ChaosBlade for k8s
阿里的混沌测试平台在K8s上的搭建和演练。
1. 安装部署
1.1 Kubernetes
1.1.1 环境准备
三台虚拟机 master node1 node2
系统CentOS7.9 内存4G 处理器4 硬盘20G+100G
1.1.2 安装kubernetes所有虚机的配置
- 集群中所有主机设置主机名,并添加到/etc/hosts里
172.20.70.92:
# hostnamectl set-hostname master
# bash
# vim /etc/hosts
172.20.70.92 master
172.20.70.84 node1
172.20.70.69 node2
172.20.70.84:
# hostnamectl set-hostname node1
# bash
# vim /etc/hosts
172.20.70.92 master
172.20.70.84 node1
172.20.70.69 node2
172.20.70.69:
# hostnamectl set-hostname node2
# bash
# vim /etc/hosts
172.20.70.92 master
172.20.70.84 node1
172.20.70.69 node2
- 关闭swap
[root@master ~]# swapoff -a // 临时关闭
[root@master ~]# vim /etc/fstab
# 注释掉swpa分区
#/dev/mapper/centos-swap swap swap defaults 0 0
- 关闭防火墙
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
- 关闭Selinux
[root@master ~]# setenforce 0
[root@master ~]# sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
- 配置NTP时间同步服务
# 安装ntp服务
[root@master ~]# yum -y install ntp
# 设置为开机自启动
[root@master ~]# systemctl enable ntpd
# 启动ntp服务
[root@master ~]# systemctl start ntpd
# 从时间服务器同步一次时间
[root@master ~]# ntpdate -u 172.20.64.111
# 将系统时间同步到硬件时钟
[root@master ~]# hwclock --systohc
- 添加网桥过滤和地址转发功能
[root@master ~]# cat > /etc/sysctl.d/kubernetes.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
[root@master ~]# sysctl --system // 执行生效
[root@master ~]# modprobe br_netfilter // 加载网桥过滤模块
[root@master ~]# lsmod | grep br_netfilter // 查看网桥过滤模块是否加载成功
br_netfilter 22256 0
bridge 151336 1 br_netfilter
- 配置ipvs功能
# 安装ipset和ipvsadm
[root@master ~]# yum install ipset ipvsadm -y
# 添加需要加载的模块写入脚本文件
[root@master ~]# vim /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
# 执行脚本文件
[root@master ~]# /bin/bash /etc/sysconfig/modules/ipvs.modules
# 查看对应的模块是否加载成功
[root@master ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
ip_vs_sh 12688 0
ip_vs_wrr 12697 0
ip_vs_rr 12600 0
ip_vs 145458 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 139264 1 ip_vs
libcrc32c 12644 3 xfs,ip_vs,nf_conntrack
- 下载k8s
# 1、配置k8s源
[root@master ~]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
[root@master ~]# yum clean all && yum makecache
# 2、安装 kubeadm,kubelet 和 kubectl
[root@master ~]# yum install kubelet kubeadm kubectl -y
[root@master ~]# kubeadm version // 验证是否安装成功
kubeadm version: &version.Info{Major:"1", Minor:"24", GitVersion:"v1.24.2", GitCommit:"f66044f4361b9f1f96f0053dd46cb7dce5e990a8", GitTreeState:"clean", BuildDate:"2022-06-15T14:20:54Z", GoVersion:"go1.18.3", Compiler:"gc", Platform:"linux/amd64"}
# 3、配置kubelet
[root@master ~]# cat <<EOF > /etc/sysconfig/kubelet
KUBE_PROXY_MODE="ipvs"
EOF
# 4、设置 kubelet开机自启动
[root@master ~]# systemctl enable kubelet
- 安装并配置containerd容器
# 1、添加源
[root@master ~]# wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo --no-check-certificate
# 2、修改源
[root@master ~]# sed -i 's@download.docker.com@mirrors.tuna.tsinghua.edu.cn/docker-ce@g' /etc/yum.repos.d/docker-ce.repo
