
秒杀——UNet++解读、Camvid数据集无坑实践
UNet++是一种新的通用图像分割架构,用于更准确的图像分割。UNet++由深度不同的U-Net组成,其解码器通过重新设计的跳跃路径在相同分辨率上密集连接,旨在解决U-Net的两个关键挑战:1)最佳架构的深度未知2)跳跃连接设计过于限制。
一、简介
Unet++:《UNet++: A Nested U-Net Architecture for Medical Image Segmentation》
作者对Unet和Unet++的理解:研习U-Net
本文将介绍Unet++网络,在pytorch框架上复现Unet++,并在Camvid数据集上进行训练。
UNet++是一种新的通用图像分割架构,用于更准确的图像分割。UNet++由深度不同的U-Net组成,其解码器通过重新设计的跳跃路径在相同分辨率上密集连接,旨在解决U-Net的两个关键挑战:
1)最佳架构的深度未知
2)跳跃连接设计过于限制。
二、Unet++网络
1.Dense connection
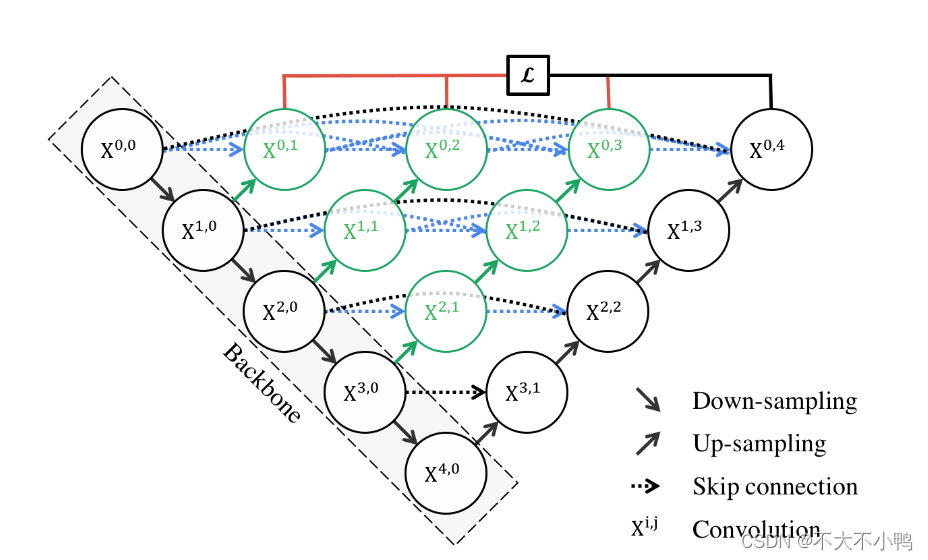
Unet++继承了Unet的结构,同时又借鉴了DenseNet的稠密连接方式(图1中各种分支)。实际上,也就意味着有了两者得优点了。
像DenseNet一样,通过密集连接将各层联系在一起,使得分割效果更好。在实际分割中,每次下采样都可能损失一些细节特征。Unet++采用了密集连接的方式,保留了每一层的细节信息和全局信息,实现了更好的分割效果。
这个网络架构,一顿听下来,可能会懵了,就这么个分割网络,都能说这么久,要我说就放个结构图,说这个网络很牛逼,再告知一下代码在哪儿,谢谢大家就完事儿了。
但就像文章一开始提到得,
Unet++解决U-Net的两个关键挑战:
1)最佳架构的深度未知
2)跳跃连接设计过于限制。
2.我的理解
以下是我的理解,希望对后来者有帮助!
① U-Net++的嵌套结构就相当对应小学(L1)、初中(L2)、高中(L3)、大学(L4)学的数学知识。每个结构都包含了更小的结构,比如大学(L4)包含了高中(L3),其实也包含了初中(L2)和小学(L1)
② 关于文中说的“剪枝”那部分,对于U-Net++训练中的反向传播,相当于你学到后面的知识会影响你前面学过的知识,比如在大学(L4)学的线性代数,会帮助你理解初中(L2)学了但是没学好的方程组;而当U-Net++进行测试的时候(即只有前向传播),因为L2和L4的精度差不多,但L4会花更多的时间,所以用L2就能解决问题。对应到前面的例子中就是对于求解多个未知数,可以只用 初中 的方程组就能搞定,无需用上 大学 线代中的矩阵知识了。所以,训练的时候不能剪枝,但预测的时候可以剪枝!
