loss
-
其中我们选择的专家是 Top2,且这一项不可微,所以使用了所有专家的平均概率作为优化目标
2022 年经典工作 Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Introduction
- 简单的模型结构,加上大量的数据、算力和模型参数,就可以远超复杂的算法设计
- 因此作者们提出了一种稀疏激活的专家模型,即 Switch Transformer
- MoE 模型目前依然受限于:复杂度、通信成本以及训练稳定性
Switch Transformer
-
设计原则是:使用简单和计算高效的方法,最大化 Transformer 模型的参数量
-
Simplifying Sparse Routing
-
2017 年的 Shazeer 设计的 MoE 网络结构为:使用一个 Token Representation 作为输入,然后将其路由到 TopK 个 Expert 上(从 N 个 Expert 中选择)门的选择概率是 Softmax 之后的概率分布的 TopK,然后讲选择的专家的结果进行线性组合
Pi(x)=eh(x)i∑jNeh(x)jP_i(x)=\frac{eh(x)_i}{\sum_{j}{N}eh(x)_j}P_i(x)=\frac{eh(x)_i}{\sum_{j}{N}eh(x)_j}
y=∑i∈Tpi(x)Ei(x)y = \sum_{i\in T}p_i(x)E_i(x)y = \sum_{i\in T}p_i(x)E_i(x) -
Shazeer 猜测 k>1 experts 是非常必要的,这一点对于路由梯度的重要性很有必要
-
Shazeer 认为至少需要 2 个专家,但是这篇工作反其道而行之,只选择了一个专家
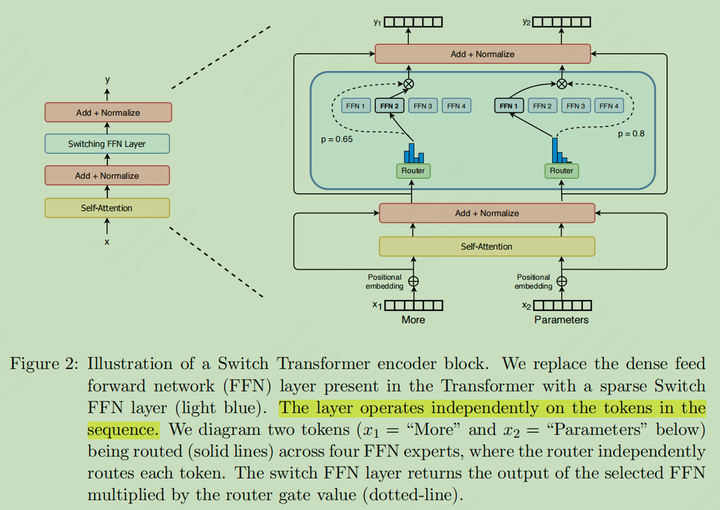
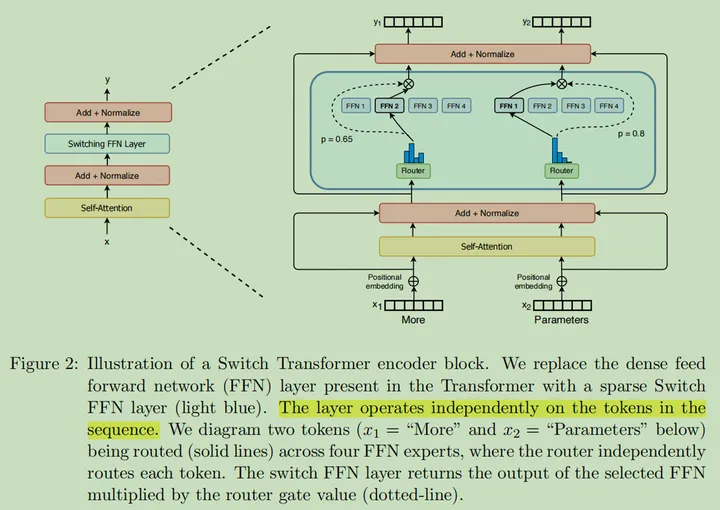
Switch Transformer MoE 设计示意图
-
Efficient Sparse Routing
-
专家容量定义为每个专家计算的 Token 数量
