
巧妙的 Node.js:Node JS 中的 Node.Clustering
近年来,Node.js变得非常流行。它还能够吸引LinkedIn,Netflix和eBay等大公司。这显示了它的架构功能和效率。扩展应用程序的性能是支持不断增长的客户端数量的重要一步。在Node.js中,群集是一种允许利用基于多核处理器的硬件的技术。默认情况下,Node.js遵循基于单线程事件循环的体系结构。即使计算机具有多个 CPU 内核,默认情况下Node.js也不会使用所有 CPU 内核。它
概述
近年来,Node.js变得非常流行。它还能够吸引LinkedIn,Netflix和eBay等大公司。这显示了它的架构功能和效率。扩展应用程序的性能是支持不断增长的客户端数量的重要一步。在Node.js中,群集是一种允许利用基于多核处理器的硬件的技术。
介绍
默认情况下,Node.js遵循基于单线程事件循环的体系结构。即使计算机具有多个 CPU 内核,默认情况下Node.js也不会使用所有 CPU 内核。它仅将一个 CPU 内核用于处理事件循环的主线程。因此,例如,如果您有一个四核系统,则默认情况下 Node 将仅使用其中一个。
假设两个请求同时出现;在这种情况下,事件循环将只能接受其中一个,而另一个将进入队列。因此,要同时处理大量用户,一个内核是不够的。为了处理如此繁重的负载,我们需要启动一个由此类Node.js进程组成的集群,从而使用多个内核。
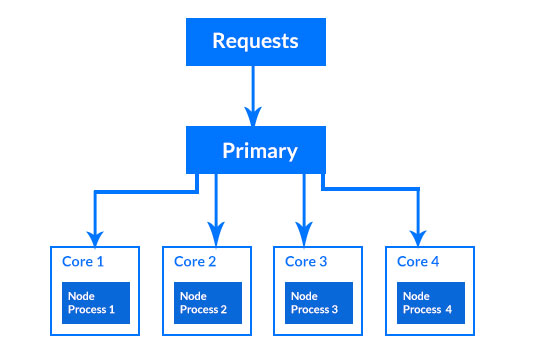
Node.js与集群模块捆绑在一起。群集模块允许创建子进程,这些子进程是在同一服务器端口上并发运行的程序副本。每个子进程都有一个事件循环、V8 实例和内存。有一个父进程将流量路由到这些子进程。为了与父进程进行通信,子进程采用进程间通信。
因此,在使用集群模块时,如果是 4 核计算机,您将拥有四个程序副本。这将允许您以相同的速度处理四倍于正常流量的流量。因此,群集能够提高Node.js应用程序的性能。
聚类的必要性
Node.js具有单线程事件循环体系结构。这意味着只有一个线程接收所有请求。这并不意味着您的Node.js应用程序不能使用多个内核。为了利用多个内核,需要启动一组进程来处理负载。集群模块是设置集群和利用众多处理器所必需的。
当应用程序的客户端增长时,需要可伸缩性。必须更新应用程序,以便支持大量用户并为所有用户提供良好的体验。群集充当负载平衡和并行处理服务。
当负载在应用程序的多个内核之间共享时,应用程序的性能会得到显著提升。如今,大多数系统都具有多个内核。因此,必须使用群集模块来从应用程序中获得最佳性能。
Node.js 群集模块如何工作?