# 3、安装containerd
[root@master ~]# yum install containerd -y
# 4、初始化默认配置并修改
[root@master ~]# containerd config default | tee /etc/containerd/config.toml
# 5、修改containerd配置更改cgroup
[root@master ~]# sed -i "s#SystemdCgroup\ \=\ false#SystemdCgroup\ \=\ true#g" /etc/containerd/config.toml
# 6、修改镜像源
[root@master ~]# sed -i "s#registry.k8s.io#registry.aliyuncs.com/google_containers#g" /etc/containerd/config.toml
# 7、配置crictl
[root@master ~]# cat <<EOF | tee /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
# 8、启动containerd
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart containerd
[root@master ~]# systemctl enable containerd
# 9、验证是否可用
[root@master ~]# crictl pull nginx:alpine
[root@master ~]# crictl rmi nginx:alpine
[root@master ~]# crictl images
1.1.3 只在master虚机的配置
- 初始化k8s
# 1、生成配置文件
[root@master ~]# kubeadm config print init-defaults > kubeadm.yml
# 2、修改配置文件
[root@master ~]# vim kubeadm.yml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 172.20.70.92 // 修改为对应ip
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: master // 修改为对应hostname
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers // 修改为阿里云源
kind: ClusterConfiguration
kubernetesVersion: 1.24.2 // 修改为对应版本
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
# 3、查看所需镜像列表
[root@master ~]# kubeadm config images list --config kubeadm.yml
registry.aliyuncs.com/google_containers/kube-apiserver:v1.24.0
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.24.0
registry.aliyuncs.com/google_containers/kube-scheduler:v1.24.0
registry.aliyuncs.com/google_containers/kube-proxy:v1.24.0
registry.aliyuncs.com/google_containers/pause:3.7
registry.aliyuncs.com/google_containers/etcd:3.5.3-0
registry.aliyuncs.com/google_containers/coredns:v1.8.6
# 4、拉取镜像
[root@master ~]# kubeadm config images pull --config kubeadm.yml
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.24.2
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.24.2
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.24.2
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.24.2
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.7
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.3-0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.8.6
# 5、根据配置文件启动 kubeadm 初始化 k8s
[root@master ~]# kubeadm init --config=kubeadm.yml --upload-certs --v=6
# 启动成功(加入集群的join命令,需要复制记录下载)
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.2.1:6443 --token ochspx.15in9qkiu5z8tx2y \
--discovery-token-ca-cert-hash sha256:1f31202107af96a07df9fd78c3aa9bb44fd40076ac123e8ff28d6ab691a02a31
# 6、开启集群
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 7、修改变量
[root@master ~]# vim /root/.bash_profile
export KUBECONFIG=/etc/kubernetes/admin.conf // 超级用户变量
alias k=kubectl // 设置别名
source <(kubectl completion bash) //设置kubectl命令补齐功能
[root@master ~]# source /root/.bash_profile
- 设定kubeletl网络(主节点部署)
# 1、下载kube-flannel.yml
[root@master ~]# wget https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
