
ZooKeeper、Eureka、Consul (1),Java之内存泄漏调试学习与总结
关于 P 的理解,我觉得是在整个系统中某个部分,挂掉了,或者宕机了,并不影响整个系统的运作或者说使用,而可用性是,某个系统的某个节点挂了,但是并不影响系统的接受或者发出请求,CAP 不可能都取,只能取其中2个原因是 如果C是第一需求的话,那么会影响A的性能,因为要数据同步,不然请求结果会有差异,但是数据同步会消耗时间,期间可用性就会降低。再如果,同事满足一致性和可用性,那么分区容错就很难保证了,也
=====
CAP理论是分布式架构中重要理论
-
一致性(Consistency) (所有节点在同一时间具有相同的数据)
-
可用性(Availability) (保证每个请求不管成功或者失败都有响应)
-
分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
关于 P 的理解,我觉得是在整个系统中某个部分,挂掉了,或者宕机了,并不影响整个系统的运作或者说使用,而可用性是,某个系统的某个节点挂了,但是并不影响系统的接受或者发出请求,CAP 不可能都取,只能取其中2个原因是 如果C是第一需求的话,那么会影响A的性能,因为要数据同步,不然请求结果会有差异,但是数据同步会消耗时间,期间可用性就会降低。
如果A是第一需求,那么只要有一个服务在,就能正常接受请求,但是对与返回结果变不能保证,原因是,在分布式部署的时候,数据一致的过程不可能想切线路那么快。
再如果,同事满足一致性和可用性,那么分区容错就很难保证了,也就是单点,也是分布式的基本核心,好了,明白这些理论,就可以在相应的场景选取服务注册与发现了
服务注册中心解决方案
==========
设计或者选型一个服务注册中心,首先要考虑的就是服务注册与发现机制。纵观当下各种主流的服务注册中心解决方案,大致可归为三类:
-
应用内:直接集成到应用中,依赖于应用自身完成服务的注册与发现,最典型的是Netflix提供的Eureka
-
应用外:把应用当成黑盒,通过应用外的某种机制将服务注册到注册中心,最小化对应用的侵入性,比如Airbnb的SmartStack,HashiCorp的Consul
-
DNS:将服务注册为DNS的SRV记录,严格来说,是一种特殊的应用外注册方式,SkyDNS是其中的代表
注1: 对于第一类注册方式,除了Eureka这种一站式解决方案,还可以基于ZooKeeper或者Etcd自行实现一套服务注册机制,这在大公司比较常见,但对于小公司而言显然性价比太低。
注2: 由于DNS固有的缓存缺陷,本文不对第三类注册方式作深入探讨。
除了基本的服务注册与发现机制,从开发和运维角度,至少还要考虑如下五个方面:
-
测活:服务注册之后,如何对服务进行测活以保证服务的可用性?
-
负载均衡:当存在多个服务提供者时,如何均衡各个提供者的负载?
-
集成:在服务提供端或者调用端,如何集成注册中心?
-
运行时依赖:引入注册中心之后,对应用的运行时环境有何影响?
-
可用性:如何保证注册中心本身的可用性,特别是消除单点故障?
主流注册中心产品
========
软件产品特性并非一成不变,如果发现功能特性有变更,欢迎评论指正

