毕业设计:基于语音识别的智能垃圾分类系统
毕业设计:基于语音识别的智能垃圾分类系统通过分析语音指令和内容,实现自动垃圾分类。我们采用了先进的语音识别技术和深度学习算法,构建了一个高效准确的垃圾分类模型。通过训练模型,我们能够将语音指令转化为垃圾类别,并自动将垃圾分类到相应的垃圾桶中。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,它提供了一个具有挑战性和创新性的研究课题。无论您对深度学习技术保持浓厚兴趣,还是希望探索机
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于语音识别的智能垃圾分类系统
课题背景和意义
随着全球城市化进程的加快和垃圾问题的日益突出,垃圾分类成为了一项紧迫的任务。然而,传统的人工垃圾分类方式效率低下且成本高昂。基于语音识别的智能垃圾分类系统能够通过分析语音指令和语音内容,自动识别垃圾的种类,并将其准确分类。这种系统不仅能够提高垃圾分类的效率和准确性,还能够鼓励和引导人们积极参与垃圾分类,促进环境保护和资源回收利用,具有重要的社会和环境意义。
实现技术思路
一、算法技术理论
1.1 语音增强算法
NMF是一种常用的盲源分离方法,它通过将观测到的混合信号表示为非负矩阵的乘积形式,从中分解出源信号的近似表示。在语音增强中,观测信号是由混合的干净语音信号和背景噪声组成。通过应用NMF,可以将观测信号分解为干净语音信号和噪声的近似表示。基于时间约束的NMF方法进一步考虑到语音信号的时序特性。它利用了语音信号在时间上的平稳性和频谱上的变化性。具体而言,该方法使用了两个NMF模型,一个用于建模语音的谱信息,另一个用于建模语音的时序信息。通过在两个模型之间添加时间约束,可以更好地保留语音信号的时序特性。
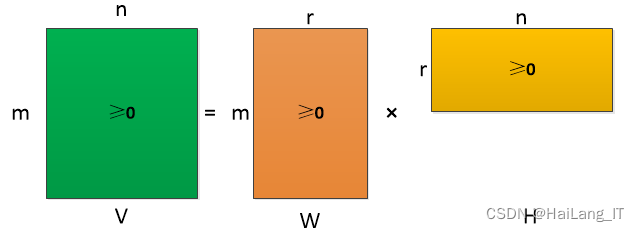
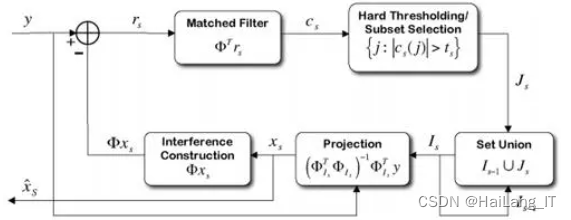
疏性是语音信号的特性之一,利用非负矩阵分解可以得到基矩阵和系数矩阵两种形式的矩阵。然而,在分解的过程中,稀疏度不易控制,容易导致过度拟合或残余噪声过多的情况。稀疏约束系数是解决这一问题的关键所在,通过控制系数矩阵的稀疏度,可以解决过度拟合和噪声干扰的问题。稀疏度正交匹配追踪算法(OMP)主要用于重构原始语音信号,但关注的是纯净语音信号,对于噪声信号来说,随着迭代次数增加,噪声分量会增大。因此,为了保证重构语音的纯净性,必须对重构阶段加以控制,通过设置能量阈值来控制重构阶段。
双重约束NMF是一种基于NMF的方法,它结合了频谱约束和时域约束。在语音增强中,双重约束NMF通过对观测信号的频谱进行NMF分解,并在分解过程中引入频谱和时域的约束条件。频谱约束旨在保留语音信号的谱特性,使其更接近干净语音的频谱。时域约束则用于捕捉语音信号的时序特性,避免过度拟合和残余噪声的引入。通过这种双重约束,双重约束NMF能够更准确地分离语音信号和噪声。
改进OMP算法是一种迭代稀疏表示算法,用于估计语音信号的稀疏表示系数。在语音增强中,改进OMP算法通过迭代选择最相关的基向量来逐步重构原始语音信号,并利用稀疏性约束来控制噪声的引入。改进OMP算法相比传统的OMP算法在选择基向量时引入了一些改进策略,如阈值设置和迭代次数的控制,以提高对噪声的抑制效果和语音信号的重构质量。
1.2 端点检测算法
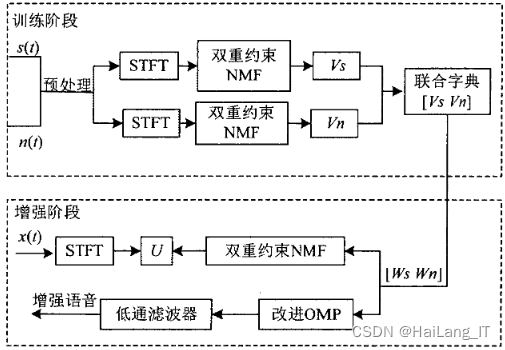
通过EMD算法的分解、相关分析和稀疏表示的方法,结合OS-DL算法和子带频带方差法,可以实现对语音信号的降噪处理。这种方法可以有效地分离语音信号和噪声,并重构出清晰的语音信号,从而提高语音的质量和清晰度。