// 网络不通的话直接新建kube-flannel.yml
---
kind: Namespace
apiVersion: v1
metadata:
name: kube-flannel
labels:
k8s-app: flannel
pod-security.kubernetes.io/enforce: privileged
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: flannel
name: flannel
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- networking.k8s.io
resources:
- clustercidrs
verbs:
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
labels:
k8s-app: flannel
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-flannel
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: flannel
name: flannel
namespace: kube-flannel
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-flannel
labels:
tier: node
k8s-app: flannel
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-flannel
labels:
tier: node
app: flannel
k8s-app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni-plugin
image: docker.io/flannel/flannel-cni-plugin:v1.2.0
command:
- cp
args:
- -f
- /flannel
- /opt/cni/bin/flannel
volumeMounts:
- name: cni-plugin
mountPath: /opt/cni/bin
- name: install-cni
image: docker.io/flannel/flannel:v0.22.3
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: docker.io/flannel/flannel:v0.22.3
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: EVENT_QUEUE_DEPTH
value: "5000"
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
- name: xtables-lock
mountPath: /run/xtables.lock
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni-plugin
hostPath:
path: /opt/cni/bin
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
- name: xtables-lock
hostPath:
path: /run/xtables.lock
type: FileOrCreate
# 2、使用配置文件安装组件
[root@master ~]# kubectl apply -f kube-flannel.yml
[root@master ~]# kubectl get pod --all-namespaces
//必须所有的容器都是Running,如果kube-flannel起不来,那么就用kubectl describe pod kube-flannel-ds-hv7cr -n kube-flannel命令查看pod起不来的原因
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-hv7cr 1/1 Running 0 3h33m
kube-flannel kube-flannel-ds-lpwkd 1/1 Running 0 3h26m
kube-system coredns-66f779496c-7qvfx 1/1 Running 0 3h36m
kube-system coredns-66f779496c-bwlm8 1/1 Running 0 3h36m
kube-system etcd-master 1/1 Running 2 3h37m
kube-system kube-apiserver-master 1/1 Running 2 3h37m
kube-system kube-controller-manager-master 1/1 Running 0 3h37m
kube-system kube-proxy-l9fgm 1/1 Running 0 3h36m
kube-system kube-proxy-z45qq 1/1 Running 0 3h26m
kube-system kube-scheduler-master 1/1 Running 2 3h37m
# 查看通信状态
[root@master ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66f779496c-7qvfx 1/1 Running 0 3h38m
coredns-66f779496c-bwlm8 1/1 Running 0 3h38m
etcd-master 1/1 Running 2 3h39m
kube-apiserver-master 1/1 Running 2 3h39m
kube-controller-manager-master 1/1 Running 0 3h39m
kube-proxy-l9fgm 1/1 Running 0 3h38m
kube-proxy-z45qq 1/1 Running 0 3h28m
kube-scheduler-master 1/1 Running 2 3h39m
# 获取主节点的状态
[root@master ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy ok
# 查看节点状态(如果没添加节点,此时只有主节点)
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane 4h26m v1.28.2