deep supervision
当然,简单的将各个模块连接起来是会实现很好的效果。而我们又能发现,一个Unet++其实是很多个不同深度的Unet++叠加。那么,每一个深度的Unet++是不是就都可以输出一个loss?答案自然是可以的。
所以,作者提出了deep supervision,也就是监督每一个深度的Unet++的输出,通过一定的方式来叠加Loss(比如加权的方式),这样就得到了一个经由1、2、3、4层的Unet++的加权Loss(图2 不同深度Unet++融合)。
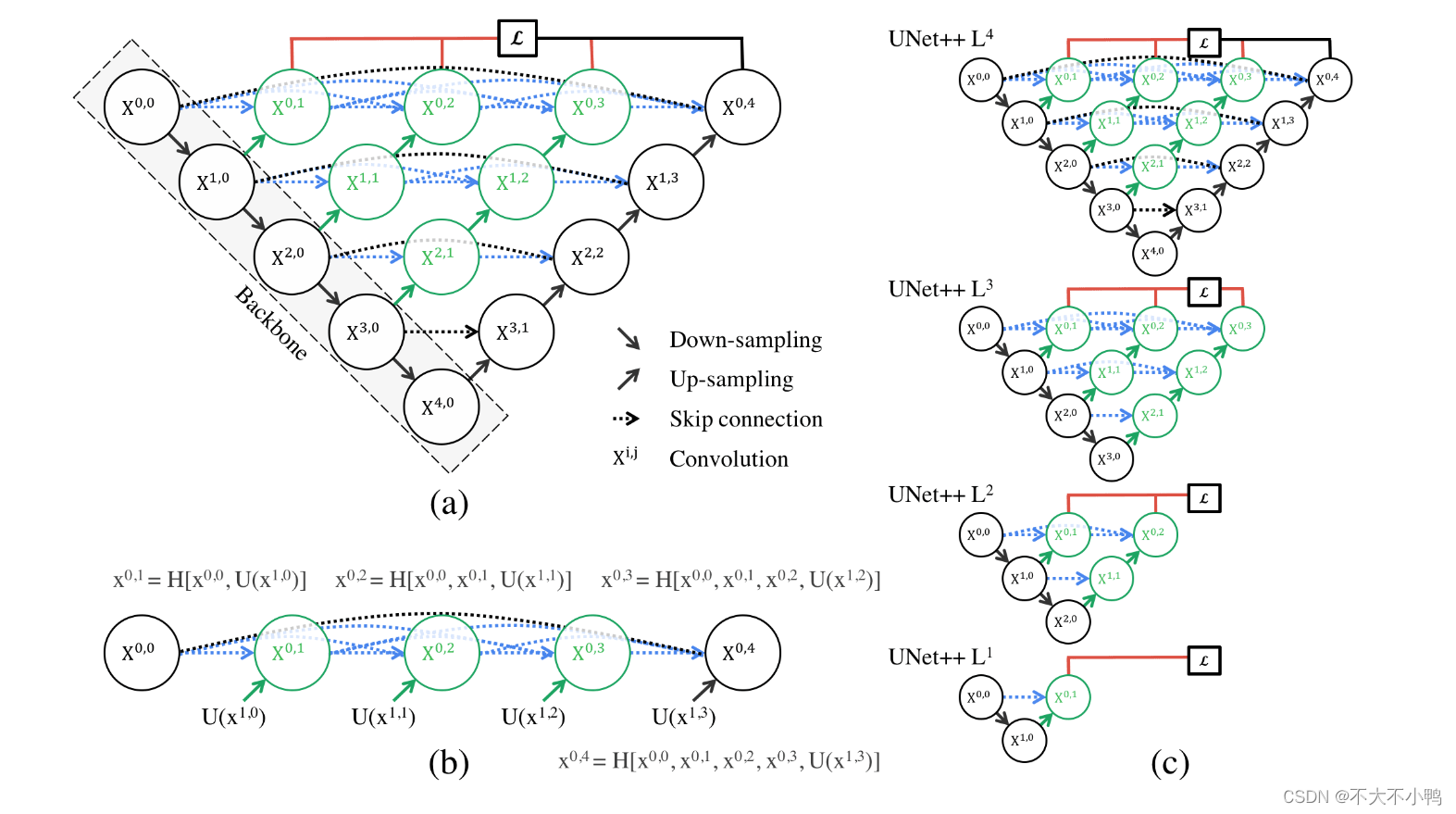
那么,deep supervision又有什么用呢?-剪枝
训练的时候参数为9M,但实际上应用到生活上(比如移动终端手机等)预测只要0.5M
可以《二.2我的理解》重新体会这个过程
既然Unet++由多个不同深度的Unet++叠加起来,那么随意去掉一层,前向传播的梯度不会受到任何变化,但你发现Unet++第三个输出的效果和第四个输出效果差不多时,那就可以毫不犹豫删去4层深度的Unet++。比如,直接删去图3中棕色部分,就可以实现剪枝。这样,就得到了更加轻量化的网络。


先看看L1~L4的网络参数量,差了好多,L1只有0.1M,而L4有9M,也就是理论上如果L1的结果我是满意的,那么模型可以被剪掉的参数达到98.8%。不过根据我们的四个数据集,L1的效果并不会那么好,因为太浅了嘛。但是其中有三个数据集显示L2的结果和L4已经非常接近了,也就是说对于这三个数据集,在测试阶段,我们不需要用9M的网络,用半M的网络足够了。
三、基于 UNet++ 的Camvid数据集实战代码案例(无坑实践)
1、数据集准备(CamVidDataset.py)
a.从头到尾学会数据集处理:
数据集使用Camvid数据集,可在CamVid数据集的创建和使用-pytorch中参考构建方法。
b.直接下载作者原格式数据集:
链接:https://pan.baidu.com/s/1Kk_t-EugzyZdJuesDaFHQA?pwd=yumi
提取码:yumi
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
from torch.utils.data import Dataset, DataLoader, random_split
import warnings
warnings.filterwarnings("ignore")
from PIL import Image
import torchvision.transforms as transforms
torch.manual_seed(17)
class CamVidDataset(torch.utils.data.Dataset):
def __init__(self, images_dir, masks_dir):
self.transform = transforms.Compose([
transforms.Resize((240, 240)),
transforms.CenterCrop(224),
# 将PIL图像转换为Tensor之前的变换
transforms.ToTensor(), # 将图像转换为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), # 归一化
])
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
def __getitem__(self, i):
# read data
image = Image.open(self.images_fps[i]).convert('RGB')
mask = Image.open(self.masks_fps[i]).convert('RGB')
# 应用图像变换
image = self.transform(image)
# 将掩码转换为Tensor,并应用相同的变换
mask = transforms.ToTensor()(mask)
mask = transforms.Resize((240, 240))(mask)
mask = transforms.CenterCrop(224)(mask)
# 将掩码的数据类型转换为长整型
mask = mask.to(torch.long)
return image, mask[0] # 返回图像和掩码的Tensor
def __len__(self):
return len(self.ids)
2、搭建U++模型(UnetPlusPlus.py)
import torch
import torch.nn as nn
class ContinusParalleConv(nn.Module):
# 一个连续的卷积模块,包含BatchNorm 在前 和 在后 两种模式
def __init__(self, in_channels, out_channels, pre_Batch_Norm=True):
super(ContinusParalleConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
if pre_Batch_Norm:
self.Conv_forward = nn.Sequential(
nn.BatchNorm2d(self.in_channels),
nn.ReLU(),
nn.Conv2d(self.in_channels, self.out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(self.out_channels, self.out_channels, 3, padding=1))
else:
self.Conv_forward = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(self.out_channels, self.out_channels, 3, padding=1),
nn.BatchNorm2d(self.out_channels),
nn.ReLU())
def forward(self, x):
x = self.Conv_forward(x)
return x
class UnetPlusPlus(nn.Module):
def __init__(self, num_classes, deep_supervision=False):