Node.js集群模块可以说是提供了负载均衡服务器。应用程序的负载由父进程分发到在共享端口上运行的子进程。假设正在处理一个大型同步操作。事件循环占用所有进程的同步部分。这将使其他请求进入队列。这将花费大量时间来处理这些请求。因此,多个过程可以减少等待时间并提高性能。
当多个进程正在运行时,如果一个进程参与大量 CPU 密集型进程,则还有其他进程可以处理传入请求。这也将确保多核的利用率。因此,群集模块支持子进程之间的负载共享,并防止应用程序停止。
有一个父进程或一个主进程可用于管理子进程的负载。主进程侦听进程。有两种方式可以路由流量。一种是基于循环技术。在这种情况下,负载在子进程之间平均分配。第二种方法涉及将工作发送到感兴趣的子进程。
在 Node.js 中使用聚类分析的优点
在Node.js中使用集群有许多不同的优点:
- 由于 Node.js 程序可能会使用所有可用的 CPU 资源(现在大多数 PC 都具有多核 CPU),因此处理负担将分配给这些内核。随着负载平衡的完成,所有 CPU 内核都得到了充分利用。将创建多个单线程进程,这将提高系统的吞吐量(以每秒请求数衡量)。
- 由于有许多进程可以接收传入请求,因此允许同时处理多个请求。即使存在阻塞或冗长的作业,也只有一个工作人员受到影响,其他工作人员可以继续处理其他请求。在阻止过程完成之前,您的Node.js应用程序不会像以前那样停止响应。
- 拥有多个工作进程允许软件在很少或没有停机时间的情况下进行更新。它们可以一次回收/重新启动一个,因为有很多工人。这意味着一个子进程可以顺利地替换另一个子进程,并且永远不会有所有工人都处于非活动状态的时刻。如您所见,这可以快速提高更新的速度和效率。
- 如果启动的进程意外或故意死亡,可以立即启动新进程作为死亡进程的替代品,而无需手动中断或任何延迟。
- 使用大量内核进行执行可提高应用程序的应用程序性能。
- 通过充分利用处理器的潜力,大大减少了硬件资源的浪费。
- 无需创建额外的依赖项,因为所有工作都由 NodeJs 模块管理。
群集属性和方法
| 方法 | 描述 |
|---|---|
| fork() | 从主节点创建新工作线程 |
| settings | 返回包含群集设置的对象 |
| disconnect() | 断开所有工作人员的连接 |
| exitedAfterDisconnect | 如果 worker 在断开连接后退出,则返回 true,或者 kill 方法 |
| isMaster | 如果当前进程是主进程,则返回 true,否则返回 false |
| id | 工作人员的唯一 ID |
| kill() | 杀死当前工作线程 |
| isConnected | 如果工作线程连接到其主服务器,则返回 true,否则返回 false |
| worker | 返回当前工作线程对象 |
| isWorker | 如果当前进程是 worker,则返回 true,否则返回 false |
| workers | 返回主节点的所有工作线程 |
| isDead | 如果工作进程已失效,则返回 true,否则返回 false |
| process | 返回全局子进程 |
| schedulingPolicy | 设置或获取 schedulingPolicy |
| send() | 向主站或工作人员发送消息 |
| setupMaster() | 更改集群的设置 |
例
现在让我们看一下如何使用集群模块来提高应用程序的性能。我们将创建两个应用程序,一个具有聚类功能,另一个没有聚类功能。
在开始创建应用程序之前,请检查系统是否已安装 Node.js。
设置一个简单的 NodeJS Express 服务器:
创建一个新目录,clustering-node.js借助以下命令:
$ mkdir clustering-node
现在通过以下命令切换到新创建的目录:
$ cd clustering-node
现在,要初始化Node.js项目,请在终端中执行以下命令:
$ npm init -y
将提出一系列关于该项目的问题。回答问题后,您会注意到目录中有一个package.json文件,其中包含您输入的所有信息。
现在使用节点包管理器安装 express
$ npm install --save express
成功完成后,express 及其版本将显示在 package.json 文件的 dependencies 部分。
现在创建一个名为 without-clustering.js 的文件。在此文件中,您将在不使用群集的情况下为应用程序编写代码。现在您的文件夹结构如下:
现在在 without-clustering.js 文件中编写以下代码:
const express = require("express");
const PORT = 3000;
const app = express();
// Log the process id of the current process.
console.log(`Worker with id ${process.pid} started`);
// GET endpoint for '/' path
app.get("/", (req, res) => {
res.send("Welcome to the API without the use of clustering");
});
// GET endpoint for '/nocluster' path.
app.get("/nocluster", function (req, res) {
// Log the time at the start of function execution.
console.time("API-without-cluster");
const base = 9;
const POW = 7;
let result = 0;
// Iterate 9^7 times.
for (let i = Math.pow(base, POW); i >= 0; i--) {
// Perform a complex operation.
result += i + Math.pow(i, 10);
}
// Log the time at the completion of complex operation's execution.
console.timeEnd("API-without-cluster");
console.log(`RESULT IS ${result} - from PROCESS ${process.pid}`);
// Return the result as response.
res.send(`Result number is ${result}`);
});
// Make the application listen on the specified port.