node1 Ready <none> 34m v1.28.2
node2 Ready <none> 5m43s v1.28.2
1.1.4 子节点加入集群
# 1、在子节点上执行join命令
[root@node1 ~]# kubeadm join 172.20.70.92:6443 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:39a31114e4df287db6a763d6fb7ec40773184a39844e25d7c0e2a12cbe6e5541
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
# 2、在主节点查看集群中节点的状态(必须要都为Ready状态)
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane 4h26m v1.28.2
node1 Ready <none> 34m v1.28.2
node2 Ready <none> 5m43s v1.28.2
# 默认的 join token有效期限为24小时,当过期后该 token 就不能用了,这时需要重新创建 token,创建新的join token需要在主节点上创建,创建命令如下:
[root@master ~]# kubeadm token create --print-join-command
1.1.5 删除子节点
# 1、在主节点上操作
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets
kubectl delete node <node name>
# 2、在子节点上操作
kubeadm reset
rm -rf /etc/cni/net.d/
rm -rf /root/.kube/config
ifconfig cni0 down
ip link delete cni0
ifconfig flannel.1 down
ip link delete flannel.1
1.1.6 安装Metrics Server(核心指标监控工具)
# 1、安装Metrics Server
[root@master ~]# vim metrics-server.yml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.4
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
[root@master ~]# kubectl apply -f metrics-server.yml
# 2、查看metrics server pod是否运行正常
[root@master ~]# kubectl get pods -n=kube-system |grep metrics
metrics-server-794bb5d868-zxqvm 1/1 Running 0 8m41s
# 3、使用kubectl top 命令查看pod的cpu ,内存占比
[root@master ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 151m 3% 868Mi 23%
node1 38m 0% 1290Mi 34%
node2 33m 0% 1135Mi 30%
1.1.7 部署k8s dashboard(这里使用kubepi)
# 1、安装kubepi
[root@master ~]# kubectl apply -f https://raw.githubusercontent.com/KubeOperator/KubePi/master/docs/deploy/kubectl/kubepi.yaml
// 网络不通的话直接新建
apiVersion: v1
kind: ServiceAccount
metadata:
name: kubepi-user
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kubepi-user
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: kubepi-user
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kubepi-user
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: v1
kind: Secret
metadata:
name: kubepi-user
namespace: kube-system
annotations:
kubernetes.io/service-account.name: "kubepi-user"
type: kubernetes.io/service-account-token
---
apiVersion: v1
kind: Service
metadata:
name: kubepi
namespace: kube-system
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
selector:
app.kubernetes.io/name: kubepi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubepi
namespace: kube-system
labels:
app.kubernetes.io/name: kubepi
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: kubepi
template:
metadata:
labels:
app.kubernetes.io/name: kubepi
spec:
containers:
- name: kubepi
image: kubeoperator/kubepi-server:latest
imagePullPolicy: Always
ports:
- containerPort: 80
protocol: TCP
securityContext:
privileged: true
# kubectl apply -f kubepi.yaml
# 2、获取NodeIp
[root@master ~]# export NODE_IP=$(kubectl get nodes -o jsonpath="{.items[0].status.addresses[0].address}")
