
DETR: End-to-End Object Detection with Transformers快速介绍
transformers
huggingface/transformers: 是一个基于 Python 的自然语言处理库,它使用了 PostgreSQL 数据库存储数据。适合用于自然语言处理任务的开发和实现,特别是对于需要使用 Python 和 PostgreSQL 数据库的场景。特点是自然语言处理库、Python、PostgreSQL 数据库。
项目地址:https://gitcode.com/gh_mirrors/tra/transformers
·
本文亮点
无需anchor 且 无需后处理的端到端的检测任务
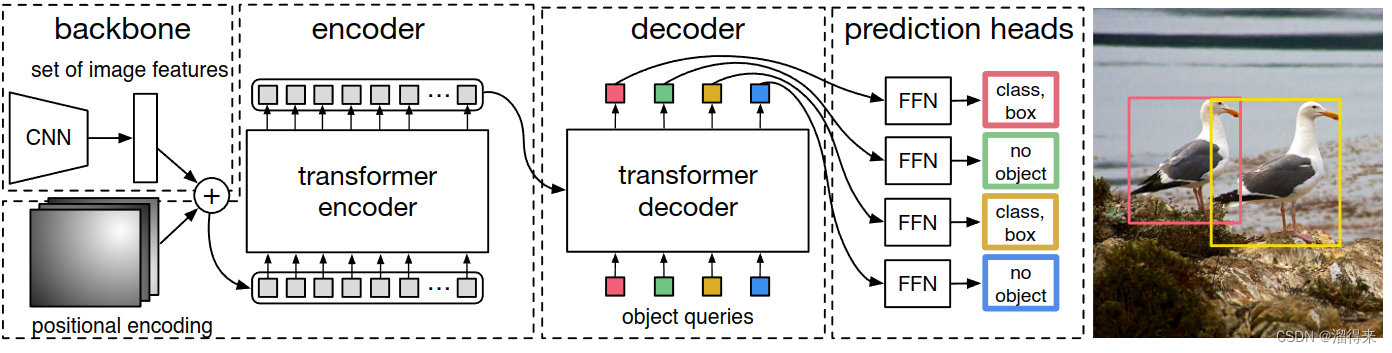
模型介绍
前向传播
文章直接使用了transformer结构来做目标检测,流程如下