super(UnetPlusPlus, self).__init__()
self.num_classes = num_classes
self.deep_supervision = deep_supervision
self.filters = [64, 128, 256, 512, 1024]
self.CONV3_1 = ContinusParalleConv(512 * 2, 512, pre_Batch_Norm=True)
self.CONV2_2 = ContinusParalleConv(256 * 3, 256, pre_Batch_Norm=True)
self.CONV2_1 = ContinusParalleConv(256 * 2, 256, pre_Batch_Norm=True)
self.CONV1_1 = ContinusParalleConv(128 * 2, 128, pre_Batch_Norm=True)
self.CONV1_2 = ContinusParalleConv(128 * 3, 128, pre_Batch_Norm=True)
self.CONV1_3 = ContinusParalleConv(128 * 4, 128, pre_Batch_Norm=True)
self.CONV0_1 = ContinusParalleConv(64 * 2, 64, pre_Batch_Norm=True)
self.CONV0_2 = ContinusParalleConv(64 * 3, 64, pre_Batch_Norm=True)
self.CONV0_3 = ContinusParalleConv(64 * 4, 64, pre_Batch_Norm=True)
self.CONV0_4 = ContinusParalleConv(64 * 5, 64, pre_Batch_Norm=True)
self.stage_0 = ContinusParalleConv(3, 64, pre_Batch_Norm=False)
self.stage_1 = ContinusParalleConv(64, 128, pre_Batch_Norm=False)
self.stage_2 = ContinusParalleConv(128, 256, pre_Batch_Norm=False)
self.stage_3 = ContinusParalleConv(256, 512, pre_Batch_Norm=False)
self.stage_4 = ContinusParalleConv(512, 1024, pre_Batch_Norm=False)
self.pool = nn.MaxPool2d(2)
self.upsample_3_1 = nn.ConvTranspose2d(in_channels=1024, out_channels=512, kernel_size=4, stride=2, padding=1)
self.upsample_2_1 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4, stride=2, padding=1)
self.upsample_2_2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4, stride=2, padding=1)
self.upsample_1_1 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1)
self.upsample_1_2 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1)
self.upsample_1_3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1)
self.upsample_0_1 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)
self.upsample_0_2 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)
self.upsample_0_3 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)
self.upsample_0_4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1)
# 分割头
self.final_super_0_1 = nn.Sequential(
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, self.num_classes, 3, padding=1),
)
self.final_super_0_2 = nn.Sequential(
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, self.num_classes, 3, padding=1),
)
self.final_super_0_3 = nn.Sequential(
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, self.num_classes, 3, padding=1),
)
self.final_super_0_4 = nn.Sequential(
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, self.num_classes, 3, padding=1),
)
def forward(self, x):
x_0_0 = self.stage_0(x)
x_1_0 = self.stage_1(self.pool(x_0_0))
x_2_0 = self.stage_2(self.pool(x_1_0))
x_3_0 = self.stage_3(self.pool(x_2_0))
x_4_0 = self.stage_4(self.pool(x_3_0))
x_0_1 = torch.cat([self.upsample_0_1(x_1_0), x_0_0], 1)
x_0_1 = self.CONV0_1(x_0_1)