# 3、获取 NodePort
[root@master ~]# export NODE_PORT=$(kubectl -n kube-system get services kubepi -o jsonpath="{.spec.ports[0].nodePort}")
# 4、获取 Address
[root@master ~]# echo http://$NODE_IP:$NODE_PORT
# 用户名: admin
# 密码: kubepi
# 5、集群导入
# 获取 apiserver 地址
[root@master ~]# cat ~/.kube/config | grep server: | awk '{print $2}'
# 获取token
[root@master ~]# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep kubepi-user | awk '{print $1}') | grep token: | awk '{print $2}'
1.2 安装helm
# 1、解压安装包
tar -zxvf helm-v3.3.1-linux-amd64.tar.gz
# 2、复制指令
cp linux-amd64/helm /usr/local/bin
# 3、验证是否安装成功
helm version
1.3 安装ChaosBalde-Operator
# 1、为chaosblade创建一个 namespace
[root@master ~]# kubectl create namespace chaosblade
namespace/chaosblade created
# 2、安装 ChaosBlade-Operator
# 安装最新版本,低版本在演练时存在问题
[root@master ~]# helm repo add chaosblade-io https://chaosblade-io.github.io/charts
[root@master ~]# helm install chaosblade chaosblade-io/chaosblade-operator --namespace chaosblade --set webhook.enable=true // --set webhook.enable=true 是为了 Pod 文件系统 I/O 故障实验
# 3、查看安装结果
[root@master ~]# helm ls --all-namespaces
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
chaosblade chaosblade 1 2023-11-06 11:28:33.615048287 +0800 CST deployed chaosblade-operator-1.7.2 1.7.2
[root@master ~]# kubectl get pod -n chaosblade
NAME READY STATUS RESTARTS AGE
chaosblade-operator-9d5ff7d9f-rv4l5 1/1 Running 0 62s
chaosblade-tool-q8j5d 1/1 Running 0 61s
chaosblade-tool-rxzlj 1/1 Running 0 62s
chaosblade-tool-svbsp 1/1 Running 0 61s
1.4 安装ChaosBalde-Box
[root@master ~]# helm install chaosblade-box chaosblade-box-1.0.3.tgz --namespace chaosblade --set spring.datasource.password=DATASOURCE_PASSWORD
NAME: chaosblade-box
LAST DEPLOYED: Mon Oct 30 15:14:13 2023
NAMESPACE: chaosblade
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Thank you for using chaosblade-box.
[root@master ~]# kubectl get po -n chaosblade
NAME READY STATUS RESTARTS AGE
chaosblade-box-678c848b5f-gn68l 1/1 Running 0 2m36s
chaosblade-box-mysql-79fd97f685-zd46b 1/1 Running 0 2m36s
chaosblade-operator-9d5ff7d9f-rv4l5 1/1 Running 1 (2d23h ago) 3d4h
chaosblade-tool-q8j5d 1/1 Running 1 (2d23h ago) 3d4h
chaosblade-tool-rxzlj 1/1 Running 1 (2d23h ago) 3d4h
chaosblade-tool-svbsp 1/1 Running 1 (2d23h ago) 3d4h
guestbook-v1-5457d6dd58-b4xfk 1/1 Running 0 47h
guestbook-v1-5457d6dd58-lqshp 1/1 Running 0 47h
guestbook-v1-5457d6dd58-n7zdm 1/1 Running 0 47h
redis-master-77456ff7b4-8j8ld 1/1 Running 0 47h
redis-slave-5698767898-nfwr4 1/1 Running 0 47h
redis-slave-5698767898-rcdnq 1/1 Running 0 47h
[root@master ~]# export NODE_PORT=$(kubectl -n chaosblade get services chaosblade-box -o jsonpath="{.spec.ports[0].nodePort}")
[root@master ~]# export NODE_IP=$(kubectl get nodes -o jsonpath="{.items[0].status.addresses[0].address}")
[root@master ~]# echo http://$NODE_IP:$NODE_PORT
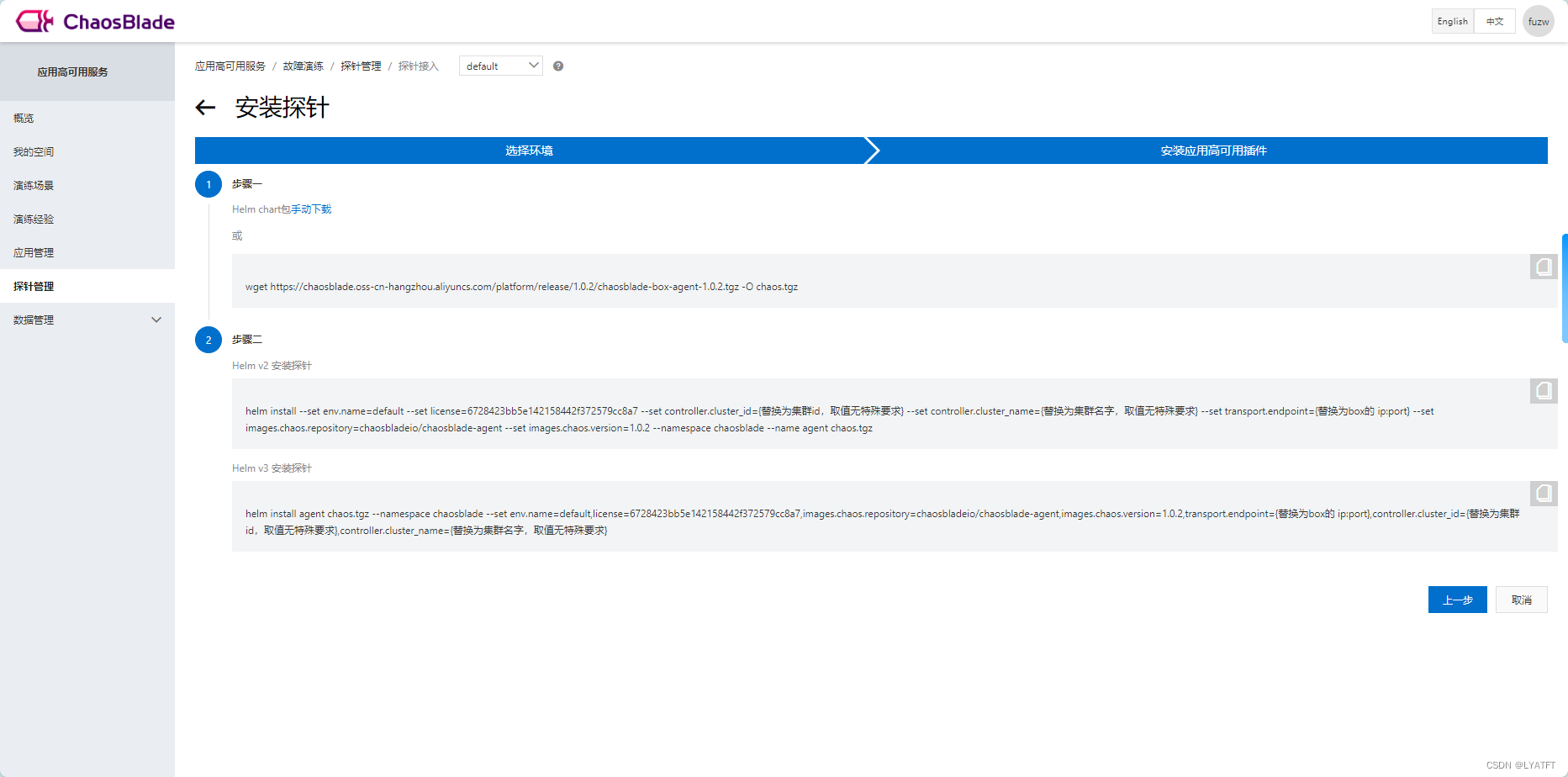
1.5 安装探针
在 ChaosBalde-Box页面获取安装k8s探针的方法

