
CentOS7部署ELK_centos7 elk部署(1),2024年最新小白勿进
将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
Logstash:日志收集的工具,通过此工具可以实现日志内容收集及格式转换
为Elasticsearch提供系统配置
Elasticsearch在CentOS7中安装部署的时候,需要系统为其提供若干系统配置。如:应用可启动的线程数、应用可以在系统中划分的虚拟内存、应用可以最多创建多少文件等
修改限制信息
vim /etc/security/limits.conf
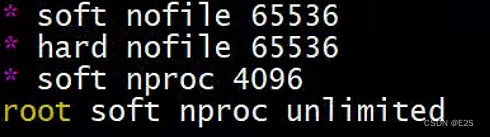
Linux默认来说,一般限制应用最多创建的文件是65535个。但是Elasticsearch至少需要65536的文件创建权限。修改后的内容为:
* soft nofile 65536
* hard nofile 65536
*代表任意用户,soft表示内存中虚拟文件(软文件),hard表示落地到磁盘的具体文件(硬文件), nofile表示权限,65536表示个数
修改线程开启限制
vim /etc/security/limits.conf
默认的Linux限制root用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启1024个线程。必须修改限制数为4096+。因为Elasticsearch至少需要4096的线程池预备。Elasticsearch在5.x版本之后,强制要求在Linux中不能使用root用户启动Elasticsearch进程。所以必须使用其他用户启动Elasticsearch进程才可以
* soft nproc 4096
root soft nproc unlimited
Linux低版本内核为线程分配的内存是128K。4.x版本的内核分配的内存更大。如果虚拟机的内存是1G,最多只能开启3000+个线程数。至少为虚拟机分配1.5G以上的内存,建议2G以上
修改完成后如下图所示:

修改系统控制权限
vim /etc/sysctl.d/99-sysctl.conf
系统控制文件是管理系统中的各种资源控制的配置文件。Elasticsearch需要开辟一个65536字节以上空间的虚拟内存。Linux默认不允许任何用户和应用直接开辟虚拟内存,新增内容为:
vm.max\_map\_count=655360
使用以下命令,让系统控制权限配置生效
sysctl -p
安装Elasticsearch
创建目录/app,将安装包上传到该目录,并解压,之后重命名文件名
mkdir -p /app
cd /app
tar -zxvf elasticsearch-7.17.0.tar.gz
mv elasticsearch-7.17.0 es
配置环境变量
vim /etc/profile
export JAVA\_HOME=/app/jdk/jdk1.8.0_171
export ROCKETMQ\_HOME=/app/rocketMQ/rocketmq-all-5.1.0-bin-release
export MAVEN\_HOME=/app/maven/apache-maven-3.9.1
export ES\_HOME=/app/es
export PATH=$ES\_HOME/bin:$MAVEN\_HOME/bin:$ROCKETMQ\_HOME/bin:$JAVA\_HOME/bin:$PATH
source /etc/profile #环境变量生效
elasticsearch默认不允许root账号运行,需要创建账户
groupadd elasticsearch
useradd -r -g elasticsearch
chown -R elasticsearch:elasticsearch /app/es/
chmod 755 /app/es/
su elasticsearch
修改配置
cd /app/es/config
修改elasticsearch.yml
mkdir /app/es/data
mkdir /app/es/logs
vim elasticsearch.yml
path.data: /app/es/data # 数据目录位置
path.logs: /app/es/logs # 日志目录位置
network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问
node.name: node-1 # 此节点在集群中的名字
http.port: 9200 # 访问端口号
cluster.initial_master_nodes: ["node-1"] # 集群中节点名称,此名称要和node.name对应
修改内存占用
vim jvm.options
-Xms512m
-Xmx512m
运行elasticsearch
su elasticsearch
cd /app/es/bin
./elasticsearch
./elasticsearch -d # 后台启动
测试
curl http://localhost:9200

安装Kibana
Kibana是一个基于WEB的Elasticsearch管理控制台
root用户创建目录/app/kibana,将安装包上传到该目录,并解压
mkdir -p /app/kibana
cd /app/kibana
tar -zxvf kibana-7.17.0.tar.gz
cd /app/kibana/kibana-7.17.0
创建日志存放目录
mkdir -p /app/kibana/logs
修改config/kibana.yml
vim config/kibana.yml
#编辑内容:
server.host: "0.0.0.0"
server.publicBaseUrl: "http://127.0.0.1:5601"
elasticsearch.hosts: ["http://127.0.0.1:9200"]
logging.dest: /app/kibana/logs/kibana.log
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

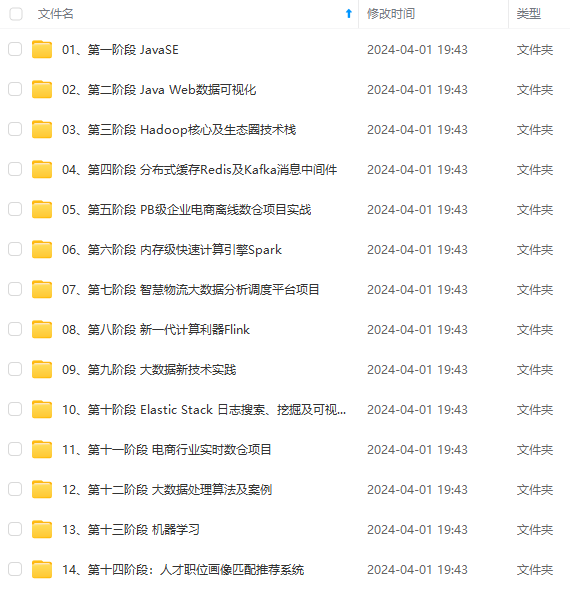
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-Hd6cXE0N-1712954362420)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)