首先,利用EMD算法对语音信号进行分解,得到多个IMF分量。然后,采用相关分析的方法去除每个分量中的噪声部分。接下来,通过OS-DL算法进行字典的训练,得到纯净语音信号和噪声信号,并将分离出的语音信号和噪声信号进行稀疏表示,得到包含系数的矩阵。利用这个系数矩阵对语音信号进行重构,得到降噪后的语音信号。然后,通过子带频带方差法计算每帧均匀子带分离的频率方差值。在确定未输入语音阶段的帧数后,可以进一步得到阈值,最终求得语音信号的起始点。
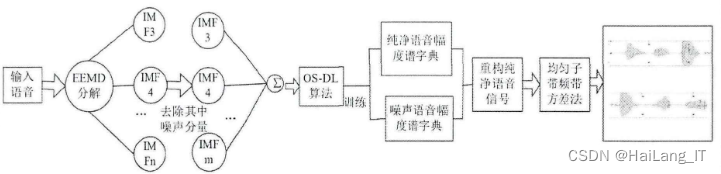
具体算法步骤如下:
- Step 1: 输入语音信号(带噪声);
- Step 2: 利用EMD算法对语音信号进行分解,得到多个IMF分量;
- Step 3: 利用OS-DL算法进行字典训练;
- Step 4: 对训练出的语音信号和噪声信号进行稀疏表示,得到系数矩阵;
- Step 5: 对系数矩阵进行信号重构,得到消噪后的纯净语音信号;
- Step 6: 对重构后的语音信号进行分帧;
- Step 7: 计算每帧子带分离的频带方差;
- Step 8: 根据频域方差双门限法进行端点的检测。
通过这些步骤,可以实现对带噪声的语音信号进行分解、降噪和端点检测的处理。最终得到的结果是清晰的纯净语音信号,去除了噪声并确定了语音的起止点。
1.3 深度神经网络
深度神经网络(DNN)是一种基于人工神经网络的机器学习模型,具有多层的神经网络结构。DNN的网络结构通常由多个神经网络层组成,每个层由多个神经元(或称为节点)组成,并且每个神经元与前一层的所有神经元相连接。DNN的每一层可以看作是对输入数据的不同特征表示,底层提取底层特征,而高层则逐渐提取更抽象的特征。这种分层结构使得DNN能够学习到输入数据的复杂特征和表示。
在DNN中,每个神经元通常由激活函数、权重和偏置组成。激活函数用于引入非线性变换,增加网络的表达能力。权重表示连接的强度,偏置表示神经元的偏置值。DNN通过反向传播算法(Backpropagation)来训练网络,即通过计算预测输出与实际输出之间的误差,并根据误差调整网络中的权重和偏置,以最小化误差。
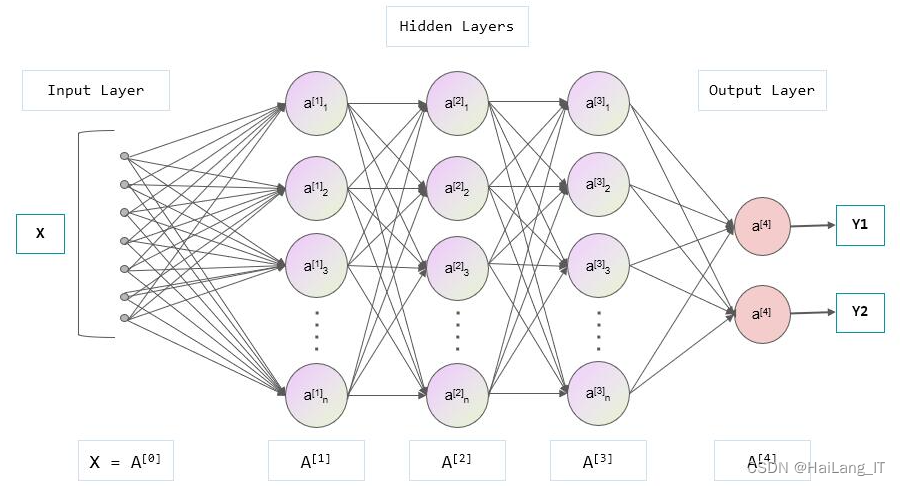
DNN自适应技术是为了解决语音识别中训练数据与测试数据不匹配的问题而提出的。由于说话人和说话环境通常处于多变的状态,传统的机器学习技术难以满足需求。DNN自适应技术通过线性变换、保守训练和子空间方法等方式,使得DNN能够适应不同的特征分布,提高系统的鲁棒性和泛化能力。这些方法可以在训练过程中对权重和偏置进行在线更新,引入额外的约束或惩罚项,或将数据映射到共享的子空间中。通过这些技术,DNN能够更好地适应不同的说话人和说话环境,提高语音识别系统的性能。
二、 数据集
2.1 数据集
由于网络上没有现有的合适的数据集,我决定亲自进行数据收集并制作一个全新的数据集,以支持基于语音识别的智能垃圾分类系统的研究。我选择了多个语音来源和场景,包括日常生活中的语音指令、垃圾分类说明等。通过在真实环境中录制语音样本,我能够捕捉到不同背景噪音和语音变体,从而提高模型在实际使用中的鲁棒性。通过手动标注语音样本的垃圾类别,我得到了准确的标签数据,为模型训练提供了有价值的参考。
2.2 数据扩充
为了增加数据集的规模和多样性,我采用了数据扩充的技术。对于语音数据,我应用了声音合成和语音变换技术,生成了具有不同语速、语调和音色的语音样本。通过数据扩充,我能够增加数据集的大小和多样性,提高模型的泛化能力。此外,我还对语音样本进行了噪声添加和音频剪辑等操作,以模拟真实的环境噪声和语音干扰情况。这些数据扩充技术使得数据集更加全面,能够更好地应对各种噪声和变化,提高了智能垃圾分类系统的性能和鲁棒性。
# 声音合成
synthesized_file = synthesizer(input_text, "synthesized.wav")