[root@master ~]# helm install agent chaos.tgz --namespace chaosblade --set env.name=default,license=6728423bb5e142158442f372579cc8a7,images.chaos.repository=chaosbladeio/chaosblade-agent,images.chaos.version=1.0.2,transport.endpoint=172.20.70.92:30499,controller.cluster_id=kubernetes,controller.cluster_name=kubernetes-admin@kubernetes
# 获取集群id和集群名称的方法
[root@master ~]# kubectl config current-context
kubernetes-admin@kubernetes
[root@master ~]# kubectl cluster-info
Kubernetes control plane is running at https://172.20.70.92:6443
CoreDNS is running at https://172.20.70.92:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
# 查看安装结果
[root@master ~]# helm ls --all-namespaces
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
agent chaosblade 1 2023-11-06 11:31:01.999367578 +0800 CST deployed chaosblade-box-agent-1.0.2 1.0.2
chaosblade chaosblade 1 2023-11-06 11:28:33.615048287 +0800 CST deployed chaosblade-operator-1.7.2 1.7.2
chaosblade-box chaosblade 1 2023-10-31 18:10:11.656259774 +0800 CST deployed chaosblade-box-1.0.3 1.0.3
[root@master ~]# kubectl get deployments.apps -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
chaosblade chaos-agent 1/1 1 1 144m
chaosblade chaosblade-box 1/1 1 1 5d19h
chaosblade chaosblade-box-mysql 1/1 1 1 5d19h
chaosblade chaosblade-operator 1/1 1 1 147m
2. 模拟实验
由于k8s环境下的节点演练,和主机演练实质相同,所以这里将不再赘述。下面将重点介绍容器和pod的演练
2.1 安装测试demo
# 安装应用示例
[root@master guestbook]# ls
guestbook-deployment.yaml loss_pod_network_by_names.yaml redis-master-service.yaml redis-slave-service.yaml
guestbook-service.yaml redis-master-deployment.yaml redis-slave-deployment.yaml
[root@master guestbook]# kubectl apply -f redis-master-deployment.yaml -n chaosblade
[root@master guestbook]# kubectl apply -f redis-master-service.yaml -n chaosblade
[root@master guestbook]# kubectl apply -f redis-slave-deployment.yaml -n chaosblade
[root@master guestbook]# kubectl apply -f redis-slave-service.yaml -n chaosblade
[root@master guestbook]# kubectl apply -f guestbook-deployment.yaml -n chaosblade
[root@master guestbook]# kubectl apply -f guestbook-service.yaml -n chaosblade
[root@master guestbook]# kubectl get pods -n chaosblade -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
chaosblade-operator-9d5ff7d9f-rv4l5 1/1 Running 1 (2d19h ago) 3d 10.244.3.8 node2 <none> <none>
chaosblade-tool-q8j5d 1/1 Running 1 (2d19h ago) 3d 172.20.70.84 node2 <none> <none>
chaosblade-tool-rxzlj 1/1 Running 1 (2d19h ago) 3d 172.20.70.92 master <none> <none>
chaosblade-tool-svbsp 1/1 Running 1 (2d19h ago) 3d 172.20.70.69 node1 <none> <none>
guestbook-v1-5457d6dd58-b4xfk 1/1 Running 0 43h 10.244.2.18 node1 <none> <none>
guestbook-v1-5457d6dd58-lqshp 1/1 Running 0 43h 10.244.0.10 master <none> <none>
guestbook-v1-5457d6dd58-n7zdm 1/1 Running 0 43h 10.244.3.14 node2 <none> <none>
redis-master-77456ff7b4-8j8ld 1/1 Running 0 43h 10.244.2.16 node1 <none> <none>
redis-slave-5698767898-nfwr4 1/1 Running 0 43h 10.244.3.13 node2 <none> <none>
redis-slave-5698767898-rcdnq 1/1 Running 0 43h 10.244.2.17 node1 <none> <none>
2.2 模拟容器内cpu满载
- 选择演练场景:Kubernetes – Cpu资源 – 容器内Cpu满载,点击创建演练