expert capacity=(token per batchnumber of experts)×capacity factorexpert\ capacity=(\frac{token \ per\ batch}{number\ of\ experts})\times capacity\ factorexpert\ capacity=(\frac{token \ per\ batch}{number\ of\ experts})\times capacity\ factor
专家容量少一点,吞吐更高(一般将 capacity factor 设置为 1)
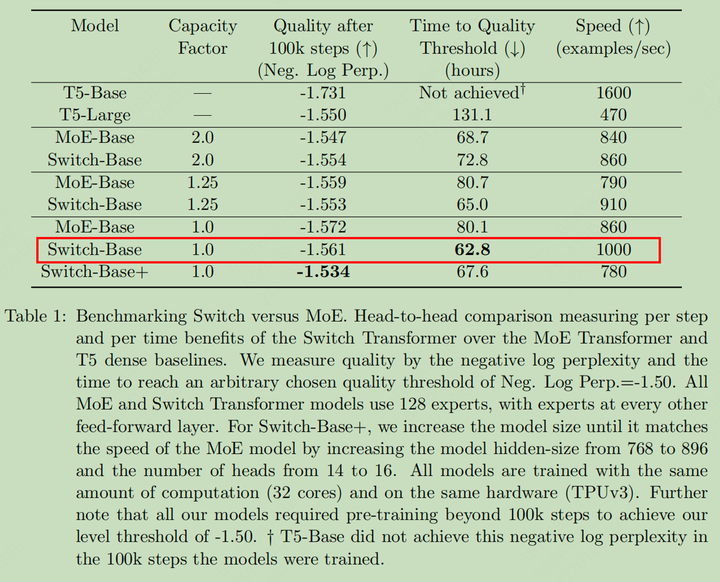
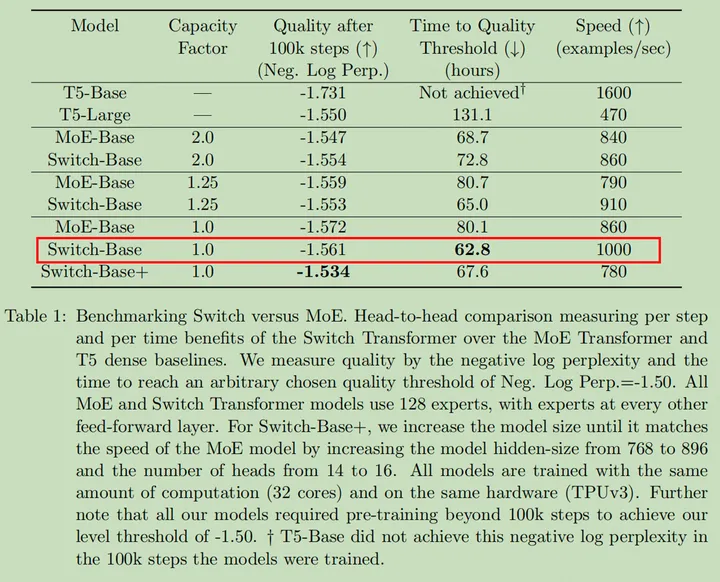
模型架构及专家容量选择对比
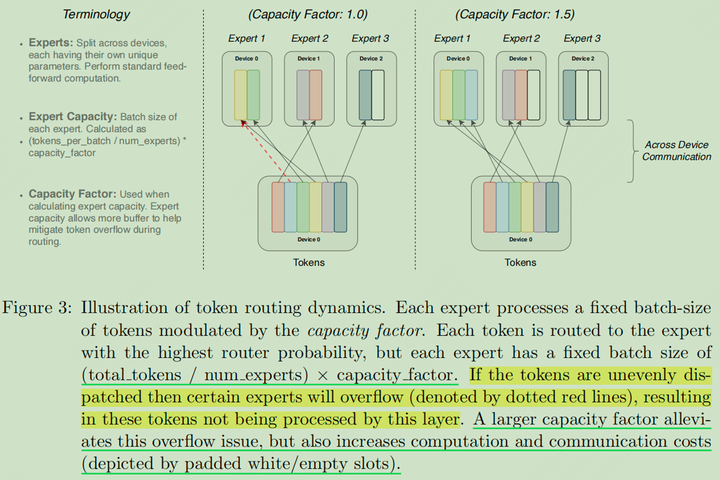

专家容量示意图
Introduction