app.listen(PORT, () => {
console.log(`App listening on port: ${PORT}`);
});
在上面的代码片段中,首先导入了 express 框架,并创建了一个 express 实例。实例设置为在端口 3000 上运行。
已为 / 和 nocluster 路径创建了两个 HTTP GET 端点。GET API endpointat /nocluster 路径具有在每个请求时执行的复杂操作。一个具有 9^7 次迭代的循环,等于4782969(一个大值)。
pow() 操作在每次迭代中执行,并且每次都会将结果添加到结果变量中。结果变量将被记录下来,并在响应中发送。
复杂操作的开始和完成之间的时间也会被注销。复杂操作旨在模拟阻塞和 CPU 密集型操作。
现在通过终端中的以下命令运行快速应用程序:
$ node without-clustering.js
终端将给出类似于以下内容的输出:
Worker with id 616 started
App listening on port: 3000
现在在任何浏览器中打开 http://localhost:3000/nocluster。浏览器将显示以下响应:
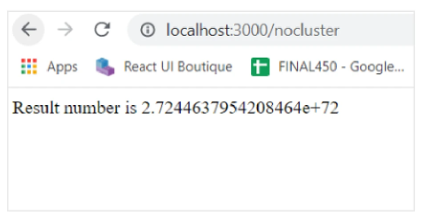
Node 服务器的终端将显示以下响应:
Worker with id 616 started
App listening on port: 3000
API-without-cluster: 1.033s
RESULT IS 2.7244637954208464e+72 - from PROCESS 616
将集群添加到 NodeJS Express 服务器:
现在创建一个with-clustering.js文件,并在该文件中写入以下代码以创建集群:
const express = require("express");
const PORT = 3001;
const cluster = require("cluster");
const totalCPUs = require("os").cpus().length;
if (cluster.isMaster) {
console.log(`Number of CPUs is ${totalCPUs}`);
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < totalCPUs; i++) {
cluster.fork();
}
cluster.on("exit", (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
console.log("Let's fork another worker!");
cluster.fork();
});
} else {
start();
}
function start() {
const app = express();
console.log(`Worker with id ${process.pid} started`);
app.get("/", (req, res) => {
res.send("Welcome to the API with the use of clustering");
});
app.get("/cluster", function (req, res) {
console.time("API-with-cluster");
const base = 9;
const POW = 7;
let result = 0;
// Iterate 9^7 times.
for (let i = Math.pow(base, POW); i >= 0; i--) {
// Perform a complex operation.
result += i + Math.pow(i, 10);
}
console.timeEnd("API-with-cluster");
console.log(`Result is ${result} - from PROCESS ${process.pid}`);
res.send(`Result number is ${result}`);
});
app.listen(PORT, () => {
console.log(`App listening on PORT : ${PORT}`);
});
}
在上面的代码片段中,已导入集群模块。require('os').cpus().length 用于获取系统上可用的 CPU 内核数。首先,检查集群进程是主进程还是工作进程。如果进程是主进程,则分叉等于内核数的子进程。如果它是一个工作进程,那么它将调用 start() 函数。
start() 函数包含我们在没有聚类的情况下创建的快速应用程序的副本。在 /cluster GET 端点中,已定义阻塞操作。
该程序将执行与以前相同的计算,但这次将完成子进程的创建,并且它们都将在同一端口 3001 上运行。fork() 方法用于创建子进程。
fork() 技术用于启动工作进程。返回一个 ChildProcess 对象,该对象具有集成的数据传输连接,用于在子对象与其父对象之间传递消息。
Express 应用程序已设置为在 PORT 3001 上运行。现在在终端中通过以下命令运行代码:
$ node with-clustering.js
根据计算机中的内核数,将出现类似的输出:
Number of CPUs is 8
Master 10468 is running
Worker with id 1620 started
Worker with id 11844 started
App listening on PORT : 3001
App listening on PORT : 3001
Worker with id 9844 started
Worker with id 7880 started
Worker with id 14792 started
Worker with id 14868 started
App listening on PORT : 3001
App listening on PORT : 3001
App listening on PORT : 3001
App listening on PORT : 3001
Worker with id 9252 started
App listening on PORT : 3001
Worker with id 3544 started
App listening on PORT : 3001
注意-最佳做法之一是生成的工作线程数不要超过可用逻辑内核的数量,因为这会导致调度开销。
现在在任何浏览器中打开 http://localhost:3001/cluster。浏览器将显示与之前相同的响应。
在终端中,您将看到如下响应:
API-with-cluster: 1.437s
Result is 2.7244637954208464e+72 - from PROCESS 3544
由于存在 8 个内核,因此创建了 8 个子进程,每个子进程位于端口 3001 上。集群版本将能够处理更多数量的并发请求,并且总体处理时间将更短。
结论
- 默认情况下,Node.js遵循基于单线程事件循环的体系结构。
- Node.js与集群模块捆绑在一起。cluster 模块允许创建子进程。
- 每个子进程都是程序的副本,并具有事件循环、V8 实例和内存。
- 群集充当负载平衡和并行处理服务。
- 当多个进程正在运行时,如果一个进程处于繁重的 CPU 密集型进程中,则还有其他进程可以处理传入的请求。
- 当负载在应用程序的多个内核之间共享时,应用程序的性能会得到显著提升。
- 有一个父进程或一个主进程可用,它通过将流量路由到子进程来管理负载。
- 有两种方式可以路由流量。一种是基于循环技术。另一个涉及将工作发送给感兴趣的子进程。

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐


 43
43 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)