- 图像([B, 3, 800, 1066])经过CNN(可以为resnet-50)卷积,得到特征图([B, 256, 25, 34])
- 图像位置编码,可以是learned positional encoding,也可以是基于sin/cos函数的 【B, 256, 25,34】
- 特征图+位置编码
- 建立nn.transformer(d_model), 这里的d_model为25*34。
- 调用transformer,encoder输入为第3步输出, decoder输入为100个可学习的object_query
- transformer输出为100个对应于object_query的dense编码变量,通过FFN获得类别以及bbox的位置,【c, x1, y1, x2, y2】
loss
- 分类loss
- bbox位置回归 L1 loss
- giou cost,使得预测的bbox和真实的bbox的iou尽量的大
几个问题
为什么不需要anchor
transformers
huggingface/transformers: 是一个基于 Python 的自然语言处理库,它使用了 PostgreSQL 数据库存储数据。适合用于自然语言处理任务的开发和实现,特别是对于需要使用 Python 和 PostgreSQL 数据库的场景。特点是自然语言处理库、Python、PostgreSQL 数据库。
项目地址:https://gitcode.com/gh_mirrors/tra/transformers
在transformer的decoder输入中,文章中设置了100个可学习的embedding, 即object_query
self.object_query = nn.Parameter(torch.rand(100, hidden_dim))
直接计算出针对于每一个query的类别的概率和位置。推理的时候取概率大于阈值的类别,并画框即可
为什么不需要NMS后处理
在训练的过程中,文中通过匈牙利匹配避免让多个query计算后的候选框去学习一个同一个label。因此在推理的过程中,也就不会出现多个候选框都在某一个物体周围的情况
下面举例说明如何做到这一点的
假设某一帧图像中,有五个label需要学习,即2个cat,2个remote和一个couch 网络的输出会对100个候选框都打上分,此时,谁也不知道应该对100个中的哪5个进行优化。因此,我们需要逐一去计算,每一个候选框产生会产生多少loss
网络的输出会对100个候选框都打上分,此时,谁也不知道应该对100个中的哪5个进行优化。因此,我们需要逐一去计算,每一个候选框产生会产生多少loss
为了简单起见,假设网络这里候选框有只有6个,我们需要找出其中五个能和label对应上的候选框,假设经过计算六个候选框的loss分别如下
| 猫1 | 猫2 | remote1 | remote2 | couch | |
|---|---|---|---|---|---|
| 候选框1 | 0.1 | 0.8 | 0.7 | 1.5 | 1.7 |
| 候选框2 | 0.5 | 0.2 | 0.4 | 0.7 | 1.2 |
| 候选框3 | 1.0 | 0.4 | 0.8 | 0.5 | 0.9 |
| 候选框4 | 0.5 | 0.8 | 0.1 | 1.2 | 1.8 |
| 候选框5 | 0.5 | 1.6 | 1.5 | 1.2 | 0.1 |
| 候选框6 | 0.7 | 0.4 | 0.9 | 0.1 | 1.0 |
通过匈牙利匹配 scipy.optimize.linear_sum_assignment (双向最小loss匹配) 可以得到
候选框1 匹配 猫1
候选框2 匹配 猫2
候选框3 不参与匹配
候选框4 匹配 remote1
候选框5 匹配 couch
候选框6 匹配 remote2
因此,训练时期的候选框在参与优化的时候不会产生多个候选框往一个目标上去优化的问题,因此推理过程中也无需NMS处理
推荐内容
阅读全文
AI总结
huggingface/transformers: 是一个基于 Python 的自然语言处理库,它使用了 PostgreSQL 数据库存储数据。适合用于自然语言处理任务的开发和实现,特别是对于需要使用 Python 和 PostgreSQL 数据库的场景。特点是自然语言处理库、Python、PostgreSQL 数据库。
最近提交(Master分支:8 个月前 )
7bb619d7
* docs: ko: roberta.md
* fix: manual edits
* Apply suggestions from code review
Co-authored-by: Woojun Jung <46880056+jungnerd@users.noreply.github.com>
Co-authored-by: YONGSANG <71686691+4N3MONE@users.noreply.github.com>
---------
Co-authored-by: Woojun Jung <46880056+jungnerd@users.noreply.github.com>
Co-authored-by: YONGSANG <71686691+4N3MONE@users.noreply.github.com> 10 小时前
cfe66691
* Update Gemma model card
* Updated after review
* Update following review 10 小时前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容
相关推荐
查看更多
transformers
Hugging Face 的 Transformers 库是一个基于 Python 开发的自然语言处理工具包,其采用 PostgreSQL 数据库进行数据存储。该库非常适合于自然语言处理任务的研发,尤其是在需要结合 Python 编程语言与 PostgreSQL 数据库的应用环境中。其显著特征在于它是一个自然语言处理库,且支持 Python 语言及 PostgreSQL 数据库的使用。
Transformers
Transformers and related deep network architectures are summarized and implemented here.
transformers
热门开源项目
运营活动

活动日历
查看更多
直播时间 2025-04-23 19:00:00


GitTalk:国内首个微服务编排框架Juggle实战解析

直播时间 2025-04-22 18:31:56

字节AI 黑科技!从 Manus Agent 入门 Eino
直播时间 2025-04-09 14:34:18

樱花限定季|G-Star校园行&华中师范大学专场
直播时间 2025-04-07 14:51:20

樱花限定季|G-Star校园行&华中农业大学专场
直播时间 2025-03-26 14:30:09

开源工业物联实战!
目录

所有评论(0)