-
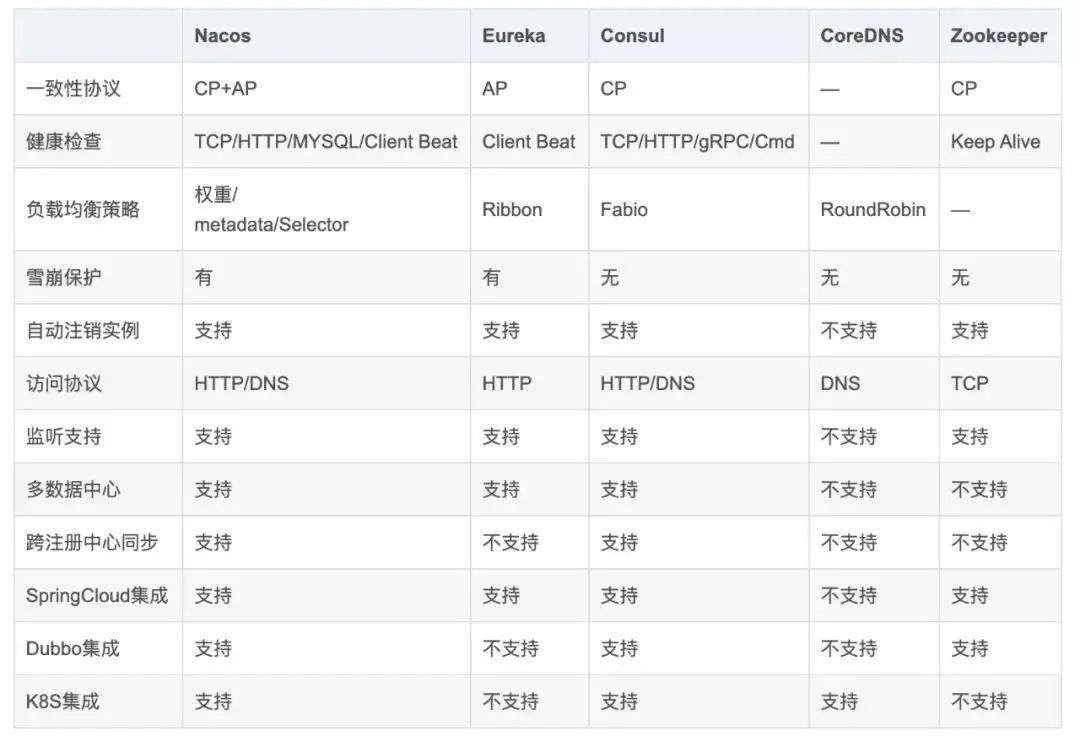
Consul是支持自动注销服务实例, 请见文档:https://www.consul.io/api-docs/agent/service,在check的 DeregisterCriticalServiceAfter 这个参数-- 感谢@超帅的菜鸟博主提供最新信息
-
新版本的Dubbo也扩展了对 Consul 的支持。参考: https://github.com/apache/dubbo/tree/master/dubbo-registry
Apache Zookeeper -> CP
与 Eureka 有所不同,Apache Zookeeper 在设计时就紧遵CP原则,即任何时候对 Zookeeper 的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性,但是 Zookeeper 不能保证每次服务请求都是可达的。
从 Zookeeper 的实际应用情况来看,在使用 Zookeeper 获取服务列表时,如果此时的 Zookeeper 集群中的 Leader 宕机了,该集群就要进行 Leader 的选举,又或者 Zookeeper 集群中半数以上服务器节点不可用(例如有三个节点,如果节点一检测到节点三挂了 ,节点二也检测到节点三挂了,那这个节点才算是真的挂了),那么将无法处理该请求。所以说,Zookeeper 不能保证服务可用性。
当然,在大多数分布式环境中,尤其是涉及到数据存储的场景,数据一致性应该是首先被保证的,这也是 Zookeeper 设计紧遵CP原则的另一个原因。
但是对于服务发现来说,情况就不太一样了,针对同一个服务,即使注册中心的不同节点保存的服务提供者信息不尽相同,也并不会造成灾难性的后果。
因为对于服务消费者来说,能消费才是最重要的,消费者虽然拿到可能不正确的服务实例信息后尝试消费一下,也要胜过因为无法获取实例信息而不去消费,导致系统异常要好(淘宝的双十一,京东的618就是紧遵AP的最好参照)。
当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30~120s,而且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。
在云部署环境下, 因为网络问题使得zk集群失去master节点是大概率事件,虽然服务能最终恢复,但是漫长的选举事件导致注册长期不可用是不能容忍的。
Spring Cloud Eureka -> AP

Spring Cloud Netflix 在设计 Eureka 时就紧遵AP原则(尽管现在2.0发布了,但是由于其闭源的原因 ,但是目前 Ereka 1.x 任然是比较活跃的)。
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)

感受:
其实我投简历的时候,都不太敢投递阿里。因为在阿里一面前已经过了字节的三次面试,投阿里的简历一直没被捞,所以以为简历就挂了。
特别感谢一面的面试官捞了我,给了我机会,同时也认可我的努力和态度。对比我的面经和其他大佬的面经,自己真的是运气好。别人8成实力,我可能8成运气。所以对我而言,我要继续加倍努力,弥补自己技术上的不足,以及与科班大佬们基础上的差距。希望自己能继续保持学习的热情,继续努力走下去。
也祝愿各位同学,都能找到自己心动的offer。
分享我在这次面试前所做的准备(刷题复习资料以及一些大佬们的学习笔记和学习路线),都已经整理成了电子文档

要继续加倍努力,弥补自己技术上的不足,以及与科班大佬们基础上的差距。希望自己能继续保持学习的热情,继续努力走下去。
也祝愿各位同学,都能找到自己心动的offer。
分享我在这次面试前所做的准备(刷题复习资料以及一些大佬们的学习笔记和学习路线),都已经整理成了电子文档
[外链图片转存中…(img-gsTYkEe5-1711160170581)]

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐



 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)