x_1_1 = torch.cat([self.upsample_1_1(x_2_0), x_1_0], 1)
x_1_1 = self.CONV1_1(x_1_1)
x_2_1 = torch.cat([self.upsample_2_1(x_3_0), x_2_0], 1)
x_2_1 = self.CONV2_1(x_2_1)
x_3_1 = torch.cat([self.upsample_3_1(x_4_0), x_3_0], 1)
x_3_1 = self.CONV3_1(x_3_1)
x_2_2 = torch.cat([self.upsample_2_2(x_3_1), x_2_0, x_2_1], 1)
x_2_2 = self.CONV2_2(x_2_2)
x_1_2 = torch.cat([self.upsample_1_2(x_2_1), x_1_0, x_1_1], 1)
x_1_2 = self.CONV1_2(x_1_2)
x_1_3 = torch.cat([self.upsample_1_3(x_2_2), x_1_0, x_1_1, x_1_2], 1)
x_1_3 = self.CONV1_3(x_1_3)
x_0_2 = torch.cat([self.upsample_0_2(x_1_1), x_0_0, x_0_1], 1)
x_0_2 = self.CONV0_2(x_0_2)
x_0_3 = torch.cat([self.upsample_0_3(x_1_2), x_0_0, x_0_1, x_0_2], 1)
x_0_3 = self.CONV0_3(x_0_3)
x_0_4 = torch.cat([self.upsample_0_4(x_1_3), x_0_0, x_0_1, x_0_2, x_0_3], 1)
x_0_4 = self.CONV0_4(x_0_4)
if self.deep_supervision:
out_put1 = self.final_super_0_1(x_0_1)
out_put2 = self.final_super_0_2(x_0_2)
out_put3 = self.final_super_0_3(x_0_3)
out_put4 = self.final_super_0_4(x_0_4)
return [out_put1, out_put2, out_put3, out_put4]
else:
return self.final_super_0_4(x_0_4)
if __name__ == "__main__":
print("deep_supervision: False")
deep_supervision = False
device = torch.device('cpu')
inputs = torch.randn((1, 3, 224, 224)).to(device)
model = UnetPlusPlus(num_classes=3, deep_supervision=deep_supervision).to(device)
outputs = model(inputs)
print(outputs.shape)
print("deep_supervision: True")
deep_supervision = True
model = UnetPlusPlus(num_classes=3, deep_supervision=deep_supervision).to(device)
outputs = model(inputs)
for out in outputs:
print(out.shape)
3、模型训练(mytrain.py)
# 导入库
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import torch
import pandas as pd
from torch import optim
from torch.utils.data import DataLoader
import warnings
warnings.filterwarnings("ignore")
import numpy as np
from torch import nn
from CamVidDataset import CamVidDataset
from UnetPlusPlus import UnetPlusPlus
import time
torch.manual_seed(17)
# 设置数据集路径
DATA_DIR = r'CamVid' # 根据自己的路径来设置
x_train_dir = os.path.join(DATA_DIR, 'train')
y_train_dir = os.path.join(DATA_DIR, 'train_labels')
x_valid_dir = os.path.join(DATA_DIR, 'val')
y_valid_dir = os.path.join(DATA_DIR, 'val_labels')
batch_size = 4
num_classes = 33
learning_rate = 0.01
epochs_num = 50
train_dataset = CamVidDataset(
x_train_dir,
y_train_dir,
)
val_dataset = CamVidDataset(
x_valid_dir,
y_valid_dir,
)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
model = UnetPlusPlus(num_classes=num_classes).cuda()
# 载入预训练模型(可以不使用从头开始训练)
# model.load_state_dict(torch.load(r"checkpoints/Unet++_25.pth"), strict=False)
# 损失函数选用多分类交叉熵损失函数
lossf = nn.CrossEntropyLoss(ignore_index=255)
# 选用adam优化器来训练
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1, last_epoch=-1)
## 计算正确率等
class MetricsAccumulator:
def __init__(self):