# 语音变换
converted_file = voice_conversion(input_file, "converted.wav")
# 对生成的语音样本进行噪声添加和音频剪辑等操作
# 噪声添加
noisy_file = add_noise(converted_file, "noisy.wav")
# 音频剪辑
clipped_file = audio_clipping(noisy_file, "clipped.wav")
# 将生成的样本文件添加到训练集中
training_data.append(clipped_file)三、实验及结果分析
3.1 实验环境搭建
在Kaidi语音识别工具上进行开发和实验的内容。首先,搭建了GMM-HMM模型,选择了13维MFCC特征及其一阶和二阶差分共39维作为GMM-HMM的输入。对比了DNN模型和本文的自适应DNN模型,选择了FBANK特征。窗长设为25ms,帧移为10ms。在实验中,DNN框架的输入层、隐藏层和输出层分别设置为1、5、1。其中,隐藏层包含2048个节点,输出层采用改进的Softmax进行归一化处理。另一方面,根据开发集与测试集的迭代关系,设置了深度神经网络的参数。在参数初始化完成后,对自适应模型进行迭代。
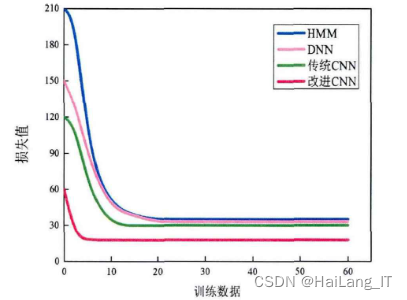
3.2 结果分析
为了应对复杂环境和噪声情况,提出了一种双重约束非负矩阵分解和改进正交匹配追踪算法的语音增强方法,相比传统算法获得了明显的改进。针对汉语语音识别的特点,改进了传统的语音信号特征提取算法,用GammaTone滤波器替代传统的三角滤波器,使得提取的特征更符合听觉特征。最后,通过比较分析了改进前后系统的多个评价指标,结果显示多个指标参数均获得明显提升。
def improved_omp(Y, D, sparsity):
# 初始化稀疏表示矩阵 X
X = np.zeros((D.shape[1], Y.shape[1]))
# 迭代优化
for i in range(Y.shape[1]):
residual = Y[:, i]
support = []
for j in range(sparsity):
# 计算原子与残差的相关性
correlations = np.abs(np.dot(D.T, residual))
# 选择具有最大相关性的原子
atom_index = np.argmax(correlations)
support.append(atom_index)
# 使用选择的原子更新稀疏表示矩阵
sub_dictionary = D[:, support]
sub_residual = Y[:, i] - np.dot(sub_dictionary, np.dot(np.linalg.pinv(sub_dictionary), Y[:, i]))
residual = sub_residual
# 更新稀疏表示矩阵 X
sub_dictionary = D[:, support]
X[support, i] = np.dot(np.linalg.pinv(sub_dictionary), Y[:, i])
return X在对照组中使用常见的GMM-HMM和传统DNN声学模型,并与自适应DNN模型进行比较。在系统训练过程中,将上下文相关的三音素融入模型中,并在训练完成后对输出特征进行解码。在采用自适应DNN模型时,为了保证词错误率尽可能低的情况下,训练时间也不至于过长,对DNN隐藏层数量和节点个数进行了多组实验。
最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 16
16 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)