- MoE 是一个持续了 30 多年的一个概念,过往很多人提出过很多方法,他们的核心思想都是使用全量参数的子集
- 通过这样的做法,可以实现大而高速的模型
- MoE 的架构可以加速训练和推理,是一种新的范式
- 针对每个数据样本,传统的模型会激活全部的参数进行训练和推理,而 MoE 架构的模型,会让输入样本路由到特定的专家网络(参数的子集)
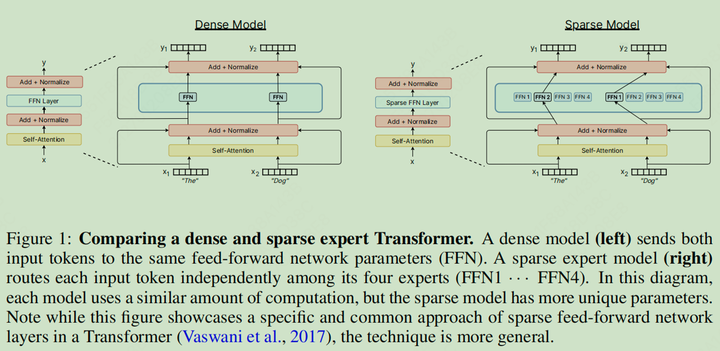
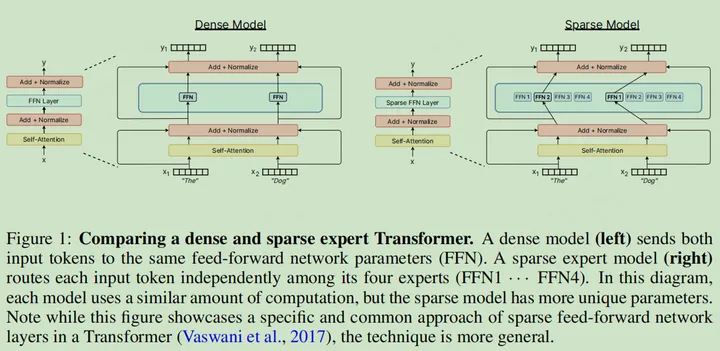
Dense Model VS Sparse Model
Scaling Properties Of Sparse Expert Models
-
Upstream Scaling(Pretrain)
-
在 Pretrain 阶段,稀疏网络的增益显著高于稠密网络
-
Expert Scaling 性质如下左图表示,到了 256 个有增益衰减出现,所以理论上也不是无限大的(但是要注意这个曲线对应的数据规模,下面的曲线不一定有拓展性,或者说形状可以拓展,但是对应的横坐标的数值不一定可以 Scaling)