- 在页面设置演练名称、分组名称、应用、应用分组和机器列表等

- 演练内容将自动添加,点击配置相关参数

# 获取相关配置参数的方法
[root@master ~]# kubectl describe pod guestbook-v1-5457d6dd58-q74sc -n chaosblade
Name: guestbook-v1-5457d6dd58-q74sc
Namespace: chaosblade
Priority: 0
Service Account: default
Node: node2/172.20.70.84
Start Time: Tue, 31 Oct 2023 18:05:55 +0800
Labels: app=guestbook
pod-template-hash=5457d6dd58
version=1.0
Annotations: <none>
Status: Running
IP: 10.244.3.9
IPs:
IP: 10.244.3.9
Controlled By: ReplicaSet/guestbook-v1-5457d6dd58
Containers:
guestbook:
Container ID: containerd://ab4357a8e96fb3593595a8da1b16ffa6148fffeaf20784485293584a5f0c1215 // 填写containerd://后的内容
......
# 获取容器索引
# Pod代表一组容器,容器可以是一个或多个
# 可以看到在指定的Pod guestbook-v1-5457d6dd58-q74sc中只有一个容器,并且容器的名称是 guestbook。由于只有一个容器,因此其索引为0。
[root@master ~]# kubectl get pod guestbook-v1-5457d6dd58-q74sc -n chaosblade -o jsonpath='{.spec.containers[*].name}'
guestbook
- 在全局配置页面完成以下配置

- 点击下一步、创建演练

- 点击演练详情,跳转到演练页面,点击执行演练

- 待演练成功后,查看容器内cpu状态

[root@master ~]# kubectl exec -it guestbook-v1-5457d6dd58-q74sc -n chaosblade -c guestbook top
# 可以看到容器内Cpu负载达到80%
- 待演练结束后(手动结束或自动结束),再查看容器cpu状态

可以看到cpu负载已恢复到正常

2.3 模拟容器内内存负载
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 内存资源 – 容器内内存负载
步骤3中配置mem-percent、mode
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.2 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内内存情况,可以看到内存负载接近60%

待演练结束后,再查看容器内内存情况,可以看到内存已经恢复到正常

2.4 网络资源
2.4.1 模拟容器内网络丢包
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 网络资源 – 容器内网络丢包
步骤3中配置interface、percent、destination-ip
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内网络情况,可以看到在ping目标ip时,丢包率在50%左右
[root@master ~]# kubectl exec -it guestbook-v1-5457d6dd58-q74sc -n chaosblade -c guestbook sh

待演练结束后,再查看容器内网络情况,可以看到网络已经恢复到正常

2.4.2 模拟容器内网络占用
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 网络资源 – 容器内网络占用
步骤3中配置port
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内网络情况,可以看到8888端口被占用

待演练结束后,再查看容器内网络情况,可以看到端口已被释放

2.4.3 模拟容器内网络Dns异常
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 网络资源 – 容器内网络Dns异常
步骤3中配置domain、ip(通过nslookup www.baidu.com获取)
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内网络情况,可以看到网络Dns异常

待演练结束后,再查看容器内网络情况,可以看到Dns恢复正常

2.4.4 模拟容器内网络乱序
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 网络资源 – 容器内网络乱序
步骤3中配置correlation、interface、percent、destination-ip、time
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)


创建演练成功后执行
执行成功后查看容器内网络情况,可以看到网络存在乱序现象,往返时间达到设定的100ms

待演练结束后,再查看容器内网络情况,可以看到网络恢复正常

2.4.5 模拟容器内网络损坏
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 网络资源 – 容器内网络损坏
步骤3中配置interface、percent、destination-ip
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内网络情况,可以看到网络损坏

待演练结束后,再查看容器内网络情况,可以看到网络恢复正常

2.4.6 模拟容器内网络延迟
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 网络资源 – 容器内网络延迟
步骤3中配置interface、time、destination-ip
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内网络情况,可以看到网络延迟达到设定的100ms

待演练结束后,再查看容器内网络情况,可以看到网络恢复正常

2.5 磁盘资源
2.5.1 模拟容器内文件移动
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 磁盘资源 – 容器内文件移动
步骤3中配置filepath、target
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内演练结果

待演练结束后,再查看容器内文件,已恢复到原有位置

2.5.2 模拟容器内文件新增
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 磁盘资源 – 容器内文件新增
步骤3中配置filepath、content
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内演练结果,可以看到新增的文件

待演练结束后,再查看容器,文件已删除

2.5.3 模拟容器内文件删除
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 磁盘资源 – 容器内文件删除
步骤3中配置filepath
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内演练结果,可以看到指定的文件被删除