self.loss_sum = 0.0
self.acc_sum = 0.0
self.num_examples = 0
self.num_predictions = 0
def add(self, loss, acc, num_examples, num_predictions):
self.loss_sum += loss
self.acc_sum += acc
self.num_examples += num_examples
self.num_predictions += num_predictions
def get_average_loss(self):
return self.loss_sum / self.num_examples
def get_average_accuracy(self):
return self.acc_sum / self.num_predictions
# 在每个 epoch 结束时评估模型的函数
def evaluate_model(model, data_loader, device):
model.eval() # 将模型设置为评估模式
correct, total = 0, 0
with torch.no_grad():
for features, labels in data_loader:
features, labels = features.to(device), labels.to(device)
outputs = model(features)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return correct / total
def mytrain(net, train_iter, test_iter, loss, optimizer, num_epochs, scheduler):
# 初始化变量
num_batches = len(train_iter)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
loss_list = []
train_acc_list = []
test_acc_list = []
epochs_list = []
time_list = []
# 在需要计时的地方创建一个计时器对象
timer = time.time()
metric = MetricsAccumulator()
for epoch in range(num_epochs):
net.train() # 将模型设置为训练模式
train_loss, correct, total = 0.0, 0, 0
for i, (features, labels) in enumerate(train_iter):
# 在需要计算时间差的地方,记录当前时间
start_time = time.time()
features, labels = features.to(device), labels.to(device)
optimizer.zero_grad() # 梯度清零
outputs = net(features) # 前向传播
loss_value = loss(outputs, labels) # 计算损失
loss_value.backward() # 反向传播
optimizer.step() # 更新参数
train_loss += loss_value.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
train_accuracy = correct / total
# 打印训练信息
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {train_loss / num_batches:.4f}, Accuracy: {train_accuracy:.4f}')
scheduler.step() # 更新学习率
train_loss_avg = metric.get_average_loss()
train_acc_avg = metric.get_average_accuracy()
# 计算验证集上的准确率
test_accuracy = evaluate_model(net, test_iter, device)
print(
f"epoch {epoch + 1} --- loss {train_loss_avg:.3f} --- train acc {train_acc_avg:.3f} --- test acc {test_accuracy:.3f} --- cost time {timer.sum()}")
# ---------保存训练数据---------------
df = pd.DataFrame()
loss_list.append(train_loss_avg)
train_acc_list.append(train_acc_avg)
test_acc_list.append(test_accuracy)
epochs_list.append(epoch)
time_list.append(timer.sum())
# 在需要计算时间差的地方,再次记录当前时间,并计算时间差
elapsed_time = time.time() - start_time
df['epoch'] = epochs_list
df['loss'] = loss_list
df['train_acc'] = train_acc_list
df['test_acc'] = test_acc_list
df['time'] = elapsed_time
df.to_excel("savefile/Unet++_camvid1.xlsx")
# ----------------保存模型-------------------
if np.mod(epoch + 1, 5) == 0:
torch.save(model.state_dict(), f'checkpoints/Unet++_{epoch + 1}.pth')
mytrain(model, train_loader, val_loader, lossf, optimizer, epochs_num, scheduler)
4、全部代码格式:
5、训练结果:


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)