-
Switch Transformers 实现了在相同的参数量下,4-7 倍的增速(训练和推理)
-
Downstream Scaling
-
每个 Token 的计算量越多,效果越好
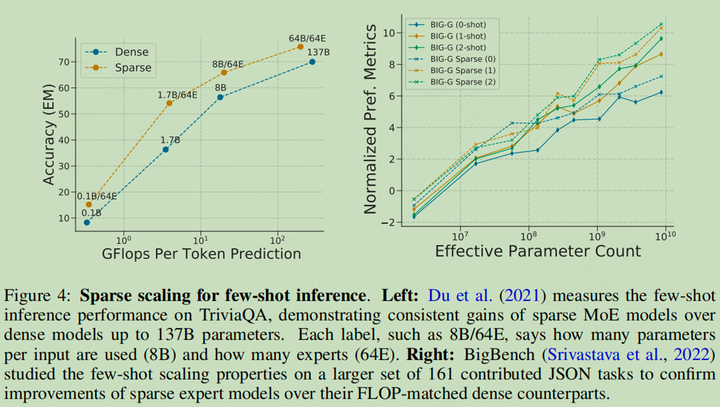
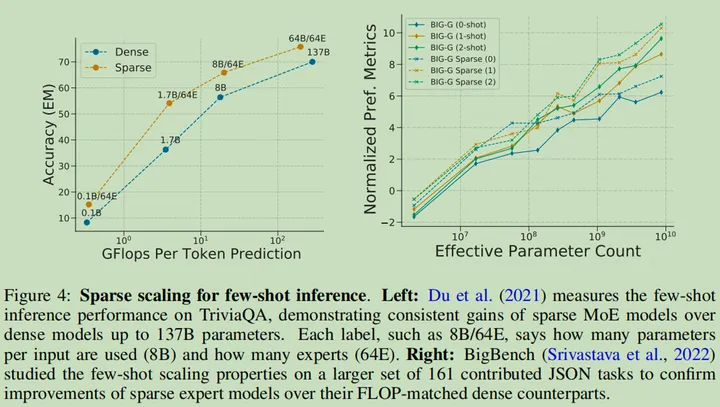
Downstream Scaling 示意图
Routing Algorithms
- 每个 Token 选择 TopK 个专家
- 每个专家选择 TopK 个 Token
- 全局决定哪个 Token 应该去哪个专家
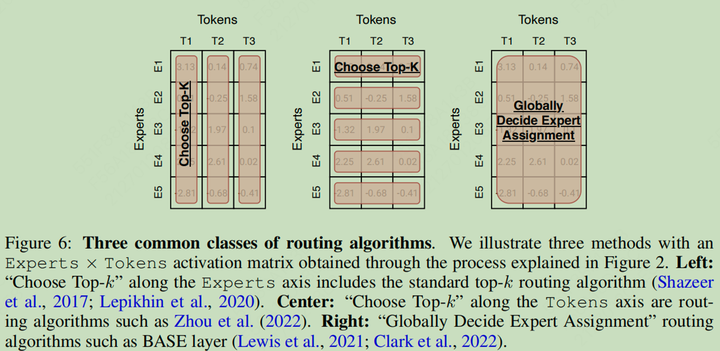
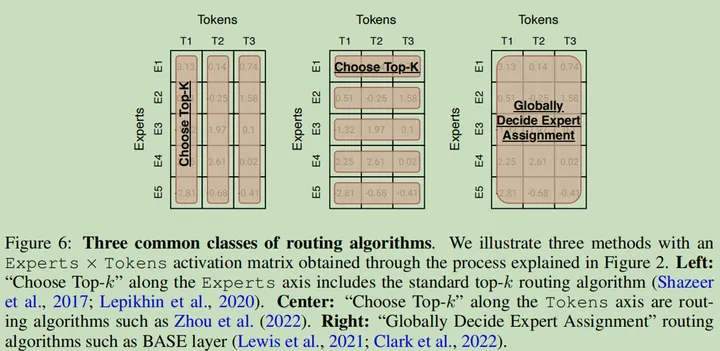
三种路由选择
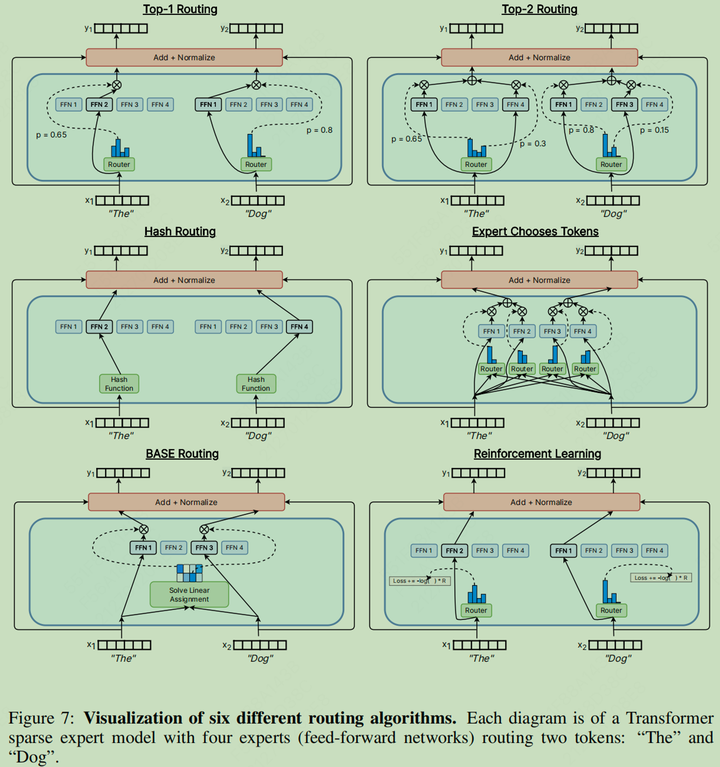
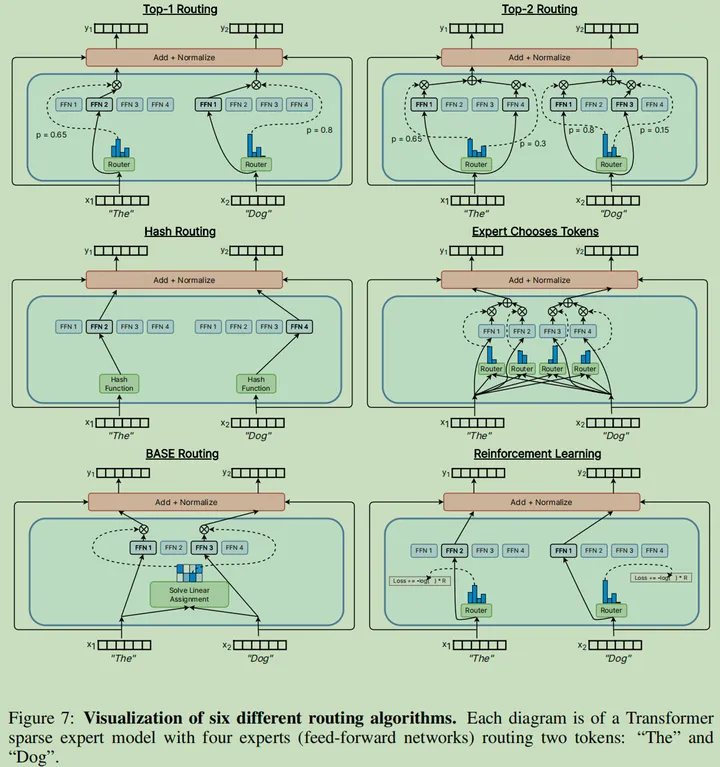