待演练结束后,再查看容器,文件已恢复

2.5.4 模拟容器内文件追加
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 磁盘资源 – 容器内文件追加
步骤3中配置content、filepath
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内演练结果

容器内文件追加:已经追加的内容不支持恢复
2.5.5 模拟容器更改文件属性
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 磁盘资源 – 容器内文件追加
步骤3中配置filepath
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内文件属性,可以看到文件的权限被改为了777

待演练结束后,再查看容器,文件权限已恢复

2.5.6 模拟容器内磁盘负载提升
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 磁盘资源 – 容器内磁盘负载提升
步骤3中配置path、size、write
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内磁盘负载重复着不断上升

待演练结束后,再查看容器磁盘,已恢复正常

2.5.7 模拟容器内磁盘填充
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 磁盘资源 – 容器内磁盘填充
步骤3中配置path、percent
guestbook容器内dd指令版本问题,导致演练失败。该演练使用redis-slave容器
namespace、container-ids、container-index、container-names、labels和names填写相应的值

创建演练成功后执行
执行成功后查看容器内磁盘负载达到80%

待演练结束后,再查看容器磁盘,已恢复正常

2.6 应用进程
2.6.1 模拟容器内进程停止
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 应用进程 – 容器内进程停止
步骤3中配置process
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内top进程被停止

2.6.2 模拟容器内进程杀死
步骤同 2.2中步骤相似,演练场景选择:Kubernetes – 应用进程 – 容器内进程杀死
步骤3中配置process,signal
namespace、container-ids、container-index、container-names、labels和names都不变(和 2.1 中使用同一个节点机)

创建演练成功后执行
执行成功后查看容器内top进程被杀死

3. 常见错误
3.1 kubectl get pods -A 查看 coredns 一直处于 Pending 或者 ContainerCreating 状态
# 查看日志
kubectl describe pods -n kube-system coredns-5bfd685c78-mmjxc
报错: network: open /run/flannel/subnet.env: no such file or directory
# 解决办法
# 在每个节点创建文件/run/flannel/subnet.env写入以下内容。注意每个节点都要加,不是主节点
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
3.2 deployment报错:missing required field “selector“ in io.k8s.api.apps.v1.DeploymentSpec
kubectl create -f deployment-test.yaml
error: error validating "deployment-test.yaml": error validating data: ValidationError(Deployment.spec): missing required field "selector" in io.k8s.api.apps.v1.DeploymentSpec;
# 解决办法
# 缺少selector属性,编辑yml文件加入即可
apiVersion: apps/v1
kind: Deployment
metadata:
name: nio4444-deployment
spec:
selector:
matchLabels:
app: nio4444-pod-label
replicas: 3
minReadySeconds: 10
strateg
3.3 helm install 报错
helm install nginx apphub/nginx
# 报错 Error: unable to build kubernetes objects from release manifest: unable to recognize "": no matches for kind "Deployment" in version "extensions/v1beta1"
# 解决办法
helm pull apphub/nginx-ingress --untar
grep -irl "extensions/v1beta1" nginx-ingress | grep deployment
grep -irl "extensions/v1beta1" nginx-ingress | grep deploy | xargs sed -i 's#extensions/v1beta1#apps/v1#g'
helm install nginx1 ./nginx-ingress/
3.4 Readiness probe failed: HTTP probe failed with statuscode: 500
修改yml文件,加入一行 ‘–kubelet-insecure-tls’

3.5 执行blade create时权限错误
[root@master chaosblade-1.7.2]# ./blade create k8s node-cpu fullload --names cn-hangzhou.192.168.0.205 --cpu-percent 80 --kubeconfig ~/.kube/config
{"code":63061,"success":false,"error":"`getClient`: k8s exec failed, err: Get \"https://172.20.70.92:6443/api?timeout=32s\": x509: certificate signed by unknown authority (possibly because of \"crypto/rsa: verification error\" while trying to verify candidate authority certificate \"kubernetes\")"}
# 解决办法
[root@master chaosblade-1.7.2]# mv $HOME/.kube $HOME/.kube.bak
[root@master chaosblade-1.7.2]# mkdir $HOME/.kube
[root@master chaosblade-1.7.2]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master chaosblade-1.7.2]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
个人原创,禁止转载!如有侵权,联系必删
717707754@qq.com

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)