多种路由算法示意图
MoE 的关键选择
-
总体而言,目前有一些关键的参数,影响还比较大的
-
专家数量
-
很多早期的工作,每层有几千个专家,取得了不错的效果
-
最近的比较好的工作使用了 64 个更大的专家,用来平衡计算量和参数
-
但目前如果要在 LLM 中实践,可以 Follow OpenAI 的 16 Expert Top2 的选择
-
每个专家的大小
-
一般情况下,保证跟 Dense Model FFN 一样的尺寸就行
-
专家层的频率
-
目前都是每隔一个 Block 出现一次,而且更深层的专家层更加重要(参考 DeepSpeed MoE 的 Paper)
-
稀疏网络的初始化
-
基于一个 Dense 网络
MoE 的 Scaling 性质(以后填坑 Scaling Law)
- 这里主要贴一些 Scaling 的图,以后搞明白 MoE 的 Scaling Law,再回来填坑
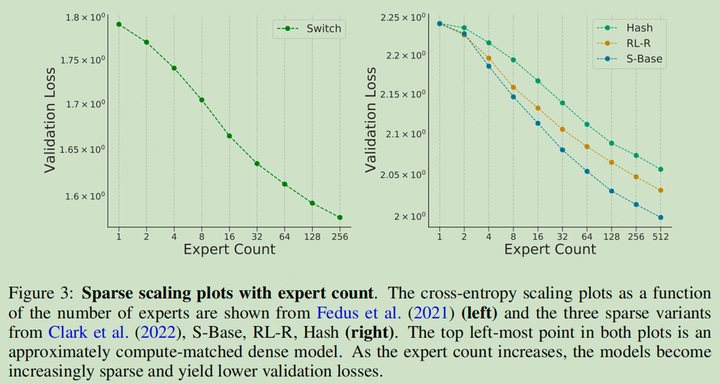
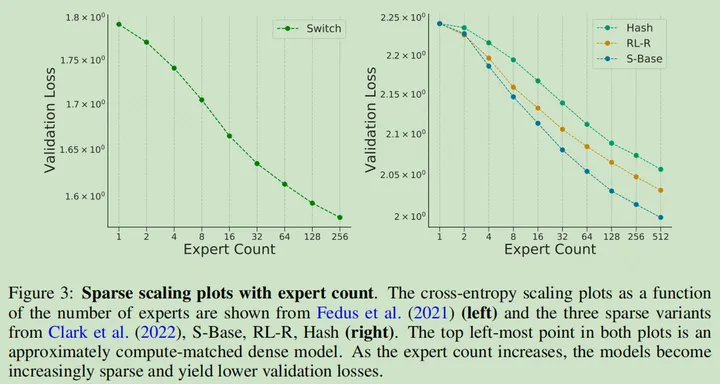
专家数量的 Scaling 性质
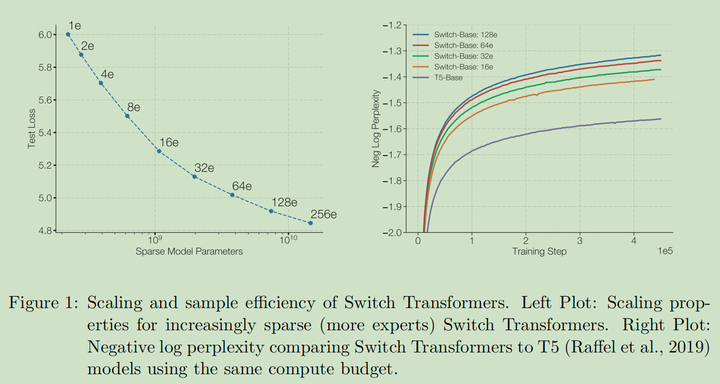
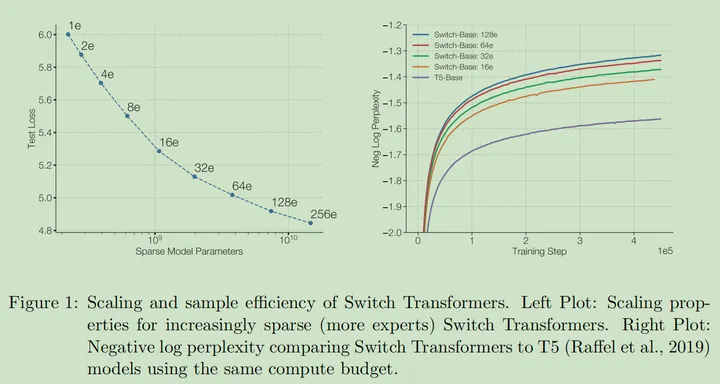
参数量的 Scaling 性质
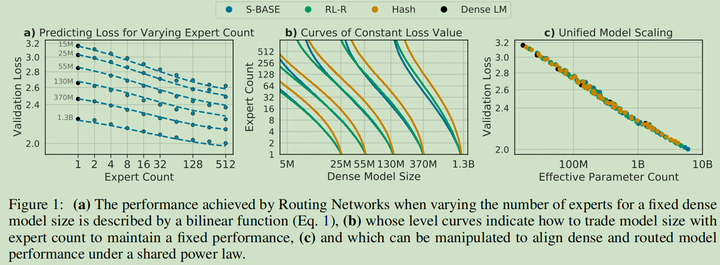
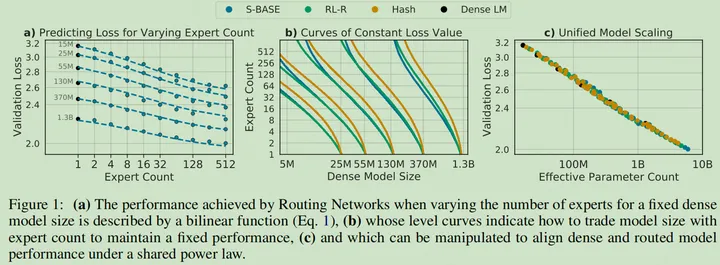
专家数量、Dense Model Size 以及参数量的 Scaling 性质
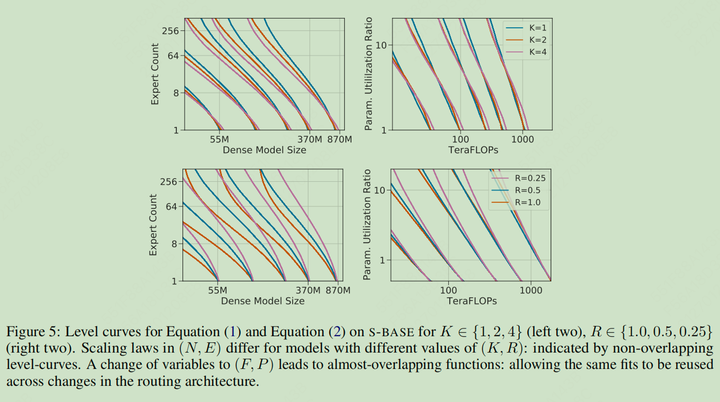
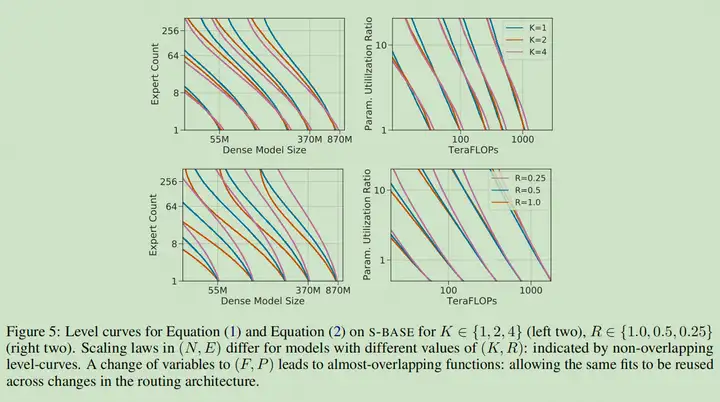
相同效果的帕累托图

Agent 垂直技术社区,欢迎活跃、内容共建,欢迎商务合作。wx: diudiu5555
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)